Kotlin's current development

Last week, with the support of Redmadrobot SPB , the SPB Kotlin User Group hosted a meeting with Stanislav Erokhin, a developer from JetBrains. At the meeting, he shared information about the possibilities being developed for the next major version of Kotlin (numbered 1.3).
In this article, we will summarize the material received, tell you about the plans.
Important. The design of all the features that will be discussed may be changed beyond recognition. Everything below is the current plans of the team, but the developers do not give any guarantees.
View the report can be on the link to YouTube .
Introduction
In the upcoming major version of Kotlin (1.3), many changes are expected. Told us only about some of them.
Main directions:
- Korutiny
- Inline classes
- Unsigned arithmetic
- Default methods for Java
- Meta-information for DFA (Data Flow Analysis) and smartcasts
- Annotations to control type inference
- SAM for Java methods
- SAM for Kotlin methods and interfaces
- Smart inference for builders
- Compiler Schema Changes
Korutiny
In version 1.3, the long-awaited release of Korutin in Kotlin is planned, with the result that they will move from the kotlin.coroutines.experimental package to kotlin.coroutines .
Later it is planned to release the support library to support the existing API korutin.
Major Changes in the Quercines
- JetBrains are actively working on performance. For example, it is planned that in the new version state-machine will not be generated where they are not needed. Due to this, the number of generated objects will decrease.
- Work is underway to fully support suspend for inline functions.
- Support callable reference will be added for suspend functions.
Continuationinterface willContinuation
At the moment, Continuation contains two methods that allow you to forward either a result or an error.
interface Continuation<in T> { fun resume(value: T) fun resumeWithException(exception: Throwable) } In the new version, we plan to use a typed Result class containing a value or error in some form, and in Continuation leave one resume(result: Result<T>) method resume(result: Result<T>) :
class Result<out T> { val value: T? val exception: Throwable? } interface Continuation<in T> { fun resume(result: Result<T>) } Such an implementation will make it more convenient to develop libraries for corutin, since developers will not have to perform checks before each value / error forwarding. The API of this solution will definitely be changed, but the meaning will be preserved.
Unfortunately, this solution has a problem. For everything to work in the current Kotlin implementation, it is necessary to wrap each value in a wrapper Result , which leads to the creation of an extra object for each call to resume . The solution to this problem will be inline classes.
Inline classes
Example for Result :
inline class Result<out T>(val o: Any?) { val value: T? get() = if (o is Box) null else o as T val exception: Throwable? get() = (o as? Box).exception } private class Box(val exception: Throwable) The advantage of inline classes is that at runtime the object will be stored simply as val o , passed in the constructor, according to the example above, and the exception will remain in the wrapper Box . This is due to the fact that errors are thrown quite rarely, and the generation of the wrapper will not affect performance. The value and exception getters will be generated into static methods, and the wrapper itself will disappear. This solves the problem of creating unnecessary objects when calling Continuation.resume .
Inline class restrictions
- While it is possible to create an inline class with only one field, because at run time, the wrapper is erased and only the field value remains
- If generics are used, the
Resultwill still be wrapped, since it is not known after unpacking whether the object is wrapped or returned (for example, if we useList<Result>)
Unsigned arithmetic
One of the possible consequences of the appearance of inline classes are unsigned types:
inline class UInt(val i: Int) inline class ULong(val l: Long) ... The standard library for each primitive will describe the corresponding unsigned variants in which work with arithmetic operators will be implemented, as well as basic methods, such as toString() .
Literal support and implicit conversion will also be added.
Default methods
In Kotlin's interfaces, methods with a standard implementation appeared earlier than in Java.
If the interface is written in Kotlin, and the implementation is in Java 8, then for methods with a standard implementation, you can use the @JvmDefault annotation, so that from the Java point of view this method is marked as default .
Meta-information for DFA and smartkastov
Another interesting piece of development is contracts, with which you can add meta information for DFA (Data Flow Analysis) and smartkastov. Consider an example:
fun test(x: Any) { check(x is String) println(x.length) } The check(Boolean) function is passed the result of checking that x belongs to the String type. At this level, it is not known what this function does inside, so the next line of code will cause an error (a smart-cast is not possible in this case). The compiler cannot be sure that x is a String . Contracts will help explain it to him.
Here is the implementation of the check with the contract:
fun check(value: Boolean) { contract { returns() implies value } if (!value) throw ... } Here is added a call to the contract function with a rather specific syntax, which says that if this method returns a result, this result is exactly true . Otherwise, an exception will be thrown.
Thanks to such a contract, the compiler will be able to perform a smart cast for x , and there will be no error when calling println(x.length) .
In addition to resolving situations with unknown types, contracts will also solve other problems. For example:
fun test() { val x: String run { x = "Hello" } println(x.length) } fun <R> run(block: () -> R): R { contract { callsInPlace(block, EXACTLY_ONCE) } return block() } The contract in the run function tells the compiler that the passed block will be called exactly once, the constant x correctly initialize and x.length will run without error.
Contracts are used by the compiler, but do not affect the resulting compilation code. All contracts are converted to meta-information, which informs the compiler about some assumptions in certain functions.
The IDE is planning a certain highlight of contracts and autogeneration, where it will be possible.
Annotations to control type inference
In Stdlib Kotlin there are already various features that are used only inside. Some of them are ready to share developers. Consider the new annotations and the features they provide:
@NoInfer
The @NoInfer is designed to make type inference a little smarter.
Suppose we want to filter a collection using the filterIsInstance method. In this method, it is important to specify the type by which the filtering will be performed, but the compiler can allow the call without setting the type (trying to infer it). If the signature uses @NoInfer , then a call without a type is highlighted as an error.
fun print(c: Collection<Any>) { ... } val c: Collection<Any> print(c.filterIsInstance()) // print(c.filterIsInstance<String>()) fun <R> Iterable<*>.filterIsInstance(): List<@NoInfer R> @Exact
This annotation is very similar to @NoInfer . She says that the type must be exactly equal to the specified one, that is, not a "subtype" and not a "overtype."
@OnlyInputTypes
This annotation indicates that only the types that the user had in the arguments or in the receiver should be inference results.
SAM for Java methods
Another feature being developed makes it easy to work with SAM. Consider an example:
//Java static void test(Factory f, Runnable r) interface Factory { String produce(); } //Kotlin fun use(f: Factory) { test(f) { } // Factory != () -> String } In Java, a method is declared that accepts two functional interfaces. It is logical that at the Kotlin level we should be able to call this method, passing both interface implementation objects and lambda expressions corresponding to the signatures of the methods of these interfaces in any combination:
1. test(Factory, Runnable) 2. test(Factory, () -> Unit) 3. test(() -> String, Runnable) 4. test(() -> String, () -> Unit) Now options 2. and 3. impossible. Kotlin compiler allows only two options: accepting two interfaces and accepting two lambda.
Making all 4 options possible with the current implementation of the compiler is a difficult task, but not impossible. The new type inference system will support such situations. In the environment, only one fun test(Factory, Runnable) function will be visible, but it will be possible to transmit both lambdas and interface implementation objects in any combination.
SAM for Kotlin methods and interfaces
If a method accepting the Kotlin interface is defined in Kotlin, then automatic conversion takes place (you can transfer both the interface implementation and the lambda), you must mark the interface with the sam keyword.
sam interface Predicate<T> { fun test(t: T): Boolean } fun Collection<T>.filter(p: Predicate<T>): Collection<T> { ... } fun use() { test { println("Hello") } val l = listOf(-1, 2, 3) l.filter { it > 0 } } For Java interfaces, conversion will always work.
Smart inference for builders
Imagine that we want to write a builder:
fun <T> buildList(l: MutableList<T>.() -> Unit): List<T> { ... } And we want to use it like this:
val list = buildList { add("one") add("two") } This is currently not possible, since type T not derived from calls to add(String) . Therefore you have to write like this:
val list = buildList<String> { add("one") add("two") } It is planned that it will be possible to use the first option (without explicitly indicating the type).
Compiler Schema Changes
JetBrains is actively working on Kotlin Native. As a result, another link in the compiler scheme appeared - Back-end Internal Representation (BE IR) .
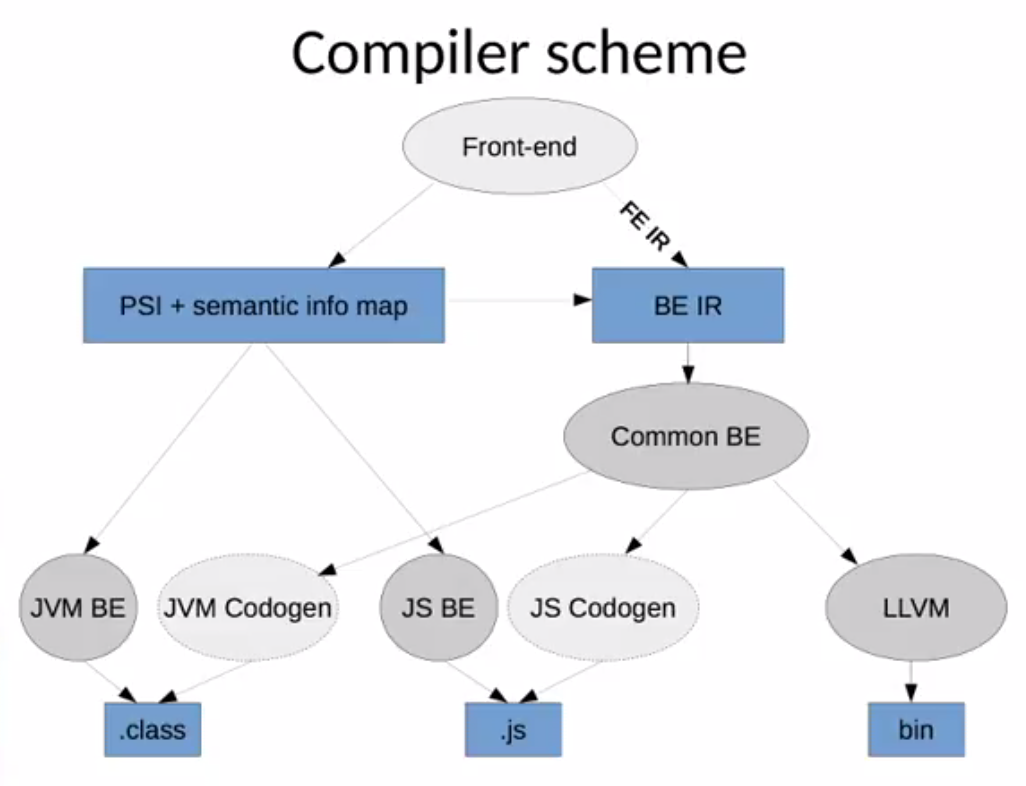
BE IR is an intermediate representation that contains all the semantics of the source code, which can be compiled for executable files of any platform, including the binary code of the system. Now BE IR is used only in Kotlin Native, but it is planned to be used for all platforms, instead of PSI with additional information on semantics. For JVM and JS, there are already prototypes, and they are being actively developed.
As a result, the entire source code will be converted to BE IR, and then to target platform executable files.
Summary
As it was written above, it is not known what innovations will reach the release, in what form and in which version of the language. There are only the current plans of the Kotlin team, but the developers do not give any guarantees :
- API Corutin Release and Finalization - 1.3
- Inline classes - an experimental feature in 1.3
- Unsigned arithmetic - an experimental feature in 1.3 or 1.4
- @JvmDefault - experimental feature in 1.2.x, release in 1.3
- Meta-information for DFA and smartkastov - partly release in 1.3
- Annotations for type inference control - an experimental feature in 1.2.x
- New type inference engine (including SAM and Smart inference for builders) - an experimental feature in 1.3
Kotlin is undoubtedly a programming language, but with the increase in the user base, the range of its application is expanding. There are new requirements, platforms and use cases. Old code accumulates that needs to be maintained. The language developers understand the difficulties and problems and work with them; as a result, the new versions will make it even more convenient to use it in more situations.
')
Source: https://habr.com/ru/post/351516/
All Articles