An alternative look at the problem from Odnoklassniki with JPoint 2018
Hello!
Recently, it has become fashionable to do exposures for tasks . In the post I decided to give my thoughts on the problems of Odnoklassniki . I liked the tasks, but it was painfully ambiguous, and I couldn’t find a place in the allotted space on a piece of paper . Discuss?
Attention! In the original article, you can get acquainted with the full condition of the tasks and solve them yourself.
')
Code snippet is borrowed from authoring.
From the task condition, it remains unclear whether the
Case one: the
In this case, what is the fault in this code? The first thing that catches your eye is that the partitioning algorithm is strictly related to the number of servers. This problem is faced by users of various distributed repositories in terms of the number of shards. For example, this problem is relevant for Elasticsearch. The MongoDB documentation also reminds us of this .
Choosing the number of shards and the algorithm for calculating the shard key is a crucial task. In the examples with Elasticsearch and MongoDB, changing the number of shards is a conscious desire. But if the shard server, regardless of our will, decided to rest, then replication will come to our rescue. The following is the Replica Set organization for MongoDB:
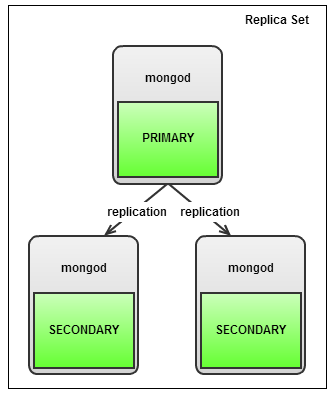
Picture taken from severalnines.com .
Case two: the
Instability
Special case: the
For example, in Intellij IDEA, you can generate
and get this implementation:
So what's the problem, you ask? It’s too early to draw conclusions, we’ll continue to study the source code (JDK 8):
Great, we made sure that the result is reproducible between application restarts. The problem is that we rely on implementation details . There are no guarantees that the behavior will remain unchanged in future versions of Java. Even despite the uniqueness of javadocs that we trust, because they relate only to the current implementation.
Addition. Throwing on
I have to say that I am not a very big fan of
Let me remind you that there are two uses:
If
Let's start with a simple example:
Suddenly,
First, the use of a short recording gives us a little more information than nothing — you can't figure it out without a griddle.
Secondly, let's turn to javadoc to
For example, there are no available shards - quite a full-time (processed) situation. Should the
In both cases, it is more appropriate to use an
The task is a vivid example of the benefits of applying tests. At the same time, it is a good demonstration of how unstable tests appear.
On the use of
Thanks to the authors for the warm-up for the brain.
Recently, it has become fashionable to do exposures for tasks . In the post I decided to give my thoughts on the problems of Odnoklassniki . I liked the tasks, but it was painfully ambiguous, and I couldn’t find a place in the allotted space on a piece of paper . Discuss?
Attention! In the original article, you can get acquainted with the full condition of the tasks and solve them yourself.
')
Code snippet is borrowed from authoring.
1. Vadim and Music Partitioning
/** * @return partition between 0 inclusive * and partitions exclusive */ int partition(Track track, int partitions) { assert track != null; assert partitions > 0; return track.hashCode() % partitions; } What is wrong with the Track objects partitioning algorithm by servers?
hashCode ()
From the task condition, it remains unclear whether the
hashCode() method is redefined in the Track class or the implementation from the Object class is used.Case one: the
hashCode() method is redefined. Javadoc looks quite convincing, but we are used to trusting javadocs, right? ;) So, Vadim had to take care of the negative values of hashCode (or someone had Flaky tests ).In this case, what is the fault in this code? The first thing that catches your eye is that the partitioning algorithm is strictly related to the number of servers. This problem is faced by users of various distributed repositories in terms of the number of shards. For example, this problem is relevant for Elasticsearch. The MongoDB documentation also reminds us of this .
Choosing the number of shards and the algorithm for calculating the shard key is a crucial task. In the examples with Elasticsearch and MongoDB, changing the number of shards is a conscious desire. But if the shard server, regardless of our will, decided to rest, then replication will come to our rescue. The following is the Replica Set organization for MongoDB:
Picture taken from severalnines.com .
Case two: the
Object.hashCode() method is used. The best way to say this is javadoc to this method (a key fragment is highlighted):Whenever it is invokedThe latter means that the
an execution of a Java application, thehashCodemethod
must consistently return the same integer, provided no information
used inequalscomparisons.
This integer need not remain consistent
application to another execution of the same application.
hashCode value of the same object after restarting the application is likely to be different. The object is the same in the context of business logic (for example, obtained from the database). But this is still half the trouble: as a result, on different servers at one point in time, hashes will probably also be different.Instability
hashCode and the likelihood of negative values can cause Flaky tests . Roughly speaking, these are tests that on one codebase for unknown reasons become red, and at the time of their study (or by themselves) suddenly turn green again.Special case: the
hashCode() method relies on the hashCode business data (primitives and strings). This case is the most common and no less interesting!For example, in Intellij IDEA, you can generate
hashCode() and equals() methods for a simple data class: public class Address { private final String street; private final Integer house; } and get this implementation:
@Override public int hashCode() { int result = street != null ? street.hashCode() : 0; result = 31 * result + (house != null ? house.hashCode() : 0); return result; } So what's the problem, you ask? It’s too early to draw conclusions, we’ll continue to study the source code (JDK 8):
public final class String { /** * Returns a hash code for this string. The hash code for a * {@code String} object is computed as * <blockquote><pre> * s[0]*31^(n-1) + s[1]*31^(n-2) + ... + s[n-1] * </pre></blockquote> * using {@code int} arithmetic, where {@code s[i]} is the * <i>i</i>th character of the string, {@code n} is the length of * the string, and {@code ^} indicates exponentiation. * (The hash value of the empty string is zero.) * * @return a hash code value for this object. */ @Override public int hashCode() { int h = hash; if (h == 0 && value.length > 0) { char val[] = value; for (int i = 0; i < value.length; i++) { h = 31 * h + val[i]; } hash = h; } return h; } } public final class Integer { /** * Returns a hash code for this {@code Integer}. * * @return a hash code value for this object, equal to the * primitive {@code int} value represented by this * {@code Integer} object. */ @Override public int hashCode() { return Integer.hashCode(value); } /** * Returns a hash code for a {@code int} value; compatible with * {@code Integer.hashCode()}. * * @param value the value to hash * @since 1.8 * * @return a hash code value for a {@code int} value. */ public static int hashCode(int value) { return value; } } Great, we made sure that the result is reproducible between application restarts. The problem is that we rely on implementation details . There are no guarantees that the behavior will remain unchanged in future versions of Java. Even despite the uniqueness of javadocs that we trust, because they relate only to the current implementation.
Addition. Throwing on
String.hashCode() holds to a lesser extent. As was rightly noted in the comments, changing the algorithm will make a ton of compiled code invalid, which will cause resentment of the entire Java community.Example
Such source code:
compiles to:
As you can see, hash constants are stitched in the compiled code.
switch(s) { case "s": System.out.println("S"); break; case "b": System.out.println("B"); break; } compiles to:
int var_ = -1; switch(s.hashCode()) { case 98: if(s.equals("b")) { var_ = 1; } break; case 115: if(s.equals("s")) { var_ = 0; } } switch(var_) { case 0: System.out.println("S"); break; case 1: System.out.println("B"); } As you can see, hash constants are stitched in the compiled code.
assert
I have to say that I am not a very big fan of
assert . This is about using the assert statement ( JLS 14.10 ).Let me remind you that there are two uses:
assert condition [: msg];If
condition == false , an AssertionError error will be thrown. In this case, if the expression msg not specified, then we get an error without a detail message , which, in my opinion, is unacceptable . In the second case, the AssetionError(String detailMessage) constructor will be called.Let's start with a simple example:
public class Main { public static void main(String[] args) { assert args.length != 0; assert args.length == 0; System.out.println("OMG! Is it possible?"); } } Suddenly,
OMG! Is it possible? will be displayed on the console OMG! Is it possible? OMG! Is it possible? because assert not enabled by default:java -ea | -enableassertions Main java -ea | -enableassertions Main .Why I do not use assert
First, the use of a short recording gives us a little more information than nothing — you can't figure it out without a griddle.
Secondly, let's turn to javadoc to
Error : /** * An {@code Error} is a subclass of {@code Throwable} * that indicates serious problems that a reasonable application * should not try to catch. Most such errors are abnormal conditions. * The {@code ThreadDeath} error, though a "normal" condition, * is also a subclass of {@code Error} because most applications * should not try to catch it. * <p> * A method is not required to declare in its {@code throws} * clause any subclasses of {@code Error} that might be thrown * during the execution of the method but not caught, since these * errors are abnormal conditions that should never occur. * * That is, {@code Error} and its subclasses are regarded as unchecked * exceptions for the purposes of compile-time checking of exceptions. * * @author Frank Yellin * @see java.lang.ThreadDeath * @jls 11.2 Compile-Time Checking of Exceptions * @since JDK1.0 */ public class Error extends Throwable { /* code omitted */ } Error indicates there is no problem to try to catch. Most such errors are abnormal conditions.Error should not be used by the user code as business exceptions , and their appearance should indicate a bug. In the code from the partitions == 0 task, it looks more like a business check than a code error.For example, there are no available shards - quite a full-time (processed) situation. Should the
partition() method be responsible for handling this case? Rather, no, but that is another question.In both cases, it is more appropriate to use an
IllegalArgumentException .Conclusion
The task is a vivid example of the benefits of applying tests. At the same time, it is a good demonstration of how unstable tests appear.
On the use of
assert adhere to the position that it is not necessary to transfer the tests in fact to the production code.Thanks to the authors for the warm-up for the brain.
Source: https://habr.com/ru/post/353034/
All Articles