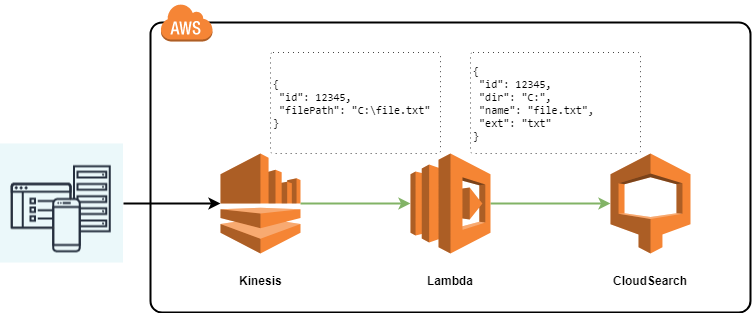
Aws Lambda Go 1.x, Kinesis, CloudSearch
In the previous article I described how to create a simple lambda on Golang, which takes as input a simple object of two fields and gives the same simple object at the output. Now let's complicate the task a bit by connecting Kinesis to the lambda as a data source, and we will transfer the result of processing Kinesis records to CloudSearch. No special logic in lambda will be simplified: just accept requests from Kinesis, log them in to CloudWatch, convert and send to CloudSearch.
The Kinesis event that we expect to receive in the function is as follows:
')
Here we are interested in the data field. The code of the Lambda function that receives events from Kinesis and logs the data of the data field is described below: (The code is taken here ):
Now you need to supplement the code to write the changed data in CloudSearch
Here we will generate the data from Kinesis into our submission for the search domain (CloudSearch).
Kinesis data comes in a base64 encoded form in the data field. After decoding, the data contains the following fields:
In CloudSearch, we send the following data:
In this case, the id field will be stored in the document identifier. The preparation of data for upload to CloudSearch can be found here in detail. In short, in CloudSearch we send the following json:
where type is a type of request that takes two values: add or delete; id is the document identifier, and in our case the value stored in the object from kinesis in the Id field; fields are name-value pairs that we save in the search domain, in our case, an object of type CloudSearchDocument.
The code below converts the data from the Records collection of an object from Kinesis into a collection of data ready for upload to CloudSearch:
The following code connects to the search domain to load previously prepared data into it:
In order to compile the code, it is necessary to load the aws -sdk-go and aws-lambda-go files :
How to collect and close the lambda described in the previous article, here it is only necessary to add environment variables through the Lambda console and prepare new test data:
The full code is available here .
But first, open the CloudSearch console and create a search domain. For the domain, I will choose the most minimal instance and the number of replications = 1. Next, you need to create the fields dir , name , ext . For these fields, I will select the string type, but some of them may have a different type, for example, a literal field. But it all depends on how you will manipulate these fields. For more information, read Amazon documentation.
Create a search domain (button Create a new Domain ), fill in the name and select the instance type:

Create fields:

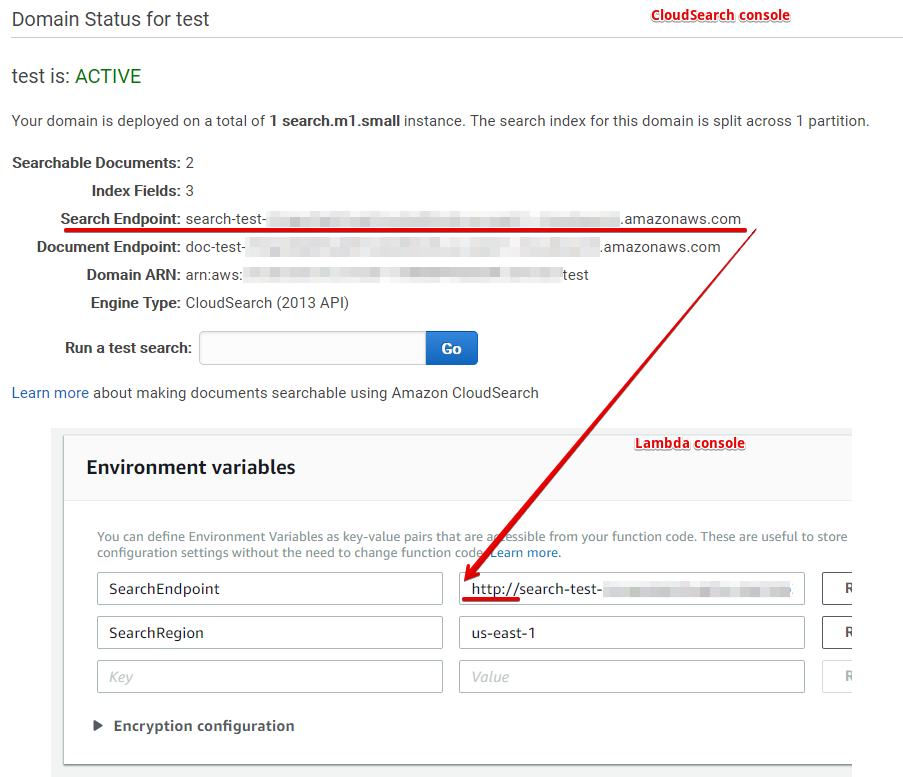
The domain is created about 10 minutes. After it becomes active, you will have the Url of the search domain that you need to enter in the environment variables in the Lambda console, do not forget to specify the protocol as in the image below in front of the Url, and also specify the region in which search domain:
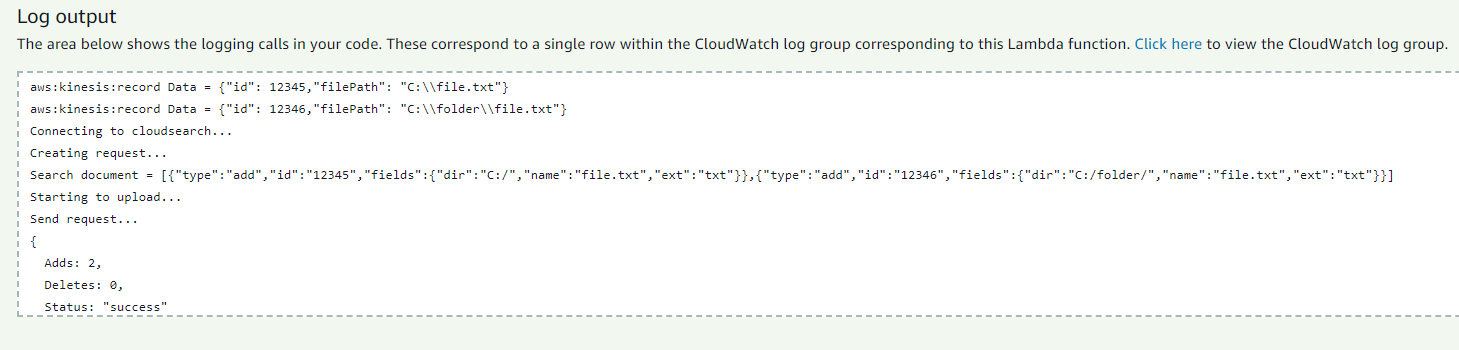
Now do not forget to issue the rights lambda through the IAM console for working with Kinesis, CloudWatch and CloudSearch. Kinesis can be connected via the Lambda console: to do this, select it in the Add triggers box and fill in the fields, indicating the stream existing in the region, the number of records in the batch and the position in the stream with which reading will begin. We can test the work of the lambda without connecting it to kinesis, for this you need to create a test and add the following json to it:
To generate other values of the data field, you can use the link .
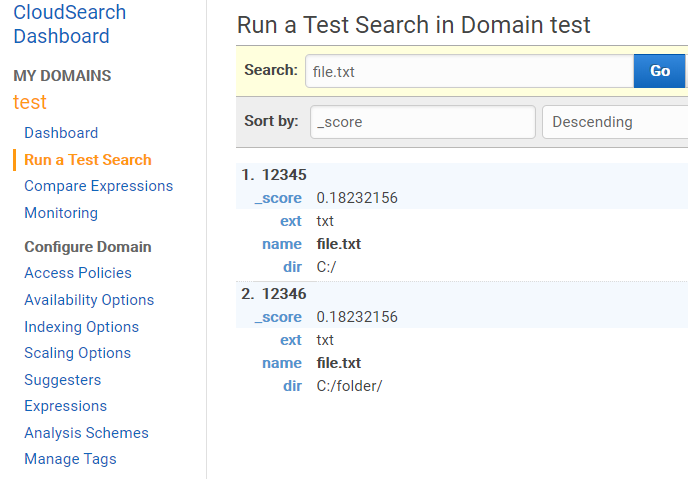
The result of the work can also be viewed in the search domain:
Additional materials:
Search code for documents in the search domain on Go.
The next article will discuss the CloudFormation script for the automatic creation and connection of Lambda, Kinesis, CloudSearch.
The Kinesis event that we expect to receive in the function is as follows:
')
{ "Records": [ { "awsRegion": "us-east-1", "eventID": "<event-id>", "eventName": "aws:kinesis:record", "eventSource": "aws:kinesis", "eventSourceARN": "arn:aws:kinesis:us-east-1:<xxxxxxxx>:stream/<stream>", "eventVersion": "1.0", "invokeIdentityArn": "arn:aws:iam::<xxxxxx>:role/<role>", "kinesis": { "approximateArrivalTimestamp": <timestamp>, "data": <data>, "partitionKey": "<partionkey>", "sequenceNumber": "<sequenceNumber>", "kinesisSchemaVersion": "1.0" } } ] } Here we are interested in the data field. The code of the Lambda function that receives events from Kinesis and logs the data of the data field is described below: (The code is taken here ):
package main import ( "context" "fmt" "github.com/aws/aws-lambda-go/events" "github.com/aws/aws-lambda-go/lambda" ) func handler(ctx context.Context, kinesisEvent events.KinesisEvent) error { for _, record := range kinesisEvent.Records { kinesisRecord := record.Kinesis dataBytes := kinesisRecord.Data dataText := string(dataBytes) fmt.Printf("%s Data = %s \n", record.EventName, dataText) } return nil } func main() { lambda.Start(handler) } Now you need to supplement the code to write the changed data in CloudSearch
Here we will generate the data from Kinesis into our submission for the search domain (CloudSearch).
Kinesis data comes in a base64 encoded form in the data field. After decoding, the data contains the following fields:
type KinesisEventData struct { FilePath string `json:"filePath"` Id int `json:"id"` } In CloudSearch, we send the following data:
type CloudSearchDocument struct { Directory string `json:"dir"` FileName string `json:"name"` FileExtension string `json:"ext"` } In this case, the id field will be stored in the document identifier. The preparation of data for upload to CloudSearch can be found here in detail. In short, in CloudSearch we send the following json:
[ {"type": "add", "id": "12345", "fields": { "dir": ":", "name": "file.txt", "ext": "txt" } } ] where type is a type of request that takes two values: add or delete; id is the document identifier, and in our case the value stored in the object from kinesis in the Id field; fields are name-value pairs that we save in the search domain, in our case, an object of type CloudSearchDocument.
The code below converts the data from the Records collection of an object from Kinesis into a collection of data ready for upload to CloudSearch:
var amasonDocumentsBatch []AmazonDocumentUploadRequest //Preparing data for _, record := range kinesisEvent.Records { kinesisRecord := record.Kinesis dataBytes := kinesisRecord.Data fmt.Printf("%s Data = %s \n", record.EventName, string(dataBytes)) //Deserialize data from kinesis to KinesisEventData var eventData KinesisEventData err := json.Unmarshal(dataBytes, &eventData) if err != nil { return failed(), err } //Convert data to CloudSearch format document := ConvertToCloudSearchDocument(eventData) request := CreateAmazonDocumentUploadRequest(eventData.Id, document) amasonDocumentsBatch = append(amasonDocumentsBatch, request) } The following code connects to the search domain to load previously prepared data into it:
if len(amasonDocumentsBatch) > 0 { fmt.Print("Connecting to cloudsearch...\n") svc := cloudsearchdomain.New(session.New(&aws.Config{ Region: aws.String(os.Getenv("SearchRegion")), Endpoint: aws.String(os.Getenv("SearchEndpoint")), MaxRetries: aws.Int(6), })) fmt.Print("Creating request...\n") batch, err := json.Marshal(amasonDocumentsBatch) if err != nil { return failed(), err } fmt.Printf("Search document = %s \n", batch) params := &cloudsearchdomain.UploadDocumentsInput{ ContentType: aws.String("application/json"), Documents: strings.NewReader(string(batch)), } fmt.Print("Starting to upload...\n") req, resp := svc.UploadDocumentsRequest(params) fmt.Print("Send request...\n") err = req.Send() if err != nil { return failed(), err } fmt.Println(resp) } In order to compile the code, it is necessary to load the aws -sdk-go and aws-lambda-go files :
go get -u github.com/aws/aws-lambda-go/cmd/build-lambda-zip go get -d github.com/aws/aws-sdk-go/ How to collect and close the lambda described in the previous article, here it is only necessary to add environment variables through the Lambda console and prepare new test data:
os.Getenv("SearchRegion") os.Getenv("SearchEndpoint") The full code is available here .
But first, open the CloudSearch console and create a search domain. For the domain, I will choose the most minimal instance and the number of replications = 1. Next, you need to create the fields dir , name , ext . For these fields, I will select the string type, but some of them may have a different type, for example, a literal field. But it all depends on how you will manipulate these fields. For more information, read Amazon documentation.
Create a search domain (button Create a new Domain ), fill in the name and select the instance type:
Create fields:
The domain is created about 10 minutes. After it becomes active, you will have the Url of the search domain that you need to enter in the environment variables in the Lambda console, do not forget to specify the protocol as in the image below in front of the Url, and also specify the region in which search domain:
Now do not forget to issue the rights lambda through the IAM console for working with Kinesis, CloudWatch and CloudSearch. Kinesis can be connected via the Lambda console: to do this, select it in the Add triggers box and fill in the fields, indicating the stream existing in the region, the number of records in the batch and the position in the stream with which reading will begin. We can test the work of the lambda without connecting it to kinesis, for this you need to create a test and add the following json to it:
{ "Records": [ { "awsRegion": "us-east-1", "eventID": "shardId-000000000001:1", "eventName": "aws:kinesis:record", "eventSource": "aws:kinesis", "eventSourceARN": "arn:aws:kinesis:us-east-1:xxx", "eventVersion": "1.0", "invokeIdentityArn": "arn:aws:iam::xxx", "kinesis": { "approximateArrivalTimestamp": 1522222222.06, "data": "eyJpZCI6IDEyMzQ1LCJmaWxlUGF0aCI6ICJDOlxcZmlsZS50eHQifQ==", "partitionKey": "key", "sequenceNumber": "1", "kinesisSchemaVersion": "1.0" } }, { "awsRegion": "us-east-1", "eventID": "shardId-000000000001:1", "eventName": "aws:kinesis:record", "eventSource": "aws:kinesis", "eventSourceARN": "arn:aws:kinesis:us-east-1:xxx", "eventVersion": "1.0", "invokeIdentityArn": "arn:aws:iam::xxx", "kinesis": { "approximateArrivalTimestamp": 1522222222.06, "data": "eyJpZCI6IDEyMzQ2LCJmaWxlUGF0aCI6ICJDOlxcZm9sZGVyXFxmaWxlLnR4dCJ9", "partitionKey": "key", "sequenceNumber": "2", "kinesisSchemaVersion": "1.0" } } ] } To generate other values of the data field, you can use the link .
The result of the work can also be viewed in the search domain:
Additional materials:
Search code for documents in the search domain on Go.
The next article will discuss the CloudFormation script for the automatic creation and connection of Lambda, Kinesis, CloudSearch.
Source: https://habr.com/ru/post/351876/
All Articles