Network Optimization for Unreal Engine 4

Not so long ago, in the official group UE4 in vk, I asked which topics would be interesting for the community to talk about them :) One of the popular requests was to work with the network on the engine.
In the beginning, I did not plan to somehow disclose or mention this topic, but then I thought that it would be nice to issue a “Best Practices” even for myself and my team.
So, if you're wondering how we made the network for our Armored Warfare: Assault , welcome under cat.
It is impossible to imagine the Unreal Engine apart from the Unreal Tournament, a leitmotif going through all versions of the engine. As a result, one of the strengths of the UE4 is a powerful network toolkit integrated into the engine at the basic level. By my personal assessment, the only engine that would equally scrupulously approach questions at the same level is the Quake 3 engine.
The presence of high-quality technology does not deprive us of the need to think when developing. Unfortunately, I have seen quite a few projects where an irresponsible attitude to the organization of the work of the network led to disastrous results.
This article is never a “beginner’s guide” or “a detailed description of how things work.” No, this is a certain exaggerated view of the principles that allow you to effectively optimize the network.
How things are arranged
To start working on multiplayer in UE4, you will need to understand the three available communication paths:
- Replication of variables: from server to client, and not otherwise. The client cannot under any circumstances change the variable so that it changes its value on the server.
- RPC: from server to client.
- RPC: from client to server.
The third way is the only way to report any data from the client to the server. Variable replication (first path) is used to synchronize ector states between the server and clients. Sending RPC from server to client (second path) - event model for sending specific data.
In short, everything works like this. Each replicated ector has a NetUpdateFrequency parameter that sets how many times per second the ector will check its state for “what would I exchange over the network”. By default, this parameter is insanely 100.f , which means: if your ector is replicated, attempts to synchronize and send data will be every tick.
The consequences are obvious and sad: it becomes an elementary task to hammer in the network with packages. The load on the server CPU increases. Everything lags, “nothing works,” “the character is teleported,” “other players are trembling,” and so on, in the very simple way, on seemingly simple projects.
So we come to the very first rule: set adequate NetUpdateFrequency for all replicable ectors .
What is "adequate" - the question, as always, is open. For a hardcore quake shooter, everything that concerns a character — his movement and weapon — must be synchronized with the maximum frequency. But this is a specific case, and if you are working on such a project, you will not have enough “basic” knowledge and approaches - dig deeper if you want to get a quality product.
In a certain "average" case - arcades, MOBA, mobile toys, as well as "slow shooters" a la tanks and others - the frequency of network updates can and should be much lower. In AW: Assault, we use the frequency of updating the state of the tank 10 times per second . I also know projects that work based on the frequency of network updates of the main character 6-8 times per second.
Other objects - various "capture points", "flags", "cartridges", "game states" - can be updated even less often. A good example: by default, the PlayerState engine class is replicated only once per second, and rightly so . If suddenly a change in the ector state should be delivered as quickly as possible, there is always the possibility to call ForceNetUpdate () .
I note that the ector components inherit its network update frequency, so the immediately occurring "separation" of one ector into parts with different update rates is not a trivial task. More precisely: if a component requires a different frequency than the ector as a whole is able to live, you must carefully cut it into a separate entity. If a component can live on the network “slower” than its owner, the owner does not update every tick - this is a normal situation.
Rule two: reliable RPC should be seriously justified . In our department there is a joke that every reliable rpc function is issued “against the signature” of the manager. In every joke share jokes.
We must remember that it is expensive. Highly. The overhead for RPC as such is not as large as the possible consequences. Handle carefully, as with a bottle of nitroglycerin. Especially in the case of multicast . The worst thing that can happen after you have ceased to "teleport" is to disconnect the client from the server due to an overflow of such a thing as a reliable buffer. The network architecture built on such events becomes hypersensitive to ping and packet loss.
A simple example: you want to send a notification about an action from the server to the client. Suppose you are doing an alcoholic simulator online, and your character has every tick regen liver that exists as a separate component. All customers really need to know every step of the "treatment" to beautifully show it on the screen (multicast, reliable). Each tick you send RPC LiverHealed (float HealedHeath). You test in the editor on two clients: beauty, everyone is happy. And here, a live situation: the client pledged, the loss of packets, it is necessary to send all the RPC that had accumulated in half a second, and you discover how the patient happily flies out from the server.
Obviously, at a minimum, there is no need to send every server tick to RPC, if NetUpdateFrequency is many times less - it will just stop the queue. It is necessary to accumulate these values and send less often. And think again, is it reliable data, and if so, can you manage to replicate the variable, and if not, make unreliable. In many cases, it is also worth considering whether the client himself can not calculate whether an event occurred, based on his data about the game world (the same treatment for a character's liver is the change in her health for a client tic).
Conceptual traps
Or rather, a couple of things worth mentioning.
When the variable - the replicated UObject, is reset, OnRep will not be called and will cease to be called on the client in the future. It sounds like a bug, and honestly, I do not remember why it works that way. Enough to know about it and take into account when developing.I checked on a synthetic test for UE 4.18: everything works as it should, so the information is no longer relevant.- Calling client RPC on the server does not perform the function on the server, only sends the command to execute it on the client. If you need to execute it on the server, you must manually call Implementation.
- If the ector is rarely updated over the network (for example, PlayerState), use a reliable RPC there twice with caution. During the time between synchronizations, you can easily get a buffer if you don’t think about it. Ideally, such special networking classes should tick and update over the network in single order frequency.
Network tricks and receptions
Aimed at optimizing the load on the network, as well as optimizing the load on the CPU.
Global states
By the way, the third rule: if you can do without replicating ectors, do it .
Two examples from our AW: Assault, which implement this rule, but in different ways:
- Destroyable trees. They are not critical for gameplay, so they simply do not replicate. Each client will drop his own tree, based on the data available to him. It is not at all scary that the real picture of the world in this regard varies between the server, clients and between clients.
- Destructible objects of the environment. Fences, cars, fences. They directly affect the gameplay, you can “hide” behind them until the object is destroyed. Therefore, it is required that these objects on all clients reflect the real state of affairs. This global state is used for synchronization.
In the second example, the whole concept can be described as:
/** Array of bit masks for minimization of space used for destructible actors states. Replication handled by OnRep_DestructableMasks method */ UPROPERTY(ReplicatedUsing=OnRep_DestructableMasks) TArray<int32> DestructedActorsMasks; /** Handles replication of destructible actors masks */ UFUNCTION() void OnRep_DestructableMasks(); Each int32 encodes the state of as many as 32 objects . On stage we can have over a thousand such objects. In the case of coding up to 1024 objects, it would be possible to manage with only two int32 (multiplication of bit masks), but we have so far left the array replication, since even the current solution works without network load. At the stage of loading the map, the transfer of conditional forty ints over the network is not too big data, and during the battle not so many objects die at the same time. The engine takes care of optimal replication of an array when some of its fields change.

This approach works on the basis that static objects have a clear loading order both on the server and on the client. They can be cached into an array and replicate only the indices of modified objects. And let now only binary logic is implemented (alive / destroyed), such an approach will be justified even if additional fields appear (for example, "health" and "penetrability"), since These are homogeneous ectors living in large numbers on the map.
Want to make a completely destructible world of walls? Work with them through such states. Several ints in the form of bit masks will enable to encode thousands of destructible objects . The “standard” path through the replication of each such ector separately will easily kill you both the network and the server’s CPU (for checking who needs to be replicated there and to whom, and who will not).
Data packing
In general, I have already touched on this topic in the paragraph above, only indirectly: there we pack information about the state of thousands of objects on the scene into an array of bit masks. However, the same technique should be used for flags inside replicable ectors.
At a certain stage, we came to the conclusion that there were more than a dozen of the usual replicated Boolean flags in a tank. These are the usual gameplay states “is a tank drowning”, “arson”, “target is locked”, “dead” and others.
As a result, our core programmer wrote a proxy class for replicating such states . Usage looks like this:
RepOwnerFlags .Add(&bEnableLockTarget) .Add(&bCanMove) .Add(&bIsDrowning) .Add(&bInWater) .Build(); RepPublicFlags .Add(&bIsDying, this, "OnRep_IsDying") .Add(&bIsMoving, this, "OnRep_IsMoving") .Add(&bIsTurning, this, "OnRep_IsTurning") .Add(&bIsInFire) .Add(&bIsEngineBurning, this, "OnRep_IsEngineBurning") .Add(&bHasMinimapObservers) .Build(); RepOwnerFlags and RepPublicFlags are replicable class variables that act as a wrapper for uint64 . The variables themselves have become ordinary, not replicable from the point of view of the engine:
/** Notifies of death */ UFUNCTION() void OnRep_IsDying(); /** Identifies if pawn is in its dying state */ UPROPERTY(VisibleAnywhere, BlueprintReadOnly, Category = Death) bool bIsDying; It is also a good idea to pack bool's in uint8: 1 inside replicated structures , if there are several of them.
And yes, the same rule applies for RPC functions. You send some bulls - pack them. With floats in a vector and int8 (if possible) instead of int32, the same situation.
Fat ectors
It is easy to imagine a situation where starting replication of an ector takes a decent amount of time. For example, data on tank armor in our case (inside the tank consists of a large number of pieces, with their parameters, depending on the leveling).
When a large chunk of data arrives for replication from the ector, the network is considered overloaded, and no other ectors are replicated all this time .
In this case, a good way to avoid network saturation is to place this data piece by piece in an array and replicate it in chunks , checking for probable saturation:
bool AMyActor::ReplicateSubobjects(class UActorChannel **Channel, class FOutBunch **Bunch, FReplicationFlags **RepFlags) { bool WroteSomething = Super::ReplicateSubobjects(Channel, Bunch, RepFlags); auto NetDriver = Channel->Connection->GetDriver(); for (int32 i = 0; i < MyDataArray.Num(); i++) { // Check for saturation if (((Channel->Connection->QueuedBits) + Channel->Connection->SendBuffer.GetNumBits() + Bunch->GetNumBits()) >= 0) { return WroteSomething; } auto DataObject = MyDataArray[i]; if (DataObject != nullptr) { WroteSomething |= Channel->ReplicateSubobject(DataObject, **Bunch, **RepFlags); } } return WroteSomething; } MyDataArray is the same data. This approach allows you to avoid the "hang" of the entire network when creating an ector over the network.
It is worth considering that in this case the ector will be created, shown and revived before all its properties are replicated. If these properties determine its appearance and behavior, it is a good idea to hide it until the end of the full network initialization.
Condition, not result
From the point of view of network optimization, it will be correct for clients to replicate the condition that generates the calculations, and not the final result of such calculations. For example, information about the point where a character “looks” can generate all calculations about rotation and aiming, which can be calculated and smoothed over on the client.
On the other side of the coin is client optimization. The less the client thinks, the more pleasant it is to play on the same mobile phones.
Vector Quantization
It is rarely necessary to replicate a vector with complete accuracy. Therefore, for the replication of vectors, you should use special classes optimized for this case: FVector_NetQuantize, FVector_NetQuantize10, FVector_NetQuantize100 and FVector_NetQuantizeNormal.
From personal practice: accuracy above FVector_NetQuantize100 was never required, the vast majority for the network use FVector_NetQuantize and FVector_NetQuantizeNormal.
(Un) use of network relevance
If you do not know why you need network relevance for game characters, it is better to turn it off . The default settings in the engine are calculated more for quake-like shooters (UT ears, which I have already mentioned). They are not suitable for games with an open (visually) world, and the case with “fat” ectors is also not very pleasant.
The server, based on NetCullDistanceSquared (distance squared) between the ector and the player, decides whether this ector should exist on a specific client. If the distance between them is greater, the ector will be removed from the client; if less, it is re-created on the client. This operation is performed with a timeout of 5 seconds (default value RelevantTimeout).
The key here is to re-create . In the case of a fat ector, this process can either clog the network or lead to a frieze for the time the object is spawned (if its resources have been unloaded from memory). In the case of an open world, this is also an appearance in the middle of the location “from nowhere”. If your actors are constantly running "on the border" (by default, it runs 150 meters from your character), this process can be unpleasant.
At the same time, properly configured relevancy can significantly save you traffic and nerves, if the gameplay allows for such a setting . In the case of our AWA, network relevance is not used in any way: unlike the usual scheme of many, “a tank is visible on the client only when it is detected,” here you can see the enemy’s tank through the entire map.
Of course, you can manage relevance not only on the basis of the built-in mechanism, but also by redefining AActor :: IsNetRelevantFor (...). Sometimes this is necessary not so much because of network optimization considerations, but rather to protect against cheaters. On the example of MOBA: characters hidden in the fog of war should not be replicated to the client in order to avoid the most banal maphacks. No data - no candy.
Network debugging
Playtests
Play Test it. Check. Not in the editor and greenhouse conditions, but in real - with a client assembled and a server deployed in combat conditions. A local server on a development machine is a bad idea , especially if later you plan to use virtual machines, where usually there are ~ 4000 flops of performance.
And yes, no matter how convenient the network testing in the editor is, the real build, especially when it comes to consoles or mobile devices, is still a separate universe. Customer behavior in non-ideal conditions will be different.
Network profiler
Included with the engine is a great utility: NetworkProfiler
Just recently, this is how we searched for the cause of disconnect on one particular tank:
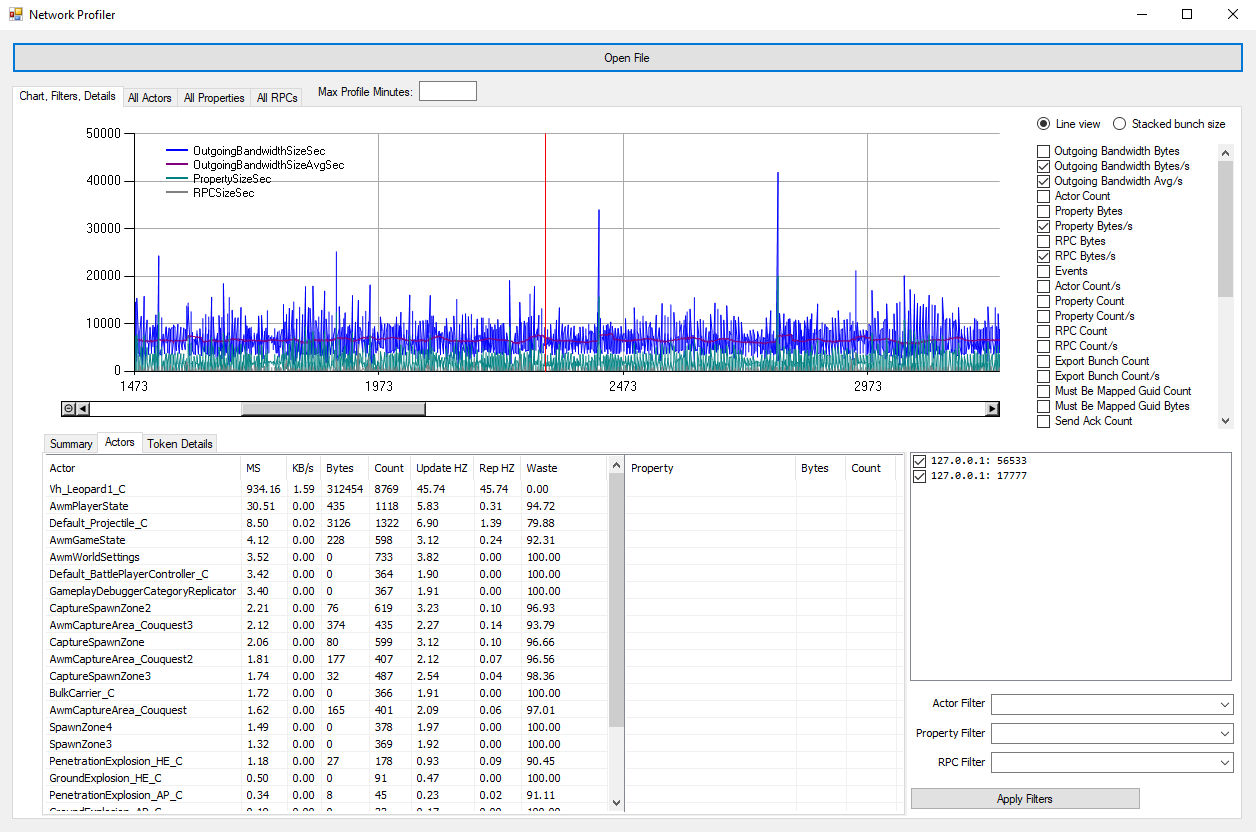
Profiler has its own oddities and works limitedly on mobile devices, but gives an understanding of the overall picture of your network data .
It is most useful for detecting suspiciously “fat” data and network spikes. Required.
Bad Network Simulation
Playtests can only reveal obvious network problems. Unfortunately, the real problems begin when your paying user sits in a distant village, he has a Wi-Fi router and a three-meter antenna on the house through which the Internet goes to this router, and a cell phone tower is three kilometers away. With packages in this configuration , anything can happen , despite the fact that the ping will be quite adequate.
UE4 out of the box can simulate various network conditions, such as ping delay, packet loss, or the wrong order. Read more about it here: Finding Network-based Exploits
The epic article provides an example of configuring the network by specifying parameters in ini, which is not very convenient for testing. Moreover, for full testing it is more convenient to have several presets and switch between them at runtime, without restarting the editor.
This is done like this: in the UE4 / Engine / Binaries / folder you create a file, for example, network_bad.txt, of such content
Net PktLoss=1 Net PktOrder=0 Net PktDup=0 Net PktLag=120 Net PktLagVariance=0 p.netshowcorrections 1 Now you can call exec network_bad.txt directly in the editor console and apply the described settings. As you already understood, this is just a set of console commands "packed" into a file.
Traffic monitoring
Raise dedicited. You are arranging playtest on it. See traffic on a single port. Estimate how much is the average traffic per entry and exit.
This item is very obvious, but for some reason, many people neglect it.
Afterword
I tried to briefly talk about all the things that I consider to be fundamentally important at a general level when working on multiplayer in the archive. You can talk endlessly about lag compensation, network interpolation / extrapolation, network architecture features, but all this will be based on the same principles and approaches described above. Yes, and deserves a separate article.
Our result on AW: Assault - the ability to play on the 3G network without any problems and significant lags. Even Edge (albeit with a stable connection) can be called sufficient. In my opinion, these are very decent numbers for 16 player multiplayer. In addition to the thickness of the channel, we are also not very critical to ping, unlike many other games.
If you have something to add, refute or discuss - welcome to the comments! :)
')
Source: https://habr.com/ru/post/352634/
All Articles