Neural networks, genetic algorithms, etc. ... Myths and reality. Signs
This work is a continuation of everything said earlier in the article “ Neural networks, genetic algorithms, etc. ... Myths and reality. Version II . In the majority of articles devoted to the analysis of texts that the author was able to study, text analysis is understood mainly as two perfectly practical tasks related either to extracting a context or translating text from one language to another. In the first case, it is usually a question of either “clearing” the analyzed content and comparing any part of the text to the standard in accordance with the predefined taxonomy 1 of any entities. For example, analysis of addresses, goods, etc. In the second case, the search for the correspondence of one block of text written in one language to a block written in another.
Combining both of these options is a statistical, in fact, analysis of sections of contexts, taking into account synonyms of words, well-established expressions. At the same time, the analysis of trails 2 , rhetorical turns and much more goes beyond the scope of such an analysis. The reason for this lies in the misunderstanding of modern science, even at the philosophical level, of some basic issues related to the logic of thinking and decision making, the construction of sign systems, i.e. underdevelopment of semiotics, etc.
From the point of view of statistical approaches, if we do not take into account the problems with the formulation of the problem as such, there is a lack of computing resources to track all possible combinations, as well as the analysis of semantic structures when implementing various kinds of neural and other combinatorial algorithms. An exception is the analysis of relatively small semantic structures, such as addresses, goods and services in the presence of a well-developed reference guide, and even then with not very high accuracy rates. Obviously, most fans of neural networks and other weak, inherently AI, can not agree with this postulate. But the practice of using the translator google.com or Korolev Yandex.ru only confirms all of the above. The number of articles on this topic, both scientific and not so huge. For example, "Google Translate: a guide for a complete idiot." Some analysis of research on this topic is presented in the article “Comparison of technological approaches to solving data extraction problems” . By itself, the attractiveness of the same neural networks for solving a certain class of tasks not related to the “meaning” analysis is not diminished to any degree. The task of finding statistically significant patterns is a fully developed area.
Let us return to the main question about the reasons why today there is no need to talk about any significant success in the analysis of texts. Let us try to outline the main steps that, in the author’s opinion, should be followed before we can talk about text analysis in the full sense of the word.
Analyzing the majority of practical decisions in the field of Data mining and Data Science almost the same picture model inevitably emerges. In this model, ontological directories are built, the modules of morphological analysis are added, the base of synonyms of both words and stable expressions is built. Further, based on the accuracy and percentage of matches found in the analyzed text to elements of an anthological reference book, a conclusion is drawn up about the effectiveness of an algorithm. In this regard, it is not decisive whether an approach based on neural networks, “hash” algorithms, or any other is chosen. All of them are based on the statistical-frequency principle. As an example, I would like to cite all the frequent publications about how neural networks could “self-learn” and “learn” a new meaning. In reality, one can speak only of the “discovery” of nothing more than new groups or elements of entities within the framework of well-known descriptive models and patterns. To decide that a new entity or class has been identified, and not an instance within the previously described class, such a system cannot even theoretically. The mathematical apparatus has no mathematics of induction and abstraction.
Therefore, the existing algorithms and libraries of AI are for the most part a dead-end branch in terms of “understanding the meaning” tasks, but despite this, they will give good results in some areas because of the “simple” extensive growth of marked up knowledge bases, and computing power. All these victories will lie within the framework of the implementation of Intellectual agents, designed to solve fairly narrow practical problems and are rather connected with the solution of the problem of creating an AI-complete mechanism.
In fact, the understanding of the meaning of the text is much more complex and is associated with such concepts as "sign", "meaning", "induction", "value" and much more, as mentioned earlier . This article is devoted to the first of the basic concepts, namely the sign .
Sign concept
Starting to discuss the sign as such, it is necessary to make some clarifications related to the fact that in reality it is necessary to discuss three terms at once, which are closely related to each other. This is a "sign" , "symbol" and "signal" . With respect to terminology, the concept of a sign and symbol is often synonymous, in nature, the signal is a slightly different entity.
According to Yu. Schreder 3, "it is hardly worth trying to determine exactly what a sign is." But this can be explained in terms of the “sign situation”. A sign situation is a pair of a sign and signified. In other words, a sign is something that is used as a “substitute” for something. At the same time, in the "real" world there can be neither a sign nor a denoted denotate. Before him C. Pierce 4
distinguished three types of signs:
- Iconic sign.
Pierce defined it as a sign with a known natural resemblance to the object to which it relates. That is, its action is based on the actual similarity of the signifier and signified (for example, the drawing of a lion and the lion itself). - An index whose action is based on the real contiguity of the signifier and the signified (for example, a moan is an index of injury, illness; a cheerful, cheerful laugh — an index of joy, of happiness). Index characters can also point to an object (indicated by a finger, an arrow, or a shout). The form of these signs is not random for the referent (as opposed to symbols), but is not a direct repetition of the form of the referent (as iconic signs). The form of index signs is connected with the referent by certain relations - for example, cause-and-effect relations.
- A symbol whose action is based on a conditional, established “by agreement” connection of the signified and signifying (for example, a nod of the head, as a rule, means an affirmative answer, however, for some peoples this movement is characterized as a negative answer). Here we see that the connection between the signifier and the signified means not a separate object or thing, but the nature of the thing and depends on the mentality of a particular culture.
A kind of continuation of this typing is the definition given by J. Lotman 5 , In his understanding, "symbol" in terms of expression, and in terms of content is always some text, that is, it has some single closed value in itself and a clearly expressed border, which allows to clearly distinguish him from the surrounding semiotic context. In this case, further Yu. Lotman, gives an explanation, clarifying the position of the "symbol" within the entire set of characters. By the fact that a symbol has the iconic property “a certain similarity between the plans of expression and content” 6 . Thus, it is possible to express the assumption that a “symbol” is a kind of subclass of “signs”, which is closely associated primarily with its presentation in the form of texts or audio recordings, but is not a graphic symbol, in other words, the connection is only a semantic one, which is a kind of hint .
The idea that a text is first of all a signal transmitted from one addressee to another was first expressed at the beginning of the last century by C. Morris 7 . Later on it was remarkably developed, for example, A. M. Pyatigorsky 8
in his work "Some general comments on the consideration of the text as a type of signal." Here are some of his theses:
"In linguistics, text is a certain way limited by the diversity of signals ... Another reason in favor of attributing text theory to the science of signal rather than language is the fact that a significant part of texts (some ideographic hieroglyphic, etc.) may be not related to a specific language. "
"The text is created in a certain, single communication situation - a subjective situation, and is perceived depending on the time and place in countless situations."
Further Pyatigorsky writes that the text is in its essence a certain “act of the author’s behavior, in a certain way physically objectified and internally determined by him, and his creation as such kind of behavior, the content of which is the description”
“For any act of semiotic awareness, it is essential to single out significant and insignificant elements in the surrounding reality. Elements that do not carry values do not exist from the point of view of the modeling system. ” 9
Thus, any stream of information and text, in the opinion of a number of authors, should be considered primarily as a signal that should cause a reaction in the recipient.
Contextual. According to the apt expression of the same Y. Lotman, each text has its own “audience”, possessing a certain general memory. Thus, the task of text analysis is complicated by the fact that the “analyzer” must correctly predict the target group of text users.
In practice, the situation is even “worse”, according to some authors, any text is built on the basis of “model images having a syncretic 10
the word-of-sight being ” 11 , including confusion and collision of contexts in order to rhetorically enhance meaning. In the case of texts intended for a wide audience, the task of choosing the right context and set of codes can be partially solved by analyzing the terminology, settled expressions, etc. In the case of private correspondence, the search for the correct semiotic field is a practically unsolvable task that requires an in-depth analysis of the history of the relations of correspondents, the construction of their own code structure, including paths, “own”, invented words etc ...
Structure of sign systems
The structure of sign systems is a multifaceted and multi-level phenomenon. The sciences that can be described as sections of semiotics include syntactics, semantics, pragmatics, linguistics, rhetoric, cultural studies, and a number of others. Cultural anthropology, ethnosemiotics and ethnography, history, philosophy, mathematics, etc. can be referred to interdisciplinary sciences affecting the sphere of interests of semiotics.
At the lower level, we can talk about the structure of the sign, on the average, about semantic and semiotic structures. At the highest level - about the semiosphere as a whole.
For the first time G. Frege, C. Ogden and A. Richards 12 , De Saussure 13 , C. Morris and a number of other authors spoke about the structure of the sign back in the 1920s. On this subject there is a huge amount of work, for example, the work of Schrader 14 , or articles in the Russian journal and many others, which it does not make sense to repeat in this article. Let us briefly dwell only on the Frege triangle:
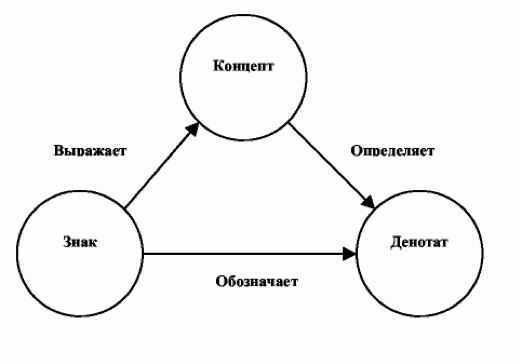
All these works are combined by analyzing the relationship of the sign-concept-denotat. Where the concept is the information that the sign carries about possible denotates 15 , and the denotation is what is indicated. C. Morris identifies an additional abstract concept - designat. In his understanding, a designatum is not a thing, but a genus of an object or a class of objects, and a class can include either many members, or only one member, or no members at all. 16 The concept of the sign described above. Thus, any text can be considered in two ways: on the one hand, this is a kind of superposition of signs, and on the other, of their concepts, in some cases, the entire text will be a complete sign.
Much more ambiguous, everything is with the definition of the sign-signal relationship. As mentioned above, in the works of such researchers as C. Morris, A. Pyatigorsky, R. Jacobson, one of the priority messages is the fact that any text should first of all be taken as a signal. If at the beginning of the last century great importance was attached to this, today, for the sake of translating and extracting data, the lion's share of research is devoted to syntagmatic and semantic analysis, the construction of various kinds of thesauri.
All that today is mentioned in connection with signals - this is what, part of the signs can be attributed to signals or, in Pierce’s terminology, indices. In reality, the picture is completely opposite - the signs are part of the signal system. If you carefully consider the analysis of a pair of sign-signal, then we move on to a completely different area of research related to the signal properties that are additional to the sign.
Signal:
The main features of the signal include the following:
- It has a physical entity in the form of a distribution channel.
According to the concept proposed by A. Pyatigorsky, the text possesses such basic characteristics as spatiality, time and objectivity. Spatial is understood as the fact of the presence of the information carrier, as its form. Form can be essential. For example, a letter and a newspaper clipping have completely different sensitivity to the assessment and interpretation of the meaning of the text.
- The channel serves to transmit non-verbal and verbal signs.
Most often, when speaking about understanding meaning, we operate with the tasks of analyzing texts or recognizing emotions on a person’s face. These tasks essentially boil down to two rather isolated channels — texts and images.
- Waiting for feedback - reaction is assumed.
The cause of any signal is the need or the need to get some kind of reaction. It may be aimed at establishing feedback, and it may also be one-sided. But the presence of any reaction is imperative.
- The accuracy of the response may vary.
Varying the accuracy of the reaction is a function depending on such parameters as the presence of noise, the presence of a common multiplicity of concepts, associative series. All this can be expressed by the generalized concept of the general (identical) previous experience. In this case, under the noise should be understood not the truth or falsity of the flow of signs, but rather its mutual consistency of signs. This problem is exacerbated by the presence of trails and rhetorical turns in general, which is not a drop-down context. They serve to enhance the flow of signals.
- strength and quality of signal exposure;
The property of strength and quality of influence depends on many factors, but mainly on the availability of general experience, the state of the addressee at the time of receiving the signal, and the totality of signs through which the signal is transmitted. In addition, it is necessary to take into account the “density” and speed of the transmitted flow of signs, limiting the limit of perception, and the strength of the emotional impact, which limits the possibilities of the psyche, in the case of the addressee.
emotional coloring;
In itself, the theme of emotion is limitless. Within the scope of the current research tasks, two issues are of interest. Is emotion an independent signal? Does it in itself have a symbolic nature, i.e. Is there a concept and designat? Is the emotion a property of the sign or one of the characteristics of the signal transmission channel? Due to the limited nature of the article itself, we limit ourselves to the statement that emotion is at least a full-fledged signal, with an unobvious sign nature. Emotional coloring is a channel characteristic that changes over time as part of the channel's work process.
Part of the above signs to some extent echoes the well-known theory of signals in information theory.
Semiosphere - the habitat of signs
The term semiosphere 17 was introduced by J. Lotman, by analogy with the biosphere of V. Vernadsky, as a common cultural space, including language as part of it.
')
The semiotic system, according to Lotman, is binary, asymmetric, and heterogeneous. The principle of binarity suggests that any language (semiotic system) is sooner or later subject to fragmentation into other languages (systems). At the same time, it is necessary to take into account the presence and inverse mechanism - unification. As a result, new languages of art appear on the one hand, and new canons emerge on the other. The principle of asymmetry suggests that such fragmentation occurs in different proportions. The principle of heterogeneity suggests that within the semiosphere there can exist structures of a completely different nature. Simplistically, various kinds of memes, local notions about the truth of certain statements, different designations of the same concepts and denotates, and much more, can act as such. As a result, there can be situations of both partial and complete untranslatability.
Based on the foregoing, the conclusion suggests itself that there is no single semiotic structure or any isolated systems. In contrast, it is necessary to speak about the presence of the global semiosphere, which is a kind of “superposition” of various semiotic systems.
Exchange patterns.
Building a communication channel model is one of the most important tasks, without which it is impossible to analyze the processes during which signals are exchanged, and in particular, signs are exchanged.
One of the first communication models was proposed by R. Jacobson 18 . This model is the following abstraction 19 :
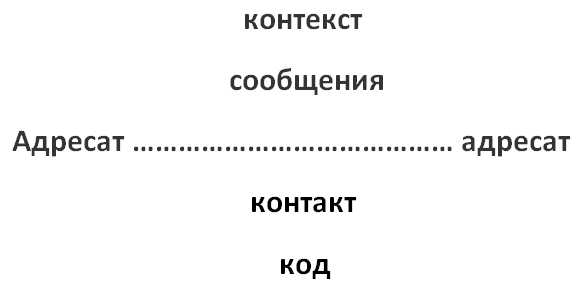
Later, other advanced models were proposed. For example, “theatrical model” by Y. Kristeva 20 : “author-addressee-other-situation”.
All of these models indicate that by itself, any of the models, apart from the fact that it operates with the general concepts of the addressee and the recipient, are strongly dependent on such concepts as “context”. According to Yu. Kristeva, 21 , one of the basic problems in analyzing the transmitted content is the lack of a Single meaning, and, therefore, the rejection of the very possibility of unambiguous interpretation. The distortion or differences in interpretations of the meaning are due to the denial of the right to the author subject in “sacredness”, “magic” and “effect”.
By "sacredness" is meant the absence of the right to a single meaning in the very right. By "magic" - the inability to protect the subject from the dominant semiosphere, i.e. from possible changes in interpretations of certain semiotic systems.
From the point of view of the topic of the article, the presence of these models indicates the fact that it is necessary to design not only the channel itself, but also to implement, for example, such subsystems as:
- network base graphs of characters, which themselves can be encapsulated into each other;
- groups of subjects (recipients and recipients)
- network models of possible contexts.
Omnicanality 22
Most of the works related to semiotics and semantics operate with such concepts as isolated text or image from the point of view of analysis. But without the study of effects, which imposes the presence of a large number of parallel and interintegrated streams, there is no need to talk about full-fledged AI, even in the tasks of “simple” text analysis. When transferring information, for example, educational films, lecture courses, etc. both textual and audio-video streams of information are present simultaneously.
Until today, the author did not come across how significant serious work on this topic.
findings
This topic is a huge layer of questions, a detailed discussion of which is impossible in a separate article. Therefore, the main task was to show the main blocks, without the implementation of which further progress is simply impossible.
The existing solutions, from those that are known to the author at the moment, either ignore the problem of signs altogether or have a greatly simplified approach to the problem of analyzing and operating with signs.
For further advancement, it is necessary to solve the following engineering tasks:
- Creation of unified complexes of bases and rules of operation uniting various classes of sign systems such as text, graphic, video and audio signs. These complexes should include such subsystems as signs, concepts and denotations in the context of cultural, professional, historical and a number of other dimensions.
- Creation of databases and types of subjects-recipients taking into account the measurements specified in the previous paragraph.
- Creating databases of interrelationships of semiotic structures, and not just blocks of interrelated texts and all sorts of thesauri.
- Creation of bases and rules for generating and operating as a whole the emotional effects of signs.
- The system being created must necessarily take into account the omni-channel problem, even in the case of operating within only one of the channels.
- The refusal of attempts to obtain a single meaning in favor of building rather probabilistic results characteristic of one or another semiotic structure, the interpretation of which depends cumulatively on the previously analyzed contexts, including adjacent ones.
- The concept of fidelity and falsity of statements, formed by the superposition of assertions, formed by signs are credibility only in the context of one point in time. Consequently, subsystems for monitoring and analyzing such superpositions should be implemented. Developed models for correcting the main stream of conclusions.
Links
1 TAXONOMY is the science of the classification of complex objects of reality (living nature, the structure of the Earth, ethnic communities, language, etc.). Ozhegov Dictionary. S.I. Ozhegov, N.Yu. Shvedov. 1949-1992.
2 TRAILS (from the Greek tropos - turn, turn of speech), 1) in the style and poetics, the use of the word in the figurative sense, in which there is a shift in the semantics of the word from its direct meaning to the figurative. On the correlation of direct and figurative meanings of the word, three types of pathways are built: correlation by similarity ( metaphor ), by contrast ( oxymoron ), by contiguity ( metonymy ). Different ways of word transformation (from word to image) are an important element of artistic thinking. The main types of trails are also distinguished by their varieties ( irony , synecdoche, hyperbole , litos , epithet , etc.). 2) (Musical) in the Gregorian chorale insert (or a series of inserts) in canonical chants - text or non-text. Modern encyclopedia. 2000
3 Schrader Yu.A. Logic of sign systems: Elements of semiotics. Book House "LIBRIKOM", 2012. Page four
4 textb.net/51/18.html
5 Lotman Yu.M. Inside the thinking worlds. Publishing house of the Alphabet, 2015. .158
6 Lotman Yu.M. Inside the thinking worlds. Publishing house of the Alphabet, 2015. .171
7 Ch. Morris Fundations of the theory of Sings. Chicago, 1938
8 A.M. Pyatigorsky "Some general comments regarding the consideration of the text as a type of signal." Structural typological studies. Digest of articles. M .: Publishing House of the Academy of Sciences of the USSR, 1962. Pp. 144-154
9 Lotman Yu.M. Inside the thinking worlds. Publishing house of the Alphabet, 2015. P.90
10 Syncretic - Philos. consisting of heterogeneous elements, but being integral.
11 Lotman Yu.M. Inside the thinking worlds. Azbuka Publishers, 2015. C.127
12 CK Ogden and IA Richards, The Thought for the Meaning of Meaning, 1923, Magdalene College, University of Cambridge, p. eleven
13 Saussure Ferdinand de, Course in General Linguistics: Published by S. Bally and A. Seshe with the participation of A. Riedlinger. Per.s fr. / Ed. And with notes. R.O. Shor., Book House "LIBRIKOM", 2016.
14 Shreyder Yu.A. Logic of sign systems: Elements of semiotics. Book House "LIBRIKOM", 2012.
15 Shreyder Yu.A. Logic of sign systems: Elements of semiotics. Book House "LIBRIKOM", 2012. P.10
16 Ch.Morris Fundations of the theory of Sings. Chicago, 1938
17 Lotman Yu.M. Inside the thinking worlds. Publishing house of the Alphabet, 2015. .176
18 Jakobson R. Lingustics and Poetics. Style in Linguage. Cambridge, 1964. P. 353
19 Lotman Yu.M. Inside the thinking worlds. Publishing house of the Alphabet, 2015. P.30
20 Kristeva Yu. Semiotics: Research on semanalysis. Academic project, 2015.
21 Kristeva Yu. Semiotics: Research on semanalysis. Academic project, 2015. C 13.
22 The term “omnicanality” was introduced by the author by analogy with the concept of omnicanality adopted in marketing.
Source: https://habr.com/ru/post/352248/
All Articles