#PostgreSQL. We accelerate the deployment seven times with the help of "multithreads"
Hello! We at the GIS utilities project use PostgreSQL and recently faced the problem of long execution of SQL scripts due to the rapid increase in data in the database. In February 2018, at PGConf, I told how we solved this problem. Presentation slides are available on the conference website . I offer you the text of my speech.

About GIS utilities has already been a detailed article in the blog group LANIT Habré. If in a nutshell, GIS utilities is Russia's first federal portal about all the information in the housing and utilities sector, which is launched in almost all regions (in 2019, Moscow, St. Petersburg and Sevastopol will join). Over the past three months, more than 12 TB of data about houses, personal accounts, payment facts and a lot of other things have been loaded into the system, and now more than 24 TB are already in PostgreSQL.
The project is architecturally divided into subsystems. Each subsystem is allocated a separate database. In total, there are about 60 such databases, they are located on 11 virtual servers. Some subsystems are heavier than others, and their bases can take 3-6 terabytes in volume.
')
Now a little more talk about the problem. I'll start from afar: we have application code and database migration code (by migration I mean transferring a database from one revision to another with all the necessary SQL scripts for this) are stored together in the version control system. This is possible due to the use of Liquibase (for more information about Liquibase on the project, see Misha Balayan’s report on TechGuruDay in LANIT).
Now let's imagine a release version. When data is only a couple of terabytes or less and all tables are within a hundred gigabytes, changes (migrations) of any data or structure changes in any tables pass quickly (usually).
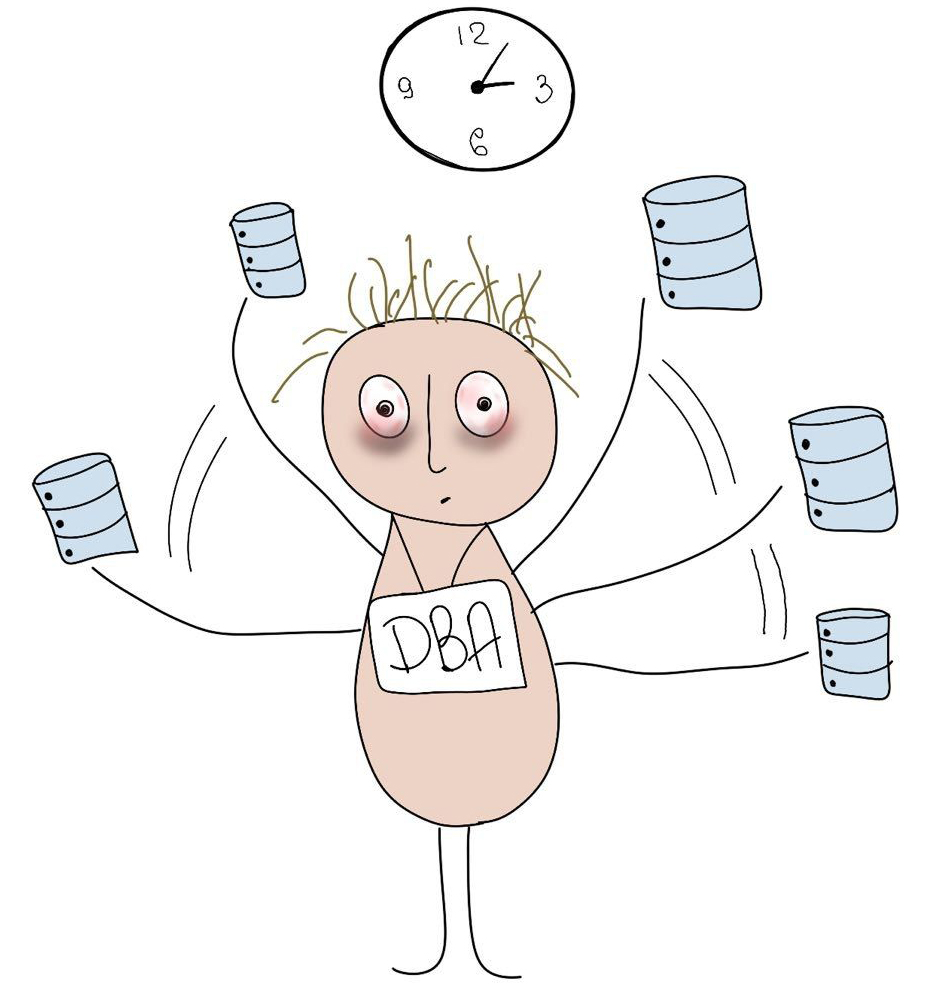
And now let's imagine that we already have a couple of tens of terabytes of data and several tables of terabyte and more appeared (possibly divided into partitions). In the new version, we need to migrate to one of these tables, or even worse all at once. And while the time of maintenance work can not be increased. And at the same time, the same migration should be done on test databases, where iron is weaker. And at the same time, it is necessary to understand in advance how much all migrations will take in time. This is where the problem begins.
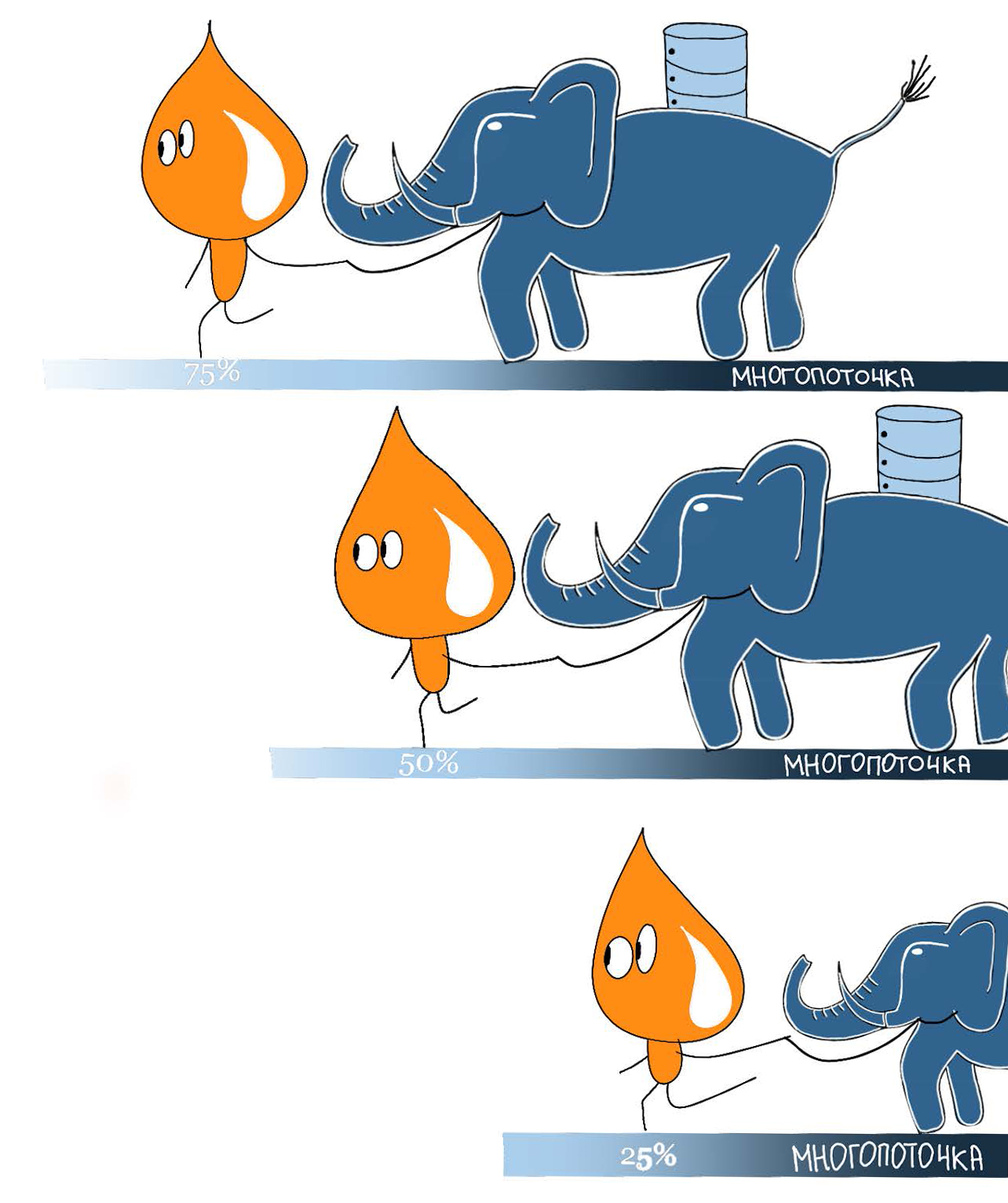
First, we tried tips from the official PostgreSQL documentation (removing indexes and FK before mass migration, re-creating tables from scratch, using copy, dynamically changing the config). This had an effect, but we wanted to be even faster and more convenient (here, of course, it is a subjective matter - as it is convenient for anyone :–)). As a result, we implemented parallel execution of mass migrations, which increased the speed on many cases by several times (and sometimes by an order of magnitude). Although in fact several processes are launched in parallel, we have got the word “multithread” inside the command.

The main idea of this approach is to divide a large table into disjoint ranges (for example, using the ntile function) and execute the SQL script not all data at once, but parallel across several ranges. Each parallel process takes one range for itself, blocks it and starts executing a SQL script only for data from this range. As soon as the script has completed, we again look for the unlocked and not yet processed range and repeat the operation. It is important to choose the right key to separate. This must be an indexed field with unique values. If there is no such field, you can use the ctid service field.
The first version of the "multithreads" was implemented using an auxiliary table with ranges and taking functions of the next range. The required SQL script was substituted into an anonymous function and started in the required number of sessions, providing parallel execution.
This approach, although it worked quickly, but required a very large number of actions by hand. And if the deployment took place at 3 o'clock in the morning, the DBA had to catch the moment of the execution of the “multi-threaded” script in Liquibase (which performed it, in fact, in one process) and run some more processes to accelerate it.
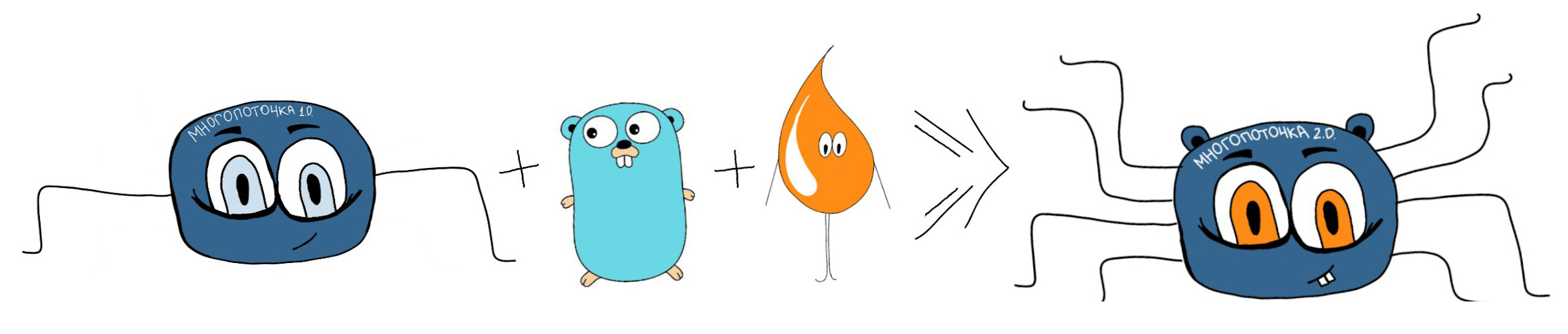
The previous version of the multithread was inconvenient to use. Therefore, we made an application on Go that automates the process (it can be done in Python, for example, and in many other languages).
First, we break the data in the variable table into ranges. After that, we add information about the script to the auxiliary table of tasks - its name (a unique identifier, for example, the name of the task in Jira) and the number of simultaneously launched processes. Then we add the text of the SQL migration divided into ranges into the auxiliary script table.
During the deployment, an application is invoked on Go, which reads the configuration of the task and the scripts for this task from the auxiliary tables and automatically runs the scripts with a specified number of parallel processes (workers). After execution, control is transferred back to Liquibase.
The application consists of three main abstractions:
In the task.do method , a channel is created to which all statements statements are sent. This channel starts the specified number of workers. Inside workers, there is an infinite loop, it multiplexes on two channels: by which it gets the statements and executes them, and the empty channel as a signaling device? that need to be completed. As soon as the empty channel is closed, the worker will shut down - this happens when an error occurs in one of the workers. Since the channels in Go are a thread – safe structure, then by closing one channel we can cancel all workers at once. When the statement in the pipe ends, the worker will simply exit the loop and reduce the total counter for all workers. Since the task always knows how many workers it works on, it simply waits for this counter to be reset and after that it completes itself.
Due to such a multithread implementation, several interesting features appeared:
The main disadvantage is the need to go full time through the plate to split it into ranges, if the text field, date or uid is used as the key. If the key for splitting is a field with successively increasing dense values, then there is no such problem (we can specify all the ranges in advance simply by specifying the required step).

Finally, I will give an example of comparing the speed of an UPDATE operation of 500,000,000 rows without using a multi-threaded one and with it. A simple UPDATE was performed for 49 minutes, while the “multithread” was completed in seven minutes.

All tools are good for certain tasks, and here are a few for multithreading.
Given
About GIS utilities has already been a detailed article in the blog group LANIT Habré. If in a nutshell, GIS utilities is Russia's first federal portal about all the information in the housing and utilities sector, which is launched in almost all regions (in 2019, Moscow, St. Petersburg and Sevastopol will join). Over the past three months, more than 12 TB of data about houses, personal accounts, payment facts and a lot of other things have been loaded into the system, and now more than 24 TB are already in PostgreSQL.
The project is architecturally divided into subsystems. Each subsystem is allocated a separate database. In total, there are about 60 such databases, they are located on 11 virtual servers. Some subsystems are heavier than others, and their bases can take 3-6 terabytes in volume.
')
MCC, we have a problem
Now a little more talk about the problem. I'll start from afar: we have application code and database migration code (by migration I mean transferring a database from one revision to another with all the necessary SQL scripts for this) are stored together in the version control system. This is possible due to the use of Liquibase (for more information about Liquibase on the project, see Misha Balayan’s report on TechGuruDay in LANIT).
Now let's imagine a release version. When data is only a couple of terabytes or less and all tables are within a hundred gigabytes, changes (migrations) of any data or structure changes in any tables pass quickly (usually).
And now let's imagine that we already have a couple of tens of terabytes of data and several tables of terabyte and more appeared (possibly divided into partitions). In the new version, we need to migrate to one of these tables, or even worse all at once. And while the time of maintenance work can not be increased. And at the same time, the same migration should be done on test databases, where iron is weaker. And at the same time, it is necessary to understand in advance how much all migrations will take in time. This is where the problem begins.
First, we tried tips from the official PostgreSQL documentation (removing indexes and FK before mass migration, re-creating tables from scratch, using copy, dynamically changing the config). This had an effect, but we wanted to be even faster and more convenient (here, of course, it is a subjective matter - as it is convenient for anyone :–)). As a result, we implemented parallel execution of mass migrations, which increased the speed on many cases by several times (and sometimes by an order of magnitude). Although in fact several processes are launched in parallel, we have got the word “multithread” inside the command.
"Multithread"
The main idea of this approach is to divide a large table into disjoint ranges (for example, using the ntile function) and execute the SQL script not all data at once, but parallel across several ranges. Each parallel process takes one range for itself, blocks it and starts executing a SQL script only for data from this range. As soon as the script has completed, we again look for the unlocked and not yet processed range and repeat the operation. It is important to choose the right key to separate. This must be an indexed field with unique values. If there is no such field, you can use the ctid service field.
The first version of the "multithreads" was implemented using an auxiliary table with ranges and taking functions of the next range. The required SQL script was substituted into an anonymous function and started in the required number of sessions, providing parallel execution.
Code example
-- UPDATE_INFO_STEPS / -- , / CREATE TABLE UPDATE_INFO_STEPS ( BEGIN_GUID varchar(36), END_GUID varchar(36) NOT NULL, STEP_NO int, STATUS char(1), BEGIN_UPD timestamp, END_UPD timestamp, ROWS_UPDATED int, ROWS_UPDATED_TEXT varchar(30), DISCR varchar(10) ); ALTER TABLE UPDATE_INFO_STEPS ADD PRIMARY KEY(discr, step_no); -- FUNC_UPDATE_INFO_STEPS . -- "" , . CREATE OR REPLACE FUNCTION func_update_info_steps( pStep_no int, pDiscr varchar(10) ) RETURNS text AS $BODY$ DECLARE lResult text; BEGIN SELECT 'SUCCESS' INTO lResult FROM update_info_steps WHERE step_no = pStep_no AND discr = pDiscr AND status = 'N' FOR UPDATE NOWAIT; UPDATE UPDATE_INFO_STEPS SET status = 'A', begin_upd = now() WHERE step_no = pStep_no AND discr = pDiscr AND status = 'N'; return lResult; EXCEPTION WHEN lock_not_available THEN SELECT 'ERROR' INTO lResult; return lResult; END; $BODY$ LANGUAGE PLPGSQL VOLATILE; -- (1 1 ) -- 1. . DO LANGUAGE PLPGSQL $$ DECLARE -- l_count int := 10000; -- l_discr VARCHAR(10) := '<discr>'; BEGIN INSERT INTO UPDATE_INFO_STEPS ( BEGIN_GUID, END_GUID, STEP_NO, STATUS, DISCR ) SELECT min(guid) BEGIN_GUID, max(guid) END_GUID, RES2.STEP STEP_NO, 'N' :: char(1) STATUS, l_discr DISCR FROM ( SELECT guid, floor( (ROWNUM - 1) / l_count ) + 1 AS STEP FROM ( -- SELECT <column> AS GUID, -- row_number() over ( ORDER BY <column> ) AS ROWNUM FROM -- <schema>.<table_name> ORDER BY 1 -- ) RES1 ) RES2 GROUP BY RES2.step; END; $$; -- 2. , UPDATE. DO LANGUAGE PLPGSQL $$ DECLARE cur record; vCount int; vCount_text varchar(30); vCurStatus char(1); vCurUpdDate date; -- l_discr varchar(10) := '<discr>'; l_upd_res varchar(100); BEGIN FOR cur IN ( SELECT * FROM UPDATE_INFO_STEPS WHERE status = 'N' AND DISCR = l_discr ORDER BY step_no ) LOOP vCount := 0; -- ! SELECT result INTO l_upd_res FROM dblink( '<parameters>', 'SELECT FUNC_UPDATE_INFO_STEPS(' || cur.step_no || ',''' || l_discr || ''')' ) AS T (result text); IF l_upd_res = 'SUCCESS' THEN -- . -- , . -- - -- cur.begin_guid - cur.end_guid dblink " ". -- . SELECT dblink( '<parameters>', 'UPDATE FOO set level = 42 WHERE id BETWEEN ''' || cur.begin_guid || ''' AND ''' || cur.end_guid || '''' ) INTO vCount_text; -- . SELECT dblink( '<parameters>', 'update UPDATE_INFO_STEPS SET status = ''P'', end_upd = now(), rows_updated_text = ''' || vCount_text || ''' WHERE step_no = ' || cur.step_no || ' AND discr = ''' || l_discr || '''' ) INTO l_upd_res; END IF; END LOOP; END; $$; -- . SELECT SUM(CASE status WHEN 'P' THEN 1 ELSE 0 END) done, SUM(CASE status WHEN 'A' THEN 1 ELSE 0 END) processing, SUM(CASE status WHEN 'N' THEN 1 ELSE 0 END) LEFT_, round( SUM(CASE status WHEN 'P' THEN 1 ELSE 0 END):: numeric / COUNT(*)* 100 :: numeric, 2 ) done_proc FROM UPDATE_INFO_STEPS WHERE discr = '<discr>'; This approach, although it worked quickly, but required a very large number of actions by hand. And if the deployment took place at 3 o'clock in the morning, the DBA had to catch the moment of the execution of the “multi-threaded” script in Liquibase (which performed it, in fact, in one process) and run some more processes to accelerate it.
“Multipoint 2.0”
The previous version of the multithread was inconvenient to use. Therefore, we made an application on Go that automates the process (it can be done in Python, for example, and in many other languages).
First, we break the data in the variable table into ranges. After that, we add information about the script to the auxiliary table of tasks - its name (a unique identifier, for example, the name of the task in Jira) and the number of simultaneously launched processes. Then we add the text of the SQL migration divided into ranges into the auxiliary script table.
Code example
-- , -- (pg_parallel_task) -- (pg_parallel_task_statements). CREATE TABLE IF NOT EXISTS public.pg_parallel_task ( name text primary key, threads_count int not null DEFAULT 10, comment text ); COMMENT ON table public.pg_parallel_task IS ' '; COMMENT ON COLUMN public.pg_parallel_task.name IS ' '; COMMENT ON COLUMN public.pg_parallel_task.threads_count IS ' . 10'; COMMENT ON COLUMN public.pg_parallel_task.comment IS ''; CREATE TABLE IF NOT EXISTS public.pg_parallel_task_statements ( statement_id bigserial primary key, task_name text not null references public.pg_parallel_task (name), sql_statement text not null, status text not null check ( status in ( 'new', 'in progress', 'ok', 'error' ) ) DEFAULT 'new', start_time timestamp without time zone, elapsed_sec float(8), rows_affected bigint, err text ); COMMENT ON table public.pg_parallel_task_statements IS ' '; COMMENT ON COLUMN public.pg_parallel_task_statements.sql_statement IS ' '; COMMENT ON COLUMN public.pg_parallel_task_statements.status IS ' . new|in progress|ok|error'; COMMENT ON COLUMN public.pg_parallel_task_statements.start_time IS ' '; COMMENT ON COLUMN public.pg_parallel_task_statements.elapsed_sec IS ' , '; COMMENT ON COLUMN public.pg_parallel_task_statements.rows_affected IS ' , '; COMMENT ON COLUMN public.pg_parallel_task_statements.err IS ' , . NULL, .'; -- INSERT INTO PUBLIC.pg_parallel_task (NAME, threads_count) VALUES ('JIRA-001', 10); INSERT INTO PUBLIC.pg_parallel_task_statements (task_name, sql_statement) SELECT 'JIRA-001' task_name, FORMAT( 'UPDATE FOO SET level = 42 where id >= ''%s'' and id <= ''%s''', MIN(d.id), MAX(d.id) ) sql_statement FROM ( SELECT id, NTILE(10) OVER ( ORDER BY id ) part FROM foo ) d GROUP BY d.part; -- During the deployment, an application is invoked on Go, which reads the configuration of the task and the scripts for this task from the auxiliary tables and automatically runs the scripts with a specified number of parallel processes (workers). After execution, control is transferred back to Liquibase.
Code
<changeSet id="JIRA-001" author="soldatov"> <executeCommand os="Linux, Mac OS X" executable="./pgpar.sh"> <arg value="testdatabase"/><arg value="JIRA-001"/> </executeCommand> </changeSet> The application consists of three main abstractions:
- task - loads the migration parameters, the number of processes and all ranges into memory, starts the “multithread” and raises the Web – server to monitor the progress of the execution;
- statement - represents one range of the operation being performed, is also responsible for changing the status of the range execution, recording the range execution time, the number of lines in the range, etc .;
- worker is a single execution thread.
In the task.do method , a channel is created to which all statements statements are sent. This channel starts the specified number of workers. Inside workers, there is an infinite loop, it multiplexes on two channels: by which it gets the statements and executes them, and the empty channel as a signaling device? that need to be completed. As soon as the empty channel is closed, the worker will shut down - this happens when an error occurs in one of the workers. Since the channels in Go are a thread – safe structure, then by closing one channel we can cancel all workers at once. When the statement in the pipe ends, the worker will simply exit the loop and reduce the total counter for all workers. Since the task always knows how many workers it works on, it simply waits for this counter to be reset and after that it completes itself.
Buns
Due to such a multithread implementation, several interesting features appeared:
- Integration with Liquibase (called with the executeCommand tag).
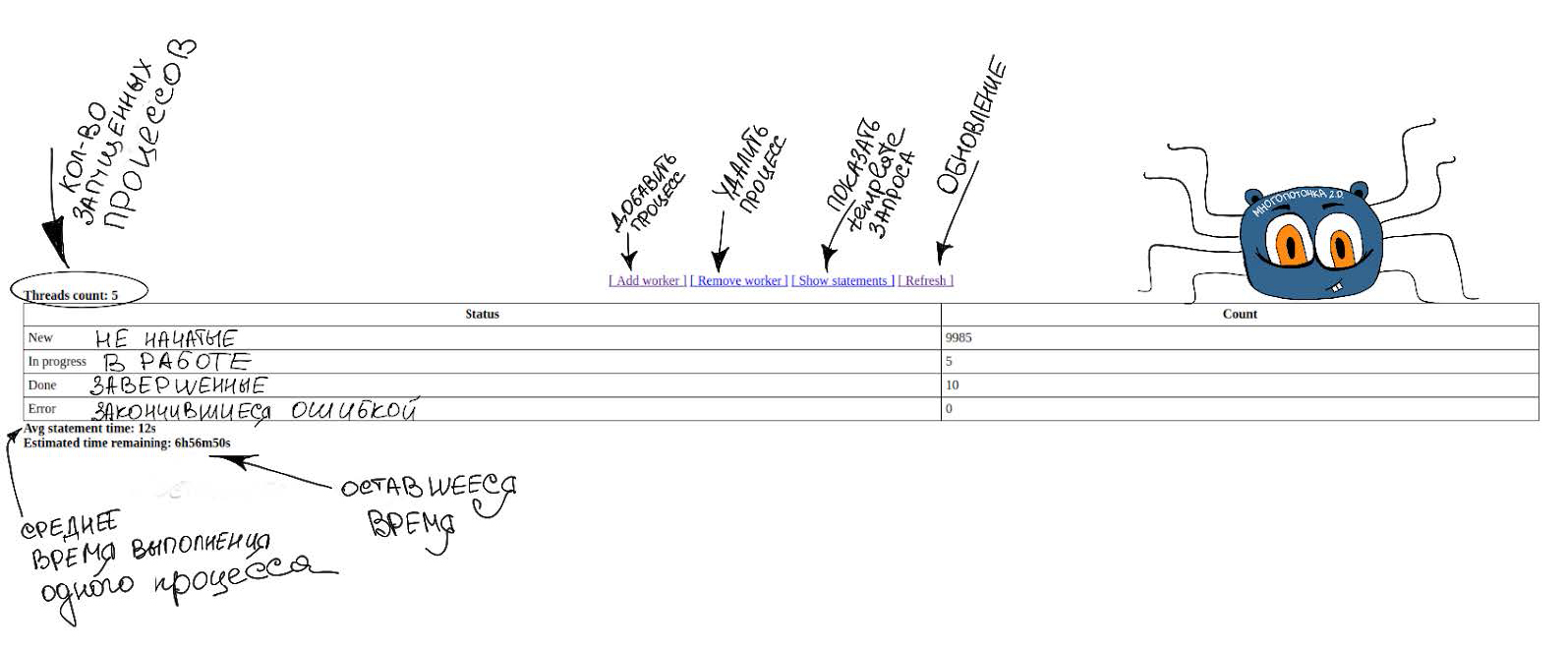
- a simple web interface that appears when you start a “multi-thread” and contains all the information about its progress.
- Progress bar (we know how much one range is processed, how many parallel processes are running and how many ranges are left to process - so we can calculate the completion time).
- Dynamic change of parallel processes (while we do it by hand, but in the future we want to automate).
- Logging information on the execution of multithreaded scripts for further analysis.
- You can perform blocking operations like update, blocking almost nothing (if you break the tablet into very small ranges, all scripts will be executed almost instantly).
- There is a wrapper for calling a “multi-threaded” directly from the database.
No buns
The main disadvantage is the need to go full time through the plate to split it into ranges, if the text field, date or uid is used as the key. If the key for splitting is a field with successively increasing dense values, then there is no such problem (we can specify all the ranges in advance simply by specifying the required step).
Accelerate seven times (test on pgbench table)
Finally, I will give an example of comparing the speed of an UPDATE operation of 500,000,000 rows without using a multi-threaded one and with it. A simple UPDATE was performed for 49 minutes, while the “multithread” was completed in seven minutes.
Code example
SELECT count(1) FROM pgbench_accounts; count ------- 500000000 (1 row) SELECT pg_size_pretty(pg_total_relation_size('pgbench_accounts')); pg_size_pretty ---------------- 62 Gb (1 row) UPDATE pgbench_accounts SET abalance = 42; -- 49 vacuum full analyze verbose pgbench_accounts; INSERT INTO public.pg_parallel_tASk (name, threads_count) values ('JIRA-002', 25); INSERT INTO public.pg_parallel_tASk_statements (tASk_name, sql_statement) SELECT 'JIRA-002' tASk_name, FORMAT('UPDATE pgbench_accounts SET abalance = 42 WHERE aid >= ''%s'' AND aid <= ''%s'';', MIN(d.aid), MAX(d.aid)) sql_statement FROM (SELECT aid, ntile(25) over (order by aid) part FROM pgbench_accounts) d GROUP BY d.part; -- 10 -- ctid, INSERT INTO public.pg_parallel_tASk_statements (tASk_name, sql_statement) SELECT 'JIRA-002-ctid' tASk_name, FORMAT('UPDATE pgbench_accounts SET abalance = 45 WHERE (ctid::text::point)[0]::text > ''%s'' AND (ctid::text::point)[0]::text <= ''%s'';', (d.min_ctid), (d.max_ctid)) sql_statement FROM ( WITH max_ctid AS ( SELECT MAX((ctid::text::point)[0]::int) FROM pgbench_accounts) SELECT generate_series - (SELECT max / 25 FROM max_ctid) AS min_ctid, generate_series AS max_ctid FROM generate_series((SELECT max / 25 FROM max_ctid), (SELECT max FROM max_ctid), (SELECT max / 25 FROM max_ctid))) d; -- 9 ./pgpar-linux-amd64 jdbc:postgresql://localhost:5432 soldatov password testdatabase JIRA-002 -- 7 PS You need it if:
All tools are good for certain tasks, and here are a few for multithreading.
- UPDATE tables> 100,000 rows.
- UPDATE with complex logic that can be parallelized (for example, calling functions to evaluate something).
- UPDATE without locks. By crushing into very small ranges and starting a small number of processes, instant processing of each range can be achieved. Thus, the lock will also be almost instant.
- Parallel execution of changeSets in Liquibase (for example, VACUUM).
- Creating and filling data with new fields in the table.
- Sophisticated reports.
Almost non-blocking UPDATE (50,000 ranges of 10,000 rows each)
<changeSet author="soldatov" id="JIRA-002-01"> <sql> <![CDATA[ INSERT INTO public.pg_parallel_task (name, threads_count) VALUES ('JIRA-002', 5); INSERT INTO public.pg_parallel_task_statements (task_name, sql_statement) SELECT 'JIRA-002' task_name, FORMAT( 'UPDATE pgbench_accounts SET abalance = 42 WHERE filler IS NULL AND aid >= ''%s'' AND aid <= ''%s'';', MIN(d.aid), MAX(d.aid) ) sql_statement FROM ( SELECT aid, ntile(10000) over ( order by aid ) part FROM pgbench_accounts WHERE filler IS NULL ) d GROUP BY d.part; ]]> </sql> </changeSet> <changeSet author="soldatov" id="JIRA-002-02"> <executeCommand os="Linux, Mac OS X" executable="./pgpar.sh"> <arg value="pgconfdb"/><arg value="JIRA-002"/> </executeCommand> </changeSet> Parallel changeSets in Liquibase
<changeSet author="soldatov" id="JIRA-003-01"> <sql> <![CDATA[ INSERT INTO pg_parallel_task (name, threads_count) VALUES ('JIRA-003', 2); INSERT INTO pg_parallel_task_statements (task_name, sql_statement) SELECT 'JIRA-003' task_name, 'VACUUM FULL ANALYZE pgbench_accounts;' sql_statement; INSERT INTO pg_parallel_task_statements (task_name, sql_statement) SELECT 'JIRA-003' task_name, 'VACUUM FULL ANALYZE pgbench_branches;' sql_statement; ]]> </sql> </changeSet> <changeSet author="soldatov" id="JIRA-003-02"> <executeCommand os="Linux, Mac OS X" executable="./pgpar.sh"> <arg value="testdatabase"/><arg value="JIRA-003"/> </executeCommand> </changeSet> Almost non-blocking filling of a new field of the table with data (50,000 ranges of 10,000 lines each) with the call of a "multi-threaded" function from the database
-- SQL part ALTER TABLE pgbench_accounts ADD COLUMN account_number text; INSERT INTO public.pg_parallel_task (name, threads_count) VALUES ('JIRA-004', 5); INSERT INTO public.pg_parallel_task_statements (task_name, sql_statement) SELECT 'JIRA-004' task_name, FORMAT('UPDATE pgbench_accounts SET account_number = aid::text || filler WHERE aid >= ''%s'' AND aid <= ''%s'';', MIN(d.aid), MAX(d.aid)) sql_statement FROM (SELECT aid, ntile(50000) over (order by device_version_guid) part FROM pgbench_accounts) d GROUP BY d.part; SELECT * FROM func_run_parallel_task('testdatabase','JIRA-004'); By the way, we have a vacancy.
Source: https://habr.com/ru/post/351160/
All Articles