Unit testing interfaces in Headless Chrome. Yandex lecture
To continuously improve large client interfaces, you need a powerful system of autotests. Yandex developer Dmitry Andriyanov dima117 knows something about it - a couple of months ago, he shared his experience on J. Subbotnik in Nizhny Novgorod.
- Today I will tell you how we, in Direkt, write unit tests on the web interface. We will generally see how the interface tests differ from other tests. Consider two approaches to writing tests: using Selenium and using Headless browsers. And at the end I will show the tool that we wrote in Directive for running tests in Headless Chrome.
This is Direct - such an admin for advertisements.
')
And this is the second largest project in Yandex after Search. For example, we have 16 people in the front-end team. All my previous jobs had a maximum of four. Why are there so many people? You just entered the ad, the key phrases - what are all these people doing there?
Direct is a very complex subject area. This is a typical ad for the sale of elephants. I highlighted one small block in red with additional links.

In the Yandex interface, the form with the block settings looks like this:
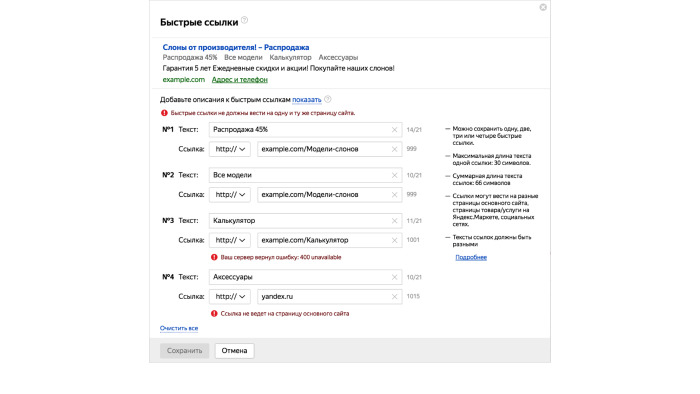
There are ad previews, several fields for each link, and they are also hung with complex validation, to the extent that a special piece on the server taps the link that you entered and checks that it opens at all. There is a lot of other logic there, and this form is just for one small block, and there are many blocks in the declaration.
And it was only one type of ad - a text ad. There are many other types. In addition, we are now talking only about the display settings. There are still many other settings that determine when and to whom this ad should show.
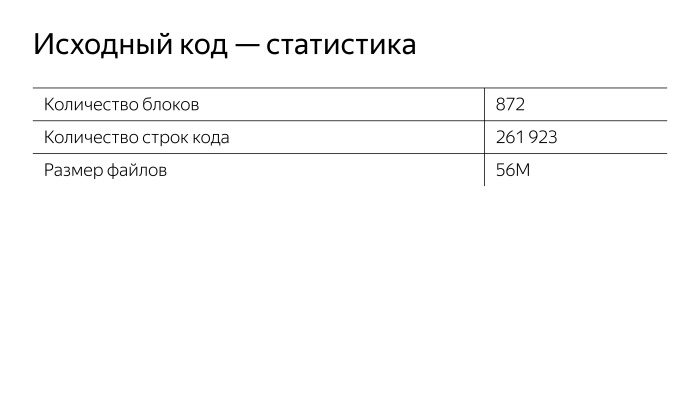
In general, this picture is obtained.

The ads that you see on the site or in the search have a lot of settings and a very complex interface with which they are created. To implement this complex interface, a lot of code has been written. We use BEM-stack in Direct. The project is divided into blocks, and these blocks in the project are about 800. If you write on React, imagine a project with 800 React components. This is a very big project! I tried to measure the list of files in Web Storm, I got a height of 20 screens. You see, this is a lot of code.
The project is constantly changing, these 16 developers make dozens of commits daily there, constantly adding new features. And we need to somehow check that when you add a new feature to the project, it does not break anything. If the project were small, it could have been done with the help of manual testers: they added a feature - they tested it and made it into production. And since our project is very large, we cannot afford to retest it every time.
We write autotests for everything. There are about 7,000 unit tests in the project, we run them on every commit, and they make sure that nothing is broken.
When you have a very large project, auto tests are not just a nice addition, which sometimes helps to find errors. This is a necessary working tool, without which you can not work. You will drown in the number of bugs that appear in the code.
This is an example of tests when you are testing some kind of logic, some kind of class or function.

First, you do some preparatory actions, then an action that needs to be checked, and at the end you compare the result of this action with the expected one. If not as expected, then the test has dropped.
How to write tests on the interface, on all sorts of buttons? Similar!

We first render something on the page, then do the action that needs to be checked, for example, enter a value and click on the button, and at the end check that, for example, a request was sent to the server with the correct parameters or in the right place on the form An error message was displayed. The sequence of actions is the same as when writing ordinary logic tests.
What is the problem with this scheme? These tests all need a browser. This is a program with a graphical interface, where the user enters something from the keyboard, clicks on the buttons, and the result of any browser is the pixels drawn on the screen. We have autotests, we want to run them automatically, without human intervention. For tests on the interface, we need a browser, and this is not suitable for us.
What can be done? There are two ways to solve this problem. The first is to use some kind of browser control tool. Selenium is such a thing that does the same actions as the user in the browser, but you can control these actions programmatically, it will do them automatically. The second way is to use Headless browsers. Very popular - PhantomJS. He died, but still very popular.
When you use Selenium or another similar browser management tool, the scheme will be something like this.
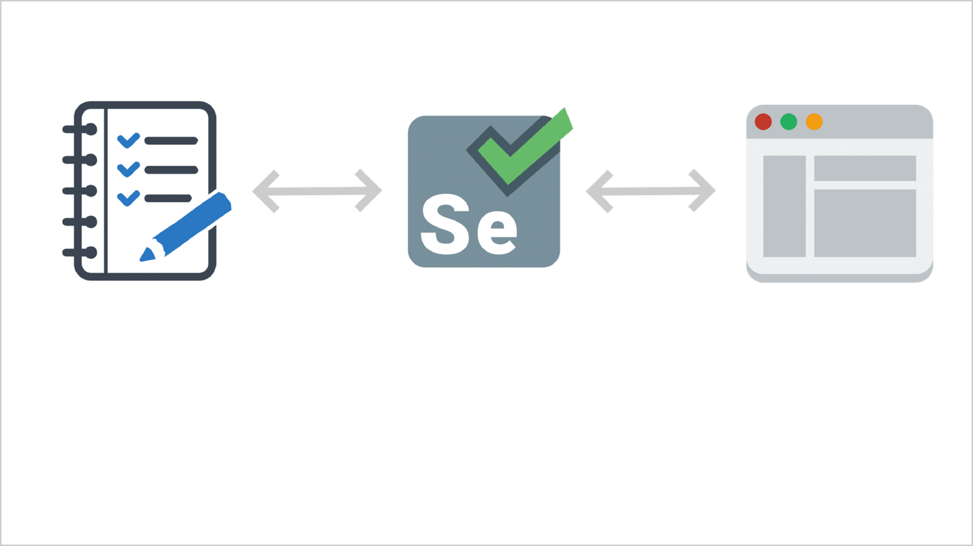
This notebook with checkmarks is a test run, it is similar to the code that you saw on the screen, and it gives commands to a special piece called the “Selenium web driver”. This is a software library that provides an API to control the browser. There are commands “open the page”, “click on the button”, “enter text in the input field” and so on.
Selenium web driver starts somewhere, on this machine or on a remote, real browser, a window will be drawn there, and the actions that need to be performed in the test will be automatically executed in it. In this case, the browser will be unavailable to the user. There will be a message that the browser is controlled by automated software and nothing can be done in this window. This approach is similar to the usual test by the tester, only the commands are given not by the person, but by your test. The test code here will look something like this.

There is a variable browser. In different frameworks, it may be called differently, but the essence is the same: you have an object with which you access the Selenium API of the web driver. Preparing, verifiable actions, verification - there are all the same actions that were on the slide about testing functions / classes. You just tell the browser what to do.
What are the benefits of this approach? First, the Selenium web driver provides the same way to control different browsers. For example, you use it to test in Firefox and Chrome. Then you were told to run tests in IE or in mobile Safari. You add IE8 in the settings, and the tests start running in IE. You do not need to edit the test code. The uniformity of browser management is a big plus.
The second plus is scalability. In the scheme I showed, the third component is the browser. It can be located not only on the computer where the tests are running, but also on the other. And what's more, you can add more computers with browsers to this scheme, and at once drive a lot of tests into them in parallel. This is very useful when you have hundreds or thousands of tests, and on the same computer they, for example, run for an hour and a half, and you added 10 computers or launched in the cloud, and they take you 10 minutes to complete. This is a very good way to speed up your tests, and you can do it very easily. This scheme scales very well.
This approach works well, it is actively used in the search, because they have a large audience with different browsers.
How to run tests using Selenium?
The guys from the Search wrote a special tool - "Hermione" . This is not just a test run, there are many possibilities. But first of all, it is a tool that runs tests in Selenium in a heap of browsers.

On the slide - npm packages. Nightwatch knows about the same thing as Hermione, their possibilities are slightly different, you can watch these two things and choose what you like.
Testing in Selenium is a good approach, it works, many people use it. But he has one significant limitation.
You cannot write unit tests. Only integration. What is the difference between unit tests and integration tests?
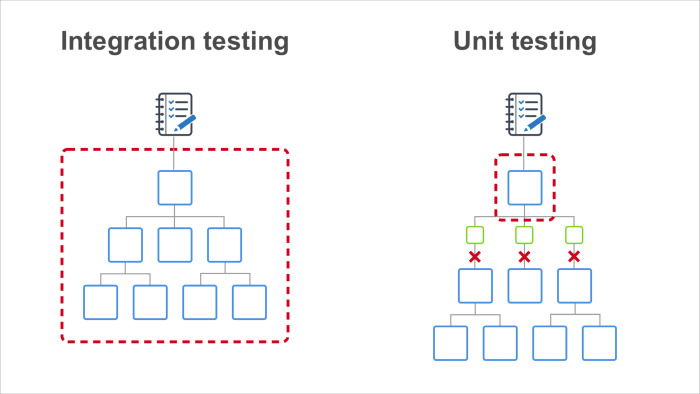
Integration tests check everything in the collection. Your interface element under test can use other interface elements inside, for example, you are testing a form, it uses buttons, input fields, nested forms. And it can have external APIs in dependencies, for example, it can download something from the network, download from some storage, system time is also an external dependency. Integration tests are testing everything in a heap, they say: to render the forms on the page with all the pieces, to do some actions there.
Unit tests test an element in isolation from its dependencies. They put a stub on each arrow on the diagram, and the dependency code is not executed during the test. Instead, the small stub code is executed. He slips the data to be checked for the test block.
Each approach solves its problem. We in the Directive are exactly the unit tests. Because we have very complex blocks with very complex logic and it is very difficult to check them with integration tests. They need to submit a large sheet of data at the entrance, prepare the data for all the dependencies of the block. If something breaks inside, it's hard to understand where it broke. And integration tests are slow.
We have integration tests, but there are many places where you need to write unit tests, test a separate unit, without this tail.
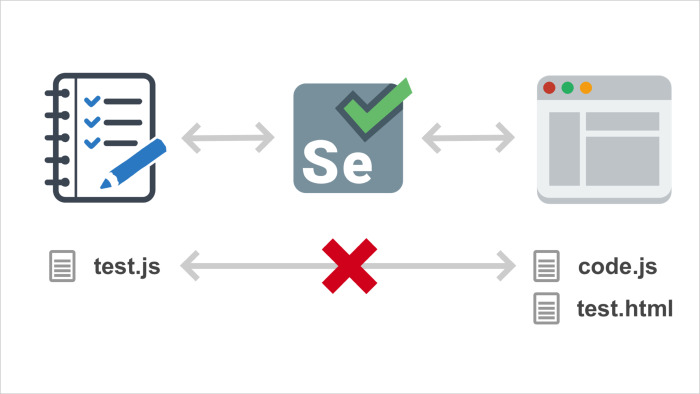
What happens in Selenium? At the bottom of the file with the code that runs in the scheme. On the left, where the test runs, the code of our tests is executed, and on the right, where the browser is, the test page code and the code we are testing are executed. Between them is a layer in the form of Selenium, and the test code does not have direct access to the code that it is testing. The test code cannot put all stubs in order to isolate the test code from dependencies. It can interact only with the Selenium API, click something. He can perform some kind of JS, but still he does not have direct access. Because of this, you cannot write unit tests.
Alternatively, it would be possible to transfer this test code to the browser side and report the data on how the tests go to the test run, so that it displays its checkmarks and crosses. But with Selenium we cannot do this, because this API is one way. You can ask the browser for something from the test, but you cannot send something from the browser to the program that controls it.
Conclusion: we need modular tests in Direkt, but we cannot use the approach from Selenium for unit tests, only for integration tests.
Let's take a look at the second approach - testing in Headless browsers.
Headless browsers are the same as regular browsers, but during their work they do not display anything on the screen. You can launch the Headless browser as a console application. There the page will be opened inside, all CSS, JS will be executed, but you will not see anything on the screen.
In this case, you can control the browser only through some API, it does not have any user interface. This is similar to Selenium and the browser in one bottle, but the API is implemented inside the browser itself, it is not a separate external component.
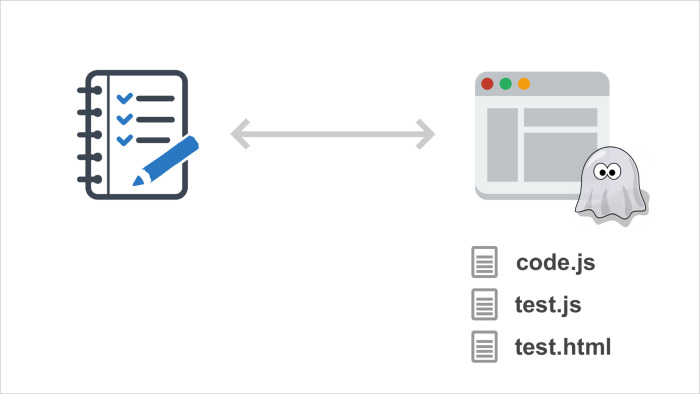
It turns out, the API has access to the internals of the browser. Headless browsers APIs provide, as a rule, a much larger set of features than Selenium. In particular, there you can listen to browser events like page load, page error, you can intercept requests to the network, intercept output to the console and much more. These things make it possible for the variant I was talking about: transfer the test code to the browser side so that it sends information about how the tests go to the test runner. This approach is also very popular, many need unit tests. We have been using it for about three years.
Until recently, the only browser that worked fine was PhantomJS.
It had drawbacks - memory is flowing and it is difficult to join the debugger in order to debug tests - but in principle, this is a normal working browser. He has a webkit inside, it all works, we used it for two years.

This is a screenshot from Google Groups, there the last PhantomJS developer Vitaly Slobodin says something like this: “soon there will be Headless Chrome, it works better, it does not eat memory like crazy, so I will not develop PhantomJS, switch to Chrome”. We also began to look at Chrome and switched to it.
This is the tool logo called Puppeteer - for managing Chrome in Headless mode. Puppeteer (translated as "puppeteer") is developed by the Chrome Dev Tools team, there is some confidence that they will not abandon his support. This is the NodeJS package, it has the JS API, and the coolest is that it puts Chrome along with it as a dependency. You do not need to separately install the browser in order to run something in it. You wrote npm install - and it all worked right away.
We looked in his direction, tried it, we liked it. The only problem was that there were no tools to cross our tests and Headless Chrome. For PhantomJS such tools were, since it has existed for a long time, and Headless Chrome only appeared, there were no tools.
We wrote our mocha-headless-chrome tool.

We have less fantasy than in the Search: their tool is called “Hermione”, and ours is “mocha-headless-chrome”. We use it for half a year, it works. For example, a small project will show how this happens. (A demo from the report is here - ed.)
In the test project, one file is test-form.js. It is easy to guess that this is a search form, there is an input and a button. The SearchForm class, it has a render method, almost like in React, and it adds a form, an input and a button to the page. In addition, he subscribes to a click on the button, and when you click on the button, he makes an Ajax request, sends the contents of the form to example.com, and then he cleans the form.
Let's write for this simple test. The folder tests, in it file test.js. While there are no tests here, just describe and the action that needs to be performed before each test and after.
Before each test we add our form to the page, and after each test we delete it.
Also, before each test we make a stub for Ajax requests, so that the test can check which requests are made. And after each test, we reset this stub - remove it.
We wrote a file of our tests, JS, there are no tests there yet, we will write soon.
But first, let's make a test page that will open in the browser.
In the tests folder, I make a file test.html. There is nothing complicated here, we are connecting three libraries, Mocha is a test framework, I think everyone is familiar with it. Sinon is a library that allows you to automatically create all sorts of stubs to isolate our block from its dependencies. And the chai library with all kinds of assertions, it gives an API for various checks in tests.
We connected these three libraries, further connected the code of our form, the search-form, and connected our test file we just created. In the end, they called the mocha-run command to start the tests.
Run the page in the browser and make sure that everything is ok. The page has opened, there are zero tests in it, which is expected. Let's write a couple of tests. The test checks that when we clicked the button, an Ajax request to the correct address was sent to the server. This is the searchForm we created at the beginning. The test fills the form with data, then clicks on the button, then with the help of a stub in the server variable it checks that the last request made had the desired url.
Let's see the page in the browser, it has been updated, and we see that one test has passed. The browser has code that makes an Ajax request. We put a stub on it so that it did not make this request during the test, and checked that the request was made with the correct parameters.
Let's run it all in Headless Chrome.
npm install mocha-headless-chrome
I add the test command to package.json so that I do not write every time. When you install the mocha-headless-chrome package, it adds a utility with the same name. It needs to pass the parameter -f - the path to our test page, which we opened in the browser.
Now, if I run the npm test now, everything should work.
We set the dependency, it downloaded Chrome itself, put it locally in the node_modules folder. Then we just call it by name as a console application and pass a test page via the f parameter. The test passed, this is our test that we wrote.
Let's try to add another test that verifies that after sending an Ajax request, we cleared the value in the search form.
In the browser, check that it appeared. Next, run it in the terminal. We had two tests, and when they were executed, you did not see any browser window. The person who starts it, did nothing with his hands, everything goes completely automatically.
We use this tool for about six months. 7000 tests that previously worked in PhantomJS, without any problems began to work in Headless Chrome. Test execution accelerated by 30%. This thing is available in external npm, you can also take it and use it. There are already 5000 downloads per month, that is, there are people outside of Yandex who use it.
- Today I will tell you how we, in Direkt, write unit tests on the web interface. We will generally see how the interface tests differ from other tests. Consider two approaches to writing tests: using Selenium and using Headless browsers. And at the end I will show the tool that we wrote in Directive for running tests in Headless Chrome.
This is Direct - such an admin for advertisements.
')
And this is the second largest project in Yandex after Search. For example, we have 16 people in the front-end team. All my previous jobs had a maximum of four. Why are there so many people? You just entered the ad, the key phrases - what are all these people doing there?
Direct is a very complex subject area. This is a typical ad for the sale of elephants. I highlighted one small block in red with additional links.
In the Yandex interface, the form with the block settings looks like this:
There are ad previews, several fields for each link, and they are also hung with complex validation, to the extent that a special piece on the server taps the link that you entered and checks that it opens at all. There is a lot of other logic there, and this form is just for one small block, and there are many blocks in the declaration.
And it was only one type of ad - a text ad. There are many other types. In addition, we are now talking only about the display settings. There are still many other settings that determine when and to whom this ad should show.
In general, this picture is obtained.
The ads that you see on the site or in the search have a lot of settings and a very complex interface with which they are created. To implement this complex interface, a lot of code has been written. We use BEM-stack in Direct. The project is divided into blocks, and these blocks in the project are about 800. If you write on React, imagine a project with 800 React components. This is a very big project! I tried to measure the list of files in Web Storm, I got a height of 20 screens. You see, this is a lot of code.
The project is constantly changing, these 16 developers make dozens of commits daily there, constantly adding new features. And we need to somehow check that when you add a new feature to the project, it does not break anything. If the project were small, it could have been done with the help of manual testers: they added a feature - they tested it and made it into production. And since our project is very large, we cannot afford to retest it every time.
We write autotests for everything. There are about 7,000 unit tests in the project, we run them on every commit, and they make sure that nothing is broken.
When you have a very large project, auto tests are not just a nice addition, which sometimes helps to find errors. This is a necessary working tool, without which you can not work. You will drown in the number of bugs that appear in the code.
This is an example of tests when you are testing some kind of logic, some kind of class or function.
First, you do some preparatory actions, then an action that needs to be checked, and at the end you compare the result of this action with the expected one. If not as expected, then the test has dropped.
How to write tests on the interface, on all sorts of buttons? Similar!
We first render something on the page, then do the action that needs to be checked, for example, enter a value and click on the button, and at the end check that, for example, a request was sent to the server with the correct parameters or in the right place on the form An error message was displayed. The sequence of actions is the same as when writing ordinary logic tests.
What is the problem with this scheme? These tests all need a browser. This is a program with a graphical interface, where the user enters something from the keyboard, clicks on the buttons, and the result of any browser is the pixels drawn on the screen. We have autotests, we want to run them automatically, without human intervention. For tests on the interface, we need a browser, and this is not suitable for us.
What can be done? There are two ways to solve this problem. The first is to use some kind of browser control tool. Selenium is such a thing that does the same actions as the user in the browser, but you can control these actions programmatically, it will do them automatically. The second way is to use Headless browsers. Very popular - PhantomJS. He died, but still very popular.
When you use Selenium or another similar browser management tool, the scheme will be something like this.
This notebook with checkmarks is a test run, it is similar to the code that you saw on the screen, and it gives commands to a special piece called the “Selenium web driver”. This is a software library that provides an API to control the browser. There are commands “open the page”, “click on the button”, “enter text in the input field” and so on.
Selenium web driver starts somewhere, on this machine or on a remote, real browser, a window will be drawn there, and the actions that need to be performed in the test will be automatically executed in it. In this case, the browser will be unavailable to the user. There will be a message that the browser is controlled by automated software and nothing can be done in this window. This approach is similar to the usual test by the tester, only the commands are given not by the person, but by your test. The test code here will look something like this.
There is a variable browser. In different frameworks, it may be called differently, but the essence is the same: you have an object with which you access the Selenium API of the web driver. Preparing, verifiable actions, verification - there are all the same actions that were on the slide about testing functions / classes. You just tell the browser what to do.
What are the benefits of this approach? First, the Selenium web driver provides the same way to control different browsers. For example, you use it to test in Firefox and Chrome. Then you were told to run tests in IE or in mobile Safari. You add IE8 in the settings, and the tests start running in IE. You do not need to edit the test code. The uniformity of browser management is a big plus.
The second plus is scalability. In the scheme I showed, the third component is the browser. It can be located not only on the computer where the tests are running, but also on the other. And what's more, you can add more computers with browsers to this scheme, and at once drive a lot of tests into them in parallel. This is very useful when you have hundreds or thousands of tests, and on the same computer they, for example, run for an hour and a half, and you added 10 computers or launched in the cloud, and they take you 10 minutes to complete. This is a very good way to speed up your tests, and you can do it very easily. This scheme scales very well.
This approach works well, it is actively used in the search, because they have a large audience with different browsers.
How to run tests using Selenium?
The guys from the Search wrote a special tool - "Hermione" . This is not just a test run, there are many possibilities. But first of all, it is a tool that runs tests in Selenium in a heap of browsers.
On the slide - npm packages. Nightwatch knows about the same thing as Hermione, their possibilities are slightly different, you can watch these two things and choose what you like.
Testing in Selenium is a good approach, it works, many people use it. But he has one significant limitation.
You cannot write unit tests. Only integration. What is the difference between unit tests and integration tests?
Integration tests check everything in the collection. Your interface element under test can use other interface elements inside, for example, you are testing a form, it uses buttons, input fields, nested forms. And it can have external APIs in dependencies, for example, it can download something from the network, download from some storage, system time is also an external dependency. Integration tests are testing everything in a heap, they say: to render the forms on the page with all the pieces, to do some actions there.
Unit tests test an element in isolation from its dependencies. They put a stub on each arrow on the diagram, and the dependency code is not executed during the test. Instead, the small stub code is executed. He slips the data to be checked for the test block.
Each approach solves its problem. We in the Directive are exactly the unit tests. Because we have very complex blocks with very complex logic and it is very difficult to check them with integration tests. They need to submit a large sheet of data at the entrance, prepare the data for all the dependencies of the block. If something breaks inside, it's hard to understand where it broke. And integration tests are slow.
We have integration tests, but there are many places where you need to write unit tests, test a separate unit, without this tail.
What happens in Selenium? At the bottom of the file with the code that runs in the scheme. On the left, where the test runs, the code of our tests is executed, and on the right, where the browser is, the test page code and the code we are testing are executed. Between them is a layer in the form of Selenium, and the test code does not have direct access to the code that it is testing. The test code cannot put all stubs in order to isolate the test code from dependencies. It can interact only with the Selenium API, click something. He can perform some kind of JS, but still he does not have direct access. Because of this, you cannot write unit tests.
Alternatively, it would be possible to transfer this test code to the browser side and report the data on how the tests go to the test run, so that it displays its checkmarks and crosses. But with Selenium we cannot do this, because this API is one way. You can ask the browser for something from the test, but you cannot send something from the browser to the program that controls it.
Conclusion: we need modular tests in Direkt, but we cannot use the approach from Selenium for unit tests, only for integration tests.
Let's take a look at the second approach - testing in Headless browsers.
Headless browsers are the same as regular browsers, but during their work they do not display anything on the screen. You can launch the Headless browser as a console application. There the page will be opened inside, all CSS, JS will be executed, but you will not see anything on the screen.
In this case, you can control the browser only through some API, it does not have any user interface. This is similar to Selenium and the browser in one bottle, but the API is implemented inside the browser itself, it is not a separate external component.
It turns out, the API has access to the internals of the browser. Headless browsers APIs provide, as a rule, a much larger set of features than Selenium. In particular, there you can listen to browser events like page load, page error, you can intercept requests to the network, intercept output to the console and much more. These things make it possible for the variant I was talking about: transfer the test code to the browser side so that it sends information about how the tests go to the test runner. This approach is also very popular, many need unit tests. We have been using it for about three years.
Until recently, the only browser that worked fine was PhantomJS.
It had drawbacks - memory is flowing and it is difficult to join the debugger in order to debug tests - but in principle, this is a normal working browser. He has a webkit inside, it all works, we used it for two years.
This is a screenshot from Google Groups, there the last PhantomJS developer Vitaly Slobodin says something like this: “soon there will be Headless Chrome, it works better, it does not eat memory like crazy, so I will not develop PhantomJS, switch to Chrome”. We also began to look at Chrome and switched to it.
This is the tool logo called Puppeteer - for managing Chrome in Headless mode. Puppeteer (translated as "puppeteer") is developed by the Chrome Dev Tools team, there is some confidence that they will not abandon his support. This is the NodeJS package, it has the JS API, and the coolest is that it puts Chrome along with it as a dependency. You do not need to separately install the browser in order to run something in it. You wrote npm install - and it all worked right away.
We looked in his direction, tried it, we liked it. The only problem was that there were no tools to cross our tests and Headless Chrome. For PhantomJS such tools were, since it has existed for a long time, and Headless Chrome only appeared, there were no tools.
We wrote our mocha-headless-chrome tool.
We have less fantasy than in the Search: their tool is called “Hermione”, and ours is “mocha-headless-chrome”. We use it for half a year, it works. For example, a small project will show how this happens. (A demo from the report is here - ed.)
In the test project, one file is test-form.js. It is easy to guess that this is a search form, there is an input and a button. The SearchForm class, it has a render method, almost like in React, and it adds a form, an input and a button to the page. In addition, he subscribes to a click on the button, and when you click on the button, he makes an Ajax request, sends the contents of the form to example.com, and then he cleans the form.
class SearchForm { onClick(e) { e.preventDefault(); let xhr = new XMLHttpRequest(); xhr.open("GET", "http://example.com"); xhr.send(new FormData(this.form)); this.form.reset(); } render(parent) { this.form = document.createElement('form'); this.form.innerHTML = `<input type="text" name="query" /> <input type="button" value="" />`; this.input = this.form.querySelector('input[type=text]'); this.button = this.form.querySelector('input[type=button]'); this.button.addEventListener('click', this.onClick.bind(this)); parent.appendChild(this.form); } destroy() { this.form.remove(); } } Let's write for this simple test. The folder tests, in it file test.js. While there are no tests here, just describe and the action that needs to be performed before each test and after.
const assert = chai.assert; describe(' ', function() { let searchForm, server; beforeEach(function() { searchForm = new SearchForm(); searchForm.render(document.body); server = sinon.createFakeServer({ respondImmediately: true }); }); afterEach(function () { searchForm.destroy(); server.restore(); }); }); Before each test we add our form to the page, and after each test we delete it.
Also, before each test we make a stub for Ajax requests, so that the test can check which requests are made. And after each test, we reset this stub - remove it.
We wrote a file of our tests, JS, there are no tests there yet, we will write soon.
But first, let's make a test page that will open in the browser.
In the tests folder, I make a file test.html. There is nothing complicated here, we are connecting three libraries, Mocha is a test framework, I think everyone is familiar with it. Sinon is a library that allows you to automatically create all sorts of stubs to isolate our block from its dependencies. And the chai library with all kinds of assertions, it gives an API for various checks in tests.
<html> <head> <meta charset="utf-8"> <link href="../node_modules/mocha/mocha.css" rel="stylesheet" /> <script src="../node_modules/mocha/mocha.js"></script> <script src="../node_modules/sinon/pkg/sinon.js"></script> <script src="../node_modules/chai/chai.js"></script> <script>mocha.setup('bdd');</script> </head> <body> <div id="mocha"></div> <script src="../src/search-form.js"></script> <script src="../tests/test.js"></script> <script>mocha.run();</script> </body> </html> We connected these three libraries, further connected the code of our form, the search-form, and connected our test file we just created. In the end, they called the mocha-run command to start the tests.
Run the page in the browser and make sure that everything is ok. The page has opened, there are zero tests in it, which is expected. Let's write a couple of tests. The test checks that when we clicked the button, an Ajax request to the correct address was sent to the server. This is the searchForm we created at the beginning. The test fills the form with data, then clicks on the button, then with the help of a stub in the server variable it checks that the last request made had the desired url.
it(' ', function() { // searchForm.input.value = ''; // searchForm.button.click(); // assert.equal(server.lastRequest.url, 'http://example.com'); }); Let's see the page in the browser, it has been updated, and we see that one test has passed. The browser has code that makes an Ajax request. We put a stub on it so that it did not make this request during the test, and checked that the request was made with the correct parameters.
Let's run it all in Headless Chrome.
npm install mocha-headless-chrome
I add the test command to package.json so that I do not write every time. When you install the mocha-headless-chrome package, it adds a utility with the same name. It needs to pass the parameter -f - the path to our test page, which we opened in the browser.
{ ... "scripts": { "test": "mocha-headless-chrome -f tests/test.html" }, ... } Now, if I run the npm test now, everything should work.
We set the dependency, it downloaded Chrome itself, put it locally in the node_modules folder. Then we just call it by name as a console application and pass a test page via the f parameter. The test passed, this is our test that we wrote.
Let's try to add another test that verifies that after sending an Ajax request, we cleared the value in the search form.
it(' ', function() { // searchForm.input.value = ''; // searchForm.button.click(); // assert.equal(searchForm.input.value, ''); }); In the browser, check that it appeared. Next, run it in the terminal. We had two tests, and when they were executed, you did not see any browser window. The person who starts it, did nothing with his hands, everything goes completely automatically.
We use this tool for about six months. 7000 tests that previously worked in PhantomJS, without any problems began to work in Headless Chrome. Test execution accelerated by 30%. This thing is available in external npm, you can also take it and use it. There are already 5000 downloads per month, that is, there are people outside of Yandex who use it.
Source: https://habr.com/ru/post/353018/
All Articles