From the installation of AWX to the launch of the first playbook - setting up centralized control Ansible

The number of servers in our infrastructure has already exceeded 800, although a year ago there were about 500 . To work with this, Red Hat solutions are widely used. We have already written about FreeIPA - for organizing and managing access for Linux-servers - now I want to touch on the topic of configuration management. For these purposes, we use Ansible, and more recently AWX has been added to it - a solution presented for six months ago for centralized management of playbooks, their launch schedule, inventory management, server access credentials, and a callback mechanism for requesting configurations from server side.
Because of a number of things, we were not immediately able to integrate it with our main project War Robots, but there were plenty of AWX verification fields. First, the company is developing new projects that need dev / stage-environments and, of course, production-environments in the future. And recently, a project for internal analytics was added to this, which required a completely new cluster.
')
So, let's begin!
AWX was introduced in September 2017 - this is a free open source project, distributed under the Apache-2.0 license, which is upstream for the commercial project Ansible Tower . In general, this is the same principle as other Red Hat projects: Red Hat Cloud Forms - ManageIQ; RHEV - Ovirt; Red Hat Identify Managment - FreeIPA and so on.
This article is a guide - from installing AWX to launching the first playbook. But first, let's list the main features of AWX:
- Integration with version control systems (git / mercurial / subversion).
- Tracking the status of playbukov in real time.
- Setting the schedule for the automatic launch of playbukov.
- Execution of several playbooks within one workflow.
- Remote execution of commands without playbooks (Ansible ad hoc).
- Support for callbacks that allow new servers to request configurations from their side.
- Inventory management for ansibla, including with the ability to integrate with AWS / Azure / OpenStack platforms, etc., as well as support for your own scripts to generate Dynamic Inventory.
- Flexible access control system. Integration with LDAP / SAML / Active Directory, etc.
- Native email / Slack / PagerDuty / HipChat / MatterMost / IRC notification support.
- Integration with external log aggregation systems: Logstash / Splunk / Loggly / Sumologic.
Installation
Currently, several installation options are supported:
- Kubernetes.
- Openshift
- Docker / Docker Compose.
All of them are described in the documentation on GitHub , and for example, consider the option with a clean Docker, since this is the fastest option that does not require additional configuration of OpenShift / Kubernetes.
We will install everything on Centos 7. Docker's installation is also described in the official documentation , so we will not touch it in the article.
Next, we need to install the ansible and docker-py module. This can be done from pip:
pip install ansible pip install docker-py Clone the AWX repository:
git clone https://github.com/ansible/awx.git cd awx/installer Edit the file inventory. First of all, I recommend correcting the postgres_data_dir variable. By default, it is equal to / tmp / pgdocker, but if left in this form - after some time, you can lose the postgresql database that AWX uses.
If you want to use an external database, specify the variables:
pg_hostname pg_username pg_password pg_database pg_port After this, run:
ansible-playbook -i inventory install.yml This command will start the playbook execution, which will load the required docker images and launch the containers directly with AWX and additional components: Postgres, MemCached, RabbitMQ.
After the completion of the playbook, we should see the following containers:
docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES b1bd94f83420 ansible/awx_task:latest "/tini -- /bin/sh ..." 6 days ago Up 6 days 8052/tcp awx_task abf30fd81335 ansible/awx_web:latest "/tini -- /bin/sh ..." 6 days ago Up 6 days 0.0.0.0:80->8052/tcp awx_web b13ee3c7cbb7 memcached:alpine "docker-entrypoint..." 2 months ago Up 6 days 11211/tcp memcached 3c4cac5a4ce5 rabbitmq:3 "docker-entrypoint..." 2 months ago Up 6 days 4369/tcp, 5671-5672/tcp, 25672/tcp rabbitmq b717c6019e02 postgres:9.6 "docker-entrypoint..." 2 months ago Up 6 days 5432/tcp postgres You can follow the AWX installation process as follows:
docker logs -f awx_task AWX will be available at the server address on port 80 (if you did not change the port in the inventory file).
Default login and password:
Admin:password Use and examples
We now turn directly to AWX, but first we will deal a little with how everything is organized.
First of all, we are interested in the Projects section. Projects in AWX terminology means a collection of playbooks that are located locally on a server with AWX or in a repository.
Let's create our first Project:
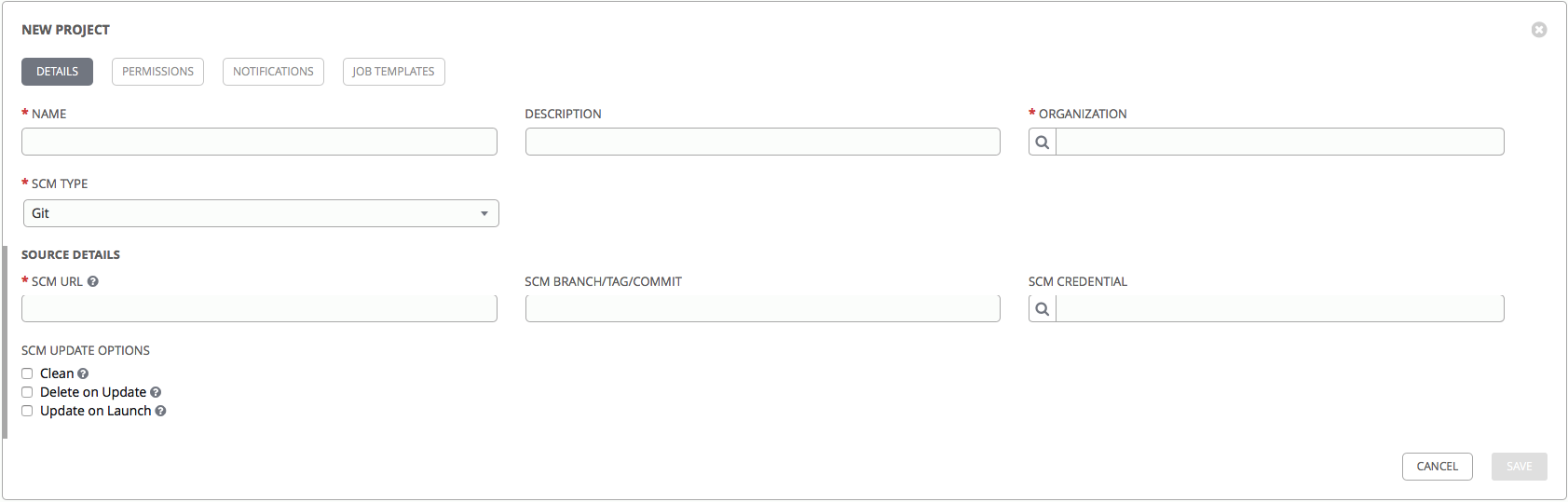
- Name: the name of the project, let it be firstproject.
- Organization: in AWX, this is the entity that is used to delimit access. Organization may include inventories, users, user groups, playbooks. Choose Default.
- SCM TYPE: repository type, can be either a local directory, or one of the version control systems to choose from: git, mercurial, subversion.
- SCM Url: URL for the repository.
- SCM branch / tag / commit: optionally, you can specify the desired branch / tag / commit.
- In the field SCM credentials, you can select the details that will be used to access the repository.
You can also check the checkboxes:
- Clean: delete all local changes before updating.
- Delete on Update: when updating Project, delete the local copy and reload the new copy of the repository.
- Update on Launch: every time you start a playbook from this Project, update the local copy of the repository to the current version. It can be used in conjunction with Delete on Update, but this may lead to a longer execution of the playbook, since each time you need to wait for the end of synchronization with the repository.
Choose Clean and Update on Launch. Click Save and after that the creation of our first Project is completed.
Go to the Projects section and for our Project, click on the Start an scm update button. Let's wait for the completion of the first download of our repository (you can monitor the status of the update in the Jobs section).
Let's look at the playbook, which is in our repository. On Habré there are many articles in which it is told about Ansible and the structure of his playbooks / roles, therefore we will not detail this moment (here are some articles for example: 1 , 2 , 3 ).
firstproject/ ├── ansible.cfg ├── group_vars/ ├── host_vars/ ├── roles/ │ └── requirements.yml └── run.yml AWX files that are located in the root of the firstproject directory are .yml files as playbooks.
Contents of the run.yml file:
--- - name: Test Role hosts: - all gather_facts: true roles: - roleawx That is, we simply start roleawx, after collecting facts. Hosts we specify all as it is possible to specify hosts and host of group in AWX.
Next interesting point is the contents of the roles / requirements.yml file:
- src: git@gitlab.example.com:ansible-roles/roleawx.git scm: git When synchronizing Project, AWX will install all roles into the roles directory in accordance with the requirements.yml file. In this case, it will establish the roleawx role from the git repository.
Create a role using the command:
ansible-galaxy init roleawx The role structure will be as follows:
roleawx/ ├── README.md ├── defaults │ └── main.yml ├── files ├── handlers │ └── main.yml ├── meta │ └── main.yml ├── tasks │ └── main.yml ├── templates ├── tests │ ├── inventory │ └── test.yml └── vars └── main.yml Contents of tasks / main.yml file:
--- # tasks file for roleawx - name: Test Message debug: msg: "AWX and Ansible" To start, just display the message “AWX and Ansible”.
Note that in order for AWX to automatically install the roles specified in the requirements.yml file, the meta / main.yml file must be correctly formed in the role itself (if you created a template for the role using an ansible-galaxy init, then with meta / main .yml is fine and AWX will be able to load this role).
So, we have a repository with a playbook, there is a repository with a role. And we also have several virtual machines with addresses 192.168.10.233, 192.168.10.234 and 192.168.10.239.
Before launching our playbook, we need to ensure that Ansible can get from our AWX server to our hosts (in our case via SSH). We can specify passwords directly in the variables inside the playbook, but this is not interesting. AWX is able to manage the details for access to the servers and we will use this.
Go to the Credentials tab and click the Add button:
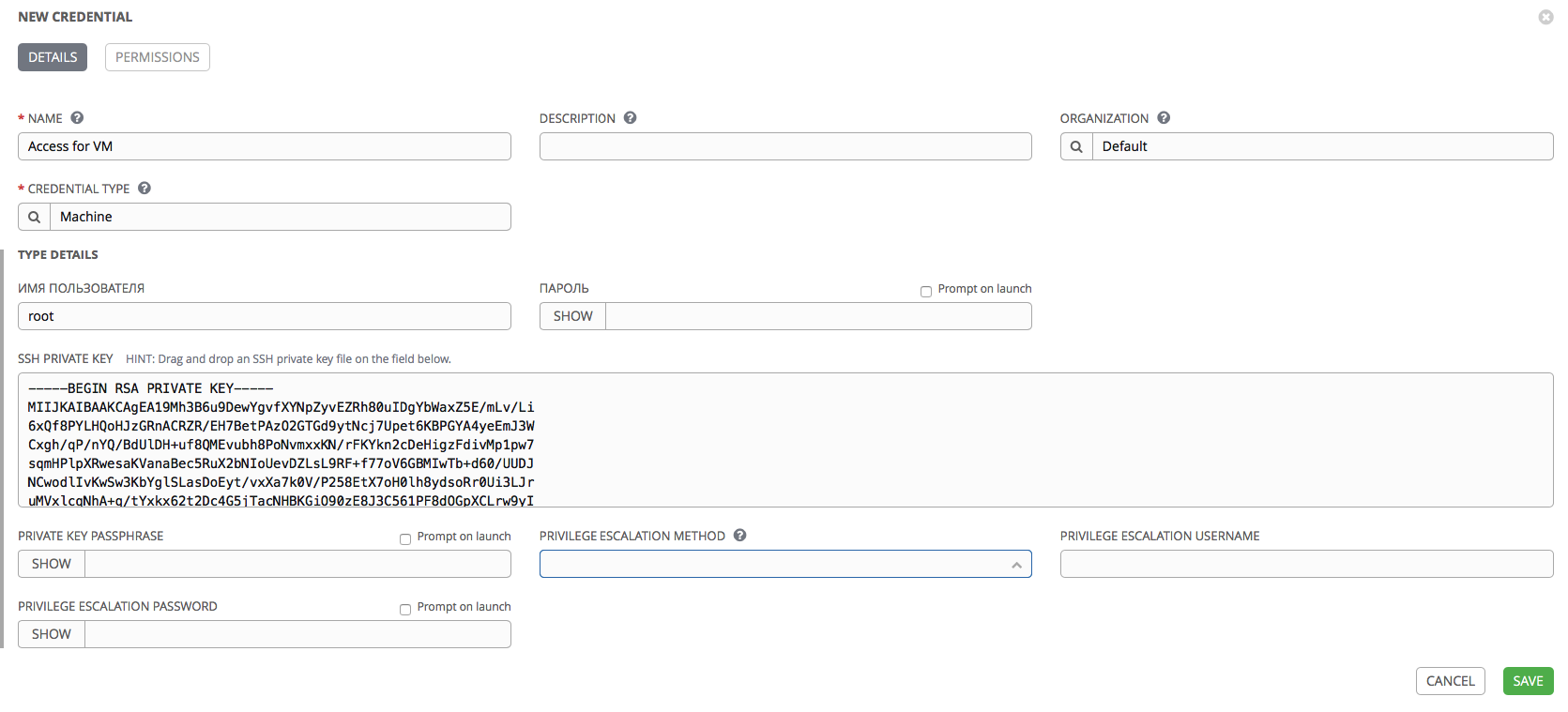
- Name: specify the name for our details.
- Credential Type: here you can select the type of details. We are interested in Machine to use them to access our servers. In addition, AWX offers many different types of access details that can be used to integrate with various services such as scm (git, svn, mercurial), Red Hat Insight, AWS, Azure, Red Hat Satellite, RHEV, Vmware, OpenStack. You can also create your own credentials types.
- Username: choose root.
- Password: leave blank, since we will use access by key.
- PRIVATE KEY PASSPHRASE: password for the key, if the key is created with a password. In our case, the key is without a password, so the field is left blank.
- PRIVILEGE ESCALATION METHOD: privilege elevation method. For example: sudo, su, pfexec, etc.
- PRIVILEGE ESCALATION USERNAME: the user under which Ansible should receive privileges.
- PRIVILEGE ESCALATION PASSWORD: password for privilege escalation.
We will leave the fields associated with the escalation of privileges empty, since we will be logged in as root.
Please note: a number of fields have the Prompt on launch checkbox. When you activate this checkbox, you will be asked to fill in the corresponding field manually each time you start the playbook with which these details are associated. Thus, it is possible not to save the password inside AWX, but to request it every time a playbook is launched.
So, we created Project and details for access to servers. Now we need Inventory.
Go to the Inventory section, click the Add button. The choice will be asked to create:
- Inventory: normal Inventory.
- Smart Inventory: allows you to generate inventory based on existing hosts, based on any parameters, for example, the type of operating system.
Create a regular inventory:
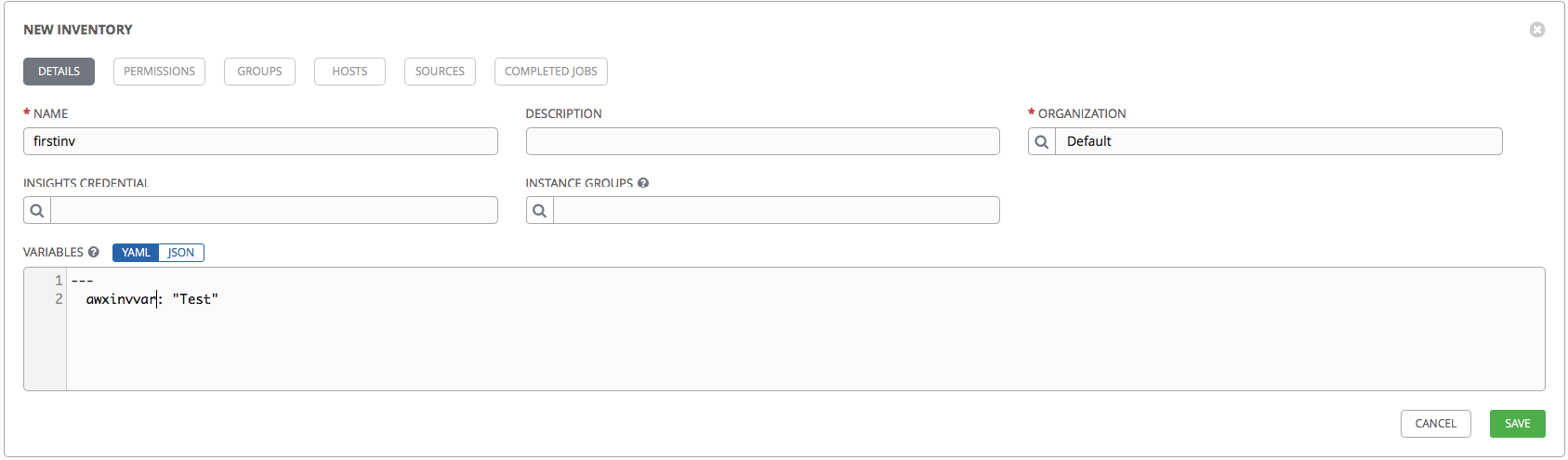
- In the Name field specify the name.
- Select the Default Organization.
- In the Variables field, you can specify variables that will later be available from the playbook.
We try to specify:
--- awxinvvar: "Test" The remaining tabs are inactive until we save our Inventory.
Save and return to the Inventory section. Our inventory appeared in the list. Go to it: after creating the top tabs have become active.
- Permissions: control over which user or user group has access to Inventory.
- Groups: list of host groups.
- Hosts: list of hosts.
- Sources: a list of sources for Inventory. You can unload inventory from AWS / Azure / OpenStack / RHEV and a number of other services, you can specify the inventory file that is inside our Project or you can specify your own script as the source, which generates Dynamic Inventory.
- Completed Jobs: list of running playbooks associated with hosts from the current Inventory.
We fill our inventory with hands, as we have few hosts. Go to the Hosts tab and create several hosts:
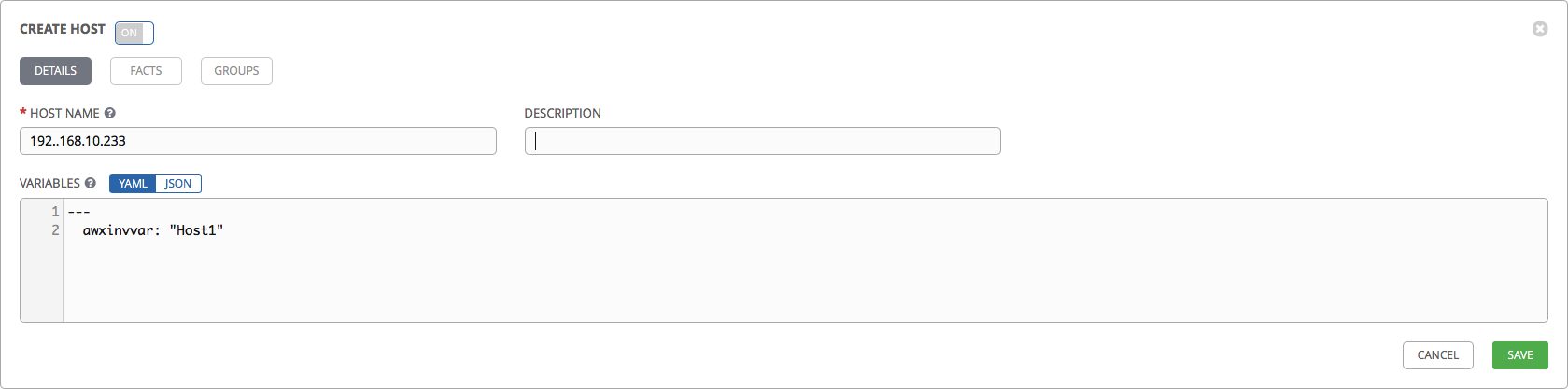
- In the Host Name field, you can specify the IP address of the server or its DNS name.
- In the Variables field, we try to override the awxinvvar variable for one of our hosts:
--- awxinvvar: "Host1" After creating the hosts, go to the Groups tab and create groups for our hosts:
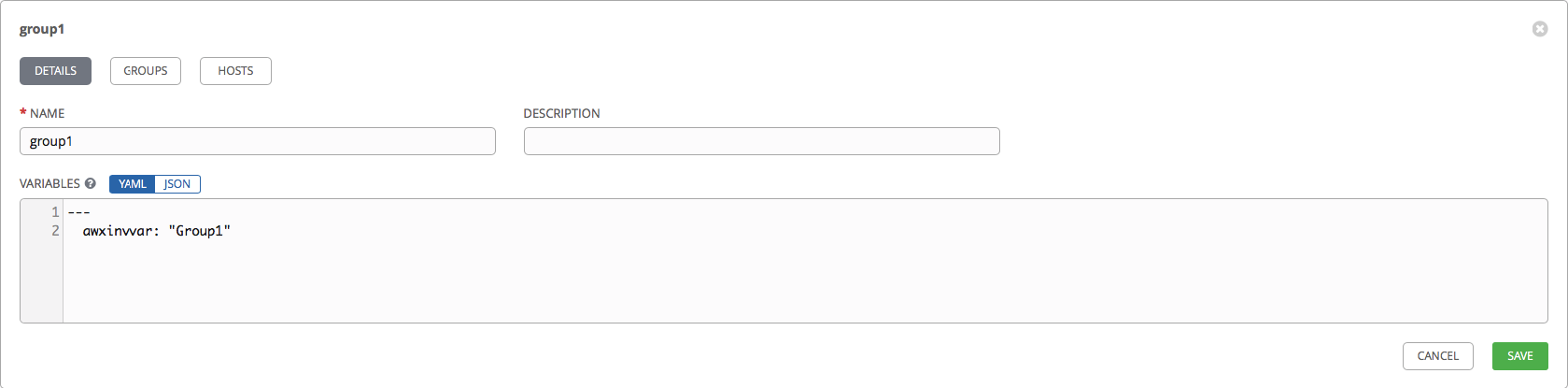
In the same way, we specify the name of the group and override the variable awxinvvar for one of the groups.
Go back to the Hosts tab, select one of the hosts from the list, go to the Groups tab for this host and click Associate Group:
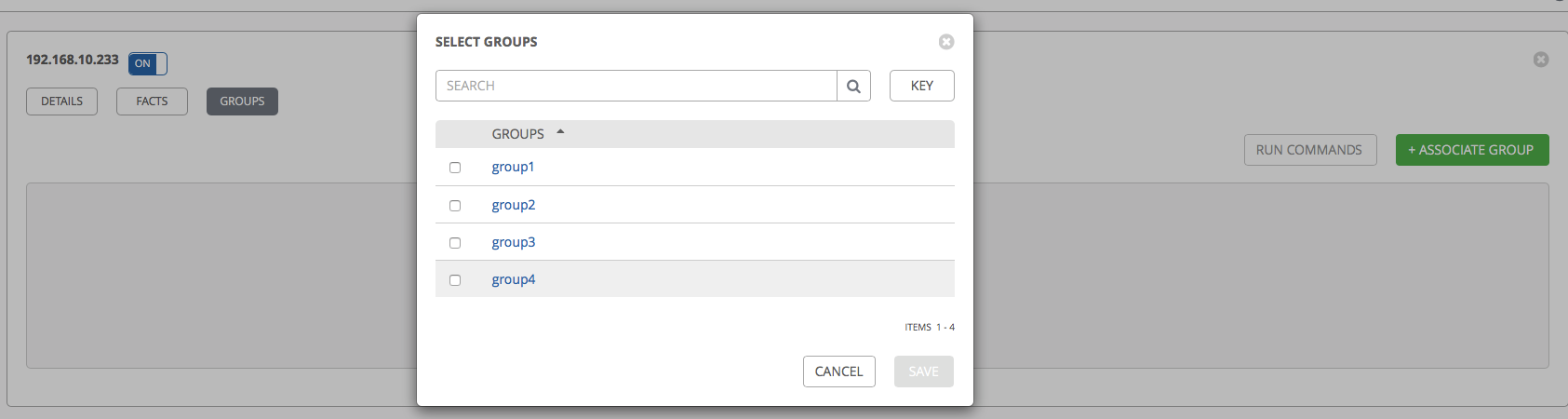
In the Hosts tab, you can now see which groups each host is in:

By the way, the Run command button is also available on the Hosts and Groups tabs. This is an analogue of ad-hoc commands in Ansible, which allow you to perform actions on remote hosts, without a playbook.
Let's try. Select our hosts from the list, select the SSH access key that we created earlier and try to execute the date command using the shell module:
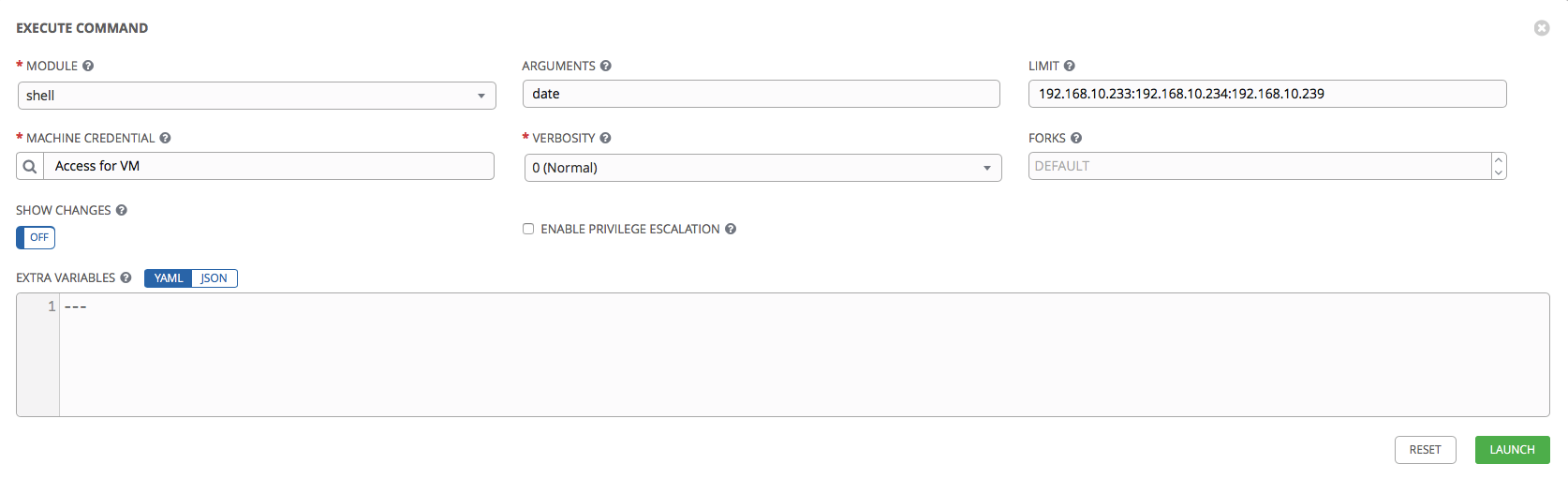
Click Launch. We should be transferred to a page where we can monitor the implementation in real time. Also, all startups of playbooks / ad-hoc commands are visible in the Jobs section.
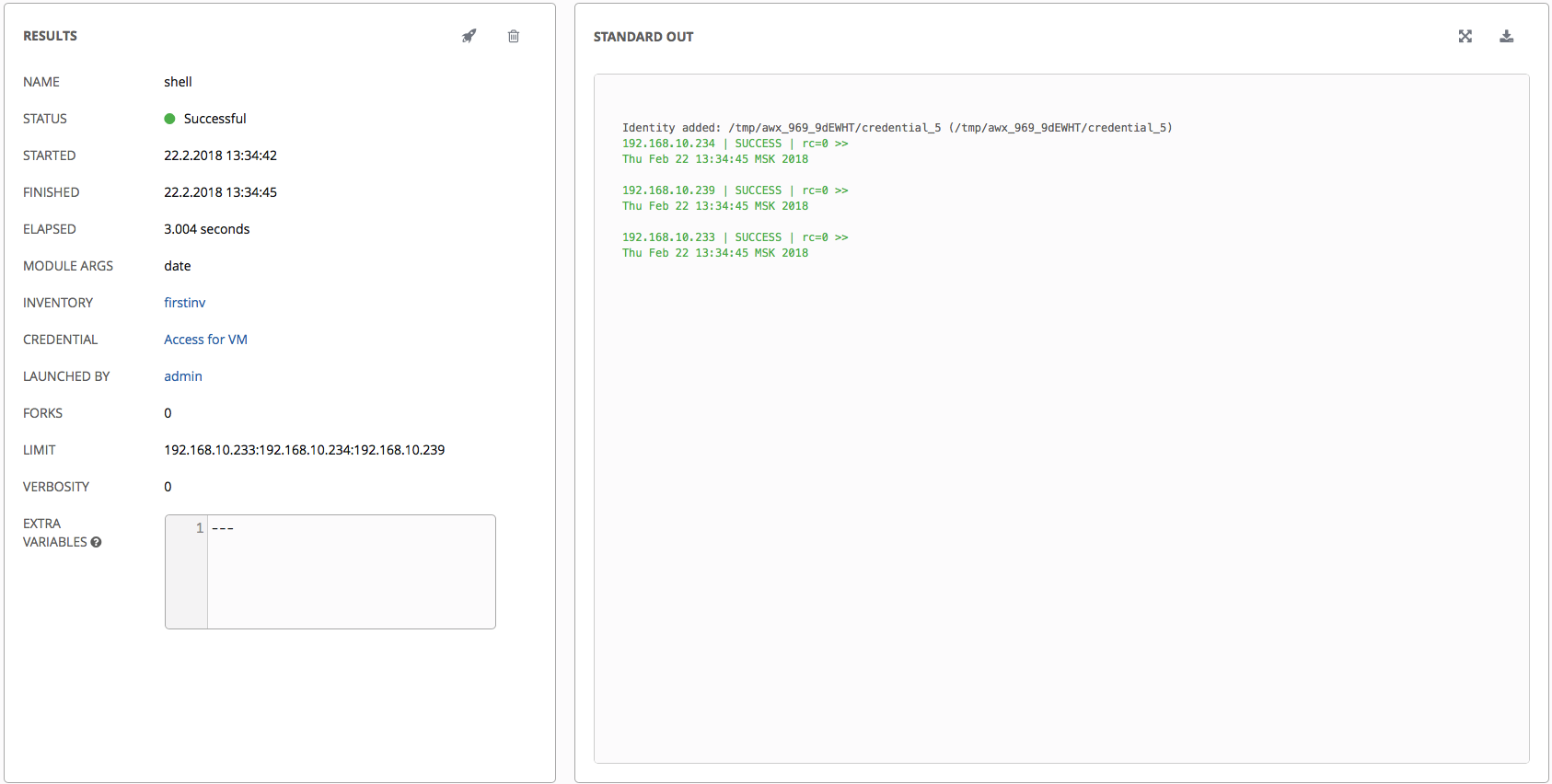
Our ad-hoc team successfully completed.
Let's now try to run our playbook. Go to the Templates section, click the Add button, select the Job Template.
In terminology, AWX Template is a set of parameters that are used to launch a playbook. In the minimum form, you must specify the name of the template, select the project, select the playbook, select inventory.
Template creation looks like this:
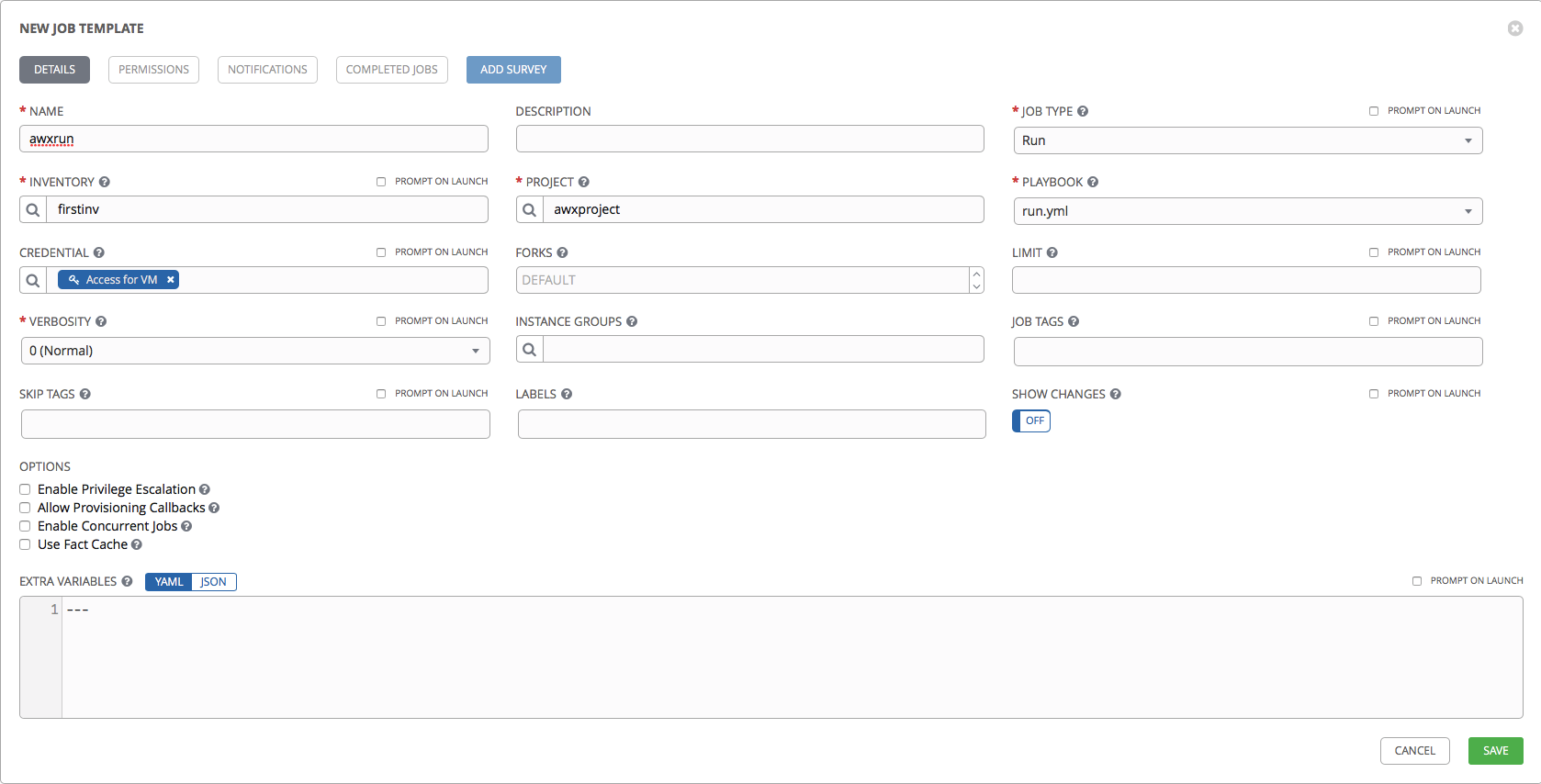
- Name and Description: the name and description of the template.
- Job Type: Run or Check. That is, starting the playbook or just checking the playbook (dry-run) without making changes.
- Inventory: Inventory with which the playbook will be launched.
- Project and Playbook: designed to select a Project with playbooks and a specific playbook from Project.
- Limit: list of hosts and groups on which the playbook will be launched.
- Verbosity: how much detail Ansible will output the result of execution (analogue of the keys -v -vv -vvv).
- Job tags: list of tags - tasks that should be run. If not specified, all tasks described in the roles will be performed.
- Skip tags: list of tags - tasks that will not be performed.
- Labels: tags that will be associated with this template. Can be used to filter in the AWX itself.
- Show diff: show the changes that Ansibl makes (the analog of the --diff key).
Save the project, go back to the Templates section, and launch our playbook (the button is in the form of a rocket):
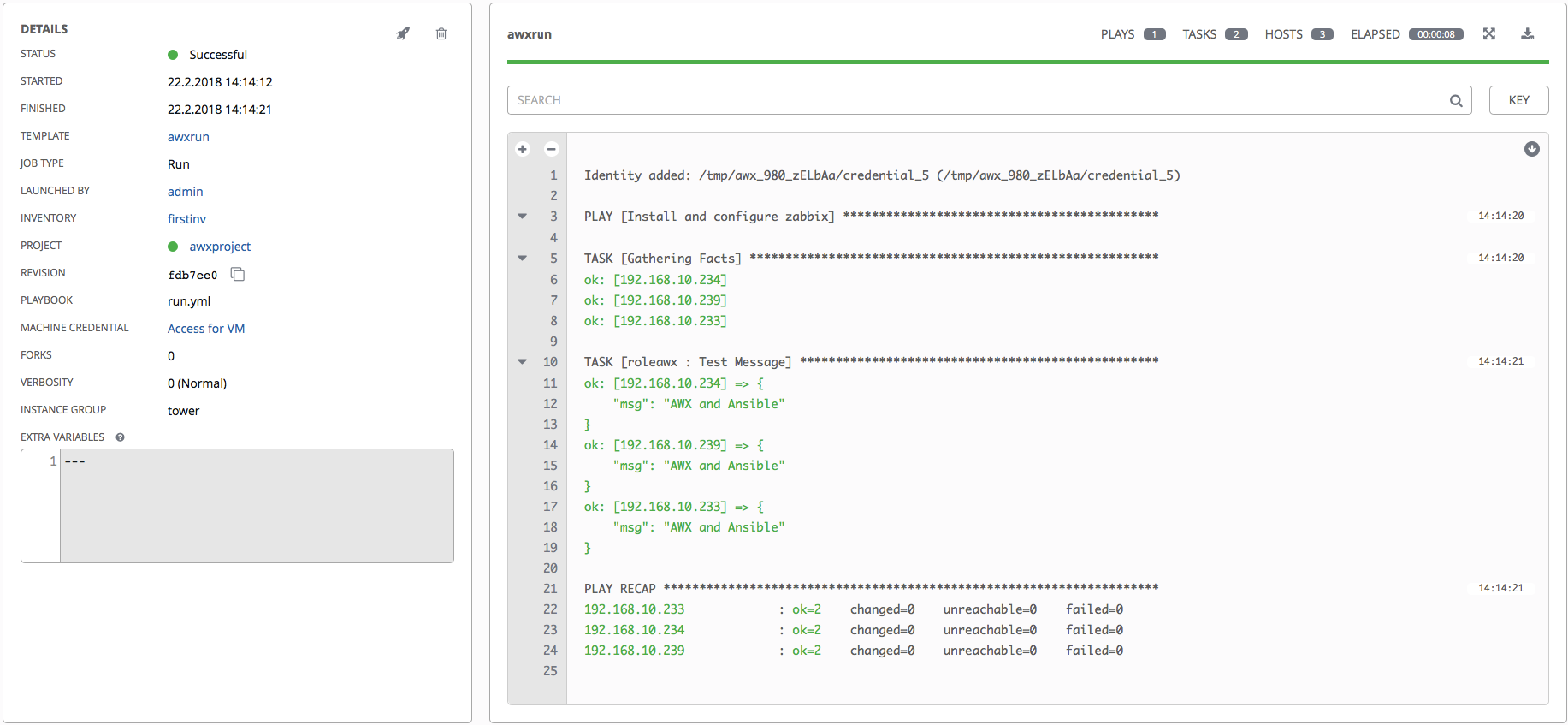
Hooray, our playbook started, loaded the necessary roles and successfully worked. By the way, on the same page you can download the result of the playbook. It is also possible to search for the output of the playbook.
Remember we added the awxinvvar variable in several places? Let's try to bring it in and see what happens.
We add the following to our role in the tasks / main.yml file:
- name: Print var debug: msg: "{{ awxinvvar }}" And again we launch our template.

Playbook sees our variable, which we defined in the Inventory and correctly redefines it in accordance with the priority of the use of variables .
Variables, by the way, can also be stored in the repository in the host_vars group_vars directories, if that’s convenient for you. However, in this case, they will not be displayed in the Inventory in the AWX.
Instead of conclusion
AWX we have been using for several months and for now everything suits us. Of course, since this is a new project, we occasionally meet with various kinds of problems (mostly minor bugs in the interface), but they are not critical and do not interfere with work.
Note: New releases are now coming out often and there may be problems when updating. Make backups!
This manual is written to familiarize you with the basic features of AWX, and if it’s interesting, we’ll write about additional useful features, such as integration with sources for Dynamic Inventory, callback mechanism, etc.
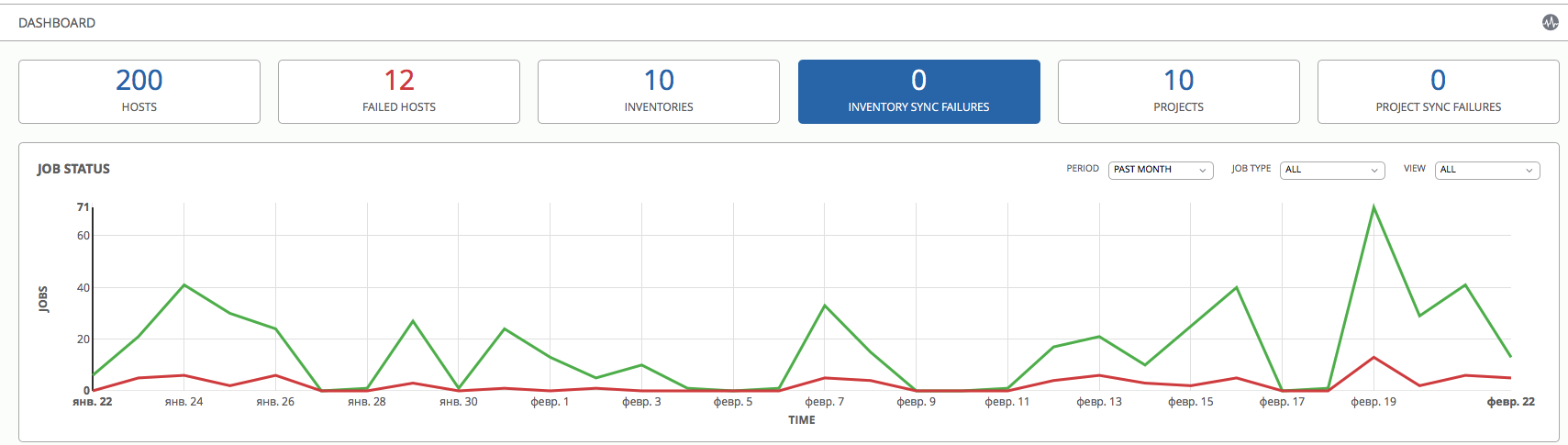
PS This is, by the way, our AWX dashboard, which we use for a part of the infrastructure:
Source: https://habr.com/ru/post/352184/
All Articles