SOC for intermediate. We understand what we are protecting, or how to make an inventory of infrastructure
Hello again. The cycle “SOC for ...” continues its movement and development. We have already covered the first layer of the internal kitchen of the centers for monitoring and responding to incidents in previous articles, so we will try to go a little further into the technical details and more subtle problems.
We have already indirectly dealt with the topic of asset management several times: both in the article on security control , and in matters of automation and artificial intelligence in SOC . Obviously, without an inventory of the customer’s infrastructure, the monitoring center cannot protect it. In this case, to make its detailed description is not a trivial task. And the main thing is that in a couple of months it is again irrelevant: some hosts have disappeared, others have appeared, new services or systems have appeared. But the protection of infrastructure is a continuous process, and SOC cannot slow down its activities until it receives relevant information about the assets of the customer. Let me remind you that the quality of Solar JSOC’s work is not governed by abstract promises, but by quite concrete SLA, followed by various sky punishments. How to get out in such a situation and not lose as a service provided?
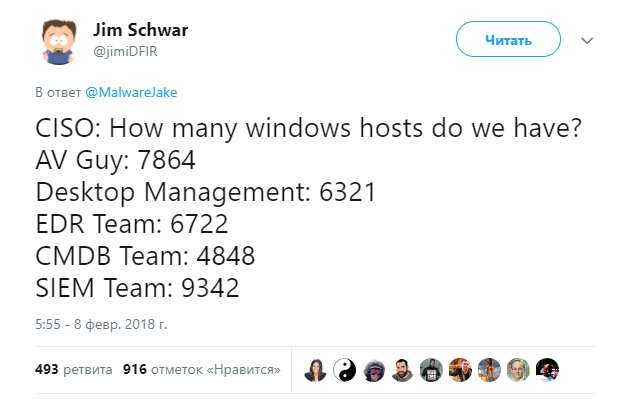
We now propose to return to this issue through one of the comparative examples of incident alerts:
It would seem that the difference between these two notifications is in depth. In the first case, the notification looks as if it was received automatically from the SIEM platform, while in the second case, the operator’s work and incident enrichment are visible. This is so and not so. In order for the operator to analyze the incident and draw any conclusions, it is extremely important for him to understand that (or who) lies behind these mysterious and almost identical IP addresses with customers, and use this information in the analysis of the incident.
')
20% of our readers will say about percents: “Well, for this, CMDB system is implemented in all companies, which is simpler than connecting data from it to the SIEM? Even the connector does not need to write. " Leave on this conviction colleagues from integrators and vendors. From our practice, sadly aware of this, information from the CMDB should not even be connected or exported to the SIEM due to its complete irrelevance. So you have to roll up your sleeves and do everything yourself. Let's look at this question more attentively and try to understand how to understand the depths of the infrastructure,without attracting the attention of nurses without relying on the full support of IT departments.
Eating an elephant in parts or immersed in the description of the infrastructure
In our move to an inventory of assets, we usually try to pass four control points.
1. Building a high-level but detailed organization network map
Here, the customer’s IT departments are the first and main contact (except for cases when the network equipment management system or firewall management is correctly implemented and configured in the company, but this is still an exception). The descriptive parts of information from network equipment, network diagrams, and so on are also used.
The target result of this stage is the ability to split all internal addresses into network zones with the identification of the following information:
This leads to the first important conclusion : assets are not only a description of specific hosts with detailed inventory information about them, but also the ability to describe network segments and use this data in reports / correlation / search by events.
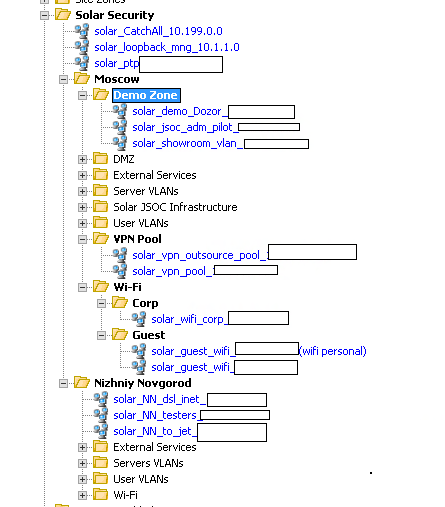
Here is how it looks in SIEM:
2. Description of the main subsystems in the data center
As a rule, the initial identification of these machines appears on the basis of the first business interviews. Communicating with security, IT, networkers and applied workers allows us, as a first approximation, to understand how the company's infrastructure is organized and which resources / systems in it are the most critical. Collecting information about their addressing and network accessories is quite easy. Further, in the point questions mode, it is already possible to obtain the required information:
At this stage, unloadings from various centralization systems usually help:
A second important conclusion follows from this: you need to be able to “pick up” information about assets from completely different sources and add this information to the SIEM in accordance with the configured monitoring scenarios and logic.
3. Description of critical hosts and assets in terms of information security
When the customer has identified his “pain points” and the most critical systems, we enter into a dialogue with those responsible for them, to figure out how these systems are related to each other, what data is stored there and what risks of information security are associated with them. We also evaluate them by additional parameters, after which we assign coefficients to some of the systems that increase the level of criticality. Here is what we pay attention to:
Example descriptions:
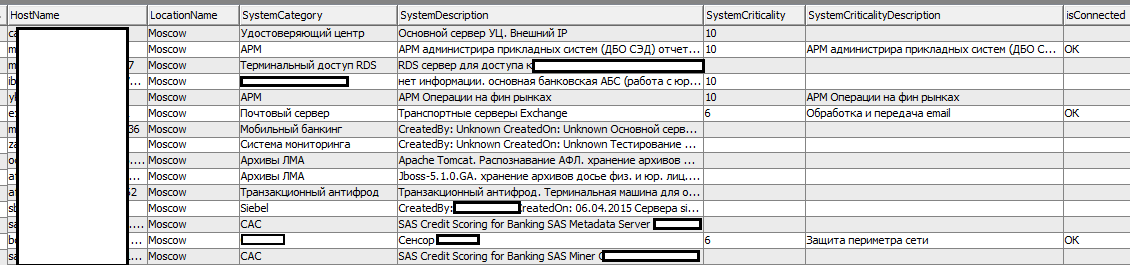
The third important conclusion : the SOC should be able to add its own descriptions of the purpose, functionality and criticality of the host for each asset and for each subnet entered into the system. As the saying goes, “the taste and color of all the markers are different,” and what is good in IT is not always necessary in information security.
4. Enriching Host / Asset Information
In the final, we are trying to enrich the information on the host / asset with data from information security inventory systems or security scanners:
This information is extremely useful for investigation, although, in our opinion, it is not primary in identifying and assessing the criticality of the incident itself associated with the host.
We understand the problems
Although even at first glance, the process of describing the infrastructure looks rather complicated, in reality these are only those difficulties that lie on the surface. As always, inside you can find a number of underwaterrakes of stones. Let's try to discuss them and share possible solutions.
Choosing a unique asset identifier
It would seem that the question is banal and obvious. Choose anything: even the IP-address (if several interfaces - assign the main), even the domain name, even the serial number. But in life, everything is not so simple.
Any hardware or software identifiers are really very good for their uniqueness and direct connection with the device. The problem is the same - we work with logs, and we detect incidents based on logs, but they simply do not have these unique identifiers. Therefore, we do not have (almost) any opportunity to correctly associate what is happening in our network with an asset.
The DNS name is also good in terms of its uniqueness (ignoring those companies that prefer not to use it). But the problem, unfortunately, is quite similar - the absolute majority of the logs do not contain any information about this DNS name itself. Therefore, matching an incident with an asset also remains a problem.
It would seem that we have no options left, we will have to work with an IP address. It appears in the vast majority of logs with which we have to deal, and in the case of the server segment is almost a guaranteed criterion for determining the device.
But things get more complicated when we try to use it to identify user hosts. Quite often, in user networks or parts of them, we are faced with DHCP and randomly issuing the IP address of a host within a segment. This breaks all the logic of the incident: at the time of the event, the IP address could relate to one machine, and by the time the analyst connects to the parsing or the customer's IT service blocks it, this IP address may already belong to a completely different host.
There are even more enchanting cases. Look, for example, at logging Windows with RDP authentication:

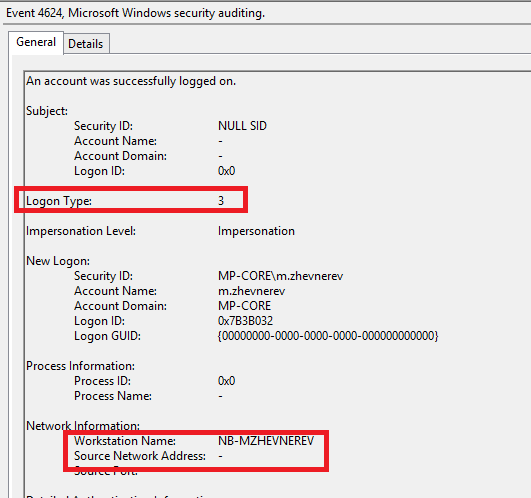
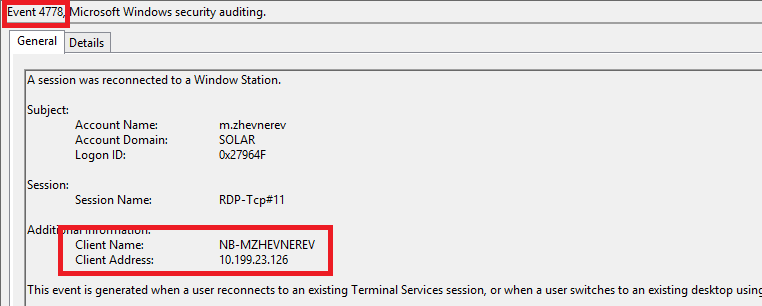
As a result, depending on the type of event, the identifier will be either a host or IP. And this problem is generally better solved at the level of parsing the event.
Most often we use the following host definition scheme. When processing events, a number of conditions are sequentially checked and the first non-zero value is selected (problems with parsing from the example above are solved at the level of parsers :)):
This process is performed for each incoming event and is used when checking all exclusion lists, profiles, etc.
It is important to note here that it’s never possible to acquire assets for all the hosts in the company and keep them up to date. In any case, there are guest networks, VPN address pools, test environments, the Internet . In these networks, you can not start an asset, because everything is constantly changing. But at the same time, it is still important to correctly determine the source of the activity, and not to generate alerts for the same host present in the logs in a different format (for example, nb-hostname.domain.local, nb-hostname, 10.10.10.10 (but there is nb -hostname in DHCP)).
Use of current inventory information when enriching events
When we talk about incident analysis, it is very important to operate with actual data on the presence of updates / software / vulnerabilities on the host, etc.
As a rule, regular scans (and, respectively, and updating information about assets) occur at best once a month. Scanning the entire infrastructure more often is practically unrealistic, and at some point this gives rise to another very important detail in incident handling, which is often overlooked: between two inventory scans, the state of the host can change as often as desired and at the same time eventually return to the original condition For example, in incidents involving malicious mailings, referrals to infected websites, identifying indicators of compromise, etc., it is very important to understand whether the antivirus was active at that particular moment.
We solve this problem in two ways:
This information is automatically added to the appropriate incident:

Keeping asset information up to date.
As we have already said, no matter how thoroughly you approach the description of the infrastructure, it will soon become obsolete. Literally in a month or two, the customer’s network will begin to change: new services or hosts will appear, old ones will disappear, some systems will change their purpose.
Here are a few approaches that we use in Solar JSOC to maintain the current context:
The game is not worth the candle, and the result - labor?
Surely, by the end of this article, not one of our practical readers has wondered: why do we need to fence all this insane construction, taking into account and updating the asset model? Maybe it's easier and “cheaper” to manually deal with each host in the event of an incident, and the end customer does not need such a meticulous inventory?
We will try with a few examples to show how the asset model simplifies and automates part of the activities of the SOC operator and helps in its daily work.
Ability to filter excess
"Correct" SIEM systems allow you to automatically use the asset model to filter potential incidents into exceptions. This can significantly reduce the time that the operator has to spend on the analysis of "garbage".
For example, we often begin to collect primary information about script triggers from a customer before we fill in the first network model, because the rule for identifying calls to C & C servers and malicious sites can be started fairly quickly.
Does this mean that the entire customer network is full of malware or, conversely, the reputational bases of C & C servers give so many false positives? As a rule, neither one nor the other. Just in the offices of the customer company there is a guest wifi, all user sessions of which use the same infrastructure of access to the Internet as the main client network, and therefore come into the view of monitoring.
Is it interesting to the customer how safe are the phones of external people who just used his guest Wi-Fi? Should SOC operator handle such incidents? Most likely no. So filtering Wi-Fi networks from this scenario is a very reasonable and desirable step.
Or another example: usually in a company at the level of security policy there is a restriction on using Remote Admin Tools. But helpdesk employees, whose duties include servicing remote machines, users on business trips or remote sales points, are often forced to use this tool in their daily work. Wouldn't it be easier for SOC to identify the helpdesk locations and ignore such events than to handle each suspicion of the incident manually?
Increasing the criticality and priority of the incident, depending on the specific asset
The situation, in my opinion, also does not require additional comments. An incident that occurred on the AWS of the CBD in a bank or at the junction of the main and technological segment in the energy sector will always be many times more important and more important than even fixing the launch of hacker tools in the user segment. And such an incident should be detected and processed much faster.
From our practice in recent years, it is clear that attackers have learned to use the weak prioritization of incidents in young SOCs. As one of the final stages of the attack, they use the so-called "incident storm", creating several dozen suspicions of the incident in different parts of the infrastructure, before seizing the target resource or compromising information. The SOC operator, processing several dozen incidents in turn, simply does not have time to get to the right, really critical, until it is too late. Whereas a proper prioritization would allow him to focus his attention on the most important incident and prevent the consequences of the attack.
Seeing the strange
The more information about the asset and the situation as a whole the operator has at the beginning of the analysis of the incident, the faster he will make a decision, and the more correct it will be. And of course, the greater the chance that a real complex attack, caught on the basis of a small anomaly, will be effectively identified and dismantled in a SOC.
Well, in general, who owns the information, he owns the world. On this we would like to finish our immersion in the subject of asset management. For all the remaining practical and not very questions - welcome to the comments. And to new meetings in the cycle "SOC for ....".
We have already indirectly dealt with the topic of asset management several times: both in the article on security control , and in matters of automation and artificial intelligence in SOC . Obviously, without an inventory of the customer’s infrastructure, the monitoring center cannot protect it. In this case, to make its detailed description is not a trivial task. And the main thing is that in a couple of months it is again irrelevant: some hosts have disappeared, others have appeared, new services or systems have appeared. But the protection of infrastructure is a continuous process, and SOC cannot slow down its activities until it receives relevant information about the assets of the customer. Let me remind you that the quality of Solar JSOC’s work is not governed by abstract promises, but by quite concrete SLA, followed by various sky punishments. How to get out in such a situation and not lose as a service provided?
We now propose to return to this issue through one of the comparative examples of incident alerts:
RAT utility AmmyAdmin is launched on host 172.16.13.2.vs
The RAT utility AmmyAdmin was launched on host 172.16.13.2, the Moscow office at Kuznetsky Most, the machine Ivanov Peter Mikhailovich, the deputy head of the communication center, the functionality - processing the flights of the IRC and working with the AWS KBR, remote work of the administrator is prohibited.
It would seem that the difference between these two notifications is in depth. In the first case, the notification looks as if it was received automatically from the SIEM platform, while in the second case, the operator’s work and incident enrichment are visible. This is so and not so. In order for the operator to analyze the incident and draw any conclusions, it is extremely important for him to understand that (or who) lies behind these mysterious and almost identical IP addresses with customers, and use this information in the analysis of the incident.
')
20% of our readers will say about percents: “Well, for this, CMDB system is implemented in all companies, which is simpler than connecting data from it to the SIEM? Even the connector does not need to write. " Leave on this conviction colleagues from integrators and vendors. From our practice, sadly aware of this, information from the CMDB should not even be connected or exported to the SIEM due to its complete irrelevance. So you have to roll up your sleeves and do everything yourself. Let's look at this question more attentively and try to understand how to understand the depths of the infrastructure,
Eating an elephant in parts or immersed in the description of the infrastructure
In our move to an inventory of assets, we usually try to pass four control points.
1. Building a high-level but detailed organization network map
Here, the customer’s IT departments are the first and main contact (except for cases when the network equipment management system or firewall management is correctly implemented and configured in the company, but this is still an exception). The descriptive parts of information from network equipment, network diagrams, and so on are also used.
The target result of this stage is the ability to split all internal addresses into network zones with the identification of the following information:
- Which site (geolocation / location, if applicable) refers to a specific IP address.
- What type of site (data center / head office / branch / point of sale) it belongs to.
- The global purpose of a dedicated network segment is user / corporate Wi-Fi / guest Wi-Fi / admins / server.
- The application purpose of this network segment is relative to the system or business application, if possible.
This leads to the first important conclusion : assets are not only a description of specific hosts with detailed inventory information about them, but also the ability to describe network segments and use this data in reports / correlation / search by events.
Here is how it looks in SIEM:
2. Description of the main subsystems in the data center
As a rule, the initial identification of these machines appears on the basis of the first business interviews. Communicating with security, IT, networkers and applied workers allows us, as a first approximation, to understand how the company's infrastructure is organized and which resources / systems in it are the most critical. Collecting information about their addressing and network accessories is quite easy. Further, in the point questions mode, it is already possible to obtain the required information:
- What exactly are the services and applications deployed on this host.
- What class of criticality according to IT is it assigned to?
- What is the functional role of the system (planned).
At this stage, unloadings from various centralization systems usually help:
- Virtualization systems. Often, comments on the creation of virtual machines describe their functional roles.
- Active Directory and other directories. At a minimum, the domain structure very often gives answers about the functional purpose of the systems:

- Various SZI (as a rule, antiviruses) have a large amount of inventory information:

- Or just a large Excel file, which lists key systems with reference to platforms, addressing, etc.
A second important conclusion follows from this: you need to be able to “pick up” information about assets from completely different sources and add this information to the SIEM in accordance with the configured monitoring scenarios and logic.
3. Description of critical hosts and assets in terms of information security
When the customer has identified his “pain points” and the most critical systems, we enter into a dialogue with those responsible for them, to figure out how these systems are related to each other, what data is stored there and what risks of information security are associated with them. We also evaluate them by additional parameters, after which we assign coefficients to some of the systems that increase the level of criticality. Here is what we pay attention to:
- How dangerous this system is in terms of monetizing the attack. Examples are the AWS of the CBD, the machines of the settlement center in banks, the machines of the treasury and the bank clients in other companies.
- How critical this system is in terms of compromising the data on it. Examples are management reporting systems, folders that store information with a commercial secret, etc.
- As far as this system is concerned, a burglary can be used to develop an attack on an infrastructure. Examples are central network equipment, antivirus servers, AD, and a security scanner (with the help of which, an attacker can often get access anywhere).
- Another reason for the high criticality of this host, which tells us the customer.
Example descriptions:
The third important conclusion : the SOC should be able to add its own descriptions of the purpose, functionality and criticality of the host for each asset and for each subnet entered into the system. As the saying goes, “the taste and color of all the markers are different,” and what is good in IT is not always necessary in information security.
4. Enriching Host / Asset Information
In the final, we are trying to enrich the information on the host / asset with data from information security inventory systems or security scanners:
- Hardware characteristics (processors, memory, disks, etc.).
- Information on the OS and all installed patches (and, if lucky, even with vulnerabilities that are relevant to them).
- List of installed software with versioning.
- List of processes running at the time of scanning.
- A lot of additional information (MD5 libraries, etc.).
This information is extremely useful for investigation, although, in our opinion, it is not primary in identifying and assessing the criticality of the incident itself associated with the host.
We understand the problems
Although even at first glance, the process of describing the infrastructure looks rather complicated, in reality these are only those difficulties that lie on the surface. As always, inside you can find a number of underwater
Choosing a unique asset identifier
It would seem that the question is banal and obvious. Choose anything: even the IP-address (if several interfaces - assign the main), even the domain name, even the serial number. But in life, everything is not so simple.
Any hardware or software identifiers are really very good for their uniqueness and direct connection with the device. The problem is the same - we work with logs, and we detect incidents based on logs, but they simply do not have these unique identifiers. Therefore, we do not have (almost) any opportunity to correctly associate what is happening in our network with an asset.
The DNS name is also good in terms of its uniqueness (ignoring those companies that prefer not to use it). But the problem, unfortunately, is quite similar - the absolute majority of the logs do not contain any information about this DNS name itself. Therefore, matching an incident with an asset also remains a problem.
It would seem that we have no options left, we will have to work with an IP address. It appears in the vast majority of logs with which we have to deal, and in the case of the server segment is almost a guaranteed criterion for determining the device.
But things get more complicated when we try to use it to identify user hosts. Quite often, in user networks or parts of them, we are faced with DHCP and randomly issuing the IP address of a host within a segment. This breaks all the logic of the incident: at the time of the event, the IP address could relate to one machine, and by the time the analyst connects to the parsing or the customer's IT service blocks it, this IP address may already belong to a completely different host.
There are even more enchanting cases. Look, for example, at logging Windows with RDP authentication:
As a result, depending on the type of event, the identifier will be either a host or IP. And this problem is generally better solved at the level of parsing the event.
Most often we use the following host definition scheme. When processing events, a number of conditions are sequentially checked and the first non-zero value is selected (problems with parsing from the example above are solved at the level of parsers :)):
- The network has static addressing, and in SIEM, an asset is created for this IP (identifier = asset name).
- In active DHCP leases there is information on HostName when sampling by IP from the log (identifier = host name, without domain).
- Does HostName log (id = hostname, without domain)?
- Is there an IP address (id = IP address) in the log?
This process is performed for each incoming event and is used when checking all exclusion lists, profiles, etc.
It is important to note here that it’s never possible to acquire assets for all the hosts in the company and keep them up to date. In any case, there are guest networks, VPN address pools, test environments, the Internet . In these networks, you can not start an asset, because everything is constantly changing. But at the same time, it is still important to correctly determine the source of the activity, and not to generate alerts for the same host present in the logs in a different format (for example, nb-hostname.domain.local, nb-hostname, 10.10.10.10 (but there is nb -hostname in DHCP)).
Use of current inventory information when enriching events
When we talk about incident analysis, it is very important to operate with actual data on the presence of updates / software / vulnerabilities on the host, etc.
As a rule, regular scans (and, respectively, and updating information about assets) occur at best once a month. Scanning the entire infrastructure more often is practically unrealistic, and at some point this gives rise to another very important detail in incident handling, which is often overlooked: between two inventory scans, the state of the host can change as often as desired and at the same time eventually return to the original condition For example, in incidents involving malicious mailings, referrals to infected websites, identifying indicators of compromise, etc., it is very important to understand whether the antivirus was active at that particular moment.
We solve this problem in two ways:
- Separate alerts for disconnection / status changes of the software or host.
- Uploading statuses by host or using host logs to update current status.
This information is automatically added to the appropriate incident:
Keeping asset information up to date.
As we have already said, no matter how thoroughly you approach the description of the infrastructure, it will soon become obsolete. Literally in a month or two, the customer’s network will begin to change: new services or hosts will appear, old ones will disappear, some systems will change their purpose.
Here are a few approaches that we use in Solar JSOC to maintain the current context:
- Replenishment of information on on-demand assets, upon the occurrence of suspicions of an incident. When analyzing the incident revealed that the asset (IP address) was not included in our network model, upon notification, we ask the customer for information on the host. This applies to filling in information about both the asset and subnets.
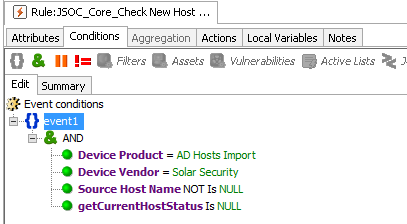
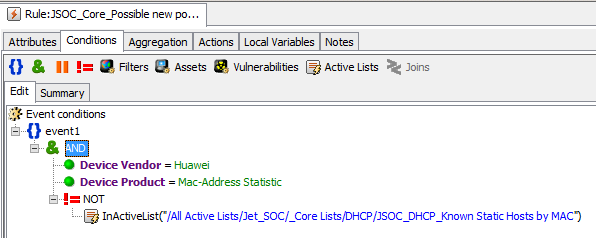
- Regular inventory of potential new hosts. There are several options:
- Unload hosts from a domain, antivirus, etc., and compare it with the current state. This is done with the help of the simplest correlation rule, under which you can specify a specific OrganizationUnit, hostname by mask, etc. - depending on what you want to see.
- Unload IP-MAC matching on switches in some network segments.
- Monitor the network activity of the host.
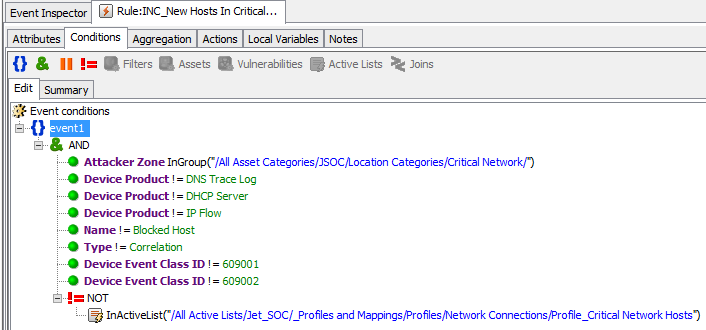
“On delivery” to the process described above, we receive information about hosts that have not appeared for a long time in the designated reports and which probably no longer exist. For example, you can “follow the process of dismissal of employees” and make alerts / reports on the movement of the host / UZ in “OU = disabled”.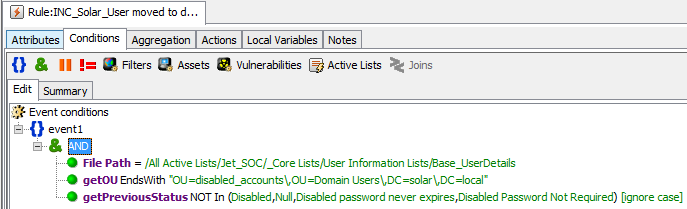
- Unload hosts from a domain, antivirus, etc., and compare it with the current state. This is done with the help of the simplest correlation rule, under which you can specify a specific OrganizationUnit, hostname by mask, etc. - depending on what you want to see.
- Finally, the most difficult, but very important process is the “manual” gathering from the responsible specialists of the customer information about changes, new subsystems, or scaling up old ones. In Solar JSOC, the contract service manager deals with this, and often this work brings significantly more results than the automation described above.
The game is not worth the candle, and the result - labor?
Surely, by the end of this article, not one of our practical readers has wondered: why do we need to fence all this insane construction, taking into account and updating the asset model? Maybe it's easier and “cheaper” to manually deal with each host in the event of an incident, and the end customer does not need such a meticulous inventory?
We will try with a few examples to show how the asset model simplifies and automates part of the activities of the SOC operator and helps in its daily work.
Ability to filter excess
"Correct" SIEM systems allow you to automatically use the asset model to filter potential incidents into exceptions. This can significantly reduce the time that the operator has to spend on the analysis of "garbage".
For example, we often begin to collect primary information about script triggers from a customer before we fill in the first network model, because the rule for identifying calls to C & C servers and malicious sites can be started fairly quickly.
Does this mean that the entire customer network is full of malware or, conversely, the reputational bases of C & C servers give so many false positives? As a rule, neither one nor the other. Just in the offices of the customer company there is a guest wifi, all user sessions of which use the same infrastructure of access to the Internet as the main client network, and therefore come into the view of monitoring.
Is it interesting to the customer how safe are the phones of external people who just used his guest Wi-Fi? Should SOC operator handle such incidents? Most likely no. So filtering Wi-Fi networks from this scenario is a very reasonable and desirable step.
Or another example: usually in a company at the level of security policy there is a restriction on using Remote Admin Tools. But helpdesk employees, whose duties include servicing remote machines, users on business trips or remote sales points, are often forced to use this tool in their daily work. Wouldn't it be easier for SOC to identify the helpdesk locations and ignore such events than to handle each suspicion of the incident manually?
Increasing the criticality and priority of the incident, depending on the specific asset
The situation, in my opinion, also does not require additional comments. An incident that occurred on the AWS of the CBD in a bank or at the junction of the main and technological segment in the energy sector will always be many times more important and more important than even fixing the launch of hacker tools in the user segment. And such an incident should be detected and processed much faster.
From our practice in recent years, it is clear that attackers have learned to use the weak prioritization of incidents in young SOCs. As one of the final stages of the attack, they use the so-called "incident storm", creating several dozen suspicions of the incident in different parts of the infrastructure, before seizing the target resource or compromising information. The SOC operator, processing several dozen incidents in turn, simply does not have time to get to the right, really critical, until it is too late. Whereas a proper prioritization would allow him to focus his attention on the most important incident and prevent the consequences of the attack.
Seeing the strange
The more information about the asset and the situation as a whole the operator has at the beginning of the analysis of the incident, the faster he will make a decision, and the more correct it will be. And of course, the greater the chance that a real complex attack, caught on the basis of a small anomaly, will be effectively identified and dismantled in a SOC.
Well, in general, who owns the information, he owns the world. On this we would like to finish our immersion in the subject of asset management. For all the remaining practical and not very questions - welcome to the comments. And to new meetings in the cycle "SOC for ....".
Source: https://habr.com/ru/post/353314/
All Articles