Efficient use of memory with parallel input-output operations in Python
There are two classes of tasks where we may need parallel processing: input-output operations and tasks that actively use CPUs, such as image processing. Python allows you to implement several approaches to parallel data processing. Let's consider them with reference to input-output operations.
Prior to Python 3.5, there were two ways to implement parallel processing of I / O operations. The native method is the use of multithreading, another option is libraries like Gevent, which parallelize tasks in the form of micro-threads. Python 3.5 provided native support for concurrency using asyncio. I was curious to see how each of them would work in terms of memory. Results below.
For testing, I created a simple script. Although there are not so many functions, it demonstrates a real use case. The script downloads bus tickets for 100 days from the site and prepares them for processing. Memory consumption was measured using memory_profiler . The code is available on Github .
I implemented a single-threaded version of the script, which became the benchmark for other solutions. Memory usage was fairly stable throughout the execution, and the apparent drawback was the execution time. Without any parallelism, the script took about 29 seconds.
')
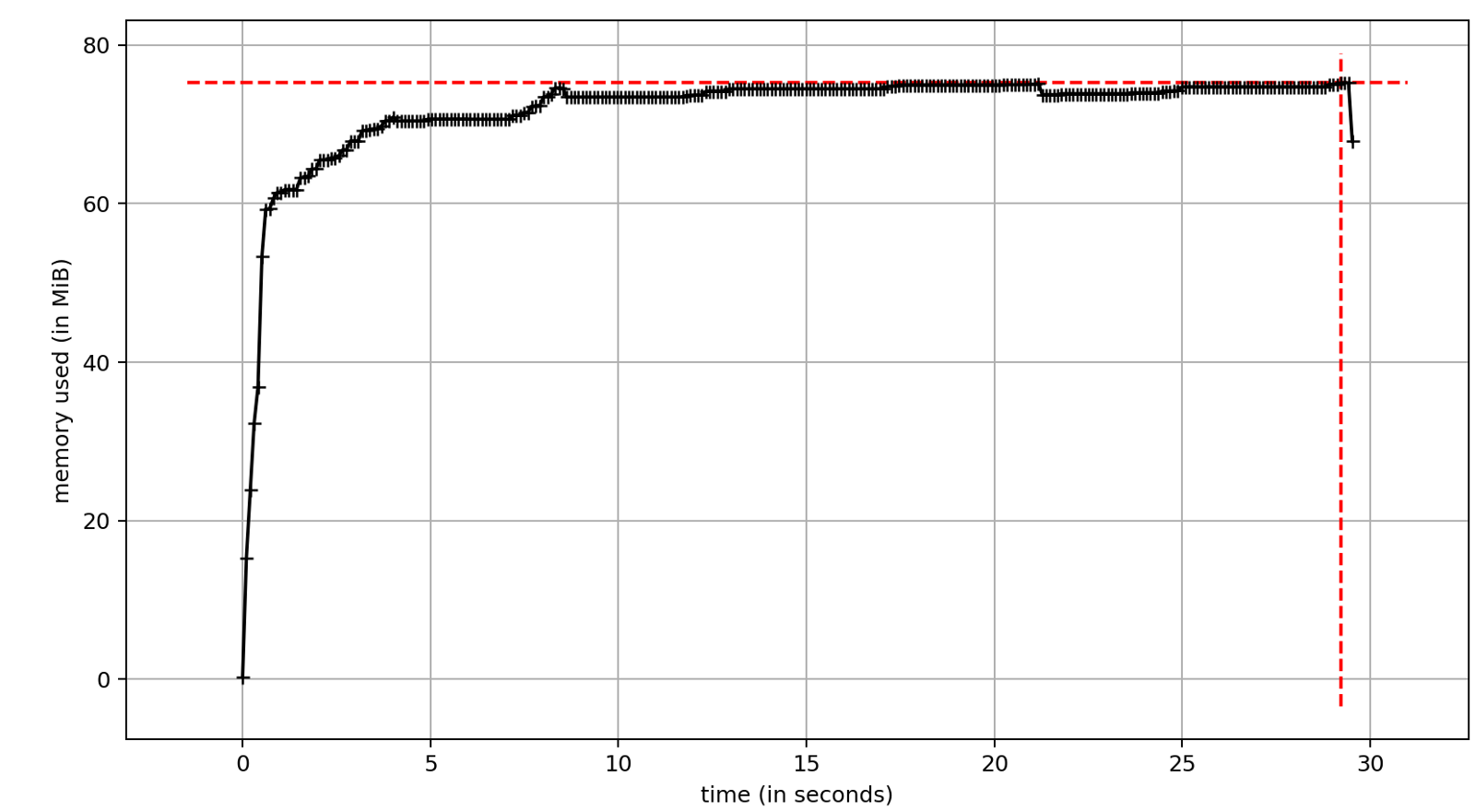
Work with multithreading is implemented in the standard library. The most convenient API provides ThreadPoolExecutor . However, the use of threads is associated with some drawbacks, one of which is significant memory consumption. On the other hand, a significant increase in execution speed is the reason we want to use multithreading. Test run time ~ 17 seconds. This is significantly less than ~ 29 seconds with synchronous execution. The difference is the speed of I / O operations. In our case, network latency.

Gevent is an alternative approach to concurrency; it brings cortutin to Python code to version 3.5. Under the hood, we have light pseudo-streams of “greenlet” plus several streams for internal needs. Total memory consumption is similar to multipath.

Since the Python 3.5 version, cortices are available in the asyncio module, which has become part of the standard library. To take advantage of asyncio , I used aiohttp instead of requests . aiohttp is the asynchronous equivalent of requests with similar functionality and API.
Having the appropriate libraries is the main issue that needs to be clarified before starting development with asyncio , although the most popular IO libraries — requests , redis , psycopg2 — have asynchronous counterparts.
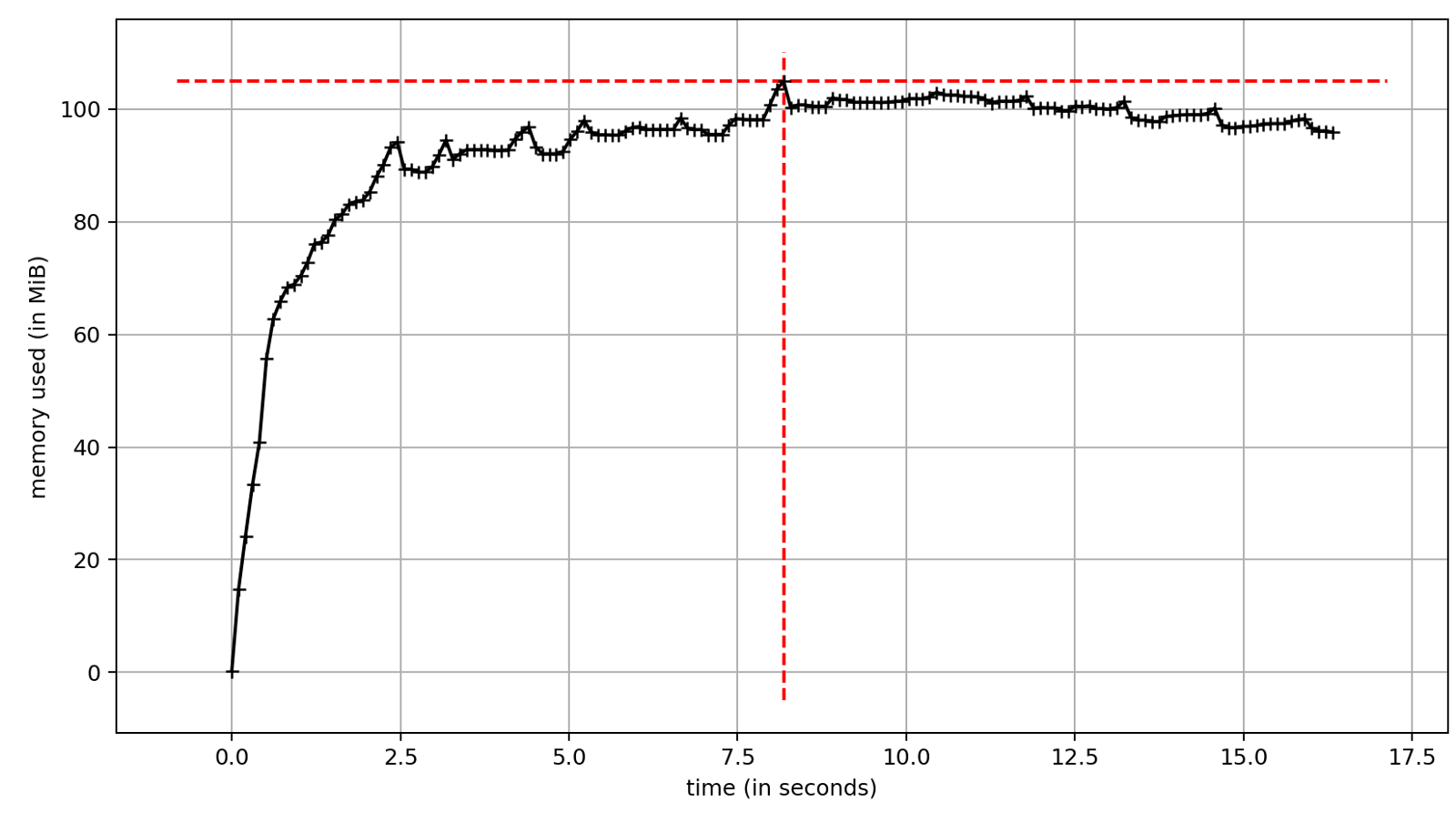
With asyncio, memory consumption is significantly less. It is similar to the single-threaded version of the script without parallelism.
Parallelism is a very efficient way to accelerate applications with a large number of I / O operations. In my case, this is ~ 40% performance increase compared to sequential processing. The differences in speed for the considered methods of implementing parallelism are insignificant.
ThreadPoolExecutor and Gevent are powerful tools that can speed up existing applications. Their main advantage is that in most cases they require minor changes to the code base. If we talk about overall performance, then the best tool is asyncio . Its memory consumption is much lower compared to other methods of parallelism, which does not affect the overall speed. For the benefits you have to pay specialized libraries, sharpened by working with asyncio .
Prior to Python 3.5, there were two ways to implement parallel processing of I / O operations. The native method is the use of multithreading, another option is libraries like Gevent, which parallelize tasks in the form of micro-threads. Python 3.5 provided native support for concurrency using asyncio. I was curious to see how each of them would work in terms of memory. Results below.
Preparing the test environment
For testing, I created a simple script. Although there are not so many functions, it demonstrates a real use case. The script downloads bus tickets for 100 days from the site and prepares them for processing. Memory consumption was measured using memory_profiler . The code is available on Github .
Go!
Synchronous processing
I implemented a single-threaded version of the script, which became the benchmark for other solutions. Memory usage was fairly stable throughout the execution, and the apparent drawback was the execution time. Without any parallelism, the script took about 29 seconds.
')
ThreadPoolExecutor
Work with multithreading is implemented in the standard library. The most convenient API provides ThreadPoolExecutor . However, the use of threads is associated with some drawbacks, one of which is significant memory consumption. On the other hand, a significant increase in execution speed is the reason we want to use multithreading. Test run time ~ 17 seconds. This is significantly less than ~ 29 seconds with synchronous execution. The difference is the speed of I / O operations. In our case, network latency.
Gevent
Gevent is an alternative approach to concurrency; it brings cortutin to Python code to version 3.5. Under the hood, we have light pseudo-streams of “greenlet” plus several streams for internal needs. Total memory consumption is similar to multipath.
Asyncio
Since the Python 3.5 version, cortices are available in the asyncio module, which has become part of the standard library. To take advantage of asyncio , I used aiohttp instead of requests . aiohttp is the asynchronous equivalent of requests with similar functionality and API.
Having the appropriate libraries is the main issue that needs to be clarified before starting development with asyncio , although the most popular IO libraries — requests , redis , psycopg2 — have asynchronous counterparts.
With asyncio, memory consumption is significantly less. It is similar to the single-threaded version of the script without parallelism.
Is it time to start using asyncio?
Parallelism is a very efficient way to accelerate applications with a large number of I / O operations. In my case, this is ~ 40% performance increase compared to sequential processing. The differences in speed for the considered methods of implementing parallelism are insignificant.
ThreadPoolExecutor and Gevent are powerful tools that can speed up existing applications. Their main advantage is that in most cases they require minor changes to the code base. If we talk about overall performance, then the best tool is asyncio . Its memory consumption is much lower compared to other methods of parallelism, which does not affect the overall speed. For the benefits you have to pay specialized libraries, sharpened by working with asyncio .
Source: https://habr.com/ru/post/351112/
All Articles