What else do we check with Selenium, besides the interface logic
Hi, Habr!
My name is Vitaliy Kotov, I work in the testing department of Badoo. Most of the time I work with Selenium. We use this wonderful tool for solving various tasks: from functional testing to simplifying work with error logs and testing interaction with API.
About what tasks Selenium helps us to solve, and will be discussed in this article. Go! :)
')

The first thing Google will tell us about “Selenium”:
Selenium allows you to do almost the same thing that we could do with our hands: open the pages and interact with them. However, he does it faster and more reliably, since he cannot “blush” his eye and he cannot click wrongly by mistake.
In test automation, the first thing Selenium uses is to check the functionality of the site.
What do users usually do on the site? They open it, click here and there, see some results of their clicks: redirects, pop-ups, highlighting of elements, and so on. This process is desirable (and necessary) to test. It is necessary to make sure that the user sees exactly the response to his action, which is incorporated in our business logic.
For this, scripts are created that describe the actions of users. For example:
If the authorization is broken on the site (for example, the programmer got it wrong - and the getUser method now always returns false), Selenium fails to go through step 6. The test will drop and let us know. In fact, somewhere in the code, Exception will be thrown, and the process will end with the corresponding error code.
This sequence of actions is called functional testing. This is perhaps the most common use of Selenium. But there are more interesting.
Normal user JS-error does not see. This is right - he has no reason. But it is important for developers to understand whether their code does not “fire” in some cases. JS-errors I would divide in this context into two types: visible to the user and those that do not interfere with the user.
With the first kind of errors, everything is clear. If the site does not respond to the user's action due to a JS error, the Selenium test will notice it.
With the second kind of errors, everything is more complicated. If they do not interfere with the use of the application, is it worth it to fix them? In Badoo, we try to correct such errors along with the errors of the first type. First, any error somehow signals some kind of problem. Secondly, if it does not interfere with the user in one case, this does not mean that it does not interfere with him in another.
Badoo developers use a self-written solution to collect JS errors. When an error occurs on the client, the code collects all possible data and sends it to a special repository. It stores information about the time of the error, user data and the trace. But even this information is sometimes not enough to reproduce the error. This is where Selenium helps us.
Our Selenium tests check all the most popular actions that users perform on the site. If there is an error, it will certainly occur during the passage of these tests. It is enough just to teach Selenium to pay attention to such errors.
I solved this problem as follows: I added a template that was connected only for test servers. In this template there was a piece of JS code that collected JS errors into a specific object. Something like this:
The same could be done in the Selenium test itself using the execute command. It allows you to execute the JS code on the page as if the user opened the browser console and executed the code in it. But then we could miss some of the mistakes.
The fact is that it is possible to execute this code in the Selenium test only after the page is fully loaded. Consequently, all errors that appear during the download itself will go unnoticed. There is no such problem with the template, since the code in it is executed before the main JS code.
After adding the template, all errors began to be collected into an errorObj object that is available globally. And now you could use the execute command. I added to our Selenium framework a method that executed errorObj.getErrors (), that is, I received all the errors that got into errorObj, and saved them on the side of the Selenium test itself.
Let me remind you that we write Selenium tests in PHP. The error collection code was like this:
We get errors from the errorObj JS object and process each one.
Some errors are already known to us. We know that they are on the project and are either already in the process of correction, or are being reproduced only in “laboratory” conditions. For example, errors that appear only for test users and that are related to the way we prepared them for the test. We ignore such errors in the test.
If the same error occurs during the test for the second time, we also ignore it - we are only interested in unique ones.
For each new error we add the URL and save all the information in an array.
We call the collectJsErrors () method after each action on the site: opening the page, waiting and clicking on an item, entering some data, and so on. No matter how we interact with the interface, we are sure to make sure that this action was not the cause of the error.
We check the array with collected errors only at the end of the test in tearDown (). After all, if the error somehow affects the user, the test will fall. And if it does not, then dropping the test immediately is bad, you first need to check the script to the end. Suddenly, behind this error there are more serious problems.
Thus, we managed to teach Selenium tests to catch client errors. And it became easier to reproduce the errors themselves, knowing what kind of test catches them.
By themselves, Selenium tests are not intended to test layout. Of course, if an element that you have to interact with is invisible or hidden by another element, the test will “tell” us about it. Such Selenium can do “out of the box”. But if the button has gone somewhere down and it looks bad, then already the Selenium test as a whole is just the same - its task is to click on it ...
Nevertheless, it is a long time to check the layout manually before each release (and for the Desktop Web, for example, we have two of them per day). And the human factor can intervene again: the eye is “washed out”, something can be forgotten ... It is necessary to automate this process somehow.
First, we created a simple storage for images. By a POST request, it was possible to send a screenshot to it, specifying an additional release version, and by a GET request with an indication of the release version - to receive all the screenshots related to this release.
Next, we wrote Selenium tests, which raised all browsers of interest to us, which opened all pages of interest to us, pop-ups, overlays, and so on. In each place they took a screenshot of the page and sent it to this repository.
The storage interface allowed you to quickly scroll through all the screenshots manually and make sure that all pages look decent on all browsers. Of course, it is difficult to catch a minor bug in this way. But if the layout broke significantly, it immediately caught my eye. And in any case, scrolling through screenshots is faster and easier than clicking the site in all browsers with your hands.
At first we had not so many screenshots and it was possible to live with it. However, after some time we wanted to test letters, the variants of which are much more than the pages on the site.
To get screenshots of letters I had to resort to some tricks. The fact is that it is much easier to get the generated HTML in the test than to go to the real mail service (and we are still talking about Selenium tests), find the right letter there, open it and take a screenshot. Just because you can get HTML letters on our side using “backdoor” (we have the QaAPI tool that allows us to retrieve data about a particular user in a test environment for test users using a simple cURL query). But for a third-party service, you would have to write, stabilize and maintain Page Objects: locators, methods, and so on.
It is clear that almost all email clients display a letter a little differently than we will see in the “bare” HTML. But some serious mistakes in the layout, breaking the appearance of the letter, even out of context, are thus successfully caught.
But what to do with the resulting HTML? How to make sure that it is displayed correctly in all browsers? It turned out pretty simple. There is an empty page on our collector, where the Selenium test can go and perform a simple execute:
If you do this on the right browser, you can see how the HTML will look in it. It remains only to take a screenshot and send it to the same collector.
After this was done, there were a lot of screenshots. And checking them by hand twice a day was really difficult.
To solve this problem, you can resort to a simple comparison of pictures by pixels. In this case, you will have to take into account all the variables that are on your project. In the example with the letter, for example, it can be the name of the user and his picture. In this case, before you take a screenshot, you will have to tweak HTML a bit, replacing the pictures and names with default ones. Or generate letters for users with the same name and photo. :)
For less permanent content, such manipulations can be much more.
Then you can get the number of mismatched pixels and make a conclusion about how critical the changes are. You can build diff by marking on the image to be checked those zones that do not coincide with the reference ones.
In PHP, the ImageMagick library is great for this purpose. Also, similar tests are written by JavaScript developers, they use Resemble.js .
As an example, consider the Badoo authorization page:
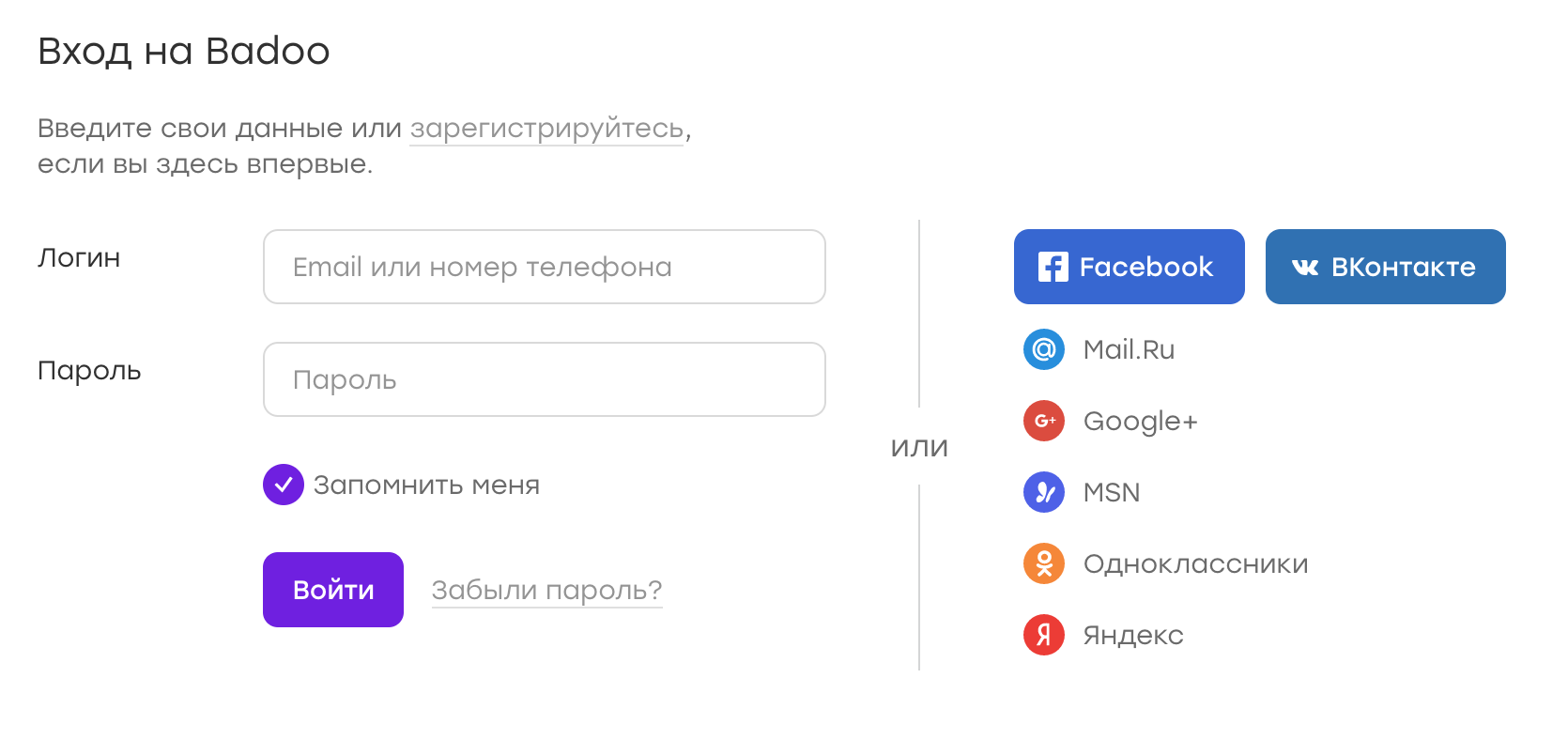
Suppose, for some reason, the “remember me” checkbox is lost. Because of this, the submission button was slightly higher. Then the diff will look like this:
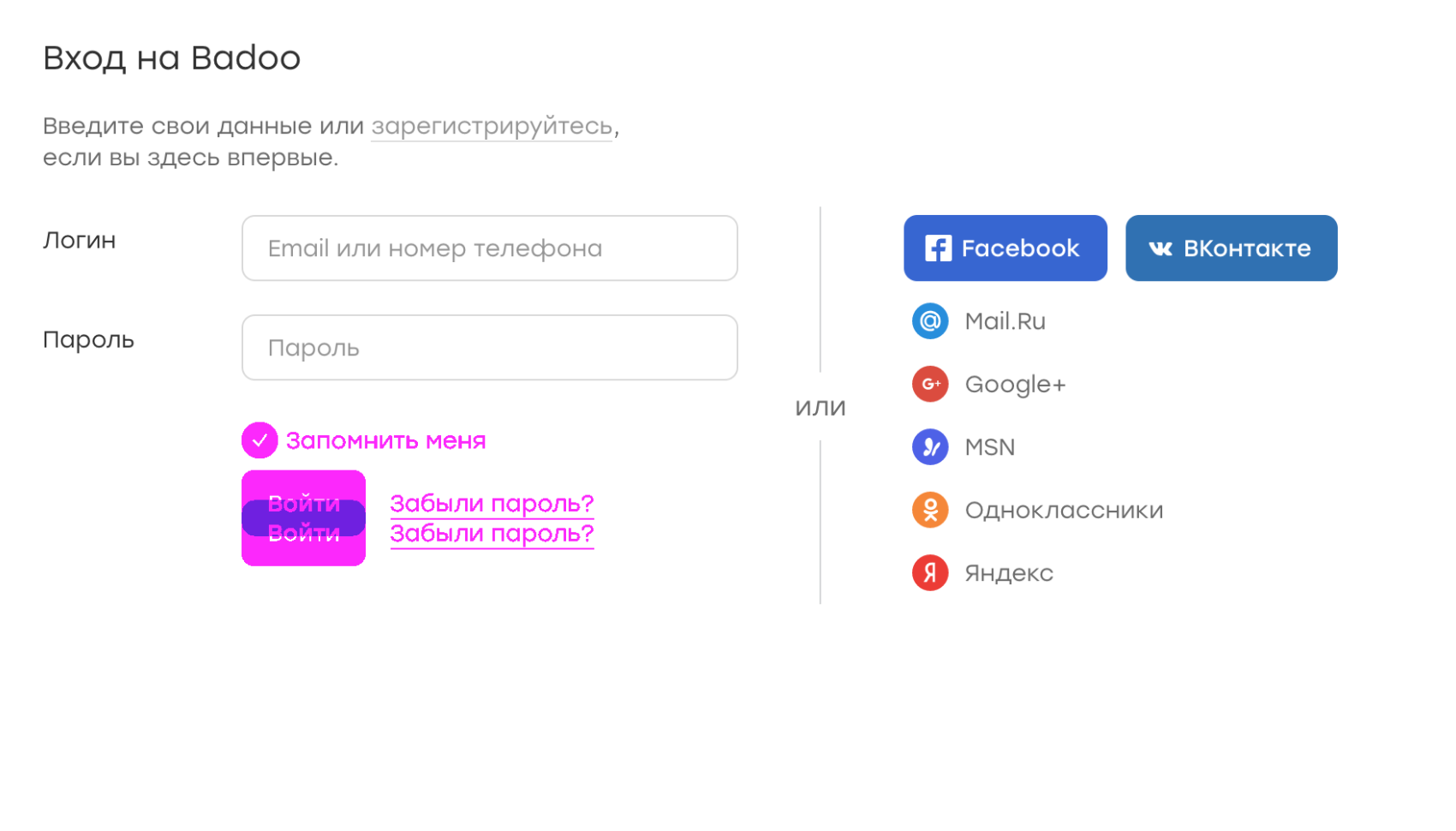
In the picture, the purple shows the discrepancies between the reference screenshot and the one on which the element is missing. We immediately see what is wrong.
The comparison system can be set to a critical number of pixels, and if no screenshot exceeds this number, you can send a notification that all is well. If any screenshots began to differ significantly - to ring the alarm ...
Thus, you can forget about checking screenshots manually, looking only at what really deserves attention.
In Badoo, all clients (Desktop Web, Mobile Web, Android and iOS applications) communicate with the server using a specific HTTP-based API. This approach has several advantages. For example, it is much easier to develop clients and server in parallel.
However, there is a place for mistakes. It may happen that the client accesses the server more often than it should, because of a bug or because of a generally improperly designed architecture. In this case, an extra load will be created, not to mention the fact that maybe something will work incorrectly.
To monitor such things at the development and testing stage, we also use Selenium tests. At the beginning of these tests, we generate a cookie, which we call “device id”. We transfer its value to the server, which for this “device id” starts recording all API requests that come to it.
After that, the tests themselves are run that perform certain scenarios: open pages, write to each other, like, and so on. All this time the server considers requests.
At the end of the tests, we send a signal to the server to stop recording. The server generates a special log by which you can understand how many requests of which types were made. If this number deviates from the benchmark by more than N percent, the auto tester receives a special notification, and we begin to understand the situation. Sometimes this behavior is expected (for example, when a new request appears that is associated with a new functionality on the site) - then we adjust the reference values. And sometimes it turns out that the client by mistake creates unnecessary requests, and this needs to be fixed.
We run such tests on pricing before the new version of the client is obtained by the user. Visually comparing the number of requests from release to release looks like this:
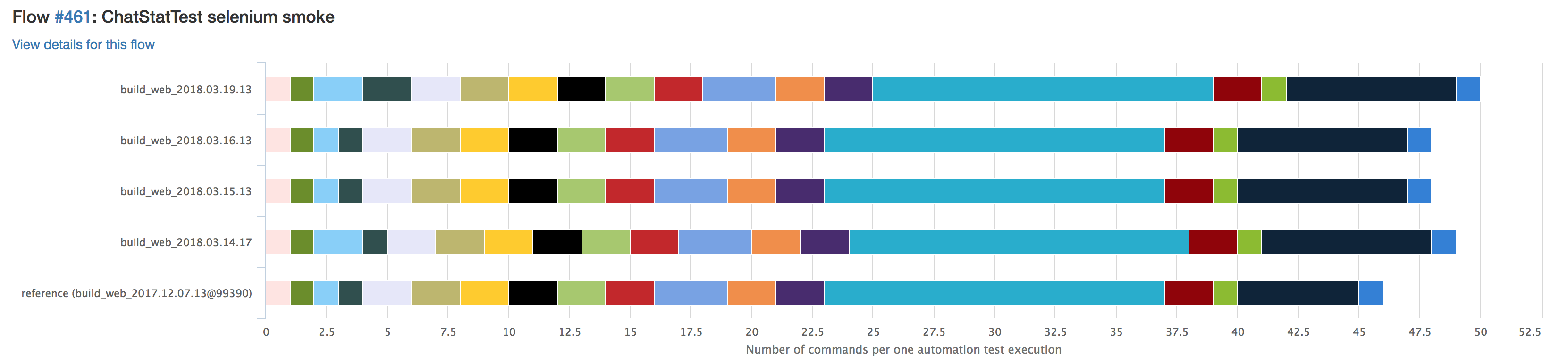
Each color represents a specific type of request. If some query will be repeated more often, it will be visually noticeable. We also have a special notification for this case, so no need to go in and see the statistics before each release.
We resort to similar tricks in order to quickly deal with errors in the server logs. When a new error appears on pricing, it is not always clear how to reproduce it and because of what ticket it appeared.
At the very beginning of any Selenium test, a special cookie “testname” is created, into which we pass the name of the current test. Accordingly, if an error on the server was generated during the AutoTest, it is easier to reproduce it in most cases, since we know the playback scenario. To find the task from which the error came to release, you can run the Selenium test on all released tasks and see their logs.
We have this process automated, I wrote about this in a previous article .
In general, this approach allows much faster to deal with server errors in the release and localize them.
And why, actually, no? :)

Selenium is a tool that allows you to manipulate the browser. And how exactly and why, it is already up to those who use this tool. By showing ingenuity, you can significantly ease your life.
Needless to say, for some types of checks there are some more appropriate tools. For example, Selenium will not be able to fully replace vulnerability scanners or fast parsers, written, for example, on cURL libraries. It is also rather strange to use it for load testing - in this case, it will be possible to test the fault tolerance of the Selenium farm rather than the combat application. :)
However, there is a set of tasks for which Selenium is great. I talked about how he helps us. I will be glad to hear about interesting ways to use Selenium in your companies.
Thanks for attention.
My name is Vitaliy Kotov, I work in the testing department of Badoo. Most of the time I work with Selenium. We use this wonderful tool for solving various tasks: from functional testing to simplifying work with error logs and testing interaction with API.
About what tasks Selenium helps us to solve, and will be discussed in this article. Go! :)
')
A bit about Selenium
The first thing Google will tell us about “Selenium”:
Selenium is a tool to automate web browser actions. In most cases, it is used to test Web applications, but is not limited to this.
Selenium allows you to do almost the same thing that we could do with our hands: open the pages and interact with them. However, he does it faster and more reliably, since he cannot “blush” his eye and he cannot click wrongly by mistake.
In test automation, the first thing Selenium uses is to check the functionality of the site.
Functional check
What do users usually do on the site? They open it, click here and there, see some results of their clicks: redirects, pop-ups, highlighting of elements, and so on. This process is desirable (and necessary) to test. It is necessary to make sure that the user sees exactly the response to his action, which is incorporated in our business logic.
For this, scripts are created that describe the actions of users. For example:
- View site.
- Click on the authorization button.
- Wait for the login form to load.
- Enter username and password.
- Click on the submission button.
- Wait for the redirect to the authorized page.
If the authorization is broken on the site (for example, the programmer got it wrong - and the getUser method now always returns false), Selenium fails to go through step 6. The test will drop and let us know. In fact, somewhere in the code, Exception will be thrown, and the process will end with the corresponding error code.
This sequence of actions is called functional testing. This is perhaps the most common use of Selenium. But there are more interesting.
Collecting js errors
Normal user JS-error does not see. This is right - he has no reason. But it is important for developers to understand whether their code does not “fire” in some cases. JS-errors I would divide in this context into two types: visible to the user and those that do not interfere with the user.
With the first kind of errors, everything is clear. If the site does not respond to the user's action due to a JS error, the Selenium test will notice it.
With the second kind of errors, everything is more complicated. If they do not interfere with the use of the application, is it worth it to fix them? In Badoo, we try to correct such errors along with the errors of the first type. First, any error somehow signals some kind of problem. Secondly, if it does not interfere with the user in one case, this does not mean that it does not interfere with him in another.
Badoo developers use a self-written solution to collect JS errors. When an error occurs on the client, the code collects all possible data and sends it to a special repository. It stores information about the time of the error, user data and the trace. But even this information is sometimes not enough to reproduce the error. This is where Selenium helps us.
Our Selenium tests check all the most popular actions that users perform on the site. If there is an error, it will certainly occur during the passage of these tests. It is enough just to teach Selenium to pay attention to such errors.
I solved this problem as follows: I added a template that was connected only for test servers. In this template there was a piece of JS code that collected JS errors into a specific object. Something like this:
var errorObj = { _errors : [], addError : function(message, source, lineno) { this._errors.push( "Message: " + message + "\n" + "Source: " + source + "\n" + "Line: " + lineno ); }, getErrors : function() { return this._errors; } } window.onerror = function(message, source, line_no) { errorObj.addError(message, source, line_no); } The same could be done in the Selenium test itself using the execute command. It allows you to execute the JS code on the page as if the user opened the browser console and executed the code in it. But then we could miss some of the mistakes.
The fact is that it is possible to execute this code in the Selenium test only after the page is fully loaded. Consequently, all errors that appear during the download itself will go unnoticed. There is no such problem with the template, since the code in it is executed before the main JS code.
After adding the template, all errors began to be collected into an errorObj object that is available globally. And now you could use the execute command. I added to our Selenium framework a method that executed errorObj.getErrors (), that is, I received all the errors that got into errorObj, and saved them on the side of the Selenium test itself.
Let me remind you that we write Selenium tests in PHP. The error collection code was like this:
public function collectJsErrors() { $return_errorObj = /** @lang JavaScript */ 'if (typeof errorObj !== "undefined") {return errorObj.getErrors();} else {return null;}'; $js_result = $this->execute($return_errorObj)->sync(); foreach ($js_result as $result) { $current_stacktrace = $result; //check if an error is known foreach (self::$known_js_errors as $known_error) { if (strpos($current_stacktrace, $known_error) !== false) { continue 2; } } //check if the error already caught foreach ($this->getJsErrors() as $error) { $existed_stacktrace = $error['error']; if ($current_stacktrace == $existed_stacktrace) { continue 2; } } //collect an error $this->addJsError([ 'error' => $result, 'location' => $this->getLocation(), ]); } } We get errors from the errorObj JS object and process each one.
Some errors are already known to us. We know that they are on the project and are either already in the process of correction, or are being reproduced only in “laboratory” conditions. For example, errors that appear only for test users and that are related to the way we prepared them for the test. We ignore such errors in the test.
If the same error occurs during the test for the second time, we also ignore it - we are only interested in unique ones.
For each new error we add the URL and save all the information in an array.
We call the collectJsErrors () method after each action on the site: opening the page, waiting and clicking on an item, entering some data, and so on. No matter how we interact with the interface, we are sure to make sure that this action was not the cause of the error.
We check the array with collected errors only at the end of the test in tearDown (). After all, if the error somehow affects the user, the test will fall. And if it does not, then dropping the test immediately is bad, you first need to check the script to the end. Suddenly, behind this error there are more serious problems.
Thus, we managed to teach Selenium tests to catch client errors. And it became easier to reproduce the errors themselves, knowing what kind of test catches them.
Typesetting
By themselves, Selenium tests are not intended to test layout. Of course, if an element that you have to interact with is invisible or hidden by another element, the test will “tell” us about it. Such Selenium can do “out of the box”. But if the button has gone somewhere down and it looks bad, then already the Selenium test as a whole is just the same - its task is to click on it ...
Nevertheless, it is a long time to check the layout manually before each release (and for the Desktop Web, for example, we have two of them per day). And the human factor can intervene again: the eye is “washed out”, something can be forgotten ... It is necessary to automate this process somehow.
First, we created a simple storage for images. By a POST request, it was possible to send a screenshot to it, specifying an additional release version, and by a GET request with an indication of the release version - to receive all the screenshots related to this release.
Next, we wrote Selenium tests, which raised all browsers of interest to us, which opened all pages of interest to us, pop-ups, overlays, and so on. In each place they took a screenshot of the page and sent it to this repository.
The storage interface allowed you to quickly scroll through all the screenshots manually and make sure that all pages look decent on all browsers. Of course, it is difficult to catch a minor bug in this way. But if the layout broke significantly, it immediately caught my eye. And in any case, scrolling through screenshots is faster and easier than clicking the site in all browsers with your hands.
At first we had not so many screenshots and it was possible to live with it. However, after some time we wanted to test letters, the variants of which are much more than the pages on the site.
To get screenshots of letters I had to resort to some tricks. The fact is that it is much easier to get the generated HTML in the test than to go to the real mail service (and we are still talking about Selenium tests), find the right letter there, open it and take a screenshot. Just because you can get HTML letters on our side using “backdoor” (we have the QaAPI tool that allows us to retrieve data about a particular user in a test environment for test users using a simple cURL query). But for a third-party service, you would have to write, stabilize and maintain Page Objects: locators, methods, and so on.
It is clear that almost all email clients display a letter a little differently than we will see in the “bare” HTML. But some serious mistakes in the layout, breaking the appearance of the letter, even out of context, are thus successfully caught.
But what to do with the resulting HTML? How to make sure that it is displayed correctly in all browsers? It turned out pretty simple. There is an empty page on our collector, where the Selenium test can go and perform a simple execute:
public function drawMailHTML(string $html) { $js = /** @lang JavaScript */ 'document.write("{HTML}")'; $js = str_replace('{HTML}', $html, $js); $this->execute($js)->sync(); } If you do this on the right browser, you can see how the HTML will look in it. It remains only to take a screenshot and send it to the same collector.
After this was done, there were a lot of screenshots. And checking them by hand twice a day was really difficult.
To solve this problem, you can resort to a simple comparison of pictures by pixels. In this case, you will have to take into account all the variables that are on your project. In the example with the letter, for example, it can be the name of the user and his picture. In this case, before you take a screenshot, you will have to tweak HTML a bit, replacing the pictures and names with default ones. Or generate letters for users with the same name and photo. :)
For less permanent content, such manipulations can be much more.
Then you can get the number of mismatched pixels and make a conclusion about how critical the changes are. You can build diff by marking on the image to be checked those zones that do not coincide with the reference ones.
In PHP, the ImageMagick library is great for this purpose. Also, similar tests are written by JavaScript developers, they use Resemble.js .
As an example, consider the Badoo authorization page:
Suppose, for some reason, the “remember me” checkbox is lost. Because of this, the submission button was slightly higher. Then the diff will look like this:
In the picture, the purple shows the discrepancies between the reference screenshot and the one on which the element is missing. We immediately see what is wrong.
The comparison system can be set to a critical number of pixels, and if no screenshot exceeds this number, you can send a notification that all is well. If any screenshots began to differ significantly - to ring the alarm ...
Thus, you can forget about checking screenshots manually, looking only at what really deserves attention.
Test client interaction with API
In Badoo, all clients (Desktop Web, Mobile Web, Android and iOS applications) communicate with the server using a specific HTTP-based API. This approach has several advantages. For example, it is much easier to develop clients and server in parallel.
However, there is a place for mistakes. It may happen that the client accesses the server more often than it should, because of a bug or because of a generally improperly designed architecture. In this case, an extra load will be created, not to mention the fact that maybe something will work incorrectly.
To monitor such things at the development and testing stage, we also use Selenium tests. At the beginning of these tests, we generate a cookie, which we call “device id”. We transfer its value to the server, which for this “device id” starts recording all API requests that come to it.
After that, the tests themselves are run that perform certain scenarios: open pages, write to each other, like, and so on. All this time the server considers requests.
At the end of the tests, we send a signal to the server to stop recording. The server generates a special log by which you can understand how many requests of which types were made. If this number deviates from the benchmark by more than N percent, the auto tester receives a special notification, and we begin to understand the situation. Sometimes this behavior is expected (for example, when a new request appears that is associated with a new functionality on the site) - then we adjust the reference values. And sometimes it turns out that the client by mistake creates unnecessary requests, and this needs to be fixed.
We run such tests on pricing before the new version of the client is obtained by the user. Visually comparing the number of requests from release to release looks like this:
Each color represents a specific type of request. If some query will be repeated more often, it will be visually noticeable. We also have a special notification for this case, so no need to go in and see the statistics before each release.
Server logs
We resort to similar tricks in order to quickly deal with errors in the server logs. When a new error appears on pricing, it is not always clear how to reproduce it and because of what ticket it appeared.
At the very beginning of any Selenium test, a special cookie “testname” is created, into which we pass the name of the current test. Accordingly, if an error on the server was generated during the AutoTest, it is easier to reproduce it in most cases, since we know the playback scenario. To find the task from which the error came to release, you can run the Selenium test on all released tasks and see their logs.
We have this process automated, I wrote about this in a previous article .
In general, this approach allows much faster to deal with server errors in the release and localize them.
Automatic pizza order on Friday night
And why, actually, no? :)
Results
Selenium is a tool that allows you to manipulate the browser. And how exactly and why, it is already up to those who use this tool. By showing ingenuity, you can significantly ease your life.
Needless to say, for some types of checks there are some more appropriate tools. For example, Selenium will not be able to fully replace vulnerability scanners or fast parsers, written, for example, on cURL libraries. It is also rather strange to use it for load testing - in this case, it will be possible to test the fault tolerance of the Selenium farm rather than the combat application. :)
However, there is a set of tasks for which Selenium is great. I talked about how he helps us. I will be glad to hear about interesting ways to use Selenium in your companies.
Thanks for attention.
Source: https://habr.com/ru/post/351444/
All Articles