Java and Project Reactor

Hello! My name is Lyokha, and I work as a back-end developer at FunCorp. Today we will talk about reactive programming, the Reactor library and a little about the web.
Reactive programming is often “mentioned”, but if you (as well as the author of the article) still do not know what it is - get comfortable, try to figure it out together.
What is reactive programming?
Reactive programming is the management of asynchronous data streams. Just like that. We are impatient people and do not delve into all your manifestos with details , but would be worth it.
And here the web?
It is rumored that if you build your system reactively, according to all the canons of Reactive Manifesto, starting with the HTTP server and ending with the database driver, you can call the second coming. Well, or at least build a really high-quality backend.
This, of course, easy slyness. But if your use case is the processing of multiple and not always fast requests, and the servlet container stops coping - welcome to the wonderful world of reactive!
If you have 128 parallel parallel requests for a job.
And what to write reactively, if not on Netty ? It is worth noting that writing a backend on a bare Netty is tiring and it's nice to have abstractions for work.
There are not many good server abstractions for Netty, so the guys from Pivotal have added support to it in Spring Boot 2 . March 1, 2018, all this even broke out . To make us completely happy, they created the WebFlux module, which is an alternative to Spring MVC and is a reactive approach for writing web services.
WebFlux positions itself as a microframe (microfreemvork and Spring, haha), promises to fit into these your (our) trendy microservices, represents the API in a functional style and has already been mentioned on Habré . More details (including differences from Spring MVC) can be found here . But today is about something else. At the core of WebFlux is the Reactor library. About her and talk.
Reactor is a reactive (all of a sudden!) Open-source platform developed by Pivotal. I decided on a free retelling (with comments) of an introduction to this wonderful library .
Go.
Blocking code (for the smallest)
Java code is usually blocking. For example, calls over HTTP or requests to the database hang our current thread until a third-party service answers us. This is normal practice if the service is responsible for a reasonable time. Otherwise, this case turns into a bottleneck. We have to parallelize it, run more threads that will execute the same blocking code. Along the way, you have to solve emerging problems with contention and competitiveness.
Frequent blocking, especially because of I / O (and even if you have a lot of mobile clients, not at all a fast I / O ), causes our many threads to sit down while waiting for data, spending precious resources on context switching and all that.
Parallelization is not a magic wand that solves all problems. This is a complex tool that carries its overhead.
Async && non-blocking
These terms are easy to find, difficult to understand and impossible to forget. But they often figure when it comes to reactivity, so let's try to understand them.
From the text above, we can conclude that the blocking code is to blame. Ok, let's start writing non-blocking. What is meant by this? If we are not yet ready to give the result, then instead of waiting for it, we give some error, for example, with a request to repeat the request later. Cool, of course, but what do we do with this error? So we have asynchronous processing, to respond to the answer later: everything is ready!
So, you need to write asynchronous and non-blocking code, and everything will be fine with us? No, it will not. But it can make life easier. For this, kind and intelligent people have invented all sorts of specifications (including reactive ones) and filed libraries that these specifications respect.
So, Reactor. If very short
In fact, Reactor (at least its core part) is the implementation of the Reactive Streams specification and parts of ReactiveX operators . But more on that later.
If you know or heard about RxJava, then Reactor shares the approach and philosophy of RxJav, but has a number of semantic differences (which grow due to backward compatibility from RxJava and the features of Android development).
What is Reactive Streams in Java?
If roughly, then these are 4 interfaces that are represented in the library reactive-streams-jvm :
- Publisher;
- Subscriber;
- Subscription;
- Processor.
Exact copies of them are present in the class Flow of nine .
If it is even more rude, then the following requirements are put forward to all of them:
- ASYNC - asynchrony;
- NIO - non-blocking I / O;
- RESPECT BACKPRESSURE - the ability to handle situations where data appears faster than they are consumed (in a synchronous, imperative code, a similar situation does not arise, but this is often found in reactive systems).
Let's take a look at the Flow class code from JDK 9 (Javadoc comments have been removed for brevity):
public final class Flow { public static interface Publisher<T> { public void subscribe(Subscriber<? super T> subscriber); } public static interface Subscriber<T> { public void onSubscribe(Subscription subscription); public void onNext(T item); public void onError(Throwable throwable); public void onComplete(); } public static interface Subscription { public void request(long n); public void cancel(); } public static interface Processor<T,R> extends Subscriber<T>, Publisher<R> { } } So far this is all support for reactivity at the JDK level. Somewhere in the incubator module, an HTTP / 2 client is ripening, in which Flow is actively used. I did not find any other uses inside JDK 9.
Integration
Reactor is integrated into our favorite Java 8 Pribluds, including CompletableFuture, Stream, Duration. Supports IPC modules . It has adapters for Akka and RxJava , test modules (obviously, for writing tests) and extra (utility classes).
For lovers of Redis, lettuce / redisson customers have a reactive API with Reactor support.
For MongoDB lovers, there is an official jet driver that implements Reactive Streams, and therefore it is easily picked up by Reactor.
Great, but how to start all this?
All this can be run on JDK8 and up. However, if you are using Android and yours (minSdk <26), then better look at RxJava 2.
<dependencyManagement> <dependencies> <dependency> <groupId>io.projectreactor</groupId> <artifactId>reactor-bom</artifactId> <version>Bismuth-RELEASE</version> <type>pom</type> <scope>import</scope> </dependency> </dependencies> </dependencyManagement> <dependencies> <dependency> <groupId>io.projectreactor</groupId> <artifactId>reactor-core</artifactId> </dependency> </dependencies> plugins { id "io.spring.dependency-management" version "1.0.1.RELEASE" } dependencyManagement { imports { mavenBom "io.projectreactor:reactor-bom:Bismuth-RELEASE" } } dependencies { compile 'io.projectreactor:reactor-core' } BOM serves to ensure better compatibility of various Reactor pieces. There is no native BOM support in Gradle, so you need a plugin .
Fittings
So, we need to write asynchronous and non-blocking code. In other words, to allow the current thread of execution not to block and wait, but to switch to something useful by returning to the current process when the asynchronous processing is complete.
On a sunny island called Java, there are two main ways to do this:
Callbacks. In the case of callbacks, the method has no return value (void), but it takes an additional parameter (lambda, anonymous class, etc.) that is called after a certain event. An example is EventListener from the Swing library.
- Futures. This is an object that promises to return something in the future. In Future, there is a reference to the <T> object, the value of which will be calculated later (asynchronously). Future can block to wait for the result. Let's say ExecutorService on submit () returns you Future <T> from Callable <T>.
These are well-known tools, but at some point they are not enough.
Problems with callbacks
Callbacks are difficult to compose and quickly turn into a jumble called "callback hell".
Let's look at an example
You need to show the user 5 top memes, and if they are not, then go to the service offers and take 5 memes from there.
Total 3 services are involved: the first one gives the ID of the user's favorite memes, the second one fetches the memes themselves, and the third one gives the offers if there are no favorite memes.
// userService.getFavoriteMemes(userId, new Callback<>() { // public void onSuccess(List<String> userFavoriteMemes) { if (userFavoriteMemes.isEmpty()) { // , suggestionService.getSuggestedMemes(new Callback<>() { public void onSuccess(List<Meme> suggestedMemes) { uiUtils.submitOnUiThread(() -> { suggestedMemes.stream().limit(5).forEach(meme -> { // UI })); } } public void onError(Throwable error) { uiUtils.errorPopup(error); // UI } }); } else { // userFavoriteMemes.stream() .limit(5) // 5 .forEach(favId -> memeService.getMemes(favId, new Callback<Favorite>() { // public void onSuccess(Meme loadedMeme) { uiUtils.submitOnUiThread(() -> { // UI }); } public void onError(Throwable error) { uiUtils.errorPopup(error); } })); } } public void onError(Throwable error) { uiUtils.errorPopup(error); } }); It looks somehow not cool.
Now let's see how we would do it with Reactor.
// userService.getFavoriteMemes(userId) .flatMap(memeService.getMemes) // ID // , .switchIfEmpty(suggestionService.getSuggestedMemes()) .take(5) // 5 .publishOn(UiUtils.uiThreadScheduler()) // UI- .subscribe(favorites -> { uiList.show(favorites); // UI- }, UiUtils::errorPopup); // 
But what if we suddenly wanted to fall off a 800 ms timeout and load cached data?
userService.getFavoriteMemes(userId) .timeout(Duration.ofMillis(800)) // - // .onErrorResume(cacheService.cachedFavoritesFor(userId)) .flatMap(memeService.getMemes) // ID .switchIfEmpty(suggestionService.getSuggestedMemes()) .take(5) // 5 .publishOn(UiUtils.uiThreadScheduler()) .subscribe(favorites -> { uiList.show(favorites); }, UiUtils::errorPopup); In Reactor, we simply add a timeout operator to the call chain. Timeout throws an exception. With the onErrorResume operator , we specify an alternate (fallback) source from which to take data in case of an error.
Callbacks are 20! 8, we also have a CompletableFuture
We have a list of IDs for which we want to request a name and statistics, and then combine them in the form of key-value pairs, and all this is asynchronous.
CompletableFuture<List<String>> ids = ifhIds(); // CompletableFuture<List<String>> result = ids.thenComposeAsync(l -> { Stream<CompletableFuture<String>> zip = l.stream().map(i -> { // () CompletableFuture<String> nameTask = ifhName(i); // () CompletableFuture<Integer> statTask = ifhStat(i); // return nameTask.thenCombineAsync(statTask, (name, stat) -> "Name " + name + " has stats " + stat); }); // CompletableFuture List<CompletableFuture<String>> combinationList = zip.collect(Collectors.toList()); CompletableFuture<String>[] combinationArray = combinationList.toArray( new CompletableFuture[combinationList.size()]); // Feature allOf CompletableFuture<Void> allDone = CompletableFuture.allOf(combinationArray); // , , allOf Feauture<Void> return allDone.thenApply(v -> combinationList.stream() .map(CompletableFuture::join) .collect(Collectors.toList())); }); List<String> results = result.join(); assertThat(results).contains( "Name NameJoe has stats 103", "Name NameBart has stats 104", "Name NameHenry has stats 105", "Name NameNicole has stats 106", "Name NameABSLAJNFOAJNFOANFANSF has stats 121" ); How can we do this with Reactor?
Flux<String> ids = ifhrIds(); Flux<String> combinations = ids.flatMap(id -> { Mono<String> nameTask = ifhrName(id); Mono<Integer> statTask = ifhrStat(id); //zipWith- return nameTask.zipWith( statTask, (name, stat) -> "Name " + name + " has stats " + stat ); }); Mono<List<String>> result = combinations.collectList(); List<String> results = result.block(); // .. , assertThat(results).containsExactly( "Name NameJoe has stats 103", "Name NameBart has stats 104", "Name NameHenry has stats 105", "Name NameNicole has stats 106", "Name NameABSLAJNFOAJNFOANFANSF has stats 121" ); As a result, we are provided with a high-level API, composable and readable ( in fact, we initially used Reactor for this, because we needed a way to write asynchronous code in the same style ), and other goodies: lazy execution, BackPressure control, various schedulers ( Schedulers) and integration.
OK, what else Flux and Mono?
Flux and Mono are the two main Reactor data structures.
Flux
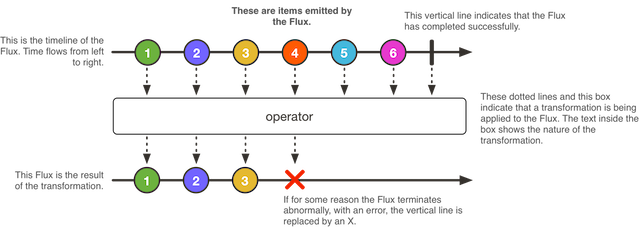
Flux is the implementation of the Publisher interface, is a sequence of 0..N elements, which can (but not necessarily) terminate (including with an error).
A Flux sequence has 3 valid values: a sequence object, a termination signal, or an error signal (calls to the onNext , onComplete, and onError methods, respectively).
Each of the 3 values is optional. For example, Flux can be an infinite empty sequence (no method is called). Or a final empty sequence (only onComplete is called). Or an infinite sequence of values (only onNext is called). Etc.
For example, Flux.interval () returns an infinite sequence of ticks of the type Flux <Long>.
Construction view:
Flux .interval(Duration.ofSeconds(1)) .doOnEach(signal -> logger.info("{}", signal.get())) .blockLast(); Displays the following text:
12:24:42.698 [parallel-1] INFO - 0 12:24:43.697 [parallel-1] INFO - 1 12:24:44.698 [parallel-1] INFO - 2 12:24:45.698 [parallel-1] INFO - 3 12:24:46.698 [parallel-1] INFO - 4 12:24:47.699 [parallel-1] INFO - 5 12:24:48.696 [parallel-1] INFO - 6 12:24:49.696 [parallel-1] INFO - 7 12:24:50.698 [parallel-1] INFO - 8 12:24:51.699 [parallel-1] INFO - 9 12:24:52.699 [parallel-1] INFO - 10 The doOnEach (Consumer <T>) method applies a side effect to each element in the sequence, which is convenient for logging.
Pay attention to blockLast () : the sequence is infinite, the flow in which the call occurs will wait indefinitely for the end
If you're familiar with RxJava, then Flux is very similar to Observable.
Mono
Mono is the implementation of the Publisher interface, is some kind of asynchronous element or its absence Mono.empty () .
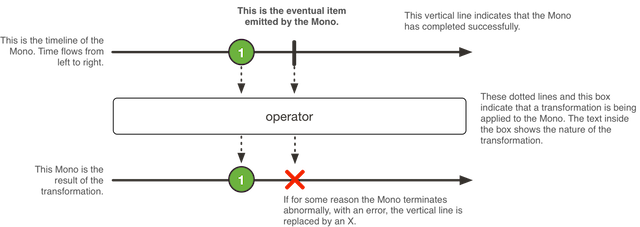
Unlike Flux, Mono can return no more than 1 item. Calls onComplete () and onError () , as in the case of Flux, are optional.
Mono can also be used as some kind of asynchronous task in the “completed and forgotten” style, without a return result (similar to the Runnable). To do this, you can declare it as Mono <Void> and use the operator empty.
Mono<Void> asyncCall = Mono.fromRunnable(() -> { // - // Mono.empty() }); asyncCall.subscribe(); If you are familiar with RxJava, take Mono as a cocktail from Single + Maybe
Why this separation?
Separation on Flux and Mono helps to improve the semantics of the reactive API, making it quite expressive, but not redundant.
Ideally, just by looking at the return value, we can understand what the method does: some kind of call (Mono <Void>), request-response (Mono <T>) or return us a data stream (Flux <T>).
Flux and Mono use their semantics and flow into each other. Flux has a single () method that returns Mono <T>, and Mono has a concatWith (Mono <T>) method that already returns Flux <T>.
They also have unique operators. Some make sense only with N elements in the sequence (Flux) or, on the contrary, are relevant only for one value. For example, Mono has or (Mono <T>) , and Flux has limit / take statements.
More examples
The easiest way to create Flux / Mono is to use one of the many factory methods that are presented in these classes.
Flux<String> sequence = Flux.just("foo", "bar", "foobar"); List<String> iterable = Arrays.asList("foo", "bar", "foobar"); Flux<String> sequence = Flux.fromIterable(iterable); Publisher<String> publisher = redisson.getKeys().getKeys(); Flux<String> from = Flux.from(publisher); Mono<String> noData = Mono.empty(); // Mono Mono<String> data = Mono.just("foo"); // "foo" // // - 5,,7 Flux<Integer> numbersFromFiveToSeven = Flux.range(5, 3); Flux and Mono are lazy. In order to start some processing and take advantage of the data in our Mono and Flux, you need to subscribe to them using .subscribe () .
Subscription is a way to ensure lazy behavior and at the same time indicate what to do with our data. The subscribe methods use lambda expressions from Java 8 as parameters.
subscribe(); // .. // .. - subscribe(Consumer<? super T> consumer); // .. - subscribe(Consumer<? super T> consumer, Consumer<? super Throwable> errorConsumer); // .. - subscribe( Consumer<? super T> consumer, Consumer<? super Throwable> errorConsumer, Runnable completeConsumer ); Flux<Integer> ints = Flux.range(1, 3); ints.subscribe(i -> System.out.println(i)); will output the following:
1 2 3 Flux<Integer> ints = Flux.range(1, 4) .map(i -> { if (i <= 3) { return i; } throw new RuntimeException("Got to 4"); }); ints.subscribe( i -> System.out.println(i), error -> System.err.println("Error: " + error) ); will output the following:
1 2 3 Error: java.lang.RuntimeException: Got to 4 Flux<Integer> ints = Flux.range(1, 4); ints.subscribe(i -> System.out.println(i), error -> System.err.println("Error " + error), () -> {System.out.println("Done"); }); will output the following:
1 2 3 4 Done By default, all this will work out in the current thread. The execution flow can be changed, for example, using the .publishOn () operator, passing the Scheduler we are interested in (Scheduler is such a fad over ExecutorService).
Flux<Integer> sequence = Flux.range(0, 100).publishOn(Schedulers.single()); // onNext, onComplete onError single. sequence.subscribe(n -> { System.out.println("n = " + n); System.out.println("Thread.currentThread() = " + Thread.currentThread()); }); sequence.blockLast(); will print the following (100 times):
n = 0 Thread.currentThread() = Thread[single-1,5,main] What conclusions can be made?
- With all due respect to CompletableFuture, their API, composability and readability leaves much to be desired.
- Using Reactor, we get a way to manipulate asynchronous data streams without locks and suffering.
- Unfortunately, from the backend side there are a number of reasons that still prevent building fully reactive systems (for example, blocking drivers).
- Reactivity does not make your code more productive, but it improves scalability .
- To manage data within the application, Reactor can be used right now.
Here is such an interesting review turned out (no). If you were interested - write, and we delve into what is happening. And do not hesitate to comment!
Thanks for attention!
Based on Reactor documentation
It’s not a bad idea.
I am not here, but there are more worthy men, incl. and contributors / maintainers.
')
Source: https://habr.com/ru/post/350996/
All Articles