Personal recommendations in ivi: Hydra
In the ivi online cinema tens of thousands of pieces of content and the task of “choosing what to watch” becomes nontrivial.

We wrote about the recommendation system in ivi, which deals with the selection of content based on user interests (the internal name is Hydra ) here and here . Much time has passed and the project code has changed significantly: the offline part has moved to Spark, the online part has adapted to high loads, Hydra has started using another recommender model - all these changes will be covered in the article.
Back in 2014, Hydra was created as a Python application: the data for the recommender model was loaded by a separate script — the “offline part” —from external sources (Vertica, Mongo, Postgres). The script was preparing user-item matrix dimension , where m is the number of users in the training sample, and n is the size of the catalog (the number of unique content units), you can read more about item-based personal recommendations in articles by Sergey Nikolenko .
The history of viewing the user is a vector of dimension in which for each content with which the user interacted (looked, rated), there are units, the remaining elements are zero. Since each user interacts with dozens of content units, and the size of the directory is thousands of units, we get a sparse row vector in which there are a lot of zeros and the user-item matrix consists of such vectors. The online cinema ivi collects rich feedback from users - content views, ratings (on a ten-point scale), onboarding results (binary preferences “like - dislike”, here is a presentation with an example from Netflix ) - the model is trained on this data.
')
The classic memory-based algorithm was used to issue recommendations - Hydra “memorized” the training sample and stored a matrix of user views (and ratings) in memory. With the growth of the service audience in proportion to the growth and size of the matrix user-item. The architecture of the reference service at the time looked like this:
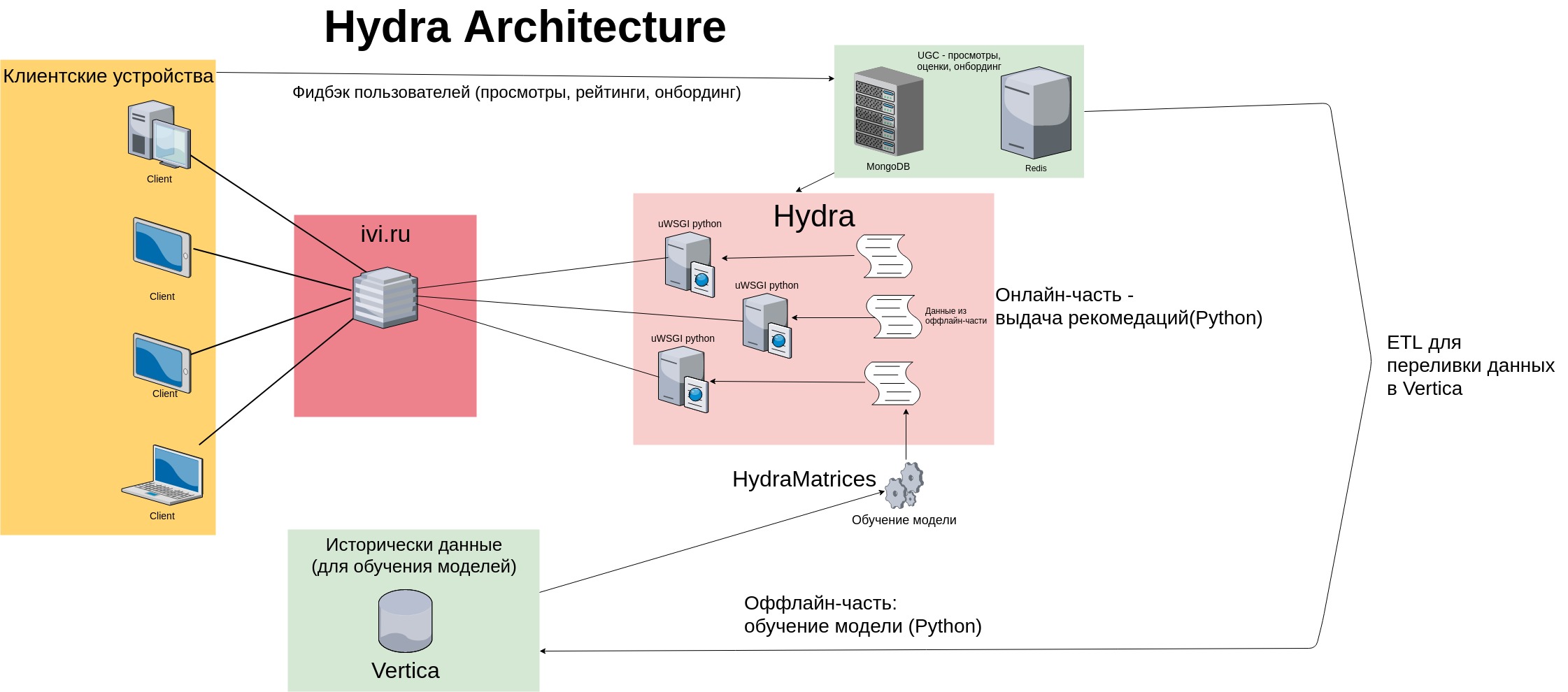
As can be seen in the diagram, feedback from users (views, content ratings, onboarding marks) is stored in fast key-value repositories (MongoDB and Redis) and in Vertica - column data repository. Data is vertically fed incrementally using special ETL procedures.
The offline part is launched daily by crown: it downloads data, trains the model, saves it as textual and binary files (sparse matrices, python-objects in the .pkl format). The online part generates recommendations based on the model and history of the user's targeted actions — views, ratings, content purchases (read user feedback from Redis / Mongo). Recommendations are issued using dozens of python processes running on each server (there are a total of 8 servers in the Hydra cluster).
This architecture gave rise to several problems:
The system in this form (with constant modifications and improvements) survived until February 2017. Time to download data in offline parts grew algorithm of the model remained unchanged. At the beginning of 2017, we decided to move from a memory-based reference model to a more recent ALS algorithm (on the Coursera there is a video about this model ).
In short, the algorithm tries to present our huge sparse user-item matrix. in the form of a product of two "dense" matrices: user matrices and content matrices:
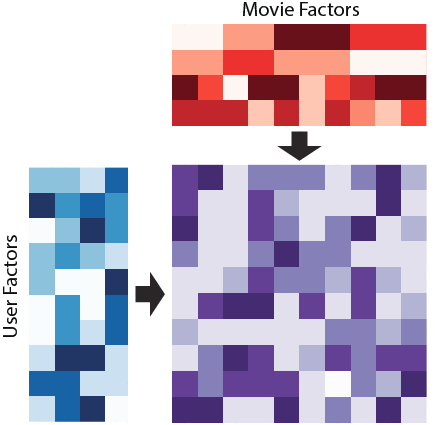
ALS allows you to train for each user. vector dimensions - so-called "Hidden factors" of the user. Each content unit matches vector the same dimension, "hidden factors" of content. Wherein , the dimension of the space of hidden factors is much smaller than the size of the directory, each user describes a dense vector of low dimension (usually ).
The product of the vector of the user by the vector of the content is the relevance of the content to the user: the higher it is, the more chances the film has to get to the issue. The ALS exhaust is ground in the business rules grinder, because besides the “show content that a user will like” task, the recommender system has a number of tasks related to content monetization, service positioning, etc. Business rules slightly distort the vector of recommendations - this fact must be taken into account, for example, when conducting an offline assessment of the model.
Much work has been done on redesigning the service, the results of which are as follows:

Hydra for the year has changed a lot both in architectural terms and in the algorithmic part. More details about these changes will be discussed in a series of articles.
We wrote about the recommendation system in ivi, which deals with the selection of content based on user interests (the internal name is Hydra ) here and here . Much time has passed and the project code has changed significantly: the offline part has moved to Spark, the online part has adapted to high loads, Hydra has started using another recommender model - all these changes will be covered in the article.
Hydra Architecture
Back in 2014, Hydra was created as a Python application: the data for the recommender model was loaded by a separate script — the “offline part” —from external sources (Vertica, Mongo, Postgres). The script was preparing user-item matrix dimension , where m is the number of users in the training sample, and n is the size of the catalog (the number of unique content units), you can read more about item-based personal recommendations in articles by Sergey Nikolenko .
The history of viewing the user is a vector of dimension in which for each content with which the user interacted (looked, rated), there are units, the remaining elements are zero. Since each user interacts with dozens of content units, and the size of the directory is thousands of units, we get a sparse row vector in which there are a lot of zeros and the user-item matrix consists of such vectors. The online cinema ivi collects rich feedback from users - content views, ratings (on a ten-point scale), onboarding results (binary preferences “like - dislike”, here is a presentation with an example from Netflix ) - the model is trained on this data.
')
The classic memory-based algorithm was used to issue recommendations - Hydra “memorized” the training sample and stored a matrix of user views (and ratings) in memory. With the growth of the service audience in proportion to the growth and size of the matrix user-item. The architecture of the reference service at the time looked like this:
Disadvantages of Hydra
As can be seen in the diagram, feedback from users (views, content ratings, onboarding marks) is stored in fast key-value repositories (MongoDB and Redis) and in Vertica - column data repository. Data is vertically fed incrementally using special ETL procedures.
The offline part is launched daily by crown: it downloads data, trains the model, saves it as textual and binary files (sparse matrices, python-objects in the .pkl format). The online part generates recommendations based on the model and history of the user's targeted actions — views, ratings, content purchases (read user feedback from Redis / Mongo). Recommendations are issued using dozens of python processes running on each server (there are a total of 8 servers in the Hydra cluster).
This architecture gave rise to several problems:
- Hydra is a bundle of python processes, each of which picks up its own set of files from the offline part into memory - this leads to the fact that memory consumption grows over time (the file size grows with the number of users), which makes it difficult to scale the system. In addition, when starting the service, each process must read files from the disk - this is slow;
- there are more and more users; data collection starts to take a lot of time;
- Hydra was a monolithic application: data preparation became more and more complex, it didn’t use the rest of ivi microservices - because of this it was necessary to develop various auxiliary scripts.
Hydra: revival
The system in this form (with constant modifications and improvements) survived until February 2017. Time to download data in offline parts grew algorithm of the model remained unchanged. At the beginning of 2017, we decided to move from a memory-based reference model to a more recent ALS algorithm (on the Coursera there is a video about this model ).
In short, the algorithm tries to present our huge sparse user-item matrix. in the form of a product of two "dense" matrices: user matrices and content matrices:
ALS allows you to train for each user. vector dimensions - so-called "Hidden factors" of the user. Each content unit matches vector the same dimension, "hidden factors" of content. Wherein , the dimension of the space of hidden factors is much smaller than the size of the directory, each user describes a dense vector of low dimension (usually ).
The product of the vector of the user by the vector of the content is the relevance of the content to the user: the higher it is, the more chances the film has to get to the issue. The ALS exhaust is ground in the business rules grinder, because besides the “show content that a user will like” task, the recommender system has a number of tasks related to content monetization, service positioning, etc. Business rules slightly distort the vector of recommendations - this fact must be taken into account, for example, when conducting an offline assessment of the model.
New architecture
Much work has been done on redesigning the service, the results of which are as follows:
- Data preparation for training models was transferred to Spark - instead of appeals to Vertica we read from Hadoop-repository Hive. Vertika is a very fast database, but with the growth of data volumes it takes a long time to transfer them over the network, and Spark allows you to perform computations distributed, on the nodes of the cluster. In addition, Spark implements an ALS model for implicit feedback (the model is trained on data about the duration of content viewing by the user);
- the data from the offline parts, which had previously been raised in memory of each process, moved to Redis. Now, instead of duplicating objects in memory, Hydra accesses the Redis-storage - we get one instance of data for all processes on the server, memory consumption has decreased by 2 times. Time to restart the service was reduced from half an hour to 6 minutes - wait until several dozen processes read the data from the files for a long time, and now the data is already in Redis, at the time of the restart Hydra just checks their availability
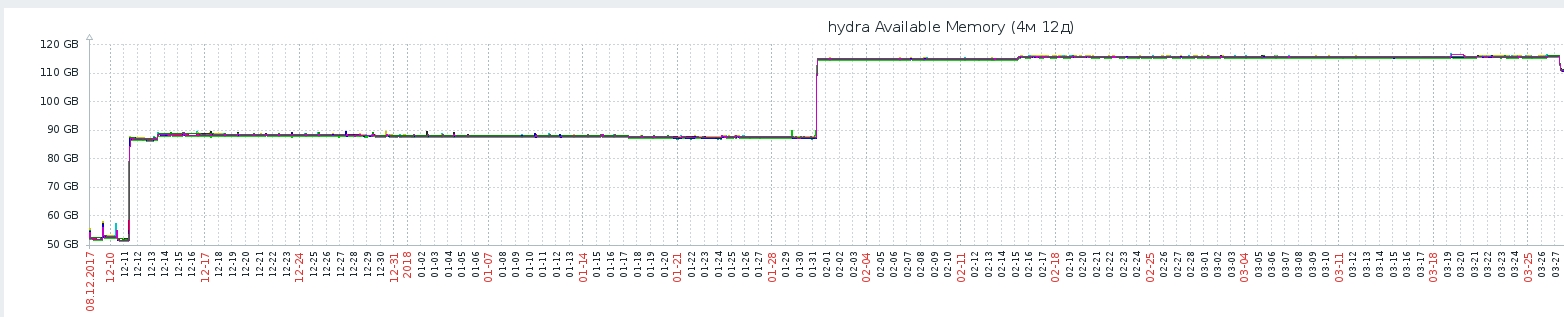
- Hydra recalculated the recommendations in response to each user’s transition between the application screens — even if the user didn’t perform targeted actions that could change his recommendations (looked at the content, rated it). To produce a huge amount of calculations turned out to be very expensive for processor resources. In the depths of the method of obtaining recommendations on the ALS model, we use a bit of linear algebra from numpy (for example, numpy.linalg.solve ), with each python process using several cores to read faster - this greatly loads the CPU. As can be seen in the picture, after the implementation of the recommendatory model, the ALS Response Time system increased with each passing day (this is due to the fact that the AB test of the new model captured all new users). To avoid linear dependence of the load on the number of users, the system of caching the vector of recommendations was developed: the cache was dropped (and the recommendations were recalculated) only after a new “target action” of the user: viewing or evaluation.

- For the formation of the vector of user recommendations began to use a hybrid model. Earlier in the business rules of the recommendatory system (and we have a lot of business rules) there was a so-called “Personalization boundary”: if the user has less than 5 views, the recommendations were top popular content, and after the 5th viewing, the user began to receive personal recommendations - this led to a situation where the user recommendations changed dramatically after the fifth viewing. In the formation of recommendations, the information that is popular on the service at the moment and the user's personal recommendations are combined: the more feedback from the user has accumulated, the less popular becomes in the top and the more personal — the user receives (some) personalized issue after the first view.
- The diagram has an arrow from client applications immediately in Hive - this is data from the groot event analytics system, the data from which (user clicks, local time of the client application) Hydra began to use more actively: for example, we ran tests of context-sensitive recommendations when the same user the vector of recommendations adapted under a context - for example, viewing time (morning or evening, weekdays or the weekend).
- Previously, the result of the work of the offline part was a bundle of files that were raised by each Hydra process into memory at the time of the service restart. Now the data gets to Redis from offline parts directly, bypassing intermediate files. This scheme greatly accelerates the restart of the service - no need to read anything from the disk, the data is already in memory and ready for use.
Conclusion
Hydra for the year has changed a lot both in architectural terms and in the algorithmic part. More details about these changes will be discussed in a series of articles.
Source: https://habr.com/ru/post/351176/
All Articles