Flask Mega-Tutorial, Part XVI: Full-Text Search
(edition 2018)
Miguel grinberg


This is the sixteenth part of a series of Flask Mega-textbooks, in which I am going to add the possibility of full-text search to a microblog.
Under the spoiler is a list of all articles in this 2018 series.
- Chapter 1: Hello world!
- Chapter 2: Templates
- Chapter 3: Web Forms
- Chapter 4: Database
- Chapter 5: User Logins
- Chapter 6: Profile Page and Avatars
- Chapter 7: Error Handling
- Chapter 8: Subscribers, Contacts, and Friends
- Chapter 9: Pagination
- Chapter 10: Email Support
- Chapter 11: Reconstruction
- Chapter 12: Date and Time
- Chapter 13: I18n and L10n
- Chapter 14: Ajax
- Chapter 15: Improving Application Structure
- Chapter 16: Full-Text Search (This article)
- Chapter 17: Deploying to Linux
- Chapter 18: Deploying to Heroku
- Chapter 19: Deploying to Docker Containers
- Chapter 20: JavaScript Magic
- Chapter 21: User Notifications (Available April 24, 2018)
- Chapter 22: Reference Tasks (Available May 1, 2018)
- Chapter 23: Application Programming Interfaces (APIs) (Available May 8, 2018)
Note 1: If you are looking for old versions of this course, this is here .
Note 2: If suddenly you would like to speak in support of my (Miguel) work, or simply do not have the patience to wait for the article for a week, I (Miguel Greenberg) offer the full version of this manual (in English) in the form of an electronic book or video. For more information, visit learn.miguelgrinberg.com .
The purpose of this chapter is to implement the search function for Microblog so that users can find interesting messages using their usual language. For many types of websites, you can simply allow Google, Bing, etc. To index all content and provide search results through their search APIs. This works for sites that have mostly static pages, such as a forum. But in my application, the main unit of content is the user post, which is a small part of the entire web page. The search I need refers to these individual blog posts, not entire pages. For example, if I’m looking for the word “dog,” I want to see posts that include this word in blogs of different users. The problem is that a page that shows all the posts that have the word "dog" (or any other possible search term) does not exist as a blog page that large search engines can find and index, so I have no other choice. except to create your own search function.
GitHub links for this chapter: Browse , Zip , Diff .
Introduction to Full-Text Search Engines
Full-text search support is not standardized like relational databases. There are several open-source full-text engines: Elasticsearch , Apache Solr , Whoosh , Xapian , Sphinx , etc. As if this is not enough! There are several databases that also provide search capabilities comparable to dedicated search engines, such as the ones I listed above. SQLite , MySQL and PostgreSQL offer some support for text search, as well as NoSQL databases such as MongoDB and CouchDB .
If you are wondering which of them can work in the Flask application, the answer is all of them! This is one of the strengths of Flask, it does its job and is not stubborn. So what is the best choice?
In my opinion, from the list of specialized search engines Elasticsearch stands out in particular. Both as the most popular and significant, it stands first as an “E” character in the ELK stack for indexing logs, together with Logstash and Kibana. Using search capabilities in one of the relational databases might be a good choice, but given the fact that SQLAlchemy does not support this functionality, I would have to process the search using raw SQL instructions or find a package with access to text queries, as well as sharing with SQLAlchemy.
Based on the above, I choose Elasticsearch, but I am going to implement all of the text indexing and search functions in such a way that it is very easy to switch to another engine. This will replace my implementation with an alternative version based on a different mechanism, simply by rewriting several functions in one module.
There are several ways to install Elasticsearch, including one-click installation or a zip file with binaries that you need to install yourself, and even a Docker image. The documentation has an installation page with detailed information about all these options. If you are using Linux, you will probably have an available package for your distribution. If you are using a Mac and you have Homebrew installed, then you can simply run brew install elasticsearch .
After installing Elasticsearch on your computer, you can check whether it works by entering http://localhost:9200 in the address bar of the browser, which should return some basic information about the service in JSON format.
Since Elasticsearch will be managed from Python, I will use the Python client library:
(venv) $ pip install elasticsearch Now it doesn’t hurt to update the requirements.txt file:
(venv) $ pip freeze > requirements.txt Elasticsearch Tutorial
First, I'll show you the basics of working with Elasticsearch from the Python shell. This will help you familiarize yourself with this service and understand its implementation, which I will discuss later.
To create a connection to Elasticsearch, create an instance of the Elasticsearch class by passing the connection URL as an argument:
>>> from elasticsearch import Elasticsearch >>> es = Elasticsearch('http://localhost:9200') Data in Elasticsearch is indexed during recording. Unlike a relational database, this is just a JSON object. The following example writes an object in a field of type text , under the index my_index :
>>> es.index(index='my_index', doc_type='my_index', id=1, body={'text': 'this is a test'}) If desired, index can store documents of different types, in which case the argument doc_type can be set to different values according to these different formats. I'm going to keep all documents in the same format, so I set the document type to the name of the index.
For each saved document, Elasticsearch receives a unique identifier and a JSON object with the data.
Let's save the second document at the same index:
>>> es.index(index='my_index', doc_type='my_index', id=2, body={'text': 'a second test'}) And now, when there are two documents in this index, I can perform a free-form search. In this example, I will look for this test :
>>> es.search(index='my_index', doc_type='my_index', ... body={'query': {'match': {'text': 'this test'}}}) The es.search() response is a Python dictionary with search results:
{ 'took': 1, 'timed_out': False, '_shards': {'total': 5, 'successful': 5, 'skipped': 0, 'failed': 0}, 'hits': { 'total': 2, 'max_score': 0.5753642, 'hits': [ { '_index': 'my_index', '_type': 'my_index', '_id': '1', '_score': 0.5753642, '_source': {'text': 'this is a test'} }, { '_index': 'my_index', '_type': 'my_index', '_id': '2', '_score': 0.25316024, '_source': {'text': 'a second test'} } ] } } Here you can see that the search returned two documents, each with its own assessment. The document with the highest score contains two words that I was looking for, and the other document contains only one. But, as you can see, even the best result does not have a great score, because the words do not quite correspond to the text.
Now let's see the result for the search for the word second :
>>> es.search(index='my_index', doc_type='my_index', ... body={'query': {'match': {'text': 'second'}}}) { 'took': 1, 'timed_out': False, '_shards': {'total': 5, 'successful': 5, 'skipped': 0, 'failed': 0}, 'hits': { 'total': 1, 'max_score': 0.25316024, 'hits': [ { '_index': 'my_index', '_type': 'my_index', '_id': '2', '_score': 0.25316024, '_source': {'text': 'a second test'} } ] } } The score is rather low because my search does not match the text in this document, but since only one of the two documents contains the word "second", the other document is not displayed at all.
The Elasticsearch request object has many parameters and all of them are well documented . Among them, such as pagination and sorting, as well as in the case of relational databases.
Feel free to add more entries to this index and try different search options. When you finish experimenting, you can delete the index with the following command:
>>> es.indices.delete('my_index') Elasticsearch configuration
Integrating Elasticsearch into an application is an excellent example of the coolness of Flask. This service and the Python package, which has nothing to do with Flask, but I still try to get a decent level of integration. I will start with the configuration that I will write in the app.config dictionary for Flask:
config.py : Elasticsearch Configuration.
class Config(object): # ... ELASTICSEARCH_URL = os.environ.get('ELASTICSEARCH_URL') As with many other configuration entries, the connection URL for Elasticsearch will be obtained from the environment variable. If the variable is not defined, we get the value None , and this will be a signal to disable Elasticsearch. This is done mainly for convenience, so as not to force us to always have the Elasticsearch service when working with the application, and in particular when performing unit tests. Therefore, to make sure that the service is used, I need to define the ELASTICSEARCH_URL environment ELASTICSEARCH_URL , either directly in the terminal, or by adding its .env file as follows:
ELASTICSEARCH_URL=http://localhost:9200 Elasticsearch creates a problem because it is not decorated with the Flask extension. I cannot create an instance of Elasticsearch in the global realm, as in the examples above, because to initialize it, I need access to the app.config , which becomes available only after calling the create_app() function. So I decided to add the elasticsearch attribute to the app instance in the application factory functions:
app / init .py : Elasticsearch instance.
# ... from elasticsearch import Elasticsearch # ... def create_app(config_class=Config): app = Flask(__name__) app.config.from_object(config_class) # ... app.elasticsearch = Elasticsearch([app.config['ELASTICSEARCH_URL']]) \ if app.config['ELASTICSEARCH_URL'] else None # ... Adding a new attribute to an app instance may seem a bit odd, but Python objects are not too strict in their structure; new attributes can be added to them at any time. An alternative, which you can also consider, is to create a subclass of Flask (perhaps call it Microblog ) with the elasticsearch attribute defined in its __init__() function.
Notice how I use the conditional expression to assign None Elasticsearch instance if the URL of the Elasticsearch service has not been defined in the environment.
Abstraction Full-Text Search
As I said in the introduction to the chapter, I want to simplify the possible transition from Elasticsearch to other search engines. And I don’t want to encode this function specifically for searching blog posts, but prefer to develop a solution that I can easily extend to other models in the future if I need it. For all these reasons, I decided to create an abstraction for the search function. The idea is to develop a function in general terms, so I will not assume that the Post model is the only one that needs to be indexed, and I also will not assume that Elasticsearch is the preferred index engine. But if I can't make any assumptions about anything, how can I make this work?
The first thing I need is to somehow find a common way to indicate which model and which field or fields in it should be indexed. I want to say that any model that needs indexing should define an attribute of the __searchable__ class that contains the fields that should be included in the index. For the Post model it will look like this:
app / models.py : Add a __searchable__ attribute to the Post model.
class Post(db.Model): __searchable__ = ['body'] # ... It says that this model should have an indexed body field. Let me explain for clarity! This attribute __searchable__ , which I added, is simply a variable, it has no behavior associated with it. It just helps me to write my indexing functions in general.
I'm going to write all the code that interacts with the Elasticsearch index in the app / search.py module. The idea is to save all Elasticsearch code in this module. The rest of the application will use the functions in this new module to access the index and will not have direct access to Elasticsearch. This is important because if one day I decide that I don’t like Elasticsearch anymore and get ready to switch to another engine, all I need to do is overwrite the functions in this one module and the application will continue to work as before.
For this application, I decided that I needed three auxiliary functions related to text indexing: I needed:
- Add entries to the full-text index
- remove entries from the index (provided that one day I support deleting blog posts),
- perform a search query.
Here is the app / search.py module, which implements these three functions for Elasticsearch, using the functionality I showed you above from the Python console:
app / search.py: Search functions.
from flask import current_app def add_to_index(index, model): if not current_app.elasticsearch: return payload = {} for field in model.__searchable__: payload[field] = getattr(model, field) current_app.elasticsearch.index(index=index, doc_type=index, id=model.id, body=payload) def remove_from_index(index, model): if not current_app.elasticsearch: return current_app.elasticsearch.delete(index=index, doc_type=index, id=model.id) def query_index(index, query, page, per_page): if not current_app.elasticsearch: return [], 0 search = current_app.elasticsearch.search( index=index, doc_type=index, body={'query': {'multi_match': {'query': query, 'fields': ['*']}}, 'from': (page - 1) * per_page, 'size': per_page}) ids = [int(hit['_id']) for hit in search['hits']['hits']] return ids, search['hits']['total'] All of these functions begin with checking whether app.elasticsearch is app.elasticsearch . In the case of None exit the function without any action. This means that if the Elasticsearch server is not configured, the application will continue to work without searching and without any errors. How convenient it will become clear during development or when performing unit tests.
Functions take the name index as an argument. In all calls that I pass to Elasticsearch, I use this name as the index name, as well as the document type, as I did in the Python console examples.
Functions that add and remove records from the index take the SQLAlchemy model as the second argument. The add_to_index() function uses the class variable __searchable__ added to the model to build the document inserted into the index. If you remember, Elasticsearch documents also needed a unique identifier. For this, I use the id field of the SQLAlchemy model, which is also unique. Using the same id value for SQLAlchemy and Elasticsearch is very useful when performing a search, because it allows me to link records in two databases. Another joke is that if you try to add an entry with an existing identifier, Elasticsearch will replace the old entry with a new one, so add_to_index() can be used for both new and changed objects.
I did not show you the es.delete () function that I used to use in remove_from_index() . This function deletes the document stored under the given identifier. Here is a good example of the convenience of using the same identifier for linking records in both databases.
The query_index() function accepts the index name and text for the search, as well as the paging controls, so the search results can be paginated as Flask-SQLAlchemy results. You have already seen an example of using the es.search() function from the Python console. The call I give out is quite similar, but instead of using the match query type, I decided to use multi_match , which can perform a search on several fields. The field name * , allows the installation of Elasticsearch to look at all the fields for searching the index. This is useful to make this feature universal, since different models may have different field names in the index.
The body argument of es.search() complements the query itself with a es.search() argument. The from and size arguments determine which subset of the entire result set needs to be returned. Elasticsearch does not provide a full Pagination object, similar to the Flask-SQLAlchemy object, so I will have to write the pagination procedure myself to calculate the value from .
The return in the query_index() function is somewhat more complicated. It returns two values: the first is a list of identification elements for the search results, and the second is the total number of results. Both are derived from the Python dictionary returned by the es.search() function. If you are not familiar with the expression that I use to get a list of identifiers, then I’ll explain: her name is list comprehension , and this is a fantastic Python function that allows you to convert lists from one format to another. In this case, I use a list generator to extract id values from a much larger list of results provided by Elasticsearch.
Is it too confusing? Perhaps a demonstration of these functions in the Python console can help you understand them better. In the next session, I manually add all messages from the database to the Elasticsearch index. In my test database, I had several messages that had the digits “one,” “two,” “three,” “four,” and “five,” so I used them in search queries. You may have to adapt your query to match the contents of your database:
>>> from app.search import add_to_index, remove_from_index, query_index >>> for post in Post.query.all(): ... add_to_index('posts', post) >>> query_index('posts', 'one two three four five', 1, 100) ([15, 13, 12, 4, 11, 8, 14], 7) >>> query_index('posts', 'one two three four five', 1, 3) ([15, 13, 12], 7) >>> query_index('posts', 'one two three four five', 2, 3) ([4, 11, 8], 7) >>> query_index('posts', 'one two three four five', 3, 3) ([14], 7) The query I sent returns seven results. At first, I requested 1 page with 100 points per page and received all seven possible. Then the following three examples show how I can break pages in a very similar way to how I did it for Flask-SQLAlchemy, except that the results come in the form of a list of identifiers instead of SQLAlchemy objects.
If you want to keep everything clean, delete the posts index after experimenting with it:
>>> app.elasticsearch.indices.delete('posts') Search Integration with SQLAlchemy
The solution that I showed you in the previous section is acceptable, but it still has several unsolved problems. The first and most obvious is that the results come in the form of a list of numeric identifiers. This is very inconvenient, because I need the SQLAlchemy models so that I can transfer them to the templates for rendering, and I need a way to replace this list of numbers with the corresponding models from the database. The second problem is that this solution requires the application to explicitly issue index calls. Messages are added or removed, which is not terrible, but not ideal, because an error that causes missing call indexation when making changes on the SQLAlchemy side is not going to be easily detected. Two databases will get out of sync more and more each time an error occurs and you probably won't notice it for a while. The best solution would be to automatically include these calls when making changes to the SQLAlchemy database.
The problem of replacing identifiers with objects can be solved by creating a SQLAlchemy query that reads these objects from the database. It sounds simple, but it’s actually not so easy to implement efficiently performing a single request.
To solve the second problem (automatic tracking of indexing changes), I decided to perform updates of the Elasticsearch index from the SQLAlchemy events. SQLAlchemy provides a large list of events about which applications can receive notifications. For example, for each commit commit ( commit changes ) session, I could have a function in an application called SQLAlchemy, in which I could apply the same updates that were made in the SQLAlchemy session to the Elasticsearch index.
To implement the solutions of these two tasks, I am going to write a mixin class. Remember to mixin? In Chapter 5, I added the UserMixin class from Flask-Login to the user model to entrust it with some of the functions that Flask-Login required. To support the search, I'm going to define my own SearchableMixin class, which, when connected to the model, will give it the ability to automatically manage the full-text index associated with the SQLAlchemy model. The mixin class will act as a "glue" layer between the worlds of SQLAlchemy and Elasticsearch, providing solutions to the two problems I mentioned above.
Let me show you the implementation, and then I will look at some interesting details. Note the use of several advanced methods, so you will need to carefully study this code to fully understand it.
app / models.py : SearchableMixin class.
from app.search import add_to_index, remove_from_index, query_index class SearchableMixin(object): @classmethod def search(cls, expression, page, per_page): ids, total = query_index(cls.__tablename__, expression, page, per_page) if total == 0: return cls.query.filter_by(id=0), 0 when = [] for i in range(len(ids)): when.append((ids[i], i)) return cls.query.filter(cls.id.in_(ids)).order_by( db.case(when, value=cls.id)), total @classmethod def before_commit(cls, session): session._changes = { 'add': list(session.new), 'update': list(session.dirty), 'delete': list(session.deleted) } @classmethod def after_commit(cls, session): for obj in session._changes['add']: if isinstance(obj, SearchableMixin): add_to_index(obj.__tablename__, obj) for obj in session._changes['update']: if isinstance(obj, SearchableMixin): add_to_index(obj.__tablename__, obj) for obj in session._changes['delete']: if isinstance(obj, SearchableMixin): remove_from_index(obj.__tablename__, obj) session._changes = None @classmethod def reindex(cls): for obj in cls.query: add_to_index(cls.__tablename__, obj) db.event.listen(db.session, 'before_commit', SearchableMixin.before_commit) db.event.listen(db.session, 'after_commit', SearchableMixin.after_commit) There are four functions in this mixin class — all class methods (See the classmethod decorator). This is a special method that is associated with the class, and not with a specific instance. Notice how I renamed the self argument used in the usual instance methods for cls so that it is clear that this method takes a class as the first argument, not an instance. For example, when connecting to the Post model, the search() method above will be called Post.search() without having an actual instance of the Post class.
The class method search() wraps the query_index() function from app / search.py, replacing the list of object identifiers with actual objects. Obviously, the first thing this function does is call query_index() , passing cls.__ tablename__ as an index name. With this arrangement, all indexes will be named with the Flask-SQLAlchemy name assigned to the relational table. The function returns a list of result IDs and their total number. The SQLAlchemy query, which retrieves the list of objects by their ID, is based on the CASE statement from the SQL language, which should be used to ensure that the results from the database come in the same order as the identifiers. This is important because the Elasticsearch query returns results sorted from more to less relevant. If you want to find out more about how this query works, you can refer to the answer to this question from StackOverflow . search() , , .
before_commit() after_commit() SQLAlchemy, . before , , , , , session.new session.dirty session.deleted . , . session._changes , , , Elasticsearch.
after_commit() , , Elasticsearch. _changes , before_commit() , , app/search.py .
reindex() — , . , - Python , . , Post.reindex(), ( search index ).
, db.event.listen() , . , before after . Post .
SearchableMixin Post , , befor after :
app/models.py : SearchableMixin class Post model.
class Post(SearchableMixin, db.Model): # ... reindex() , :
>>> Post.reindex() , SQLAlchemy, Post.search() . :
>>> query, total = Post.search('one two three four five', 1, 5) >>> total 7 >>> query.all() [<Post five>, <Post two>, <Post one>, <Post one more>, <Post one>] , . . .
- , , q URL-. , Python Google, , URL- , :
https://www.google.com/search?q=python URL- , , .
, - . POST , , , , GET , , URL- . , , .
, q :
app/main/forms.py : Search form.
from flask import request class SearchForm(FlaskForm): q = StringField(_l('Search'), validators=[DataRequired()]) def __init__(self, *args, **kwargs): if 'formdata' not in kwargs: kwargs['formdata'] = request.args if 'csrf_enabled' not in kwargs: kwargs['csrf_enabled'] = False super(SearchForm, self).__init__(*args, **kwargs) q , , . . , , , Enter , . __init__ , formdata csrf_enabled , . formdata , Flask-WTF . request.form , Flask , POST . , GET , , Flask-WTF request.args , Flask . , , CSRF- , CSRF, form.hidden_tag() . CSRF- , csrf_enabled False , Flask-WTF , CSRF .
, , SearchForm , . , , . , ( route ), ( templates ), , , . before_request , 6 , . , , , :
app/main/routes.py : before_request handler.
from flask import g from app.main.forms import SearchForm @bp.before_app_request def before_request(): if current_user.is_authenticated: current_user.last_seen = datetime.utcnow() db.session.commit() g.search_form = SearchForm() g.locale = str(get_locale()) , . , , , , , - . - g , Flask. g , Flask, , , . g.search_form , , before Flask , URL, g , , . , g , , - , g , , , .
— . , , . , , g , render_template() . :
app/templates/base.html : .
... <div class="collapse navbar-collapse" id="bs-example-navbar-collapse-1"> <ul class="nav navbar-nav"> ... home and explore links ... </ul> {% if g.search_form %} <form class="navbar-form navbar-left" method="get" action="{{ url_for('main.search') }}"> <div class="form-group"> {{ g.search_form.q(size=20, class='form-control', placeholder=g.search_form.q.label.text) }} </div> </form> {% endif %} ... , g.search_form . , , , . , . method get , , GET . , action empty, , . , , , , , .
- , . view — /search , http://localhost:5000/search?q=search-words , Google.
app/main/routes.py : Search view function.
@bp.route('/search') @login_required def search(): if not g.search_form.validate(): return redirect(url_for('main.explore')) page = request.args.get('page', 1, type=int) posts, total = Post.search(g.search_form.q.data, page, current_app.config['POSTS_PER_PAGE']) next_url = url_for('main.search', q=g.search_form.q.data, page=page + 1) \ if total > page * current_app.config['POSTS_PER_PAGE'] else None prev_url = url_for('main.search', q=g.search_form.q.data, page=page - 1) \ if page > 1 else None return render_template('search.html', title=_('Search'), posts=posts, next_url=next_url, prev_url=prev_url) , form.validate_on_submit() , , . , , POST , form.validate() , , , . , , , , .
Post.search() SearchableMixin . , Pagination Flask-SQLAlchemy. , Post.search() .
, , , - . index.html , , , search.html , , _post.html sub- :
app/templates/search.html : .
{% extends "base.html" %} {% block app_content %} <h1>{{ _('Search Results') }}</h1> {% for post in posts %} {% include '_post.html' %} {% endfor %} <nav aria-label="..."> <ul class="pager"> <li class="previous{% if not prev_url %} disabled{% endif %}"> <a href="{{ prev_url or '#' }}"> <span aria-hidden="true">←</span> {{ _('Previous results') }} </a> </li> <li class="next{% if not next_url %} disabled{% endif %}"> <a href="{{ next_url or '#' }}"> {{ _('Next results') }} <span aria-hidden="true">→</span> </a> </li> </ul> </nav> {% endblock %} 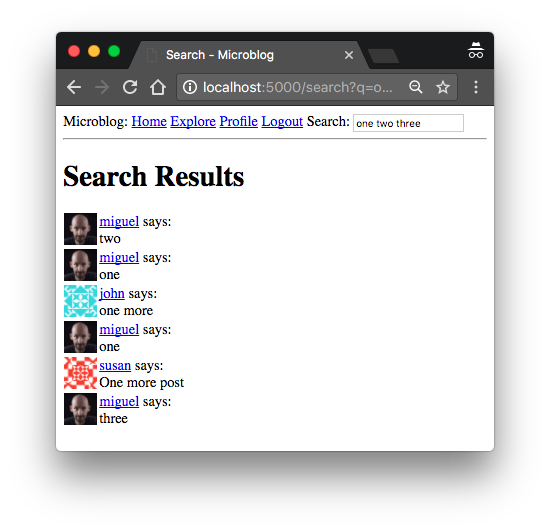
? , . . , Elasticsearch, , , app/search.py . , , , , SearchableMixin , __searchable__ SQLAlchemy. , , .
')
Source: https://habr.com/ru/post/351900/
All Articles