Fantastic-Elasticsearch. How we "tamed" smart search through documents
Full-text search allows you to search for documents by text content. Such a need may arise when the system contains many text entities, and users are required to take this data into account during the search. We are faced with a similar situation when developing a solution for workflow *. System data is stored in MS SQL Server or PostgreSQL, and a flexible attribute search allows you to find documents on various meta-information. However, over time, this was not enough. We were faced with a task: to learn how to search for documents by text properties and attached files.

The problem is that full-text search is supported by SQL server only for a fee and does not provide the flexibility we need. At this moment the search engines come on the scene. There are different full-text search systems, for example: Sphinx, Solr or Elasticsearch; but our choice was the last one. In general, we have a large dynamic database of documents, Elasticsearch and the desire of customers to have a web-interface for full-text search. As well as auto-completion, hints, facets and other features that are close to the functionality of an online store. An article about how we solved this problem.
* The system of documentation management "Priority" on the platform Docsvision
Architecture
In the Elasticsearch database, the tables are called indexes, and the document loading process is called indexing. To index data from the main repository, a special service was written in Elasticsearch. It is a Windows service, in addition to which the admin utility is running. The utility sets the necessary settings, creates indexes and starts loading documents into the database.
However, at the stage of data indexing, we encountered a problem. The system is dynamic, and thousands of changes occur every minute in the documents. The indexing service must maintain Elasticsearch data in a state as close as possible to the current state of affairs. Therefore, a new entity appears in the SQL database - a queue of documents for indexing. Every N minutes, the special job finds all documents that have been changed since the previous execution and adds their identifiers to the queue. As a result, the service will update in the indices only the documents that require it.
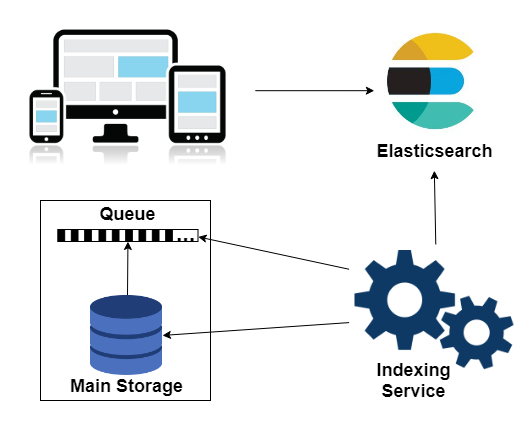
Technology stack
Search engine. Elasticsearch 5.5
Plugins analysis morphology and ingest-attachment
Service. Written in C #. Libraries for interaction with the engine: NEST and ElasticsearchNET.
Frontend. Angular 4
Loading settings
Administrator's utility is a part of the service, with the help of which the types of documents and fields to be indexed are selected. After that, data schemes are loaded into Elasticsearch (in the ES ecosystem they are called mappings). This is necessary in order to set their own settings for different fields, which will be taken into account when indexing documents. In addition, the utility saves the selection results to the database.
Mapping Formation
Mappings are generated dynamically using the NEST library. Each type of system data is assigned an Elasticsearch data type. The database also maintains a hierarchical structure of documents. This corresponds to the object and nested data types (for arrays).
var sectionProperty = section.SectionType == SectionType.Struct ? new ObjectProperty { Name = section.Name } : new NestedProperty { Name = section.Name }; Text field analysis
Elasticsearch provides great opportunities for full-text search. It can take into account word forms, skip stop words, use the morphology of the language. To do this, at the stage of mapping formation, you need to specify the correct analyzer for text fields that require it. These settings are also specified in the admin utility.
The analyzer includes three stages: the transformation of individual characters, the division of characters into tokens and the processing of these tokens. In our case, character filtering is not required. We use a standard tokenizer, which works out of the box for most cases. The key link in the Russian language analyzer is the official analysis-morphology plugin. It provides a token filter that allows you to search for word forms. We also reduce all words to lower case and use our own set of stop words.
var stopFilter = new StopTokenFilter { StopWords = new StopWords(StopWordsArray) }; var filters = new TokenFilters { { "my_stopwords", stopFilter } }; var rusAnalyzer = new CustomAnalyzer { Tokenizer = "standard", Filter = new[] { "lowercase", "russian_morphology", "my_stopwords" } }; var analazyers = new Analyzers { { "rus_analyzer", rusAnalyzer } }; var analyzis = new Analysis { Analyzers = analazyers, TokenFilters = filters }; Settings for files
In Elasticsearch version 5.0, a new entity has appeared - the Ingest node. Such nodes are used to process documents before they are indexed. To do this, create a pipeline ( pipeline ) and add processors ( processor ). Any of your nodes can be used as ingest. Or you can select a separate node for primary processing.
Many documents of our system contain text files. Full-text search should be able to work on their content. To implement this, we used the Ingest Attachment plugin, which uses the recently introduced pipeline technology. Let us define a processor, which for each document file uses a processor that is accessible thanks to the plugin. The essence of this processor is to extract text from a Base64 line into a separate field. All that remains is for us: during indexing, get the Base64 line on the file and get into the mapping. In the processor, we indicate which field contains the file ( Field ) and where to place the text ( TargetFiled ). Setting IndexedCharacters limits the length of the file being processed (-1 removes restrictions).
new PutPipelineRequest(pipelineName) { Processors = new List<ProcessorBase> { new ForeachProcessor { Field = "Files", Processor = new AttachmentProcessor { TargetField = "_ingest._value.attachment", Field = "_ingest._value.RawContent", IndexedCharacters = -1 } } } }; Indexing
The task of the service is to continuously retrieve new objects from the queue and index the relevant documents. In this process, we are not using the NEST object model, but the low-level ElasticsearchNet library. It provides a database interaction interface via JSON. Objects are formed dynamically by traversing the depth of the hierarchical structure of the document. To do this, use the well-known library NewtonsoftJson.
client.LowLevel.IndexPut<string>(indexName, typeName, documentId, json); Indexing is implemented multithreadedly with parallel processing of each document. The formation of JSON takes an order of magnitude longer than its indexing. Therefore, the API is used to index individual documents, not the Bulk API, in which an array of documents is loaded into ES in one call. In this case, the indexing would occur at the rate of formation of JSON for the largest document.
File indexing
Files are indexed along with the rest of the data as part of a JSON object. All you need to do is convert the byte stream to a Base64 string. This is done using standard library tools. In addition, it is necessary that the files fall under the definition of the processor. Otherwise, the magic will not happen, and they will remain the usual Base64 line. To use a pipeline when indexing, change the method call.
client.LowLevel.IndexPut<string>(indexName, typeName, documentId, json, parameters => parameters.Pipeline(pipelineName)); Autocompletion
Autocomplete prompts you to continue the line as you type.

In our case, the autocompet should work on those text fields that have been marked with the appropriate flag in the admin utility. At the stage of loading mappings, a separate index is created for all complementary rows. This is due to the fact that the search should work on multiple indexes. Mapping is formed with a special type field completion .
var completionProperty = new CompletionProperty { Name = "autocomplete", Analyzer = "simple", SearchAnalyzer = "simple" }; When indexing documents, the text that is needed for autocompletion is broken down into sets of terms and loaded into the index. Terms should satisfy regular expression - it is important for us to select words that are not too short and consist only of letters. Sets are sequentially shifted by one term, so for each word there will be a line in the index that starts with it. The length of the set is bounded above; we use a completeSize of four.
var regex = new Regex(pattern, RegexOptions.Compiled); var words = regex.Matches(text); for (var i = 0; i < words.Count; i++) { var inputWords = words.OfType<Match>().Skip(i).Take(completeSize).ToArray(); var wordValues = inputWords.Select(x => x.Value).ToArray(); var output = string.Join(" ", wordValues); // JSON } During the search for autocompletion, a separate query works. With each character entered, the database is accessed with the corresponding substring. Requests to Elasticsearch are json objects. To get autocomplete, we only need the block suggest . It includes the Completion Suggester , which allows you to quickly search for a prefix. It works only for completion fields. We will meet with other sadzhester when we discuss typos.
{ "suggest": { "completion_suggest": { "text": " ", "completion": { "field": "autocomplete", "size": 10 } } } } Search
The basic part of the interface is the search line. When a user enters characters, two queries are processed: for auto-completion and for search. According to the results of the first of them there are hints for the continuation of printing, and on the second - issuing documents. The search query consists of several blocks, each of which is responsible for different properties.
Full text search
The query block corresponds to the search part of the query. Thanks to him, selected documents that will fall into the issue. Other important query blocks are applied to these results. query can have subqueries that are connected using boolean operations. To do this, we define a bool block. It can include four types of conditions: must , filter , must_not , should . In our query, the condition is should , which corresponds to a logical OR. It combines several full-text subqueries. We’ll go back to the filter block a bit later, but for the time being we think that we are looking for all the documents.
{ "query": { "bool": { "filter": [], "should": [ // ] } } // } For full-text search, the multi_match block is used . The text from the query parameter is searched for in several fields at once, which are specified in the fields parameter. In response to the request, a list of documents is returned, each of which has a certain score . The better the document matches the request, the higher this number. The multi_match query does not consider the text as a single phrase, but searches for individual terms. Add a similar block, but with the phrase parameter, which implements the necessary functionality. To ensure that documents with a match for the phrase are valued higher, we indicate the parameter boost . It multiplies the score of the document by the specified number.
{ "multi_match": { "query": " ", "fields": [ "FieldName" ] } }, { "multi_match": { "query": " ", "fields": [ "FieldName" ], "type": "phrase", "boost": 10 } } Among the pitfalls can be noted search among the objects in the array. When creating a mapping, we marked some fields as nested . This means that they are arrays of objects. To search for any fields of these objects, you need a separate subquery, which is called nested . It is necessary to specify the path to the array ( path ) and the request itself. If you are looking for a single index, then this will be enough. However, in our case, the search works simultaneously on several indices, and if there is no such path in any of them, ES will return an error. Therefore, a nested query must be enclosed in an indeces block and indicate in which index to search. To clearly show that no search is needed for the rest of the indexes, write " no_match_query ": " none ".
{ "indices": { "index": "indexName", "query": { "nested": { "path": "PathToArray", "query": { "multi_match": { "query": " ", "fields": [ "PathToArray.FieldName" ] } } } }, "no_match_query": "none" } } Highlights
Elasticsearch provides a nice way to highlight text found in a document upon request.

To do this, add a new block request: highlight . In fields we list the fields for which the highlight should be returned. Specify in the pre_tags and post_tags parameters which characters to select words with. If the search works on a large text field (for example, a file), Elasticsearch returns the highlights not together with the entire field, but inside a small passage. As a result, the engine did all the work for us: and highlighted the coincidences in bold, and highlighted the context.
{ "highlight": { "pre_tags": [ "<b>" ], "post_tags": [ "</b>" ], "fields": { "FieldName": {} } } } Despite all the convenience of this feature, we are faced with a serious problem when working with it. If the highlight has worked on the object in the array, then the response to the request cannot be determined to which object it belongs. Files are stored in an array, and file highlighting is one of the key requirements of the customer. The logical solution to this problem is to create a set of fields of the form File_i , where i will cover a reasonable number of attached files. Then, by the highlight, it will become clear which index has the file, and from the search results you can take the file name from this index.
However, it turned out that not everything is so simple. The base64-to-text conversion processor can only work on an array with like fields. Thanks to the help on the discuss.elastic.co forum, a solution was found: add another processor, which, after being converted into text, renames the fields to the desired form. Processor Code:
"script": { "lang": "painless", "inline": """for (def i = 0; i < ctx.Files.length; i++) { def f = 'File' + (i+1); ctx.Files[i][f] = ctx.Files[i].attachment; ctx.Files[i][f].Name = ctx.Files[i].Name; for (def rf : ['attachment', 'Name']) { ctx.Files[i].remove(rf); } }""" } Sajesta
Sometimes the user makes typos when entering a request. In this case, the search results will be empty. However, Elasticsearch may suggest a possible error.

This functionality is implemented at the expense of the block suggest . We already met with him when we discussed auto-completion, but another type of sadgetster is used to handle typos. It is called a phrase and looks for mistakes, considering the entire phrase, not individual words. We indicate the number of prompts in the results ( size ), the search fields ( field ) and the number of possible typos in the phrase ( max_errors ). To cut off undesirable results, add a subquery ( collate ), which checks that the received sadest is contained in at least one index field. Also hints support the built-in highlight, which highlights the word with an error.
{ "suggest": { "my_suggest": { "text": " ", "phrase": { "size": 1, "field": "_all", "max_errors": 4, "collate": { "query": { "inline": { "match": { "{{field_name}}": { "query": "{{suggestion}}", "operator": "and" } } } }, "params": { "field_name": "_all" } }, "highlight": { "pre_tag": "<b>", "post_tag": "</b>" } } } } } Facets
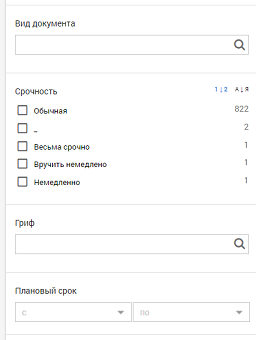
Another interesting feature that can be implemented using Elasticsearch. Facets are called aggregation blocks, which can often be seen in online stores. Add the aggs block to the request . The most common type of aggregation that can be added to this block is called terms . The results will contain all the unique values of the corresponding field and the number of documents in which they are found. It is important that aggregations do not apply to the entire set of documents, but only to those that satisfy the search query. Therefore, when entering text, the contents of the facets will dynamically change.
{ "aggs": { "types": { "terms": { "field": "TypeField" } }, "min_date": { "min": { "field": "DateField" } } } } For the complete implementation of the facets, it remains to add a filtering block to the search query. By this we limit the search to only those parameters of the documents that were selected in the facets. In the filter block, add a subquery for each filter block.
{ "terms" : { "TypeField" : [ /* */] } }, { "range" : { "DateField" : { "gte" : /* */ } } } Total
This is what the whole picture looks like.
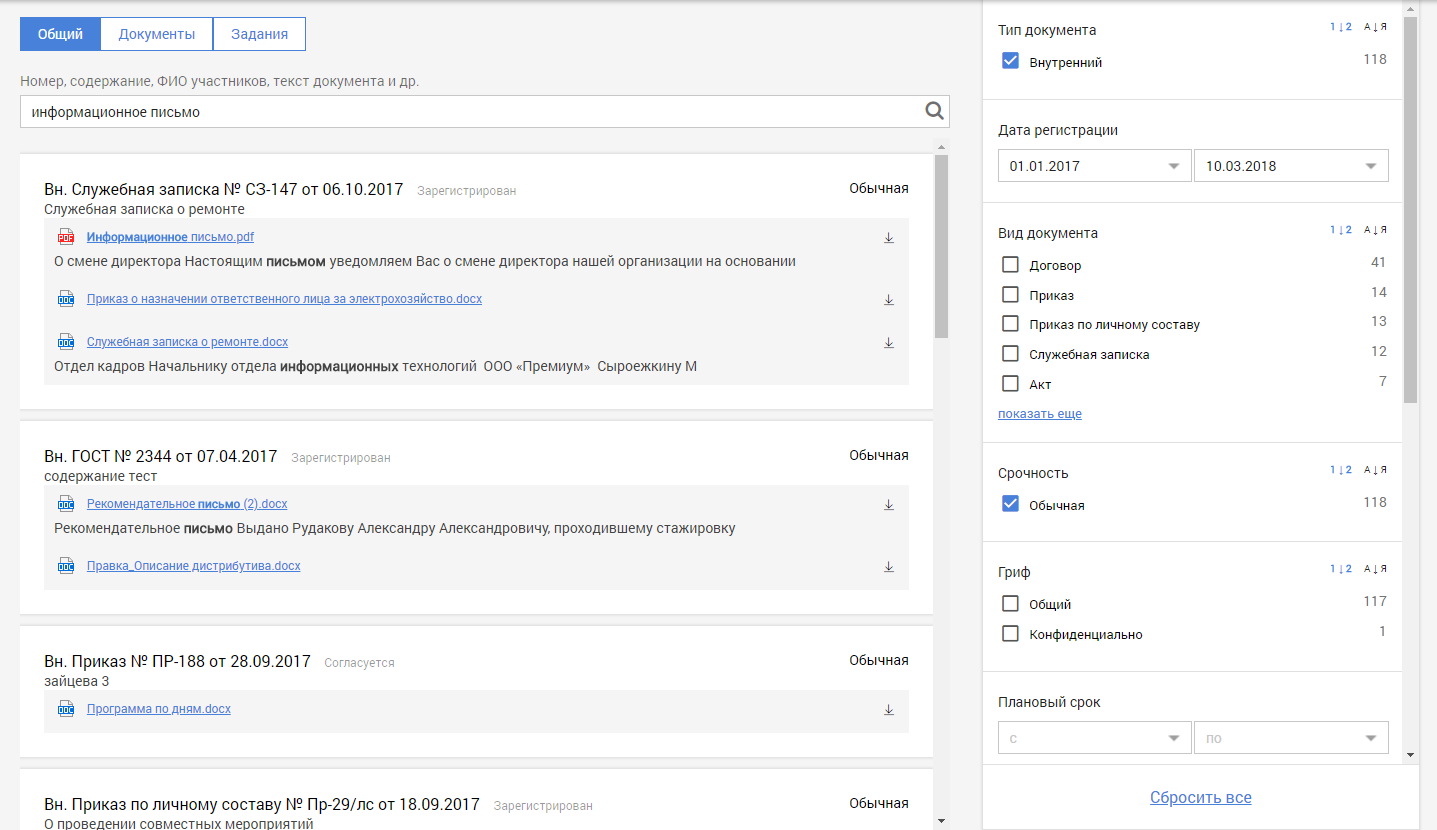
Indexing statistics
Currently the pilot version uses the configuration:
2 servers:
CPU : intel Xeon Platinum 8160 (10 cores)
RAM : 40 GB
The volume of indices : 260 GB
Number of documents in indices : 600 thousand
Indexing speed : 5000 doc / h
')
Source: https://habr.com/ru/post/351002/
All Articles