Introducing the cloud: how static traffic distribution methods work
The load distribution in the cloud IaaS provider helps to efficiently use the resources of virtual machines. There are many methods of load balancing, but in today's article we will focus on one of the most popular static methods: the round-robin, CMA and the threshold algorithm. Under the cut, let's talk about how they are arranged, what their characteristic features are and where they are used.

/ Flickr / woodleywonderworks / CC
Static methods of load balancing imply that the distribution of traffic does not take into account the state of individual nodes. Information about their parameters is “prescribed” in advance. And it turns out that there is a " binding " to a specific server.
')
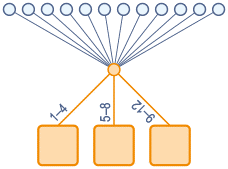
Static distribution - binding to one machine
The choice of server can be due to various factors, for example, the geographical location of the client, and can be chosen randomly.
This algorithm distributes the load evenly across all nodes. In this case, the tasks do not have priorities: the first node is selected randomly, and the rest - further in order. When the number of servers ends, the queue returns to the first one.
One of the implementations of this algorithm is the round-robin DNS . In this case, the DNS responds to requests not with a single IP address, but with a list of several addresses. When a user requests a name resolution for a site, the DNS server assigns a new connection to the first server in the list. This constantly redistributes the load to the server group.
Today, this approach is used to allocate resources both within the data center and between individual data centers. Round-robin is usually implemented using reverse proxies, haproxy, apache and nginx. The mediation application accepts all incoming messages from external clients, maintains a list of servers and monitors the broadcast of requests.
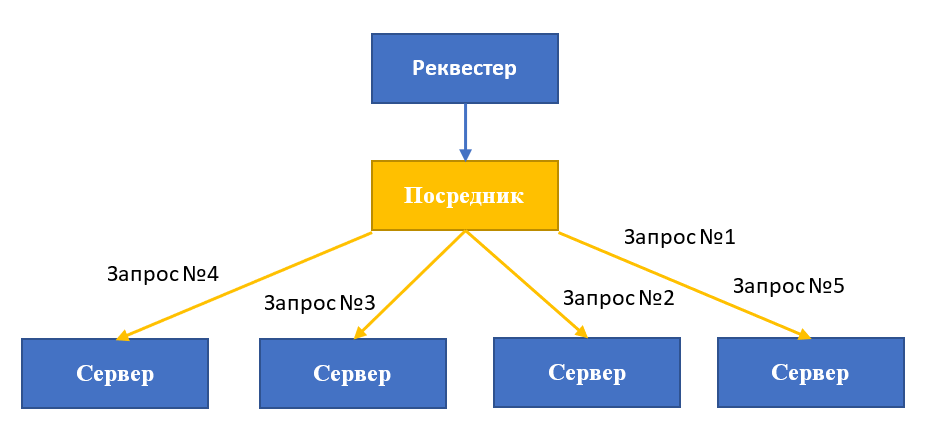
Imagine that we have two environments deployed with highly accessible application servers Tomcat 7 and nginx balancers. DNS servers “bind” several IP addresses to the domain name by adding external balancer addresses to the A resource record . Next, the DNS server sends a list of IP addresses of available servers, and the client “tries” them in order and establishes a connection with the first responder.
Note that this approach is not without flaws. For example, DNS does not check servers for errors and does not exclude identifiers of disconnected VMs from the list of IP addresses. Therefore, if one of the servers is unavailable, there may be delays in processing requests (about 10–30 seconds).
Another problem - you need to adjust the lifetime of the cache tables with addresses. If the value is too large, clients will not know about changes in the server group, and if it is too small, the load on the DNS server will increase significantly.
In this algorithm, the central processor (CM) determines the host for the new process by selecting the least loaded server. The central processor makes a choice based on the information that the servers send to it each time the number of processed tasks changes (for example, when a child process is created or terminated).
A similar approach is used by IBM in the Guardium solution. The application collects and constantly updates information about all managed modules and creates on its basis the so-called load map. With its help, data flow management is performed. The balancer accepts HTTPS requests from S-TAP - a traffic monitoring tool - listening on port 8443 and using Transport Layer Security (TLS).
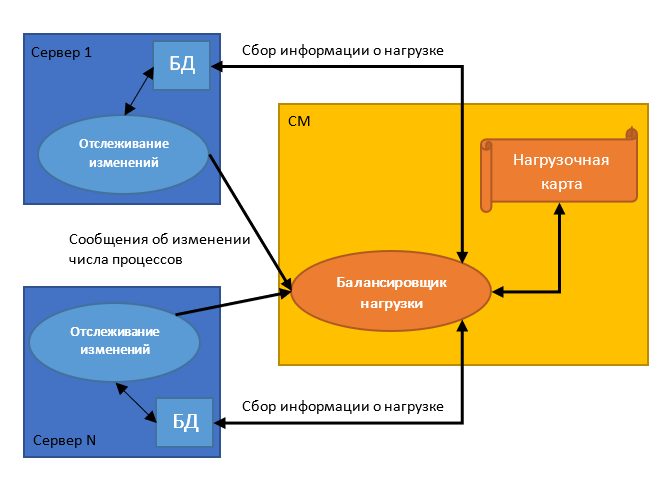
Central Manager Algorithm allows you to evenly distribute the load, since the decision to assign a process to a server is made at the time of its creation. However, the approach has one serious drawback - this is a large number of interprocess interactions, which leads to the emergence of a “bottleneck”. In this case, the central processor itself is a single point of failure.
Processes are assigned to hosts immediately upon their creation. In this case, the server can be in one of the three states defined by two threshold values - t_upper and t_under.
If the system is in a balanced state, then no further action is taken. If there is an imbalance, the system takes one of two actions: it sends a request to increase the load or, conversely, to reduce it.
In the first case, the central server evaluates which tasks that have not yet begun to be performed by other hosts can be delegated to the node. Indian scientists from the University of Guru Gobind Singh Indraprasta in their study, which they devoted to evaluating the performance of the threshold-algorithm in heterogeneous systems, give an example of the function that nodes can use to send a request for increasing load:
In the second case, the central server can take away from the node those tasks that it has not yet begun to perform, and if possible transfer them to another server. To start the migration process, scientists used the following function:
When load redistribution is performed , servers send a message about changing their process counter to other hosts so that they update their system state information. The advantage of this approach is that such messages are rarely exchanged, since with a sufficient amount of server resources, it simply starts a new process in itself - this improves performance.
/ Flickr / woodleywonderworks / CC
Static methods of load balancing imply that the distribution of traffic does not take into account the state of individual nodes. Information about their parameters is “prescribed” in advance. And it turns out that there is a " binding " to a specific server.
')
Static distribution - binding to one machine
The choice of server can be due to various factors, for example, the geographical location of the client, and can be chosen randomly.
Round-robin
This algorithm distributes the load evenly across all nodes. In this case, the tasks do not have priorities: the first node is selected randomly, and the rest - further in order. When the number of servers ends, the queue returns to the first one.
One of the implementations of this algorithm is the round-robin DNS . In this case, the DNS responds to requests not with a single IP address, but with a list of several addresses. When a user requests a name resolution for a site, the DNS server assigns a new connection to the first server in the list. This constantly redistributes the load to the server group.
Today, this approach is used to allocate resources both within the data center and between individual data centers. Round-robin is usually implemented using reverse proxies, haproxy, apache and nginx. The mediation application accepts all incoming messages from external clients, maintains a list of servers and monitors the broadcast of requests.
Imagine that we have two environments deployed with highly accessible application servers Tomcat 7 and nginx balancers. DNS servers “bind” several IP addresses to the domain name by adding external balancer addresses to the A resource record . Next, the DNS server sends a list of IP addresses of available servers, and the client “tries” them in order and establishes a connection with the first responder.
Note that this approach is not without flaws. For example, DNS does not check servers for errors and does not exclude identifiers of disconnected VMs from the list of IP addresses. Therefore, if one of the servers is unavailable, there may be delays in processing requests (about 10–30 seconds).
Another problem - you need to adjust the lifetime of the cache tables with addresses. If the value is too large, clients will not know about changes in the server group, and if it is too small, the load on the DNS server will increase significantly.
Central Manager Algorithm
In this algorithm, the central processor (CM) determines the host for the new process by selecting the least loaded server. The central processor makes a choice based on the information that the servers send to it each time the number of processed tasks changes (for example, when a child process is created or terminated).
A similar approach is used by IBM in the Guardium solution. The application collects and constantly updates information about all managed modules and creates on its basis the so-called load map. With its help, data flow management is performed. The balancer accepts HTTPS requests from S-TAP - a traffic monitoring tool - listening on port 8443 and using Transport Layer Security (TLS).
Central Manager Algorithm allows you to evenly distribute the load, since the decision to assign a process to a server is made at the time of its creation. However, the approach has one serious drawback - this is a large number of interprocess interactions, which leads to the emergence of a “bottleneck”. In this case, the central processor itself is a single point of failure.
Threshold algorithm
Processes are assigned to hosts immediately upon their creation. In this case, the server can be in one of the three states defined by two threshold values - t_upper and t_under.
- Not loaded: load <t_under
- Balanced: t_under ≤ load ≤ t_upper
- Overloaded: load> t_upper
If the system is in a balanced state, then no further action is taken. If there is an imbalance, the system takes one of two actions: it sends a request to increase the load or, conversely, to reduce it.
In the first case, the central server evaluates which tasks that have not yet begun to be performed by other hosts can be delegated to the node. Indian scientists from the University of Guru Gobind Singh Indraprasta in their study, which they devoted to evaluating the performance of the threshold-algorithm in heterogeneous systems, give an example of the function that nodes can use to send a request for increasing load:
UnderLoaded() { // validating request made by node int status = Load_Balancing_Request(Ni); if (status = = 0 ) { // checking for non executable jobs from load matrix int job_status = Load_Matrix_Nxj (No); if (job_status = =1) { // checking suitable node from capability matrix int node_status=Check_CM(); if (node_status = = 1) { // calling load balancer for balancing load Load_Balancer() } } } } In the second case, the central server can take away from the node those tasks that it has not yet begun to perform, and if possible transfer them to another server. To start the migration process, scientists used the following function:
OverLoaded() { // validating request made by node int status = Load_Balancing_Request(No); if (status = = 1) { // checking load matrix for non executing jobs int job_status = Load_Matrix_Nxj (No); if (job_status = =1) int node_status=Check_CM(); if (node_status = = 1) { // calling load balancer to balance load Load_Balancer() } } } } When load redistribution is performed , servers send a message about changing their process counter to other hosts so that they update their system state information. The advantage of this approach is that such messages are rarely exchanged, since with a sufficient amount of server resources, it simply starts a new process in itself - this improves performance.
More materials from the corporate blog 1cloud:
Source: https://habr.com/ru/post/352350/
All Articles