How I parsed the C-Tree DB, developed 34 years ago

I recently had a task to add the functionality of one rather old program (there is no source code for the program). In fact, it was necessary to simply scan periodically the database, analyze the information and perform mailings on the basis of this. The whole difficulty turned out to be that the application works from the c-tree database, written in 1984 already.
Having rummaged on the website of the manufacturer of this database, I found a certain odbc driver, but I could not connect it at all. Numerous googling also did not help to connect normally to the base and retrieve the data. It was later decided to contact technical support and ask for help from the developers of this database, but the guys honestly admitted that 34 years had passed, everything changed 100,500 times, they don’t have normal drivers for connecting to such junk and probably there aren’t wrote this miracle.
Rummaging through the database files and examining the structure, I realized that each table in the database is saved in two files with the extension * .dat and * .idx. The idx file stores information on id, index, etc. for faster information search in the database. The dat file contains the information itself, which is stored in the labels.
It was decided to parse these files independently and somehow obtain this information. Go was used as a language, since the rest of the project is written on it.
I will describe only the most interesting moments that I encountered in data processing, which mainly affect not the Go language itself, but the computational algorithms and the magic of mathematics.
')
From the go understand that where in the files is unrealistic, since there is no normal encoding, the data is written to some specific bits and initially looks more like a data trash.

I received an inspirational little phrase from a client with a short description of why: “**** was a MS-DOS application running on 8086 processors and memory was scarce”.
The logic of the work was this: I assign some new data in the program, I look at which files were changed and then I try to extract the data bits that changed values.
During the development process, I realized the following important rules that helped me figure out more quickly:
- the beginning and end of the file (the size is always different) are reserved for tabular data
- the length of the row in the table is always the same number of bytes
- calculations are performed in the 256th level
Time in schedule
The application creates a schedule with an interval of 15 minutes (For example, 12:15 - 14:45). Poke at different times, I found a memory area that is responsible for the clock. I read data from file byte-by-bye. For time, 2 bytes of data are used.
Each byte can contain a value from 0 to 255. When 15 minutes are added to the schedule, the number 15 is added to the first byte. Plus 15 minutes more and in the byte number 30, etc.
For example, we have the following values:
[0] [245]
As soon as the value exceeds 255, 1 is added to the next byte, and the remainder is written to the current byte.
245 + 15 = 260
260 - 256 = 4
Total we have a value in the file:
[14]
And now attention! Very interesting logic. If this range is from 0 minutes to 45 minutes per hour, then 15 minutes is added to the bytes. BUT! If it is the last 15 minutes in an hour (from 45 to 60), then the number 55 is added to the bytes.
It turns out that 1 hour is always equal to the number 100. If we have 15 hours and 45 minutes, then we will see the following data in the file:
[6] [9]
And now we turn on some magic and translate the values from bytes to an integer:
6 * 256 + 9 = 1545
If you divide this number by 100, then the integer part will be equal to the hours, and the fractional will be minutes:
1545/100 = 15.45
Kodjar:
data, err := ioutil.ReadFile(defaultPath + scheduleFileName) if err != nil { log.Printf("[Error] File %s not found: %v", defaultPath+scheduleFileName, err) } timeOffset1 := 98 timeOffset2 := 99 timeSize := 1 //first 1613 bytes reserved for table //one record use 1598 bytes //last 1600 bytes reserved for end of table for position := 1613; position < (len(data) - 1600); position += 1598 { ... timeInBytesPart1 := data[(position + timeOffset2):(position + timeOffset2 + timeSize)] timeInBytesPart2 := data[(position + timeOffset1):(position + timeOffset1 + timeSize)] totalBytes := (int(timeInBytesPart1[0]) * 256) + int(timeInBytesPart2[0]) hours := totalBytes / 100 minutes := totalBytes - hours*100 ... } Date in schedule
The logic of calculating the value of bytes for dates is the same as in time. The byte is filled to 255, then reset to zero, and 1 is added to the next byte, and so on. Only for the date it was already allocated not two, but four bytes of memory. Apparently the developers decided that their application could live several million more years. It turns out that the maximum number we can get is equal to:
[255] [255] [255] [256]
256 * 256 * 256 * 256 + 256 * 256 * 256 + 256 * 256 + 256 = 4311810304
The reference starting date in the appendix is December 31, 1849. I consider the specific date by adding days. I initially know that AddDate from the time package has a limitation and will not be able to eat 4311810304 days, however, the next 200 years will be enough).
After analyzing a decent number of files, I found three options for the location of dates in memory:
- reading bytes of a specific memory area must be performed from left to right
- reading bytes of a specific memory area must be performed from right to left
- a zero byte is inserted between each “useful byte” of the data. For example [1] [0] [101] [0] [100] [0] [28]
I did not manage to understand why different logic was used to locate the data, but the principle of calculating the date is the same everywhere, the main thing is to get the data correctly.
Kodjar:
func getDate(data []uint8) time.Time { startDate := time.Date(1849, 12, 31, 0, 00, 00, 0, time.UTC) var result int for i := 0; i < len(data)-1; i++ { var sqr = 1 for j := 0; j < i; j++ { sqr = sqr * 256 } result = result + (int(data[i]) * sqr) } return startDate.AddDate(0, 0, result) } Availability schedule
Employees have an availability schedule. Up to three time intervals can be assigned per day. For example:
8:00 - 13:00
14:00 - 16:30
5:00 pm - 7:00 pm
Schedule can be scheduled for any day of the week. I needed to generate a schedule for the next 3 months.
Here is an example file storage scheme:
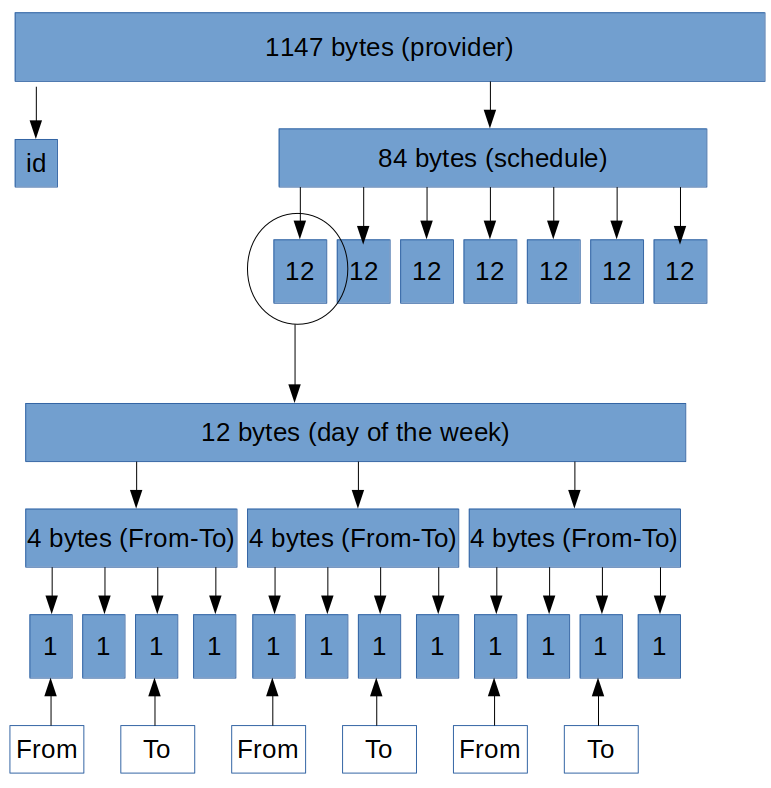
I cut out each record from the file separately, then I shift to a certain number of bytes depending on the day of the week and there I am already processing the time.
Kodjar:
type Schedule struct { ProviderID string `json:"provider_id"` Date time.Time `json:"date"` DayStart string `json:"day_start"` DayEnd string `json:"day_end"` Breaks *ScheduleBreaks `json:"breaks"` } type SheduleBreaks []*cheduleBreak type ScheduleBreak struct { Start time.Time `json:"start"` End time.Time `json:"end"` } func ScanSchedule(config Config) (schedules []Schedule, err error) { dataFromFile, err := ioutil.ReadFile(config.DBPath + providersFileName) if err != nil { return schedules, err } scheduleOffset := 774 weeklyDayOffset := map[string]int{ "Sunday": 0, "Monday": 12, "Tuesday": 24, "Wednesday": 36, "Thursday": 48, "Friday": 60, "Saturday": 72, } //first 1158 bytes reserved for table //one record with contact information use 1147 bytes //last 4494 bytes reserved for end of table for position := 1158; position < (len(dataFromFile) - 4494); position += 1147 { id := getIDFromSliceByte(dataFromFile[position:(position + idSize)]) //if table border (id equal "255|255"), then finish parse file if id == "255|255" { break } position := position + scheduleOffset date := time.Now() //create schedule on 3 future month (90 days) for dayNumber := 1; dayNumber < 90; dayNumber++ { schedule := Schedule{} offset := weeklyDayOffset[date.Weekday().String()] from1, to1 := getScheduleTimeFromBytes((dataFromFile[(position + offset):(position + offset + 4)]), date) from2, to2 := getScheduleTimeFromBytes((dataFromFile[(position + offset + 1):(position + offset + 4 + 1)]), date) from3, to3 := getScheduleTimeFromBytes((dataFromFile[(position + offset + 2):(position + offset + 4 + 2)]), date) //no schedule on this day if from1.IsZero() { continue } schedule.Date = time.Date(date.Year(), date.Month(), date.Day(), 0, 0, 0, 0, time.UTC) schedule.DayStart = from1.Format(time.RFC3339) switch { case to3.IsZero() == false: schedule.DayEnd = to3.Format(time.RFC3339) case to2.IsZero() == false: schedule.DayEnd = to2.Format(time.RFC3339) case to1.IsZero() == false: schedule.DayEnd = to1.Format(time.RFC3339) } if from2.IsZero() == false { scheduleBreaks := ScheduleBreaks{} scheduleBreak := ScheduleBreak{} scheduleBreak.Start = to1 scheduleBreak.End = from2 scheduleBreaks = append(scheduleBreaks, &scheduleBreak) if from3.IsZero() == false { scheduleBreak.Start = to2 scheduleBreak.End = from3 scheduleBreaks = append(scheduleBreaks, &scheduleBreak) } schedule.Breaks = &scheduleBreaks } date = date.AddDate(0, 0, 1) schedules = append(schedules, &schedule) } } return schedules, err } //getScheduleTimeFromBytes calculate bytes in time range func getScheduleTimeFromBytes(data []uint8, date time.Time) (from, to time.Time) { totalTimeFrom := int(data[0]) totalTimeTo := int(data[3]) //no schedule if totalTimeFrom == 0 && totalTimeTo == 0 { return from, to } hoursFrom := totalTimeFrom / 4 hoursTo := totalTimeTo / 4 minutesFrom := (totalTimeFrom*25 - hoursFrom*100) * 6 / 10 minutesTo := (totalTimeTo*25 - hoursTo*100) * 6 / 10 from = time.Date(date.Year(), date.Month(), date.Day(), hoursFrom, minutesFrom, 0, 0, time.UTC) to = time.Date(date.Year(), date.Month(), date.Day(), hoursTo, minutesTo, 0, 0, time.UTC) return from, to } In general, I just wanted to share knowledge about what algorithms of calculations used before.
Source: https://habr.com/ru/post/351658/
All Articles