"Computer, how is my build doing?" And other magic spells
Baruh Sadogursky tells how using the voice command service Alexa you can add a voice interface to completely unexpected things, such as IntelliJ IDEA and Jenkins, as well as, leaning back in your chair with a glass of your favorite drink, manage anything you want.
The article is based on the speech of Baruch at the JPoint 2017 conference in Moscow.
Baruch deals with Developer Relations at JFrog. In addition, he is an enthusiast of Groovy, DevOps, IOT and Home Automation.
In this article I will talk to Alexa. This is a product of Amazon - a voice assistant, the same as Siri, Cortana (God forbid, if anyone could not remove), Google Home, etc. Alexa is today the market leader and we will talk why, although the reason is obvious.
')
There are three kinds of Alexa-based devices.

I will be talking to Amazon Tap. Previously, she did not know how to respond to the name, so you had to press a button, hence the name Tap. Now she is already responding to the name, but the name remains. Full-fledged Alexa is big, with a good speaker. There is also a "trinket" with a weak speaker, which is designed to connect to other receivers, speakers, etc. All of them are quite accessible, cost 170, 130 and 50 dollars. I have a total of nine at home. Why do I need all this, we'll talk now.
I mentioned that Alexa is now the undisputed market leader. The leader is thanks to the open API for writing scripts to Alexa Skills. Just recently it was said that the number of skills in the main base reached 10 thousand. Most of them are stupid, but thanks to many useful skills there is nothing like Alexa in terms of usefulness or popularity. How they clocked up 10 thousand, quite understandable. There is a pattern by which you can make a skill by changing a couple of lines. Then publish it, get a T-shirt - and now they have 10 thousand. But today we will learn to write some more interesting skills - and you will understand that this is quite simple.
Why am I interested in this and how do I use the “Alex” army that is in my house?

I get up and the first thing I ask her to turn off the alarm ("Alexa, turn off the alarm"). Then somehow I get to the kitchen and ask me to turn on the light (“Alexa, turn on morning lights”). I greet her (“Alexa, good morning”). By the way, on “Good morning” she answers interesting things, for example, reports that a large snake was found in Malaysia last year. Useful information in the morning, under the coffee.
Then I ask about the news (“Alexa, what's my news flash?”), And she reads me news from various resources. After that I ask what's on my calendar? (“Alexa, what's on my agenda?”). Because of this, I know what my day looks like. And then I ask how I am going to work, whether there are traffic jams on the way, and so on (“Alexa, how's my commute?”). This is a home-oriented use, there are no custom skills at all, it’s all built-in.
But there are still many cool applications.

But you came here, of course, not to listen to the consumer talk about Alex - you came to hear about the voice interfaces of the future. Today it is HYIP, and, in general, quite unexpected. But this HYIP is very practical, because voice interfaces are what we are waiting for. We grew up waiting for voice interfaces to work. And now it is happening before our eyes.
Analysts say that over the past 30 months, there has been progress in the field of voice interfaces, which has not been for the past 30 years. The bottom line is that the voice interface at some point replaced the graphic one. This is logical, because the graphical interface is a crutch that existed only because the voice was insufficiently developed.
Of course, there are things that are better to show, but, nevertheless, a lot of what we do from the screen, it would be possible, and it would be necessary, to do it with a voice.
This API, which lies on top of voice recognition and a certain Artificial Intelligence, which Alex has, is what guarantees explosive development in this industry and the opportunity for many people to write a lot of useful skills.
Today we will see two skills. The first one opens the application, my IntelliJ IDEA, and it’s certainly cool, but not very useful (since opening the application with a voice and then writing code with pens doesn’t make much sense). The second will be about Jenkins, and it should be much more useful.
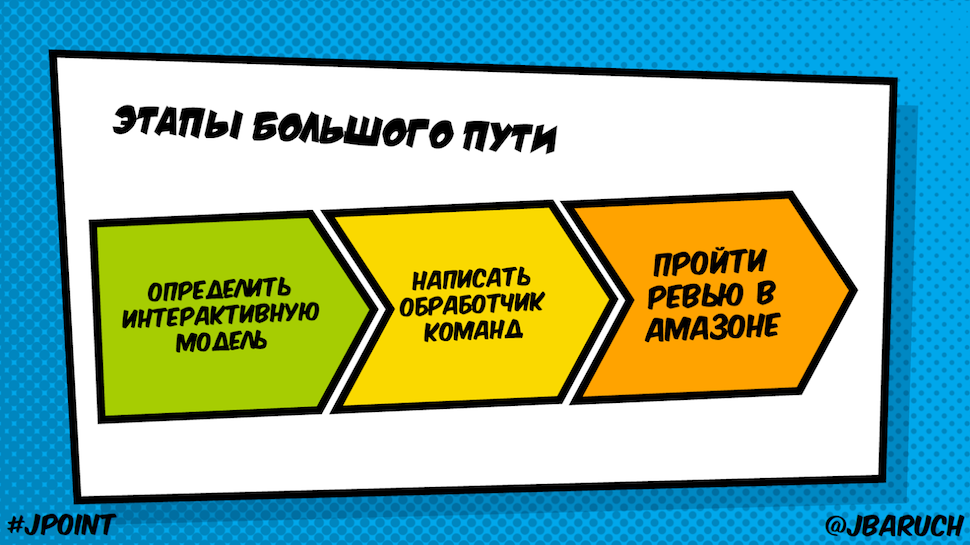
Writing a skill is a simple thing and consists of three stages:
It is based on a very simple idea:

We can extract variables from the text and pass to the handler (for example, I ask to open IDEA, which is a slot, but I could also ask to open Rider or Sea Lion).
I call JSON commands, and then I give the text how these commands can sound. And here comes the magic, because the same can be said in different ways. And this Artificial Intelligence (Voice Recognition, which is provided by Alexa) is able to select not only the command that I have registered, but also all similar ones. In addition, there is a set of built-in commands, such as Stop, Start, Help, Yes, No, and so on, for which no examples should be written.
Here is JSON IntentSchema, which states what examples I want. This is our example that opens tools from JetBrains Toolbox.
You see that I have an intent, which is called OpenIntent, and there is one slot Tool. Its parameter is some list of tools. In addition, there is still a help.
Here are the types of slots:
Be sure to remember that they are not enum. That is, this list is only a priority. If Alexa learns some other word, it will be transferred to my skill.
Here is the very List of Tools - the options that I gave her.

Writing here is different from writing products from JetBrains simply because Alexa works with natural words. Accordingly, if I write IntelliJ IDEA in one word, it will not be able to recognize what it is.
Here are examples of how people can apply to request the opening of this tool:
There are other options. When Alexa sees this set, she knows that the synonyms of these words also fall under this intent.
We described the voice interface, and then we have a command handler. It works very simply: Alexa turns the voice we are talking to into a REST request in JSON format.
The request can go either to AWS Lambda Function or to an arbitrary HTTP server. The advantage of Lambda Function is that they do not need an arbitrary HTTP server. We have a platform as a service, where we can write our handler without having to lift any services.
Benefits of AWS Lambda Function:
Java 8 is much more complicated. In Java, we don’t have any top-level functions that we can write and call — all of which should be wrapped in classes. Our friend Sergey Egorov is on a short leg with the guys who are sawing Lambda, and now he is working to make Groovy use in Lambda not like now (when we make a jar file and work with it the same way), but directly through Groovy scripts when you can write scripts with callbacks that will be called.
The class that handles Alexa requests to Java is called Speechlet. When you see speechboxes, you remember applets, midlets, and servlets. And you already know what to expect - a controlled execution cycle, that is, roughly speaking, some kind of interface that we, as developers, need to implement with different phases of our “summer” life, in this case a matchlet.
And you were not mistaken, because here you have the Speechlet interface, where there are four methods that we need to implement:
At the beginning,
In general, it is very similar to any other "years", and now we will see how everything looks in code.
There are two places in Amazon that we need to work with:


We have a user who says: “Alexa, ask Jenkins how's my build?”. It comes to the device, in this case, Amazon Tap. Then everything goes to the same skill that turns a voice into JSON, turns into Lambda Functions and jerks Jenkins API.
Now it's time to look at the code.
( https://github.com/jbaruch/jb-toolbox-alexa-skill/blob/master/src/main/groovy/ru/jug/jpoint2017/alexa/jbtoolboxactivator/JbToolBoxActivatorSpeechlet.groovy )
Here is our match. We derived Help Test, Default Question, and so on. We have an HTTP BUILDER, let me remind you, this is a service that runs to Amazon Lambda. Accordingly, he should jerk something on the Internet. This is actually Groovy, but add a boilerplate, and you’ll get Java.
We configure our HTTP client on the
From
The

And the most interesting is
Accordingly, then we return the answer. The answer can be either
The HELP works as a HELP, STOP and CANCEL does
Everything is extremely simple, I specifically wrote it so simple that you can see how simple it is.
I have nothing
Let's look at another skill. And this time let's go the other way: from the code to the skill and at the end try to start it. Here is Jenkins speechlet - the handler of the skill that drives Jenkins ( https://github.com/jbaruch/jenkins-alexa-skill/blob/master/src/main/groovy/ru/jug/jpoint2017/alexa/jenkins/JenkinsSpeechlet.groovy ).
It all starts out very much the same:
Here we have, respectively, more intents, it makes sense to look at our model - https://github.com/jbaruch/jenkins-alexa-skill/blob/master/src/main/resources/speechAssets/IntentSchema.json
We have
Let's start. Here the intent came to us, and we take data from it by name. If we have been asked for the last build, then we will go to the Jenkins API and take a list of builds with their name and color from there (the color red or blue has passed or has not passed). Take last, a build with such a name, whether it is passed or not.
And then we have that same yes-no. If we answered yes, then we need to check if there was a question, or maybe we just said yes. And if the question was, then again, we will create some post request, this time in our Jenkins API, and fill up the job. And if the job really became red, we say that we have filled up the job, and if not - nothing happened. Well, stop - we say Goodbye and exit.
Such interesting functionality, and a code here on one page. I tried to complicate the code, but there is nothing to complicate, because it's really that simple.
After that we collect all this with graidl, and Gradle is the simplest here. I have a lot of dependencies here: groovy, which I naturally need, plus three dependencies of this API, logger, commons-io, commons-lang. Everything! testCompile - naturally, I have tests for this case. And then I build a ZIP in which in the main directory is my jar. In addition, there is a lib directory with all dependencies. Really easier to go.

Now let's see what we do with this build. We have two places where we really turn. The first is the Alexa Skill Kit, it has all the skills that I wrote. Let's look at Jenkins Skill.

As I said, here we have metadata: the name and invocation name is that very word (Jenkins) when I say: “Alexa, ask Jenkins to do this and that.”
Then you can specify whether I need an audio player (if I, for example, want to stream a sound, for example, play music, play news, and so on)
Next we have our interactive model - the same JSON that describes intents.

There is no slot here, but in JetBrains we would have a custom slot and this slot would have values and examples that work for my intents.

Configuration tab - what I call: Lambda or HTTPS.

Immediately there is the same Account Linking - do we give the opportunity to log in when setting up the skill (and in theory, it would be nice to do this in Jenkins).

And further Permissions for all purchases, but it does not really interest us anymore.

Testing tab - here I can write what it will do if I speak.

Further tab Publishing Information. Skill passes all checks from Amazon. I have to tell them how good it is, how it is tested, and so on.
The second part of working with the skill is my AWS Lambda. There I have nothing but these three skills.
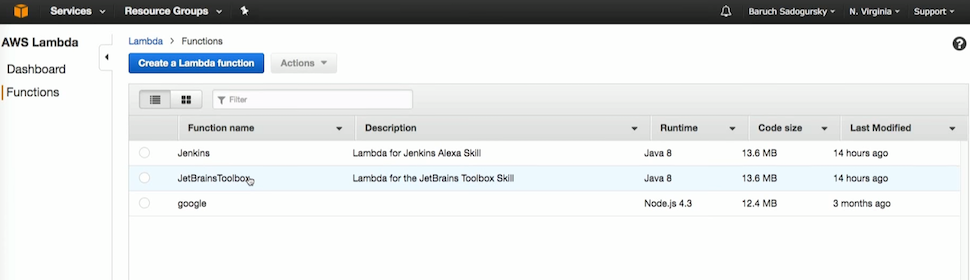
Let's look at Jenkins. Here I poured the very jar that built Gradle. There are also variables (host, password and user).
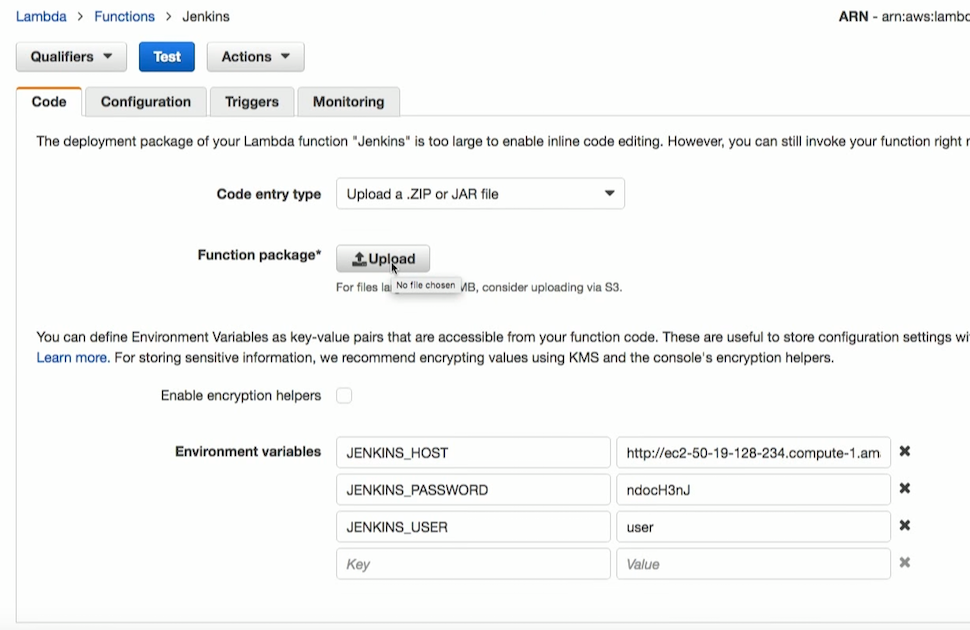
In the configuration I am writing, which one I need is runtime. As I said before, Node, Python, and Java are supported. And recently it became supported by C #. Next is the handler. This is where my match is inside. Role is called lambda_basic_execution. And I have a description. Everything.
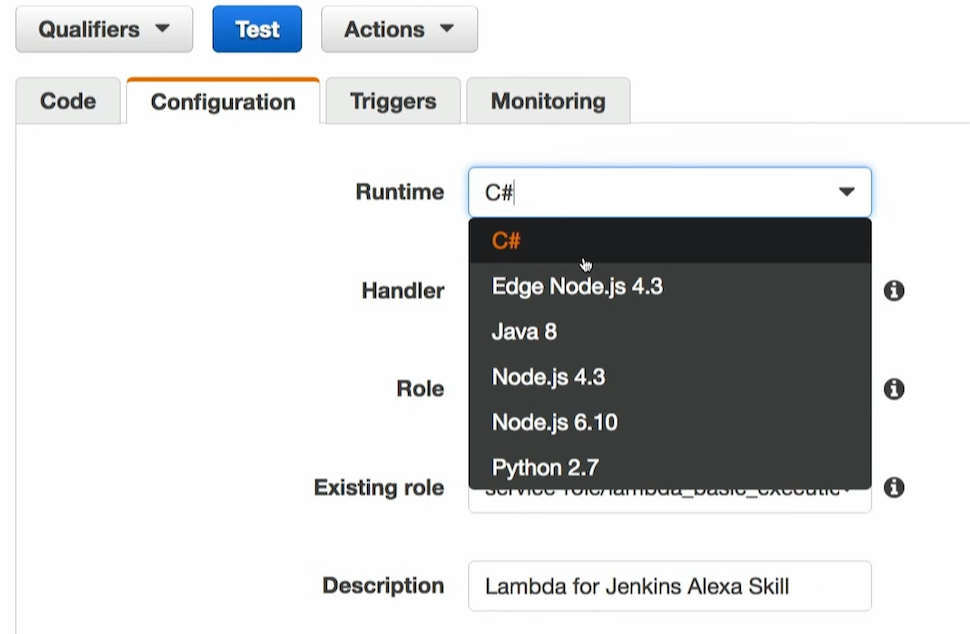
The trigger comes from Alexa. There is a special kind of trigger that is called the Alexa Kit. This means that the call will be from there.

And here, too, you can test, if you know what JSON Alex sends Lambda. And I know what, because when I test it here, I will see this Jenkins. And now let's look at this Jenkins. I sent a request: how is my build.
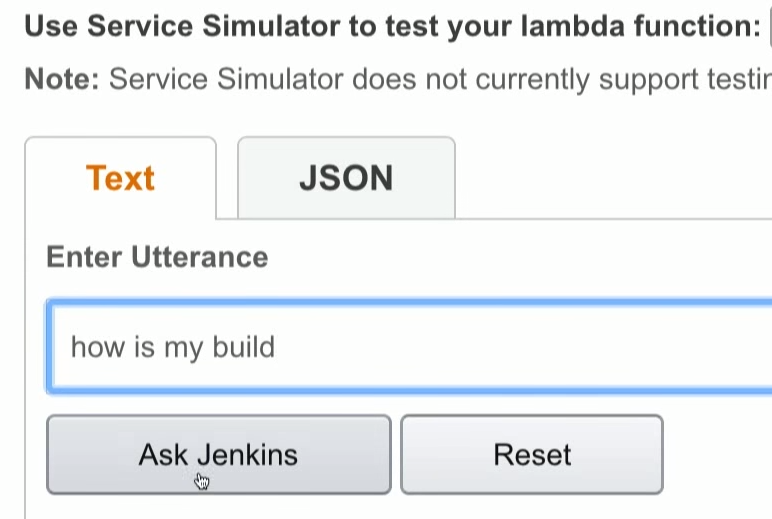
I sent an intent, the intent is called last build, and Alexa realized what I want.

This is all wrapped in JSON, which I can test in Lambda. I can say: I am sending this JSON. And when I say this, I can only test this piece.
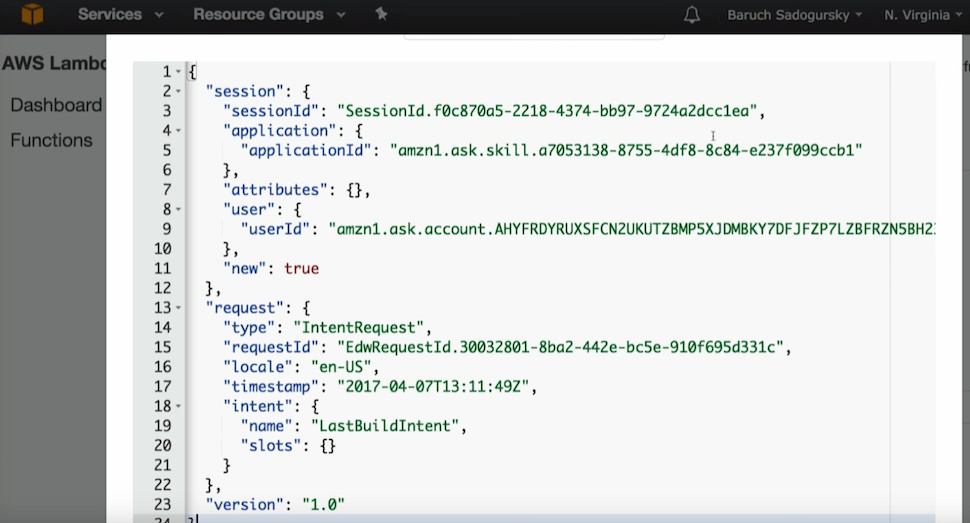
Yes, I have end to end testing with this voice recognition thing (text in JSON, in Lambda and then back) or I can only test this at the Lambda level, if I know the JSON that is needed.
In general, it is time to start everything. We have Jenkins, and I have a build of the previous skill.
Then I have this dialogue with the system:
Baruch: Alexa, open Jenkins
Alexa: With this skill you can control your build server
Baruch: Alexa, ask Jenkins, how is my build?
Alexa: You last build jb-toolbox-alexa-skill is passing. What do you want to do next?
Baruch: What's the code coverage?
Alexa: jb-toolbox-alexa-skill build is 30%. What do you want to do next?
Baruch: Fail the build.
Alexa: I understand you successful build. Are you sure?
Baruch: Yes
Alexa: Successfully changed the build status to failed. Thank you and goodbye.

It is very cool and very simple, even ashamed of such an easy level.
In addition to the voice interface, Alexa has a visual companion. This application, in which in addition to setting up all devices, the Internet and other things, there are also cards. This is such a stream of information that is auxiliary to the voice interface. In general, this is a sensible idea, because not everything can be said with a voice. If, for example, I have now requested
Let's now talk about two kinds of flaws: imaginary and real. The first - imaginary - is associated with speech recognition. The user can speak with an accent or not very clearly pronounce the words. I do not know how they do it, but Alexa perfectly understands even my little son, although my wife and I do not always understand him.
The second perceived flaw is shown in the illustration below.

In fact, this problem is solved very simply with the help of security tools: Alexa will never place an order in the store or open the door until you say a pre-set PIN code.
There is another aspect: "Oh, oh, oh, they constantly listen to us." It's all a long time ago, reverse-engineering, it is perfectly clear to everyone that they are listening. The only thing that they constantly listen to is trigger words. That is when I call her. Sometimes trigger words are pronounced randomly, after that, within ten seconds, what we say is recorded, and the record is sent to the main intent, to the main skill. If there it is not recognized, then thrown into the trash. Therefore, all this paranoia is unjustified.
And now we will talk about the real disadvantages. They can be divided into several categories.
There are drawbacks to the voice user interface. They are related to the fact that some call things the same words. Try asking for Helloween's music and not get music for Halloween. I think that, given the progress, the context should solve this problem, because Alexa should already know that I prefer the group between the music for Halloween and the band Helloween. Everything goes to this, but so far this is not so, especially - if the context is incomprehensible.
And one more problem. It is connected with the lack of support for non-standard names and names. If Alexa does not know a name or a title, then she will not be able to pronounce it.
In addition, Alexa itself, like a consumer device, also has flaws:
The biggest and disgusting flaws come out when trying to write Alexa Skill, for example the one we are doing now. Java API is a nightmare, the voice model must be manually copied to the page, and this is indicated even in the documentation. In addition, there is no bootstrap: neither Maven Archetype, nor Lazybones Template.
There is no local test infrastructure, that is, if I changed the only line in the code, I need to go to the site of the skill and change the pens in the text area json, and then go to Lambda and load the new jar there (well, on Lambda, let's say Rest API, because it still wrote for the developers, there you can make a continuous deployment, everything is fine there). But on the side of the skill kit with any change, I need to go and download it all and test it only on the server. Locally there is no infrastructure, and this, of course, is also a very big minus.
That's all.Skills, which were discussed, can be taken from my Github - jb-toolbox-alexa-skill and jenkins-alexa-skill . I have a big request for you: let's invent and write useful skills, then we will be able to return to this topic at the next conferences.
We hope you find the Baruch experience useful. And if you like to savor all the details of Java development in the same way as we do, you probably will be interested in these reports at our April JPoint 2018 conference :
The article is based on the speech of Baruch at the JPoint 2017 conference in Moscow.
Baruch deals with Developer Relations at JFrog. In addition, he is an enthusiast of Groovy, DevOps, IOT and Home Automation.
What is Alexa and why is it in our lives?
In this article I will talk to Alexa. This is a product of Amazon - a voice assistant, the same as Siri, Cortana (God forbid, if anyone could not remove), Google Home, etc. Alexa is today the market leader and we will talk why, although the reason is obvious.
')
There are three kinds of Alexa-based devices.
I will be talking to Amazon Tap. Previously, she did not know how to respond to the name, so you had to press a button, hence the name Tap. Now she is already responding to the name, but the name remains. Full-fledged Alexa is big, with a good speaker. There is also a "trinket" with a weak speaker, which is designed to connect to other receivers, speakers, etc. All of them are quite accessible, cost 170, 130 and 50 dollars. I have a total of nine at home. Why do I need all this, we'll talk now.
I mentioned that Alexa is now the undisputed market leader. The leader is thanks to the open API for writing scripts to Alexa Skills. Just recently it was said that the number of skills in the main base reached 10 thousand. Most of them are stupid, but thanks to many useful skills there is nothing like Alexa in terms of usefulness or popularity. How they clocked up 10 thousand, quite understandable. There is a pattern by which you can make a skill by changing a couple of lines. Then publish it, get a T-shirt - and now they have 10 thousand. But today we will learn to write some more interesting skills - and you will understand that this is quite simple.
Why am I interested in this and how do I use the “Alex” army that is in my house?
I get up and the first thing I ask her to turn off the alarm ("Alexa, turn off the alarm"). Then somehow I get to the kitchen and ask me to turn on the light (“Alexa, turn on morning lights”). I greet her (“Alexa, good morning”). By the way, on “Good morning” she answers interesting things, for example, reports that a large snake was found in Malaysia last year. Useful information in the morning, under the coffee.
Then I ask about the news (“Alexa, what's my news flash?”), And she reads me news from various resources. After that I ask what's on my calendar? (“Alexa, what's on my agenda?”). Because of this, I know what my day looks like. And then I ask how I am going to work, whether there are traffic jams on the way, and so on (“Alexa, how's my commute?”). This is a home-oriented use, there are no custom skills at all, it’s all built-in.
But there are still many cool applications.
- Smart home is the coolest option. As you have probably seen, I turned on the light through Alex. But it can be not only light: locks, cameras, burglar alarms, all sorts of sensors - everything that connects to a smart home.
- Music. Alexa can play the music I love. This is the same - audiobooks. Adults usually have no time for them, but my son listens to fairy tales through Alex.
- Questions / Answers. That is what is usually searched on Wikipedia.
- News / weather - I have already spoken about this.
- Ordering food is, of course, very important so that you can order pizza, sushi, etc., without getting up from the sofa.
But you came here, of course, not to listen to the consumer talk about Alex - you came to hear about the voice interfaces of the future. Today it is HYIP, and, in general, quite unexpected. But this HYIP is very practical, because voice interfaces are what we are waiting for. We grew up waiting for voice interfaces to work. And now it is happening before our eyes.
Analysts say that over the past 30 months, there has been progress in the field of voice interfaces, which has not been for the past 30 years. The bottom line is that the voice interface at some point replaced the graphic one. This is logical, because the graphical interface is a crutch that existed only because the voice was insufficiently developed.
Of course, there are things that are better to show, but, nevertheless, a lot of what we do from the screen, it would be possible, and it would be necessary, to do it with a voice.
This API, which lies on top of voice recognition and a certain Artificial Intelligence, which Alex has, is what guarantees explosive development in this industry and the opportunity for many people to write a lot of useful skills.
Today we will see two skills. The first one opens the application, my IntelliJ IDEA, and it’s certainly cool, but not very useful (since opening the application with a voice and then writing code with pens doesn’t make much sense). The second will be about Jenkins, and it should be much more useful.
Spelling skill for alexa
Writing a skill is a simple thing and consists of three stages:
- Define an interactive model - the same voice API;
- Write a handler of commands that come to us;
- Review Amazon (we will not consider this stage).
Interactive voice model: what is it, why is it?
It is based on a very simple idea:
We can extract variables from the text and pass to the handler (for example, I ask to open IDEA, which is a slot, but I could also ask to open Rider or Sea Lion).
I call JSON commands, and then I give the text how these commands can sound. And here comes the magic, because the same can be said in different ways. And this Artificial Intelligence (Voice Recognition, which is provided by Alexa) is able to select not only the command that I have registered, but also all similar ones. In addition, there is a set of built-in commands, such as Stop, Start, Help, Yes, No, and so on, for which no examples should be written.
Here is JSON IntentSchema, which states what examples I want. This is our example that opens tools from JetBrains Toolbox.
{ "intents": [ { "intent": "OpenIntent", "slots" : [ { "name" : "Tool", "type" : "LIST_OF_TOOLS" } ] }, { "intent": "AMAZON.HelpIntent" } ] } You see that I have an intent, which is called OpenIntent, and there is one slot Tool. Its parameter is some list of tools. In addition, there is still a help.
Slot types
Here are the types of slots:
- Embedded, such as AMAZON.DATE, DURATION, FOUR_DIGIT_NUMBER, NUMBER, TIME;
- A lot of information that Alexa already knows and around which we can write skills, for example, a list of actors, ratings, a list of cities in Europe and the USA, a list of famous people, movies, drinks, etc. (AMAZON.ACTOR, AGREATERATING, AIRLINE, EUROPE_CITY, US_CITY, PERSON, MOVIE, DRINK). Information about them and all possible options are already stored and stored in Alexa.
- Custom Types.
Be sure to remember that they are not enum. That is, this list is only a priority. If Alexa learns some other word, it will be transferred to my skill.
Here is the very List of Tools - the options that I gave her.
Writing here is different from writing products from JetBrains simply because Alexa works with natural words. Accordingly, if I write IntelliJ IDEA in one word, it will not be able to recognize what it is.
Sample phrases for teams
Here are examples of how people can apply to request the opening of this tool:
OpenIntent open {Tool} OpenIntent start {Tool} OpenIntent startup {Tool} OpenIntent {Tool} There are other options. When Alexa sees this set, she knows that the synonyms of these words also fall under this intent.
Command handler
We described the voice interface, and then we have a command handler. It works very simply: Alexa turns the voice we are talking to into a REST request in JSON format.
The request can go either to AWS Lambda Function or to an arbitrary HTTP server. The advantage of Lambda Function is that they do not need an arbitrary HTTP server. We have a platform as a service, where we can write our handler without having to lift any services.
Benefits of AWS Lambda Function:
- Serverless cumpute server - it works on its own
- No-ops!
- Node.js is the most elegant of implementations. We write Javascript functions, and when we pull this service, they are processed there.
- Python support (we write a script with some functions, and it all works great)
- Java 8.
Java 8 is much more complicated. In Java, we don’t have any top-level functions that we can write and call — all of which should be wrapped in classes. Our friend Sergey Egorov is on a short leg with the guys who are sawing Lambda, and now he is working to make Groovy use in Lambda not like now (when we make a jar file and work with it the same way), but directly through Groovy scripts when you can write scripts with callbacks that will be called.
Speechlet
The class that handles Alexa requests to Java is called Speechlet. When you see speechboxes, you remember applets, midlets, and servlets. And you already know what to expect - a controlled execution cycle, that is, roughly speaking, some kind of interface that we, as developers, need to implement with different phases of our “summer” life, in this case a matchlet.
And you were not mistaken, because here you have the Speechlet interface, where there are four methods that we need to implement:
public interface Speechlet { void onSessionStarted(SessionStartedRequest request, Session session); SpeechletResponse onLaunch(LaunchRequest request, Session session); SpeechletResponse onIntent(IntentRequest request, Session session); void onSessionEnded(SessionEndedRequest request, Session session); } At the beginning,
nSessionStarted is when Alexa comes up and realizes that she has a match. onLaunch is when we call a team with the name of our skill. onIntent - when a person talked to us, and we got what he said in the form of Json and the team he called. onSessionEnded is when we make a regular clone.In general, it is very similar to any other "years", and now we will see how everything looks in code.
Where to write speechlet
There are two places in Amazon that we need to work with:
- Alexa Skill Kit, where we describe a new skill (interactive model, metadata, name, where to go when a request is received).
- Lambda or any other service where we have a speechlet that is a request handler. That is, roughly speaking, we have something like this:
We have a user who says: “Alexa, ask Jenkins how's my build?”. It comes to the device, in this case, Amazon Tap. Then everything goes to the same skill that turns a voice into JSON, turns into Lambda Functions and jerks Jenkins API.
Sample Code: JbToolBoxActivator Speechlet
Now it's time to look at the code.
( https://github.com/jbaruch/jb-toolbox-alexa-skill/blob/master/src/main/groovy/ru/jug/jpoint2017/alexa/jbtoolboxactivator/JbToolBoxActivatorSpeechlet.groovy )
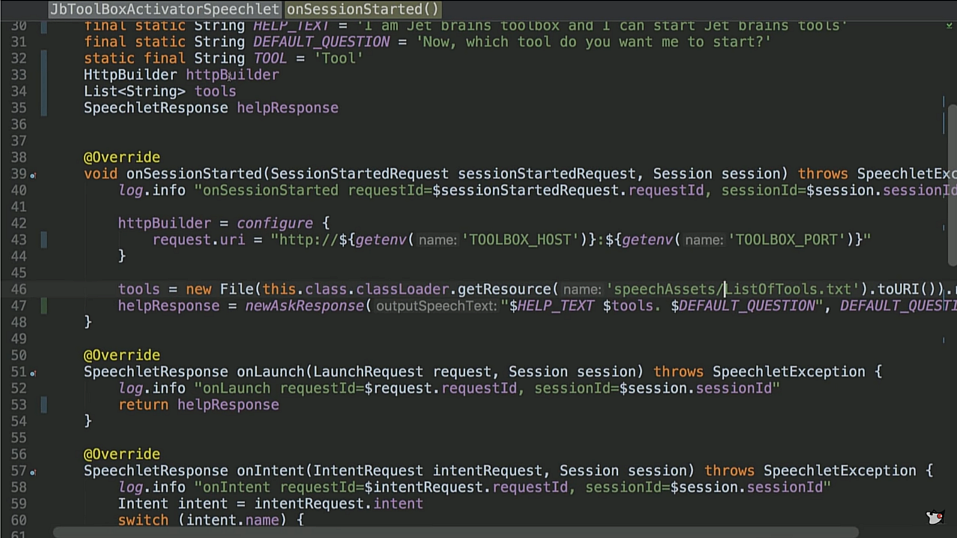
Here is our match. We derived Help Test, Default Question, and so on. We have an HTTP BUILDER, let me remind you, this is a service that runs to Amazon Lambda. Accordingly, he should jerk something on the Internet. This is actually Groovy, but add a boilerplate, and you’ll get Java.
We configure our HTTP client on the
nSessionStarted , saying that we will knock on the toolbox on such a host and such a port. Then we read from the file a list of supported tools that you also saw (List of tools.txt).From
onLaunch we issue HelpResponse . This one you heard about - I can open the same tools.The
onIntent interesting thing happens in onIntent . We make a switch by the name of intent. That is, of all the teams that we had, that came to us. In this case, if you remember, we had two intents. One is open, which is our customer, and the other is help. There may be a stop, cancel and any other.And the most interesting is
openIntent . We take the same slot out of it, tul (we had IDEA and so on), and then we call HTTP-builder to our URI plus this one. That is, we refer to the JetBrains Toolbox API, which understands this format.Accordingly, then we return the answer. The answer can be either
Opening $toolName , or, if the tool is not in the list: Sorry, I can't find a tool named $ toolName in the toolbox. GoodbyeThe HELP works as a HELP, STOP and CANCEL does
Goodbye . If an intent came, which we don't have, we throw invalid invalid.Everything is extremely simple, I specifically wrote it so simple that you can see how simple it is.
I have nothing
onSessionEnded . Here I have a newAskResponse method, which in the purest form of a boilerplate, within ten lines of code, creates three objects: one object, in which in the constructor it is theoretically necessary to translate two others, into which you need to translate some texts. In general, all he does is create a SpeechletResponse object in which we have OutputSpeech text and repromptText. Why does it take ten lines of code? Well, historically, we will talk about this a bit. I hope everything else except this boilerplate is clear and simple.Sample Code: Jenkins Speechlet
Let's look at another skill. And this time let's go the other way: from the code to the skill and at the end try to start it. Here is Jenkins speechlet - the handler of the skill that drives Jenkins ( https://github.com/jbaruch/jenkins-alexa-skill/blob/master/src/main/groovy/ru/jug/jpoint2017/alexa/jenkins/JenkinsSpeechlet.groovy ).
It all starts out very much the same:
nSessionStarted we initialize HTTPBuilder, which will access Jenkins via the Rest API in JENKINS_HOST and log in with a specific username and password. Here it is, of course, through environment variables is not very correct. Alexa has a whole system that allows you to register with username and password in a skill, that is, when we install this skill on our local Alexa, a window opens in which we can log in. But for simplicity, here we take username and password from environment variables.onLaunch we onLaunch the same text: “Greetings, giant muzzles, we manage Jenkins,” and here our interesting onIntent .Here we have, respectively, more intents, it makes sense to look at our model - https://github.com/jbaruch/jenkins-alexa-skill/blob/master/src/main/resources/speechAssets/IntentSchema.json
We have
LastBuild , which obviously will give us information about our latest build, GetCodeCoverage , which will return code coverage to us, and FailBuildIntent , which will fill up the build. In addition, there is a bunch of built-in, such as help, stop, cancel, and even yes, no. Let's see what we actually do with these yes and no.Let's start. Here the intent came to us, and we take data from it by name. If we have been asked for the last build, then we will go to the Jenkins API and take a list of builds with their name and color from there (the color red or blue has passed or has not passed). Take last, a build with such a name, whether it is passed or not.
GetCodeCoverage - again, we turn to the Jenkins API, a plugin called jacoco. In it, as in any good plugin, there is a mass of parameters. We take one - lineCoverage - and get some information.FailBuild is a request to turn an incoming build into a fayle. I would not like to immediately agree on this. Alexa often responds in vain, so there is a chance to randomly bite a build. And we will ask her for confirmation. We will send another request and say: “I want to fill up the build” “Is this really what you meant?”. We put in sessions. This is exactly what is held through different invokations, and we will put some flag in fail requested.And then we have that same yes-no. If we answered yes, then we need to check if there was a question, or maybe we just said yes. And if the question was, then again, we will create some post request, this time in our Jenkins API, and fill up the job. And if the job really became red, we say that we have filled up the job, and if not - nothing happened. Well, stop - we say Goodbye and exit.
Such interesting functionality, and a code here on one page. I tried to complicate the code, but there is nothing to complicate, because it's really that simple.
After that we collect all this with graidl, and Gradle is the simplest here. I have a lot of dependencies here: groovy, which I naturally need, plus three dependencies of this API, logger, commons-io, commons-lang. Everything! testCompile - naturally, I have tests for this case. And then I build a ZIP in which in the main directory is my jar. In addition, there is a lib directory with all dependencies. Really easier to go.
Using the Alexa Skill Kit
Now let's see what we do with this build. We have two places where we really turn. The first is the Alexa Skill Kit, it has all the skills that I wrote. Let's look at Jenkins Skill.
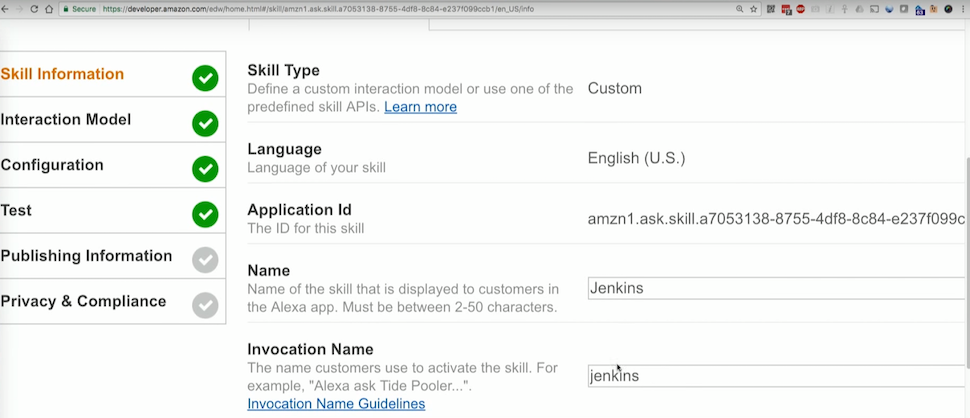
As I said, here we have metadata: the name and invocation name is that very word (Jenkins) when I say: “Alexa, ask Jenkins to do this and that.”
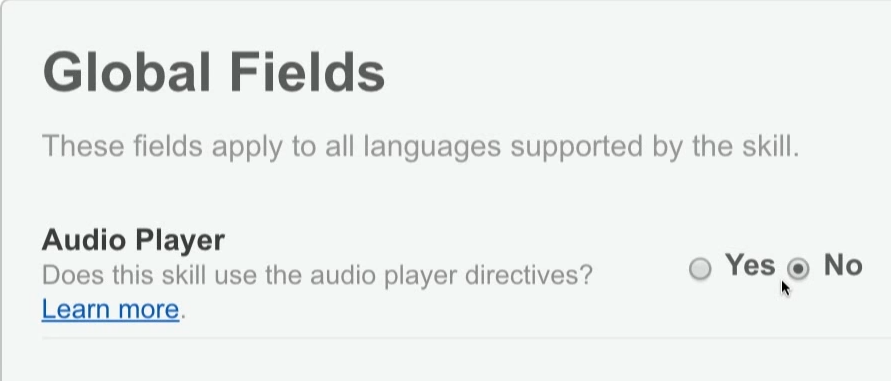
Then you can specify whether I need an audio player (if I, for example, want to stream a sound, for example, play music, play news, and so on)
Next we have our interactive model - the same JSON that describes intents.
There is no slot here, but in JetBrains we would have a custom slot and this slot would have values and examples that work for my intents.
Configuration tab - what I call: Lambda or HTTPS.
Immediately there is the same Account Linking - do we give the opportunity to log in when setting up the skill (and in theory, it would be nice to do this in Jenkins).
And further Permissions for all purchases, but it does not really interest us anymore.
Testing tab - here I can write what it will do if I speak.
Further tab Publishing Information. Skill passes all checks from Amazon. I have to tell them how good it is, how it is tested, and so on.
Using AWS Lambda
The second part of working with the skill is my AWS Lambda. There I have nothing but these three skills.
Let's look at Jenkins. Here I poured the very jar that built Gradle. There are also variables (host, password and user).
In the configuration I am writing, which one I need is runtime. As I said before, Node, Python, and Java are supported. And recently it became supported by C #. Next is the handler. This is where my match is inside. Role is called lambda_basic_execution. And I have a description. Everything.
The trigger comes from Alexa. There is a special kind of trigger that is called the Alexa Kit. This means that the call will be from there.
And here, too, you can test, if you know what JSON Alex sends Lambda. And I know what, because when I test it here, I will see this Jenkins. And now let's look at this Jenkins. I sent a request: how is my build.
I sent an intent, the intent is called last build, and Alexa realized what I want.
This is all wrapped in JSON, which I can test in Lambda. I can say: I am sending this JSON. And when I say this, I can only test this piece.
Yes, I have end to end testing with this voice recognition thing (text in JSON, in Lambda and then back) or I can only test this at the Lambda level, if I know the JSON that is needed.
Demonstration of Jenkins Speechlet
In general, it is time to start everything. We have Jenkins, and I have a build of the previous skill.
Then I have this dialogue with the system:
Baruch: Alexa, open Jenkins
Alexa: With this skill you can control your build server
Baruch: Alexa, ask Jenkins, how is my build?
Alexa: You last build jb-toolbox-alexa-skill is passing. What do you want to do next?
Baruch: What's the code coverage?
Alexa: jb-toolbox-alexa-skill build is 30%. What do you want to do next?
Baruch: Fail the build.
Alexa: I understand you successful build. Are you sure?
Baruch: Yes
Alexa: Successfully changed the build status to failed. Thank you and goodbye.
It is very cool and very simple, even ashamed of such an easy level.
Alexa's visual companion
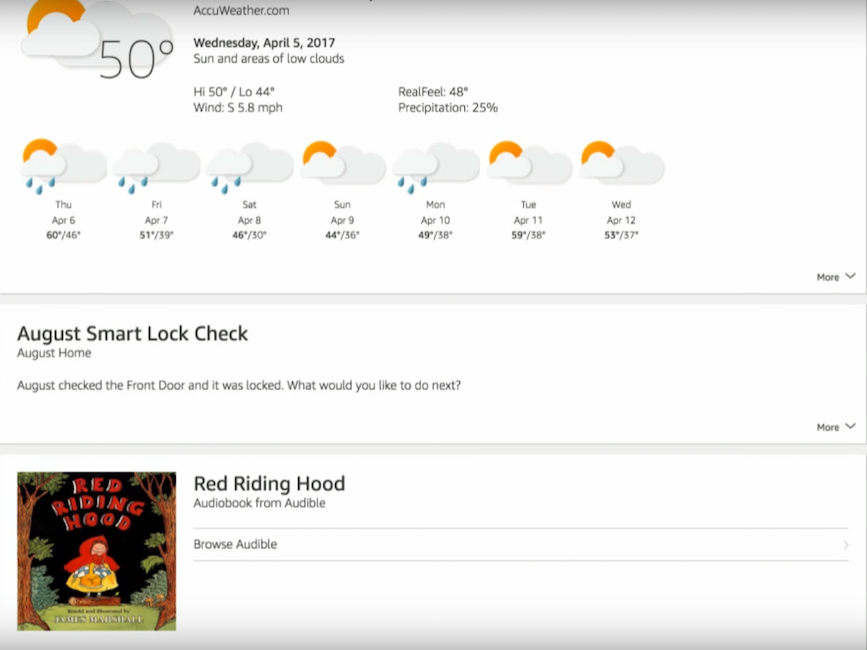
In addition to the voice interface, Alexa has a visual companion. This application, in which in addition to setting up all devices, the Internet and other things, there are also cards. This is such a stream of information that is auxiliary to the voice interface. In general, this is a sensible idea, because not everything can be said with a voice. If, for example, I have now requested
code coverage , and she gave me some kind of metric - in fact, jacoco returns six metrics: coverage for branch execution, methods, code lines, etc. Naturally, it makes sense to display this visually in the application. This can be done in one line - there is a command “send text to the application”. And then you can send a simple text, picture or html, which will be displayed there. For example, if you ask about the weather, the assistant will give a brief answer. In the application, you can see the weather for the whole week. I also checked now that the lock was locked in my house, and that my son at the moment had turned on the fairy tale about Little Red Riding Hood. Here's what it looks like:Alexa’s flaws: imaginary and real
Let's now talk about two kinds of flaws: imaginary and real. The first - imaginary - is associated with speech recognition. The user can speak with an accent or not very clearly pronounce the words. I do not know how they do it, but Alexa perfectly understands even my little son, although my wife and I do not always understand him.
The second perceived flaw is shown in the illustration below.
In fact, this problem is solved very simply with the help of security tools: Alexa will never place an order in the store or open the door until you say a pre-set PIN code.
There is another aspect: "Oh, oh, oh, they constantly listen to us." It's all a long time ago, reverse-engineering, it is perfectly clear to everyone that they are listening. The only thing that they constantly listen to is trigger words. That is when I call her. Sometimes trigger words are pronounced randomly, after that, within ten seconds, what we say is recorded, and the record is sent to the main intent, to the main skill. If there it is not recognized, then thrown into the trash. Therefore, all this paranoia is unjustified.
And now we will talk about the real disadvantages. They can be divided into several categories.
There are drawbacks to the voice user interface. They are related to the fact that some call things the same words. Try asking for Helloween's music and not get music for Halloween. I think that, given the progress, the context should solve this problem, because Alexa should already know that I prefer the group between the music for Halloween and the band Helloween. Everything goes to this, but so far this is not so, especially - if the context is incomprehensible.
And one more problem. It is connected with the lack of support for non-standard names and names. If Alexa does not know a name or a title, then she will not be able to pronounce it.
In addition, Alexa itself, like a consumer device, also has flaws:
- Does not understand multiple commands. I can build an interactive model, like we did with Jenkins, when I didn’t say her name each time to transfer the next command. But, for example, at the moment it cannot execute the command “Alexa, turn on TV and set living room lights to 20%”. And if there are many teams and you use them all the time, it will annoy you.
- Does not work in a cluster. Despite the fact that I have seven such devices at home, each of them considers himself the only one. And therefore if I stand in a place where there are three of them, then all three answer me. In addition, I cannot use one to turn on the music of another, because they do not know that there are more of them than one. This problem is known, they are working on it and, I hope, it will be solved soon.
- Do not know where she is and where I am. Because of this, Alexa cannot react to the “Turn on the lights” command. I have to say “Turn on the lights in the bedroom” and this is stupid.
- The application itself is made on html5, it is slow, crooked, but it is also being repaired.
- Understands only three languages: British English, American English and German. Accordingly, in Russian it has not yet been taught.
The biggest and disgusting flaws come out when trying to write Alexa Skill, for example the one we are doing now. Java API is a nightmare, the voice model must be manually copied to the page, and this is indicated even in the documentation. In addition, there is no bootstrap: neither Maven Archetype, nor Lazybones Template.
There is no local test infrastructure, that is, if I changed the only line in the code, I need to go to the site of the skill and change the pens in the text area json, and then go to Lambda and load the new jar there (well, on Lambda, let's say Rest API, because it still wrote for the developers, there you can make a continuous deployment, everything is fine there). But on the side of the skill kit with any change, I need to go and download it all and test it only on the server. Locally there is no infrastructure, and this, of course, is also a very big minus.
Conclusion
That's all.Skills, which were discussed, can be taken from my Github - jb-toolbox-alexa-skill and jenkins-alexa-skill . I have a big request for you: let's invent and write useful skills, then we will be able to return to this topic at the next conferences.
So that you do not miss a single detail, under the spoiler, we left for you answers to questions from the audience.
. , - (, )?
- , Alexa , (, , ).
, . Alexa?
Alexa - , . -. voice recognition, , .
Alexa Google Home?
Google Home Alexa, . – , Google Home . , . Google Home – . Alexa , .
Alexa. ?
— . , . , , – .
. , - (, )?
- , Alexa , (, , ).
, . Alexa?
Alexa - , . -. voice recognition, , .
Alexa Google Home?
Google Home Alexa, . – , Google Home . , . Google Home – . Alexa , .
Alexa. ?
— . , . , , – .
We hope you find the Baruch experience useful. And if you like to savor all the details of Java development in the same way as we do, you probably will be interested in these reports at our April JPoint 2018 conference :
- Program analysis: how to understand that you are a good programmer (Alexey Kudryavtsev, JetBrains)
- The adventures of Senor Holmes and Junior Watson in the software development world (Baruch Sadogursky, JFrog and Evgeniy Borisov, Naya Technologies)
- Extreme scaling with Alibaba JDK (Sanhong Li, Alibaba)
Source: https://habr.com/ru/post/352372/
All Articles