Resizing images on the site
Good day. I am a developer with over 10 years of experience. In order to assess the quality of the source code of the sites, not without a share of self-irony, I created a small checklist. Today I will talk about an important point for me - images on sites. I deliberately omitted a specific technology, because this problem was encountered and is found everywhere, I would be very grateful if in the comments you reveal your approaches using your technology stack, in the end we are all very similar.
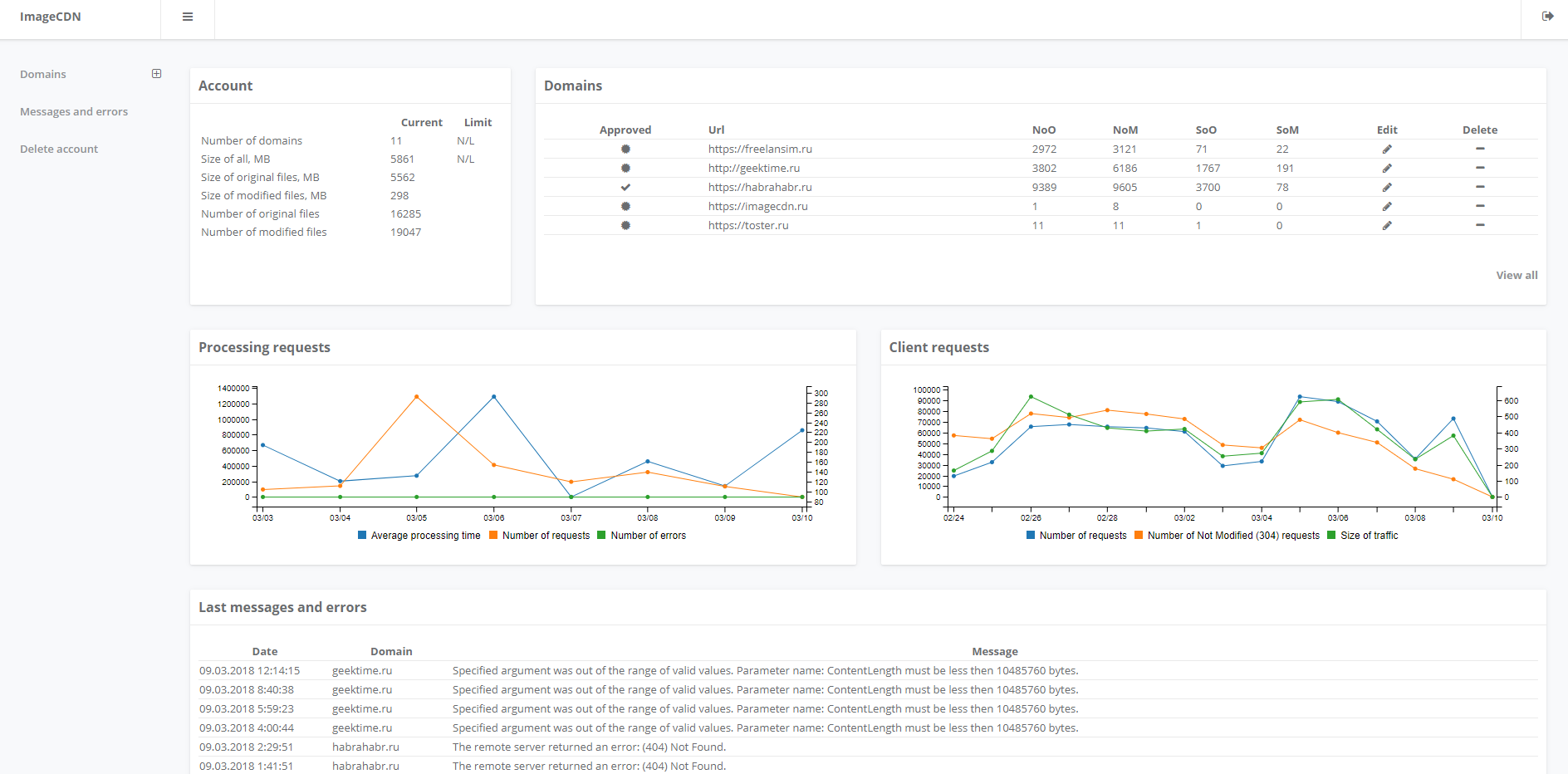
Experimentally, I found that the way to work with the image on the site is a litmus test of quality. See how a person works with images in five sizes and you can make a conclusion about the whole project. The reason is quite clear, I have not met a book or article that describes the logic of storing, updating and working with an image, if someone specifies it in the comments - I would be grateful. Everyone invented their own bike services, which could save on a specific directory structure or in the database. As time went on, the sites on the support evolved, somewhere the image sizes changed, somewhere new functionality was added, which required a new size of previously loaded images. Each step added a new round of the already debugged procedure: we walk in all the images - the originals, change the size and save in the necessary parameters. Long, expensive.
Manual control will sooner or later lead to failure, will require extra money for testing in a test environment. I started to search for a similar problem with others, because it has long been known that if you have some kind of problem, then you are not the first to encounter it. Pretty quickly, I went to the cloud services for changing images, caching and placement. I was delighted with the simplicity of the solution, using the link to the original image and the control parameters in it, you can get cropped, compressed, inverted, shifted, transparent, images with printed text and effects, and much, much more. One of these services, which seemed to me the most simple and convenient, I decided to try. For this, I made a list of the functionality I needed and decided to remove the time characteristics, because it’s not a secret to anyone that the speed of the site’s work is a very important parameter from the user's and search engines point of view.
')
Sample list by memory:
I walked through the functional requirements, each of them was reflected with an example of use and fully suited, there was a brief instruction manual and a small control panel for monitoring statistics and decreasing balance.
At the same time, I watched the speed and, to be honest, I did not expect good results in speed, as there was no Russia on the map of the location and processing servers. But I had noticed before that the speed to Europe and the USA is much better than to the neighboring city, so I decided to check. The results were acceptable, about 35-60 ms per image when changing the image width from 3000 to 500 and 30-150KB result.
Further caching was based on MaxAge and Last-modified, the ETag was missing and not transmitted from the source server of the storage in any way, but I could not think of a situation where it may be needed if there is Last-modified. MaxAge, when properly configured, quietly flowed to the service. I wondered how the service handles changing the original image on the server storage. There were three algorithms in my head, according to the first, he had to return to the original storage before returning the image and look at Last-modified from him, the second had to compare the information about what was stored in the service and at the repository in the background at some time, for example, obtained through MaxAge and the third, when the next update was assigned through MaxAge, but occurred only if the client makes a request. I decided to install a simple experiment, changing the original and requesting an image from the service. Then I found that the image has not changed, so the service does not access the repository until a certain point. Moreover, if you change the image again, the original image will be taken from the service cache, and not from the storage. Further, changing MaxAge, I achieved updating the original image in the service cache.
On my list, the price was in last place in order, but not in priority. I was unpleasantly upset by the price (I quote prices today) from $ 500 for a plan with SLA, while the plan for the number of accesses to the original image was also poorly arranged, each 1000 images were paid for separately. At the same time it was not clear how access to the original image is considered. Does access re-request a previously modified image from the service cache, without using the browser cache, i.e. new user, but before someone had already called and changed. This question arose because in one of the projects we had more than 150 new original images every day, which were viewed by at least 5 thousand people daily. Requests from the cache accounted for only ~ 50% of requests. The answer was simple, after the image service was loaded into the cache, all operations with it were unlimited and the restriction was only on consumed traffic. Having estimated the number of images came out about 150 dollars a month without traffic.
Everything would be fine, but 2014 came and the dollar began to confidently overcome the borders of the rational, the good, the eternal. Bablo began to defeat evil and it was decided to create their own service for changing images on the fly. So the internal project appeared, and recently (about a year ago) I and the team published a beta version for public testing. The service is built using Microsoft .NET technologies, and NoSQL Redis for caching original images. We work with different countries, in total about 15 sites. One of our clients, a site from Vietnam of popular Vietnamese music, as far as we can tell, from where he learned about our service is still a mystery. The attendance of each site from 50 to 30 000 people per day. Our target audience is relatively small (up to 50,000 - 100,000 people per day. Original image size is up to 10MB each, limited within the system) information sites, online stores, product catalogs, and just websites with responsive designs and a desire to reduce traffic or fill gaps with image compression in old IE.
The first version of the project was straightforward processing, no authorization and complete freedom of action for users of the service. I will say right away - this is a bad idea, in all respects except the convenience of the user, until the service falls under the load of unscrupulous users or directly violating the law. This is best shown on the diagram and identify the main components.
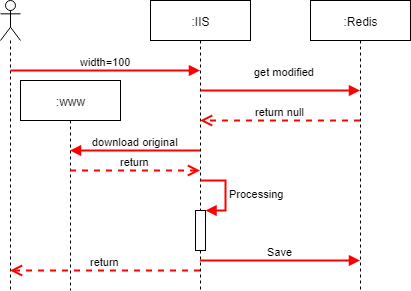
All query statistics, all caching parameters we stored on Redis. The originals and processed files were also stored there, because they wanted to maximize the speed of content delivery to the user, minimizing the participation of the disks. Having launched our prototype, we realized that it is quite viable and covers the requirements of one of the sites with interest (5,000-10,000 users per day). Placed on their own hardware, started to use. The problems started when we wanted to scale. Not because we got some sort of solution limit, but because other customers began to show interest in us and we began to fear that we could not cope with the growing load.
Thus was born the second version of the service. A version built on a queue on top of Redis and microservices that listen to the events of this queue. The facade was left behind by IIS, but it became very thin and began to proxy requests to the necessary services. There were restrictions both on the number of files and on their size, binding to the domain name in order to avoid unscrupulous users and indicate the owner to the appropriate structures, in case of their interest. DNS appeared with Round Robin and the ability to issue addresses relative to the intended client address (CDN).
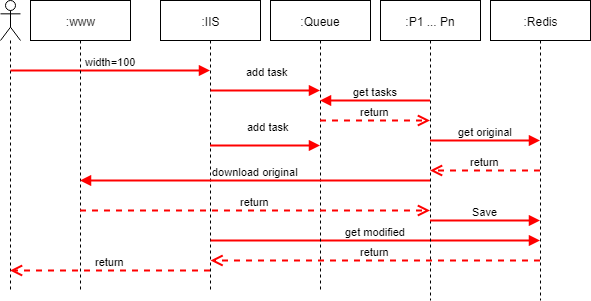
The scheme allowed us to spread processing services, duplicate them in terms of fault tolerance and performance, independently send the endpoints to the service without stopping the entire system. Moreover, services are no longer geographically linked.
We continue to develop the second version of the service. We really want to get feedback from users. We have a list of possible developments, with new features:
It is necessary - it is not necessary, it is important - it does not matter, therefore, during registration, a Early Adopter plan is issued, with 500 MB storage units, up to 5 domains, 2000 original images. It will remain with you only if you do not delete the account (this can be done on your own from the control panel at any time). All offers can and should be sent to support contacts or in the comments here. Keep in mind that the Early Adopter plan is flexible and if you need large scales, just write in support. High probability that you will be helped. Also, if it is interesting how some of the parts are arranged inside - write. I will try to answer all the questions, just give some code examples somewhere.
Contacts. I tried to approach the article objectively, not to violate the rules of topics and advertising, to share with you my thoughts about the simplicity of the approach. Thank you more for your time and attention. Contacts will inform in a personal message or comments, if there is interest.
Experimentally, I found that the way to work with the image on the site is a litmus test of quality. See how a person works with images in five sizes and you can make a conclusion about the whole project. The reason is quite clear, I have not met a book or article that describes the logic of storing, updating and working with an image, if someone specifies it in the comments - I would be grateful. Everyone invented their own bike services, which could save on a specific directory structure or in the database. As time went on, the sites on the support evolved, somewhere the image sizes changed, somewhere new functionality was added, which required a new size of previously loaded images. Each step added a new round of the already debugged procedure: we walk in all the images - the originals, change the size and save in the necessary parameters. Long, expensive.
Manual control will sooner or later lead to failure, will require extra money for testing in a test environment. I started to search for a similar problem with others, because it has long been known that if you have some kind of problem, then you are not the first to encounter it. Pretty quickly, I went to the cloud services for changing images, caching and placement. I was delighted with the simplicity of the solution, using the link to the original image and the control parameters in it, you can get cropped, compressed, inverted, shifted, transparent, images with printed text and effects, and much, much more. One of these services, which seemed to me the most simple and convenient, I decided to try. For this, I made a list of the functionality I needed and decided to remove the time characteristics, because it’s not a secret to anyone that the speed of the site’s work is a very important parameter from the user's and search engines point of view.
')
Sample list by memory:
- Change width, proportional change in height.
- Change in height, proportional change in width.
- Crop the image at the specified boundaries.
- Fit the image to the boundaries of the rectangle.
- Caching and storage of results on the service side, while its regular update depending on the ETag and MaxAge.
- The time of receiving the modified image by a new user from Russia.
- Https availability.
- Reasonable price of the service and transparency of its payment.
I walked through the functional requirements, each of them was reflected with an example of use and fully suited, there was a brief instruction manual and a small control panel for monitoring statistics and decreasing balance.
At the same time, I watched the speed and, to be honest, I did not expect good results in speed, as there was no Russia on the map of the location and processing servers. But I had noticed before that the speed to Europe and the USA is much better than to the neighboring city, so I decided to check. The results were acceptable, about 35-60 ms per image when changing the image width from 3000 to 500 and 30-150KB result.
Further caching was based on MaxAge and Last-modified, the ETag was missing and not transmitted from the source server of the storage in any way, but I could not think of a situation where it may be needed if there is Last-modified. MaxAge, when properly configured, quietly flowed to the service. I wondered how the service handles changing the original image on the server storage. There were three algorithms in my head, according to the first, he had to return to the original storage before returning the image and look at Last-modified from him, the second had to compare the information about what was stored in the service and at the repository in the background at some time, for example, obtained through MaxAge and the third, when the next update was assigned through MaxAge, but occurred only if the client makes a request. I decided to install a simple experiment, changing the original and requesting an image from the service. Then I found that the image has not changed, so the service does not access the repository until a certain point. Moreover, if you change the image again, the original image will be taken from the service cache, and not from the storage. Further, changing MaxAge, I achieved updating the original image in the service cache.
On my list, the price was in last place in order, but not in priority. I was unpleasantly upset by the price (I quote prices today) from $ 500 for a plan with SLA, while the plan for the number of accesses to the original image was also poorly arranged, each 1000 images were paid for separately. At the same time it was not clear how access to the original image is considered. Does access re-request a previously modified image from the service cache, without using the browser cache, i.e. new user, but before someone had already called and changed. This question arose because in one of the projects we had more than 150 new original images every day, which were viewed by at least 5 thousand people daily. Requests from the cache accounted for only ~ 50% of requests. The answer was simple, after the image service was loaded into the cache, all operations with it were unlimited and the restriction was only on consumed traffic. Having estimated the number of images came out about 150 dollars a month without traffic.
Everything would be fine, but 2014 came and the dollar began to confidently overcome the borders of the rational, the good, the eternal. Bablo began to defeat evil and it was decided to create their own service for changing images on the fly. So the internal project appeared, and recently (about a year ago) I and the team published a beta version for public testing. The service is built using Microsoft .NET technologies, and NoSQL Redis for caching original images. We work with different countries, in total about 15 sites. One of our clients, a site from Vietnam of popular Vietnamese music, as far as we can tell, from where he learned about our service is still a mystery. The attendance of each site from 50 to 30 000 people per day. Our target audience is relatively small (up to 50,000 - 100,000 people per day. Original image size is up to 10MB each, limited within the system) information sites, online stores, product catalogs, and just websites with responsive designs and a desire to reduce traffic or fill gaps with image compression in old IE.
Architecture
The first version of the project was straightforward processing, no authorization and complete freedom of action for users of the service. I will say right away - this is a bad idea, in all respects except the convenience of the user, until the service falls under the load of unscrupulous users or directly violating the law. This is best shown on the diagram and identify the main components.
All query statistics, all caching parameters we stored on Redis. The originals and processed files were also stored there, because they wanted to maximize the speed of content delivery to the user, minimizing the participation of the disks. Having launched our prototype, we realized that it is quite viable and covers the requirements of one of the sites with interest (5,000-10,000 users per day). Placed on their own hardware, started to use. The problems started when we wanted to scale. Not because we got some sort of solution limit, but because other customers began to show interest in us and we began to fear that we could not cope with the growing load.
Thus was born the second version of the service. A version built on a queue on top of Redis and microservices that listen to the events of this queue. The facade was left behind by IIS, but it became very thin and began to proxy requests to the necessary services. There were restrictions both on the number of files and on their size, binding to the domain name in order to avoid unscrupulous users and indicate the owner to the appropriate structures, in case of their interest. DNS appeared with Round Robin and the ability to issue addresses relative to the intended client address (CDN).
The scheme allowed us to spread processing services, duplicate them in terms of fault tolerance and performance, independently send the endpoints to the service without stopping the entire system. Moreover, services are no longer geographically linked.
We continue to develop the second version of the service. We really want to get feedback from users. We have a list of possible developments, with new features:
- Drawing text on the image - already implemented
- Setting quality in the context of a domain, rules, and / or operation (this is now a hard OptimalCompression value)
- Adding a system selection - a plan for caching original images
- Adding sources other than the site (for example, Amazon or the new Mail with its cold storage)
- Placement of additional services outside the central region
It is necessary - it is not necessary, it is important - it does not matter, therefore, during registration, a Early Adopter plan is issued, with 500 MB storage units, up to 5 domains, 2000 original images. It will remain with you only if you do not delete the account (this can be done on your own from the control panel at any time). All offers can and should be sent to support contacts or in the comments here. Keep in mind that the Early Adopter plan is flexible and if you need large scales, just write in support. High probability that you will be helped. Also, if it is interesting how some of the parts are arranged inside - write. I will try to answer all the questions, just give some code examples somewhere.
Thank!
Contacts. I tried to approach the article objectively, not to violate the rules of topics and advertising, to share with you my thoughts about the simplicity of the approach. Thank you more for your time and attention. Contacts will inform in a personal message or comments, if there is interest.
Source: https://habr.com/ru/post/352012/
All Articles