Cache problems and solutions
Hi, Habr!
My name is Victor Pryazhnikov, I work for the Badoo SRV team. Our team develops and maintains an internal API for our clients from the server side, and data caching is something we encounter every day.
There is an opinion that in programming there are only two truly complex tasks: inventing names and invalidation of the cache. I will not argue with the fact that disability is difficult, but it seems to me that caching is a pretty tricky thing, even without considering disability. There are many things to think about before starting to use the cache. In this article I will try to formulate some problems that can be encountered when working with a cache in a large system.
')

Wild horses stampeding. Original picture.
I will talk about the problems of separating cached data between servers, parallel updates of data, cold start and system malfunctioning. I will also describe possible solutions to these problems and provide links to materials where these topics are covered in more detail. I will not tell what cache is in principle and concern the details of the implementation of specific systems.
In my work, I assume that the system in question consists of an application, a database and a cache for data. Instead of a database, any other source can be used (for example, some microservice or an external API).
If you want to use caching in a large enough system, you need to make sure that you can divide the cached data among the available servers. This is necessary for several reasons:
The most obvious way to break down data is to calculate the server number in a pseudo-random manner, depending on the caching key.
There are different algorithms for implementing this. The easiest is to calculate the server number as the remainder of the integer division of the numerical key representation (for example, CRC32) by the number of cache servers:
Such an algorithm is called modular hashing (English modulo hashing). CRC32 is used here as an example. Instead, you can take any other hashing function, from the results of which you can get a number greater or equal to the number of servers, with a more or less evenly distributed result.
This method is easy to understand and implement, it distributes data fairly evenly between servers, but it has a serious drawback: when the number of servers changes (due to technical problems or when new ones are added), a significant portion of the cache is lost, since the remainder of the division changes for the keys.
I wrote a small script that will demonstrate this problem.
It generates 1 million unique keys, distributed across five servers using hashing modulo and CRC32. I emulate the failure of one of the servers and the redistribution of data on the four remaining ones.
As a result of this “failure”, approximately 80% of the keys will change their location, that is, they will be inaccessible for further reading:
Total keys count: 1,000,000
Shards count range: 4, 5
The most annoying thing here is that 80% is far from the limit. With the increase in the number of servers, the percentage of cache loss will continue to grow. The only exception is multiple changes (from two to four, from nine to three, etc.), in which the losses will be less than usual, but in any case at least half of the existing cache:

I put a script on GitHub with which I collected data, as well as an ipynb file that paints this table and data files.
To solve this problem, there is another breakdown algorithm - consistent hashing . The basic idea of this mechanism is very simple: an additional display of keys is added to the slots, the number of which significantly exceeds the number of servers (there may be thousands and even more). The slots themselves, in turn, are somehow distributed across servers.
When the number of servers changes, the number of slots does not change, but the distribution of slots between these servers changes:
Usually, the idea of consistent hashing is visualized with the help of rings, the dots on the circles of which show slots or boundaries of slot ranges (in case there are a lot of these slots). Here is a simple redistribution example for a situation with a small number of slots (60), which were initially distributed across four servers:
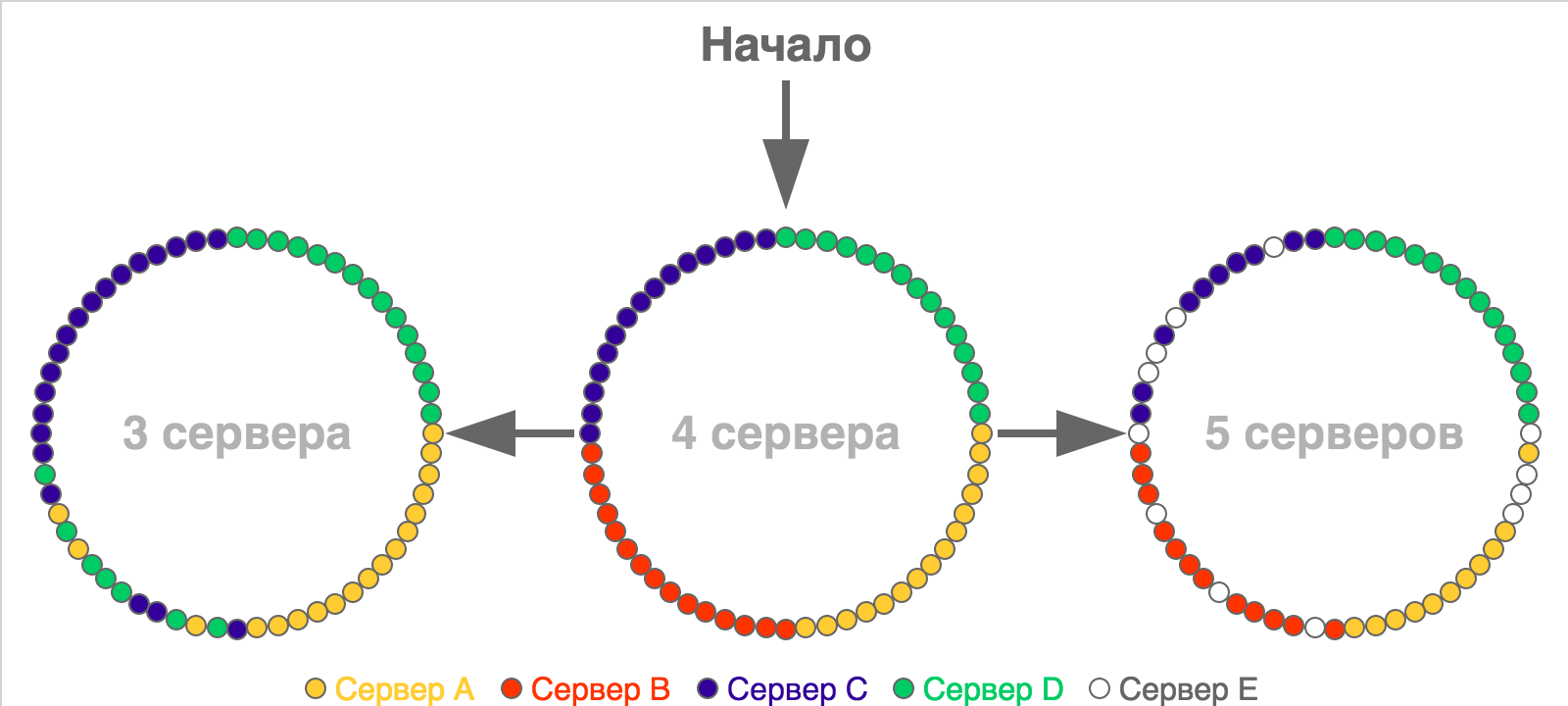
In the picture of the initial partition, all the slots of one server are located in a row, but in reality this is not a necessary condition - they can be located as you please.
The main advantage of this method over the previous one is that there is not a single value for each server, but a whole range, and when the number of servers changes, a much smaller part of the keys is redistributed (
If you go back to the scenario that I used to demonstrate the lack of hashing by module, then with the same situation with the fall of one of the five servers (with the same weight) and the redistribution of keys from it between the remaining losses, not 80% of the cache, but only 20%. If we assume that initially all data is in the cache and all of them are requested, then this difference means that with consistent hashing we will receive four times less database queries.
The code that implements this algorithm will be more complicated than the previous code, so I will not give it in the article. If desired, it can be easily found - on GitHub there are a lot of implementations in many different languages.
Along with consistent hashing, there are other ways to solve this problem (for example, rendezvous hashing ), but they are much less common.
Regardless of the algorithm chosen, choosing a server based on a key hash can work poorly. Typically, the cache is not a set of the same type of data, but a large number of heterogeneous: cached values occupy different places in the memory, are requested with different frequencies, have different generation times, different refresh rates and different lifetime. When using hashing, you cannot control where the key will go, and as a result there may be a “bias” both in the amount of stored data and in the number of requests to them, which will cause the behavior of different caching servers to vary greatly.
To solve this problem, it is necessary to “spread” the keys so that heterogeneous data is distributed more or less uniformly between servers. To do this, to select a server, you need to use not a key, but some other parameter, to which you need to apply one of the described approaches. This is not to say what the parameter will be, since it depends on your data model.
In our case, almost all cached data belongs to the same user, so we use the User ID as the sharding parameter of the data in the cache. Thanks to this, we manage to distribute data more or less evenly. In addition, we get a bonus - the ability to use
See also:
Look at such a simple piece of code:
What happens if there is no requested data in the cache? Judging by the code, the mechanism that will get this data should start. If the code is executed only in one thread, then everything will be fine: the data will be loaded, placed in the cache and with the next query taken from there. But when working in several parallel threads, everything will be different: the data will be downloaded not once, but several.
It will look something like this:

At the time of the beginning of the processing of the request in process No. 2, there is no data in the cache yet, but they are already read from the database in process No. 1. In this example, the problem is not so significant, there are only two requests, but there may be much more.
The number of parallel downloads depends on the number of parallel users and the time it takes to download the necessary data.
Suppose you have some kind of functionality that uses a cache with a load of 200 requests per second. If you need 50 ms to load data, then during this time you will receive
That is, in the absence of a cache, one process will start loading data, and during the load time, nine more requests will arrive that will not see the data in the cache and will also load it.
This problem is called cache stampede (I haven’t found the Russian equivalent of this term, literally, this can be translated as “stampede cache”, and the picture in the beginning of the article shows an example of this action in the wild), hit miss storm or the dog-pile effect . There are several ways to solve it:
The essence of this method is that, in the absence of data in the cache, a process that wants to load it must capture a lock that will not allow the same processes to be executed by other processes running in parallel. In the case of memcached, the easiest way to block is to add a key to the same caching server, in which the cached data itself should be stored.
With this option, the data is updated only in one process, but you need to decide what to do with processes that are in a situation with a missing cache, but could not get a lock. They can give an error or some default value, wait for some time, and then try to get the data again.
In addition, you need to carefully select the time of the lock itself - it is guaranteed to be enough to load data from the source and put it in the cache. If not enough, another parallel process may begin reloading the data. On the other hand, if this time period is too large and the process that received the lock dies without writing data to the cache and not releasing the lock, other processes will also not be able to get this data until the end of the lock time.
The main idea of this method is the separation of the data from the cache and writing to it according to different processes. In online processes, only the data from the cache is read, but not its loading, which is only in a separate background process. This option makes parallel data updates impossible.
This method requires additional “costs” to create and monitor a separate script that writes data to the cache, and to synchronize the lifetime of the recorded cache and the time of the next run of the updating script.
We use this option in Badoo, for example, for a counter of the total number of users, which will be discussed further.
The essence of these methods lies in the fact that the data in the cache is updated not only in the absence, but also with some probability in their presence. This will allow updating them before the cached data is “rotten” and all processes need to be used at once.
For such a mechanism to work correctly, it is necessary that at the beginning of the life of cached data, the probability of recalculation is small, but gradually increased. This can be achieved using the XFetch algorithm, which uses an exponential distribution. Its implementation looks like this:
In this example,
It should be understood that when using such probabilistic mechanisms, you do not exclude parallel updates, but only reduce their likelihood. To exclude them, you can "cross" several ways at once (for example, by adding a lock before updating).
See also:
It should be noted that the problem of mass data updates due to their absence in the cache can be caused not only by a large number of updates of the same key, but also by a large number of simultaneous updates of different keys. For example, this can happen when you roll out a new "popular" functionality using caching and a fixed cache lifetime.
In this case, immediately after rolling out the data will begin to load (the first manifestation of the problem), after which they will get into the cache - and for some time everything will be fine, and after the expiration of the cache lifetime all the data will start loading again and create an increased load on the database.
It is impossible to get rid of such a problem completely, but you can “spread out” data loading over time, thereby eliminating a sharp number of parallel queries to the database. There are several ways to achieve this:
If for some reason you do not want to use a random number, you can replace it with a pseudo-random value obtained using a hash function based on some data (for example, User ID).
I wrote a small script that emulates a “cold” cache situation.
In it, I reproduce the situation in which the user loads data about himself when requested (if they are not in the cache). Of course, the example is synthetic, but even on it you can see the difference in the behavior of the system.
This is how the graph of the number of hit misses looks in a situation with a fixed (fixed_cache_misses_count) and different (random_cache_misses_count) cache lifetime:
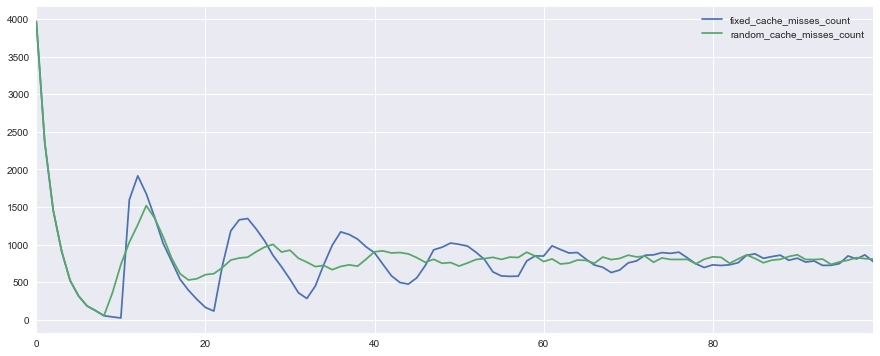
It can be seen that at the beginning of work in both cases the load peaks are very noticeable, but when using a pseudo-random lifetime, they are smoothed out much faster.
The data in the cache is heterogeneous, some of them can be requested very often. In this case, problems may be created not even by parallel updates, but by the number of readings themselves. An example of such a key is the total users count:

This counter is one of the most popular keys, and using the usual approach, all requests to it will go to one server (since this is just one key, and not many of the same type), whose behavior can change and slow down work with other keys stored in the same .
To solve this problem, you need to write data not to one caching server, but to several at once. In this case, we will multiply reduce the number of readings of this key, but we will complicate its updates and server selection code, since we will need to use a separate mechanism.
We at Badoo solve this problem by writing data to all caching servers at once. Due to this, when reading, we can use a common server selection mechanism - in the code, you can use the usual User ID sharding mechanism, and when reading, you do not need to know anything about the specifics of this “hot” key. In our case, this works because we have relatively few servers (approximately ten per site).
If there were much more caching servers, then this method might not be the most convenient - it simply does not make sense to duplicate the same data hundreds of times. In this case, it would be possible to duplicate the key not for all servers, but only for their part, but this option requires a little more effort.
If you use the server definition by the cache key, you can add a limited number of pseudo-random values to it (by making
If you use explicit sharding parameter specifications, simply pass in different pseudo-random values.
The main problem with both methods is to make sure that different values really fall on different caching servers.
See also:
The system can not be 100% reliable, so you need to consider how it will behave in case of failures. Failures can be in the work of the cache itself, and in the database.
I have already talked about cache failures in previous sections. The only thing that can be added is it would be good to provide for the possibility of disabling part of the functionality on a running system. This is useful when the system is unable to cope with the peak load.
If the database fails and there is no cache, we can get into a cache stampede situation, about which I also told earlier. You can get out of it in the ways already described, or you can write to the cache a deliberately incorrect value with a short lifespan. In this case, the system will be able to determine that the source is unavailable, and for some time will stop trying to request data.
In the article I touched upon the main problems when working with the cache, but I am sure that, besides them, there are many others, and this conversation can be continued for a very long time. I hope that after reading my article, your cache will become more efficient.
My name is Victor Pryazhnikov, I work for the Badoo SRV team. Our team develops and maintains an internal API for our clients from the server side, and data caching is something we encounter every day.
There is an opinion that in programming there are only two truly complex tasks: inventing names and invalidation of the cache. I will not argue with the fact that disability is difficult, but it seems to me that caching is a pretty tricky thing, even without considering disability. There are many things to think about before starting to use the cache. In this article I will try to formulate some problems that can be encountered when working with a cache in a large system.
')
Wild horses stampeding. Original picture.
I will talk about the problems of separating cached data between servers, parallel updates of data, cold start and system malfunctioning. I will also describe possible solutions to these problems and provide links to materials where these topics are covered in more detail. I will not tell what cache is in principle and concern the details of the implementation of specific systems.
In my work, I assume that the system in question consists of an application, a database and a cache for data. Instead of a database, any other source can be used (for example, some microservice or an external API).
Dividing data between caching servers
If you want to use caching in a large enough system, you need to make sure that you can divide the cached data among the available servers. This is necessary for several reasons:
- data can be very much, and they physically do not fit in the memory of one server;
- data can be requested very often, and one server is not able to process all these requests;
- You want to make caching more reliable. If you have only one caching server, then if it crashes, the whole system will remain without a cache, which can dramatically increase the load on the database.
The most obvious way to break down data is to calculate the server number in a pseudo-random manner, depending on the caching key.
There are different algorithms for implementing this. The easiest is to calculate the server number as the remainder of the integer division of the numerical key representation (for example, CRC32) by the number of cache servers:
$cache_server_index = crc32($cache_key) % count($cache_servers_list); Such an algorithm is called modular hashing (English modulo hashing). CRC32 is used here as an example. Instead, you can take any other hashing function, from the results of which you can get a number greater or equal to the number of servers, with a more or less evenly distributed result.
This method is easy to understand and implement, it distributes data fairly evenly between servers, but it has a serious drawback: when the number of servers changes (due to technical problems or when new ones are added), a significant portion of the cache is lost, since the remainder of the division changes for the keys.
I wrote a small script that will demonstrate this problem.
It generates 1 million unique keys, distributed across five servers using hashing modulo and CRC32. I emulate the failure of one of the servers and the redistribution of data on the four remaining ones.
As a result of this “failure”, approximately 80% of the keys will change their location, that is, they will be inaccessible for further reading:
Total keys count: 1,000,000
Shards count range: 4, 5
| ShardsBefore | ShardsAfter | LostKeysPercent | Lostkeys |
|---|---|---|---|
| five | four | 80.03% | 800345 |
The most annoying thing here is that 80% is far from the limit. With the increase in the number of servers, the percentage of cache loss will continue to grow. The only exception is multiple changes (from two to four, from nine to three, etc.), in which the losses will be less than usual, but in any case at least half of the existing cache:
I put a script on GitHub with which I collected data, as well as an ipynb file that paints this table and data files.
To solve this problem, there is another breakdown algorithm - consistent hashing . The basic idea of this mechanism is very simple: an additional display of keys is added to the slots, the number of which significantly exceeds the number of servers (there may be thousands and even more). The slots themselves, in turn, are somehow distributed across servers.
When the number of servers changes, the number of slots does not change, but the distribution of slots between these servers changes:
- if one of the servers fails, then all the slots that belong to it are distributed among the remaining ones;
- if a new server is added, then a part of the slots from the existing servers is transferred to it.
Usually, the idea of consistent hashing is visualized with the help of rings, the dots on the circles of which show slots or boundaries of slot ranges (in case there are a lot of these slots). Here is a simple redistribution example for a situation with a small number of slots (60), which were initially distributed across four servers:
In the picture of the initial partition, all the slots of one server are located in a row, but in reality this is not a necessary condition - they can be located as you please.
The main advantage of this method over the previous one is that there is not a single value for each server, but a whole range, and when the number of servers changes, a much smaller part of the keys is redistributed (
k / N , where k is the total number of keys and N is number of servers).If you go back to the scenario that I used to demonstrate the lack of hashing by module, then with the same situation with the fall of one of the five servers (with the same weight) and the redistribution of keys from it between the remaining losses, not 80% of the cache, but only 20%. If we assume that initially all data is in the cache and all of them are requested, then this difference means that with consistent hashing we will receive four times less database queries.
The code that implements this algorithm will be more complicated than the previous code, so I will not give it in the article. If desired, it can be easily found - on GitHub there are a lot of implementations in many different languages.
Along with consistent hashing, there are other ways to solve this problem (for example, rendezvous hashing ), but they are much less common.
Regardless of the algorithm chosen, choosing a server based on a key hash can work poorly. Typically, the cache is not a set of the same type of data, but a large number of heterogeneous: cached values occupy different places in the memory, are requested with different frequencies, have different generation times, different refresh rates and different lifetime. When using hashing, you cannot control where the key will go, and as a result there may be a “bias” both in the amount of stored data and in the number of requests to them, which will cause the behavior of different caching servers to vary greatly.
To solve this problem, it is necessary to “spread” the keys so that heterogeneous data is distributed more or less uniformly between servers. To do this, to select a server, you need to use not a key, but some other parameter, to which you need to apply one of the described approaches. This is not to say what the parameter will be, since it depends on your data model.
In our case, almost all cached data belongs to the same user, so we use the User ID as the sharding parameter of the data in the cache. Thanks to this, we manage to distribute data more or less evenly. In addition, we get a bonus - the ability to use
multi_get to download several different keys at once with information about the user (which we use in preloading frequently used data for the current user). If the position of each key was determined dynamically, it would be impossible to use multi_get in such a scenario, since there would be no guarantee that all the requested keys belong to the same server.See also:
- Wikipedia Distributed hash table
- Consistent hashing article on Wikipedia
- A Guide to Consistent Hashing
- Distributed hashing trees on the World Wide Web
- Building a Consistent Hashing Ring
Parallel data update requests
Look at such a simple piece of code:
public function getContactsCountCached(int $user_id) : ?int { $contacts_count = \Contacts\Cache::getContactsCount($user_id); if ($contacts_count !== false) { return $contacts_count; } $contacts_count = $this->getContactsCount($user_id); if (is_null($contacts_count)) { return null; } \Contacts\Cache::setContactsCount($user_id, $contacts_count); return $contacts_count; } What happens if there is no requested data in the cache? Judging by the code, the mechanism that will get this data should start. If the code is executed only in one thread, then everything will be fine: the data will be loaded, placed in the cache and with the next query taken from there. But when working in several parallel threads, everything will be different: the data will be downloaded not once, but several.
It will look something like this:
At the time of the beginning of the processing of the request in process No. 2, there is no data in the cache yet, but they are already read from the database in process No. 1. In this example, the problem is not so significant, there are only two requests, but there may be much more.
The number of parallel downloads depends on the number of parallel users and the time it takes to download the necessary data.
Suppose you have some kind of functionality that uses a cache with a load of 200 requests per second. If you need 50 ms to load data, then during this time you will receive
50 / (1000 / 200) = 10 requests.That is, in the absence of a cache, one process will start loading data, and during the load time, nine more requests will arrive that will not see the data in the cache and will also load it.
This problem is called cache stampede (I haven’t found the Russian equivalent of this term, literally, this can be translated as “stampede cache”, and the picture in the beginning of the article shows an example of this action in the wild), hit miss storm or the dog-pile effect . There are several ways to solve it:
Blocking before starting the operation of recalculating / loading data
The essence of this method is that, in the absence of data in the cache, a process that wants to load it must capture a lock that will not allow the same processes to be executed by other processes running in parallel. In the case of memcached, the easiest way to block is to add a key to the same caching server, in which the cached data itself should be stored.
With this option, the data is updated only in one process, but you need to decide what to do with processes that are in a situation with a missing cache, but could not get a lock. They can give an error or some default value, wait for some time, and then try to get the data again.
In addition, you need to carefully select the time of the lock itself - it is guaranteed to be enough to load data from the source and put it in the cache. If not enough, another parallel process may begin reloading the data. On the other hand, if this time period is too large and the process that received the lock dies without writing data to the cache and not releasing the lock, other processes will also not be able to get this data until the end of the lock time.
Take out updates in the background
The main idea of this method is the separation of the data from the cache and writing to it according to different processes. In online processes, only the data from the cache is read, but not its loading, which is only in a separate background process. This option makes parallel data updates impossible.
This method requires additional “costs” to create and monitor a separate script that writes data to the cache, and to synchronize the lifetime of the recorded cache and the time of the next run of the updating script.
We use this option in Badoo, for example, for a counter of the total number of users, which will be discussed further.
Probabilistic update methods
The essence of these methods lies in the fact that the data in the cache is updated not only in the absence, but also with some probability in their presence. This will allow updating them before the cached data is “rotten” and all processes need to be used at once.
For such a mechanism to work correctly, it is necessary that at the beginning of the life of cached data, the probability of recalculation is small, but gradually increased. This can be achieved using the XFetch algorithm, which uses an exponential distribution. Its implementation looks like this:
function xFetch($key, $ttl, $beta = 1) { [$value, $delta, $expiry] = cacheRead($key); if (!$value || (time() − $delta * $beta * log(rand())) > $expiry) { $start = time(); $value = recomputeValue($key); $delta = time() – $start; $expiry = time() + $ttl; cacheWrite(key, [$value, $delta, $expiry], $ttl); } return $value; } In this example,
$ttl is the lifetime of the value in the cache, $delta is the time it took to generate the cached value, $expiry is the time until which the value in the cache is valid, $beta is the algorithm setting parameter, which can be changed on the probability of recalculation (the bigger it is, the more likely the recalculation is with each request). A detailed description of this algorithm can be found in the white paper "Optimal Probabilistic Cache Stampede Prevention", a link to which you will find at the end of this section.It should be understood that when using such probabilistic mechanisms, you do not exclude parallel updates, but only reduce their likelihood. To exclude them, you can "cross" several ways at once (for example, by adding a lock before updating).
See also:
- Cache stampede article on Wikipedia
- Optimal Probabilistic Cache Stampede Prevention
- GitHub repository with descriptions and tests of different ways
- The article "Caches for" dummies ""
"Cold" start and "warming up" cache
It should be noted that the problem of mass data updates due to their absence in the cache can be caused not only by a large number of updates of the same key, but also by a large number of simultaneous updates of different keys. For example, this can happen when you roll out a new "popular" functionality using caching and a fixed cache lifetime.
In this case, immediately after rolling out the data will begin to load (the first manifestation of the problem), after which they will get into the cache - and for some time everything will be fine, and after the expiration of the cache lifetime all the data will start loading again and create an increased load on the database.
It is impossible to get rid of such a problem completely, but you can “spread out” data loading over time, thereby eliminating a sharp number of parallel queries to the database. There are several ways to achieve this:
- smooth inclusion of new functionality. This requires a mechanism that allows it to be done. The simplest version of the implementation is to roll out the new functionality included for a small part of users and gradually increase it. In this scenario, there should not be a large update shaft at once, since at first the functionality will be available only to some users, and as it increases, the cache will already be “warmed up”.
- different lifetime of different elements of the data set. This mechanism can be used only if the system is able to withstand the peak that will occur when rolling out all the functionality. Its peculiarity lies in the fact that when writing data to the cache, each element will have its own lifetime, and thanks to this, the update shaft will smooth out much faster due to the distribution of subsequent updates in time. The simplest way to implement such a mechanism is to multiply the cache lifetime by some random factor:
public function getNewSnapshotTTL() { $random_factor = rand(950, 1050) / 1000; return intval($this->getSnapshotTTL() * $random_factor); } If for some reason you do not want to use a random number, you can replace it with a pseudo-random value obtained using a hash function based on some data (for example, User ID).
Example
I wrote a small script that emulates a “cold” cache situation.
In it, I reproduce the situation in which the user loads data about himself when requested (if they are not in the cache). Of course, the example is synthetic, but even on it you can see the difference in the behavior of the system.
This is how the graph of the number of hit misses looks in a situation with a fixed (fixed_cache_misses_count) and different (random_cache_misses_count) cache lifetime:
It can be seen that at the beginning of work in both cases the load peaks are very noticeable, but when using a pseudo-random lifetime, they are smoothed out much faster.
Hot Keys
The data in the cache is heterogeneous, some of them can be requested very often. In this case, problems may be created not even by parallel updates, but by the number of readings themselves. An example of such a key is the total users count:
This counter is one of the most popular keys, and using the usual approach, all requests to it will go to one server (since this is just one key, and not many of the same type), whose behavior can change and slow down work with other keys stored in the same .
To solve this problem, you need to write data not to one caching server, but to several at once. In this case, we will multiply reduce the number of readings of this key, but we will complicate its updates and server selection code, since we will need to use a separate mechanism.
We at Badoo solve this problem by writing data to all caching servers at once. Due to this, when reading, we can use a common server selection mechanism - in the code, you can use the usual User ID sharding mechanism, and when reading, you do not need to know anything about the specifics of this “hot” key. In our case, this works because we have relatively few servers (approximately ten per site).
If there were much more caching servers, then this method might not be the most convenient - it simply does not make sense to duplicate the same data hundreds of times. In this case, it would be possible to duplicate the key not for all servers, but only for their part, but this option requires a little more effort.
If you use the server definition by the cache key, you can add a limited number of pseudo-random values to it (by making
total_users_count from total_users_count t otal_users_count_1 , total_users_count_2 , etc.). A similar approach is used, for example, in Etsy.If you use explicit sharding parameter specifications, simply pass in different pseudo-random values.
The main problem with both methods is to make sure that different values really fall on different caching servers.
See also:
Malfunctions
The system can not be 100% reliable, so you need to consider how it will behave in case of failures. Failures can be in the work of the cache itself, and in the database.
I have already talked about cache failures in previous sections. The only thing that can be added is it would be good to provide for the possibility of disabling part of the functionality on a running system. This is useful when the system is unable to cope with the peak load.
If the database fails and there is no cache, we can get into a cache stampede situation, about which I also told earlier. You can get out of it in the ways already described, or you can write to the cache a deliberately incorrect value with a short lifespan. In this case, the system will be able to determine that the source is unavailable, and for some time will stop trying to request data.
Conclusion
In the article I touched upon the main problems when working with the cache, but I am sure that, besides them, there are many others, and this conversation can be continued for a very long time. I hope that after reading my article, your cache will become more efficient.
Source: https://habr.com/ru/post/352186/
All Articles