What will be Web 3.0: blockchain-marketplace for machine learning
How to create a powerful artificial intelligence? One of the ways is to use machine learning models with data that is distributed through blockchain-based marketplays. Why is there a blockchain? It is with his help that in the future we can expect the appearance of open electronic exchanges where everyone can sell their data without violating confidentiality. And developers - choose and acquire the most useful information for their algorithms. In this post we will talk about the development and prospects of such sites.

Today, the basic elements of such systems are only being formed. Simple initial versions of such solutions inspire hope for success. These trading platforms will provide a transition from the current era of exclusive ownership of Web 2.0 data to Web 3.0 - open competition for data and algorithms with the possibility of direct monetization.
The idea of such a platform came to me in 2015 after talking with Richard from the Numerai hedge fund. They held a competition to develop a stock market model and sent encrypted market data to any specialist who wanted to participate in it. As a result, Numerai combines the best models into a “meta model”, sells it and pays rewards to those professionals whose models work efficiently.
')
The competition between data processing and analysis specialists seemed like a promising idea. Then I thought: Is it possible to create a completely decentralized version of such a system that would be of a general nature and could be used to solve any problems? I believe that this question can be answered in the affirmative.
As an example, let's try to create a fully decentralized system for trading cryptocurrencies on decentralized exchanges. Here is one of the possible schemes:
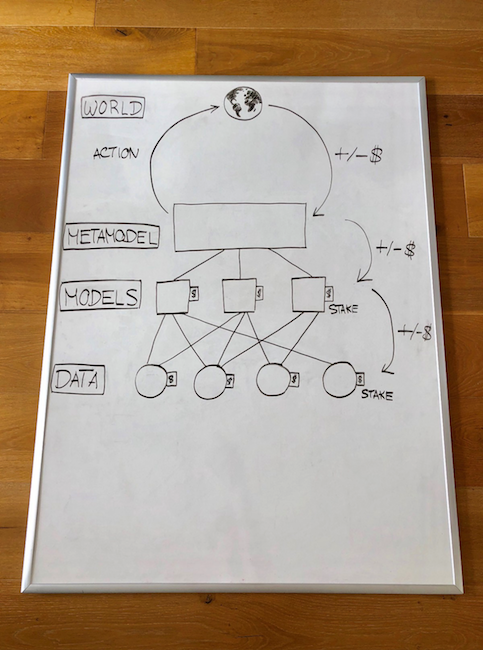
Let us explain the different levels of her work:
The data . Data providers place their data on the stock exchange and share it with model developers.
Models . Model designers choose which data to use, and create models. Training is conducted using a safe calculation method that allows you to train models without disclosing the data used. Models are put on the stock exchange in the same way as the data.
Metamodel . A meta model is created based on an algorithm that takes into account the exchange price of each model. Creating a metamodel is optional — some models are used without being merged into a metamodel. The smart contract uses the metamodel in electronic trading through decentralized exchange mechanisms (on-chain transactions).
Profit / loss distribution . After some time, the trades give a profit or loss, which is divided between the developers of the metamodel, depending on their contribution to its improvement. Models that have had a negative impact on the metamodel, lose funds attracted fully or partially. And the data providers for this model also suffer some losses.
Verification of calculations . Calculations at each stage are performed in two ways. Either centrally, but with the possibility of verification and protest through mechanisms like Truebit . Or decentralized, using the confidential calculation protocol.
Hosting . Data and models are placed either on IPFS or on nodes in a secure confidential computing system with a large number of participants. On-chain storage in this case will be too expensive.
We list the main advantages of such a system:
In addition to the above, the most important property is confidentiality. The guarantee of confidentiality allows ordinary users to easily provide any personal data. And also to prevent the loss of economic value of both data and models. If you leave the data and models unencrypted in the public domain, they will be copied for free and used by other people who do not make any contribution to the common cause (“ free ticket effect ”).
A partial solution to the free-rider problem is the sale of data in private. Even if buyers want to resell or disclose data, it is not so bad, because the cost of data is still amortized over time. However, with this approach, data is used exclusively in the short term, and problems with ensuring their confidentiality are not solved at all. So the use of secure computing seems to be more complicated, but also a more efficient approach.
Secure computing methods allow you to train models without disclosing the data itself. Currently, three basic types of secure computing are being used and investigated: homomorphic encryption (HE), confidential calculation protocol (MPC) and zero-disclosure proof (ZKP). For machine learning using personal data, MPC is most often used today, since HE is usually too slow, and it’s unclear how to use ZKP for machine learning. Methods of safe computing is the most current topic of modern computer research. Such algorithms, as a rule, require much more time than conventional calculations, and become the bottleneck of the system. But in recent years they have been significantly improved.
To illustrate the potential of machine learning on private data, imagine an application called “The Ideal Recommender System”. It monitors everything that you do on your devices: analyzes all visited sites, all actions in applications, viewed pictures on your phone, location data, cost history, information from wearable sensors, text messages, data from cameras in your house and on your future augmented reality glasses. This information will allow the application to give you recommendations: which website to visit, which article to read, which song to listen to or which product to buy.
This recommendation system will be extremely powerful, more powerful than any of the existing “silos” with data from Google, Facebook or anyone else. All thanks to the most in-depth analysis and the opportunity to learn with the help of the most sensitive personal data that you wouldn’t share with anyone anymore . As in the previous example with the cryptocurrency trading system, the key to the functioning of the recommender system is the creation of a market of models focused on different areas (for example, recommendations of websites or music). These models would compete for access to your encrypted data, the ability to recommend - and probably would even pay you for using your data or for your attention to the recommendations.
Google’s distributed learning system and Apple’s differential privacy system can be considered steps towards machine learning using personal data. But these solutions still imply the establishment of a trusting relationship , do not allow users to monitor their security on their own, and keep data apart.
It’s too early to talk about full-fledged systems of this kind. At the moment, few people already have something working, and most go to such systems gradually.
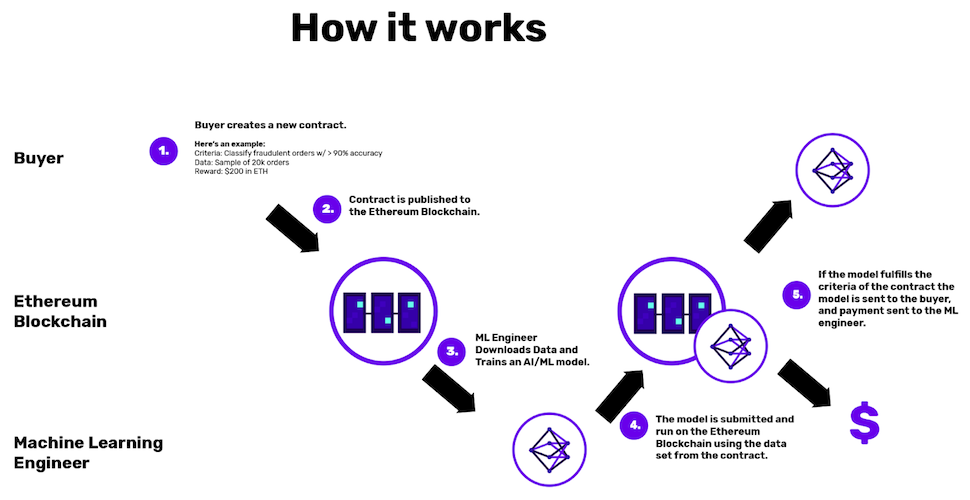
Algorithmia Research has developed a fairly simple solution that rewards the model with an accuracy above a certain threshold, which is determined retrospectively:
Numerai's hedge fund went three steps ahead. His system:
Data analysts should use Numeraire as a shell, thereby confirming their own interest and stimulating future performance. And yet, at the moment Numerai distributes data centrally, so that the most important characteristic of the system is still not implemented.
At the moment, a successful blockchain-based marketplace data has not yet been created. The first attempt to develop such a system, at least in general terms, was The Ocean . Others start by building secure computing networks. As part of the Openmined project, work is underway to create a multi-user computer network for learning Unity- based machine learning models that can work on any device, including game consoles (similar to Folding at Home ). Subsequently, it is planned to expand this system to a confidential calculation protocol. A similar approach is followed by Enigma .
As a result of these works, it would be great to get metamodels that would provide co-owners - data providers and model developers - ownership in an amount proportional to their contribution to the improvement of the metamodel . Models would be tokenized and could generate income over time, and those who trained them could even manage them. It would be a kind of jointly owned swarm intelligence. From all that I have seen so far, the Openmined project came closest to such a system, according to a video about it.
I will not say that I know which project is better, but I have some thoughts on this matter.
For blockchain, I rate the system as follows. If we decompose it in the continuous spectrum “physical-digital-blockchain”, the more from the blockchain, the better. The less blockbus in it, the more you have to involve trusted parties. So the system becomes more difficult, and it is less convenient to use it as an integral part of other systems.
This means that the system will be more likely to work if the value it creates is quantifiable. Ideally, in monetary terms, and even better in the form of tokens. This will create a fully closed system. To evaluate the effectiveness, compare the system above, for example, with the X-ray tumor recognition system. In the latter case, you need to convince the insurance company that X-rays have some value, agree on how valuable they are, and then trust a small group of people to confirm the success or failure of X-rays.
Such a system can be used in a host of other useful scenarios. They can be tied to the curation market - they can work in a closed loop on a blockchain model, and the tokens of this market can act as a bonus. Now the picture is still not clear, but I guess that with time the number of areas requiring the use of the blockchain will only grow.
Decentralized data markets and machine learning models can break the data monopoly that modern corporations have. For the past 20 years, they have been engaged in standardization and trading of the main source of value on the Internet: proprietary data networks and the impact they have. But now the creation of value is no longer connected with data, but with algorithms.
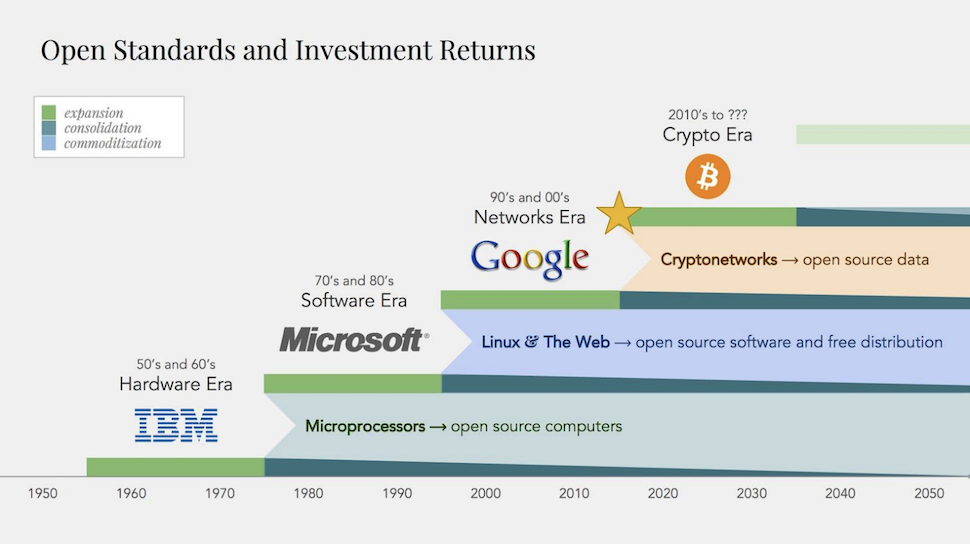
Cycles of standardization and commercialization of technology. We are nearing the end of an era of data monopolizing networks.
In other words, they create a business model of artificial intelligence, based on direct interaction , provide both the provision of data and the training of models.
The emergence of decentralized markets for data and machine learning models can lead to the creation of the most powerful AI in the world. Due to direct economic incentives, they could get the most valuable data and models. Their power is enhanced by multi-sided network effects. The monopolies of Web 2.0 era network data are turning into everyday goods and becoming good material for a new conglomeration. Probably, we have a few more years to go, but we are going in the right direction.
As the example of the recommender system shows, the search process is globally inverted . Now people are looking for goods - and in the future, goods will search for people and compete for them. Each consumer will have personal curation markets, in which recommendation systems will compete for placing the most relevant content on their channels. And relevance will be determined by the consumer.
New models will allow us to get the same benefits from powerful services based on machine learning, to which we are accustomed to the example of Google and Facebook services. But without providing personal data.
Finally, machine learning will grow faster, as any development engineer, and not just a small group of engineers at large Web 2.0 companies, will be able to access the open data marketplace.
First of all, safe computing methods are currently slow, and machine learning already requires a lot of computational power. On the other hand, interest in methods of safe computing begins to appear, and their productivity grows. Over the past six months, I have seen several new approaches that significantly improve the performance of the HE, MPC and ZKP.
It is difficult to determine the value of a particular data set or model for a metamodel.
Clearing and formatting crowdsourced data is also not easy. Most likely, a number of tools will be used in combination with each other, and standardization processes will begin in the segment with the active participation of small companies.
Finally, paradoxically, the business model for creating such a generalized system is less obvious than in the case of a private system. The same situation with many new crypto-primitives, including with supervising markets.
The combination of machine learning based on private data with blockchain-rewards can lead to the creation of the most productive artificial intelligence systems for various purposes. Now there are big technical problems, which in time seem quite solvable. This segment has enormous potential in the long term, and its development may weaken the dominant position of large Internet companies in data access. These systems even inspire some fears: they load themselves, develop themselves, consume confidential data and become almost unkillable, making me wonder if their creation would lead to the appearance of the most powerful Moloch in history. In any case, these systems are another example of how cryptocurrencies can first slowly, and then rapidly break into all spheres of economic activity.
Today, the basic elements of such systems are only being formed. Simple initial versions of such solutions inspire hope for success. These trading platforms will provide a transition from the current era of exclusive ownership of Web 2.0 data to Web 3.0 - open competition for data and algorithms with the possibility of direct monetization.
The emergence of ideas
The idea of such a platform came to me in 2015 after talking with Richard from the Numerai hedge fund. They held a competition to develop a stock market model and sent encrypted market data to any specialist who wanted to participate in it. As a result, Numerai combines the best models into a “meta model”, sells it and pays rewards to those professionals whose models work efficiently.
')
The competition between data processing and analysis specialists seemed like a promising idea. Then I thought: Is it possible to create a completely decentralized version of such a system that would be of a general nature and could be used to solve any problems? I believe that this question can be answered in the affirmative.
Design
As an example, let's try to create a fully decentralized system for trading cryptocurrencies on decentralized exchanges. Here is one of the possible schemes:
Let us explain the different levels of her work:
The data . Data providers place their data on the stock exchange and share it with model developers.
Models . Model designers choose which data to use, and create models. Training is conducted using a safe calculation method that allows you to train models without disclosing the data used. Models are put on the stock exchange in the same way as the data.
Metamodel . A meta model is created based on an algorithm that takes into account the exchange price of each model. Creating a metamodel is optional — some models are used without being merged into a metamodel. The smart contract uses the metamodel in electronic trading through decentralized exchange mechanisms (on-chain transactions).
Profit / loss distribution . After some time, the trades give a profit or loss, which is divided between the developers of the metamodel, depending on their contribution to its improvement. Models that have had a negative impact on the metamodel, lose funds attracted fully or partially. And the data providers for this model also suffer some losses.
Verification of calculations . Calculations at each stage are performed in two ways. Either centrally, but with the possibility of verification and protest through mechanisms like Truebit . Or decentralized, using the confidential calculation protocol.
Hosting . Data and models are placed either on IPFS or on nodes in a secure confidential computing system with a large number of participants. On-chain storage in this case will be too expensive.
Why will it be efficient and productive?
We list the main advantages of such a system:
- Stimulus to attract the most requested data. As a rule, for most machine learning projects, the main limiting factor is the lack of quality data. Properly designed remuneration structure will allow access to all the most valuable data in the same way as the emergence of Bitcoin with the reward system of participants led to the emergence of the most powerful computer network in the world. In addition, shutting down a system in which data comes from thousands or millions of sources is almost impossible.
- Competition between algorithms. Models and algorithms directly compete with each other in areas where this has not happened before. Imagine a decentralized Facebook network with thousands of competing news feed algorithms.
- Transparency of rewards . Providers of data and models see that they get a fair price for their products, since all the calculations can be checked. This will attract even more data providers.
- Automation. Transactions are carried out in the blockchain environment and the cost is generated directly in tokens. Thus, the entire interaction becomes automated and closed, not requiring the establishment of trust relationships.
- Network effect. The participation of users, data providers and data processing and analysis specialists provides a multilateral network effect and makes the system self-developing. The better it works, the more capital it attracts. More capital - more potential payouts. This, in turn, attracts more data providers and data processing specialists who make the system more sophisticated and rational. As a result, more investments are attracted, and further in a circle.
System privacy
In addition to the above, the most important property is confidentiality. The guarantee of confidentiality allows ordinary users to easily provide any personal data. And also to prevent the loss of economic value of both data and models. If you leave the data and models unencrypted in the public domain, they will be copied for free and used by other people who do not make any contribution to the common cause (“ free ticket effect ”).
A partial solution to the free-rider problem is the sale of data in private. Even if buyers want to resell or disclose data, it is not so bad, because the cost of data is still amortized over time. However, with this approach, data is used exclusively in the short term, and problems with ensuring their confidentiality are not solved at all. So the use of secure computing seems to be more complicated, but also a more efficient approach.
Secure computing
Secure computing methods allow you to train models without disclosing the data itself. Currently, three basic types of secure computing are being used and investigated: homomorphic encryption (HE), confidential calculation protocol (MPC) and zero-disclosure proof (ZKP). For machine learning using personal data, MPC is most often used today, since HE is usually too slow, and it’s unclear how to use ZKP for machine learning. Methods of safe computing is the most current topic of modern computer research. Such algorithms, as a rule, require much more time than conventional calculations, and become the bottleneck of the system. But in recent years they have been significantly improved.
“The ideal recommender system”
To illustrate the potential of machine learning on private data, imagine an application called “The Ideal Recommender System”. It monitors everything that you do on your devices: analyzes all visited sites, all actions in applications, viewed pictures on your phone, location data, cost history, information from wearable sensors, text messages, data from cameras in your house and on your future augmented reality glasses. This information will allow the application to give you recommendations: which website to visit, which article to read, which song to listen to or which product to buy.
This recommendation system will be extremely powerful, more powerful than any of the existing “silos” with data from Google, Facebook or anyone else. All thanks to the most in-depth analysis and the opportunity to learn with the help of the most sensitive personal data that you wouldn’t share with anyone anymore . As in the previous example with the cryptocurrency trading system, the key to the functioning of the recommender system is the creation of a market of models focused on different areas (for example, recommendations of websites or music). These models would compete for access to your encrypted data, the ability to recommend - and probably would even pay you for using your data or for your attention to the recommendations.
Google’s distributed learning system and Apple’s differential privacy system can be considered steps towards machine learning using personal data. But these solutions still imply the establishment of a trusting relationship , do not allow users to monitor their security on their own, and keep data apart.
Implemented approaches
It’s too early to talk about full-fledged systems of this kind. At the moment, few people already have something working, and most go to such systems gradually.
Algorithmia Research has developed a fairly simple solution that rewards the model with an accuracy above a certain threshold, which is determined retrospectively:
Numerai's hedge fund went three steps ahead. His system:
- uses encrypted data (although this type of encryption cannot be considered completely homomorphic),
- combines crowdsourcing models into a metamodel,
- Rewards models through Numeraire's own Ethereum token based on future performance (stock trading weeks), rather than retrospective testing.
Data analysts should use Numeraire as a shell, thereby confirming their own interest and stimulating future performance. And yet, at the moment Numerai distributes data centrally, so that the most important characteristic of the system is still not implemented.
At the moment, a successful blockchain-based marketplace data has not yet been created. The first attempt to develop such a system, at least in general terms, was The Ocean . Others start by building secure computing networks. As part of the Openmined project, work is underway to create a multi-user computer network for learning Unity- based machine learning models that can work on any device, including game consoles (similar to Folding at Home ). Subsequently, it is planned to expand this system to a confidential calculation protocol. A similar approach is followed by Enigma .
As a result of these works, it would be great to get metamodels that would provide co-owners - data providers and model developers - ownership in an amount proportional to their contribution to the improvement of the metamodel . Models would be tokenized and could generate income over time, and those who trained them could even manage them. It would be a kind of jointly owned swarm intelligence. From all that I have seen so far, the Openmined project came closest to such a system, according to a video about it.
What can work faster?
I will not say that I know which project is better, but I have some thoughts on this matter.
For blockchain, I rate the system as follows. If we decompose it in the continuous spectrum “physical-digital-blockchain”, the more from the blockchain, the better. The less blockbus in it, the more you have to involve trusted parties. So the system becomes more difficult, and it is less convenient to use it as an integral part of other systems.
This means that the system will be more likely to work if the value it creates is quantifiable. Ideally, in monetary terms, and even better in the form of tokens. This will create a fully closed system. To evaluate the effectiveness, compare the system above, for example, with the X-ray tumor recognition system. In the latter case, you need to convince the insurance company that X-rays have some value, agree on how valuable they are, and then trust a small group of people to confirm the success or failure of X-rays.
Such a system can be used in a host of other useful scenarios. They can be tied to the curation market - they can work in a closed loop on a blockchain model, and the tokens of this market can act as a bonus. Now the picture is still not clear, but I guess that with time the number of areas requiring the use of the blockchain will only grow.
Implications for the market
Decentralized data markets and machine learning models can break the data monopoly that modern corporations have. For the past 20 years, they have been engaged in standardization and trading of the main source of value on the Internet: proprietary data networks and the impact they have. But now the creation of value is no longer connected with data, but with algorithms.
Cycles of standardization and commercialization of technology. We are nearing the end of an era of data monopolizing networks.
In other words, they create a business model of artificial intelligence, based on direct interaction , provide both the provision of data and the training of models.
The emergence of decentralized markets for data and machine learning models can lead to the creation of the most powerful AI in the world. Due to direct economic incentives, they could get the most valuable data and models. Their power is enhanced by multi-sided network effects. The monopolies of Web 2.0 era network data are turning into everyday goods and becoming good material for a new conglomeration. Probably, we have a few more years to go, but we are going in the right direction.
As the example of the recommender system shows, the search process is globally inverted . Now people are looking for goods - and in the future, goods will search for people and compete for them. Each consumer will have personal curation markets, in which recommendation systems will compete for placing the most relevant content on their channels. And relevance will be determined by the consumer.
New models will allow us to get the same benefits from powerful services based on machine learning, to which we are accustomed to the example of Google and Facebook services. But without providing personal data.
Finally, machine learning will grow faster, as any development engineer, and not just a small group of engineers at large Web 2.0 companies, will be able to access the open data marketplace.
Problems
First of all, safe computing methods are currently slow, and machine learning already requires a lot of computational power. On the other hand, interest in methods of safe computing begins to appear, and their productivity grows. Over the past six months, I have seen several new approaches that significantly improve the performance of the HE, MPC and ZKP.
It is difficult to determine the value of a particular data set or model for a metamodel.
Clearing and formatting crowdsourced data is also not easy. Most likely, a number of tools will be used in combination with each other, and standardization processes will begin in the segment with the active participation of small companies.
Finally, paradoxically, the business model for creating such a generalized system is less obvious than in the case of a private system. The same situation with many new crypto-primitives, including with supervising markets.
Conclusion
The combination of machine learning based on private data with blockchain-rewards can lead to the creation of the most productive artificial intelligence systems for various purposes. Now there are big technical problems, which in time seem quite solvable. This segment has enormous potential in the long term, and its development may weaken the dominant position of large Internet companies in data access. These systems even inspire some fears: they load themselves, develop themselves, consume confidential data and become almost unkillable, making me wonder if their creation would lead to the appearance of the most powerful Moloch in history. In any case, these systems are another example of how cryptocurrencies can first slowly, and then rapidly break into all spheres of economic activity.
Source: https://habr.com/ru/post/352724/
All Articles