Artificial Intelligence and Neural Networks for .NET Developers
Artificial intelligence is now one of the most discussed topics and the main engine of digital business transformation. Microsoft’s AI strategy includes democratizing AI for developers, i.e. providing easy-to-use frameworks and services for solving intellectual problems. This article describes how .NET-developers can use the capabilities of AI in their projects: from ready-made cognitive services running in the cloud, to learning neural networks in .NET-languages and running complex neural network models on compact devices like Raspberry Pi.
The prototype of the article was the presentation by Dmitry Soshnikov at the DotNext 2017 Moscow Conference. Dmitry is a technological evangelist of Microsoft, which is involved in the popularization of modern software development technologies among novice developers. He specializes in the field of the Internet of Things, in the development of universal Windows applications, in the field of functional programming and on the .NET platform (F #, Roslyn). I personally spent dozens of hackathons throughout Russia, helped many student startups to start their projects in various fields. Associate Professor, Ph.D., leads classes at MIPT and MAI, a member of the Russian Association of Artificial Intelligence, in the summer - the leading chair of computer technology at the UNIO-R children's camp.
Caution traffic! In this post there is a huge number of pictures - slides and screenshots from a video in 720p format.
In this article we will talk about artificial intelligence. Why is it fashionable to talk about him now? Because it is a range of technologies that is changing the world very quickly.
Such an example of changing the world is McDonalds. And in America, and we have MacAuto. We have a man sitting there who takes orders. And already 20 years ago in America it was decided that there is no need for a person there, you need to replace it with an operator who sits in India - it will be much cheaper. He will talk to visitors on the phone, drive it all into the computer, the order will be prepared, and the American will not have to pay. The American sitting in the window is very expensive. Such a solution has reduced prices: hamburgers have become cheaper, people have become less healthy - all is well. The last step in this direction was taken when they realized that a person was not needed there at all. You can take it and replace it with a speech recognition algorithm. Such a project more than a year ago did our colleagues from the American Microsoft.
On the Internet there are videos in which you can try to make out what a person hears in the window of McDonalds, and feel the depth of the suffering of this person. He can not hear anything: there are noises, cars are passing, and he is forced to recognize it. It turns out that the AI does it better than a person, because a person gets tired.
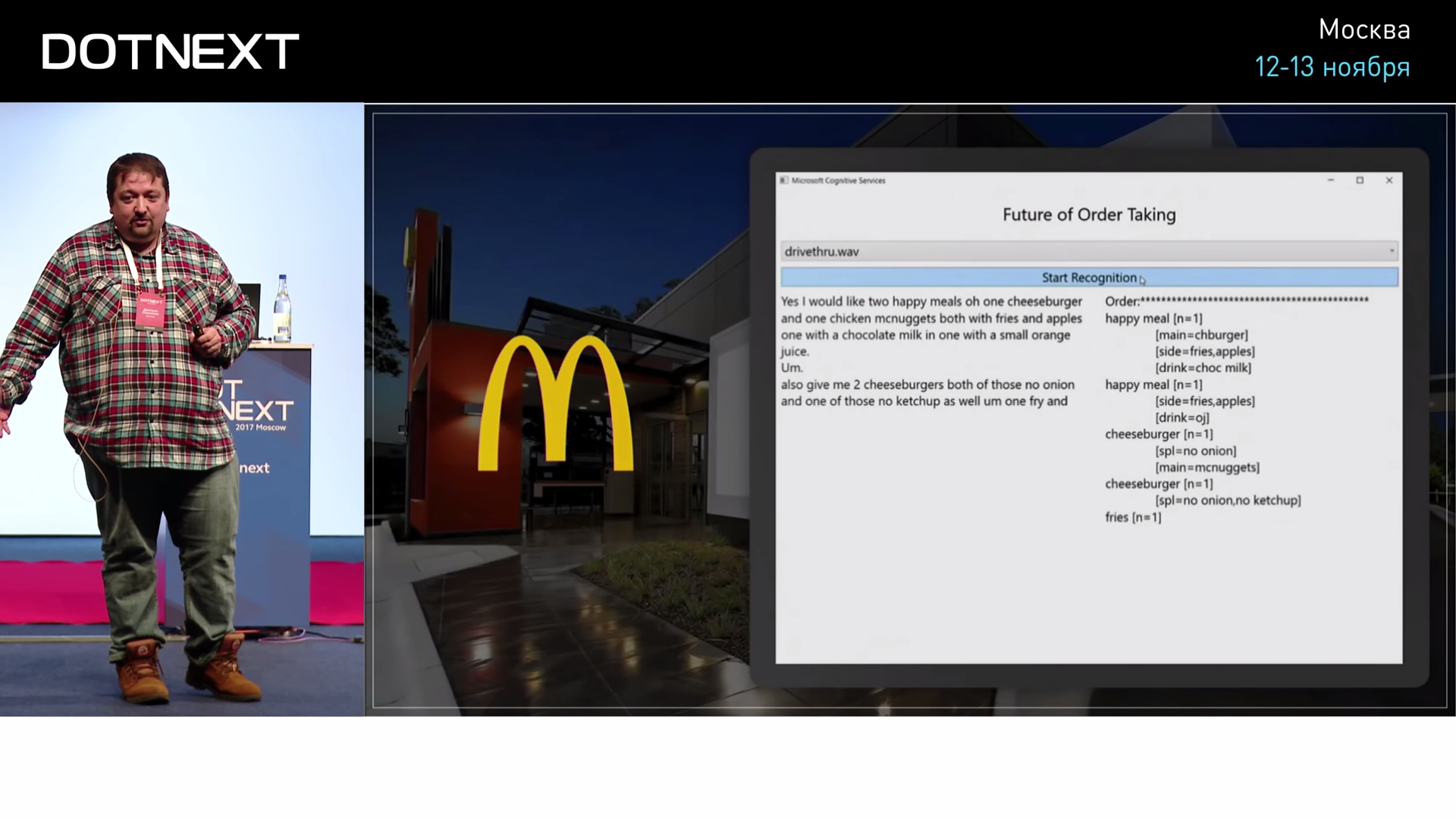
In the case of ordering, the conversation with the operator goes on a completely specific topic; no one will talk about the meaning of life with such a window. When the menu is clear, when the words are clear, the computer recognizes the person better. In 2016, Microsoft made a statement that they finally made a speech recognition algorithm that works better than humans. He was tested and confirmed that it was really better.
In 2015, the computer began to recognize certain images - road signs. Conventionally, out of a thousand pictures, a computer finds road signs better than a person. Why? Probably, it bothers a person somewhere in the middle, but not a computer. But the result is the result: the computer copes better with such tasks.
Here is a list of Microsoft's achievements in the field of AI, they are impressive.

Microsoft is ahead of the rest. Now research is being conducted on how to use FPGA chips programmed in the cloud in order to run neural networks on them. The range of solutions here is big.
What is the overall strategy of the company? What is Microsoft doing in the field of AI?
First, of course, injects into products. Power BI, HoloLens - a lot of recognition is now attached to it. And in PowerPoint there are many places where AI is used. For example, there is a button “design a slide for me”, it is called “Design ideas” and offers design for simple slides. This is the result of machine learning and the use of AI technologies. Or if you insert a picture in PowerPoint, it is generated a signature in a natural language - what is shown on it. So that later, if you export it somewhere on the web, the corresponding tags were correctly inserted. It would seem a trifle, but nice.
AI is introduced into products, research is being carried out, how it can be used more effectively in the cloud, and - most importantly for developers - the democratization of AI is happening to make it easier to use.

There are cognitive services. They can simply be used for basic tasks that have to be solved, such as image processing. For example, we want to introduce in our product such functionality that it automatically inserts a caption to the picture. It is easy - there is a ready-made cloud service: we give it a picture, it returns the description in English. If we want to introduce machine translation into our product, everything is also very simple: we use the Bing Translator service, we receive translation from almost any language into any language. These features are available to everyone.
Within the framework of democratization, there are four main areas: cognitive services, bots, machine learning - Azure ML, neural networks - Microsoft Cognitive Toolkit. Let us dwell on the last two.
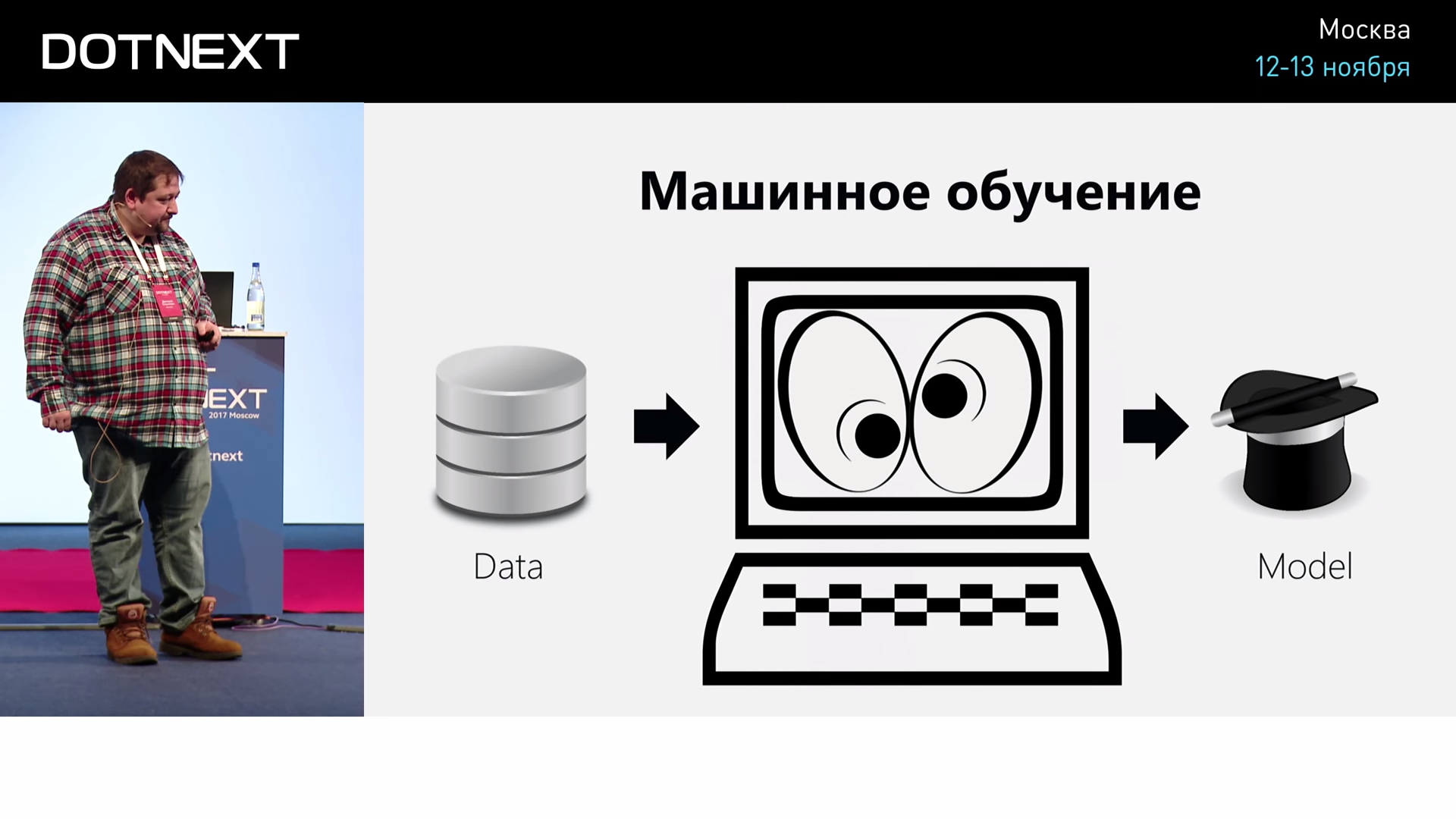
The basic idea of machine learning is that the computer on the data itself learns how to do something.
For example, we want to learn to recognize a person’s emotions from a photograph. How can I do that?

If we think about how to write an algorithm, it is clear that we will very quickly get into a dead end. For example, we do not quite know how to accurately distinguish surprise from fear: the eyes are round in both cases. It is not clear how to do this algorithmically. And if we take a lot of photos, then, probably, we can somehow automatically do it on them. How? Firstly, it is important for us to identify some basic signs from a photo — go to some numerical indicators. Because photography is an abstract thing with many details. But we can, for example, recognize the position of the eyes, the position of the corners of the lips, go to the numerical things that can be presented in a table. Then it can be submitted to the input of machine learning, so that the algorithm finds a pattern in them and builds a model, which can then make predictions to us. Then we take the face, select the same signs in it, feed the model to the input, and the model tells us that, for example, this is a person who is 80% happy, 20% something else.

If we talk about terminology, then artificial intelligence is a common topic in which we do something that copes with human tasks. Machine learning is a part of AI, when the algorithm is not written by us, but it is written on the basis of data processing. Neural networks are one particular case of machine learning. And inside the neural networks there is still a trendy term “deep learning”, when neural networks are deep. In general, neural networks are now crowding out the rest of the algorithms, because many complex problems are solved with the help of this very “deep learning”.

As for the tools: how do people who do deep learning live? They have two languages: Python and R. Why did Python become popular for data scientists? It so happens that there are some very good libraries written, naturally, in C ++ (because otherwise they would be slow), but for which there is a very good Python wrapper. And so it turned out to be convenient to use Python as gluing together different libraries. And since there are already many libraries for machine learning, it so happened that you can just pick them up and start using them.
For neural networks the same. When everyone started to implement their libraries, they thought: "All data scientists write in Python, so we also need to do all the libraries in Python." So there was a large number of libraries that support Python. Even Microsoft has made support for Python for our CNTK library, and has not done .NET support for a long time.
The R language is still more interesting: R has a ready-made Comprehensive R Archive Network, in which there are a bunch of ready-made libraries for all occasions. You just need to learn this language and one hundred thousand other libraries.
And what about a person who has never come across this?

On the one hand, you can go to study, but you don't want to. Since I have to work with neural networks, when I work with Python, I’m not exactly deeply disgusted, but it’s hard for me. Psychologically, it is very difficult after typed beautiful .NET languages to switch to an untyped language, in which errors are not checked and they become clear when you are already running everything. Feeling as if you program without a hand.
Let's see what tools are in the .NET world in order to solve the problems of machine learning and training of neural networks.

Let's start with the question: “Is it difficult to write something yourself? What if it's easy? "
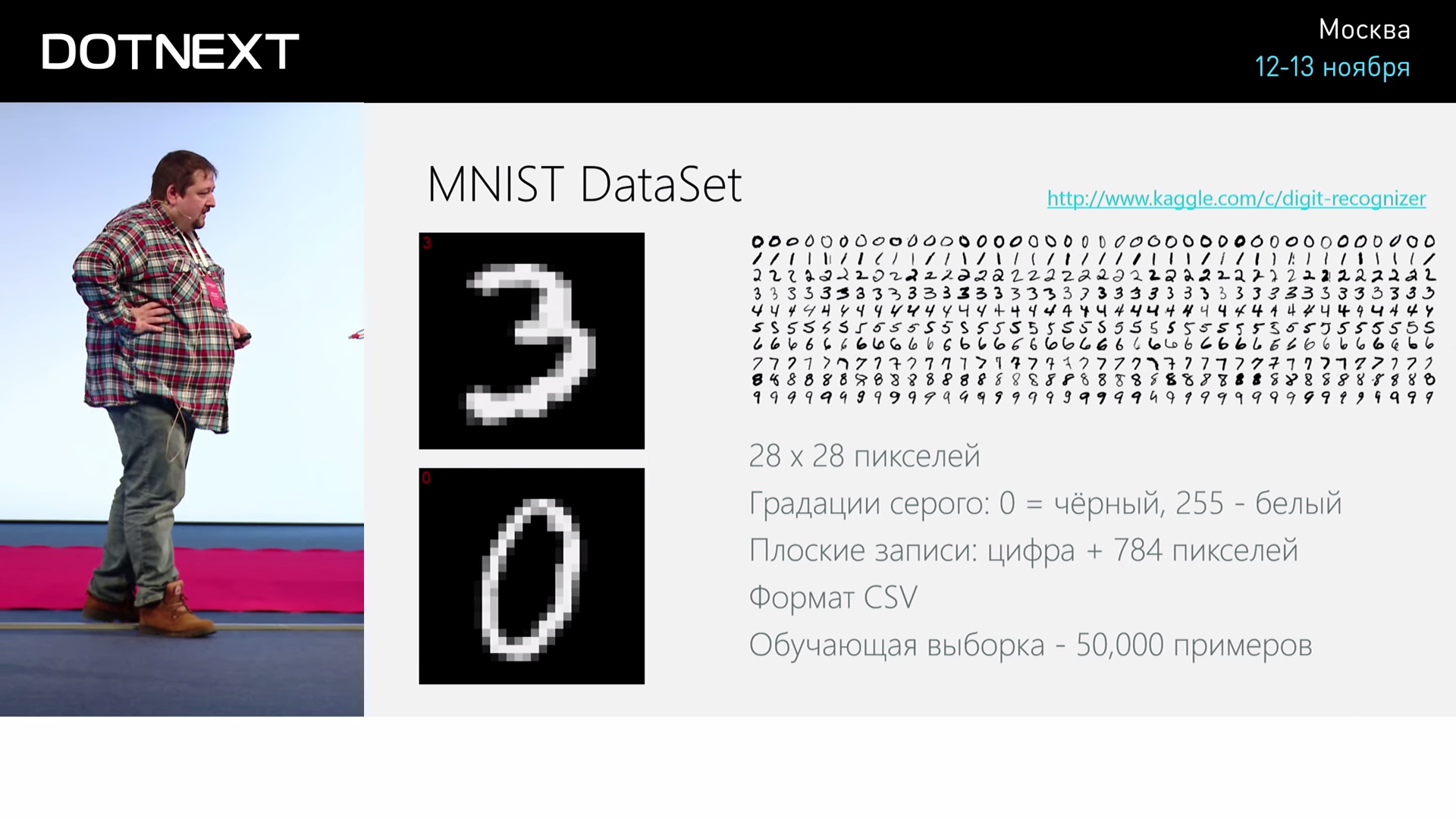
And take this classic task: recognizing handwritten numbers. There is a ready dataset out of 50000-70000 handwritten numbers, which were written by some employees of the US statistics department. This data is publicly available and they are presented as 28 by 28 pixel images. This task seems to be not too difficult, but, on the other hand, it is not too simple, some not quite toy, not forecasting the price of an apartment in Moscow. It is not very clear how to approach it. Let's see how this problem can be solved and how effectively and well it can be done.
What is the simplest solution that comes to mind? We have 50,000 examples, then someone wrote some number and said: “And what is this figure?” How can we figure out which one? We can simply compare with all 50,000 and take the one that best suits. How to compare? You can read the difference in brightness in pixels.

Such an algorithm is called “K Nearest Neighbors” with K equal to 1. Let's see if it is difficult to program it.

At the same time, I will show you one good tool that all data scientists use is called Jupyter Notebook. This is a very handy tool that allows you to combine program text on the web with some text written in Markdown. It looks like this.
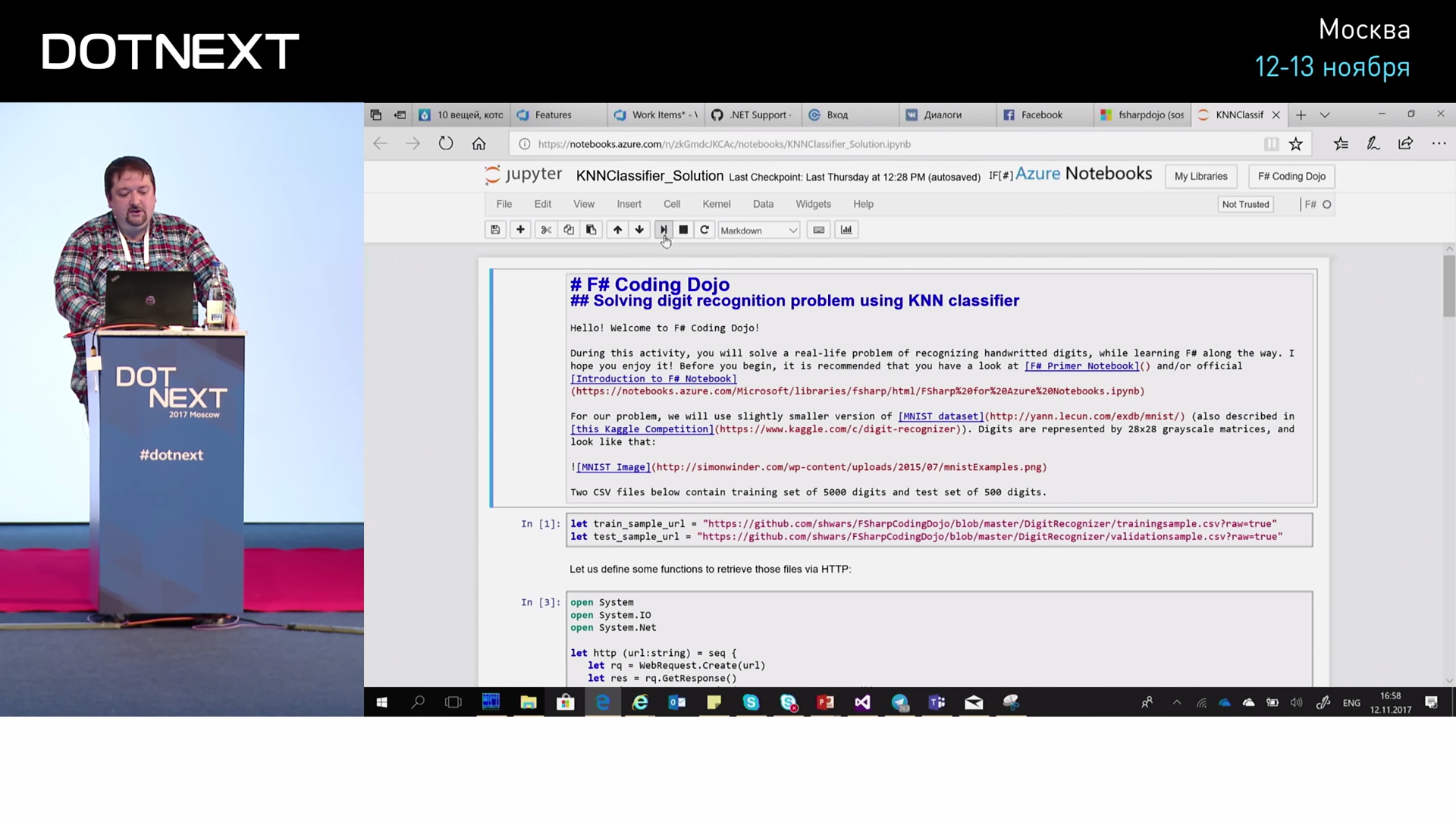
I have a cell-text, then there is a cell-code that I can execute. Since Jupyter Notebook is a tool from the Python world, it supports Python and R well, but you can tie it to support other languages: C #, F #, even Prolog. At the same time, Microsoft said: “And let us present these Jupyter Notebooks in our cloud ready.” On good, if you want to install it yourself, you need to put Python, Jupyter on your computer, run it all and continue to open it in your browser. And Microsoft provides ready-made Notebooks in the cloud, you go to notebooks.azure.com - and you can start working: log in with your Microsoft account and you can create these same Notebooks with code. This code will be executed in the cloud for free, but with certain restrictions. For example, data can be taken only from certain places: from the cloud or from GitHub. These Notebooks and Microsoft support Python, R, and F #. C # is not, and F # is supported. Why? Because F # is better?
Actually, because for F # there is already ready beautiful good support. For C # there is a similar tool called Xamarin Workbook. This is kind of a similar thing, it works locally on your computer, but it also allows you to combine code with text. Combining the code with the text is very cool, because everything is clear right away, all the steps are described.
We take these images of numbers, which are presented in the form of CSV (Comma-Separated Values). At the same time, in each line the first element is the written number itself, and the rest is an array of 784 numbers, each of which is the brightness of the corresponding pixel. And this matrix of numbers is laid out in a long line of numbers. I described on F # a function that takes these values from the Internet, reads and returns us such long lines.
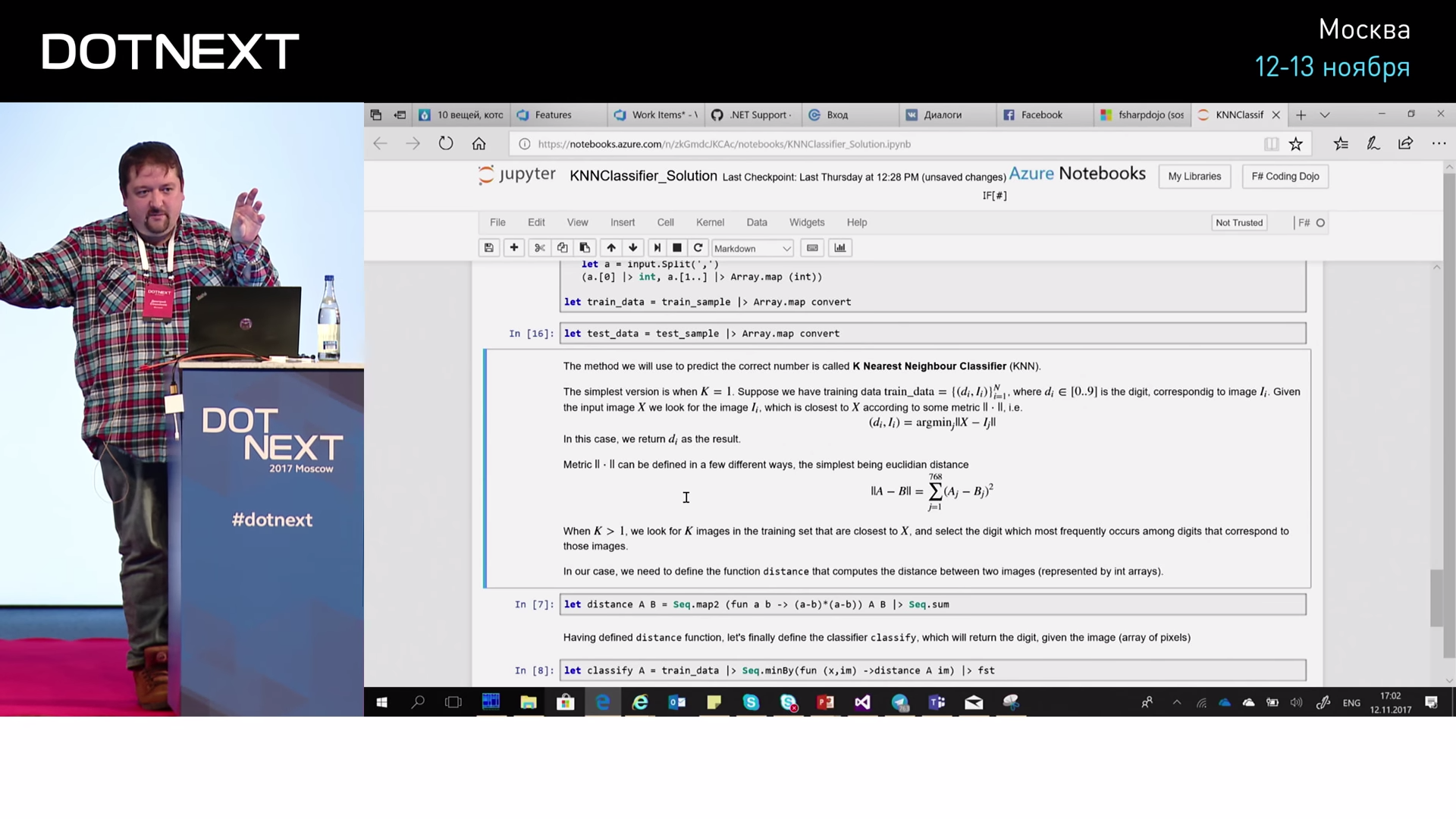
Now, in order to do something about it, we will put it into arrays and divide it into two parts: we will have train_sample — this is a training sample, and test_sample — this is for testing. Conventionally, we will take 50,000 trainers and some thousands for verification. And we bring them to a convenient form: we will present them in the form of pairs. In the pair we will have a digit and an array of the remaining pixels. And there are many such couples.
Next, how do we find the nearest one? In order to find the closest one, we need to determine the distance. To determine the distance, we describe the distance function, which takes two arrays with images, traverses these arrays, counts the difference of squares and then their sum. That is, this Cartesian distance, we simply do not extract the root. It shows proximity: if the arrays are the same, it shows zero, if slightly different, there will be some number. And in order to find the corresponding figure, we take all our train_data - 50000 - then we search for which of them the minimum distance is, and take the corresponding figure. The code is simple. Then we run, and it works.

We take test data. In this case, I take the top three entries and try to recognize: the eight is recognized as 8, the seven as 7, two as 2. This is good, it inspires hope. If we go further through the entire test sample, we get 94% correct recognition. This is, in principle, very good.
94% - then you can do almost nothing, although we wrote only a few lines.
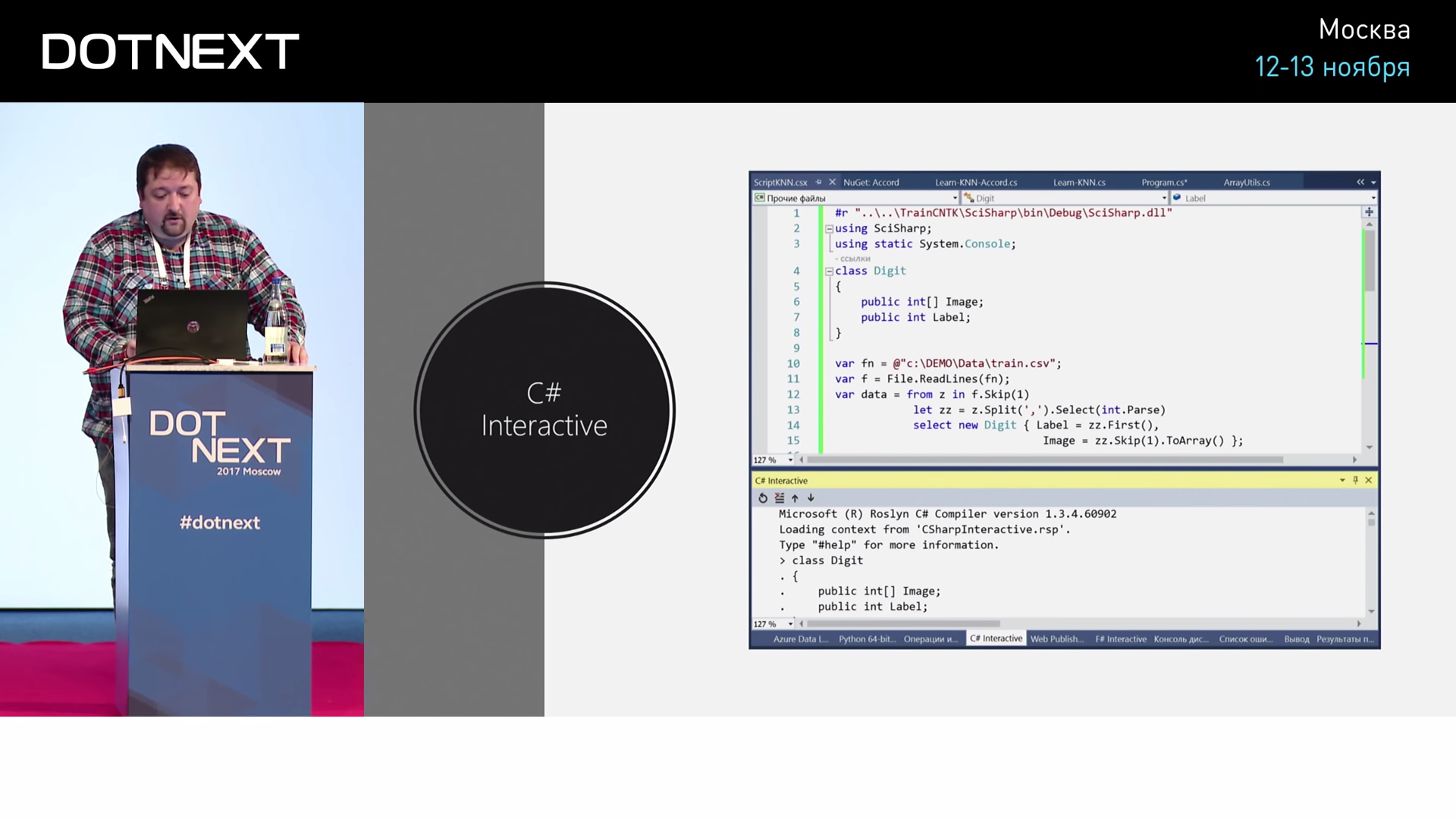
And if we want to do the same in C #?
Show if someone does not know. Visual Studio has a great tool called C # Interactive. This is a console in which you can execute C # directly like this: selected a piece of text, pressed a key and it is executed in the console. If I want to do the same in C #, what will it look like?
#r "SciSharp.dll" using SciSharp; using static System.Console; class Digit { public int[] Image; public int Label; } var fn = @"train.csv"; var f = File.ReadLines(fn); var data = from z in f.Skip(1) let zz = z.Split(',').Select(int.Parse) select new Digit { Label = zz.First(), Image = zz.Skip(1).toArray(); }; var train = data.Take(10000).toArray(); var test = data.Skip(10000).Take(1000).toArray(); Func<int[ ],int[ ],int> dist = (a, b) => a.Zip(b, (x, y) => { return (x - y); } ).Sum(); Func<int[ ], int> classify = (im) => train.MindBy(d => dist(d.Image, im)).Label; int count = 0, correct = 0; foreach (var z in test) { var n = classify(z.Image); WriteLine("{0} => {1}", z.Label, n); if (z.Label == n) correct++; count++; } That's all. Then I can run it and enjoy the result. Numbers are recognized slowly, because for each digit you need to view 50,000 records (in our case, not 50,000, but 10,000 records). Therefore, for the practical application of such an algorithm is not very well suited. We wrote it quickly, it works not so badly, but still very slowly. In general, it would be good for machine learning to build such a model that will work quickly, it will somehow encapsulate the essence of the process: not every time to compare it with all the initial data, but to find some regularity. Therefore, of course, it is better to use some other algorithms.

Thus, we smoothly proceed to the next episode.

In order not to program them yourself, you need to see if there are any ready-made libraries. And here it turns out that for .NET there is a good library called Accord.NET.

In order to do machine learning, we need to be able to operate well with matrices, statistics, various statistical functions. And Accord.NET contains the corresponding elements. There is a fragment that is responsible for statistics, there is an algorithm that is responsible for genetic algorithms, for neural networks, processing of sound, images. There are also useful features that allow you to build a graph. A data scientist often needs to take and see how data depends on each other.
For this, I will write a program, I have a blank in which WriteLine is written. This is the same code that already was. He reads all the data to me, breaks it into a test and training sample. And then I use Accord.NET to draw these numbers on the screen. There is such a beautiful feature - ImageBox.Show, which allows you to draw something.
#r "SciSharp.dll" using SciSharp; using static System.Console; class Digit { public int[] Image; public int Label; } var fn = @"train.csv"; var f = File.ReadLines(fn); var data = from z in f.Skip(1) let zz = z.Split(',').Select(int.Parse) select new Digit { Label = zz.First(), Image = zz.Skip(1).toArray(); }; var train = data.Take(10000).toArray(); var test = data.Skip(10000).Take(1000).toArray(); for (int i = 0; i < 5; i++) { ImageBox.show(train[i].Image.Select(x => x / 256.0).toArray(), 28, 28); } And now let's apply some learning algorithm to them. For starters, the same KNearestNeighbours classifier. How does it look on the Accord?
var classifier = new KNearestNeighbors(1); classifer.Learn( (from x in train select x.Image.Select(z=>(double)z).toArray()).toArray(), (from x in train select x.Label).toArray()); We simply say: “We want to create a KNearestNeighbours classifier with K equal to one”. By the way, in the KNN algorithm, what does this K mean? In the general case, we take not just the nearest available figure, but we take, for example, the five closest ones and look for the one that occurs most often among them. The number 4 can be similar three times by 4 and two times by 1. And then we take 4. The increase in this class makes the recognition a bit better, but it greatly reduces efficiency. Therefore, we take 1 and say: "Classifier.Learn. Please learn. And we give him our data. The data in this case had to be cut, because I had to separately transfer the matrix of images and separately the matrix of the corresponding numbers. This Accord is so arranged that two arrays are passed to it.
Then you can see how it works.
foreach (var z in test) { var n = classifer.Decide(z.Image.Select(t=>(double)t)).toArray()); WriteLine("{0} => {1}", z.Label, n); if (z.Label == n) correct++; count++; } It works, it seems, a little bit faster than what we saw before, but not much. If 5000 numbers wait so long it will be long enough. But the accuracy of recognition does not change, because we used the same algorithm. But we did not write it ourselves manually, but took the finished implementation.
What good is this approach? Now we can use some other classifier instead. For example, I will delete this classifier and take the so-called classifier Support vector machine. This is another class of algorithms.
var svm = new MuliclassSupportVectorLearning<Linear>(); var classifier = svm.Lean( (from x in train select x.Image.Select(z=>(double)z).toArray()).toArray(), (from x in train select x.Label).toArray()); How are they arranged? In terms of machine learning, this task is called a classification task, when there are objects and need to be assigned to one of 10 classes. And the Support vector machine takes these classes. If they are presented in some graphical form in the state space, it will be text, clouds of some multidimensional points. Imagine a point in space with a dimension of 784, each point corresponds to its own digit. They need to somehow be divided. The idea of the Support vector machine algorithm is to build such a plane that will as much as possible stand apart from the elements of these classes, which will best separate them. But it is best to separate in terms of perpendicular omitted. That is, any classification task is a task to build a plane that will be best divided. If we look at the perpendicular from the nearest point to this plane and minimize this distance, the Support vector machine will draw the corresponding plane.
We replaced just two lines. In fact, the name of the algorithm has changed.
Run, now the algorithm will take some time to learn. Here the situation is, in a sense, the opposite of what we saw. If the previous algorithm was not trained, it was just immediately ready to classify the numbers, but it did this for a very long time, because the work itself took place in the classification process, here this algorithm is first trained. He chooses the coefficients of these hyperplanes. And so a certain time passes while he does it. But then he begins to recognize very quickly. So fast that we can see in a few seconds how these 1000 or 5000 test data will all count. And we see that the accuracy is about 91.8%, a little less.

What is good Accord? There are many different algorithms in it, and it is very easy to try them, we can replace one algorithm with another, just by replacing the constructor, and further the principles of their work are quite similar. If you have a machine learning task, then this is a good second step to get started. The first step is Microsoft's Azure Machine Learning in the cloud, which does not require programming at all. There you can just visually experiment with the data. And the second step for those who know .NET is Accord.NET.

We understand that for the area where all sorts of libraries like SciPy or Scikit-learn are used in Python, their equivalent for the .NET world is Accord.NET.
Let's go to neural networks.

Let's talk a little bit about what neural networks are all about. The most important thing to know about them is that in recent years, many have considered neural networks to be synonymous with AI in general. When people say artificial intelligence, neural networks immediately pop up in their heads. All Microsoft cognitive services are based on neural networks and look like magic. Imagine: you give her a photo, and she describes what is depicted in English. How can I do that? In my opinion, this is a miracle.

But at the same time, from a mathematical point of view, we understand that this miracle is only a way of constructing some function that optimally approximates a certain cloud of points in a very multidimensional space. That is, it turns out such a strange situation: on the one hand, from the point of view of mathematics, nothing strange happens. Everything seems to be very clear. On the other hand, for some reason this solves such interesting problems.
Even lately, I began to sleep badly at night, because I am beginning to think: “Is my brain, is it like that too? Maybe he also just approximates the function? ”And for some reason this makes me depressed.
Everything looks like magic. It is very important to understand that for serious tasks, such as converting a picture into text, you need very large computational resources. This is most likely either a cloud or powerful video cards, but they have already ceased to be available, because cryptocurrency has already bought everything. And this is also sad. But in the cloud cars remained.

How is the neural network? The neural network, in a sense, resembles the architecture of the human brain. There are neurons in the human brain that are connected to each other, and these connections in the learning process change their conductance, their weights. Therefore, from a programmatic point of view, we obtain such a construction, in which there is a certain number of inputs, each of which may have some numerical value. Then there are some intermediate layers, where, for example, we take the signal from this previous layer, from the input and sum up with certain weight coefficients. Here we get some number, then we summarize from the next layer of the input and as a result we get some kind of output.
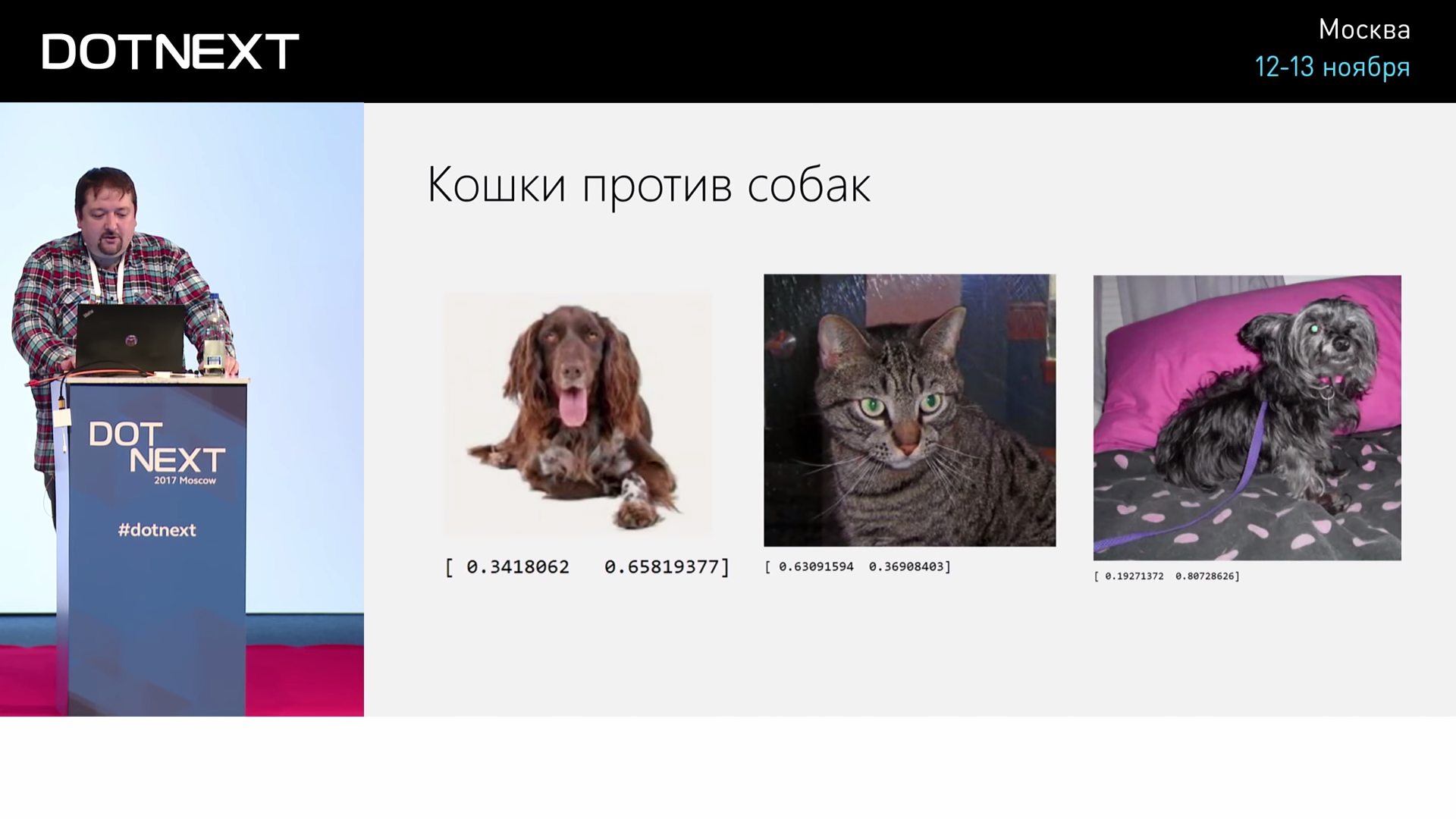
For example, for the recognition problem on a cat or dog photo. What do we give to the entrance? At the entrance we submit a photo. Each entrance - it will be a separate pixel of the photo, and the output will be two: either a cat or a dog. And there will be a certain number of layers in the middle.
And then what do we need to do? Adjusting the weights so that this neural network gives the correct output for the input. If we submit a picture at the beginning, it is obvious that it will produce some random numbers at the output. If the coefficients there were random, then it will give a certain number. And we say, "No, please, let's adjust the weights so that it looks more like a cat." And for this we use some algorithms.
There is an algorithm for back propagation of errors, which allows you to adjust the weight. Next we show the following example - we adjust the weights again. And so we do many, many times for a very large number of examples. From the point of view of mathematics, very simple things happen here. If we imagine that this layer of output of this layer is some vector, then, in essence, we multiply this input vector x by some matrix, then add some more shift and apply some non-linear function to it. As a matter of fact, we do for each layer such multiplication of a matrix by a vector. Everything is very simple.
But why do we use a nonlinear function? Partly to get a number in a certain range. But there is a very killer argument. If it were not there, it would all look just like a product of matrices, and the product of matrices is equivalent to any one matrix. If we take the input vector, multiply by one matrix, then by another - it is as if we simply multiplied two matrices and then called the number for this product of matrices. Therefore, if we didn’t add a nonlinear function, the number of layers would not affect, everything would be as one layer. And so, by adding non-linearity, it becomes like a decomposition in a row. And when this expansion in a series, we can approximate an arbitrary function. And if this were not, we could approximate only convex linear manifolds. Therefore, it is very important that we add a non-linear function. In this case, nonlinear functions are also different.
Previously, it was customary to do such beautiful non-linear functions, which are called "sigmoid", it has now become fashionable to make a non-linear function as a linear function. That is, it is half linear: it is linear more than 0, and less than 0 it is 0. Why? Because it turns out to be effective in implementation. Its derivative is considered easy, although it is a poor derivative. However, such functions are often used.

How can we implement a neural network? We can program it manually, this task is also not super complicated, but not very pleasant. What else is important: since we want to teach all this on graphics processors, if you do it well, you need to go into learning graphic matrix multiplications on hardware - this is all already becoming difficult.
Therefore, it usually uses some ready-made frameworks. There is Google's TensorFlow, which is a major competitor and is generally used by everyone. There are a few others.

Accord also has a neural network; we can lock a neural network here by simply taking and changing this algorithm. Everything will be a little different.
var nn = new ActivationNetwork(new SigmoidFunction(0.1), 784, 10); var learn = new BackPropagationLearning(nn); nn.Randomize(); WriteLine("StartingLearning"); for (int ep=0; ep<50, ep++) { var err = learn.RunEpoch((from x in train select x.Image.Select(t=>(double)t/256.0).toArray(), (from x in train select x.Label.ToOneHot10(10).ToDoubleArray()).toArray() ) WriteLine($"Epoch={ep}, Error={err}"); } int count=0, correct=0; foreach (var v in test) { var n = nn.Compute(v.Image.Select(t=>(double)t/256.0).toArray()); var z = n.MaxIndex(); WriteLine("{0} => {1}"), z, v.Label); if (z == v.Label) correct++; count++; } WriteLine("Done, {0} of {1} correct ({2}%)", correct, count, (double)count * 100); There is such a problem with a neural network: when we do it, it does not always work very well, because there are different learning parameters. In this case, this is the width of this Activation Function itself. It’s not very good that we did from 0 to 1, maybe it would be better to do from -1 to 1 so that it was in the negative zone. If we used, for example, a nonlinear function, but a semilinear one, then it is precisely important for us that it be in the negative zone. There are different subtleties. And the first attempt is not always successful.
At each stage of training, I type an error that remains. It brings the output closer to what is needed, but at the same time there is still some kind of mistake, and the learning process decreases all the time. However, sometimes it starts to increase - this is a sure sign that something has probably gone wrong, and it is already worth stopping training. There is also the problem of retraining, when the network is retrained, it starts to predict worse.
For example, we run a test of the above code, and we get 88.3%. This is not very good, but not very bad.
But until we see that the neural networks are much better than what was.
However, in Accord you can learn neural networks, but you don’t need to, because there are specialized frameworks that are better.
Our Microsoft Cognitive Toolkit, what is it beautiful about? It can be used on the GPU, on clusters of computers on the GPU - in all possible cases. In addition, it is open source, rapidly and actively developing. It is so actively developing that, for example, until September it did not allow to train neural networks on .NET, and now it already allows.

Initially, he had two training modes: you could describe the network architecture in a special language called BrainScript, and feed the original data and this Script utility on the command line and say: “Please teach me a neural network.” It all happened on the command line, and then the model file was recorded, which could be taken and used from some of my C # project, Python, on anything.
But then, as if obeying the dictates of fashion, transferred the learning process in Python. In fact, this is not so bad, because everything is more flexible, you can create various clever network architectures, you do not need to learn the new language BrainScript. But until September 2017, the main mode of using CNTK was: taught in Python, and you can use it with .NET.
But we always, when we are doing some project and we want the customer to show the result, we wrap the neural network in a bot. Then take a picture of the picture, and the network gives the result. A bot is written in C #, it is easy to embed neural network calculations into it, and learning has always been in Python and in a virtual machine in the cloud.

If you want to experiment with the cloud, there are ready-made machines in the cloud called Data Science Virtual Machine. When you create it, it turns out the machine on which all the necessary software is installed, mainly in Python.

I will repeat a little bit: before, the basic learning mode was this: either we use BrainScript, or we learn the neural network in Python, we get the file and then use it from .NET. And all this works on top of a certain library in C ++. Both that, and another: both training, and calculation.
In September, special APIs were added to support learning. Why is this possible? Why are there no such competitors?
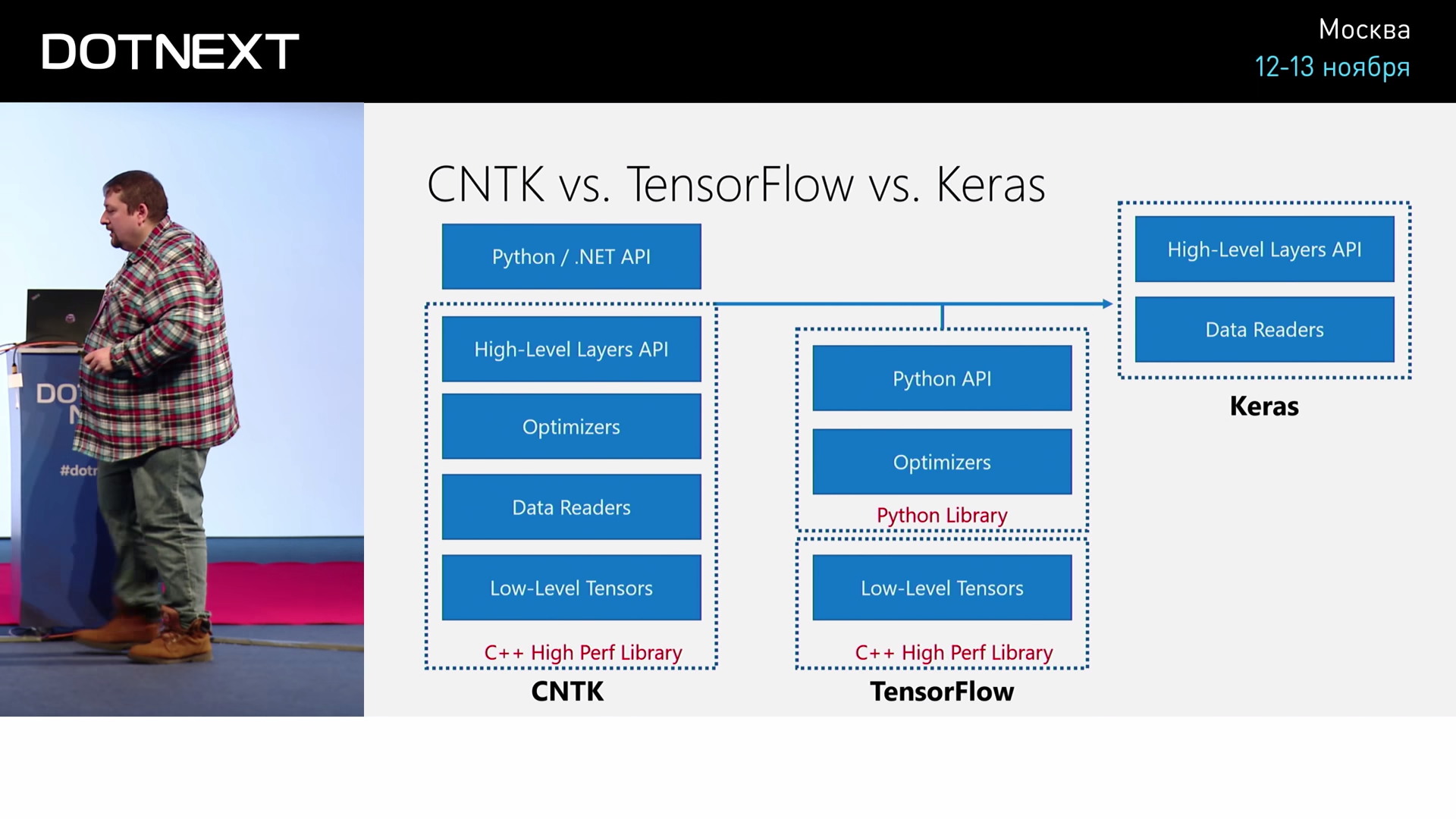
, CNTK: ? , , . , , . , , , .
CNTK , - . , : . , , , , , . - . , : , -, , , - . , transformations, - .
CNTK. — , . , , , . , , , , , . .
CNTK API , . , , : « - , -, - ». Layers API.
CNTK, C++, API Python .NET.
? TensorFlow. TensorFlow C++, , , . Python. , , , . TensorFlow .NET. , TensorFlow C#, .
Keras. TensorFlow, , , Keras , CNTK Layer API. .
Keras , CNTK . Keras, CNTK TensorFlow, - .

, CNTK .
, . ? , float, 256 — , 0 1.
#r "SciSharp.dll" using SciSharp; using static System.Console; class Digit { public float[] Image; public int Label; } var fn = @"train.csv"; var f = File.ReadLines(fn); var data = from z in f.Skip(1) let zz = z.Split(',').Select(int.Parse) select new Digit { Label = zz.First(), Image = zz.Skip(1).Select(x=>x/256f).toArray(); }; var train = data.Take(10000).toArray(); var test = data.Skip(10000).Take(1000).toArray(); , CNTK? .
DeviceDescriptor device = DeviceDescriptor.CPUDevice; int inputDim = 784; int outputDim = 10; var inputShape = new NDShape(1, inputDim); var outputShape = new NDShape(1, outputDim); -, , CPU. , 784 — 28 28, — 10, 10 . Shape. Shape — . NDShape . .
Variable features = Variable.InputVariable(inputShape, DataType.Float); Variable label = Variable.InputVariable(outputShape, DataType.Float); var W = new Parameter(new int[] { outputDim, inputDim }, DataType.Float, 1, device, "w"} ); var b = new Parameter(new int[] { outputDim }, DataType.Float, 1, device, "b"} ) var z = CNTKLib.Times(W, features) + b; ? . ? , , . , Variables, . variable, features — , 768, , lable, 10. . . , , , , .
, — W — 10 768. 10, outputDim. . , , — Z, W + b. . Everything.
: « , - , , ».
var loss = CNTLib.CrossEntropyWithSoftmax(z, label); var evalError = CNTKLib.ClassificationError(z, label); , CrossEntropyWithSoftmax, , . .
, . ). Learner, Trainer. Trainer , Learner, 60 : «Trainer.Train».
.

: ? , , , , . Python? . Python - , . Python, C# — .

. ? . ? 1500, - . , . , . 94% .

. , , , ? — ? , .

, « ». ? , . , , . , , . . , , , , . . , , . , 98%.

- .

, . Convolution. 28 28 1 — 28 28 — 14 14 4. 4 , - , , , . , 14 14 4 7 7 8. .

- . , 5 . : « , , , ?» : « , 20 , ». , . , : « ! - !» , , .
, , , , . , , . , , , , 500-1500 , . , , , , , — . , , . , .
C#, , ( Python), — 6 . 3 , 5 5 — 32 32 . . 3 3 .
Python , , 50, 75. , , , . 0,8 , 0,4 , 0,65 . , 3-4 , .
?
:
F# API CNTK:
, , . , . — , . 4, -, 6. , Notebook' Python , . . , Coursera - .
— , , - . CNTK, , , F#. C# , F#. . , . GitHub , . , , , — 2017 C#, , , .

, , . ? .NET , . , Azure Notebooks, C# Interactive, Xamarin Workbooks — , , . , Microsoft — CNTK, C#, , . , 10-15 , .
Minute advertising. As you probably know, we do conferences. The nearest .NET conference - DotNext 2018 Piter . It will be held April 22-23, 2018 in St. Petersburg. What reports are there - you can see in our archive on YouTube . At the conference, it will be possible to chat live with the speakers and the best experts on .NET in special discussion zones after each report. In short, come in, we are waiting for you.
')
Source: https://habr.com/ru/post/352138/
All Articles