True implementation of a neural network from scratch. Part 2. Recognition of numbers

Dispute about eternal
I cordially greet all Habravchan! Since the release of the first part of the "True implementation" (I recommend to get acquainted ) a lot of time has passed. There were no intelligible tutorial articles, so I decided to give you the opportunity to learn from A to Z how to write a program for recognizing numbers, due to the fact that my knowledge in this area has increased markedly. Like last time, I warn you that this article is aimed at those who understand the basics of neural networks, but do not understand how to create their “low-level”, true implementation. I invite you under the cat to familiarize yourself with the creation of those who are tired of poor XOR implementations, the general theory, the use of Tensor Flow, and others. Characters: Sharpei, last year's Visual Studio, homemade Data Collection, The embodiment of pure reason and your humble servant ...
DATASET IN HANDLING CONDITIONS
So, the choice of the machine learning task is made: pattern recognition, which will be the figure on the 3 by 5 pixel image. Therefore, the first obvious step is to create a data set even at home. Having played a little with imagination, I drew on paper a training sample of 100 elements and a test sample of 10, and then transferred it to a digital form using Photoshop. The GIF shows all the elements of the training sample in order. It turned out a kind of MNIST on the minimum salary.

Going through the whole mothafvckn training set

Going through the whole mothafvckn test set
MODEL
And now is the time to create "artificial intelligence". By tradition, I show a diagram of a multilayer perceptron with an indication of some of its parameters.
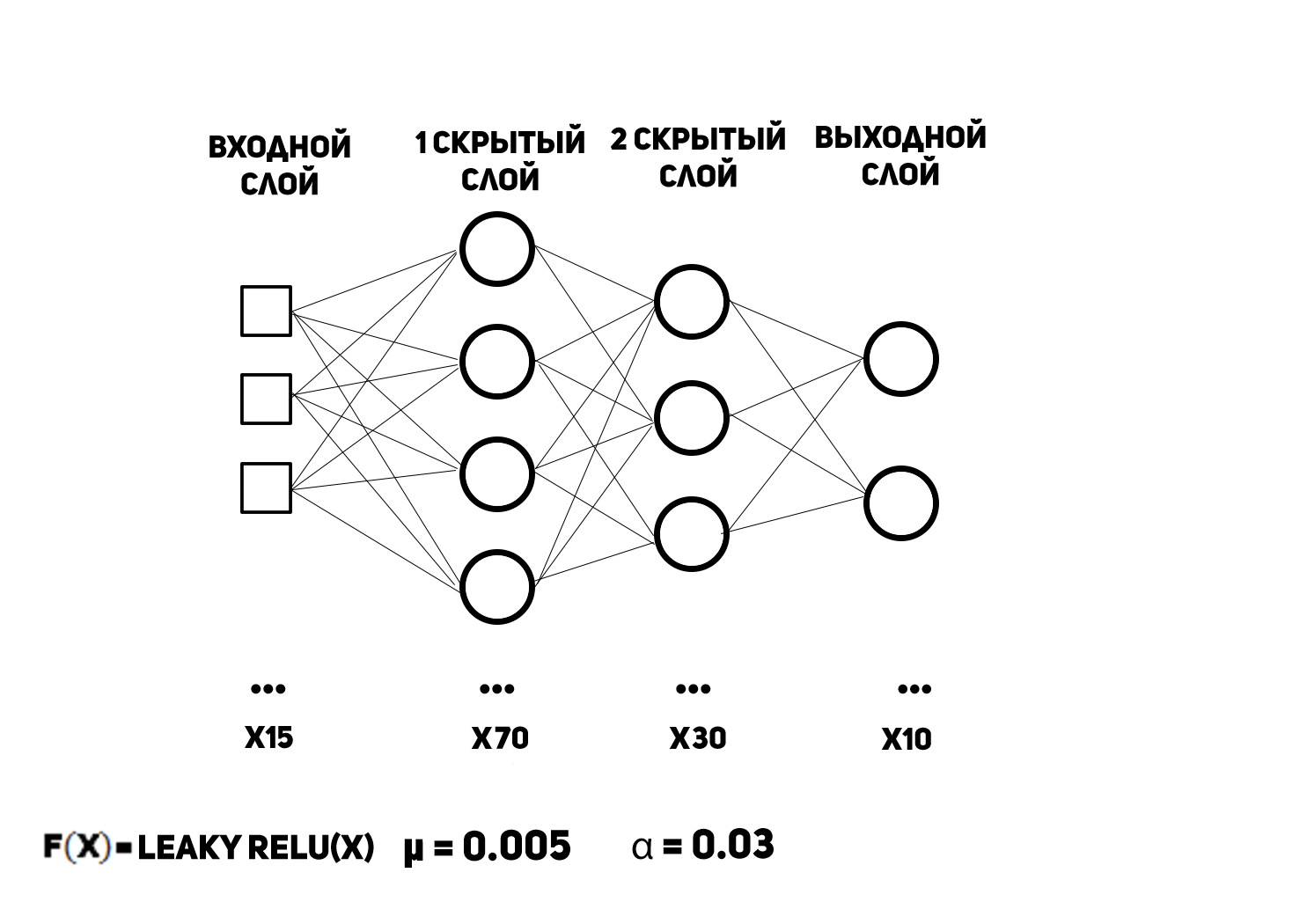
Naturally, there are 15 inputs, since there are as many pixels in the image. The output data vector is a set of probabilities that a digit belongs to a particular class, that is, the number of the neuron with the maximum output (when counting from zero) will be the digit drawn in the picture. For this data format, an activation function, proudly referred to as softmax, is used in the output layer. At the input it takes a vector, at the output it gives the vector, and its derivative is generally a matrix, but this is NOT IMPORTANT. Why? Because there is a pruflink (see page 3), which I recommend to read. The activation function of the hidden layer neurons, as can be seen from the figure above, is a leaky rectified linear unit. I want to talk about it, a little more, since it is almost the best activation function at all. It is given by the following formula:
And it looks like this:

This leads to some thoughts.
That is how Xzibit pimped identity activation function
In fact, it is good for several reasons:
- lack of neuronal overload during training;
- easy computability for the computer;
- maximum similarity of behavior with a biological neuron;
- the fact that the perceptron converges with it faster;
- unlike the ancestor, ReLU does not "kill" neurons during training.
CODE
Here, dear habrudruzya, you and doberpili to dessert. And now we program! More precisely, I will sort out the source code of the perceptron in C # 7 by bone. The namespace for it is called demoapp.Model, and you will find out why the name is such a bit later.
ModelEnums.cs
namespace demoapp.Model { enum MemoryMode// { GET, SET } enum NeuronType// { Hidden, Output } enum NetworkMode// { Train,// Test,// Demo// } } There are several enumerations in this file: the first for accessing XML files for writing / reading weights, the second for determining the type of calculations inside the neuron depending on the type of layer it belongs to, the third for overriding the network.
Neuron.cs
using static System.Math; namespace demoapp.Model { class Neuron { public Neuron(double[] inputs, double[] weights, NeuronType type) { _type = type; _weights = weights; _inputs = inputs; } private NeuronType _type;// private double[] _weights;// private double[] _inputs;// private double _output;// private double _derivative; // private double a = 0.01d; public double[] Weights { get => _weights; set => _weights = value; } public double[] Inputs { get => _inputs; set => _inputs = value; } public double Output { get => _output; } public double Derivative { get => _derivative; } public void Activator(double[] i, double[] w)// { double sum = w[0];// ( ) for (int l = 0; l < i.Length; ++l) sum += i[l] * w[l + 1];// switch (_type) { case NeuronType.Hidden:// _output = LeakyReLU(sum); _derivative = LeakyReLU_Derivativator(sum); break; case NeuronType.Output:// _output = Exp(sum); break; } } private double LeakyReLU(double sum) => (sum >= 0) ? sum : a * sum; private double LeakyReLU_Derivativator(double sum) => (sum >= 0) ? 1 : a; } } The most important class, as it implements the computing unit of the network, due to which all the "magic" occurs. The neuron was created according to the McCulloch-Pitts model, with the inclusion of offsets for affine transformations within the activation function. If the neuron is in the output layer, then an exponential function of the adder is sought as the output. This is done to implement the softmax function, which is already considered in the layer itself.
InputLayer.cs
namespace demoapp.Model { class InputLayer { public InputLayer(NetworkMode nm) { System.Drawing.Bitmap bitmap; switch (nm) { case NetworkMode.Train: bitmap = Properties.Resources.trainset; for (int y = 0; y < bitmap.Height / 5; ++y) for (int x = 0; x < bitmap.Width / 3; ++x) { _trainset[x + y * (bitmap.Width / 3)].Item2 = (byte)y; _trainset[x + y * (bitmap.Width / 3)].Item1 = new double[3 * 5]; for (int m = 0; m < 5; ++m) for (int n = 0; n < 3; ++n) { _trainset[x + y * (bitmap.Width / 3)].Item1[n + 3 * m] = (bitmap.GetPixel(n + 3 * x, m + 5 * y).R + bitmap.GetPixel(n + 3 * x, m + 5 * y).G + bitmap.GetPixel(n + 3 * x, m + 5 * y).B) / (765.0d); } } // - for (int n = Trainset.Length - 1; n >= 1; --n) { int j = random.Next(n + 1); (double[], byte) temp = _trainset[n]; _trainset[n] = _trainset[j]; _trainset[j] = temp; } break; case NetworkMode.Test: bitmap = Properties.Resources.testset; for (int y = 0; y < bitmap.Height / 5; ++y) for (int x = 0; x < bitmap.Width / 3; ++x) { _testset[x + y * (bitmap.Width / 3)] = new double[3 * 5]; for (int m = 0; m < 5; ++m) for (int n = 0; n < 3; ++n) { _trainset[x + y * (bitmap.Width / 3)].Item1[n + 3 * m] = (bitmap.GetPixel(n + 3 * x, m + 5 * y).R + bitmap.GetPixel(n + 3 * x, m + 5 * y).G + bitmap.GetPixel(n + 3 * x, m + 5 * y).B) / (765.0d); } } break; } } private System.Random random = new System.Random(); private (double[], byte)[] _trainset = new(double[], byte)[100];//100 public (double[], byte)[] Trainset { get => _trainset; } private double[][] _testset = new double[10][];//10 public double[][] Testset { get => _testset; } } } This code reads the pixels of images with training and test samples. The mixing of the training set occurs to improve the quality of training, since the examples are initially arranged in order from 0 to 9.
Layer.cs
using System.Xml; namespace demoapp.Model { abstract class Layer// protected {//type protected Layer(int non, int nopn, NeuronType nt, string type) {// WeightInitialize numofneurons = non; numofprevneurons = nopn; Neurons = new Neuron[non]; double[,] Weights = WeightInitialize(MemoryMode.GET, type); lastdeltaweights = Weights; for (int i = 0; i < non; ++i) { double[] temp_weights = new double[nopn + 1]; for (int j = 0; j < nopn + 1; ++j) temp_weights[j] = Weights[i, j]; Neurons[i] = new Neuron(null, temp_weights, nt);// null } } protected int numofneurons;// protected int numofprevneurons;// protected const double learningrate = 0.005d;// protected const double momentum = 0.03d;// protected double[,] lastdeltaweights;// Neuron[] _neurons;// public Neuron[] Neurons { get => _neurons; set => _neurons = value; } public double[] Data// null , {// set//(, , etc.) {// input' , for (int i = 0; i < Neurons.Length; ++i) { Neurons[i].Inputs = value; Neurons[i].Activator(Neurons[i].Inputs, Neurons[i].Weights); } }// } public double[,] WeightInitialize(MemoryMode mm, string type) { double[,] _weights = new double[numofneurons, numofprevneurons + 1]; XmlDocument memory_doc = new XmlDocument(); memory_doc.Load(System.IO.Path.Combine("Resources", $"{type}_memory.xml")); XmlElement memory_el = memory_doc.DocumentElement; switch (mm) { case MemoryMode.GET: for (int l = 0; l < _weights.GetLength(0); ++l) for (int k = 0; k < _weights.GetLength(1); ++k) _weights[l, k] = double.Parse(memory_el.ChildNodes.Item(k + _weights.GetLength(1) * l).InnerText.Replace(',', '.'), System.Globalization.CultureInfo.InvariantCulture);//parsing stuff break; case MemoryMode.SET: for (int l = 0; l < numofneurons; ++l) for (int k = 0; k < numofprevneurons + 1; ++k) memory_el.ChildNodes.Item(k + (numofprevneurons + 1) * l).InnerText = Neurons[l].Weights[k].ToString(); break; } memory_doc.Save(System.IO.Path.Combine("Resources", $"{type}_memory.xml")); return _weights; } abstract public void Recognize(Network net, Layer nextLayer);// abstract public double[] BackwardPass(double[] stuff);// } } This class is engaged in the initialization of network layers. Since the writing of the previous article has not changed.
HiddenLayer.cs
namespace demoapp.Model { class HiddenLayer : Layer { public HiddenLayer(int non, int nopn, NeuronType nt, string type) : base(non, nopn, nt, type) { } public override void Recognize(Network net, Layer nextLayer) { double[] hidden_out = new double[Neurons.Length]; for (int i = 0; i < Neurons.Length; ++i) hidden_out[i] = Neurons[i].Output; nextLayer.Data = hidden_out; } public override double[] BackwardPass(double[] gr_sums) { double[] gr_sum = new double[numofprevneurons]; for (int j = 0; j < gr_sum.Length; ++j) { double sum = 0; for (int k = 0; k < Neurons.Length; ++k) sum += Neurons[k].Weights[j] * Neurons[k].Derivative * gr_sums[k];// gr_sum[j] = sum; } for (int i = 0; i < numofneurons; ++i) for (int n = 0; n < numofprevneurons + 1; ++n) { double deltaw = (n == 0) ? (momentum * lastdeltaweights[i, 0] + learningrate * Neurons[i].Derivative * gr_sums[i]) : (momentum * lastdeltaweights[i, n] + learningrate * Neurons[i].Inputs[n - 1] * Neurons[i].Derivative * gr_sums[i]); lastdeltaweights[i, n] = deltaw; Neurons[i].Weights[n] += deltaw;// } return gr_sum; } } } Regarding the previous project, the innovation is the inclusion of the moment of inertia in the correction of weights. Also, due to the difference in unit sizes of the arrays of the inputs and weights of the neuron, caused by the appearance of offsets, the separation of the synapse update and offset through the ternary operator is written.
OutputLayer.cs
namespace demoapp.Model { class OutputLayer : Layer { public OutputLayer(int non, int nopn, NeuronType nt, string type) : base(non, nopn, nt, type) { } public override void Recognize(Network net, Layer nextLayer) { double e_sum = 0; for (int i = 0; i < Neurons.Length; ++i) e_sum += Neurons[i].Output; for (int i = 0; i < Neurons.Length; ++i) net.fact[i] = Neurons[i].Output / e_sum; } public override double[] BackwardPass(double[] errors) { double[] gr_sum = new double[numofprevneurons + 1]; for (int j = 0; j < gr_sum.Length; ++j)// { double sum = 0; for (int k = 0; k < Neurons.Length; ++k) sum += Neurons[k].Weights[j] * errors[k]; gr_sum[j] = sum; } for (int i = 0; i < numofneurons; ++i) for (int n = 0; n < numofprevneurons + 1; ++n) { double deltaw = (n == 0) ? (momentum * lastdeltaweights[i, 0] + learningrate * errors[i]) : (momentum * lastdeltaweights[i, n] + learningrate * Neurons[i].Inputs[n - 1] * errors[i]); lastdeltaweights[i, n] = deltaw; Neurons[i].Weights[n] += deltaw;// } return gr_sum; } } } From the listing it is clear that softmax is considered in the Recognize method, and quite elegantly due to the fact that the values of the exponential functions were already counted in neurons. You can also see the feature of calculating the gradient of neurons, which lies in its simplicity, since it is equal to the difference between the desired response and the actual one. This is caused by the use of softmax as an activation function of the neurons of the output layer.
Network.cs
namespace demoapp.Model { class Network { public Network(NetworkMode nm) => input_layer = new InputLayer(nm); // private InputLayer input_layer = null; public HiddenLayer hidden_layer1 = new HiddenLayer(70, 15, NeuronType.Hidden, nameof(hidden_layer1)); public HiddenLayer hidden_layer2 = new HiddenLayer(30, 70, NeuronType.Hidden, nameof(hidden_layer2)); public OutputLayer output_layer = new OutputLayer(10, 30, NeuronType.Output, nameof(output_layer)); // public double[] fact = new double[10]; // public void Train(Network net)//backpropagation method { int epoches = 1200; for (int k = 0; k < epoches; ++k) { for (int i = 0; i < net.input_layer.Trainset.Length; ++i) { // ForwardPass(net, net.input_layer.Trainset[i].Item1); // double[] errors = new double[net.fact.Length]; for (int x = 0; x < errors.Length; ++x) { errors[x] = (x == net.input_layer.Trainset[i].Item2) ? -(net.fact[x] - 1.0d) : -net.fact[x]; } // double[] temp_gsums1 = net.output_layer.BackwardPass(errors); double[] temp_gsums2 = net.hidden_layer2.BackwardPass(temp_gsums1); net.hidden_layer1.BackwardPass(temp_gsums2); } } // "" net.hidden_layer1.WeightInitialize(MemoryMode.SET, nameof(hidden_layer1)); net.hidden_layer2.WeightInitialize(MemoryMode.SET, nameof(hidden_layer2)); net.output_layer.WeightInitialize(MemoryMode.SET, nameof(output_layer)); } // public void Test(Network net) { for (int i = 0; i < net.input_layer.Testset.Length; ++i) ForwardPass(net, net.input_layer.Testset[i]); } public void ForwardPass(Network net, double[] netInput) { net.hidden_layer1.Data = netInput; net.hidden_layer1.Recognize(null, net.hidden_layer2); net.hidden_layer2.Recognize(null, net.output_layer); net.output_layer.Recognize(net, null); } } } The class is the "constructor" of the network, because it gathers all the layers together and is engaged in its training and testing. At this time, learning stops at the achievement of the final era. By the way, the input of the network constructor is its mode of operation in order to determine whether to initialize the input layer or not, since initialization is not required for the demonstration mode of operation.
Putting it all together
Initially, I coached the network in a console application for debugging some of its parameters, then to demonstrate the operation I threw in a simple MVP WinForms application with the ability to draw my figure, where I used the weights written in XML. All the perceptron code for beauty is divided according to the principle "one file == one class" and placed in the Model folder, hence the name namespace'a - demoapp.Model. As a result, I received such nyashnost:
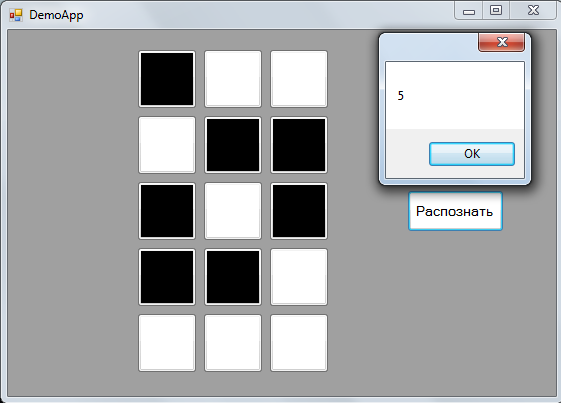
The MessageBox displays the sequence number of the neuron of the output layer with the maximum output value by the next line using the LINQ methods in the application's View component:
public double[] NetOutput { set => MessageBox.Show(value.ToList().IndexOf(value.Max()).ToString()); } Total
Today, thanks to me, you have dealt with another "Hello World" from the world of machine learning at the lowest level of implementation. It was an interesting experience for me and, I hope, for you. In the next article for this kid I will screw OpenCL so that everything will fly at all! So thank you for your attention! Wait for the next article from the educational cycle "True implementation of a neural network from scratch."
PS
For those who want more communication with this code, leave a link to Github .
Pps
I declare a contest for the reader's attention. Anyone who writes in the comments what critical error I made while programming the neural network from the previous article (although it worked, but it was pure luck) will get a nice bun.
')
Source: https://habr.com/ru/post/352632/
All Articles