A tale about how an HTTP / 2 Client engineer overclocked
Using the example of “JEP 110: HTTP / 2 Client” (which will appear in the JDK in the future), Sergey Kuksenko from Oracle shows how the team started it, where it looked and what it did to make it faster.
We offer you a decryption of his report with JPoint 2017. In general, it will not be about HTTP / 2. Although, of course, it will not be possible to do without a number of details on it.
HTTP 2 is a new standard designed to replace outdated HTTP 1.1. How does the implementation of HTTP 2 differ from the previous version in terms of performance?
')
The key thing about HTTP 2 is that we have one single TCP connection. Data streams are cut into frames, and all these frames are sent through this connection.
A separate header compression standard is also provided - RFC 7541 (HPACK). It works very well: it allows you to shrink up to 20 bytes of HTTP header that is in the order of kilobytes. For some of our optimizations, this is important.
In general, the new version has a lot of interesting things - prioritization of requests, server push (when the server itself sends data to the client) and so on. However, in the context of this narrative (in terms of performance), this is not important. In addition, many things remain the same. For example, what the HTTP protocol looks like from above: we have the same GET and POST methods, the same values of the HTTP header fields, status codes and the “request -> response -> final response” structure. In fact, if you look closely, HTTP 2 is just a low-level transport under HTTP 1.1, which removes its flaws.
We have an HttpClient project called JEP 110. It is almost included in JDK 9. Initially, this client wanted to be made part of the JDK 9 standard, but some controversy arose at the level of the API implementation. And since we do not have time to finalize the HTTP API by the release of JDK 9, we decided to make it so that we can show it to the community and discuss it.
A new incubator module (Incubator Modules aka JEP-11) appears in JDK 9. This is a sandbox, where in order to get feedback from the community, new APIs will be formed, which are not yet standardized, but, by definition, the incubator will be standardized to the next version or removed altogether ("It is expected that the API will either be standardized or removed. All who are interested can get acquainted with the API and send your feedback. Perhaps the next version - JDK 10 - where it will become the standard, everything will be fixed.
HttpClient is the first module in the incubator. Subsequently, other things related to the customer will appear in the incubator.
I'll tell you literally a couple of examples about the API (this is exactly the client API that allows you to make a request). Main classes:
This is the simple way to build a query:
Here we specify the URL, set the header, etc. - we receive request.
How can I send a request? For the client, there are two kinds of APIs. The first is a synchronous request when we block at the place of this call.
The request is gone, we received a response, interpreted it as a
The second is the asynchronous API, when we do not want to block in this place and, sending an asynchronous request, we continue execution, and with the received CompletableFuture we can then do whatever we want:
The client can be set to one thousand and one configuration parameters, differently configured:
The main feature here is that the client API is universal. It works with both old HTTP 1.1 and HTTP 2 without discerning the details. For the client, you can specify the default operation with the HTTP 2 standard. The same parameter can be specified for each individual request.
So, we have a Java library - a separate module that is based on standard JDK classes, and which we need to optimize (to do some kind of performance work). Formally, the task of the performance is as follows: we must get a reasonable client performance for an acceptable time spent by the engineer.
How can we start this work?
Let's start with benchmarking. Suddenly everything is so good there - you don't have to read the specification.
They wrote a benchmark. Well, if we have a competitor for comparison. I took Jetty Client as a competitor. I screwed Jetty Server on the side - just because I wanted the server to be in Java. Wrote GET and POST requests of different sizes.

Naturally, the question arises - what do we measure: throughput, latency (minimal, medium). During the discussion, we decided that this is not a server, but a client. This means that taking into account the minimum latency, gc-pauses and everything else in this context is not important. Therefore, specifically for this work, we decided to limit ourselves to measuring the overall system throughput. Our task is to increase it.
The overall system throughput is the inverse of the average latency. That is, we worked on the average latency, but it did not strain with each individual request. Just because the client does not have such requirements as the server.
We launch GET on 1 byte. Iron written out. We get:

I take the same benchmark for HTTPClient, I run on other operating systems and hardware (this is more or less server-side machines). I receive:

In Win64, everything looks better. But even in MacOS, things are not as bad as in Linux.
The problem is here:
This is the opening of SocketChannel to connect to the server. The problem is the lack of a single line (I highlighted it in the code below):
In principle, there are a lot of explanations on the Internet about how these two algorithms conflict and why they create such a problem. I quote a link to one article I liked: TCP Performance problems caused by the interaction between Nagle's Algorithm and Delayed ACK
A detailed description of this problem is beyond the scope of our conversation.
After a single line was added with the inclusion of

I will not take it as a percentage.
Moral: this is not a Java problem, this is a problem with the TCP stack and its configuration issues. For many areas, there are well-known shoals. So well known that people forget about them. It is desirable to simply know about them. If you are new to this area, you can easily gossip the basic shoals that exist. You can check them very quickly and without any problems.
You need to know (and do not forget) a list of well-known schools for your subject area.
We have the first change, and I didn’t even have to read the specification. It turned out 9600 requests per second, but remember that Jetty gives 11 thousand. Further we profile with the help of any profiler.
Here is what I got:

And this is a filtered version:

My benchmark takes up 93% of the CPU time.
Sending a request to the server takes 37%. Next comes any internal detailing, working with frames, and at the end of 19% this is an entry in our SocketChannel. We transfer the data and header of the request, as it should be in HTTP. And then we read -
Next, we need to read the data that came to us from the server. What then is it?
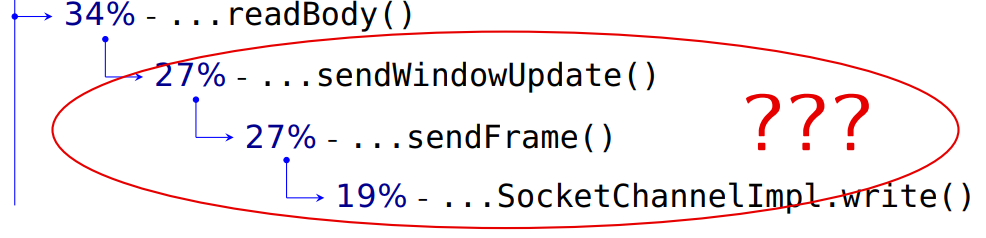
If the engineers correctly named the methods, and I trust them, then here they send something to the server, and this takes as much time as sending our requests. Why do we send something when reading the server response?
To answer this question, I had to read the specification.
In general, a lot of performance problems are solved without knowing the specification. Somewhere you need to replace
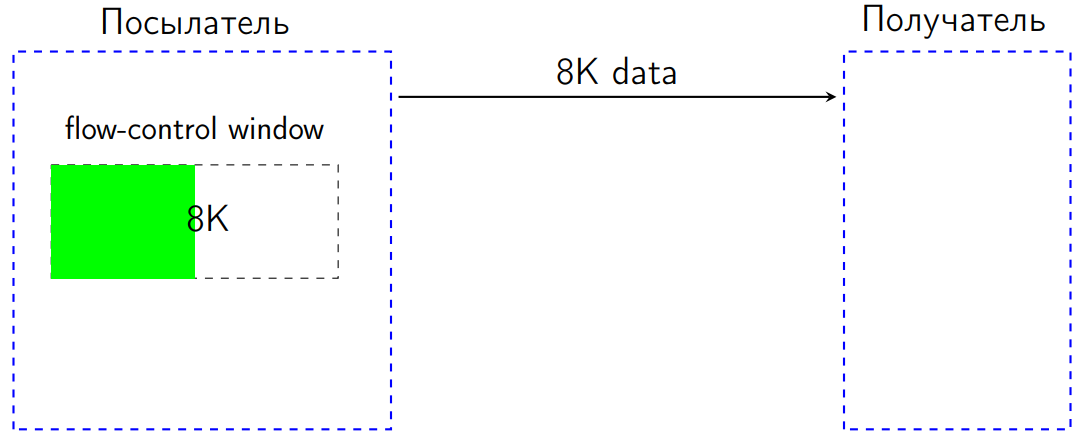
But in our case, the problem really showed up in the specification: in the HTTP 2 standard there is a so-called flow-control. It works as follows. We have two feasts: one sends data, the other receives. The sender (sender) has a window - a flow-control window the size of a number of bytes (suppose 16 KB).

Let's say we sent 8K. The flow-control window is reduced by these 8 KB.
After we sent another 8 KB, the flow-control window was 0 KB.
According to the standard in such a situation, we have no right to send anything. If we try to send some data, the recipient will be obliged to interpret this situation as a protocol error and close the connection. This is a kind of protection from DDOS, in some cases, so that we are not sent anything superfluous, and the sender adjusts to the capacity of the recipient.
When the receiver processed the received data, it had to send a special dedicated signal called WindowUpdate indicating how many bytes to increase the flow-control window.
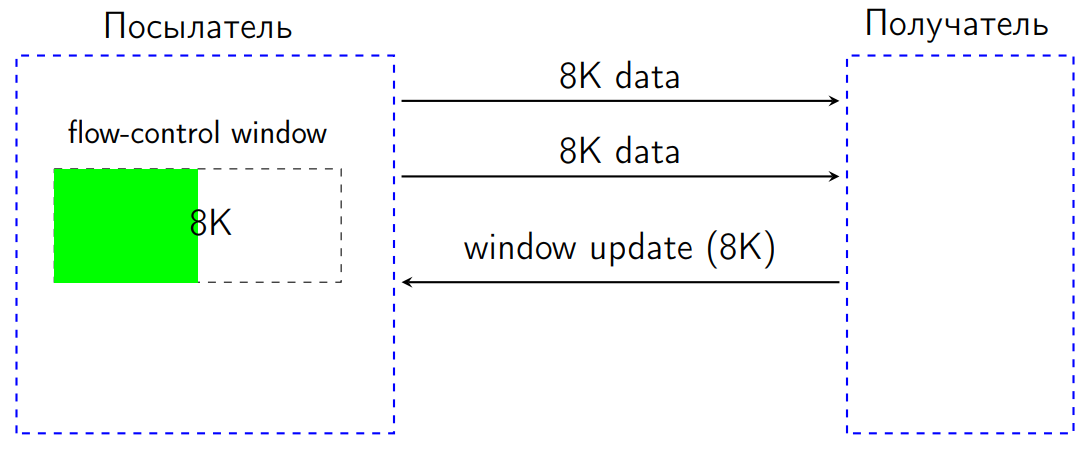
When the WindowUpdate arrives to the sender, its flow-control window increases, we can send data further.
What is going on in the client?
We received data from the server - this is the real piece of processing:
A certain
In fact, in each such place two flow-control window works. We have a flow-control window specifically for this data transfer stream (request), and we also have a general flow control window for the entire connection. Therefore, we must send two WindowUpdate requests.
How to optimize this situation?
The first. At the end of the
This is a small optimization: if we catch the end-of-stream flag, then WindowUpdate can no longer be sent for this stream: we don’t wait for any data anymore, the server will not send anything.
The second. Who said we should send WindowUpdate every time? Why can't we, having received many requests, process the incoming data and only then send a WindowUpdate package for all incoming requests?
Here is
We have a certain
For a request of 1 byte, we get:
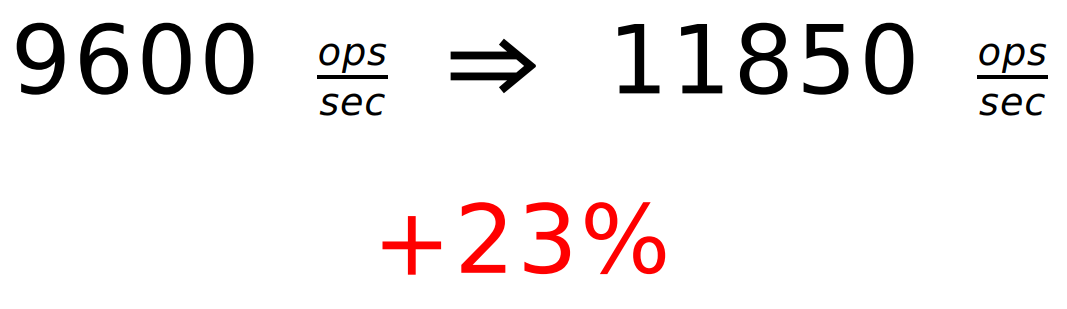
The effect will be even for megabyte requests, where there are a lot of frames. But he, naturally, is not so noticeable. In practice, I had different benchmarks, requests of different sizes. But here for each case I didn’t draw graphics, but picked up simple examples. Squeeze more detailed data will be a little later.
We received only + 23%, but the Jetty has already overtaken.
Moral: accurate reading specifications and logic are your friends.
There is a nuance of specification. There, on the one hand, it says that when we receive a data frame, we must send WindowUpdate. But, having carefully read the specification, we will see: there is no requirement that we are obliged to send WindowUpdate to every received byte. Therefore, the specification allows such a batch update to the flow-control window.
Let's explore how we scale (scale).
The laptop is not very suitable for scaling - it has only two real and two fake cores. We will take some server machine, in which 48 hardware threads, and launch the benchmark.
Here, horizontally is the number of threads, and vertically shows the total throughput.
Here you can see that up to four threads we scale very well. But further, the scalability becomes very bad.
It would seem, why do we need it? We have one customer; we will get the necessary data from the server from one thread and forget about it. But first, we have an asynchronous version of the API. To her we will come. There certainly will be some threads. Secondly, in our world now everything is multi-core, and to be able to work well with many threads in our library is simply useful - if only because when someone starts complaining about the performance of the single-threaded version, he can be advised to switch to multi-threaded and get a benefit. Therefore, let's look for the culprit in bad scalability. I usually do it like this:
I just write the file to file. In reality, this is enough for me in 90% of cases when I work with locks without any profilers. Only in some complicated trick cases I launch the Mission control or something else and watch the allocation of locks.
In the log you can see in what state I have different threads:
Here we are interested in precisely blocking, rather than waiting, when we expect events. There are 30 thousand locks, which is quite a lot against 200 thousand runnable ones.
But such a command line will simply show us the culprit (nothing extra is needed - just the command line):
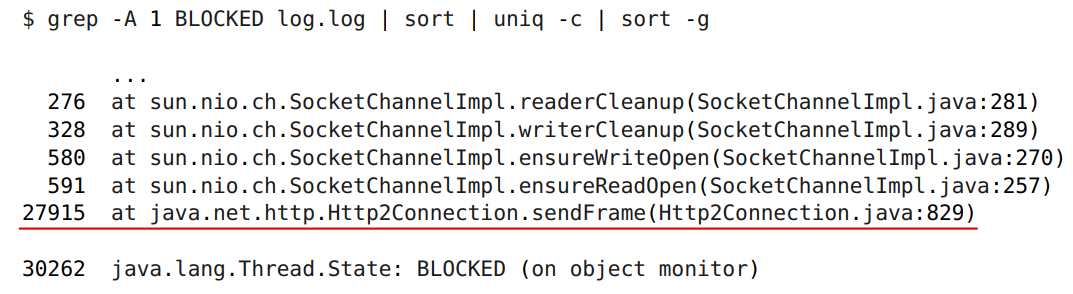
The culprit is caught. This is a method inside our library that sends a data frame to the server. Let's figure it out.
Here we have a global monitor:

But this thread -
- the beginning of the initiation of the request. This is the sending of the very first header to the server (some additional actions are required here, I will talk about them now).
This is sending all other frames to the server:

All this under a global lock!

But this method takes 1%:
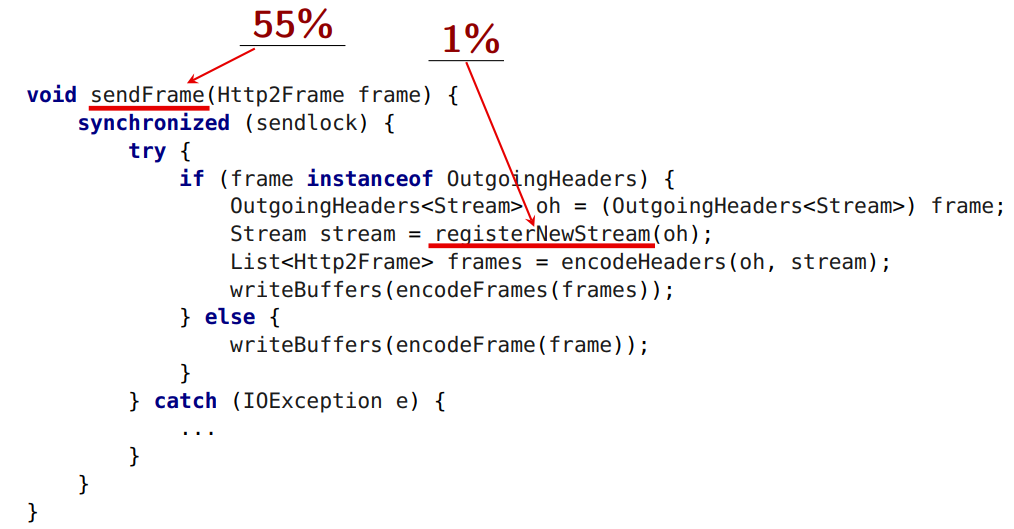
Let's try to understand what can be taken out from under the global lock.
Registration of a new stream from under the lock can not be made. The HTTP standard imposes a restriction on the numbering of streams. In
The second problem, which is not removed from the lock:
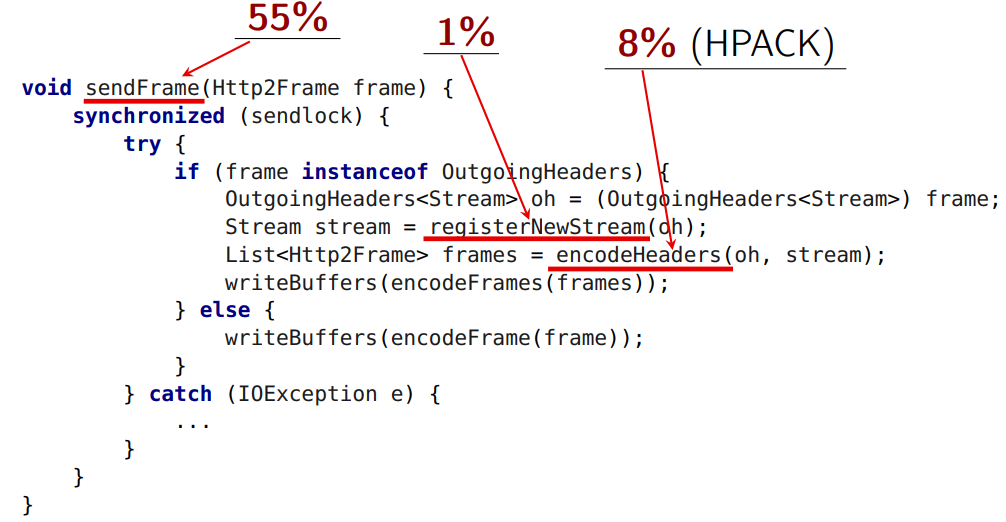
Here is the header compression.
In its usual form, our header is put in the usual map - key value (from string to string). In
The

Nothing prevents us from

There are some implementation nuances.
So it turned out that
If we try to take
Let's do the first thing that comes to mind - the queue queue. We will put the byte buffer in this queue in the correct order, and let another thread read from it.
In this case, the
So, we removed one of the most difficult operations outside and launched an additional thread. The size of the critical section was reduced by 60%.
But the implementation has its drawbacks:
Let's solve the first problem with the frame order.
An obvious idea -
We have an inseparable piece of byte buffers that cannot be mixed with anything; we add it into an array, and the array itself into a queue. Then these arrays can be intermixed with each other, and where we need a fixed order, we provide it:
Pros:
But here there is one more minus. Still, the sending stream often falls asleep and wakes up for a long time.
Let's do this:

We will have a little turn of our own. In it, we add the resulting arrays of byte-buffers. After that, between all threads that came out from under the lock, we will arrange a competition. Who won, let him write to the socket. And let the rest work on.
It should be noted that another optimization turned out to be in the
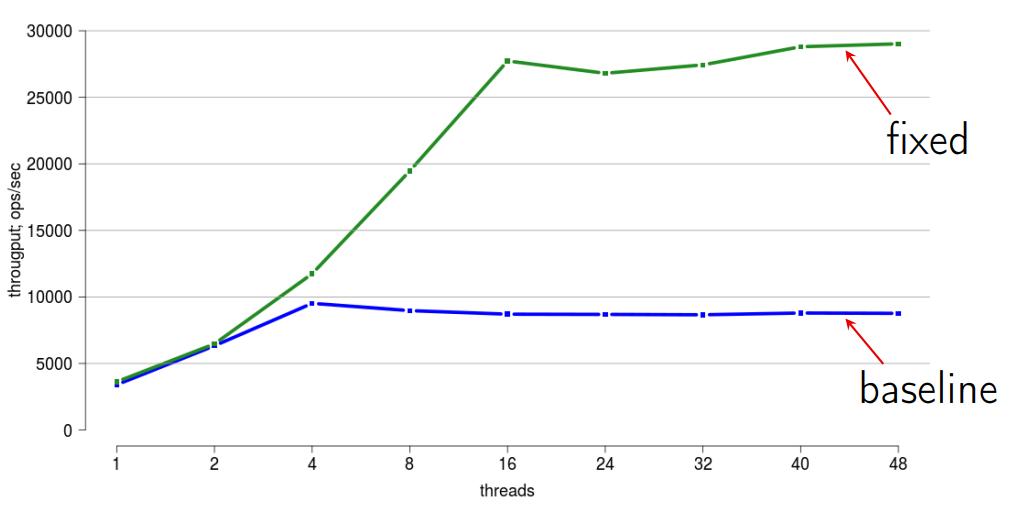
Each of the three optimizations presented allowed us to very well remove the problem with scaling. Something like this (the overall effect is reflected):
Moral: Locks - evil!
Everyone knows that you need to get rid of locks. Moreover, the concurrent library is becoming more advanced and interesting.
In theory, we have an HTTP Client designed for 100% use of ByteBufferPool. But in practice ... Immediately, the bugs, here - something fell, there - the frame was underworked ... And if ByteBuffer did not return the pool back, the functionality did not break ... In general, the engineers had no time to deal with it. And we got an unfinished version, sharpened into pools. We have (and cry):
We get all the disadvantages of working with pools, and at the same time - all the disadvantages of working without pools. There are no pluses in this version. We need to move forward: either to make a normal full-fledged pool so that all ByteBuffers return to it after use, or even to cut the pools, but at the same time we even have them in the public API.
What do people think about pools? Here is what you can hear:
Before returning to the question of pools, we need to solve a sub-question - what do we use in our problem with the HTTPClient: DirectByteBuffer or HeapByteBuffer?
First, we study the question theoretically:
Indeed, for transferring data to the socket DirectByteBuffer is better. Because if we follow the Write-s chain to nio, we will see the code where from HeapByteBuffer everything is copied into the internal DirectByteBuffer. And if we have a DirectByteBuffer, we do not copy anything.
But we have another thing - an SSL connection. The standard HTTP 2 allows you to work with both plain connection and SSL connection, but it is declared that SSL should be the de facto standard for the new web. If we follow the chain of how OpenJDK implements it in the same way, it turns out that theoretically SSLEngine works better with HeapByteBuffer, because it can reach the byte [] array and encrypt it. And in the case of DirectByteBuffer, he must first copy here, and then back.
And measurements show that HeapByteBuffer is always faster:
Those.HeapByteBuffer is our choice!
Oddly enough, reading and copying from DirectByteBuffer is more expensive, because checks remain there. The code there is not very well vectorized, since it works through unsafe. And in HeapByteBuffer - intrinsic (not even vectorization). And soon it will work even better.
Therefore, even if HeapByteBuffer were 2-3% slower than DirectByteBuffer, it might not make sense to do DirectByteBuffer. So let's get rid of the problem.
Let's make various options.
Advantages of option 1:
Minuses:
GC will do all the work, especially since we do not have DirectByteBuffer, but HeapByteBuffer.
Pros:
But two problems:
For the sake of experiment we make a mixed version. I will tell about it in more detail. Here we choose the approach depending on the data.
Outgoing data:
Incoming data:
In general, the standard HTTP 2 has nine types of frames. If eight of them came (everything except data), then we decode the byte buffer in the same place and we do not need to copy anything from it, and we return the byte buffer back to the pool. And if the data came, we perform a slice, so that we don’t have to copy anything, and then just throw it away - it will be assembled by the GC.
Well, a separate pool for encrypted SSL connection buffers, because there is a different size.
Pluses of the mixed option:
Minus one: above “allocation pressure”.
We made three options, checked, corrected bugs, achieved functional work. We measure. We look at the allocation of data. I had 32 measurement scenarios, but I did not want to draw 32 graphs here. I will show just the range averaged over all dimensions. Here, the baseline is the original unfinished code (I took it for 100%). We measured the change in the allocation rate with respect to the baseline in each of the three modifications.

The option where everything goes to the pool predictably loses less. A variant that does not require any pools allocates eight times more memory than a variant without pools. But do we really need memory for the allocation rate? Measuring GC-pause:

With such GC-pauses at the allocation rate, this does not affect.
It is seen that the first option (in the pool to the maximum) gives 25% acceleration. Lack of pools to the maximum gives 27% of acceleration, and the mixed version gives a maximum of 36% of acceleration. Any properly completed version already gives an increase in productivity.
In a number of scenarios, the mixed version gives about 10% more than the option with pools or the option without any pools at all, so it was decided to stop there.
Moral: here I had to try various options, but there was no real need to totally work with pools by dragging them into the public API.
The above are four modifications that I wanted to talk about in terms of working with blocking calls. Then I will talk a little about something else, but first I want to make an intermediate cut.
Here is a comparison of HttpClient and JettyClient on different types of connections and data volumes. Bars are slices; the higher the faster.
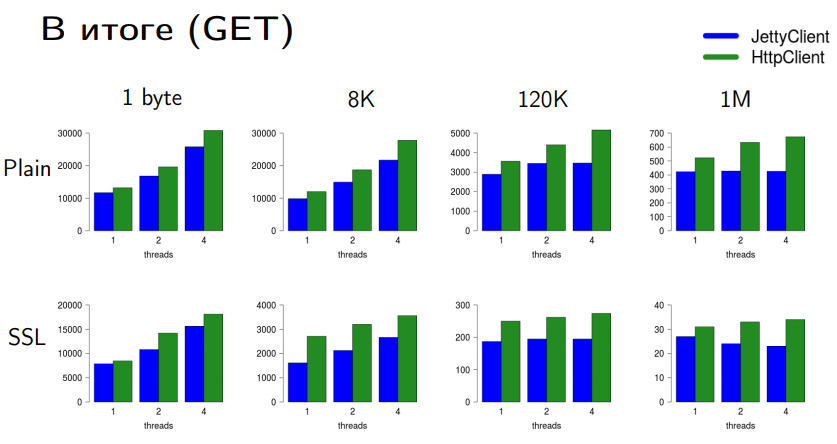
For GET requests, we are well ahead of Jetty. I put a tick. We have an acceptable performance with an acceptable cost. In principle, you can still squeeze there, but you need to stop once, otherwise you will not see this HttpClient in Java 9 or Java 10.
With POST requests, things are not so optimistic. When sending big data in a PLAIN connection, the Jetty still wins a little bit. But when sending small data and with an SSL-encrypted connection, we also have no problems.
Why do we not have data scaled when post size is large? Here we run into two serialization problems: in the case of an SSL connection, this lock is a write to the socket — it is global for writing to this particular SocketChannel. We cannot write to the socket in parallel. Although we are part of the JDK, the nio library for us is an external module where we cannot change anything. So when we write a lot, we run into this bottleneck.
With SSL (with encryption) the same situation. SSLEngine has encryption / decryption. They can work in parallel. But encryption is required to work consistently, even if I send data from many threads. This is a feature of the SSL protocol. And this is another serialization point. Nothing can be done with this, unless you switch to some native OpenSSL standards.
Let's look at asynchronous requests.
Can we make such a completely simple version of the asynchronous API?
I gave my executor - here it is written out (executor is configured in the client; I have some default executor, but you, as a user of this client, can give any executor there).
Alas, you can't just take and write an asynchronous API:

The problem is that in blocking requests we often wait for something.
Here is a very exaggerated picture. In reality, there is a query tree - waiting here, waiting there ... they are placed in different places.

When we wait, we sit on wait or on condition. If we wait in the blocking API, and at the same time we put it in the Async executor, then we took the thread from the executor.
On the one hand, it is simply ineffective. On the other - we wrote an API that allows us to give our API any external executor. This, by definition, should work with a fixed thread pool (if a user can give any executor there, then we should be able to work in at least one thread).
In reality, this was a standard situation when all the threads from my executor were blocked. They are waiting for a response from the server, and the server is waiting and not sending anything until I also send something to it. I need to send something from the client, and I have no threads in the executor. Everything.We arrived.
It is necessary to cut the entire chain of requests so that each waiting point is wrapped in a separate CompletableFuture. Like that:
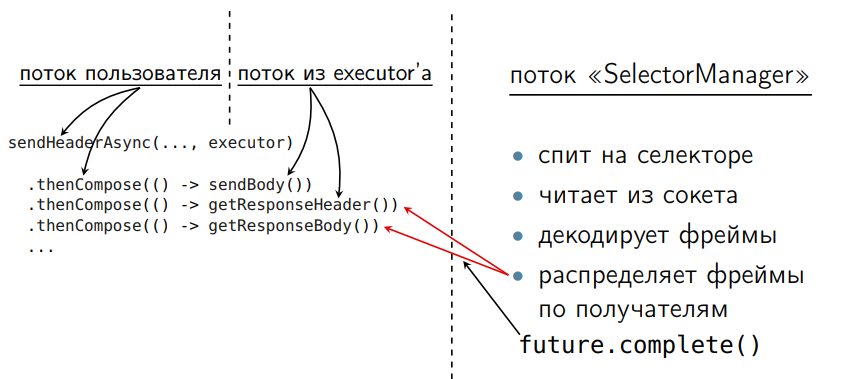
We have a user thread on the left. There we build a chain of queries. Here the method thenCompose, in which one future came, came the second future. On the other hand, we have a thread-thread selectormanager. It was in the sequential version, it just did not have to be optimized. It reads from the socket, decodes the frame and makes a complete.
When we come to thenCompose and see that we have a future that we are waiting for, has not yet been completed, we are not blocking (this is the asynchronous processing of the CompletableFuture), but leaving. The thread will return to the executor, continue to work on something else that is required for this executor, and then we will go on this execution further. This is a key feature CompletableFuture, which allows you to write such things effectively. We do not steal the thread from work. We always have someone to work with. And it is more effective in terms of performance.
We cut out all the locks on condition or wait, go to CompletableFuture. When the CompletableFuture is complete, then the thread is put to execution. We get + 40% to the processing of asynchronous requests.
We have a very popular genre of puzzlers. I do not really like jigsawers, but I want to ask. Suppose we have two threads and there is a CompletableFuture. In one thread, we attach a chain of actions - thenSomething. By this “Something” I mean Compose, Combine, Apply - any operations with CompletableFuture. And from the second thread we make the completion of this CompletableFuture.
The foo method is our action that should work - in which thread will it be executed?

The correct answer is C.
If we complete the chain - i.e. If we call the thenSomething method and the CompletableFuture has already been completed by this time, the foo method will be called in the first thread. And if the CompletableFuture has not yet been completed, it will be called from complete along the chain, i.e. from the second thread. With this key feature, we will now deal two times.
So, we in the user code build a chain of requests. We want the user to send me sendAsync. Those.I want in the user thread, where we do sendAsync, build a chain of requests and give the final CompletableFuture to the user. And there in my executor my threads, data sending, waiting will go to work.
I twist and saw java code on localhost. And what turns out: sometimes I don’t have time to complete the query chain, and the CompletableFuture is already completed:
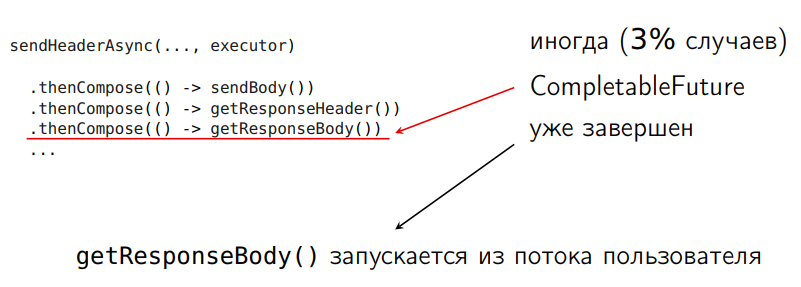
I have only four hard work threads on this machine (there may be several dozen of them), and even then he doesn’t have time to complete it. I measured it in 3% of cases. An attempt to complete the query chain further leads to the fact that some actions on this chain, such as sending and receiving data, are invoked in a user course, although I do not want this. Initially, I want this whole chain to be hidden, i.e. the user should not see it. I want it to work in the executor.
Of course, we have methods that make Compose Async. If instead of thenCompose I call the method
Pros of implementation:
Minuses:
Here is such a trick was used:
We first take an empty incomplete CompletableFuture, we build to it the whole chain of actions that we need to perform, and we will start the execution. After that we will complete the CompletableFuture - we will do it
There is another problem with the CompletableFuture:

We have a CompletableFuture and a dedicated SelectorManager stream that CompletableFuture completes. We can not write here
It is simply dangerous.

We have

But by doing
We very often have to switch the execution from thread to executor to another thread from the same executor along the chain. But we do not want to do a switch from SelectorManager to executor or from some user thread to executor. And inside the executor, we don't want our tasks to migrate. Performance suffers from this.
We can not do

But here is the same problem. In both cases we have secured our work, in our thread nothing will start, but this migration is expensive.
Pros:
Minuses:
Here's another trick: let's check, can we have the CompletableFuture already completed? If the CompletableFuture is not complete yet, we’ll go to Async. And if it is completed, it means I know for sure that the construction of the chain to the already completed CompletableFuture will be executed in my thread, and I am already doing this executor in this thread.

This is purely optimization, which removes unnecessary things.
And it gives another 16% performance to asynchronous requests.
As a result, all three of these optimizations for CompletableFuture dispersed asynchronous requests by about 80%.
Moral: Learn new.
CompletableFuture ( since 1.8)
The last fix was never made in the code of the HTTP Client itself simply because it is associated with the Public API. But the problem can be circumvented. I will tell you about it.
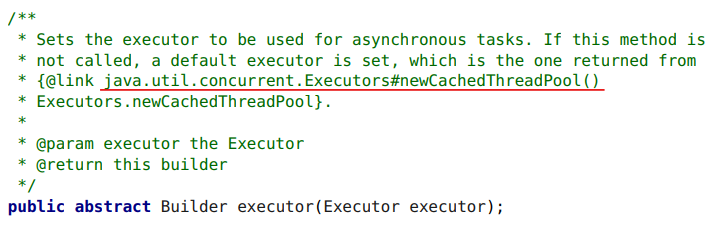
So, we have a client builder, we can give him an executor. If we did not give it an executor when creating the HTTP Client, it says that it is used by default
Let's see what it is

There
Before I made corrections from the previous paragraph (the fifth alteration), I measured, and it turned out that I
I cut all the expectations, locks, made the "Fifth mess". My threads are no longer blocked, not wasted, but they work. All the same on one request through
In fact, for such things
In this case, you need to fix the ThreadPool executor. Must measure options. But I’ll just show performance results for one that turned out to be the best candidate for correction

Two threads are the best option because writing to the socket is a bottleneck that cannot be parallelized, and SSLEngine cannot work in parallel either. The numbers speak for themselves.
Moral: Not all ThreadPools are equally useful.
With alterations HTTP 2 Client I have everything.
To be honest, reading the documentation, I swore a lot on the Java API. Especially in the part about byte buffer, sockets and so on. But my rules of the game were such that I should not have changed them. For me, the JDK is an external library on which this API is built.
But Comrade Norman Maurer was not as constrained as I was. And he wrote an interesting presentation - for those who want to dig deeper: Writing Highly Performant Network Frameworks on the JVM - A Love-Hate Relationship .
It scolds the base JDK API just in the area of sockets, APIs and other things. And describes what they wanted to change and what they lacked at the JDK level when they wrote Netty. These are all the same problems that I met, but could not fix it within the framework of the rules of the game.
If you like to savor all the details of Java development in the same way as we do, you probably will be interested in these reports at our April JPoint 2018 conference:
We offer you a decryption of his report with JPoint 2017. In general, it will not be about HTTP / 2. Although, of course, it will not be possible to do without a number of details on it.
HTTP / 2 (aka RFC 7540)
HTTP 2 is a new standard designed to replace outdated HTTP 1.1. How does the implementation of HTTP 2 differ from the previous version in terms of performance?
')
The key thing about HTTP 2 is that we have one single TCP connection. Data streams are cut into frames, and all these frames are sent through this connection.
A separate header compression standard is also provided - RFC 7541 (HPACK). It works very well: it allows you to shrink up to 20 bytes of HTTP header that is in the order of kilobytes. For some of our optimizations, this is important.
In general, the new version has a lot of interesting things - prioritization of requests, server push (when the server itself sends data to the client) and so on. However, in the context of this narrative (in terms of performance), this is not important. In addition, many things remain the same. For example, what the HTTP protocol looks like from above: we have the same GET and POST methods, the same values of the HTTP header fields, status codes and the “request -> response -> final response” structure. In fact, if you look closely, HTTP 2 is just a low-level transport under HTTP 1.1, which removes its flaws.
HTTP API (aka JEP 110, HttpClient)
We have an HttpClient project called JEP 110. It is almost included in JDK 9. Initially, this client wanted to be made part of the JDK 9 standard, but some controversy arose at the level of the API implementation. And since we do not have time to finalize the HTTP API by the release of JDK 9, we decided to make it so that we can show it to the community and discuss it.
A new incubator module (Incubator Modules aka JEP-11) appears in JDK 9. This is a sandbox, where in order to get feedback from the community, new APIs will be formed, which are not yet standardized, but, by definition, the incubator will be standardized to the next version or removed altogether ("It is expected that the API will either be standardized or removed. All who are interested can get acquainted with the API and send your feedback. Perhaps the next version - JDK 10 - where it will become the standard, everything will be fixed.
- module: jdk.incubator.httpclient
- package: jdk.incubator.http
HttpClient is the first module in the incubator. Subsequently, other things related to the customer will appear in the incubator.
I'll tell you literally a couple of examples about the API (this is exactly the client API that allows you to make a request). Main classes:
- HttpClient (its Builder);
- HttpRequest (its Builder);
- HttpResponse, which we do not build, but just get back.
This is the simple way to build a query:
HttpRequest getRequest = HttpRequest .newBuilder(URI.create("https://jpoint.ru/")) .header("X-header", "value") .GET() .build(); HttpRequest postRequest = HttpRequest .newBuilder(URI.create("https://jpoint.ru/")) .POST(fromFile(Paths.get("/abstract.txt"))) .build(); Here we specify the URL, set the header, etc. - we receive request.
How can I send a request? For the client, there are two kinds of APIs. The first is a synchronous request when we block at the place of this call.
HttpClient client = HttpClient.newHttpClient(); HttpRequest request = ...; HttpResponse response = // synchronous/blocking client.send(request, BodyHandler.asString()); if (response.statusCode() == 200) { String body = response.body(); ... } ... The request is gone, we received a response, interpreted it as a
string (we can have a different handler here — string , byte , you can write your own) and processed it.The second is the asynchronous API, when we do not want to block in this place and, sending an asynchronous request, we continue execution, and with the received CompletableFuture we can then do whatever we want:
HttpClient client = HttpClient.newHttpClient(); HttpRequest request = ...; CompletableFuture> responseFuture = // asynchronous client.sendAsync(request, BodyHandler.asString()); ... The client can be set to one thousand and one configuration parameters, differently configured:
HttpClient client = HttpClient.newBuilder() .authenticator(someAuthenticator) .sslContext(someSSLContext) .sslParameters(someSSLParameters) .proxy(someProxySelector) .executor(someExecutorService) .followRedirects(HttpClient.Redirect.ALWAYS) .cookieManager(someCookieManager) .version(HttpClient.Version.HTTP_2)</b> .build(); The main feature here is that the client API is universal. It works with both old HTTP 1.1 and HTTP 2 without discerning the details. For the client, you can specify the default operation with the HTTP 2 standard. The same parameter can be specified for each individual request.
Formulation of the problem
So, we have a Java library - a separate module that is based on standard JDK classes, and which we need to optimize (to do some kind of performance work). Formally, the task of the performance is as follows: we must get a reasonable client performance for an acceptable time spent by the engineer.
Choosing an approach
How can we start this work?
- We can sit down to read the HTTP 2 specification. This is useful.
- We can begin to study the client and rewrite the govnokod that we find.
- We can just look at this client and rewrite it entirely.
- We can spoil.
Let's start with benchmarking. Suddenly everything is so good there - you don't have to read the specification.
Benchmarks
They wrote a benchmark. Well, if we have a competitor for comparison. I took Jetty Client as a competitor. I screwed Jetty Server on the side - just because I wanted the server to be in Java. Wrote GET and POST requests of different sizes.
Naturally, the question arises - what do we measure: throughput, latency (minimal, medium). During the discussion, we decided that this is not a server, but a client. This means that taking into account the minimum latency, gc-pauses and everything else in this context is not important. Therefore, specifically for this work, we decided to limit ourselves to measuring the overall system throughput. Our task is to increase it.
The overall system throughput is the inverse of the average latency. That is, we worked on the average latency, but it did not strain with each individual request. Just because the client does not have such requirements as the server.
Alteration 1. TCP configuration
We launch GET on 1 byte. Iron written out. We get:
I take the same benchmark for HTTPClient, I run on other operating systems and hardware (this is more or less server-side machines). I receive:
In Win64, everything looks better. But even in MacOS, things are not as bad as in Linux.
The problem is here:
SocketChannel chan; ... try { chan = SocketChannel.open(); int bufsize = client.getReceiveBufferSize(); chan.setOption(StandardSocketOptions.SO_RCVBUF, bufsize); } catch (IOException e) { throw new InternalError(e); } This is the opening of SocketChannel to connect to the server. The problem is the lack of a single line (I highlighted it in the code below):
SocketChannel chan; ... try { chan = SocketChannel.open(); int bufsize = client.getReceiveBufferSize(); chan.setOption(StandardSocketOptions.SO_RCVBUF, bufsize); chan.setOption(StandardSocketOptions.TCP_NODELAY, true); <-- !!! } catch (IOException e) { throw new InternalError(e); } TCP_NODELAY is "hello" from the last century. There are various TCP stack algorithms. In this context, there are two: Nagle's Algorithm and Delayed ACK. Under some conditions, they are able to kleshitsya, causing a sharp slowdown in data transfer. This is such a known issue for the TCP stack that people turn on TCP_NODELAY , which turns off Nagle's Algorithm, by default. But sometimes even an expert (real TCP experts wrote this code) can simply forget about it and not enter this command line.In principle, there are a lot of explanations on the Internet about how these two algorithms conflict and why they create such a problem. I quote a link to one article I liked: TCP Performance problems caused by the interaction between Nagle's Algorithm and Delayed ACK
A detailed description of this problem is beyond the scope of our conversation.
After a single line was added with the inclusion of
TCP_NODELAY , we received about the following performance gain:I will not take it as a percentage.
Moral: this is not a Java problem, this is a problem with the TCP stack and its configuration issues. For many areas, there are well-known shoals. So well known that people forget about them. It is desirable to simply know about them. If you are new to this area, you can easily gossip the basic shoals that exist. You can check them very quickly and without any problems.
You need to know (and do not forget) a list of well-known schools for your subject area.
Alteration 2. Flow-control window
We have the first change, and I didn’t even have to read the specification. It turned out 9600 requests per second, but remember that Jetty gives 11 thousand. Further we profile with the help of any profiler.
Here is what I got:
And this is a filtered version:
My benchmark takes up 93% of the CPU time.
Sending a request to the server takes 37%. Next comes any internal detailing, working with frames, and at the end of 19% this is an entry in our SocketChannel. We transfer the data and header of the request, as it should be in HTTP. And then we read -
readBody() .Next, we need to read the data that came to us from the server. What then is it?
If the engineers correctly named the methods, and I trust them, then here they send something to the server, and this takes as much time as sending our requests. Why do we send something when reading the server response?
To answer this question, I had to read the specification.
In general, a lot of performance problems are solved without knowing the specification. Somewhere you need to replace
ArrayList with LinkedList or vice versa, or Integer with int and so on. And in this sense it is very good if there is a benchmark. Measure - fix - work. And you do not go into details, how it works there according to the specification.But in our case, the problem really showed up in the specification: in the HTTP 2 standard there is a so-called flow-control. It works as follows. We have two feasts: one sends data, the other receives. The sender (sender) has a window - a flow-control window the size of a number of bytes (suppose 16 KB).
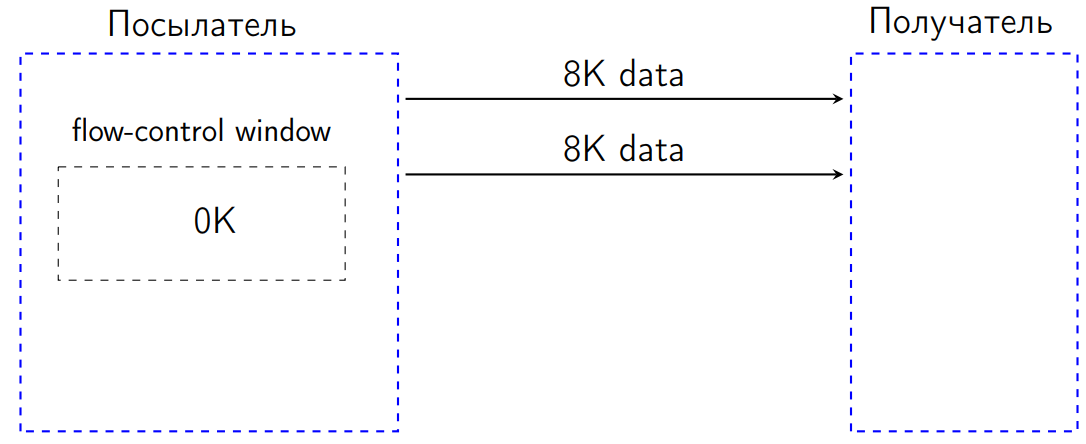
Let's say we sent 8K. The flow-control window is reduced by these 8 KB.
After we sent another 8 KB, the flow-control window was 0 KB.
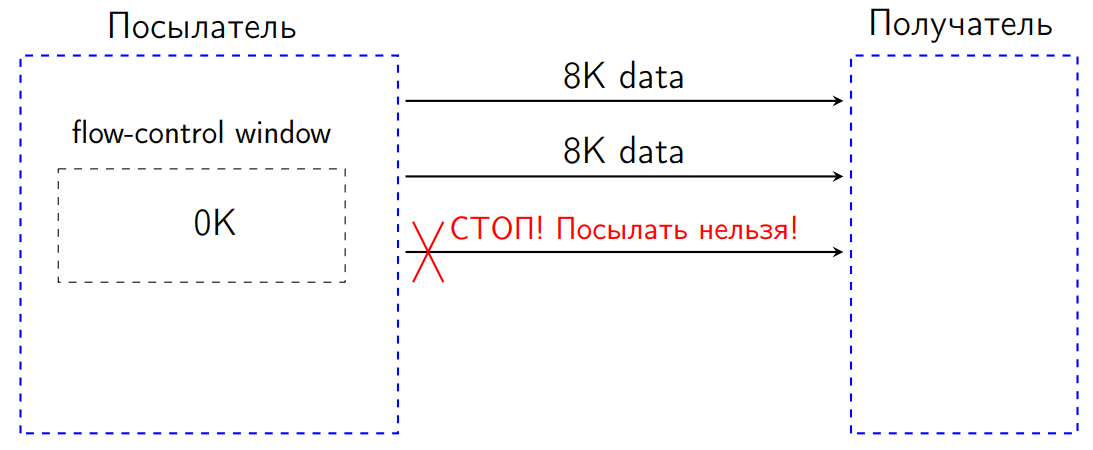
According to the standard in such a situation, we have no right to send anything. If we try to send some data, the recipient will be obliged to interpret this situation as a protocol error and close the connection. This is a kind of protection from DDOS, in some cases, so that we are not sent anything superfluous, and the sender adjusts to the capacity of the recipient.
When the receiver processed the received data, it had to send a special dedicated signal called WindowUpdate indicating how many bytes to increase the flow-control window.
When the WindowUpdate arrives to the sender, its flow-control window increases, we can send data further.
What is going on in the client?
We received data from the server - this is the real piece of processing:
// process incoming data frames ... DataFrame dataFrame; do { DataFrame dataFrame = inputQueue.take(); ... int len = dataFrame.getDataLength(); sendWindowUpdate(0, len); // update connection window sendWindowUpdate(streamid, len); //update stream window } while (!dataFrame.getFlag(END_STREAM)); ... A certain
dataFrame came - a data frame. We looked at how much data there was, processed it, and sent back WindowUpdate to increase the flow-control window to the desired value.In fact, in each such place two flow-control window works. We have a flow-control window specifically for this data transfer stream (request), and we also have a general flow control window for the entire connection. Therefore, we must send two WindowUpdate requests.
How to optimize this situation?
The first. At the end of the
while , we have a checkbox that says that the last data frame was sent to us. According to the standard, this means that no other data will come. And we do this: // process incoming data frames ... DataFrame dataFrame; do { DataFrame dataFrame = inputQueue.take(); … int len = dataFrame.getDataLength(); connectionWindowUpdater.update(len); if (dataFrame.getFlag(END_STREAM)) { break; } streamWindowUpdater.update(len); } while (true); ... This is a small optimization: if we catch the end-of-stream flag, then WindowUpdate can no longer be sent for this stream: we don’t wait for any data anymore, the server will not send anything.
The second. Who said we should send WindowUpdate every time? Why can't we, having received many requests, process the incoming data and only then send a WindowUpdate package for all incoming requests?
Here is
WindowUpdater , which works for a specific flow-control window: final AtomicInteger received; final int threshold; ... void update(int delta) { if (received.addAndGet(delta) > threshold) { synchronized (this) { int tosend = received.get(); if( tosend > threshold) { received.getAndAdd(-tosend); sendWindowUpdate(tosend); } } } } We have a certain
threshold . We receive data, do not send anything. Once we have typed the data up to this threshold , we send the entire WindowUpdate. There is a kind of heuristics that works well when the threshold value is close to half of the flow-control window. If we had this window initially 64 KB, and we received 8 KB each, then as soon as we received several data frames with a total volume of 32 KB, we send the window updater immediately to 32 KB. Normal batch processing. For good synchronization, we are also doing a completely normal double check.For a request of 1 byte, we get:
The effect will be even for megabyte requests, where there are a lot of frames. But he, naturally, is not so noticeable. In practice, I had different benchmarks, requests of different sizes. But here for each case I didn’t draw graphics, but picked up simple examples. Squeeze more detailed data will be a little later.
We received only + 23%, but the Jetty has already overtaken.
Moral: accurate reading specifications and logic are your friends.
There is a nuance of specification. There, on the one hand, it says that when we receive a data frame, we must send WindowUpdate. But, having carefully read the specification, we will see: there is no requirement that we are obliged to send WindowUpdate to every received byte. Therefore, the specification allows such a batch update to the flow-control window.
Alteration 3. Locks
Let's explore how we scale (scale).
The laptop is not very suitable for scaling - it has only two real and two fake cores. We will take some server machine, in which 48 hardware threads, and launch the benchmark.
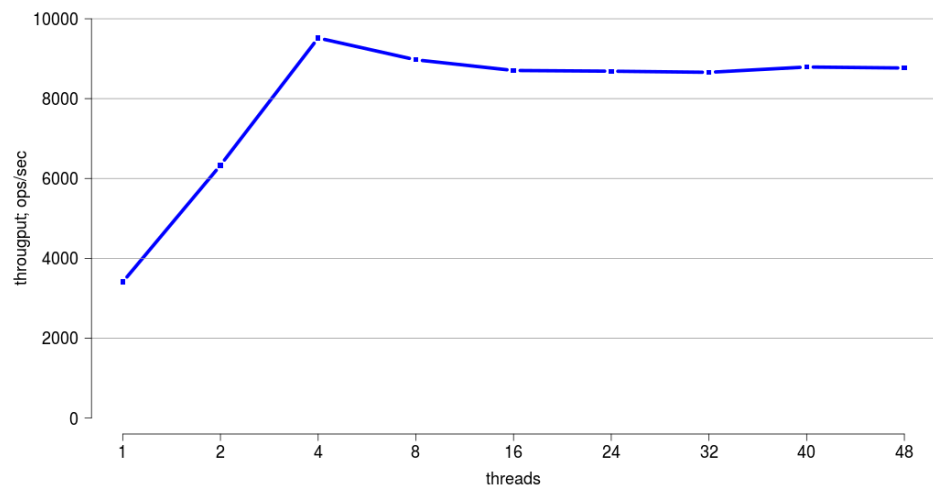
Here, horizontally is the number of threads, and vertically shows the total throughput.
Here you can see that up to four threads we scale very well. But further, the scalability becomes very bad.
It would seem, why do we need it? We have one customer; we will get the necessary data from the server from one thread and forget about it. But first, we have an asynchronous version of the API. To her we will come. There certainly will be some threads. Secondly, in our world now everything is multi-core, and to be able to work well with many threads in our library is simply useful - if only because when someone starts complaining about the performance of the single-threaded version, he can be advised to switch to multi-threaded and get a benefit. Therefore, let's look for the culprit in bad scalability. I usually do it like this:
#!/bin/bash (java -jar benchmarks.jar BenchHttpGet.get -t 4 -f 0 &> log.log) & JPID=$! sleep 5 while kill -3 $JPID; do : done I just write the file to file. In reality, this is enough for me in 90% of cases when I work with locks without any profilers. Only in some complicated trick cases I launch the Mission control or something else and watch the allocation of locks.
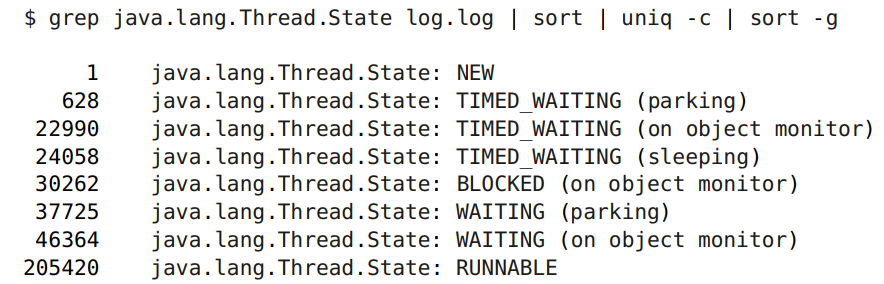
In the log you can see in what state I have different threads:
Here we are interested in precisely blocking, rather than waiting, when we expect events. There are 30 thousand locks, which is quite a lot against 200 thousand runnable ones.
But such a command line will simply show us the culprit (nothing extra is needed - just the command line):
The culprit is caught. This is a method inside our library that sends a data frame to the server. Let's figure it out.
void sendFrame(Http2Frame frame) { synchronized (sendlock) { try { if (frame instanceof OutgoingHeaders) { OutgoingHeaders oh = (OutgoingHeaders) frame; Stream stream = registerNewStream(oh); List frames = encodeHeaders(oh, stream); writeBuffers(encodeFrames(frames)); } else { writeBuffers(encodeFrame(frame)); } } catch (IOException e) { ... } } } Here we have a global monitor:
But this thread -
- the beginning of the initiation of the request. This is the sending of the very first header to the server (some additional actions are required here, I will talk about them now).
This is sending all other frames to the server:
All this under a global lock!
sendFrame itself sendFrame us an average of 55% of the time.But this method takes 1%:
Let's try to understand what can be taken out from under the global lock.
Registration of a new stream from under the lock can not be made. The HTTP standard imposes a restriction on the numbering of streams. In
registerNewStream new stream gets a number. And if I sent streams with numbers 15, 17, 19, 21 and sent 21 and then 15 to transfer my data, it will be a protocol error. I have to send them in ascending order. If I take them out of the lock, they may not be sent in the order in which I am waiting.The second problem, which is not removed from the lock:
Here is the header compression.
In its usual form, our header is put in the usual map - key value (from string to string). In
encodeHeaders header compression occurs. And here the second rake of the HTTP 2 standard is the HPACK algorithm, which works with compression, statefull. Those. he has a state (therefore, compresses very well). If I send two requests (two header-a), while at first I squeezed one, then the second, then the server must receive them in the same order. If he receives them in a different order, he will not be able to decode. This problem is the serialization point. All coding of all HTTP requests must pass through a single point of serialization, they cannot work in parallel, and even after that, the encoded frames must be sent.The
encodeFrame method takes 6% of the time, and it can theoretically be taken out from under the lock.encodeFrames drops the frame into the byte buffer in the form in which it is defined by the specification (before that, we prepared the internal structure of the frames). It takes 6% of the time.Nothing prevents us from
encodeFrames out encodeFrames from blocking, except for the method where the actual recording to the socket occurs:There are some implementation nuances.
So it turned out that
encodeFrames can encode a frame not into one, but into several byte buffers. This is primarily due to efficiency (so as not to make too much copying).If we try to take
writeBuffers out of the lock, and writeBuffers from the two frames are mixed up, we will not be able to decode the frame. Those. we must provide some kind of atomicity. At the same time writeBuffers is executed inside writeBuffers , and there stands its own global lock on writing to the socket.Let's do the first thing that comes to mind - the queue queue. We will put the byte buffer in this queue in the correct order, and let another thread read from it.
In this case, the
writeBuffers method generally “leaves” this thread. There is no need to keep it under this lock (it has its own global lock). The main thing for us is to ensure the order of byte-buffers that arrive there.So, we removed one of the most difficult operations outside and launched an additional thread. The size of the critical section was reduced by 60%.
But the implementation has its drawbacks:
- For some frames in the HTTP 2 standard, there is a limit in order. But other frames on the specification can be sent earlier. I can send the same WindowUpdate earlier than others. And I would like to do this, because the server is worth it - it is waiting (it has flow-control window = 0). However, the implementation does not allow this;
- The second problem is that when our queue is empty, the sending thread goes to sleep and wakes up for a long time.
Let's solve the first problem with the frame order.
An obvious idea -
Deque<ByteBuffer[]> .We have an inseparable piece of byte buffers that cannot be mixed with anything; we add it into an array, and the array itself into a queue. Then these arrays can be intermixed with each other, and where we need a fixed order, we provide it:
- ByteBuffer [] - atomic buffer sequence;
- WindowUpdateFrame - we can put it at the head of the queue and remove it from the blocking at all (it has neither protocol coding nor numbering);
- DataFrame - can also be removed from the lock and put in the end of the queue. As a result, the lock is becoming less and less.
Pros:
- fewer locks;
- sending window Update early allows the server to send data earlier.
But here there is one more minus. Still, the sending stream often falls asleep and wakes up for a long time.
Let's do this:
We will have a little turn of our own. In it, we add the resulting arrays of byte-buffers. After that, between all threads that came out from under the lock, we will arrange a competition. Who won, let him write to the socket. And let the rest work on.
It should be noted that another optimization turned out to be in the
flush() method, which has the effect: if I have a lot of small data (for example, 10 arrays of three to four buffers) and an encrypted SSL connection, it can take more than one array from the queue , and larger chunks, and send them to SSLEngine. In this case, the costs of coding are dramatically reduced.Each of the three optimizations presented allowed us to very well remove the problem with scaling. Something like this (the overall effect is reflected):
Moral: Locks - evil!
Everyone knows that you need to get rid of locks. Moreover, the concurrent library is becoming more advanced and interesting.
Alteration 4. Pool or GC?
In theory, we have an HTTP Client designed for 100% use of ByteBufferPool. But in practice ... Immediately, the bugs, here - something fell, there - the frame was underworked ... And if ByteBuffer did not return the pool back, the functionality did not break ... In general, the engineers had no time to deal with it. And we got an unfinished version, sharpened into pools. We have (and cry):
- only 20% of buffers are returned to the pool;
- ByteBufferPool.getBuffer () takes 12% of the time.
We get all the disadvantages of working with pools, and at the same time - all the disadvantages of working without pools. There are no pluses in this version. We need to move forward: either to make a normal full-fledged pool so that all ByteBuffers return to it after use, or even to cut the pools, but at the same time we even have them in the public API.
What do people think about pools? Here is what you can hear:
- No pool needed, pools are generally harmful! eg Dr. Cliff Click, Brian Goetz, Sergey Kuksenko, Aleksey Shipil¨ev, ...
- some claim that the pool is cool and has an effect. Poole needed! eg Netty (blog.twitter.com/2013/netty-4-at-twitter-reduced-gc-overhead), ...
DirectByteBuffer or HeapByteBuffer
Before returning to the question of pools, we need to solve a sub-question - what do we use in our problem with the HTTPClient: DirectByteBuffer or HeapByteBuffer?
First, we study the question theoretically:
- DirectByteBuffer is better for I / O.
sun.nio. * copies the HeapByteBuffer to the DirectByteBuffer; - HeapByteBuffer is better for SSL.
SSLEngine works directly with byte [] in the case of HeapByteBuffer.
Indeed, for transferring data to the socket DirectByteBuffer is better. Because if we follow the Write-s chain to nio, we will see the code where from HeapByteBuffer everything is copied into the internal DirectByteBuffer. And if we have a DirectByteBuffer, we do not copy anything.
But we have another thing - an SSL connection. The standard HTTP 2 allows you to work with both plain connection and SSL connection, but it is declared that SSL should be the de facto standard for the new web. If we follow the chain of how OpenJDK implements it in the same way, it turns out that theoretically SSLEngine works better with HeapByteBuffer, because it can reach the byte [] array and encrypt it. And in the case of DirectByteBuffer, he must first copy here, and then back.
And measurements show that HeapByteBuffer is always faster:
- PlainConnection - HeapByteBuffer is “faster” by 0% -1% - I put in quotes, because 0-1% is not faster. But there is no benefit from using DirectByteBuffer, and there are more problems;
- SSLConnection - HeapByteBuffer is 2% -3% faster
Those.HeapByteBuffer is our choice!
Oddly enough, reading and copying from DirectByteBuffer is more expensive, because checks remain there. The code there is not very well vectorized, since it works through unsafe. And in HeapByteBuffer - intrinsic (not even vectorization). And soon it will work even better.
Therefore, even if HeapByteBuffer were 2-3% slower than DirectByteBuffer, it might not make sense to do DirectByteBuffer. So let's get rid of the problem.
Let's make various options.
Option 1: All in pool
- We write a normal pool. We clearly monitor the life paths of all the buffers so that they return to the pool.
- We optimize the pool itself (based on the ConcurrentLinkedQueue).
- Separate pools (by buffer size). The question arises, what size should be the buffer. I read that Jetty made a universal ByteBufferPool, which allows you to work with byte buffers of various sizes with a granularity of 1 KB. We just need three different ByteBufferPool, each working with its own size. And if the pool works with buffers of only one size, everything becomes much simpler:
- SSL packets (SSLSession.getPacketBufferSize ());
- header encoding (MAX_FRAME_SIZE);
- all the rest.
Advantages of option 1:
- less “allocation pressure”
Minuses:
- . ? , ByteBuffer -, , , . , -. . , ;
- « »;
- ( );
- , :
ByteBuffer.slice()ByteBuffer.wrap(). ByteBuffer, - , , slice(). slice() . , . , . , - . , 128 , -, 128 , . , . — -. - . , . , .
2: — GC
GC will do all the work, especially since we do not have DirectByteBuffer, but HeapByteBuffer.
- we remove all pools, including those from the Public API, because in reality they do not carry any functionality, except for some internal technical implementation.
- well, naturally, since GC now collects everything from us, we don’t need to copy the data - we actively use
ByteBuffer.slice()/wrap()- we cut and wrap buffers.
Pros:
- the code has really become easier to understand;
- no pools in the public API;
- we have a good “data locality”;
- a significant reduction in copying costs; everything works this way;
- no pool costs.
But two problems:
- First, the allocation of data is above “allocation pressure”
- and the second problem is that we often don’t know which buffer we need. We read from the network, from I / O, from the socket, we allocate a buffer of 32 KB, well, even if it is 16 KB. And from the network read 12 bytes. And what do we have to do with this buffer? Only throw out. We get an inefficient use of memory (when the required buffer size is unknown) - for the sake of 12 Byte, 16 KB was allocated.
Option 3: Mix
For the sake of experiment we make a mixed version. I will tell about it in more detail. Here we choose the approach depending on the data.
Outgoing data:
- user data. We know their size, with the exception of coding in the HPACK algorithm, so we always allocate buffers of the right size — we do not have memory efficiently. We can do all sorts of cuts and wrapping without unnecessary copying - and let GC collect.
- for compressing HTTP headers - a separate pool, where the byte buffer comes from and then returns there.
- all the rest is buffers of the required size (GC will collect)
Incoming data:
- reading from socket - buffer from a pool of some normal size - 16 or 32 KB;
- send data (DataFrame) -
slice()(GC collect); - all the rest is returned to the pool.
In general, the standard HTTP 2 has nine types of frames. If eight of them came (everything except data), then we decode the byte buffer in the same place and we do not need to copy anything from it, and we return the byte buffer back to the pool. And if the data came, we perform a slice, so that we don’t have to copy anything, and then just throw it away - it will be assembled by the GC.
Well, a separate pool for encrypted SSL connection buffers, because there is a different size.
Pluses of the mixed option:
- the average complexity of the code (in something, but basically it is simpler than the first option with pools, because less needs to be tracked);
- no pools in the public API;
- good “data locality”;
- no copying costs;
- eligible pool costs;
- acceptable memory usage.
Minus one: above “allocation pressure”.
Comparison of options
We made three options, checked, corrected bugs, achieved functional work. We measure. We look at the allocation of data. I had 32 measurement scenarios, but I did not want to draw 32 graphs here. I will show just the range averaged over all dimensions. Here, the baseline is the original unfinished code (I took it for 100%). We measured the change in the allocation rate with respect to the baseline in each of the three modifications.
The option where everything goes to the pool predictably loses less. A variant that does not require any pools allocates eight times more memory than a variant without pools. But do we really need memory for the allocation rate? Measuring GC-pause:
With such GC-pauses at the allocation rate, this does not affect.
It is seen that the first option (in the pool to the maximum) gives 25% acceleration. Lack of pools to the maximum gives 27% of acceleration, and the mixed version gives a maximum of 36% of acceleration. Any properly completed version already gives an increase in productivity.
In a number of scenarios, the mixed version gives about 10% more than the option with pools or the option without any pools at all, so it was decided to stop there.
Moral: here I had to try various options, but there was no real need to totally work with pools by dragging them into the public API.
- Do not focus on "urban legends"
- Know the opinions of authorities
- But often "the truth is somewhere near"
Subtotals
The above are four modifications that I wanted to talk about in terms of working with blocking calls. Then I will talk a little about something else, but first I want to make an intermediate cut.
Here is a comparison of HttpClient and JettyClient on different types of connections and data volumes. Bars are slices; the higher the faster.
For GET requests, we are well ahead of Jetty. I put a tick. We have an acceptable performance with an acceptable cost. In principle, you can still squeeze there, but you need to stop once, otherwise you will not see this HttpClient in Java 9 or Java 10.
With POST requests, things are not so optimistic. When sending big data in a PLAIN connection, the Jetty still wins a little bit. But when sending small data and with an SSL-encrypted connection, we also have no problems.
Why do we not have data scaled when post size is large? Here we run into two serialization problems: in the case of an SSL connection, this lock is a write to the socket — it is global for writing to this particular SocketChannel. We cannot write to the socket in parallel. Although we are part of the JDK, the nio library for us is an external module where we cannot change anything. So when we write a lot, we run into this bottleneck.
With SSL (with encryption) the same situation. SSLEngine has encryption / decryption. They can work in parallel. But encryption is required to work consistently, even if I send data from many threads. This is a feature of the SSL protocol. And this is another serialization point. Nothing can be done with this, unless you switch to some native OpenSSL standards.
Alteration 5. Asynchronous API
Let's look at asynchronous requests.
Can we make such a completely simple version of the asynchronous API?
public <T> HttpResponse<T> send(HttpRequest req, HttpResponse.BodyHandler<T> responseHandler) { ... } public <T> CompletableFuture<HttpResponse<T>> sendAsync(HttpRequest req, HttpResponse.BodyHandler<T> responseHandler) { return CompletableFuture.supplyAsync(() -> send(req, responseHandler), executor); } I gave my executor - here it is written out (executor is configured in the client; I have some default executor, but you, as a user of this client, can give any executor there).
Alas, you can't just take and write an asynchronous API:
The problem is that in blocking requests we often wait for something.
Here is a very exaggerated picture. In reality, there is a query tree - waiting here, waiting there ... they are placed in different places.
Step 1 - transition to CompletableFuture
When we wait, we sit on wait or on condition. If we wait in the blocking API, and at the same time we put it in the Async executor, then we took the thread from the executor.
On the one hand, it is simply ineffective. On the other - we wrote an API that allows us to give our API any external executor. This, by definition, should work with a fixed thread pool (if a user can give any executor there, then we should be able to work in at least one thread).
In reality, this was a standard situation when all the threads from my executor were blocked. They are waiting for a response from the server, and the server is waiting and not sending anything until I also send something to it. I need to send something from the client, and I have no threads in the executor. Everything.We arrived.
It is necessary to cut the entire chain of requests so that each waiting point is wrapped in a separate CompletableFuture. Like that:
We have a user thread on the left. There we build a chain of queries. Here the method thenCompose, in which one future came, came the second future. On the other hand, we have a thread-thread selectormanager. It was in the sequential version, it just did not have to be optimized. It reads from the socket, decodes the frame and makes a complete.
When we come to thenCompose and see that we have a future that we are waiting for, has not yet been completed, we are not blocking (this is the asynchronous processing of the CompletableFuture), but leaving. The thread will return to the executor, continue to work on something else that is required for this executor, and then we will go on this execution further. This is a key feature CompletableFuture, which allows you to write such things effectively. We do not steal the thread from work. We always have someone to work with. And it is more effective in terms of performance.
We cut out all the locks on condition or wait, go to CompletableFuture. When the CompletableFuture is complete, then the thread is put to execution. We get + 40% to the processing of asynchronous requests.
Step 2 - delayed launch
We have a very popular genre of puzzlers. I do not really like jigsawers, but I want to ask. Suppose we have two threads and there is a CompletableFuture. In one thread, we attach a chain of actions - thenSomething. By this “Something” I mean Compose, Combine, Apply - any operations with CompletableFuture. And from the second thread we make the completion of this CompletableFuture.
The foo method is our action that should work - in which thread will it be executed?
The correct answer is C.
If we complete the chain - i.e. If we call the thenSomething method and the CompletableFuture has already been completed by this time, the foo method will be called in the first thread. And if the CompletableFuture has not yet been completed, it will be called from complete along the chain, i.e. from the second thread. With this key feature, we will now deal two times.
So, we in the user code build a chain of requests. We want the user to send me sendAsync. Those.I want in the user thread, where we do sendAsync, build a chain of requests and give the final CompletableFuture to the user. And there in my executor my threads, data sending, waiting will go to work.
I twist and saw java code on localhost. And what turns out: sometimes I don’t have time to complete the query chain, and the CompletableFuture is already completed:
I have only four hard work threads on this machine (there may be several dozen of them), and even then he doesn’t have time to complete it. I measured it in 3% of cases. An attempt to complete the query chain further leads to the fact that some actions on this chain, such as sending and receiving data, are invoked in a user course, although I do not want this. Initially, I want this whole chain to be hidden, i.e. the user should not see it. I want it to work in the executor.
Of course, we have methods that make Compose Async. If instead of thenCompose I call the method
thenComposeAsync(), I certainly will not translate my actions into the user stream.Pros of implementation:
- nothing gets into the user thread;
Minuses:
- too frequent switching from one thread from executor to another thread from executor (expensive). Nothing gets into user code, but methods
thenComposeAsync,thenApplyAsyncand generally any methods with an Async ending, switch the CompletableFuture execution to another thread from the same executor, even if we come from the thread of our executor (to Async) if it is fork-join by default or if it is explicitly set by executor. However, if the CompletableFuture is already complete, what's the point of switching from this thread? This switching from one thread to another is a waste of resources.
Here is such a trick was used:
CompletableFuture<Void> start = new CompletableFuture<>(); start.thenCompose(v -> sendHeader()) .thenCompose(() -> sendBody()) .thenCompose(() -> getResponseHeader()) .thenCompose(() -> getResponseBody()) ...; start.completeAsync( () -> null, executor); // !!! trigger execution We first take an empty incomplete CompletableFuture, we build to it the whole chain of actions that we need to perform, and we will start the execution. After that we will complete the CompletableFuture - we will do it
completeAsync- with the transition to our executor immediately. This will give us another 10% performance for asynchronous requests.Step 3 - complete () tricks
There is another problem with the CompletableFuture:
We have a CompletableFuture and a dedicated SelectorManager stream that CompletableFuture completes. We can not write here
future.complete. The problem is that the SelectorManager thread is internal, it processes all reads from the socket. And we give it to the user CompletableFuture. And he can attach a chain of his actions to him. If we start the execution of user actions using response.complete on the SelectorManager, the user can kill us with our dedicated stream SelectorManager, which should be engaged in proper operation, and should not be superfluous there. We have to somehow translate the execution - take it from that stream and push it into our executor, where we have a bunch of threads.It is simply dangerous.
We have
completeAsync.But by doing
completeAsync, we get the same problem.We very often have to switch the execution from thread to executor to another thread from the same executor along the chain. But we do not want to do a switch from SelectorManager to executor or from some user thread to executor. And inside the executor, we don't want our tasks to migrate. Performance suffers from this.
We can not do
CompleteAsync. From that side, we can always make the transition to Async.But here is the same problem. In both cases we have secured our work, in our thread nothing will start, but this migration is expensive.
Pros:
- nothing gets into the stream "SelectorManager"
Minuses:
- frequent switching from one thread from executor to another thread from executor (expensive)
Here's another trick: let's check, can we have the CompletableFuture already completed? If the CompletableFuture is not complete yet, we’ll go to Async. And if it is completed, it means I know for sure that the construction of the chain to the already completed CompletableFuture will be executed in my thread, and I am already doing this executor in this thread.
This is purely optimization, which removes unnecessary things.
And it gives another 16% performance to asynchronous requests.
As a result, all three of these optimizations for CompletableFuture dispersed asynchronous requests by about 80%.
Moral: Learn new.
CompletableFuture ( since 1.8)
Rework 6
The last fix was never made in the code of the HTTP Client itself simply because it is associated with the Public API. But the problem can be circumvented. I will tell you about it.
So, we have a client builder, we can give him an executor. If we did not give it an executor when creating the HTTP Client, it says that it is used by default
CachedThreadPool().Let's see what it is
CachedThreadPool(). I specifically emphasized what is interesting:There
CachedThreadPool()is one plus and one minus. By and large this is the same plus and minus. The problem is that when the CachedThreadPool()threads have ended, he creates new ones. On the one hand, this is good - our task is not sitting in a queue, not waiting, it can be immediately executed. On the other hand, this is bad because a new thread is being created.Before I made corrections from the previous paragraph (the fifth alteration), I measured, and it turned out that I
CachedThreadPool()created 20 threads for one request - there was too much waiting. 100 simultaneous threads issued out of memory exception. It did not work - even on servers that are available in our lab.I cut all the expectations, locks, made the "Fifth mess". My threads are no longer blocked, not wasted, but they work. All the same on one request through
CachedThreadPool()is created on average 12 flows. For 100 simultaneous requests, 800 threads were created. It creaked, but it worked.In fact, for such things
CachedThreadPool()executor can not be used. If you have very little tasks, there are a lot of them,CachedThreadPool()executor will do. But in general - no. He will create you many threads, then you will rake them.In this case, you need to fix the ThreadPool executor. Must measure options. But I’ll just show performance results for one that turned out to be the best candidate for correction
CachedThreadPool()with two threads:Two threads are the best option because writing to the socket is a bottleneck that cannot be parallelized, and SSLEngine cannot work in parallel either. The numbers speak for themselves.
Moral: Not all ThreadPools are equally useful.
With alterations HTTP 2 Client I have everything.
To be honest, reading the documentation, I swore a lot on the Java API. Especially in the part about byte buffer, sockets and so on. But my rules of the game were such that I should not have changed them. For me, the JDK is an external library on which this API is built.
But Comrade Norman Maurer was not as constrained as I was. And he wrote an interesting presentation - for those who want to dig deeper: Writing Highly Performant Network Frameworks on the JVM - A Love-Hate Relationship .
It scolds the base JDK API just in the area of sockets, APIs and other things. And describes what they wanted to change and what they lacked at the JDK level when they wrote Netty. These are all the same problems that I met, but could not fix it within the framework of the rules of the game.
If you like to savor all the details of Java development in the same way as we do, you probably will be interested in these reports at our April JPoint 2018 conference:
- Java ( , Devexperts)
- Program analysis: how to understand that you are a good programmer (Alexey Kudryavtsev, JetBrains)
- ( , )
- Java EE 8 finally final! And now EE4J? (David Delabassée, Oracle)
Source: https://habr.com/ru/post/352074/
All Articles