A small library for the use of AI in Telegram chat bots
Good day! In the wake of the general interest in chat bots in particular, and systems of dialog intelligence, in general, for some time I have been involved in projects related to this topic. Today I would like to put one of the libraries in open source. I will make a reservation that first of all I specialize in algorithmic aspects of development and therefore I will be glad to constructively criticize the decisions of a coder nature from specialists more knowledgeable in this matter.

The library is dedicated to building an interface between an algorithm that returns a response to a text request and the Telegram messenger API. Designed for flexible use of machine learning algorithms. By the way, if experts are more knowledgeable than me, they can offer a good option, unifying the interfaces of various possible communication channels (messengers, web widgets, etc.) with a single point of entry into the answer function, I will be glad to discuss it in the comments. Personally, I, at one time, had to use the module independently written in Flask and giving access to the algorithm via http-requests. To interact with each user interface (Telegram, Facebook, etc.), you had to write a separate program that dealt with it, translated the request into a unified format that could be written in Flask API, and finally, translated the response back into a format that the user interface . This design looks a bit clumsy, so, I repeat, I will be happy to discuss this issue in the comments with more experienced colleagues in this topic.
The main function called externally when the library is
')
Generation of the meta-model and the final answer are separated into two different functions for reasons of greater convenience of setting up, validating and testing the meta-model and at the same time simplicity of writing and testing of the essence of the UX part, which translates the output value of the meta-model into a user-friendly one. format.
Briefly discuss the functions contained in the library.
The main function called from a script using the library. It loads the cache file, runs a function in the parallel thread that updates the data, polls and sends the response to the Telegram and the service that monitors the status of the bot.
Receives the latest posts from the bot user.
It processes the received message and converts it into a form convenient for further processing.
The function responsible for sending a message to the Telegram chat. For historical reasons, the key argument message may be of type str (for simple single messages), list (for message strings), or dict (for messages containing an embedded keyboard).
The function responsible for logging the dialog.
A function that generates a request to the Telegram API based on the message data, the chat number, the token and the response markup (usually containing information about the embedded keyboard).
Updates data from third-party sources.
Updates the contents of the cache file. Useful in case the next time you start the program (for example, after a crash or when a new version is deployed), the data service is unavailable.
Checks if it's time to update data from third-party APIs.
A function that runs in a parallel thread and deals with updating third-party API data. I had to recall the basics of multi-threaded programming, since some APIs can respond to a request within tens of seconds and at this time the main program hung and did not respond to user requests.
The library is intended primarily to interact with machine learning algorithms, but their discussion goes far beyond the scope of this article. In order to show how it works, we will write two simple functions and use them as a generator of an example of a model and an interpreter of output.
An example of a script using the library.
Token to authorize the Telegram bot. It must be replaced by the issued BotFather for a particular bot.
The token for the alert script controlling that the bot is working. You can replace with a random string if this function is not needed.
Trivial replacement of the class responsible for the logic of processing incoming messages. Someday there will be a complex AI, but, alas, not yet. At least not in this article. And those who wish to read about how to quickly write a machine learning algorithm and roll it into production can do it here.
The function that generates the model.
The function that is responsible for the logic of forming a response to the result of applying the model. In our simple example, the answer unambiguously corresponds to one of the possible meanings of the user's messages specified in the predict () function of the HelloWorldMetaModel class.
An example of a function that attracts external variable data.
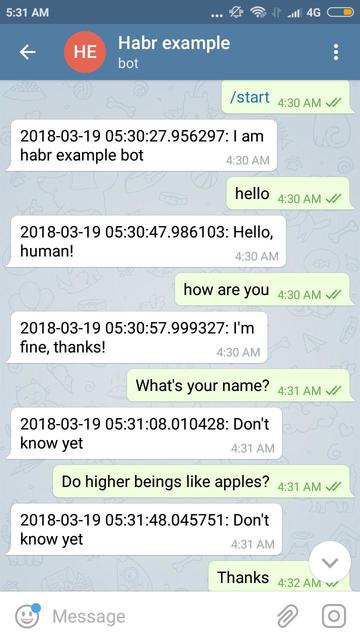
Example of work (clickable image):
The githaba code is here .
The code on the beatback is here .
It is simple to
Glossary
The (trained) machine learning model is a function that takes as its input an array of numbers of fixed length (for mathematicians, a point in n-dimensional space) and returns a class identifier (when solving a classification problem) or a number (when solving a regression problem).
[1] The meta-model is a generalization of the concept of a machine learning model. It differs in that it takes an object of arbitrary nature as an input (for example, an array of a coding image, a string, a description of a website user, and so on) and gives an output of an arbitrary nature (usually a class identifier, a number, a dictionary or a string). Abstraction is useful for encapsulating a machine learning pipeline, usually involving preprocessing, applying a model, and postprocessing into a single entity (author's terminology).
The library is dedicated to building an interface between an algorithm that returns a response to a text request and the Telegram messenger API. Designed for flexible use of machine learning algorithms. By the way, if experts are more knowledgeable than me, they can offer a good option, unifying the interfaces of various possible communication channels (messengers, web widgets, etc.) with a single point of entry into the answer function, I will be glad to discuss it in the comments. Personally, I, at one time, had to use the module independently written in Flask and giving access to the algorithm via http-requests. To interact with each user interface (Telegram, Facebook, etc.), you had to write a separate program that dealt with it, translated the request into a unified format that could be written in Flask API, and finally, translated the response back into a format that the user interface . This design looks a bit clumsy, so, I repeat, I will be happy to discuss this issue in the comments with more experienced colleagues in this topic.
The main function called externally when the library is
main_loop_webhooks() is main_loop_webhooks() , accepts a function that generates a meta-model [1], a function that generates a response based on the result of applying the model, update settings (for example, regular weather forecast updates or prices for certain goods) , a list of resources in a specific format (currently used to send answers to Telegram and regularly notify the external script that the bot is functioning and did not fall).')
Generation of the meta-model and the final answer are separated into two different functions for reasons of greater convenience of setting up, validating and testing the meta-model and at the same time simplicity of writing and testing of the essence of the UX part, which translates the output value of the meta-model into a user-friendly one. format.
Hidden text
# Author: Andrei Grinenko <andrey.grinenko@gmail.com> # License: BSD 3 clause import os import json import time import urllib.request import urllib.parse import threading import traceback import datetime def get_safe_response_data(url): try: response = urllib.request.urlopen(url, timeout=1) response_data = json.loads(response.read()) return response_data except KeyboardInterrupt: raise except: time.sleep(3) return {} def clear_updates(token, offset): urllib.request.urlopen('https://api.telegram.org/bot' + token + '/getupdates?offset=' + str(offset + 1)) def write_message(message, chat_id, token): if type(message) == str: http_request = to_request(message, chat_id, token) response = urllib.request.urlopen(http_request) # including keyboard, new format elif type(message) == dict: text = message['text'] reply_markup = message['reply_markup'] http_request = to_request(text, chat_id, token, reply_markup) response = urllib.request.urlopen(http_request) # type(mesage) == list else: for str_message in message: write_message(str_message, chat_id, token) def write_log(**kwargs): file_name = kwargs.get('file_name', './data/log.txt') current_datetime = datetime.datetime.now() kwargs.update({'current_datetime': current_datetime}) with open(file_name, 'a') as output_stream: try: output_stream.write(to_beautified_log_line(**kwargs)) except: print(kwargs) print(traceback.print_exc()) output_stream.write(to_simple_log_line(**kwargs)) def to_request(message, chat_id, token, reply_markup={}): message_ = urllib.parse.quote(message) return ('https://api.telegram.org/bot' + token + '/sendmessage?' + 'chat_id=' + str(chat_id) + '&parse_mode=Markdown' + '&text=' + message_ + '&reply_markup=' + json.dumps(reply_markup)) def to_request_old(message, chat_id, token, reply_markup={}): return to_request(message, chat_id, token, reply_markup) def get_last_message_data(token): try: response = urllib.request.urlopen('https://api.telegram.org/bot' + token + '/getupdates') text_response = response.read().decode('utf-8') json_response = json.loads(text_response) return json_response except KeyboardInterrupt: raise except: traceback.print_exc() time.sleep(3) return None def update_data(updates_settings): result = dict() for key in updates_settings['data']: result[key] = updates_settings['data'][key]() return result # Updates cash file with new data just obtained from sources def update_cash_file(new_data, cash_file_name): """ new_data: dict of dicts and values """ if os.path.isfile(cash_file_name): with open(cash_file_name) as input_stream: cash_file_data = json.loads(input_stream.read()) else: cash_file_data = {} for key in new_data: if type(new_data[key]) == dict: if not key in cash_file_data: cash_file_data[key] = dict() for subkey in new_data[key]: cash_file_data[key][subkey] = new_data[key][subkey] else: cash_file_data[key] = new_data[key] with open(cash_file_name, 'w') as output_stream: output_stream.write(json.dumps(cash_file_data)) def to_simple_log_line(**kwargs): channel = kwargs.get('channel', None) chat_id = kwargs.get('chat_id', None) message_text = kwargs['message_text'] username = kwargs.get('username', None) first_name = kwargs.get('first_name', None) last_name = kwargs.get('last_name', None) response = kwargs['response'] current_datetime = kwargs.get('current_datetime', None) datetime_output = (str(current_datetime.year) + '-' + str(current_datetime.month) + '-' + str(current_datetime.day) + '/' + str(current_datetime.hour) + ':' + str(current_datetime.minute)) output_data = {'datetime':datetime_output, 'channel':channel, 'chat_id':chat_id, 'message_text':message_text, 'username':username, 'first_name':first_name, 'last_name':last_name, 'response':response} return str(output_data) + '\n' def to_beautified_log_line(**kwargs): channel = kwargs.get('channel', None) chat_id = kwargs.get('chat_id', None) message_text = kwargs['message_text'] username = kwargs.get('username', None) first_name = kwargs.get('first_name', None) last_name = kwargs.get('last_name', None) response = kwargs['response'] current_datetime = kwargs.get('current_datetime', datetime.datetime(2000, 1, 1, 0, 0)) datetime_output = (str(current_datetime.year) + '-' + str(current_datetime.month) + '-' + str(current_datetime.day) + '/' + str(current_datetime.hour) + ':' + str(current_datetime.minute))# .encode('utf-8') username_data = str(username)# .encode('utf-8') first_name_data = str(first_name)# .encode('utf-8') last_name_data = str(last_name)# .encode('utf-8') response_data = str(response)# .encode('utf-8') output_data = {'datetime':datetime_output, 'channel':str(channel), # .encode('utf-8'), 'chat_id':str(chat_id), 'message_text':message_text, # .encode('utf-8'), 'username':username_data, 'first_name':first_name_data, 'last_name':last_name_data, 'response':response_data} return json.dumps(output_data, ensure_ascii=False) + '\n' def message_to_input(message_data): input_data = dict() try: input_data['message_text'] = message_data['result'][-1]['message']['text'] except: input_data['message_text'] = None try: input_data['update_id'] = message_data['result'][-1]['update_id'] except: input_data['update_id'] = None try: input_data['chat_id'] = message_data['result'][-1]['message']['chat']['id'] except: input_data['chat_id'] = None try: input_data['username'] = message_data['result'][-1]['message']['chat']['username'] except: input_data['username'] = None try: input_data['first_name'] = message_data['result'][-1]['message']['chat']['first_name'] except: input_data['first_name'] = None try: input_data['last_name'] = message_data['result'][-1]['message']['chat']['last_name'] except: input_data['last_name'] = None return input_data def is_update_time(new_datetime, last_update_datetime, updates_settings): if updates_settings['frequency'] == None: return False else: return new_datetime - last_update_datetime > updates_settings['frequency'] def update_data_thread_function(updates_settings, cash_file_name): global updating_data last_update_datetime = datetime.datetime.now() - datetime.timedelta(weeks=10) while True: new_datetime = datetime.datetime.now() if is_update_time(new_datetime, last_update_datetime, updates_settings): print('Updating data at datetime: {}', new_datetime) last_update_datetime = datetime.datetime.now() try: new_data = update_data(updates_settings) if cash_file_name: update_cash_file(new_data, cash_file_name) updating_data = json.load(open(cash_file_name)) else: updating_data = new_data except: traceback.print_exc() time.sleep(3) continue time.sleep(10) def main_loop_webhooks(generate_model_func, generate_response_func, updates_settings={'frequency':None, 'data':{}}, **kwargs): """ updates_settings format: {frequency: datetime.timedelta, data: {first_field: first_function, second_field: second_function, ...}} kwargs: cash_file_name: str, cash file name for cashing updates data, None for no file name """ cash_file_name = kwargs.get('cash_file_name', None) log_file_name = kwargs.get('log_file_name', None) list_of_sources = kwargs['list_of_sources'] # .get('list_of_sources', []) model = generate_model_func() print('Model trained') global updating_data if os.path.isfile(cash_file_name): updating_data = json.load(open(cash_file_name)) else: updating_data = {} update_data_thread = threading.Thread(target=update_data_thread_function, args=(updates_settings, cash_file_name)) update_data_thread.start() current_update_id = 0 activity_status = None last_ping_time = datetime.datetime.now() while True: for source in list_of_sources: current_datetime = datetime.datetime.now() if source['node'] == 'https://api.telegram.org/' and activity_status != 'waiting': try: message_data = get_last_message_data(source['id']['token']) except KeyboardInterrupt: raise except: traceback.print_exc() time.sleep(3) continue input_data = message_to_input(message_data) try: if input_data['update_id'] != None: clear_updates(source['id']['token'], input_data['update_id']) except: traceback.print_exc() if (input_data['update_id'] != None and input_data['message_text'] != None and (current_update_id == None or input_data['update_id'] > current_update_id)): current_update_id = input_data['update_id'] analizing_data = {'message_text':input_data['message_text'], 'username':input_data['username'], 'first_name':input_data['first_name'], 'last_name':input_data['last_name'], 'recipient':{'channel':'telegram', 'token':source['id']['token'], 'chat_id':input_data['chat_id']}} user_id = {'channel':analizing_data['recipient']['channel'], 'chat_id':analizing_data['recipient']['chat_id']} try: response = generate_response_func(input_data['message_text'], model, user_id, updating_data) except: response = u'Sorry, can\'t reply' traceback.print_exc() write_attempts_number = 5 write_attempts_counter = 0 while write_attempts_counter < write_attempts_number: try: write_message(response, analizing_data['recipient']['chat_id'], analizing_data['recipient']['token']) write_attempts_counter = write_attempts_number # Success! except: if write_attempts_counter == 1: traceback.print_exc() write_attempts_counter += 1 time.sleep(3) write_log(file_name=log_file_name, message_text=analizing_data['message_text'], response=response, channel=analizing_data['recipient']['channel'], chat_id=analizing_data['recipient']['chat_id'], username=analizing_data['username'], first_name=analizing_data['first_name'], last_name=analizing_data['last_name']) else: current_time = datetime.datetime.now() if current_time - last_ping_time > datetime.timedelta(seconds=10): last_ping_time = current_time response_data = get_safe_response_data(source['node'] + 'ping' + source['id']['token'] + '/getupdates') if response_data.get('sysmsg') == 'ping': activity_status = response_data.get('status') analizing_data = {'node':source['node'], 'recipient':source['id'], 'ping':True} http_address = (analizing_data['node'] + 'ping' + analizing_data['recipient']['token'] + '/sendmessage') try: urllib.request.urlopen(http_address, timeout=1) except: pass Briefly discuss the functions contained in the library.
main_loop_webhook(generate_model_func, generate_response_func, updates_settings, **kwargs) The main function called from a script using the library. It loads the cache file, runs a function in the parallel thread that updates the data, polls and sends the response to the Telegram and the service that monitors the status of the bot.
get_last_message_data(token) Receives the latest posts from the bot user.
message_to_input(message_data) It processes the received message and converts it into a form convenient for further processing.
write_message(message, chat_id, token) The function responsible for sending a message to the Telegram chat. For historical reasons, the key argument message may be of type str (for simple single messages), list (for message strings), or dict (for messages containing an embedded keyboard).
write_log(**kwargs) The function responsible for logging the dialog.
to_request(message, chat_id, token, reply_markup) A function that generates a request to the Telegram API based on the message data, the chat number, the token and the response markup (usually containing information about the embedded keyboard).
update_data(updates_settings) Updates data from third-party sources.
update_cash_file(new_data, cash_file_name) Updates the contents of the cache file. Useful in case the next time you start the program (for example, after a crash or when a new version is deployed), the data service is unavailable.
is_update_time(new_datetime, last_update_datetime, updates_settings) Checks if it's time to update data from third-party APIs.
update_data_thread_function(updates_settings, cash_file_name) A function that runs in a parallel thread and deals with updating third-party API data. I had to recall the basics of multi-threaded programming, since some APIs can respond to a request within tens of seconds and at this time the main program hung and did not respond to user requests.
The library is intended primarily to interact with machine learning algorithms, but their discussion goes far beyond the scope of this article. In order to show how it works, we will write two simple functions and use them as a generator of an example of a model and an interpreter of output.
An example of a script using the library.
Hidden text
# Author: Andrei Grinenko <andrey.grinenko@gmail.com> # License: BSD 3 clause import sys import datetime import web3 TOKEN = '123456789:abcdefghijklmnopqrstuvwxyzABCDEFGHI' REGISTER_TOKEN = '12:abcdef' class HelloWorldMetaModel(object): def __init__(self): pass def predict(self, instance): if instance == '/start': return 'start' elif instance in ['hi', 'hello']: return 'hello' elif instance == 'how are you': return 'how_are_you' else: return 'unknown' def generate_meta_model(): return HelloWorldMetaModel() def generate_response(instance, model, user_id, updating_data): current_datetime = updating_data['datetime'] meaning = model.predict(instance) if meaning == 'start': reply = current_datetime + ': ' + 'I am habr example bot' elif meaning == 'hello': reply = current_datetime + ': ' + 'Hello, human!' elif meaning == 'how_are_you': reply = current_datetime + ': ' + 'I\'m fine, thanks!' else: reply = current_datetime + ': ' + 'Don\'t know yet' # TODO Add datetime return reply def update_datetime(): return str(datetime.datetime.now()) if __name__ == '__main__': web3.main_loop_webhooks( generate_model_func=generate_meta_model, generate_response_func=generate_response, updates_settings={'frequency':datetime.timedelta(seconds=5), 'data':{'datetime':update_datetime}}, list_of_sources=[{'node':'https://api.telegram.org/', 'id':{'token':TOKEN}}, # {'node':'http://123.456.78.90/', # 'id':{'token':REGISTER_TOKEN}} ], cash_file_name='./cash_file.txt', log_file_name='./log.txt') TOKEN = '123456789:abcdefghijklmnopqrstuvwxyzABCDEFGHI' Token to authorize the Telegram bot. It must be replaced by the issued BotFather for a particular bot.
REGISTER_TOKEN = '12:abcdef' The token for the alert script controlling that the bot is working. You can replace with a random string if this function is not needed.
class HelloWorldMetaModel(object) Trivial replacement of the class responsible for the logic of processing incoming messages. Someday there will be a complex AI, but, alas, not yet. At least not in this article. And those who wish to read about how to quickly write a machine learning algorithm and roll it into production can do it here.
generate_meta_model() The function that generates the model.
generate_response(instance, model, user_id, updating_data) The function that is responsible for the logic of forming a response to the result of applying the model. In our simple example, the answer unambiguously corresponds to one of the possible meanings of the user's messages specified in the predict () function of the HelloWorldMetaModel class.
update_datetime() An example of a function that attracts external variable data.
Example of work (clickable image):
The githaba code is here .
The code on the beatback is here .
It is simple to
python3 example.py through python3 example.py , previously changing the value of the TOKEN constant.Glossary
The (trained) machine learning model is a function that takes as its input an array of numbers of fixed length (for mathematicians, a point in n-dimensional space) and returns a class identifier (when solving a classification problem) or a number (when solving a regression problem).
[1] The meta-model is a generalization of the concept of a machine learning model. It differs in that it takes an object of arbitrary nature as an input (for example, an array of a coding image, a string, a description of a website user, and so on) and gives an output of an arbitrary nature (usually a class identifier, a number, a dictionary or a string). Abstraction is useful for encapsulating a machine learning pipeline, usually involving preprocessing, applying a model, and postprocessing into a single entity (author's terminology).
Source: https://habr.com/ru/post/351410/
All Articles