Comparison of open OLAP-systems Big Data: ClickHouse, Druid and Pinot
ClickHouse , Druid and Pinot are three open data stores that allow you to perform analytical queries on large amounts of data with interactive delays. This article is a translation of the detailed comparison made by Roman Leventov.
And under the cut - a detailed story about how the novel came to this.
Details of the implementation of ClickHouse became known to me from Alexey Zatelepin , one of the key developers of the project . The documentation available in English is rather poor - the last four sections of this page of documentation are the best source of information.
')
I myself participate in the development of Druid , but I do not have a personal interest in this system - to be honest, most likely in the near future I will cease to engage in its development. Therefore, readers can count on the absence of any bias.
Everything that I will write about Pinot further is based on the Architecture page in the Pinot wiki , as well as on other wiki pages in the Design Documentation section. The last time they were updated in June 2017 - more than six months ago.
The reviewers of the original article were Alexey Zatelepin and Vitaliy Lyudvichenko (developers of ClickHouse), Jean Merlino (most active developer of Druid), Kishore Gopalakrishna (architect Pinot) and Jean-Francois Im (developer of Pinot). We join the thanks of the author and believe that this greatly increases the credibility of the article.
Warning : the article is quite large, so you may want to limit yourself to reading the section “Conclusion” at the end.
At the fundamental level, ClickHouse, Druid and Pinot are similar because they store data and perform query processing on the same nodes, moving away from the “disconnected” BigQuery architecture. Recently, I have already described several hereditary problems with related architecture in the case of Druid [ 1 , 2 ]. There is currently no open equivalent for BigQuery (with the exception of, perhaps, Drill ?). Possible approaches to building such open systems are covered in another article on my blog .
The systems reviewed in this article perform queries faster than Big Data systems from the SQL-on-Hadoop class family: Hive, Impala, Presto, and Spark, even when the latter gain access to data stored in a column format — for example, Parquet or Kudu. This is because in ClickHouse, Druid and Pinot:
Being on the other side of the database spectrum, ClickHouse, Druid and Pinot do not support point updates and deletes , as opposed to column systems like Kudu, InfluxDB and Vertica (?). This gives ClickHouse, Druid and Pinot the ability to produce more efficient column compression and more aggressive indices, which means greater resource utilization and faster query execution.
The developers of ClickHouse in Yandex plan to start supporting updates and deletions in the future , but I'm not sure if these will be “real” point requests or updates / deletions of data ranges.
All three systems support streaming data absorption from Kafka. Druid and Pinot support streaming Lambda-style streaming and packet acquisition of the same data. ClickHouse supports batch inserts directly, so it does not need a separate batch absorption system similar to that used in Druid and Pinot. If you are interested in the details, you can find them further.
All three systems are tested for performance on a large scale: ClickHouse cluster works in Yandex.Metrica , consisting of about ten thousand CPU cores. Metamarkets uses a similarly sized Druid cluster . One Pinot cluster on LinkedIn includes “ thousands of machines .”
All systems considered in the article are immature by the standards of Big Data open enterprise systems . However, most likely they are immature no more than the average open Big Data system - but this is a completely different story. ClickHouse, Druid and Pinot lack some obvious optimizations and functionality, and they are full of bugs (I’m not 100% sure about ClickHouse and Pinot, but I don’t see any reasons why they would be better than Druid in this regard).
This brings us to the next important section.
I regularly see on the network how some conduct comparisons of big data systems: they take a set of their data, in some way “feed” it to the estimated system, and then immediately try to measure performance — how much memory or disk space was used and how fast requests. Moreover, the understanding of how the systems they test the system from is absent. Then, using only such specific performance data — sometimes together with the functionality they need and which the system currently has — they ultimately make their choice or, even worse, choose to write their own “best” system with zero
This approach seems to me wrong, at least it does not apply to open OLAP-systems for Big Data. The task of creating a Bid Data OLAP system that could work effectively in most use cases and would contain all the necessary functions is so great that I estimate its implementation at least 100 man-years .
Today, ClickHouse, Druid and Pinot are optimized only for specific use cases that are required by their developer - and for the most part contain only those functions that the developers themselves need. I can guarantee that your case will necessarily “rest on” those bottlenecks that the developers of the OLAP-systems under consideration have not yet encountered - or in those places that they are not interested in.
Not to mention the fact that the above-mentioned approach “to drop data into a system that you don’t know anything about and then measure its effectiveness” is very likely to give a distorted result due to serious “narrow” places that could actually be corrected by simply changing the configuration , data schema, or other query construction.
One such example, well illustrating the problem described above, is Marek Vavrush’s post about choosing between ClickHouse and Druid at Cloudflare . They needed 4 ClickHouse servers (which eventually became 9), and they estimated that they would need “hundreds of nodes” to deploy a similar installation of Druid. Let Marek admit that the comparison is dishonest , because Druid lacks "sorting by primary key", he may not even realize that it is possible to achieve approximately the same effect in Druid simply by setting the correct measurement order in the " ingestion spec " and making simple preparations Data: trim the value of the
However, I will not argue with their final decision to choose ClickHouse, since on a scale of about 10 nodes and for their needs ClickHouse also seems to me a better choice than Druid. But their conclusion that ClickHouse is at least an order of magnitude more efficient (by the standards of infrastructure costs) than Druid is a serious misconception. In fact, among the systems we are considering today, Druid offers the best opportunity for really cheap installations (see the section “Levels of Druid request processing nodes” below).
Due to their fundamental architectural similarities, ClickHouse, Druid and Pinot have about the same “limit” of efficiency and performance optimization. There is no “magic pill” that would allow any of these systems to be faster than the rest. Do not allow yourself to be confused by the fact that in their current state, the systems show themselves very differently in different benchmarks.
Suppose Druid does not support “sorting by primary key” as well as ClickHouse does — and ClickHouse, in turn, does not support “inverted indices” as well as Druid, which gives these systems advantages with a particular load. Missed optimization can be implemented in the selected system with the help of not so much of their efforts , if you have the intention and opportunity to decide on such a step.
Other information about developing systems that you should take into account:
The Druid and Pinot architectures are almost identical to each other, while ClickHouse stands slightly apart. Therefore, we first compare ClickHouse with the “generalized” Druid / Pinot architecture, and then discuss the minor differences between Druid and Pinot.
In Druid and Pinot, all the data in each "table" (no matter how it was called in the terminology of these systems) is divided into the specified number of parts. According to the time axis, data is usually divided at a specified interval. These pieces of data are then “sealed” individually into autonomous entities, called “segments”. Each segment includes table metadata, columnar compressed data and indexes.
Segments are stored in the “deep storage” storage file system (for example, HDFS) and can be loaded onto query processing nodes, but the latter are not responsible for the stability of the segments, so query processing nodes can be replaced relatively freely. Segments are not tied tightly to specific nodes and can be loaded on those or other nodes. A dedicated dedicated server (called a “coordinator” in Druid and a “controller” in Pinot, but I’ll refer to it as a “master” below) is responsible for assigning segments to nodes, and moving segments between nodes, if necessary.
This does not contradict what I noted above, all three systems have a static distribution of data between nodes, since the loading of segments and their movement into Druid - and as I understand it in Pinot - are expensive operations and therefore are not performed for each individual queue, but occur usually every few minutes / hours / days.
Segment metadata is stored in ZooKeeper - directly in the case of Druid, and using the Helix framework at Pinot. In Druid, metadata is also stored in the SQL database, more about this in the section “Differences between Druid and Pinot”.
There are no “segments” in ClickHouse that contain data falling within specific time ranges. There is no “deep storage” for the data, the nodes in the ClickHouse cluster are also responsible for processing requests, and the constancy / stability of the data stored on them. So you do not need HDFS or cloud storage like Amazon S3.
ClickHouse has partitioned tables consisting of the specified node set. There is no “central authority” or metadata server. All nodes between which a table is divided contain complete, identical copies of the metadata, including the addresses of all the other nodes where sections of this table are stored.
The partitioned table metadata includes “weights” of nodes for distributing freshly written data — for example, 40% of the data should go to node A, 30% to node B, and 30% to C. Usually, the distribution should occur evenly, “peregos”, as in this For example, it is required only when a new node is added to a partitioned table and you need to quickly fill it with some data. Updates to these "weights" must be performed manually by the administrators of the ClickHouse cluster, or by an automated system built on top of ClickHouse.
The data management approach in ClickHouse is simpler than in Druid and Pinot: no “deep storage” is required, just one type of node, no dedicated server is needed to manage the data. But the ClickHouse approach leads to some difficulties when any data table grows so large that it requires splitting between a dozen or more nodes: the query gain becomes as large as the partitioning factor — even for queries that cover a small data interval:
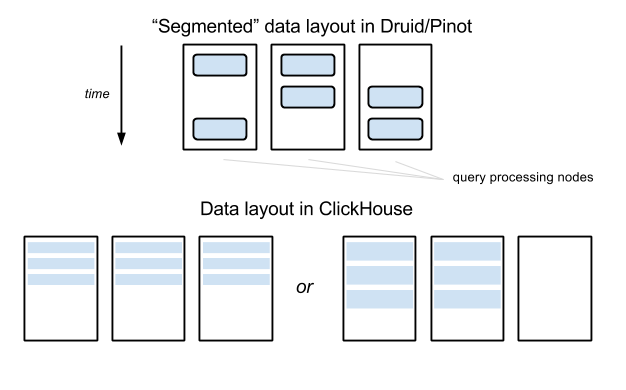
Compromise of data distribution in ClickHouse
In the example shown in the image above, these tables are distributed between the three nodes in Druid / Pinot, but a query over a small data interval usually affects only two of them (until the interval crosses the border interval of the segment). In ClickHouse, any queries will be forced to touch three nodes - if the table is segmented between three nodes. In this example, the difference does not look so significant, but imagine what happens if the number of nodes reaches 100 — while the segmentation factor can still be, for example, 10 in Druid / Pinot.
To mitigate this problem, the largest ClickHouse cluster in Yandex, consisting of hundreds of nodes, is in fact divided into many “sub-clusters” with several dozens of nodes each. The ClickHouse cluster is used to work with website analytics, and each data point has a “website ID” dimension. There is a tight binding of each site ID to a specific sub-cluster, where all the data for this site ID goes. On top of the ClickHouse cluster, there is a business logic layer that manages this data separation during data acquisition and query execution. Fortunately, in their usage scenarios, very few requests affect several site identifiers, and similar requests are not from service users, so they do not have a hard link to real time according to the service level agreement.
Another disadvantage of the ClickHouse approach is that when the cluster grows very quickly, the data cannot be rebalanced automatically without the participation of a person who manually changes the "weights" of nodes in the table being split.
Data management with “easier to imagine” segments - this concept fits well with our cognitive abilities. The segments themselves can be moved between nodes relatively simply. This two reasons allowed Druid to implement the “ leveling ” of the nodes involved in processing requests: old data is automatically transferred to servers with relatively large disks, but less memory and CPU, which can significantly reduce the cost of a large Druid work cluster by slowing down requests to more old data.
This feature allows Metamarkets to save hundreds of thousands of dollars in Druid infrastructure costs each month - as opposed to the alternative if a “flat” cluster were used.
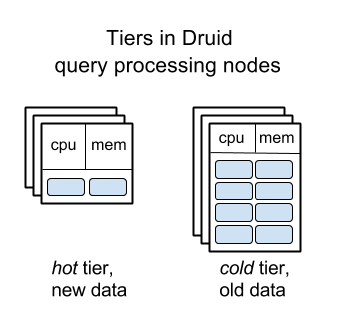
Druid query processing node levels
As far as I know, ClickHouse and Pinot do not yet have similar functionality - it is assumed that all nodes in their clusters are the same.
Due to the fact that the architecture of Pinot is very similar to the architecture of Druid, it seems to me that it will not be too difficult to add a similar function to Pinot. It will be harder in the case of ClickHouse, since using the concept of “segments” is extremely useful for implementing this function, but it is still possible.
The unit of replication in Druid and Pinot is a single segment. Segments are replicated at the deep storage level (for example, in three replicas on HDFS, or using blob storage in Amazon S3), and at the request processing level: usually in Druid and Pinot, each segment is loaded into two different nodes . A master server monitors replication levels for each segment and loads a segment to a server if the replication factor falls below a given level (for example, if any of the nodes stops responding).
The replication unit in ClickHouse is a section of the table on the server (for example, all data from any table stored on the server). Similar to sectioning, replication in ClickHouse is “static and specific” rather than “cloud-style”: several servers know that they are replicas of each other (for some particular table; in the case of another table, the replication configuration may differ). Replication provides both persistence and availability of queries. When a disk is damaged on one node, the data is not lost, since it is also stored on another node. When a node is temporarily unavailable, requests can be redirected to the replica.
In the largest ClickHouse cluster in Yandex, there are two identical sets of nodes in different data centers, and they are paired. In each pair, the nodes are replicas of each other (the replication factor of two is used), and they are located in different data centers.
ClickHouse relies on ZooKeeper to manage replication - so if you don’t need replication, then you don’t need ZooKeeper either. This means that ZooKeeper is not required for ClickHouse deployed on a single node.
In Druid and Pinot, query processing nodes specialize in loading segments and serve requests for data in segments; they are not engaged in the accumulation of new data and the production of new segments.
When a table can be updated with a delay of an hour or more, the segments are created using batch processing engines — for example, Hadoop or Spark. Both Druid and Pinot have first-class Hadoop support out of the box. There is a third-party plugin to support indexing Druid in Spark , but at the moment it is not officially supported. As far as I know, there is no such level of Spark support in Pinot yet, that is, you should be ready to deal with Pinot interfaces and code, and then write your own code in Java / Scala yourself, even if this should not be too difficult. (However, since the publication of the original article, Spark’s support for Pinot has been contributed by the contributor ).
When the table has to be updated in real time, the idea of real-time nodes comes to the rescue, which do three things: it receives new data from Kafka (Druid also supports other sources), serves requests with recent data, creates segments in the background and then writes them in the deep repository.
The fact that ClickHouse does not need to prepare "segments" that contain all the data and fall into specified time intervals allows you to build a simpler data absorption architecture. ClickHouse does not require a batch processing engine like Hadoop or real-time nodes. The usual ClickHouse nodes — the same ones that handle data storage and serve requests to them — accept packet data records directly.
If the table is divided into segments, the node that receives the packet entry (for example, 10k rows) distributes the data according to "weights" (see the section below). Lines are written in one packet, which forms a small "set". The set is immediately converted to column format. Each ClickHouse node runs a background process that combines rowsets into even larger sets. The ClickHouse documentation is strongly tied to the principle known as “MergeTree” and emphasizes the similarity of its work with the LSM tree , although I am slightly confused because the data is not organized into trees - they lie in a flat columnar format.
Data absorption in Druid and Pinot is “heavy”: it consists of several different services, and managing them is hard work.
Data acquisition in ClickHouse is much simpler (which is compensated for by the complexity of managing “historical” data — that is, not real-time data), but here there is one thing: you should be able to collect data in packets before ClickHouse itself. Automatic acquisition and batch data collection from Kafka is available out of the box , but if you use another source of data in real time (here everything is meant, anything between the query infrastructure, an alternative to Kafka, and streaming processing engines, up to various HTTP-endpoint), then you have to create an intermediate packet collection service, or enter the code directly into ClickHouse.
Druid and Pinot have a separate layer of nodes called “ brokers & kaquo;” that accept all requests to the system. They determine which “historical” ( containing non-real-time data ) query processing nodes should be sent subqueries based on the mapping of segments to nodes in which segments are loaded. Brokers store mapping information in memory. Broker nodes send further subqueries to query processing nodes, and when the results of these subqueries are returned, the broker combines them and returns the final combined result to the user.
I do not venture to suggest why when designing Druid and Pinot it was decided to introduce another type of nodes. , , , , . — . , Druid Pinot «» .
ClickHouse « » . , «» ClickHouse, , , - Druid Pinot. , , « » ClickHouse. , .
( ClickHouse, - Druid Pinot) , - , ClickHouse Pinot : , . Druid : , .
«» Druid Pinot ClickHouse . , , ( ) (, ), .
ClickHouse RDMBS, , PostgreSQL. , ClickHouse . — , 100 CPU 1 TB , , ClickHouse Druid Pinot , «», « », «». , ClickHouse InfluxDB, Druid Pinot.
Druid and Pinot Big Data HBase. , ZooKeper, ( , HDFS), , , . , ClickHouse, Druid Pinot . , , , .. « ».
-, . , . . , : , .
: , (), . , , , , Druid Pinot, ClickHouse. , Druid Pinot , ClickHouse, .
, Druid Pinot . , , , . , , , , .
Druid Pinot , , — -. , , «» «» — , .
- Druid ( Pinot) , , . ZooKeeper. , Druid SQL , Druid. , , :
SQL, , , - SQL. Druid MySQL PostgreSQL, Microsoft SQL Server. , Druid , RDBMS — , Amazon RDS.
Druid, Curator ZooKeeper, Pinot Helix .
, , Pinot . Helix , Druid, , , .
, Helix Pinot « ». Helix, , Pinot, ZooKeeper .
Druid Pinot — , , .
Kafka - , Pinot , , , - , .
« predicate pushdown » .
Druid , Hadoop, , . Druid « » .
Druid , «»:
Pinot LinkedIn , , , . « » HDFS Amazon S3, Kafka. - , , Pinot. , , Uber Slack Pinot.
, Pinot Druid:
, Druid. , Pinot , Druid, , . : Pinot ( Druid) ( Zstd) Gorilla .
Uber count (*) Druid Pinot [ 1 , 2 ], Druid , O(1) . « », .
,
Pinot , , . Druid ; , , , . Metamarkets 30–40% . , , - — .
, LinkedIn Pinot, , , , .
« », - , , Pinot - .
Druid .
. Druid , «» « CPU, RAM / » , .
, Pinot .
ClickHouse, Druid Pinot , Big Data- Impala, Presto, Spark, , , InfluxDB.
, ClickHouse, Druid Pinot « ». , . ( ) - .
, ClickHouse Druid Pinot — Druid Pinot , .
ClickHouse «» PostgreSQL. ClickHouse . ( 1 TB , 100 CPU), ClickHouse , Druid Pinot — — , ClickHouse . , InfluxDB Prometheus, Druid Pinot.
Druid Pinot Big Data Hadoop. «» ( 500 ), ClickHouse SRE. , Druid Pinot , , ClickHouse.
Druid Pinot , Pinot Helix ZooKeeper, Druid ZooKeeper. , Druid - SQL- . , Pinot , Druid.
Spoiler
| Clickhouse | Druid or Pinot |
|---|---|
| There are C ++ experts in the organization. | There are Java experts in the organization. |
| Small cluster | Large cluster |
| Some tables | Many tables |
| One data set | Multiple unrelated datasets |
| Tables and data are permanently in cluster | Tables and datasets periodically appear in the cluster and are removed from it |
| The size of the tables (and the intensity of queries to them) remains stable over time. | Tables grow and shrink significantly |
| Uniform requests (their type, size, distribution by time of day, etc.) | Heterogeneous queries |
| There is a dimension in the data by which they can be segmented, and there are almost no queries that affect data located in several segments. | There is no such measurement, and queries often affect data located throughout the cluster. |
| The cloud is not used, the cluster must be deployed on a specific physical server configuration | Cluster deployed in the cloud |
| No existing Hadoop or Spark clusters | Hadoop or Spark clusters already exist and can be used |
Information sources
Details of the implementation of ClickHouse became known to me from Alexey Zatelepin , one of the key developers of the project . The documentation available in English is rather poor - the last four sections of this page of documentation are the best source of information.
')
I myself participate in the development of Druid , but I do not have a personal interest in this system - to be honest, most likely in the near future I will cease to engage in its development. Therefore, readers can count on the absence of any bias.
Everything that I will write about Pinot further is based on the Architecture page in the Pinot wiki , as well as on other wiki pages in the Design Documentation section. The last time they were updated in June 2017 - more than six months ago.
The reviewers of the original article were Alexey Zatelepin and Vitaliy Lyudvichenko (developers of ClickHouse), Jean Merlino (most active developer of Druid), Kishore Gopalakrishna (architect Pinot) and Jean-Francois Im (developer of Pinot). We join the thanks of the author and believe that this greatly increases the credibility of the article.
Warning : the article is quite large, so you may want to limit yourself to reading the section “Conclusion” at the end.
Similarities between systems
Related data and calculations
At the fundamental level, ClickHouse, Druid and Pinot are similar because they store data and perform query processing on the same nodes, moving away from the “disconnected” BigQuery architecture. Recently, I have already described several hereditary problems with related architecture in the case of Druid [ 1 , 2 ]. There is currently no open equivalent for BigQuery (with the exception of, perhaps, Drill ?). Possible approaches to building such open systems are covered in another article on my blog .
Differences from Big Data SQL Systems: Indexes and Static Data Distribution
The systems reviewed in this article perform queries faster than Big Data systems from the SQL-on-Hadoop class family: Hive, Impala, Presto, and Spark, even when the latter gain access to data stored in a column format — for example, Parquet or Kudu. This is because in ClickHouse, Druid and Pinot:
- There is its own format for storing data with indexes , and they are tightly integrated with query processing engines. Systems of the SQL-on-Hadoop class can usually be called agnostic about the data formats and therefore they are less “intrusive” in Big Data backends.
- Data is distributed relatively “statically” between nodes, and this can be used for distributed query execution. The other side of the coin is that ClickHouse, Druid and Pinot do not support queries that require moving a large amount of data between nodes — for example, join between two large tables.
No point updates and deletes
Being on the other side of the database spectrum, ClickHouse, Druid and Pinot do not support point updates and deletes , as opposed to column systems like Kudu, InfluxDB and Vertica (?). This gives ClickHouse, Druid and Pinot the ability to produce more efficient column compression and more aggressive indices, which means greater resource utilization and faster query execution.
The developers of ClickHouse in Yandex plan to start supporting updates and deletions in the future , but I'm not sure if these will be “real” point requests or updates / deletions of data ranges.
Big Data Absorption
All three systems support streaming data absorption from Kafka. Druid and Pinot support streaming Lambda-style streaming and packet acquisition of the same data. ClickHouse supports batch inserts directly, so it does not need a separate batch absorption system similar to that used in Druid and Pinot. If you are interested in the details, you can find them further.
Tested on a large scale
All three systems are tested for performance on a large scale: ClickHouse cluster works in Yandex.Metrica , consisting of about ten thousand CPU cores. Metamarkets uses a similarly sized Druid cluster . One Pinot cluster on LinkedIn includes “ thousands of machines .”
Immaturity
All systems considered in the article are immature by the standards of Big Data open enterprise systems . However, most likely they are immature no more than the average open Big Data system - but this is a completely different story. ClickHouse, Druid and Pinot lack some obvious optimizations and functionality, and they are full of bugs (I’m not 100% sure about ClickHouse and Pinot, but I don’t see any reasons why they would be better than Druid in this regard).
This brings us to the next important section.
Pro performance comparison and system selection
I regularly see on the network how some conduct comparisons of big data systems: they take a set of their data, in some way “feed” it to the estimated system, and then immediately try to measure performance — how much memory or disk space was used and how fast requests. Moreover, the understanding of how the systems they test the system from is absent. Then, using only such specific performance data — sometimes together with the functionality they need and which the system currently has — they ultimately make their choice or, even worse, choose to write their own “best” system with zero
This approach seems to me wrong, at least it does not apply to open OLAP-systems for Big Data. The task of creating a Bid Data OLAP system that could work effectively in most use cases and would contain all the necessary functions is so great that I estimate its implementation at least 100 man-years .
Today, ClickHouse, Druid and Pinot are optimized only for specific use cases that are required by their developer - and for the most part contain only those functions that the developers themselves need. I can guarantee that your case will necessarily “rest on” those bottlenecks that the developers of the OLAP-systems under consideration have not yet encountered - or in those places that they are not interested in.
Not to mention the fact that the above-mentioned approach “to drop data into a system that you don’t know anything about and then measure its effectiveness” is very likely to give a distorted result due to serious “narrow” places that could actually be corrected by simply changing the configuration , data schema, or other query construction.
CloudFlare: ClickHouse vs. Druid
One such example, well illustrating the problem described above, is Marek Vavrush’s post about choosing between ClickHouse and Druid at Cloudflare . They needed 4 ClickHouse servers (which eventually became 9), and they estimated that they would need “hundreds of nodes” to deploy a similar installation of Druid. Let Marek admit that the comparison is dishonest , because Druid lacks "sorting by primary key", he may not even realize that it is possible to achieve approximately the same effect in Druid simply by setting the correct measurement order in the " ingestion spec " and making simple preparations Data: trim the value of the
__time column in Druid to some kind of coarse detail (for example, one hour) and optionally add another “long-type” precise_time column if some queries require a more precise timeframe. Yes, this is a hack, but, as we just figured out, in Druid, you can sort the data by any dimension before __time , and it's easy enough to implement.However, I will not argue with their final decision to choose ClickHouse, since on a scale of about 10 nodes and for their needs ClickHouse also seems to me a better choice than Druid. But their conclusion that ClickHouse is at least an order of magnitude more efficient (by the standards of infrastructure costs) than Druid is a serious misconception. In fact, among the systems we are considering today, Druid offers the best opportunity for really cheap installations (see the section “Levels of Druid request processing nodes” below).
When you choose the OLAP Big Data system, do not compare how well they are now suitable for your case. Now they are all suboptimal. Instead, compare how quickly your company can make these systems move in the direction that you need.
Due to their fundamental architectural similarities, ClickHouse, Druid and Pinot have about the same “limit” of efficiency and performance optimization. There is no “magic pill” that would allow any of these systems to be faster than the rest. Do not allow yourself to be confused by the fact that in their current state, the systems show themselves very differently in different benchmarks.
Suppose Druid does not support “sorting by primary key” as well as ClickHouse does — and ClickHouse, in turn, does not support “inverted indices” as well as Druid, which gives these systems advantages with a particular load. Missed optimization can be implemented in the selected system with the help of not so much of their efforts , if you have the intention and opportunity to decide on such a step.
- Your organization should have engineers who can read, understand, and modify the source code of the selected system, and they should also have time for that. Note that ClickHouse is written in C ++, and Druid and Pinot are written in Java.
- Or your organization must sign a contract with a company that supports the chosen system. These will be Altinity for ClickHouse, Imply and Hortonworks for Druid. For Pinot, there are no such companies at the moment.
Other information about developing systems that you should take into account:
- The authors of ClickHouse, working in Yandex, argue that they spend 50% of their time on creating the functionality that they need inside the company, and the other 50% go to the functions that most “community votes” gain. However, for you to benefit from this fact, it is required that the functions that you need are the most needed by the ClickHouse community .
- Imply's Druid developers are motivated to work on widely used features, as this will allow them to maximize their business reach in the future.
- The development process of Druid strongly resembles the Apache model , when software has been developed by several companies for several years, each of which has rather peculiar and different priorities, and there is no leading company among them. ClickHouse and Pinot are still far from this stage, since only Yandex and Linkedin, respectively, are engaged in them. The third-party contribution to the development of Druid has a minimal chance of being rejected due to the fact that it disagrees with the vision of the main developer - after all , there is no “main” developer company in Druid .
- Druid supports the “Developer API”, which allows you to add your own column types, aggregation mechanisms, possible options for “deep storage”, etc., and you can keep all this in a code base separate from the Druid kernel itself. This API is documented by the developers of Druid, and they monitor its compatibility with previous versions. However, it is not enough “adult”, and it breaks down with almost every new release of Druid. As far as I know, similar APIs are not supported in ClickHouse and Pinot.
- According to Github, the largest number of people working on Pinot - it seems that only last year at least 10 person-years were invested in Pinot. For ClickHouse, this figure is about 6 person-years, and for Druid - 7. In theory, this should mean that Pinot is improving faster than all the other systems we are considering.
The Druid and Pinot architectures are almost identical to each other, while ClickHouse stands slightly apart. Therefore, we first compare ClickHouse with the “generalized” Druid / Pinot architecture, and then discuss the minor differences between Druid and Pinot.
Differences between ClickHouse and Druid / Pinot
Data Management: Druid and Pinot
In Druid and Pinot, all the data in each "table" (no matter how it was called in the terminology of these systems) is divided into the specified number of parts. According to the time axis, data is usually divided at a specified interval. These pieces of data are then “sealed” individually into autonomous entities, called “segments”. Each segment includes table metadata, columnar compressed data and indexes.
Segments are stored in the “deep storage” storage file system (for example, HDFS) and can be loaded onto query processing nodes, but the latter are not responsible for the stability of the segments, so query processing nodes can be replaced relatively freely. Segments are not tied tightly to specific nodes and can be loaded on those or other nodes. A dedicated dedicated server (called a “coordinator” in Druid and a “controller” in Pinot, but I’ll refer to it as a “master” below) is responsible for assigning segments to nodes, and moving segments between nodes, if necessary.
This does not contradict what I noted above, all three systems have a static distribution of data between nodes, since the loading of segments and their movement into Druid - and as I understand it in Pinot - are expensive operations and therefore are not performed for each individual queue, but occur usually every few minutes / hours / days.
Segment metadata is stored in ZooKeeper - directly in the case of Druid, and using the Helix framework at Pinot. In Druid, metadata is also stored in the SQL database, more about this in the section “Differences between Druid and Pinot”.
Data Management: ClickHouse
There are no “segments” in ClickHouse that contain data falling within specific time ranges. There is no “deep storage” for the data, the nodes in the ClickHouse cluster are also responsible for processing requests, and the constancy / stability of the data stored on them. So you do not need HDFS or cloud storage like Amazon S3.
ClickHouse has partitioned tables consisting of the specified node set. There is no “central authority” or metadata server. All nodes between which a table is divided contain complete, identical copies of the metadata, including the addresses of all the other nodes where sections of this table are stored.
The partitioned table metadata includes “weights” of nodes for distributing freshly written data — for example, 40% of the data should go to node A, 30% to node B, and 30% to C. Usually, the distribution should occur evenly, “peregos”, as in this For example, it is required only when a new node is added to a partitioned table and you need to quickly fill it with some data. Updates to these "weights" must be performed manually by the administrators of the ClickHouse cluster, or by an automated system built on top of ClickHouse.
Data Management: Comparison
The data management approach in ClickHouse is simpler than in Druid and Pinot: no “deep storage” is required, just one type of node, no dedicated server is needed to manage the data. But the ClickHouse approach leads to some difficulties when any data table grows so large that it requires splitting between a dozen or more nodes: the query gain becomes as large as the partitioning factor — even for queries that cover a small data interval:
Compromise of data distribution in ClickHouse
In the example shown in the image above, these tables are distributed between the three nodes in Druid / Pinot, but a query over a small data interval usually affects only two of them (until the interval crosses the border interval of the segment). In ClickHouse, any queries will be forced to touch three nodes - if the table is segmented between three nodes. In this example, the difference does not look so significant, but imagine what happens if the number of nodes reaches 100 — while the segmentation factor can still be, for example, 10 in Druid / Pinot.
To mitigate this problem, the largest ClickHouse cluster in Yandex, consisting of hundreds of nodes, is in fact divided into many “sub-clusters” with several dozens of nodes each. The ClickHouse cluster is used to work with website analytics, and each data point has a “website ID” dimension. There is a tight binding of each site ID to a specific sub-cluster, where all the data for this site ID goes. On top of the ClickHouse cluster, there is a business logic layer that manages this data separation during data acquisition and query execution. Fortunately, in their usage scenarios, very few requests affect several site identifiers, and similar requests are not from service users, so they do not have a hard link to real time according to the service level agreement.
Another disadvantage of the ClickHouse approach is that when the cluster grows very quickly, the data cannot be rebalanced automatically without the participation of a person who manually changes the "weights" of nodes in the table being split.
Druid query processing node levels
Data management with “easier to imagine” segments - this concept fits well with our cognitive abilities. The segments themselves can be moved between nodes relatively simply. This two reasons allowed Druid to implement the “ leveling ” of the nodes involved in processing requests: old data is automatically transferred to servers with relatively large disks, but less memory and CPU, which can significantly reduce the cost of a large Druid work cluster by slowing down requests to more old data.
This feature allows Metamarkets to save hundreds of thousands of dollars in Druid infrastructure costs each month - as opposed to the alternative if a “flat” cluster were used.
Druid query processing node levels
As far as I know, ClickHouse and Pinot do not yet have similar functionality - it is assumed that all nodes in their clusters are the same.
Due to the fact that the architecture of Pinot is very similar to the architecture of Druid, it seems to me that it will not be too difficult to add a similar function to Pinot. It will be harder in the case of ClickHouse, since using the concept of “segments” is extremely useful for implementing this function, but it is still possible.
Data Replication: Druid and Pinot
The unit of replication in Druid and Pinot is a single segment. Segments are replicated at the deep storage level (for example, in three replicas on HDFS, or using blob storage in Amazon S3), and at the request processing level: usually in Druid and Pinot, each segment is loaded into two different nodes . A master server monitors replication levels for each segment and loads a segment to a server if the replication factor falls below a given level (for example, if any of the nodes stops responding).
Data Replication: ClickHouse
The replication unit in ClickHouse is a section of the table on the server (for example, all data from any table stored on the server). Similar to sectioning, replication in ClickHouse is “static and specific” rather than “cloud-style”: several servers know that they are replicas of each other (for some particular table; in the case of another table, the replication configuration may differ). Replication provides both persistence and availability of queries. When a disk is damaged on one node, the data is not lost, since it is also stored on another node. When a node is temporarily unavailable, requests can be redirected to the replica.
In the largest ClickHouse cluster in Yandex, there are two identical sets of nodes in different data centers, and they are paired. In each pair, the nodes are replicas of each other (the replication factor of two is used), and they are located in different data centers.
ClickHouse relies on ZooKeeper to manage replication - so if you don’t need replication, then you don’t need ZooKeeper either. This means that ZooKeeper is not required for ClickHouse deployed on a single node.
Data Acquisition: Druid and Pinot
In Druid and Pinot, query processing nodes specialize in loading segments and serve requests for data in segments; they are not engaged in the accumulation of new data and the production of new segments.
When a table can be updated with a delay of an hour or more, the segments are created using batch processing engines — for example, Hadoop or Spark. Both Druid and Pinot have first-class Hadoop support out of the box. There is a third-party plugin to support indexing Druid in Spark , but at the moment it is not officially supported. As far as I know, there is no such level of Spark support in Pinot yet, that is, you should be ready to deal with Pinot interfaces and code, and then write your own code in Java / Scala yourself, even if this should not be too difficult. (However, since the publication of the original article, Spark’s support for Pinot has been contributed by the contributor ).
When the table has to be updated in real time, the idea of real-time nodes comes to the rescue, which do three things: it receives new data from Kafka (Druid also supports other sources), serves requests with recent data, creates segments in the background and then writes them in the deep repository.
Data Absorption: ClickHouse
The fact that ClickHouse does not need to prepare "segments" that contain all the data and fall into specified time intervals allows you to build a simpler data absorption architecture. ClickHouse does not require a batch processing engine like Hadoop or real-time nodes. The usual ClickHouse nodes — the same ones that handle data storage and serve requests to them — accept packet data records directly.
If the table is divided into segments, the node that receives the packet entry (for example, 10k rows) distributes the data according to "weights" (see the section below). Lines are written in one packet, which forms a small "set". The set is immediately converted to column format. Each ClickHouse node runs a background process that combines rowsets into even larger sets. The ClickHouse documentation is strongly tied to the principle known as “MergeTree” and emphasizes the similarity of its work with the LSM tree , although I am slightly confused because the data is not organized into trees - they lie in a flat columnar format.
Data Absorption: Comparison
Data absorption in Druid and Pinot is “heavy”: it consists of several different services, and managing them is hard work.
Data acquisition in ClickHouse is much simpler (which is compensated for by the complexity of managing “historical” data — that is, not real-time data), but here there is one thing: you should be able to collect data in packets before ClickHouse itself. Automatic acquisition and batch data collection from Kafka is available out of the box , but if you use another source of data in real time (here everything is meant, anything between the query infrastructure, an alternative to Kafka, and streaming processing engines, up to various HTTP-endpoint), then you have to create an intermediate packet collection service, or enter the code directly into ClickHouse.
Request execution
Druid and Pinot have a separate layer of nodes called “ brokers & kaquo;” that accept all requests to the system. They determine which “historical” ( containing non-real-time data ) query processing nodes should be sent subqueries based on the mapping of segments to nodes in which segments are loaded. Brokers store mapping information in memory. Broker nodes send further subqueries to query processing nodes, and when the results of these subqueries are returned, the broker combines them and returns the final combined result to the user.
I do not venture to suggest why when designing Druid and Pinot it was decided to introduce another type of nodes. , , , , . — . , Druid Pinot «» .
ClickHouse « » . , «» ClickHouse, , , - Druid Pinot. , , « » ClickHouse. , .
( ClickHouse, - Druid Pinot) , - , ClickHouse Pinot : , . Druid : , .
ClickHouse vs. Druid Pinot:
«» Druid Pinot ClickHouse . , , ( ) (, ), .
ClickHouse RDMBS, , PostgreSQL. , ClickHouse . — , 100 CPU 1 TB , , ClickHouse Druid Pinot , «», « », «». , ClickHouse InfluxDB, Druid Pinot.
Druid and Pinot Big Data HBase. , ZooKeper, ( , HDFS), , , . , ClickHouse, Druid Pinot . , , , .. « ».
-, . , . . , : , .
| ClickHouse | Druid Pinot |
|---|---|
| C++ | Java |
| ( ) | |
| ( , , ..) | |
| , , , , | , , |
| , | |
| Hadoop Spark | Hadoop Spark |
: , (), . , , , , Druid Pinot, ClickHouse. , Druid Pinot , ClickHouse, .
Druid Pinot
, Druid Pinot . , , , . , , , , .
Druid Pinot , , — -. , , «» «» — , .
Druid
- Druid ( Pinot) , , . ZooKeeper. , Druid SQL , Druid. , , :
- ZooKeeper . , , , ZooKeeper. , , , , .. — SQL .
- , ( — ClickHouse, Druid, Pinot), ZooKeeper, « » SQL. , «» , .
- , Druid ZooKeeper . ZooKeeper : , (, ). Consul . HTTP- , , ZooKeeper «» SQL.
SQL, , , - SQL. Druid MySQL PostgreSQL, Microsoft SQL Server. , Druid , RDBMS — , Amazon RDS.
Pinot
Druid, Curator ZooKeeper, Pinot Helix .
, , Pinot . Helix , Druid, , , .
, Helix Pinot « ». Helix, , Pinot, ZooKeeper .
Druid Pinot — , , .
« » Pinot
Kafka - , Pinot , , , - , .
« predicate pushdown » .
Druid , Hadoop, , . Druid « » .
«» Druid Pinot
Druid , «»:
- HDFS, Cassandra, Amazon S3, Google Cloud Storage Azure Blob Storage .. « »;
- Kafka, r RabbitMQ, Samza, Flink, Spark, Storm, .. ( Tranquility ) ;
- Druid, Graphite, Ambari, StatsD, Kafka «» Druid ().
Pinot LinkedIn , , , . « » HDFS Amazon S3, Kafka. - , , Pinot. , , Uber Slack Pinot.
Pinot
, Pinot Druid:
- , Druid.
- . Druid , , . Druid Pinot, Uber , .
- .
- . Druid ( «CloudFlare: ClickHouse Druid»). , Pinot — Druid Pinot ( !), Uber.
- , , Pinot, Druid.
, Druid. , Pinot , Druid, , . : Pinot ( Druid) ( Zstd) Gorilla .
Uber count (*) Druid Pinot [ 1 , 2 ], Druid , O(1) . « », .
,
GROUP BY, Uber, Druid, .Druid ()
Pinot , , . Druid ; , , , . Metamarkets 30–40% . , , - — .
, LinkedIn Pinot, , , , .
Pinot
« », - , , Pinot - .
Druid .
Druid
. Druid , «» « CPU, RAM / » , .
, Pinot .
Conclusion
ClickHouse, Druid Pinot , Big Data- Impala, Presto, Spark, , , InfluxDB.
, ClickHouse, Druid Pinot « ». , . ( ) - .
— , , , .
, ClickHouse Druid Pinot — Druid Pinot , .
ClickHouse «» PostgreSQL. ClickHouse . ( 1 TB , 100 CPU), ClickHouse , Druid Pinot — — , ClickHouse . , InfluxDB Prometheus, Druid Pinot.
Druid Pinot Big Data Hadoop. «» ( 500 ), ClickHouse SRE. , Druid Pinot , , ClickHouse.
Druid Pinot , Pinot Helix ZooKeeper, Druid ZooKeeper. , Druid - SQL- . , Pinot , Druid.
, : ( ) . , , . ( 9 ) ++ : , , . , — , .
Source: https://habr.com/ru/post/351308/
All Articles