For what programmer Continuous Integration and where to start
Imagine that Roscosmos decided to assemble a new rocket without having at the same time drawings and a clear understanding of how the rocket should be arranged. A separate plant is engaged in a rocket body, a separate one produces engines, another one - nozzles. The chief manager of Roscosmos said that he trusts the professionals and masterfully did all the work for the plants.

A year later, all components are delivered to the main assembly shop, and it turns out that the engine is not included in the body, and the nozzles begin to melt even when the engine starts to test.
')
To prevent such a thing from happening, in real projects there is always a planning and design stage where the specifications of how the parts interact with each other and what characteristics they should have are fixed.
When developing software, we cannot afford the long design phase, since During this time, the business value of what we are trying to develop will be lost - our competitors will stupidly overtake us.
Therefore, teams developing components of the program (modules) are often forced to work not fully understanding how their module will interact with other parts.
As in the case of a rocket, when trying to release a new release of an application developed in parts by several teams, it may turn out that some of the modules are not compatible.
In 1991, Grady Butch , apparently tired of this outrage, and offered to do the assembly of the entire project every day, in order to find out incompatibilities not on the day of release, but earlier - and called this approach Continuous Integration.
Indeed, compiling a program is easier than assembling a rocket (especially from unfinished components), so why not start it once a day? In Extreme Programming, we decided to aggravate this topic and arrange the assembly several times a day.
Well, for example, you need to copy the modules in one place and start compiling the program.
If everything worked out, then the assembly can be considered successful, if not - then the team has a reason to learn more about it, and solve the problem until everything has gone too far.
In interpreted languages like PHP, Python and Ruby there is nothing to compile. In them, the assembly can be the launch of unit tests, deployment of a web application to a test server, and acceptance tests on this test server.
Total, Continuous Integration is a practice. The purpose of the practice is to reduce the number of integration fakap, to improve the quality of the produced software. Method - run the project assembly several times a day.
I admit that Gradi Buch in ancient times began to practice CI generally manually, running around the departments of his company, and forcing everyone to give him floppy disks with the latest versions of modules, and then compile everything manually with the language :)
We in our 2018 are already a bit simpler - the CI process is automated in a heap of systems - choose any one to your taste:

There are a lot of them . They are different. There are specialized under a specific programming language. There are mobile applications developed for development, built into the IDE, configured with the GUI, customized with the configuration file in the repository. Part only works in the cloud, some can be installed on their servers.
We will not attempt to cover them all now. We take only modern general-purpose systems, which are web applications.
Modern development means that you are using the Version Control system.
Version Control is almost always git.
Git is almost always GitHub or a similar service.
Best practice of modern development - featurebranches and pullreves.
CI just fits perfectly into the story with pullrequest.
You not only see all the changes, discuss the development of a specific feature in one place, you immediately show the status of the corresponding CI assembly:

(assembly failed here - you need to go to Details, find out what's broken and repair where)
We repaired, commited, launched, and the process begins with a new one - the CI system detects new changes on the branch and launches a new assembly:

The assembly may consist of several stages. The most typical - tests, compilation, deploy.
Naturally, the CI system needs to explain what these stages are.
All correct CI systems profess the principle of configuration as code, when the instructions for the CI system are just another file in the repository of your project. As it happened, most of the systems use the YAML format for instructions.
The simplest instructions file for GitLab CI might look like this:
Slightly more complex instructions (Circle CI):
And here we remember that all these instructions should be run somewhere.
For each push to the repository, the CI system creates a virtual machine, inside which it runs your instructions, retrieves the results of the work, and extinguishes the machine:

A clean system is needed every time in order to limit the influence of external factors on the assembly.
Some CI systems use docker for this, some get out without it. Hint: take the one with the docker;)
(in reality, everything is somewhat more complicated, and most CI systems can work in a heap of different modes, but it’s better to start with the default mode - just launching tasks inside the docker-container)
Let me give you a couple of situations from practice. It is possible that you have visited some of the following:
Two developers are developing on different branches. Each of them passes the tests successfully, including after Merge with the master.
But as soon as both branches are merged into the master, the tests begin to fall. The problem is that without CI, such a code can easily go into production, and the presence of an error will be clarified only there.
A team of fifteen people develops a web application. Vasily has a family party on his nose. He took time off from the authorities to leave early, not very carefully checking the performance of the code, launched a deployment on the command line, and left work, locked up the computer, and at the same time turned off the phone - the family is more important than work!
As a result, the production is broken, the deployment logs remain on the locked computer, the remaining developers tear their hair out in an attempt to understand what was done, and what went wrong during the deployment process, and who is to blame.
If the team uses the CI system, then all deployment logs (and any other tasks) are stored in it, so you can always see what went wrong.
A good tip gives us GitHab :

An open source project on GitHub most likely drives tests to Travis CI. You cannot face it. Ok, we take note of Travis CI, but we are not running Google yet and reading manuals.
Let's look at the findings of a recent study by The Forrester Wave about Continuous Integration Tools :

In a nutshell, the current capabilities of the CI system, the potential for development, and the current size of the market were explored.
Who is interested in the testing methodology, read the study itself. We are also interested in the conclusions.
The leaders were:
4) CloudBees is the company behind Jenkins . This is one of the oldest open source CI systems, and it would be strange not to see them among the leaders.
3) Circle CI in the second source was in the lead. So, too, deserves attention.
2) Microsoft - no comments. A huge company with great influence. If you are developing software for Windows, then most likely you will not even have a question of choice. If the company purchased licenses for the Microsoft stack of development tools with TFS and their CI system, you just have something to give, not really looking around
1) GitLab comes first. For those who have not followed the company over the past few years, this may be a complete surprise. Let's talk about it in more detail.
The author worked for a year in Gitlab in the position of Developer Advocate, so you have every right to consider me biased and unscrew the skepticism regulator by a couple of tens of percent while reading the following paragraphs. Nevertheless, I believe that many things about Hitlab need to know, and even better - start using it.
It is important that Gitlab refused to consider himself just a clone of Github, and the company decided to develop Gitlab in the direction of a “one-stop-shop” for the developer. Gitlab is already able to replace you Gitkhab, Trello, CI-system, and so on through the list. All tools are already configured and integrated with each other. The result for the developer - at least the mess with the settings.
The source code of Gitlab is open, and, if desired, it can be used for free on its own server. But in this story we are now most interested in the cloud version - GitLab.com and the opportunities it provides:
Freebie, yeah. Well, the opportunity to learn, using for personal projects, as a result.
In short, you guessed it that my personal recommendation is GitLab CI . Gitlab has every chance of becoming the next big thing in the future. And to be an experienced specialist in a suddenly fashionable thing is to be a sought-after specialist;)
If you are not ready to leave Github, try Circle CI or Travis CI .
In the initial stages of exploring CI, avoid Jenkins and TeamCity . There is too much overhead in these old-school systems, so you have to deal more with the features of the systems than fig itself CI.
You start thinking that Jenkins is CI, and that is stupid. A possible exception is whether you are a javist, a rocky or a kotlinist, and for you there everything works right out of the box.
If you have been written to program for Windows, then you’re not going past the Microsoft stack, but I wouldn’t use it because of my free will.
Ok, we go further ...
The good news is that you don't have to become a CI expert right away. For a start, enough and simple “to be in the subject.” So start with something light:
Running your first build inside CI is a two minute task. To run something useful, you have to spend a little more time, because need to set up a working environment for your scripts.
Here we will not go into it. For those interested - links at the end of the article.
In the meantime, let's see how CI is used in large projects, and how much power it can give you.
In large projects - serious requirements. There is already running one or two teams will not manage. It is easy to imagine a logic like this: 1) perform the task only when committing to certain branches, 2) if successful, perform the following tasks, 3) ignore errors when performing certain tasks and 4) wait for the manual go-ahead before you close the whole thing.
My favorite example is GitLab itself:

Work is always there, and you can see how CI works right in real time: https://gitlab.com/gitlab-org/gitlab-ce/pipelines
This is a big project, and I would not recommend looking at its CI config without prior preparation.
Instead, look better at the visualization of the CI task chain:
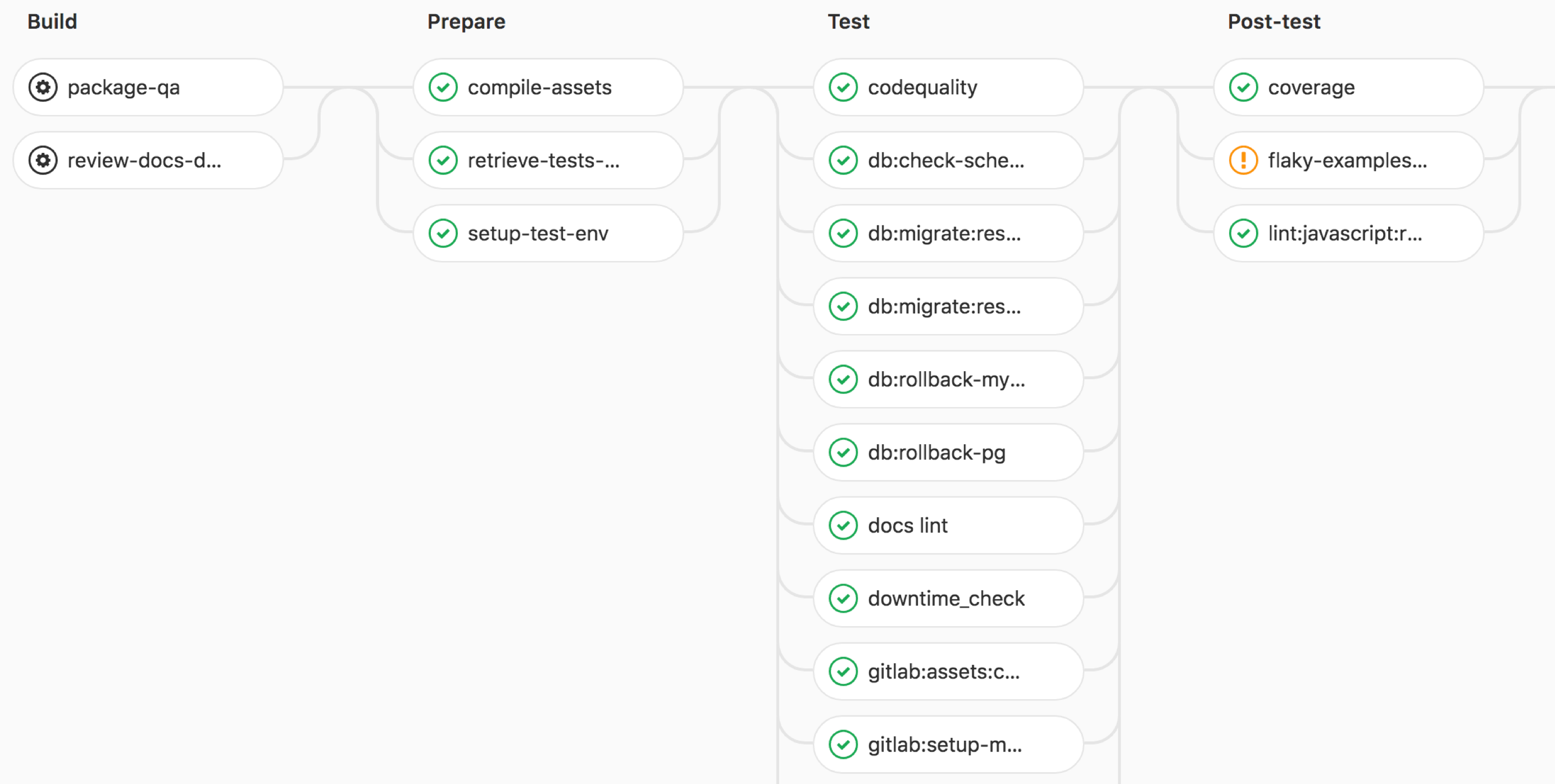
https://gitlab.com/gitlab-org/gitlab-ce/pipelines/20201164
1) This is not in all CI-systems. Where it is, it gives the team a visual representation of what is happening in CI , and I think it’s worth a lot.
2) In addition, the CI system settings file becomes the working documentation of the Continuous Integration process in the command. Any developer can add or change something there by creating a pullrequest with the desired changes.
3) Finally, the CI-system becomes the central place where you can see where and when what went wrong during a complete or test run.
Well, add to taste all these traditional blah blah blah about speeding up the development process, improving reliability, and reducing risk.
(if you wanted to learn more deeply)
1) Look at the screencast with examples of how to break the warm on S3 and on Heroku using GitLab CI.
2) Read the introduction to GitLab CI and the Deploy Guide .
3) Smoke documentation .
4) Once you are comfortable with one CI system, select and play with any other one from the list of promising ones to make sure that the principle is common everywhere and to gain even more confidence in your abilities.
A year later, all components are delivered to the main assembly shop, and it turns out that the engine is not included in the body, and the nozzles begin to melt even when the engine starts to test.
')
To prevent such a thing from happening, in real projects there is always a planning and design stage where the specifications of how the parts interact with each other and what characteristics they should have are fixed.
When developing software, we cannot afford the long design phase, since During this time, the business value of what we are trying to develop will be lost - our competitors will stupidly overtake us.
Therefore, teams developing components of the program (modules) are often forced to work not fully understanding how their module will interact with other parts.
As in the case of a rocket, when trying to release a new release of an application developed in parts by several teams, it may turn out that some of the modules are not compatible.
In 1991, Grady Butch , apparently tired of this outrage, and offered to do the assembly of the entire project every day, in order to find out incompatibilities not on the day of release, but earlier - and called this approach Continuous Integration.
Indeed, compiling a program is easier than assembling a rocket (especially from unfinished components), so why not start it once a day? In Extreme Programming, we decided to aggravate this topic and arrange the assembly several times a day.
What is an assembly?
Well, for example, you need to copy the modules in one place and start compiling the program.
If everything worked out, then the assembly can be considered successful, if not - then the team has a reason to learn more about it, and solve the problem until everything has gone too far.
In interpreted languages like PHP, Python and Ruby there is nothing to compile. In them, the assembly can be the launch of unit tests, deployment of a web application to a test server, and acceptance tests on this test server.
Total, Continuous Integration is a practice. The purpose of the practice is to reduce the number of integration fakap, to improve the quality of the produced software. Method - run the project assembly several times a day.
I admit that Gradi Buch in ancient times began to practice CI generally manually, running around the departments of his company, and forcing everyone to give him floppy disks with the latest versions of modules, and then compile everything manually with the language :)
We in our 2018 are already a bit simpler - the CI process is automated in a heap of systems - choose any one to your taste:
About CI systems
There are a lot of them . They are different. There are specialized under a specific programming language. There are mobile applications developed for development, built into the IDE, configured with the GUI, customized with the configuration file in the repository. Part only works in the cloud, some can be installed on their servers.
We will not attempt to cover them all now. We take only modern general-purpose systems, which are web applications.
Modern development means that you are using the Version Control system.
Version Control is almost always git.
Git is almost always GitHub or a similar service.
Best practice of modern development - featurebranches and pullreves.
CI just fits perfectly into the story with pullrequest.
You not only see all the changes, discuss the development of a specific feature in one place, you immediately show the status of the corresponding CI assembly:
(assembly failed here - you need to go to Details, find out what's broken and repair where)
We repaired, commited, launched, and the process begins with a new one - the CI system detects new changes on the branch and launches a new assembly:
The assembly may consist of several stages. The most typical - tests, compilation, deploy.
Naturally, the CI system needs to explain what these stages are.
Configuring CI-systems
All correct CI systems profess the principle of configuration as code, when the instructions for the CI system are just another file in the repository of your project. As it happened, most of the systems use the YAML format for instructions.
The simplest instructions file for GitLab CI might look like this:
test_job: script: - ls -l Slightly more complex instructions (Circle CI):
version: 2 jobs: test: docker: - image: circleci/ruby:2.4-node steps: - checkout - run: rspec deploy: docker: - image: circleci/ruby:2.4-node steps: - checkout - run: cap deploy And here we remember that all these instructions should be run somewhere.
What is the CI-systems under the hood
For each push to the repository, the CI system creates a virtual machine, inside which it runs your instructions, retrieves the results of the work, and extinguishes the machine:
A clean system is needed every time in order to limit the influence of external factors on the assembly.
Some CI systems use docker for this, some get out without it. Hint: take the one with the docker;)
(in reality, everything is somewhat more complicated, and most CI systems can work in a heap of different modes, but it’s better to start with the default mode - just launching tasks inside the docker-container)
Why is this all a normal developer?
- The more aspects of the development you are able to close, the greater your value. If you just wrote the code, started, and then at least the grass does not grow - this is one thing. If at the same time you took care of the tests and the deployment of the application - is quite another. If you automated all this in CI - the third :)
- Just understand that in time CI will be the same default thing as Version Control.
Let me give you a couple of situations from practice. It is possible that you have visited some of the following:
Situation # 1
Two developers are developing on different branches. Each of them passes the tests successfully, including after Merge with the master.
But as soon as both branches are merged into the master, the tests begin to fall. The problem is that without CI, such a code can easily go into production, and the presence of an error will be clarified only there.
Siucation number 2
A team of fifteen people develops a web application. Vasily has a family party on his nose. He took time off from the authorities to leave early, not very carefully checking the performance of the code, launched a deployment on the command line, and left work, locked up the computer, and at the same time turned off the phone - the family is more important than work!
As a result, the production is broken, the deployment logs remain on the locked computer, the remaining developers tear their hair out in an attempt to understand what was done, and what went wrong during the deployment process, and who is to blame.
If the team uses the CI system, then all deployment logs (and any other tasks) are stored in it, so you can always see what went wrong.
Which CI system to start
A good tip gives us GitHab :
An open source project on GitHub most likely drives tests to Travis CI. You cannot face it. Ok, we take note of Travis CI, but we are not running Google yet and reading manuals.
Let's look at the findings of a recent study by The Forrester Wave about Continuous Integration Tools :
In a nutshell, the current capabilities of the CI system, the potential for development, and the current size of the market were explored.
Who is interested in the testing methodology, read the study itself. We are also interested in the conclusions.
The leaders were:
4) CloudBees is the company behind Jenkins . This is one of the oldest open source CI systems, and it would be strange not to see them among the leaders.
3) Circle CI in the second source was in the lead. So, too, deserves attention.
2) Microsoft - no comments. A huge company with great influence. If you are developing software for Windows, then most likely you will not even have a question of choice. If the company purchased licenses for the Microsoft stack of development tools with TFS and their CI system, you just have something to give, not really looking around
1) GitLab comes first. For those who have not followed the company over the past few years, this may be a complete surprise. Let's talk about it in more detail.
Gitlab
The author worked for a year in Gitlab in the position of Developer Advocate, so you have every right to consider me biased and unscrew the skepticism regulator by a couple of tens of percent while reading the following paragraphs. Nevertheless, I believe that many things about Hitlab need to know, and even better - start using it.
It is important that Gitlab refused to consider himself just a clone of Github, and the company decided to develop Gitlab in the direction of a “one-stop-shop” for the developer. Gitlab is already able to replace you Gitkhab, Trello, CI-system, and so on through the list. All tools are already configured and integrated with each other. The result for the developer - at least the mess with the settings.
The source code of Gitlab is open, and, if desired, it can be used for free on its own server. But in this story we are now most interested in the cloud version - GitLab.com and the opportunities it provides:
- Hosting unlimited private projects
- 2000 build-minutes per month to work with built-in CI for free
Freebie, yeah. Well, the opportunity to learn, using for personal projects, as a result.
In short, you guessed it that my personal recommendation is GitLab CI . Gitlab has every chance of becoming the next big thing in the future. And to be an experienced specialist in a suddenly fashionable thing is to be a sought-after specialist;)
If you are not ready to leave Github, try Circle CI or Travis CI .
In the initial stages of exploring CI, avoid Jenkins and TeamCity . There is too much overhead in these old-school systems, so you have to deal more with the features of the systems than fig itself CI.
You start thinking that Jenkins is CI, and that is stupid. A possible exception is whether you are a javist, a rocky or a kotlinist, and for you there everything works right out of the box.
If you have been written to program for Windows, then you’re not going past the Microsoft stack, but I wouldn’t use it because of my free will.
Ok, we go further ...
What tasks to start
The good news is that you don't have to become a CI expert right away. For a start, enough and simple “to be in the subject.” So start with something light:
- For example, learn how to deploy a personal site when pushing to the master.
- Spit up a spell check with yaspeller for texts on a personal site
- Launch a pair of linters in the CI of the minor working project.
Running your first build inside CI is a two minute task. To run something useful, you have to spend a little more time, because need to set up a working environment for your scripts.
Here we will not go into it. For those interested - links at the end of the article.
In the meantime, let's see how CI is used in large projects, and how much power it can give you.
What gives CI in large projects
In large projects - serious requirements. There is already running one or two teams will not manage. It is easy to imagine a logic like this: 1) perform the task only when committing to certain branches, 2) if successful, perform the following tasks, 3) ignore errors when performing certain tasks and 4) wait for the manual go-ahead before you close the whole thing.
My favorite example is GitLab itself:
Work is always there, and you can see how CI works right in real time: https://gitlab.com/gitlab-org/gitlab-ce/pipelines
This is a big project, and I would not recommend looking at its CI config without prior preparation.
Instead, look better at the visualization of the CI task chain:
https://gitlab.com/gitlab-org/gitlab-ce/pipelines/20201164
1) This is not in all CI-systems. Where it is, it gives the team a visual representation of what is happening in CI , and I think it’s worth a lot.
2) In addition, the CI system settings file becomes the working documentation of the Continuous Integration process in the command. Any developer can add or change something there by creating a pullrequest with the desired changes.
3) Finally, the CI-system becomes the central place where you can see where and when what went wrong during a complete or test run.
Well, add to taste all these traditional blah blah blah about speeding up the development process, improving reliability, and reducing risk.
Where to dig further
(if you wanted to learn more deeply)
1) Look at the screencast with examples of how to break the warm on S3 and on Heroku using GitLab CI.
2) Read the introduction to GitLab CI and the Deploy Guide .
3) Smoke documentation .
4) Once you are comfortable with one CI system, select and play with any other one from the list of promising ones to make sure that the principle is common everywhere and to gain even more confidence in your abilities.
Source: https://habr.com/ru/post/353194/
All Articles