The history of gaming analytics platforms
Since the release of the Dreamcast console and the emergence of a modem adapter, game developers have been able to collect data from players about their behavior in their natural habitat. In fact, the story of game analytics began with old PC games like EverQuest, released in 1999. Game servers were needed to authorize users and fill worlds, but at the same time provided the ability to record data about the game process.
Since 1999, the situation with the collection and analysis of data has changed significantly. Instead of storing data locally in the form of log files, modern systems can track actions and apply machine learning in near real time. I will talk about the four stages of gaming analytics development, which I identified during my time in the gaming industry:
- Regular files: data is stored locally on game servers
- Databases: Data is obtained as simple files and loaded into a database.
- Data Lakes: Data is stored in Hadoop / S3 and then loaded into the database.
- Serverless stage: managed services are used to store and execute queries
Each of these stages of evolution supported an increasing amount of data collected and reduced the delay between data collection and analysis. In this post, I will present examples of systems from each of these eras and talk about the pros and cons of each approach.
Game analytics began to gain momentum from about 2009. Georg Zoeller from Bioware has created a system for collecting game telemetry in the game development process. He introduced this system at GDC 2010 . Shortly thereafter, Electronic Arts began collecting data from games after development to track the behavior of real players. In addition, scientific interest in the use of analytics in gaming telemetry has steadily increased. Researchers in this field, such as Ben Medler, have suggested using game analytics to personalize the gameplay.
')
Although over the past two decades there has been a general evolution of gameplay analytics pipelines, there is no clear distinction between different eras. Some game teams still use systems from earlier eras, and maybe they are better suited for their purposes. In addition, there are a large number of ready-made game analytics systems, but we will not consider them in this post. I will talk about the teams of game developers who collect telemetry and use their own data pipeline for this.
The era of simple files

Components of analytics architecture before the database era
I started playing game analytics at Electronic Arts in 2010, even before EA created an organization to work with this data. Although many game companies have already collected huge amounts of gameplay data, most telemetry was stored in the form of log files or other simple file formats stored locally on game servers. No data could not be directly queried, and the calculation of the main metrics, for example, the number of monthly active users (MAU) required considerable effort.
Electronic Arts has built a replay function into Madden NFL 11, providing an unexpected source of gaming telemetry. After each match, a game report was transmitted to the game server in XML format, which listed the strategies of the game, the movements made during the game, and the results of the downs. As a result, there were millions of files that could be analyzed to learn more about the interaction of players with Madden in their natural habitat. Passing an internship at EA in the fall of 2010, I created a regression model that analyzed the functions that most strongly influenced the retention of users' interest in the game.

The effect of winning ratio on retaining players in Madden NFL 11 based on preferred game mode.
About ten years before my internship at EA, Sony Online Entertainment had already used game analytics, collecting gameplay data using log files stored on servers. These data sets were used for analysis and modeling only a few years later, but, nevertheless, they were among the first examples of game analytics. Researchers such as Dimitri Williams and Nick I published papers based on the analyzed data from the EverQuest franchise.
Local data storage is without a doubt the simplest approach to collecting gameplay data. For example, I wrote a tutorial on using PHP to save data generated by Infinite Mario . But this approach has significant drawbacks. Here is a list of compromises that have to be made with this approach:
pros
- Simplicity: save any data we need in any desired format.
Minuses
- No fault tolerance.
- Data is not stored in the central repository.
- High latency data access.
- Lack of standard tools or ecosystem for analysis.
Regular files are fine if you have only a few servers, but in fact this approach is not an analytics pipeline, if you do not move the files to the central repository. Working in EA, I wrote a script to transfer XML files from dozens of servers to a single server that parsed files and saved game events in the Postgres database. This meant that we could perform an analysis of Madden gameplay, but the data set was incomplete and had significant delays. This system was the forerunner of the next era of gaming analytics.
Another approach that was used in that era was website scraping to collect gameplay data, followed by analysis. During my post-graduate research, I scrapped websites like TeamLiquid and GosuGamers to create a set of replay data for professional StarCraft players. Then I created a predictive model to determine the order of construction . Other examples of analytic projects from that era were scraping websites like WoW Armory . A more modern example is SteamSpy .
Database era

ETL-based analytic architecture components
The convenience of collecting game telemetry in the central repository became apparent around 2010, and many game companies began to store telemetry in databases. Many different approaches were used to transfer event data to a database that analysts could use.
When I worked at Sony Online Entertainment, we had game servers that saved event files to a central file server every couple of minutes. The file server then ran an ETL process about once an hour, which quickly loaded these event files into an analytical database (at the time, it was Vertica). This process had a reasonable delay, about an hour from the moment the game client transmitted the event to the ability to query our analytical database. In addition, it was scaled to large amounts of data, but at the same time the event data had to have a fixed scheme.
Working in Twitch, we used a similar process for one of our analytical databases. The main difference from Sony’s solution was that instead of transferring scp files from game servers to a central repository, we used Amazon Kinesis to stream events from servers to the S3 indexing area. We then used the ETL process to quickly load data into Redshift for analysis. Since then, Twitch has moved on to a “data lake” system (data lake) in order to be able to scale for large amounts of data and provide various options for executing data set queries.
The databases used by Sony and Twitch are extremely valuable for both companies, but when we increase the scale of the stored data, we began to have problems. When we began to collect more detailed information about the gameplay, we could no longer store the full history of events in the tables and we had to cut the data stored for more than a few months. This is normal if you can create summary tables containing the most important details of these events, but this situation is not ideal.
One of the problems with this approach was that the staging server becomes the main point of failure. It is also possible the emergence of "bottlenecks" when one game sends too many events, which leads to the loss of events of all games. Another problem is the speed with which queries are executed as the number of analysts working with the database increases. A team of several analysts working on several months of gameplay data copes with the work, but after years of data collection and an increase in the number of analysts, the speed of query execution can become a serious problem, due to which several queries take several hours to complete.
pros
- All data is stored in one place and access to it is possible through SQL queries.
- There is a good toolkit, for example, Tableau and DataGrip.
Minuses
- Storing all data in a database like Vertica or Redshift is expensive.
- Events must have a permanent scheme.
- May need to truncate tables.
Another problem with using the database as the main interface of the gameplay data is that it is impossible to effectively use machine learning tools, such as MLlib Spark, because you need to unload all relevant data from the database. One way to overcome this limitation is to store gameplay data in a format and storage layer that works well with Big Data tools, for example, save events as Parquet files in S3. This type of configuration became popular in the next era. It eliminated the need to truncate the tables and reduced the cost of storing all the data.
The era of data lakes

Components of Data Lake Analytical Architecture
The most popular data storage pattern during my work as a data analyst in the gaming industry was the data lake pattern. A common pattern is to store semi-structured data in a distributed database and to execute an ETL processor to retrieve the most important data into analytical databases. For a distributed database, you can use many different tools: in Electronic Arts we used Hadoop, in Microsoft Studios - Cosmos, and in Twitch - S3.
This approach allows teams to scale to huge amounts of data, and also provides additional protection against failures. Its main disadvantage is that it increases the complexity and may lead analysts to have access to less data than the traditional approach to databases, due to lack of tools or access policies. Most analysts will interact with the data in this model in the same way, using an analytical database populated from the ETL data lake.
One of the advantages of this approach is that it supports many different event schemes, and it is possible to change the attributes of an event without affecting the analytical database. Another advantage is that analyst teams can use tools such as Spark SQL to work directly with the data lake. However, in most of my workplaces, access to the data lake was limited, which prevented the use of most of the advantages of this model.
pros
- Scalability to huge amounts of data.
- Support for flexible event schemes.
- Costly requests can be transferred to the data lake.
Minuses
- Significant costs at work.
- ETL processes can create significant delays.
- In some lakes there is a lack of complete toolkit.
The main disadvantage of data lakes is that usually a whole team is required to operate the system. It makes sense for large organizations, but for small companies it can be a brute force. One of the ways to use the advantages of data lakes without the cost of costs - the use of remote management services (managed services).
Serverless era
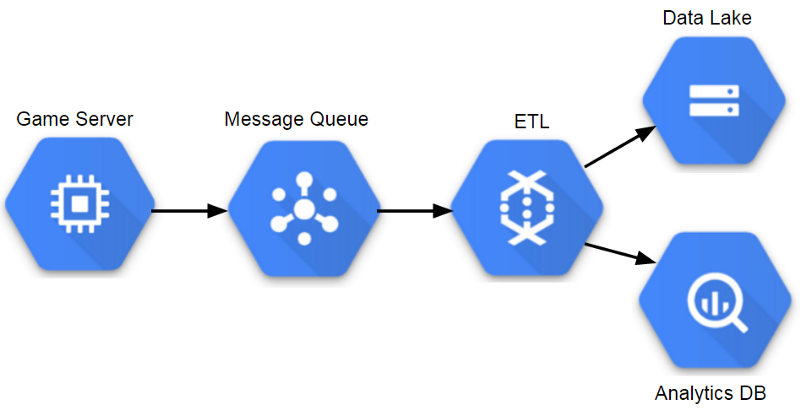
Components of a Managed Analytic Architecture (GCP)
In the current era, a variety of network management services are used on gaming analytics platforms, allowing teams to work with data in near real-time, scale systems if necessary, and reduce server support costs. I did not have to work in this era when I was in the gaming industry, but I saw signs of such a transition. Riot Games uses Spark for ETL and machine learning processes, so it needed the ability to scale the infrastructure on demand. Some game teams use adaptive methods for game services, so it is logical to apply this approach to analytics.
After GDC 2018, I decided to try to build a sample pipeline. In my current job, I used the Google Cloud Platform, and it seems that it has good tools for a managed data lake and query execution environment. The result turned into this tutorial , in which DataFlow is used to build a scalable pipeline.
pros
- Same benefits as using lake data.
- Automatic scaling based on storage and query needs.
- Minimum costs for work.
Minuses
- Remote management services can be expensive.
- Many services are tied to the platform and porting them may not be possible.
In my career, I achieved the greatest success, working with the database era approach, because it gave the analyst team access to all the important data. However, such a scheme cannot continue to scale, and most teams have since switched to environments with data lakes. For a data lake environment to succeed, teams of analysts must have access to the underlying data and have ready tools to support their workflows. If I were building a pipeline today, I would definitely start with serverless approach.
Ben Weber is the leading data analyst at Windfall Data , creating the most accurate and comprehensive model of net worth.
Source: https://habr.com/ru/post/353236/
All Articles