Scaling Selenium
Imagine that you have only one test using Selenium. What can make it unstable? How to speed it up? Now imagine that there are two tests. Now imagine a hundred. How to make quickly work out such a bunch of tests? What happens if the number of tests continues to grow?
In this article, Simon Stewart will lead us along a difficult scaling path, from one test to hundreds of tests running in parallel. We will also get acquainted with the problems that appear in this case, and with practical methods for solving these problems. There will be Java code and some thoughts on the development of a test infrastructure.
The prototype of this article is a report by Simon Stewart at Heisenbug 2017 Moscow. Simon is the creator of WebDriver, a technology that is now almost 11 years old. He became the head of the Selenium project about 9 years ago. In Google, he was engaged in scaling Selenium, from several tens of thousands to several million tests every day, on their infrastructure. Then went to Facebook. Currently he is developing a WebDriver specification for the W3C, which is part of the W3C testing and tulling group. It can be said that a standard is created on the basis of WebDriver.
In the course of the article I want to consider a simple test and show how it can be scaled. First, we will launch it on a personal laptop, and in the end it will work in the cloud and amaze everyone around, including your boss, who scratches his chin and says, "I'm obviously not crying enough for you . " That's what we write software for, isn't it?
First, let's decide - why do we need tests at all? We do not write them because we like the green (or red) color, and not because we like our work. Their only function is to provide confidence that the software works as intended. End-to-end tests (eg, Selenium) should be part of a balanced diet test. If nothing else is used apart from them, nothing good will come of it. But we'll talk about this later.

Let's start with a simple example, which is open in my IDE. It is called longAndWrong() , so the test should be, right? We create a new FirefoxDriver to run locally. Then we create an explicit wait for WebDriverWait . After that, go to http://localhost:8080 , provide an email address and password, wait until the “create a todo” element is created, and finally click on it. Everyone has seen the launch of Selenium, and there is nothing unusual in this particular code.
This test is terrible. Let's see why. First of all, it works for good luck. Having received the page, we do not wait until the element through which the entry is made appears. Thus, we expect WebDriver to correctly guess the page load time. In the above example, the HTML is simply displayed, so this approach works, but in other cases there will be problems.
More importantly, the craziness that we see in another part of the code: driver.findElements(By.tagName("button")).stream() , etc. Filtering occurs, and if nothing is found, then for some reason AssertionError is thrown. Only after all these operations is done a click, because only then it is clear that we have everything we need. Everyone agrees that it looks very creepy?
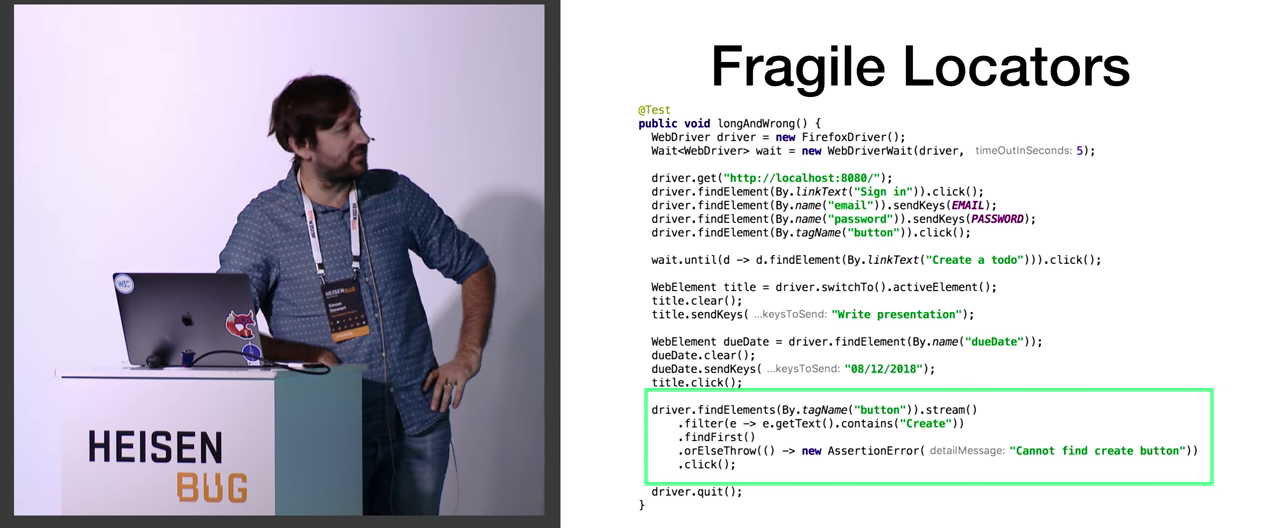

This is highlighted in green - is that all? The problem of this whole structure is its fragility. And not only this one. For example, do any of you use excessively long XPaths? Long means longer than one line. Fragile locators are one of the main reasons why tests become creepy. You can learn a lot about solving this problem in the Selenide report.
There are several ways to remedy the situation. First, you can correctly rewrite the self-test application, if you have access to the source code and the right to edit it. He is not always. Sometimes it happens that the development team in the UK communicates with a team of testers in Romania through tickets in jire, and some say that the application is working “normally”, while others do not pass tests. If you have access to the code, then you can add meaningful identifiers to the elements: classes, certain attributes.
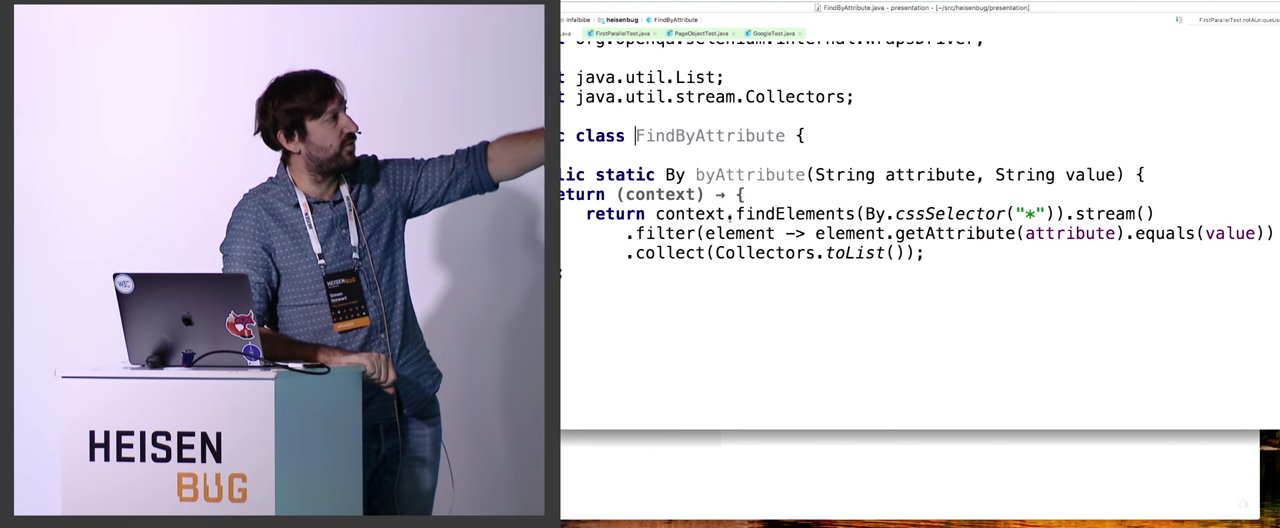
Most likely, there is some kind of WebDriver.findElement that takes a single By as input. You can manually follow it from it. We search for all elements by the selector * , we search for all child elements in the tree, and then we filter by the attribute value. However, it is extremely inefficient. Each call to the WebDriver or Selenium API is a remote procedure call, one way or another it is carried out through the network.
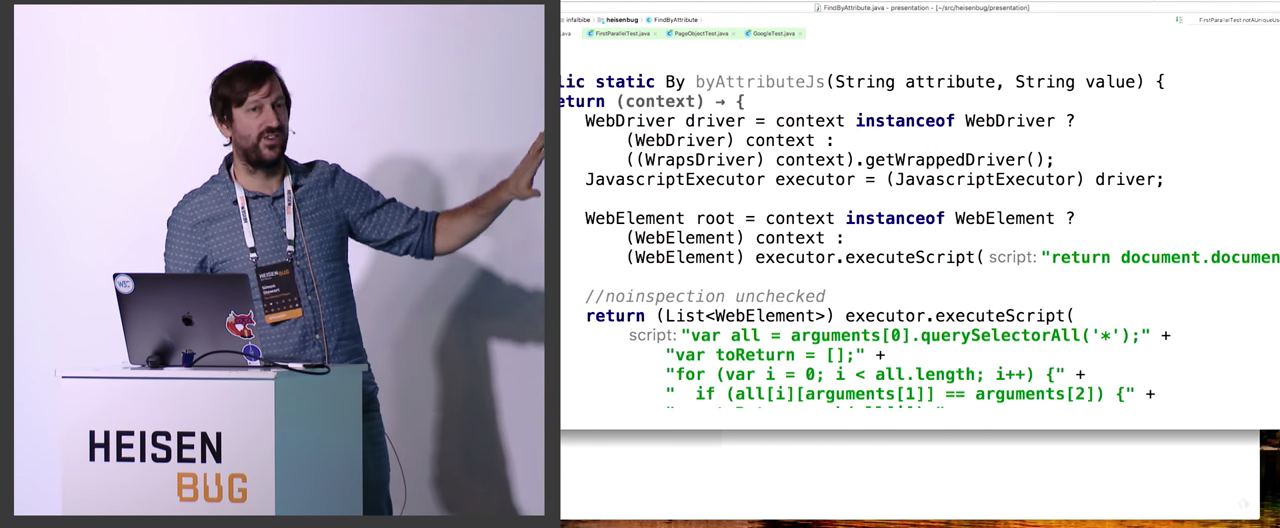
Instead, all this can be written in JavaScript, and it will do exactly the same thing. If you look at the slide, it looks much more complicated and scary, but as a matter of fact, we take the context and ask - are you really a WebDriver? .. If so, look - maybe it is a single WrapsDriver ? Then we can extract a wrapped WebDriver from it. And since we want to execute JavaScript, we further cast it to the JavascriptExecutor . Well and so on on the little things. Maybe someone does not know, but executeScript() can return elements and various other things. It will go to the browser, do some work there, return the result, and the result will correctly go into the java types. What you see on the screen really works.
Some developers dream of such a feature, not knowing that it has already been implemented. Suppose there is a JS framework, which already has an element search mechanism built into it. Even if it is something simple, such as generating random id :-) You can not re-implement this mechanism. Do not hesitate to ask the framework itself to find the necessary elements! This greatly simplifies life.
I’ll also add why Selenium uses JavaScript. Which readers use JavaScript frameworks in their application? JQuery, React, Angular, or some homebrew nightmare? You’ll have to use JavaScript to interact with them. In the example I gave, jQuery tracked the number of queries. There is no other way to get from the system unambiguous information about what is happening in it. Sometimes it is necessary. In addition, WebDriver tries to simulate user behavior. What is the user doing? He clicks the browser, prints, clicks on the elements. There are things that WebDriver and Selenium do not know how. If you want to monitor HTTP status codes or network traffic, you may need a proxy. If something happens on the page, the best option may be to ask the page itself. For example, quite often identifiers are created randomly, although they are used in an orderly manner. So you can not always count on their availability. You can simply refer to the page to find out exactly which identifier of the item, and then use it in a regular index. This whole mechanism allows you to do a gray box test. The “white box” is when the insides of the system are completely accessible to you during the testing, in the situation of the “black box” the system is hermetically closed, as if it came to us from space. And when testing the "gray box" you first grab your head on how everything inside is difficult, and then you start changing something here, then inserting a handler there, and all this is done to make testing more stable and simple. Someone looks at this as a hack. Larry Wall believes that a first-class developer should have three qualities: impatience, arrogance, and laziness. Impatience requires that everything happen now. Thanks to this, your programs will be fast. If you are asked to do something again and again, you will not do it, there are cars for that. A lazy person is ready to work a lot once, in order not to work again never. So I see in the described approach not a hack, but laziness. I could try to figure out how it works - or I can ask someone about it. My life will be easier. Well, arrogance is just a desire to throw dust in the eyes.
Another topic is waiting for an event. There is such a thing in Selenium - Wait<?> .

Hope everyone knows her. In Selenium there are two ways to wait for something: explicit and implicit. In the implicit, we are waiting for some incomprehensible time, in the obvious - we use what you now see in the illustration. Advice from the Selenium team: do not use implicit expectations, use Wait.until ! .. Why? The problem is that people, as a rule, do not know how long to wait, and therefore set the time for implicit waiting down to the minute. If everything is in order - this is not a problem, everything is fine. But if the test fell, it would take an extra minute before stopping. Due to this, the start of tests, which usually takes 5-15 minutes, can take several hours.
If the time for an explicit wait is shorter than for an implicit one, we will essentially only work with the results of an implicit wait. This is very confusing, it is impossible to support such tests. But still, you can do that.
Yes, explicit expectations interact very strangely with implicit ones. Strange - does not mean "unpredictable." In fact, everything is absolutely predictable. If a command is executed that sets the implicit wait time, it will not complete until it expires. Suppose an implicit wait time is 10 seconds and an explicit wait time is 15. You execute the query, which reports after 10 seconds that it failed. Explicit wait then compares 10 and 15, decides that 15 is greater, and performs a new wait, again 10 seconds. You are puzzled, why is it waiting for 20 seconds if I asked 15? It is not always clear when implicit expectations will be triggered. So everything happens perfectly predictable, but if you don’t know this internal mechanics, this behavior may seem extremely strange from the outside, and your life will be extremely difficult. My advice - do not use implicit expectations at all. Explicit expectations carry certain information. Your test suite not only checks the operation of the code, it describes how the system works for people unfamiliar with it. For example, explicit expectations can tell: an Internet connection should occur at the moment, an AJAX call should be made, something should be updated, etc. A person reading your test may ask: is the system really doing this at the moment? Should she do this? Why does she do it? This allows you to have a dialogue that is impossible with a different approach. In general, explicit and implicit expectations interact, not always in an obvious way, but implicit ones always take precedence.
Let's return to the initial test.

He does not sleep anywhere. The naive approach is that if at some point you have to wait, just run Thread.sleep() . The problem with this approach is that the test will wait too long. So do not.
Instead, use the Wait class. Its advantage is that it uses generics, so the type that you throw at the input will be thrown in until() . For example, you can write Wait.until(d -> driver.findElement(...)) , it will find an element, until it sends it further, and from it it is very convenient to call .isDisplayed() right there.
In addition, it is convenient to store a link to WebElement, which for some reason people avoid. I communicate with clients a lot, visit their sites and notice that for every interaction with an element they search for it again. Thus, for each action call, two remote calls are made. Suppose you need to get the value and send the keys. In this case, people often write first driver.switchTo().activeElement().clear() , and then driver.switchTo().activeElement().sendKeys() .
But the element is the same. The only situation in which it can change is if it is completely removed or disconnected from the DOM, in which case you will receive a StaleElementReferenceException . Isn't it true, you are all crazy about this exception? It reports that something has updated the DOM, and there is no longer a required item. This means that the ability to set the wait is skipped - you will not be able to wait for the desired item to appear.
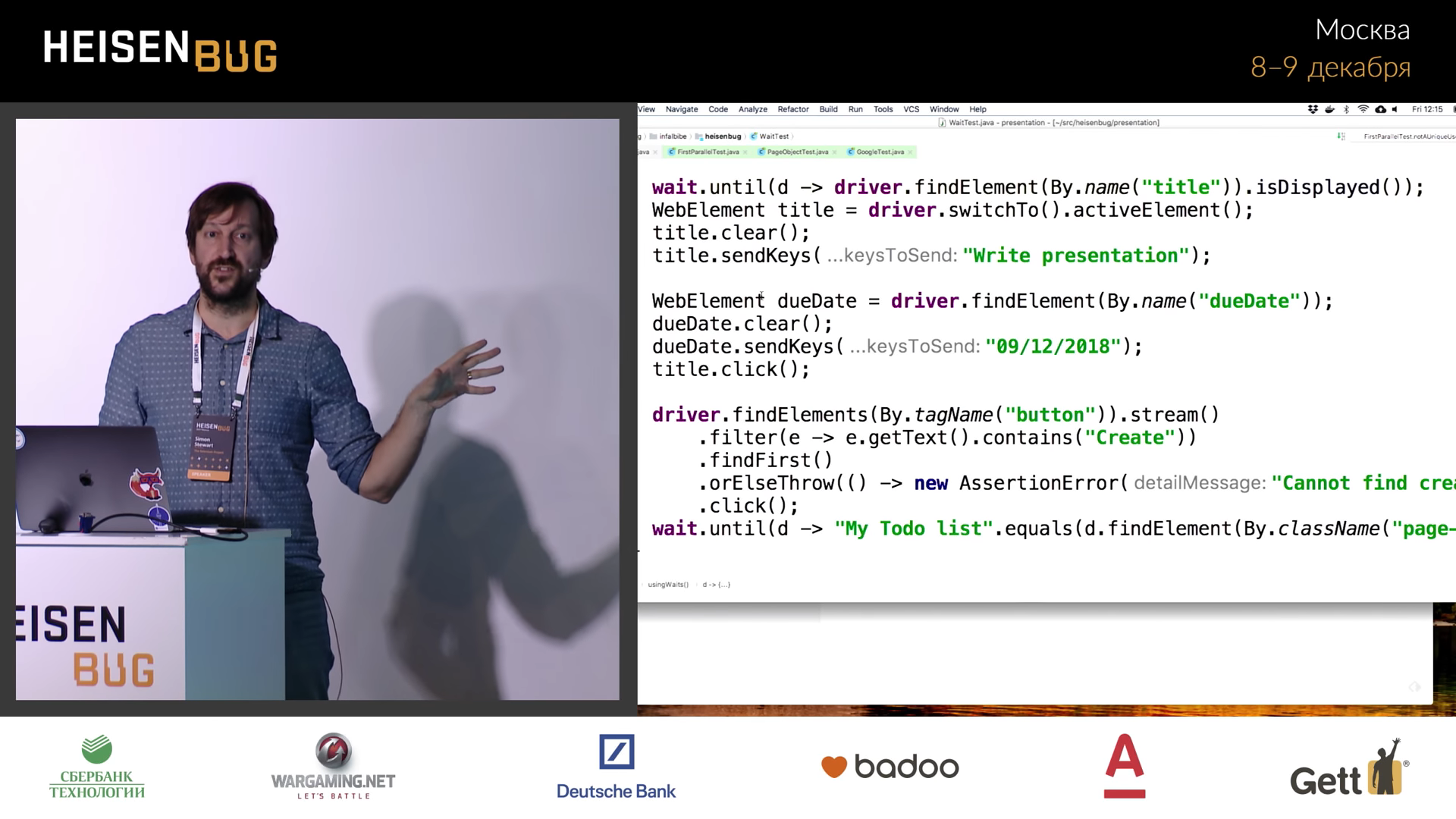
The code shown on the screen will run for the optimal amount of time, since the wait will be kept to the minimum necessary. If you restart the test with this code, the result will not change at all.
Are you still reading? I hope so far I have not said anything new :-)
So, testing on the "gray box" principle.
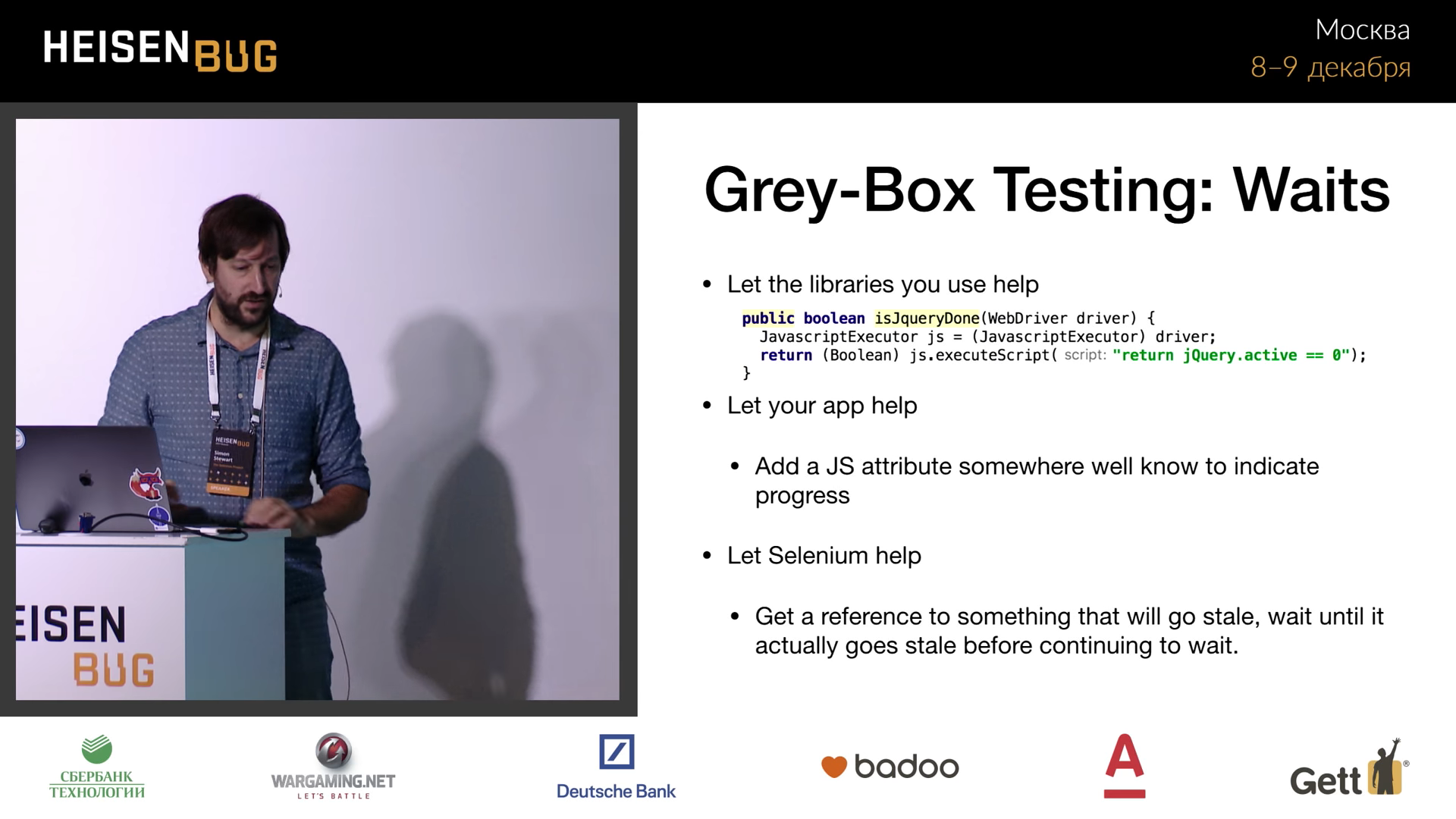
There are ways to make expectations more efficient. Look at the isJqueryDone() method on the slide above. He keeps records of active operations. If jQuery.active becomes 0, it becomes clear that nothing else happens.
On the other hand, why constantly jerk the page to find out these statistics? After all, a similar mechanism is in JS-frameworks. In AngularJS, for example. Why it is impossible to be limited only to this? Perhaps libraries are simply not at that level.
And yet, the problem can be solved with the help of your application. Suppose you are making an AJAX call and want to know if it is completed or not. Sometimes the DOM update does not occur, and new content is simply thrown into it. It becomes unclear whether to continue the test. Maybe everything remains the same, and the test can be continued? In such a situation, it is worth tracking at the application level — when making a meaningful operation, you need to create a variable, and upon completion of the operation its value can be reset. Then it will be possible to check this variable, and when it takes the correct value, this will mean that you can safely continue testing further.
Finally, you can ask for help from Selenium . Links to obsolete items may be useful information. If you expect the DOM element to be updated and removed from the DOM as a result of your actions, you can get a reference to the element before performing this action. Then it will be possible to wait for the exception StaleElementReference , find a new item and return it. In Wait you can ignore certain types of exceptions, so this code will be clean, neat and easy to use. Selenium will take over the work. Signals that indicate a change in DOM, that something has moved under the hood are a great opportunity to make testing more stable.
Let's go to Page Objects. Have you heard of the god Janus from ancient Roman mythology?

Janus is a two-headed god looking into the past and into the future. That is why January was named after him.
Page Objects often fall victim to misunderstanding. In speeches at SeleniumConf there were a lot of presentations about the automatic generation of PageObjects, about the automatic determination of the position of elements. So you can not do. It only looks beautiful because it seems that “you write the framework” and you will be great, in reality everything will be much worse.
In the original definition of Page Object - one of the faces of Janus. These are services addressed to the user. If the application under test has a login page, then you will want to log in to it, and describe all this in the domain language. If you show such a test to a business analyst, the project owner, your parents, it will immediately become clear to them whether the application behaves correctly. But Page Object has another Janus face that requires in-depth knowledge of the code and page structure. This is needed for DRY ("don't repeat yourself"), for abstraction. To make LoadableComponent easier, Selenium provides a class LoadableComponent . It seems to me that the name of the Page Object does not quite reflect the essence, since here you can model in smaller pieces, deliberately reduce their size.

I have a test here using Page Objects. It does exactly the same as the previous test. We create a User object, go to the login page and pass it the driver and the maximum wait time, and then we run get() on it. This happens according to our LoadableComponent model. If you log in, then back home page. The advantage of how the Page Object pattern is implemented in this test is that it navigates. If the login page no longer rolls the MainPage, you change the function signature and return something else from the signUp method. Such a test does not even need to run, it simply does not compile.
Let's look at the demo:
This is a simple TODO list. It does not strike the imagination, but it illustrates the idea well.

In the code of the SignupPage.signUp() function, nothing happens except searching for items.

Everything is abstracted and placed in this one function. If the entry page code changes, this function is the only place where corrections need to be made. If your developers changed UI workflow or renamed some element, then all changes will be here. The alternative is to run through millions of tests and fix them.
This concludes the basics. We have a test whose support is easy to implement. One way to scale Selenium is to simply write well-working and easily supported tests. Once I met clients who were told that their task was to make the test suite green. They solved this problem by removing all checks and, in the case of exceptions, they completed the test successfully. Testing as a whole was completed successfully, but it didn’t say anything.
Also, the data used is extremely important. It is unlikely that your application is absolutely stateless. Most likely, you have users, persistent data and more. Data is one of the problems you will encounter when scaling tests. There are several recommendations on how to parallel test.

First, static in Java and the Singleton design pattern are evil, they should be avoided. The reason is that static fields are common to all threads. If you change this field of two tests at the same time, the result will be unpredictable. When communicating with clients, I often see the use of a static variable to store a reference to WebDriver. There are complaints about the crazy behavior of tests when they are launched in parallel: sometimes they work and sometimes they don’t. This is called “race condition”.
Trying to avoid static , someone switches to using ThreadLocal . However, he is also evil. It makes you rely on thread affinity. If you constantly make sure that the test is executed in the same thread, you can safely teleport data from level to level. The very fact that you have to teleport data (WebDriver instance, username) is a bad sign, this is code smell. So, they are poorly structured. They are difficult to understand, difficult to maintain. The test, which is difficult to understand, is a source of great trouble. One colleague said that to debug a test you need two times more intelligence than writing it. If you had to use all your abilities to write the test, then during debugging you will end up in a dead end, which will be extremely painful to get out of. One of the things functional programming has taught us, including in Java: the ideal code must be immutable and must not retain states (stateless). If you create a Todo object (as in the previous illustrations), in order to change something in it, you need to create a new object. If there are two threads working simultaneously with a changeable state, this leads to dire consequences.
Imagine such a test: the user Fred comes to example.com and registers, registration must be successful. The first time the test passes successfully. However, when you run the test again, it crashes because the user named Fred is already registered. Unpleasant, is not it? I am sure that you meet with such constantly. The correct approach is to have data prepared for each test for each test.
This problem is infrequent, as you recreate the environment between test runs. , CI/CD ( ). ( , ), , .
, . — «» .

- , , . . dev , , . . , ! , happy path.
dev . : - ( - - , todo), , . , , , , . , , . — . , «».
-.

, . , LDAP. . , — , LDAP, . , . , , , . , . , , . , — , . , , - . . , . , JUnit Assume . .
, . , , . , , , . , . , . , , , — « ?», — « , ». . , , . , .
, , , , . Page Objects , , Screenplay, . , .
Selenium?

WebDriver Wire. , JSON- URL. : Json Wire Protocol W3C Dialect. OSS Dialect. , ChromeDriver, FirefoxDriver, Selenium Server, PhantomJS. W3C — Wire, . . — , , — Actions. Selenium Grid FirefoxDriver, drag-n-drop. . .
Selenium: .

. Selenium Grid. :

Selenium . :
, . . , , , . : Firefox, Chrome , , macOS — Safari:
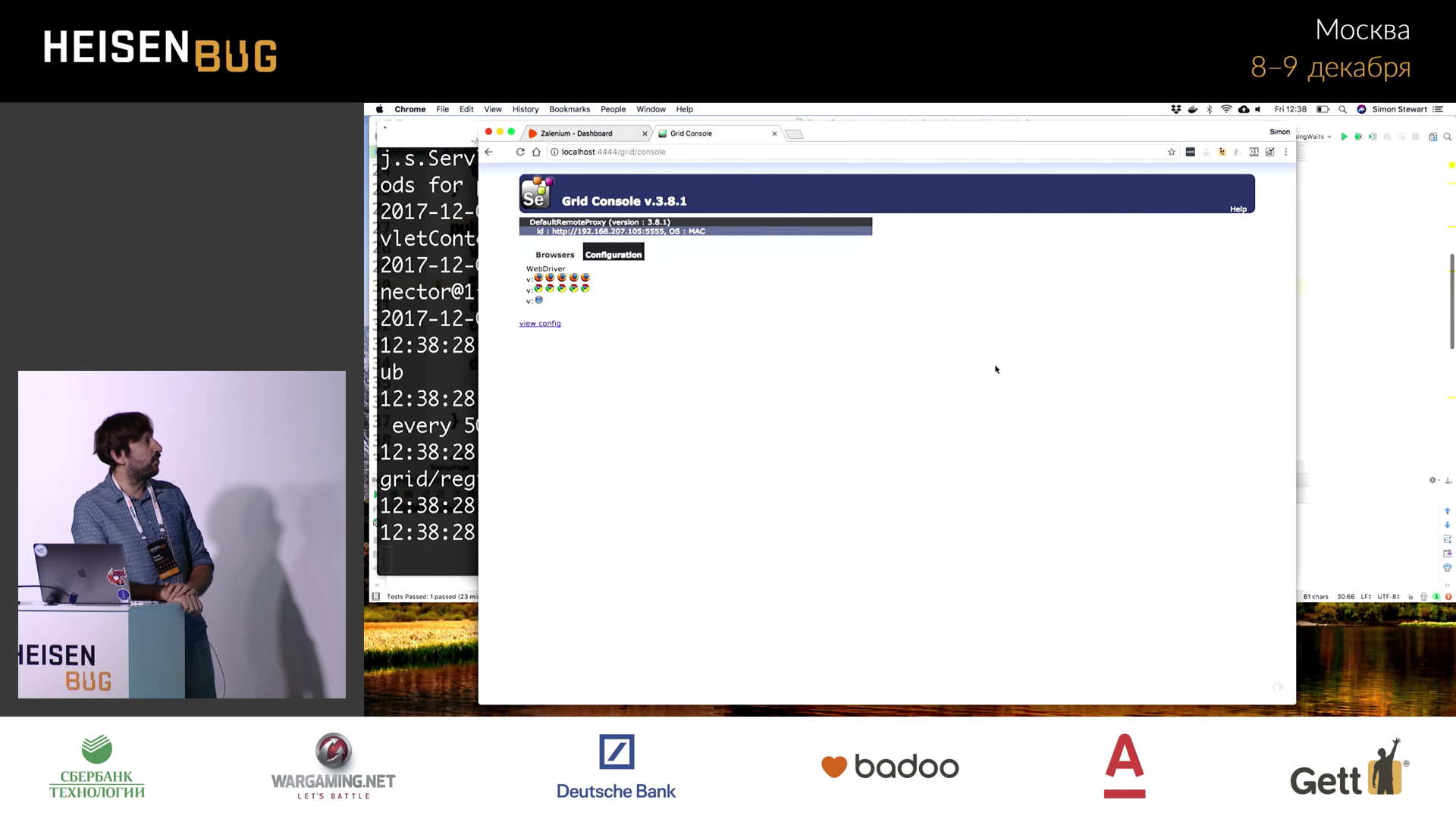
, ChromeDriver, GeckoDriver, , . : ? Docker . — -!
, ? , , . . Docker , , — .
, Selenium , . — Selenium Docker . , . , GeckoDriver ChromeDriver, Firefox GeckoDriver . . Selenium- , Docker-.

( Chrome, — Firefox).
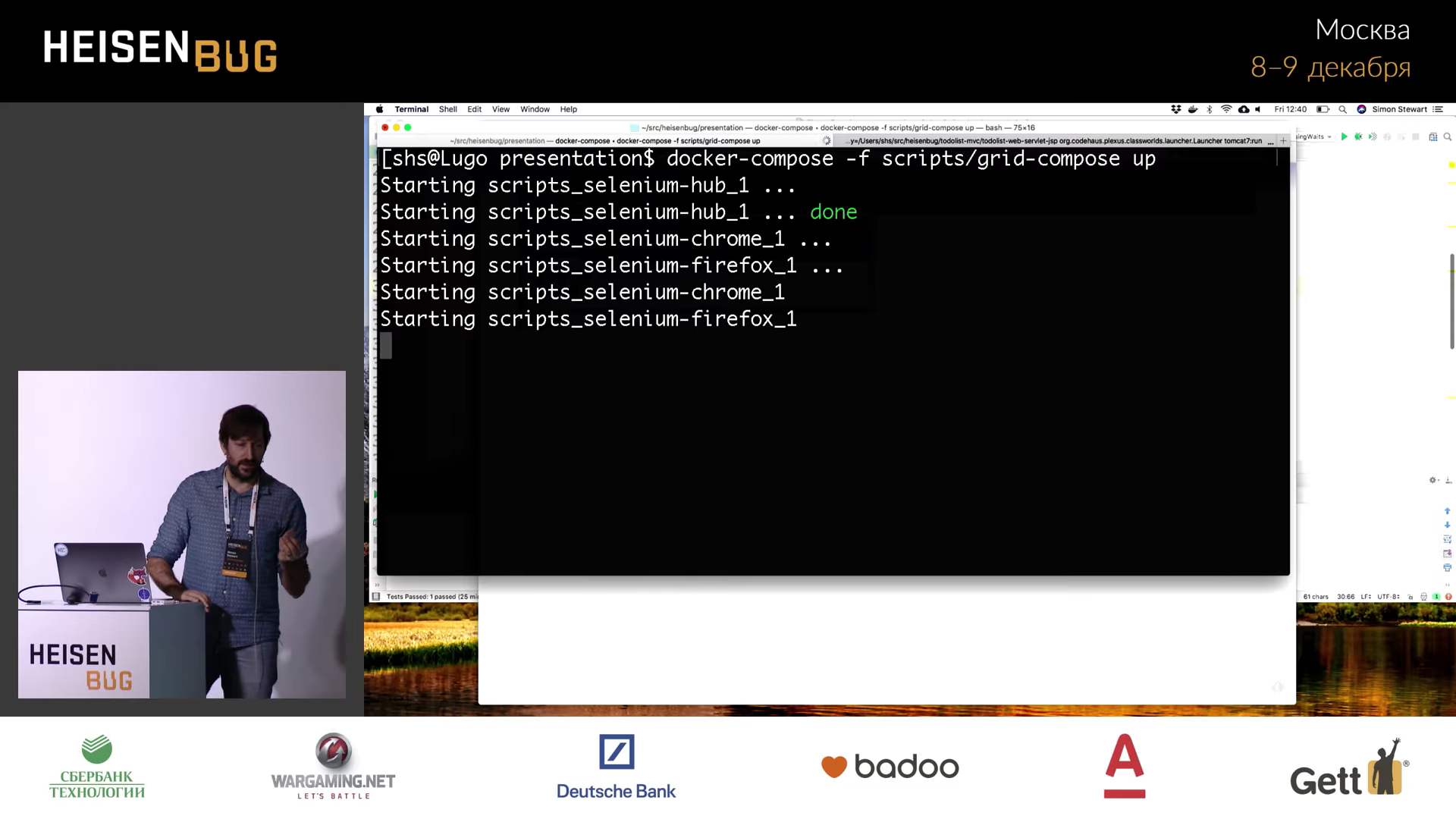
.

, Docker , . , . , . , 8 , . , , — .

, , . , Docker . Zalenium . .
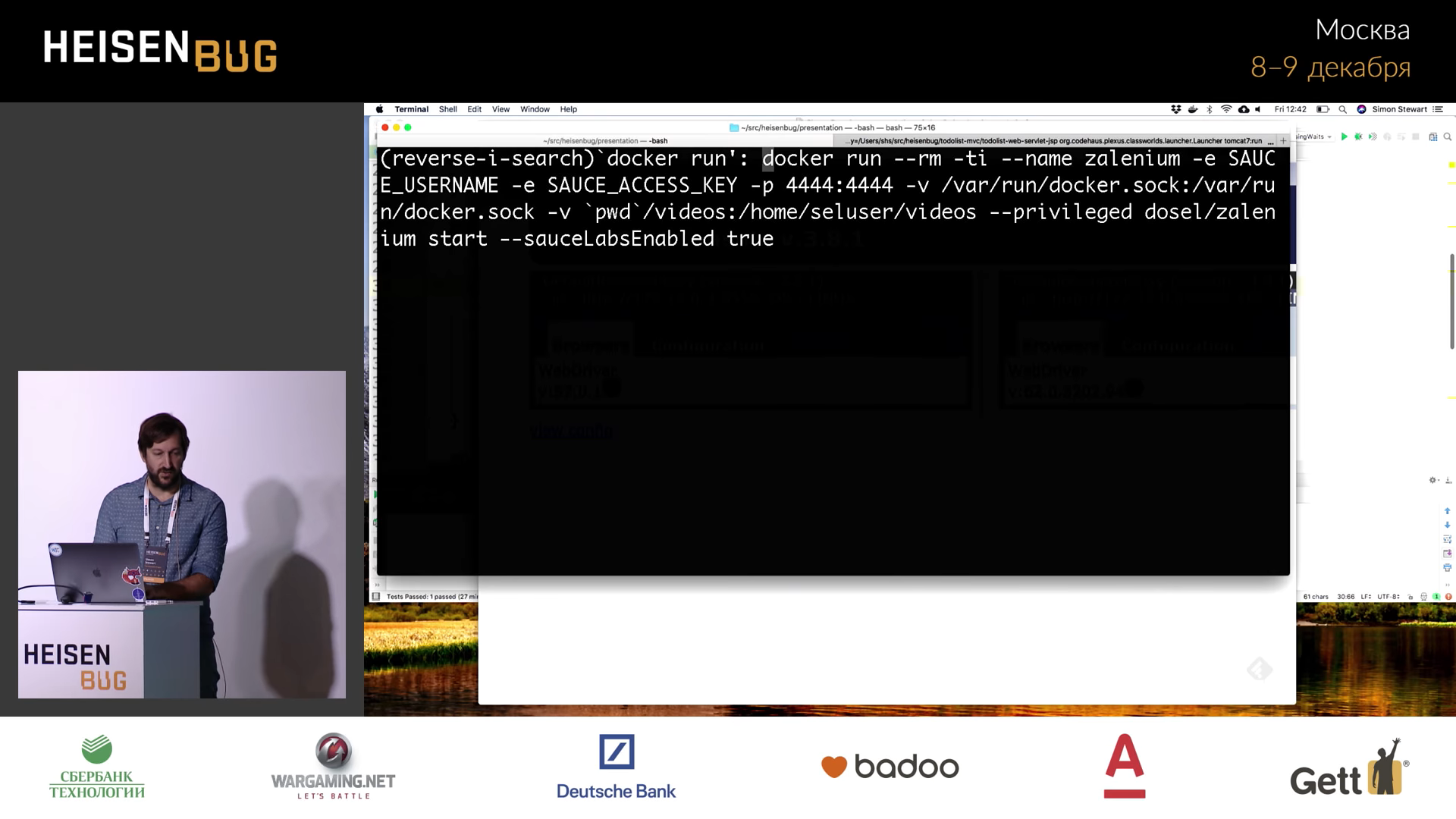
Docker, :
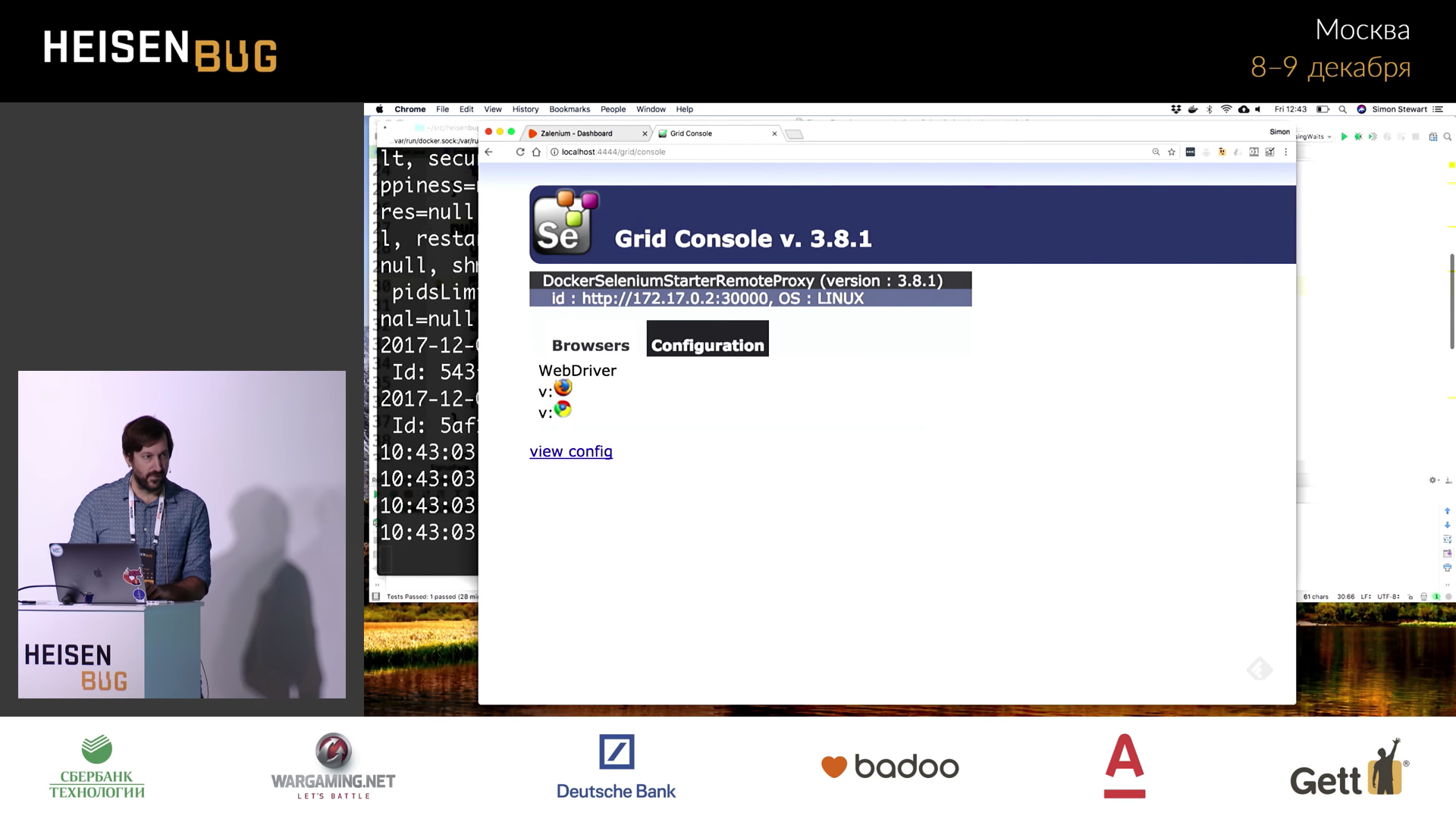
. , . . Windows, , , Edge.
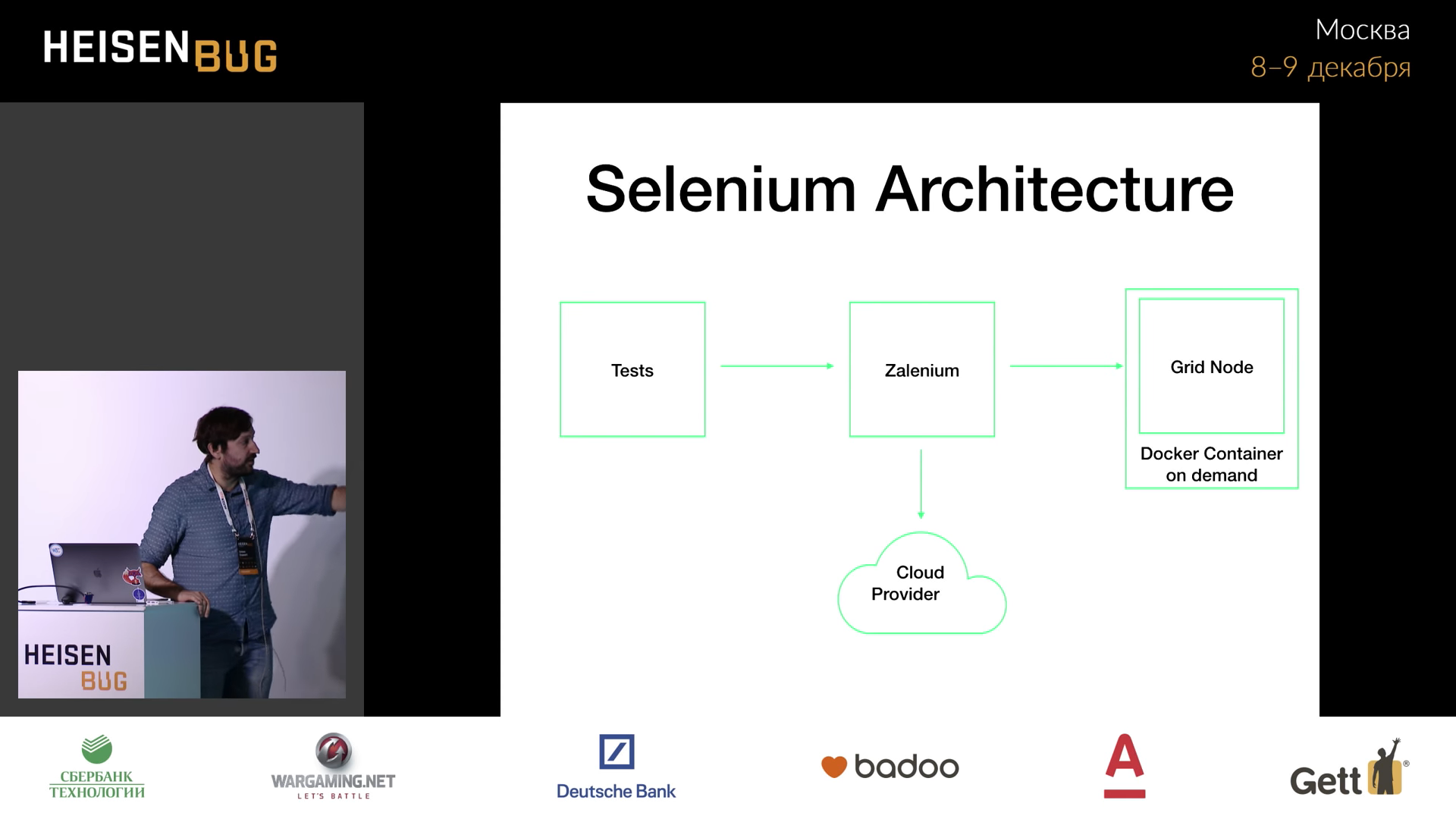
. . , Zalenium .

Zalenium --sauceLabsEnabled true , Sauce Labs . , , Sauce Labs , .
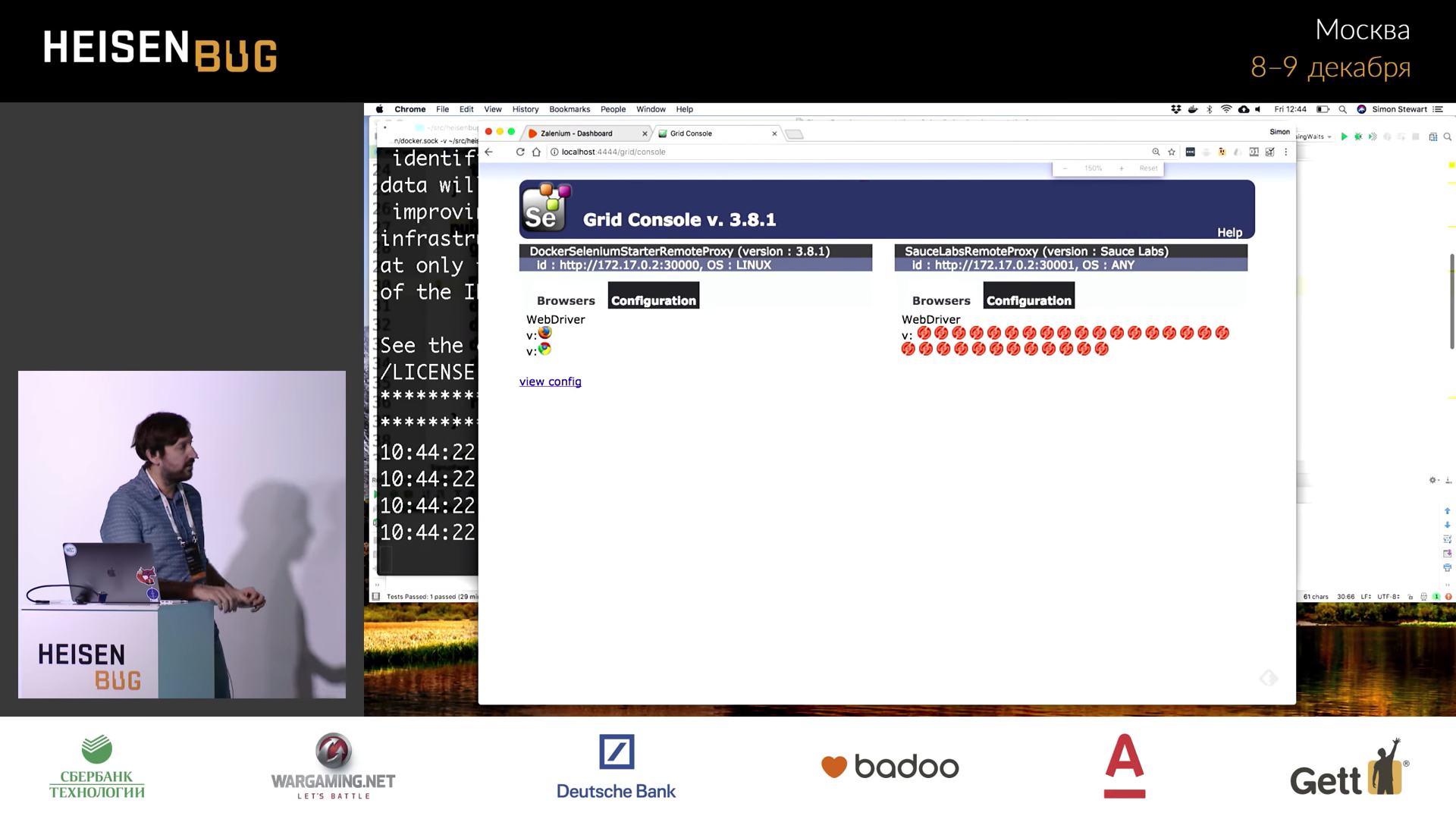
*Zalenium*** .

Zalenium , /dashboard . , . , . , , Windows macOS, Sauce Labs , BrowserStack - .
. , . , Selenium , , HTTP, . , , .
. — DDoS, , . , . , - . Selenium , . , , .

, — « ». , — ( «»), - ( «»). , , . , . , — - , — .
, : - .

, . , -. : Selenium-. Selenium — .
. . , . Buck Bazel , , . .
, . , , , — . , , . , , . JavaScript, . , ? , , , . . , .
Minute advertising. As you probably know, we do conferences. — Heisenbug 2018 Piter , 17-18 2018 -. , ( — ), . In short, come in, we are waiting for you!
')
Source: https://habr.com/ru/post/351584/
All Articles