Guide to SEO javascript sites. Part 2. Problems, experiments and recommendations
In the first part of the translation of this article, we talked about how a webmaster can look at his resource through the eyes of Google, and about what work needs to be done, if what the site developer sees is not what he is waiting for.

Today, in the second part of the translation, Tomasz Rudsky will talk about the most common SEO errors to which JavaScript-based sites are exposed, discuss the consequences of Google’s future rejection of AJAX scanning, talk about pre-rendering and isomorphic JavaScript, and share the results of indexing experiments. . Here, in addition, he will touch on the topic of the features of ranking sites of various kinds and suggest recalling that in addition to Google there are other search engines who also have to deal with JS-based web pages.
If, in your opinion, Googlebot is able to process a certain page, but it turns out that this page is not indexed as it should, check that the external and internal resources (JS-libraries, for example) required to form the page are available. search robot. If he is unable to load something and correctly recreate the page, it’s possible not to talk about its indexing.
')
If you suddenly encounter a significant drop in the ranking of a site that previously worked stably and reliably, I recommend using the Fetch and Render tools described earlier to check if Google can properly handle your site.
In general, it is useful from time to time to use Fetch and Render on an arbitrary set of site pages in order to verify that it can be correctly processed by a search engine.
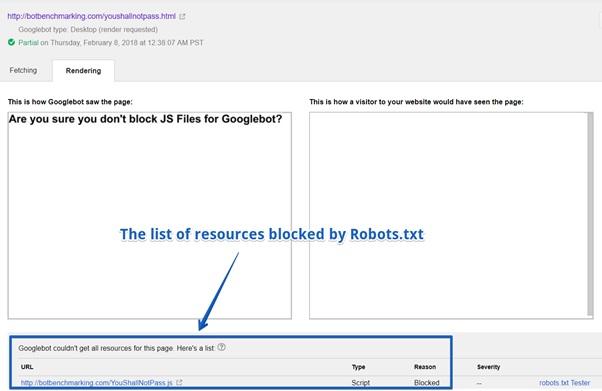
List of resources blocked by Robots.txt
Remember, Googlebot isn’t a real user, so take it for granted that it doesn’t click the links and buttons and fill out the forms. This fact has many practical consequences:
This is confirmed by John Muller:
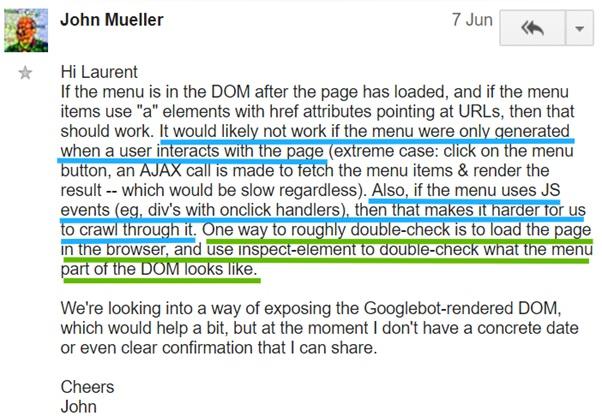
Commentary by John Muller confirming the above
In one of my previous materials , which is devoted to using Chrome 41 for research sites, there is a brief guide that demonstrates the process of checking the menu for its availability for the Google indexing system. I advise you to get acquainted with this material.
It is still common practice that JS frameworks create URLs with a
Here are some examples:
Note that this does not apply to URLs with a sequence of
Perhaps you decide that all this does not matter. Indeed - a big deal - just one extra character in the address. However, it is very important.
Let me once again quote John Muller:
“(...) From our point of view, if we see something like a # sign here, it means that what follows it may not matter. For the most part, by indexing the content, we ignore such things (...). When you need to make this content really appear in the search, it is important that you use links that look more static. ”
As a result, we can say that web developers should try to make their links not look like something like
Many sites based on JavaScript have problems with indexing due to the fact that Google has to wait too long for the results of the scripts (meaning waiting for them to load, parse, run). Slow scripts can mean that Googlebot will quickly run out of crawling your site. Ensure that your scripts are fast, and Google would not have to wait too long to download them. For those who want to learn more about this, I recommend reading this material on optimizing the page rendering process.
I want to raise here the problem that can affect even the best search engine optimization sites.

The traditional approach to SEO and SEO, taking into account the features of JS
It is important to remember that SEO taking into account the features of JavaScript is performed on the basis of traditional search engine optimization. It is impossible to optimize the site well, taking into account the peculiarities of JS, without achieving decent optimization in the usual sense of the word. Sometimes, when you encounter an SEO problem, your first impression may be that it is related to JS, although, in fact, the problem is in traditional search engine optimization.
I will not go into the details of such situations, as Justin Briggs already perfectly explained in his material “ Core Principles of SEO for JavaScript ”, in the section “Confusing Bad SEO with JavaScript Limitations”. I recommend reading this useful article.
Google has announced that since the second quarter of 2018, it will no longer use AJAX Crawling Scheme. Does this mean that Google will stop indexing sites using Ajax (asynchronous JavaScript)? No, it is not.
It is worth saying that AJAX scanning appeared in the days when Google realized that more and more sites use JS, but could not properly handle such sites. In order to solve this problem, webmasters were offered to create special versions of pages intended for a search robot and not containing JS scripts. Addresses
In practice, it looks like this: users work with a full-fledged and pleasant-looking
This is how it works (image taken from the Google blog).
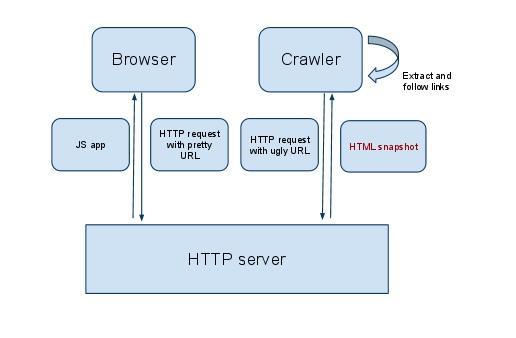
Different versions of the site for users and bots
Thanks to this approach, webmasters got the opportunity to kill two birds with one stone: both users are happy and the search robot is happy. Users see a version of the site equipped with JavaScript capabilities, and search engines can properly index the pages of this site, since they only get the usual HTML and CSS.
The problems of the Ajax Crawling Scheme lie in the fact that since users and search robots get different versions of the site, it is very difficult to analyze the problems associated with indexing sites. In addition, some webmasters had problems with preliminary preparation of versions of pages intended for the search robot.
That is why Google has announced that starting from the second quarter of 2018, webmasters no longer need to create two different versions of the website:

AJAX Scan Disable Message
How will this affect web developers?
In addition, developers will need to find a way to make their sites accessible to Bing and other search engines, which are far behind Google in processing JavaScript-based sites. Possible solutions include server rendering (universal JavaScript), or, oddly enough, continued use of the old AJAX scan for Bingbot. We will discuss this below.
It is not clear whether Google plans to update its site processing service in order to support the latest technologies. We can only hope that this will be done.
I thought a lot about it, and that is why I decided to ask John Muller on the JavaScript SEO forum about whether I can find Googlebot on the

A question to John Muller about the site version prepared specifically for Googlebot
Here is what he said:

John Muller's Answer
John agrees that a developer can find out that his site is crawling Googlebot by checking the
Imagine that Googlebot handles sites based on JS frameworks perfectly and you have no difficulties with it. Does this mean that you can forget about all the problems associated with indexing such sites? Unfortunately - does not mean. Let us recall the search engine Bing, which, in the United States, employs about a third of Internet users.
At present, it will be reasonable to assume that Bing does not handle JavaScript at all (there are rumors that Bing handles JS on highly rated pages, but I could not find a single confirmation of these rumors).
Let me tell you about one interesting study.
Angular.io is the official website of Angular 2+. Some pages of this site are created as one-page applications. This means that their HTML source does not contain any content. After loading such a page, an external JS-file is loaded, by means of which the content of the pages is formed.

Angular.io website
There is a feeling that Bing does not see the contents of this site!
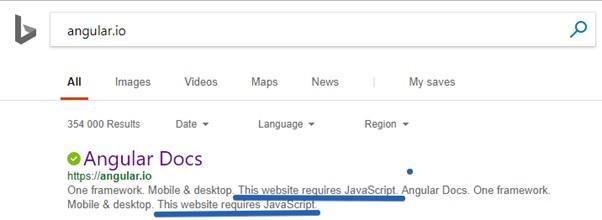
Bing does not see the contents of the site Angular.io
This site is ranked second for the keyword "Angular" in Bing.
How about the query "Angular 4". Again - the second position, below the site AngularJS.org (this is the official site of Angular 1). At the request of "Angular 5" - again the second position.
If you need evidence that Bing cannot work with Angular.io - try to find any piece of text from this site using the
Choosing a piece of text to check
Text when searching the site could not be found
For me, it's so strange. It turns out that the official website Angular 2 can not be properly scanned and indexed by the robot Bingbot.
What about Yandex? Angular.io is not even in the top 50 results when searching for the word “Angular” in Yandex!

Angular.io site in Yandex
On Twitter, I turned to the Angular.io team, asked them if they were planning to do something so that their website could be indexed by search engines like Bing, but at the time of writing this material, they hadn’t answered me yet.
As a matter of fact, from the foregoing it can be concluded that, in an effort to introduce new web technologies on your websites, you should not forget about Bing and other search engines. Here we can recommend two approaches: isomorphic JavaScript and pre-rendering.
When you notice that Google is having trouble indexing your site, which is being rendered on the client, you can consider using pre-rendering or converting the site to an isomorphic JavaScript application.
Which approach is better?
Google recommends isomorphic javascript
However, there is one problem, which is that many developers cannot correctly create isomorphic JavaScript applications.
If you are attracted to server rendering, see the documentation for the JS framework you are using. For example, in the case of Angular, you can apply Angular Universal . If you are working with React, read the documentation and watch this tutorial on Udemy.
React 16 (it was released in November) brought a lot of improvements to the server rendering area. One of these improvements is the
If we talk about the general approach to server rendering, I would like to note one important recommendation. It is that if you want a site to be rendered on a server, developers should avoid using functions that directly affect the DOM.
Whenever possible, think twice before working directly with the DOM. If you need to interact with the browser DOM - use Angular Renderer or rendering abstraction.
We, at Elephate, conducted some experiments in order to find out how deeply Googlebot can advance in finding links and navigating through them in the case of crawling websites that use only HTML, and websites based on JavaScript.
The study gave amazing results. In the case of an HTML site, Googlebot was able to index all pages. However, when processing a JS-based site, the situation was quite ordinary when Googlebot did not even get to its second level. We repeated the experiment on five different domains, but the result was always the same.

Experiment in indexing HTML sites and JS-based sites
Bartosh Goralevich turned to John Muller from Google and asked him about the sources of the problem. John confirmed that Google sees links generated by JavaScript, but " Googlebot does not want to crawl them. " He added : “We do not scan all URLs, or we scan all of them quickly, especially when our algorithm is not sure of the value of the URL. The value of the content is an ambiguous aspect of test sites. ”
If you want to delve into this topic, I recommend looking at this material .
I want to share some of my ideas about the above experiment. So, it should be noted that although the studied sites were created only for experimental purposes, the same approach was applied to their content. Namely, their texts were created by means of Articoolo - an interesting content generator based on artificial intelligence technologies. He gives out pretty good lyrics that are definitely better than my writing.
Googlebot received two very similar websites and scanned just one of them, preferring the HTML site to the site that uses JS. Why is this so? Put forward several assumptions:
There are many high-quality real links to the above websites. Many people willingly shared links to them on the Internet. In addition, they received organic traffic. And then the question arises of how to distinguish a test site from a real one. This is not an easy task.
There is a great chance that if you create a new website that is rendered on the client, you will be in the exact same situation as we are. Googlebot, in this case, simply won’t scan it. This is where the theory ends and the real problems begin. In addition, the main problem here is that there is practically no real life example, when a website, or an online store, or a company page that uses client rendering, occupy a high position in search results. Therefore, I can not guarantee that your site, filled with JavaScript capabilities, will get as high a position in the search as its HTML equivalent.
You can decide that, for sure, most SEO specialists know this anyway, and large companies can spend some money on tackling these problems. However, what about small companies that do not have the means and knowledge? This can be a real danger for something like the sites of small family restaurants that use client-side rendering.
Let us briefly summarize the conclusions and recommendations in the following list:
SEO , ( !) Google , JavaScript , , HTML. , , SEO- , JS- , , , . , SEO JavaScript- . - . , , JavaScript, , SEO .
Dear readers! , , , JS-?

Today, in the second part of the translation, Tomasz Rudsky will talk about the most common SEO errors to which JavaScript-based sites are exposed, discuss the consequences of Google’s future rejection of AJAX scanning, talk about pre-rendering and isomorphic JavaScript, and share the results of indexing experiments. . Here, in addition, he will touch on the topic of the features of ranking sites of various kinds and suggest recalling that in addition to Google there are other search engines who also have to deal with JS-based web pages.
About the resources necessary for the successful formation of the page
If, in your opinion, Googlebot is able to process a certain page, but it turns out that this page is not indexed as it should, check that the external and internal resources (JS-libraries, for example) required to form the page are available. search robot. If he is unable to load something and correctly recreate the page, it’s possible not to talk about its indexing.
')
About recurring use of the Google Search Console
If you suddenly encounter a significant drop in the ranking of a site that previously worked stably and reliably, I recommend using the Fetch and Render tools described earlier to check if Google can properly handle your site.
In general, it is useful from time to time to use Fetch and Render on an arbitrary set of site pages in order to verify that it can be correctly processed by a search engine.
List of resources blocked by Robots.txt
Dangerous onClick event
Remember, Googlebot isn’t a real user, so take it for granted that it doesn’t click the links and buttons and fill out the forms. This fact has many practical consequences:
- If you have an online store and some texts are hidden under the buttons like "More ...", but they are not present in the DOM until you click on the corresponding button, Google will not read these texts. This also applies to links that appear on the same principle in the menu.
- All links must contain the
hrefparameter. If you only rely on theonClickevent, Google will not accept such links.
This is confirmed by John Muller:
Commentary by John Muller confirming the above
In one of my previous materials , which is devoted to using Chrome 41 for research sites, there is a brief guide that demonstrates the process of checking the menu for its availability for the Google indexing system. I advise you to get acquainted with this material.
Using icons in links
It is still common practice that JS frameworks create URLs with a
# sign. There is a real danger that Googlebot will not process such links.Here are some examples:
- Bad URL: example.com/#/crisis-center/
- Bad URL: example.com # URL
- Good URL: example.com/crisis-center/
Note that this does not apply to URLs with a sequence of
#! (the so-called hashbang).Perhaps you decide that all this does not matter. Indeed - a big deal - just one extra character in the address. However, it is very important.
Let me once again quote John Muller:
“(...) From our point of view, if we see something like a # sign here, it means that what follows it may not matter. For the most part, by indexing the content, we ignore such things (...). When you need to make this content really appear in the search, it is important that you use links that look more static. ”
As a result, we can say that web developers should try to make their links not look like something like
example.com/resource#dsfsd . When using frameworks that form such links, it is worth referring to their documentation. For example, Angular 1 by default, uses addresses that use # signs. You can fix this by setting $locationProvider accordingly. But, for example, Angular 2 and without additional settings uses links that Googlebot understands well.About slow scripts and slow APIs
Many sites based on JavaScript have problems with indexing due to the fact that Google has to wait too long for the results of the scripts (meaning waiting for them to load, parse, run). Slow scripts can mean that Googlebot will quickly run out of crawling your site. Ensure that your scripts are fast, and Google would not have to wait too long to download them. For those who want to learn more about this, I recommend reading this material on optimizing the page rendering process.
Poor search engine optimization and SEO, taking into account the features of sites based on JavaScript
I want to raise here the problem that can affect even the best search engine optimization sites.
The traditional approach to SEO and SEO, taking into account the features of JS
It is important to remember that SEO taking into account the features of JavaScript is performed on the basis of traditional search engine optimization. It is impossible to optimize the site well, taking into account the peculiarities of JS, without achieving decent optimization in the usual sense of the word. Sometimes, when you encounter an SEO problem, your first impression may be that it is related to JS, although, in fact, the problem is in traditional search engine optimization.
I will not go into the details of such situations, as Justin Briggs already perfectly explained in his material “ Core Principles of SEO for JavaScript ”, in the section “Confusing Bad SEO with JavaScript Limitations”. I recommend reading this useful article.
Since the second quarter of 2018, Googlebot will not use AJAX scanning
Google has announced that since the second quarter of 2018, it will no longer use AJAX Crawling Scheme. Does this mean that Google will stop indexing sites using Ajax (asynchronous JavaScript)? No, it is not.
It is worth saying that AJAX scanning appeared in the days when Google realized that more and more sites use JS, but could not properly handle such sites. In order to solve this problem, webmasters were offered to create special versions of pages intended for a search robot and not containing JS scripts. Addresses
_=escaped_fragment_= should be added to the addresses of these pages.In practice, it looks like this: users work with a full-fledged and pleasant-looking
example.com variant, and Googlebot is visited by a not so nice equivalent of the site, to which a link like example.com?_=escaped_fragment_= leads (this, by the way, is still very popular approach to preparing materials for bots).This is how it works (image taken from the Google blog).
Different versions of the site for users and bots
Thanks to this approach, webmasters got the opportunity to kill two birds with one stone: both users are happy and the search robot is happy. Users see a version of the site equipped with JavaScript capabilities, and search engines can properly index the pages of this site, since they only get the usual HTML and CSS.
About AJAX scan problems
The problems of the Ajax Crawling Scheme lie in the fact that since users and search robots get different versions of the site, it is very difficult to analyze the problems associated with indexing sites. In addition, some webmasters had problems with preliminary preparation of versions of pages intended for the search robot.
That is why Google has announced that starting from the second quarter of 2018, webmasters no longer need to create two different versions of the website:
AJAX Scan Disable Message
How will this affect web developers?
- Google will now form the site pages by its own means. This means that developers need to ensure that Google has the technical ability to do this.
- Googlebot will stop visiting links containing
_=escaped_fragment_=and will begin to request the same materials that are intended for regular users.
In addition, developers will need to find a way to make their sites accessible to Bing and other search engines, which are far behind Google in processing JavaScript-based sites. Possible solutions include server rendering (universal JavaScript), or, oddly enough, continued use of the old AJAX scan for Bingbot. We will discuss this below.
Will Google use the most modern browser for page processing?
It is not clear whether Google plans to update its site processing service in order to support the latest technologies. We can only hope that this will be done.
How to be to those who do not want Google to process its pages based on JS, and was content with only pre-prepared pages?
I thought a lot about it, and that is why I decided to ask John Muller on the JavaScript SEO forum about whether I can find Googlebot on the
User-Agent and just give it a pre-prepared version of the site.A question to John Muller about the site version prepared specifically for Googlebot
Here is what he said:
John Muller's Answer
John agrees that a developer can find out that his site is crawling Googlebot by checking the
User-Agent header and giving it a pre-prepared HTML snapshot of the page. In addition to this, he advises regularly checking page snapshots in order to be sure that the preliminary rendering of the pages works correctly.Do not forget about Bing!
Imagine that Googlebot handles sites based on JS frameworks perfectly and you have no difficulties with it. Does this mean that you can forget about all the problems associated with indexing such sites? Unfortunately - does not mean. Let us recall the search engine Bing, which, in the United States, employs about a third of Internet users.
At present, it will be reasonable to assume that Bing does not handle JavaScript at all (there are rumors that Bing handles JS on highly rated pages, but I could not find a single confirmation of these rumors).
Let me tell you about one interesting study.
Angular.io is the official website of Angular 2+. Some pages of this site are created as one-page applications. This means that their HTML source does not contain any content. After loading such a page, an external JS-file is loaded, by means of which the content of the pages is formed.
Angular.io website
There is a feeling that Bing does not see the contents of this site!
Bing does not see the contents of the site Angular.io
This site is ranked second for the keyword "Angular" in Bing.
How about the query "Angular 4". Again - the second position, below the site AngularJS.org (this is the official site of Angular 1). At the request of "Angular 5" - again the second position.
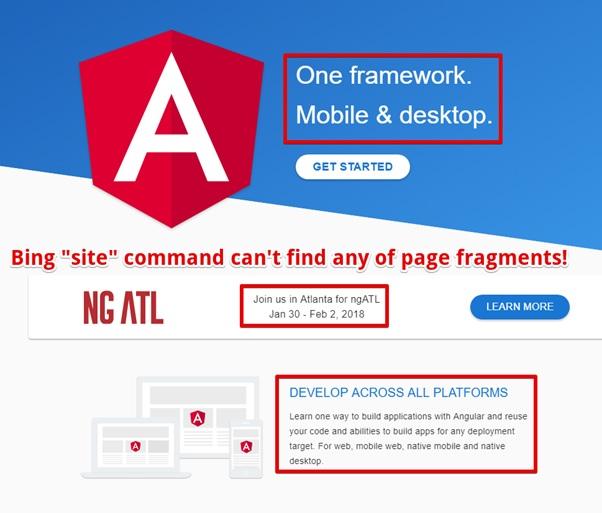
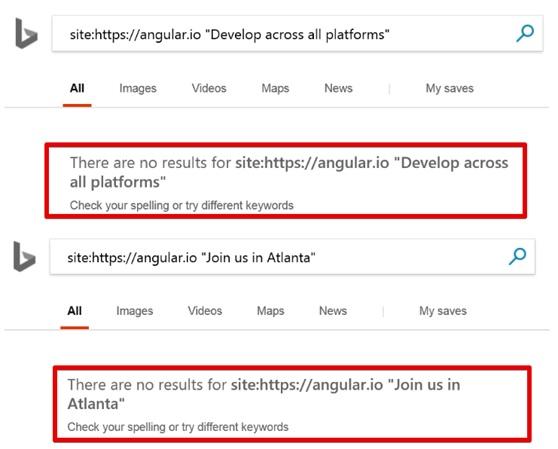
If you need evidence that Bing cannot work with Angular.io - try to find any piece of text from this site using the
site command. You will not succeed.Choosing a piece of text to check
Text when searching the site could not be found
For me, it's so strange. It turns out that the official website Angular 2 can not be properly scanned and indexed by the robot Bingbot.
What about Yandex? Angular.io is not even in the top 50 results when searching for the word “Angular” in Yandex!
Angular.io site in Yandex
On Twitter, I turned to the Angular.io team, asked them if they were planning to do something so that their website could be indexed by search engines like Bing, but at the time of writing this material, they hadn’t answered me yet.
As a matter of fact, from the foregoing it can be concluded that, in an effort to introduce new web technologies on your websites, you should not forget about Bing and other search engines. Here we can recommend two approaches: isomorphic JavaScript and pre-rendering.
Preview Rendering and Isomorphic JavaScript
When you notice that Google is having trouble indexing your site, which is being rendered on the client, you can consider using pre-rendering or converting the site to an isomorphic JavaScript application.
Which approach is better?
- Preview rendering is used when you notice that search engines are unable to correctly form the pages of your website and you perform this operation yourself. When the robot visits your site, you simply give it HTML-copies of pages (they do not contain JS-code). At the same time, users get versions of pages equipped with JS features. Copies of pages are used only by bots, but not by regular users. For pre-rendering pages, you can use external services (like prerender.io), or use tools like PhantomJS or Chrome without a user interface on your servers.
- Isomorphic JavaScript is another popular hike. When applied, both the search engine and users, when they first load the page, get all the necessary data. Then JS-scripts are loaded that already work with these pre-loaded data. This is good for ordinary users and search engines. This option is recommended for use, it is supported even by Google.
Google recommends isomorphic javascript
However, there is one problem, which is that many developers cannot correctly create isomorphic JavaScript applications.
If you are attracted to server rendering, see the documentation for the JS framework you are using. For example, in the case of Angular, you can apply Angular Universal . If you are working with React, read the documentation and watch this tutorial on Udemy.
React 16 (it was released in November) brought a lot of improvements to the server rendering area. One of these improvements is the
RenderToNodeStream function, which simplifies the entire server rendering process.If we talk about the general approach to server rendering, I would like to note one important recommendation. It is that if you want a site to be rendered on a server, developers should avoid using functions that directly affect the DOM.
Whenever possible, think twice before working directly with the DOM. If you need to interact with the browser DOM - use Angular Renderer or rendering abstraction.
Does Googlebot handle HTML and JS sites in the same way?
We, at Elephate, conducted some experiments in order to find out how deeply Googlebot can advance in finding links and navigating through them in the case of crawling websites that use only HTML, and websites based on JavaScript.
The study gave amazing results. In the case of an HTML site, Googlebot was able to index all pages. However, when processing a JS-based site, the situation was quite ordinary when Googlebot did not even get to its second level. We repeated the experiment on five different domains, but the result was always the same.
Experiment in indexing HTML sites and JS-based sites
Bartosh Goralevich turned to John Muller from Google and asked him about the sources of the problem. John confirmed that Google sees links generated by JavaScript, but " Googlebot does not want to crawl them. " He added : “We do not scan all URLs, or we scan all of them quickly, especially when our algorithm is not sure of the value of the URL. The value of the content is an ambiguous aspect of test sites. ”
If you want to delve into this topic, I recommend looking at this material .
Details about the experiment on indexing test sites
I want to share some of my ideas about the above experiment. So, it should be noted that although the studied sites were created only for experimental purposes, the same approach was applied to their content. Namely, their texts were created by means of Articoolo - an interesting content generator based on artificial intelligence technologies. He gives out pretty good lyrics that are definitely better than my writing.
Googlebot received two very similar websites and scanned just one of them, preferring the HTML site to the site that uses JS. Why is this so? Put forward several assumptions:
- Hypothesis №1. Google’s algorithms classified both sites as test sites, and then assigned them a fixed execution time. Let's say it could be something like indexing 6 pages, or 20 seconds of working time (loading all resources and forming pages).
- Hypothesis №2. Googlebot classified both sites as test sites. In the case of the JS site, he noted that the loading of resources takes too much time, so I simply did not scan it.
There are many high-quality real links to the above websites. Many people willingly shared links to them on the Internet. In addition, they received organic traffic. And then the question arises of how to distinguish a test site from a real one. This is not an easy task.
There is a great chance that if you create a new website that is rendered on the client, you will be in the exact same situation as we are. Googlebot, in this case, simply won’t scan it. This is where the theory ends and the real problems begin. In addition, the main problem here is that there is practically no real life example, when a website, or an online store, or a company page that uses client rendering, occupy a high position in search results. Therefore, I can not guarantee that your site, filled with JavaScript capabilities, will get as high a position in the search as its HTML equivalent.
You can decide that, for sure, most SEO specialists know this anyway, and large companies can spend some money on tackling these problems. However, what about small companies that do not have the means and knowledge? This can be a real danger for something like the sites of small family restaurants that use client-side rendering.
Results
Let us briefly summarize the conclusions and recommendations in the following list:
- Google uses Chrome 41 for rendering websites. This version of Chrome was released in 2015, so it does not support all the modern features of JavaScript. You can use Chrome 41 to see if Google can properly process your pages. Details on using Chrome 41 can be found here .
- It is usually not enough to analyze only the source HTML code of the site pages. Instead, take a look at the DOM.
- Google is the only search engine that widely uses JavaScript rendering.
- Do not use the Google cache to check how Google indexes the content of pages. Analyzing the cache? you can only see how your browser interprets the HTML data that Googlebot collected. This is not related to how Google processes this data before indexing.
- Use the Fetch and Render tools regularly. However, do not rely on their timeouts. When indexing, completely different timeouts can be used.
- Master the
sitecommand. - Make sure the menu items are present in the DOM before the user clicks the menu.
- Google's algorithms are trying to determine the value of a resource in terms of the expediency of processing this resource to form a page. If, according to these algorithms, the resource is of no value, Googlebot may not download it.
- - , ( , Google , , 5 ). , . , !
- Google , JavaScript, HTML. , Google, , .
- , , . , ?
SEO , ( !) Google , JavaScript , , HTML. , , SEO- , JS- , , , . , SEO JavaScript- . - . , , JavaScript, , SEO .
Dear readers! , , , JS-?
Source: https://habr.com/ru/post/351058/
All Articles