Centralized continuous deployment for the year vol 2
In our last article, we talked about how to build a centralized conveyor, but described it rather superficially. This gave rise to a lot of questions that we cannot leave unanswered. Here we will try to get as deep as possible “under the hood” and tell you how our centralized conveyor works.

I think that it is best to describe the whole process from the moment the work begins on the task to the launch of the changes made to the operation. And in the course of the story I will try to answer all the questions that were left unanswered in the last article.
Immediately make a reservation that our development teams enjoy complete freedom in building processes, so it cannot be said that all teams work in exact accordance with the description below. Although, of course, a set of tools imposes certain restrictions. So, to the point.
')
In the bank, the main error tracking system is JIRA. It registers tasks for all modifications, changes, and so on. Developing the task, the developers “cut off” the branch from the main repository and further develop it in it. Below is an example of a fairly typical problem.

When finished with the task, the developer initiates a Bitbucket pull request to make changes to the main branch. And here, for the first time, he encounters a manifestation of the work of the pipeline: pull request starts the process of automatic code revision.
Our audit is performed using the SonarQube integrated into the pipeline through the Sonar for Bamboo and Sonar for Bitbucket plugins. When you register a pull request in Bamboo, the build plan automatically runs, analyzing the branch you want to add. The result of the analysis is displayed directly in the pull request in this form:
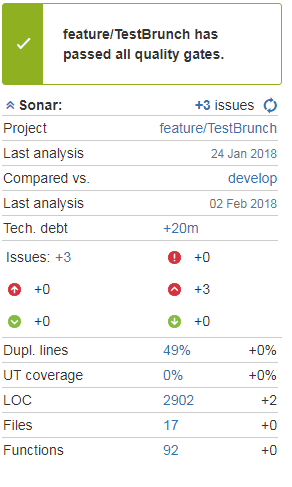
In the form of a pull request, you can immediately see which new notes the code contains, their criticality, category, etc. The comments themselves can be viewed directly from the pull request form, just go to the Diff tab.
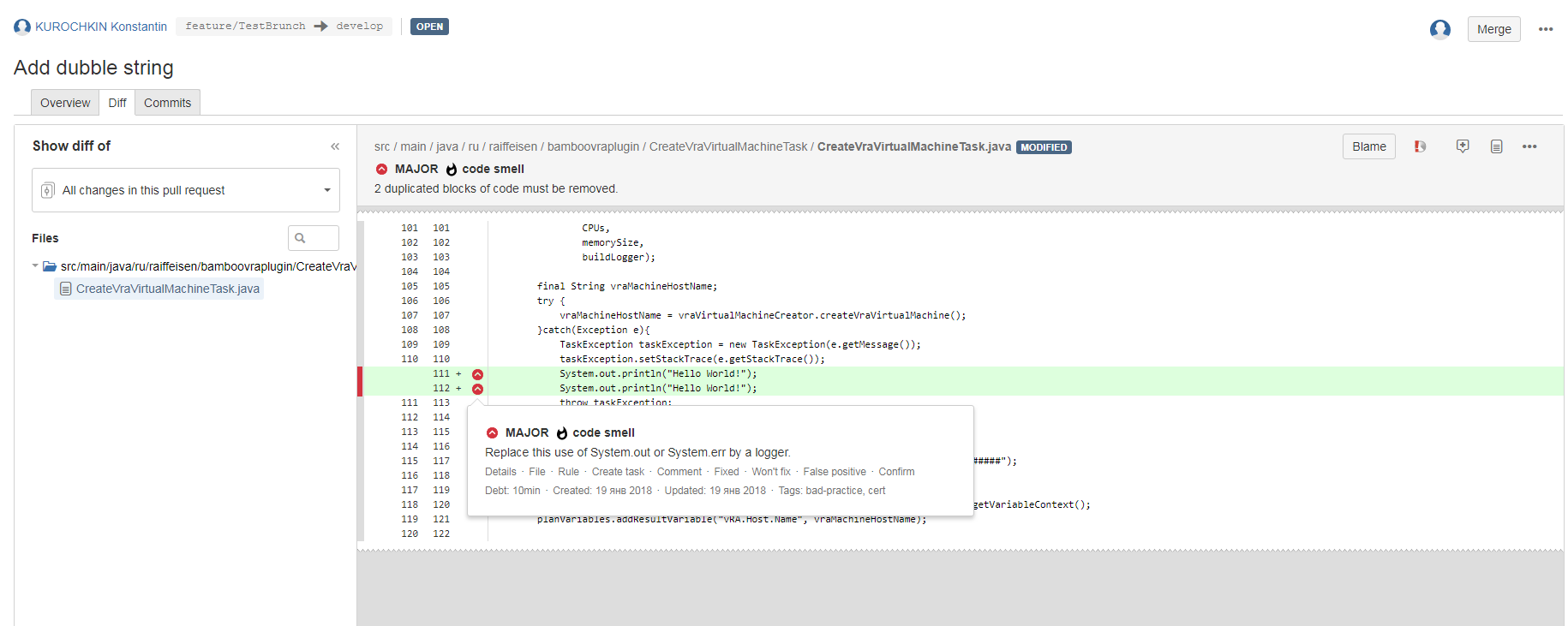
Thus, the code revision process is significantly accelerated and facilitated, plus a fairly large number of settings allows for very flexible adjustment of the behavior of the pipeline both during the audit and in its results. Suppose the audit is completed successfully, and we can move on.
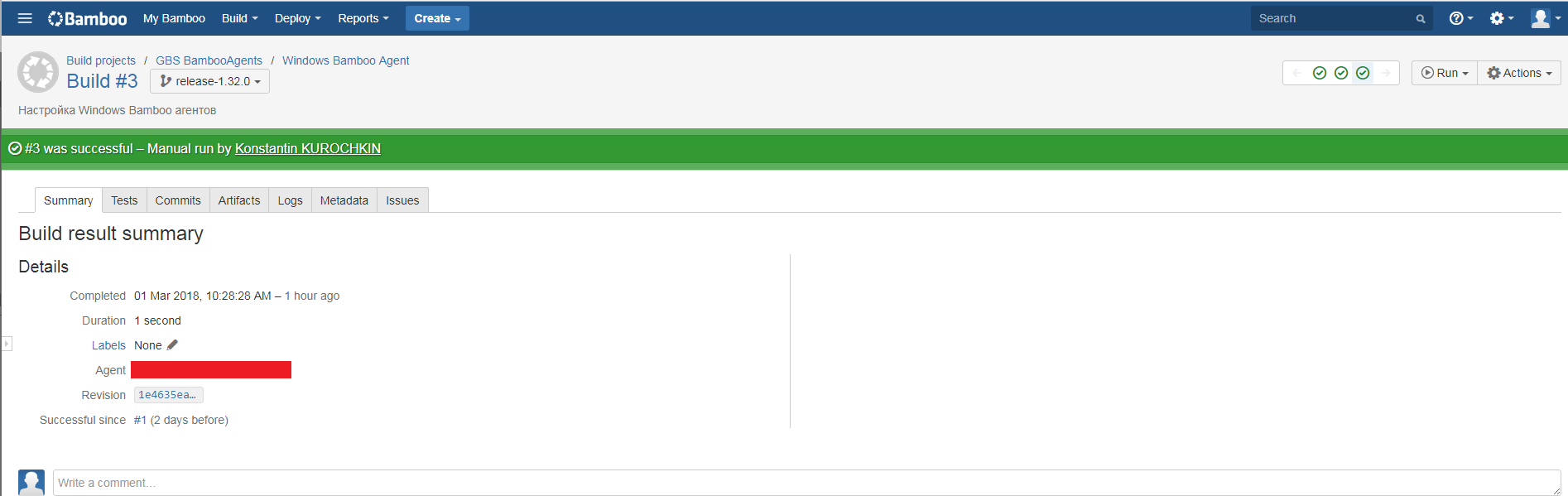
The next step is to build from our code something necessary and useful. Build runs in Bamboo in a variety of ways. You can manually, automatically after a merge or commit in the repository, on a schedule, or even through a call to the Bamboo Rest API. For simplicity and clarity, we consider the most banal option - run the assembly by hand. To do this, go to Bamboo, select the desired plan and press start.
After starting, according to the dependencies indicated in the plan, a suitable agent is selected on which the assembly will be performed. At the moment we have 30 Windows agents, 20 Linux, 2 iOS agents, and 5 more we keep for experiments and pilots. Half of the agents are deployed in our internal cloud, but more on that later. This number allows us to smoothly serve more than 500 active build plans and about a couple of hundred deployment projects.
But back to our assembly plan. The pipeline supports all common build tools, the list of which can be expanded with plug-ins.
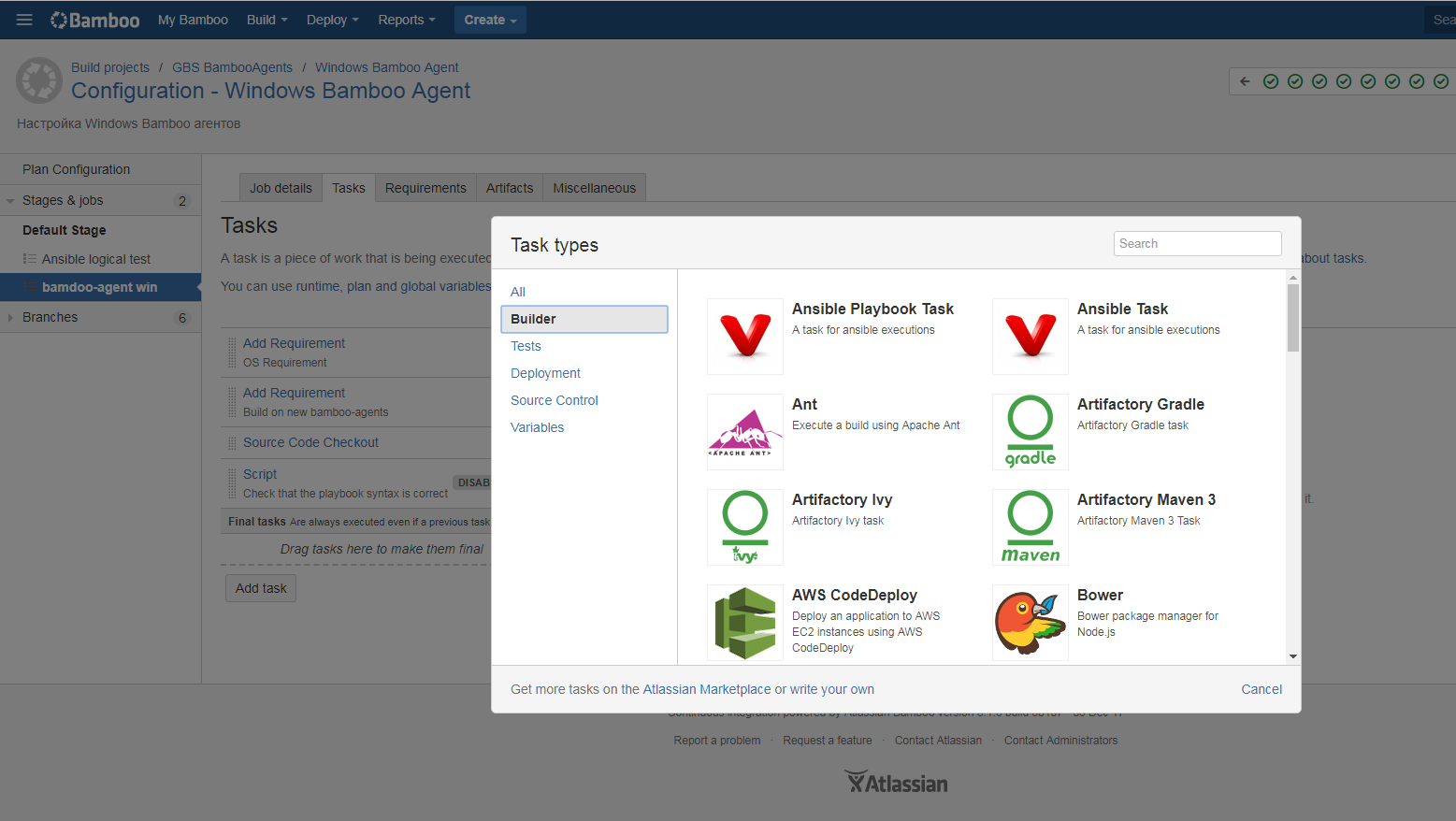
The build itself is standard: the code is saved to the agent, compiled in the same binaries and packaged in the appropriate packages. Optionally any testing is connected, up to modular and integration. At the end of the build, we get a beautiful report containing a lot of useful information about what commits went into the build, what tests were performed and with what result, what tasks went into the build, etc.
The artifact generated as a result of the assembly is automatically placed in the Artifactory.

On the one hand, this system is used as a centralized repository of artifacts collected by us, and on the other hand, through the Artifactory we proxify most external repositories, which significantly speeds up the build process and reduces the load on the network. When assembling, we turn to Artifactory for all dependencies, rather than pumping them out of external repositories, which very well affects the speed and stability of the work of the assembly plans.
Having placed the package in the Artifactory, we can do anything with it, including installing it on the environment we need. Teams typically use three environments to create software. Dev-environment - development environment, used for development and debugging. Test environment - used for functional and integration testing of applications. Preview-environment - is used for acceptance of the functionality by the customer and load testing; as a rule, it is closest to operating conditions. Some teams have decided to install to yesterday's copy of the working environment before installing it in production, which also helps to identify problems.
The teams, together with the support, decide who sets up what environments, and here we use almost all the options. There are teams that only developers are responsible for deployment (hello, DevOps!); There are teams where developers update only dev and test, and support - preview and prod. Some teams generally have dedicated people who install in all environments.
A deployable project is a collection of environments associated with a specific build plan.
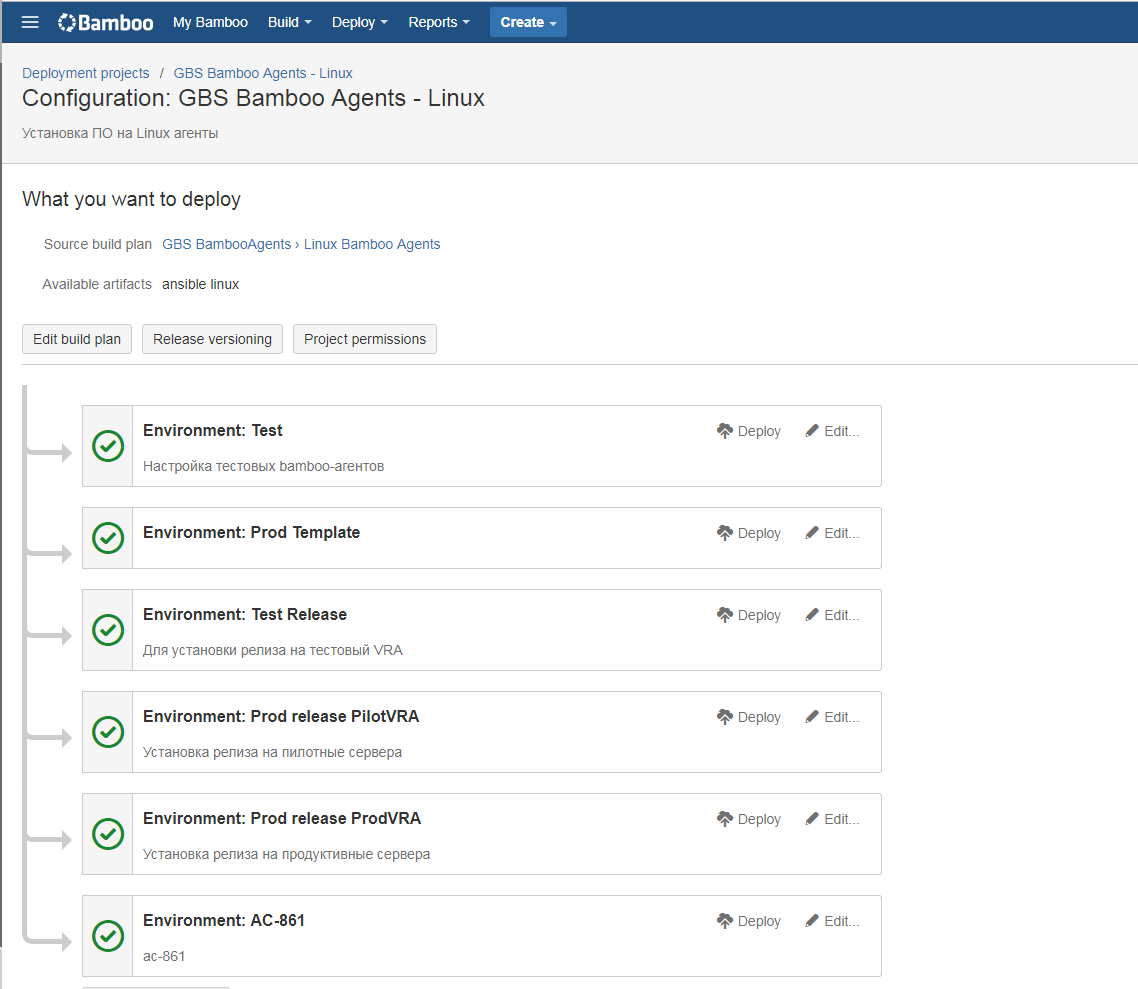
The environment contains medium-dependent variables that are configured for each environment separately. In the comments to the last article there was a question about how we store passwords. As you can see in the screenshot, we store them in the parameters of the build and deployment plans. In Bamboo, a password encryption mechanism is implemented: it is enough to use the word password in the variable name, and it will be encrypted. After saving, the value of such a variable can no longer be viewed through the interface or seen in the execution logs, it will be “masked” by asterisks everywhere.
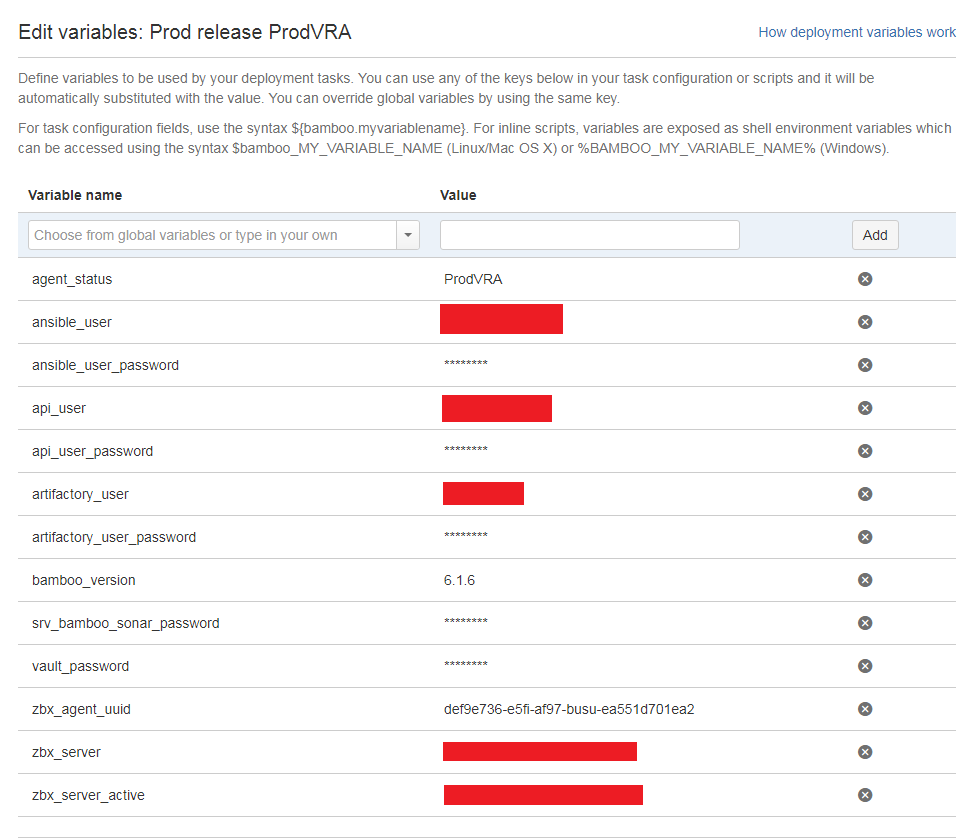
In addition to variables, the environment contains an executable part, implemented as tasks that describe the set of actions required to install the application on the target host or hosts. The list supports all standard tools and can be expanded with plugins.
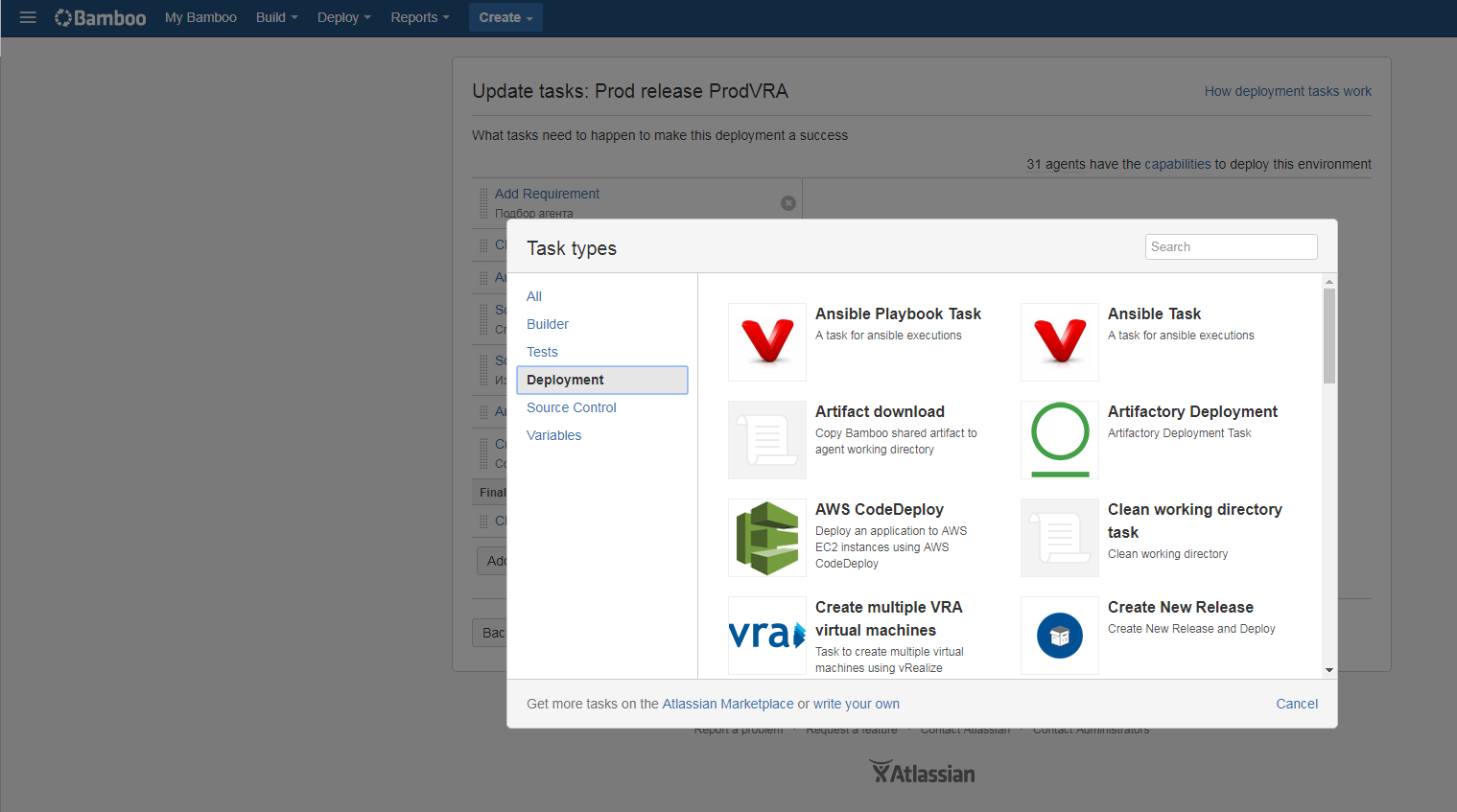
Based on the execution results, we also get a detailed execution log, with nesting levels and cross-references to tasks, commits, assemblies, etc.
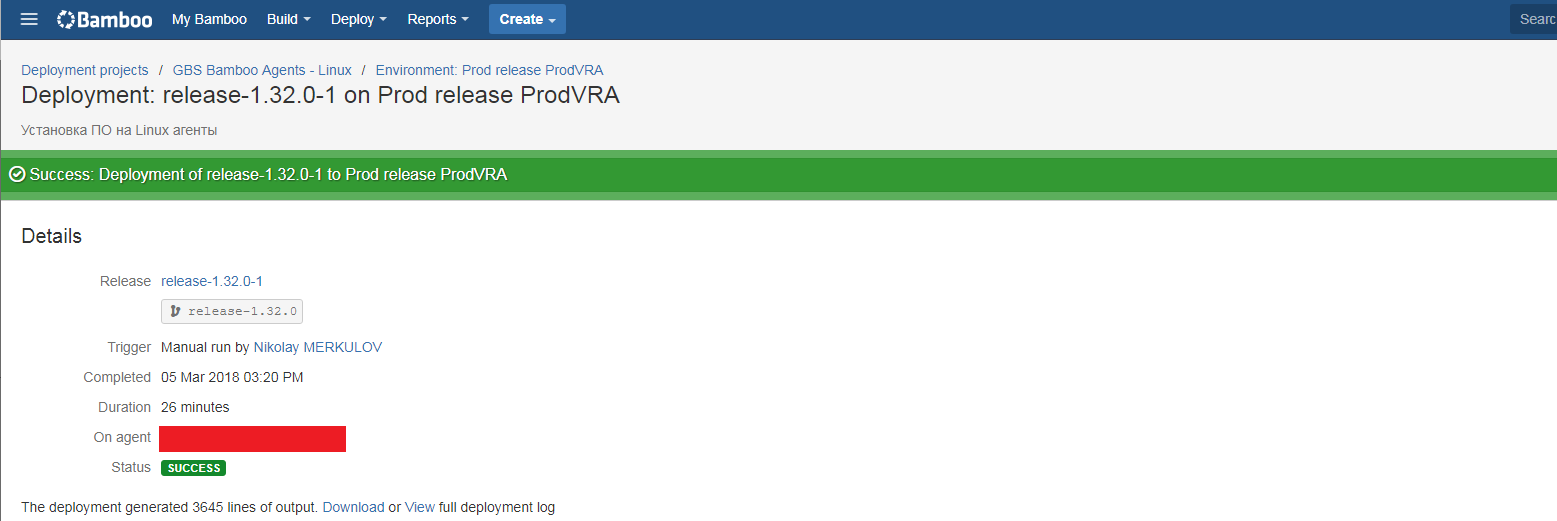
About installation in production, probably, it is worth talking separately. The bank has a change registration process (CM), according to which all changes in production must be announced and agreed in advance. To register changes, the command gets change management request (CRQ) at least three days before installation. All sorts of testing reports are attached to this CRQ, an impressive list of coordinators is being formed. The process is rather slow and cumbersome ... But we are dispelling myths about IT in banks
We have teams that, together with business and support, have decided that they are doing everything so well that they are ready to make any changes to production at any time, and this will not lead to disastrous consequences. Especially for such teams, the process of simplified registration and coordination of changes in the production-system was invented, within which you can make changes to production at any time, and register the CRQ after the actual work has been done. But what kind of a CI / CD is this, if you need to start some applications manually ... Therefore, we wrote our own plugin for Bamboo, which allows you to automatically register a CRQ that is embedded in the deployment plan.
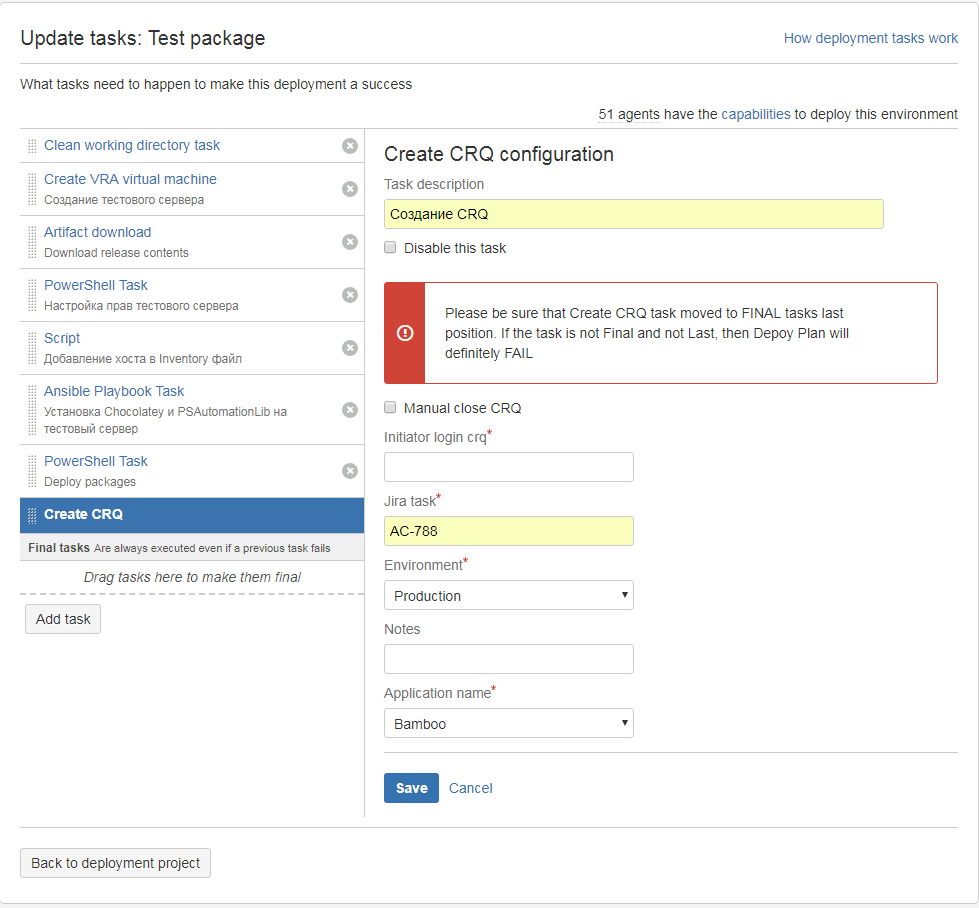
Now the whole process of registration and approval of changes takes several minutes and does not require manual intervention. By the way, we have more than a dozen teams working in this new process, and their number is steadily growing. So, in such bulky, conservative organizations like a bank, you can successfully implement best practices from the IT sphere.
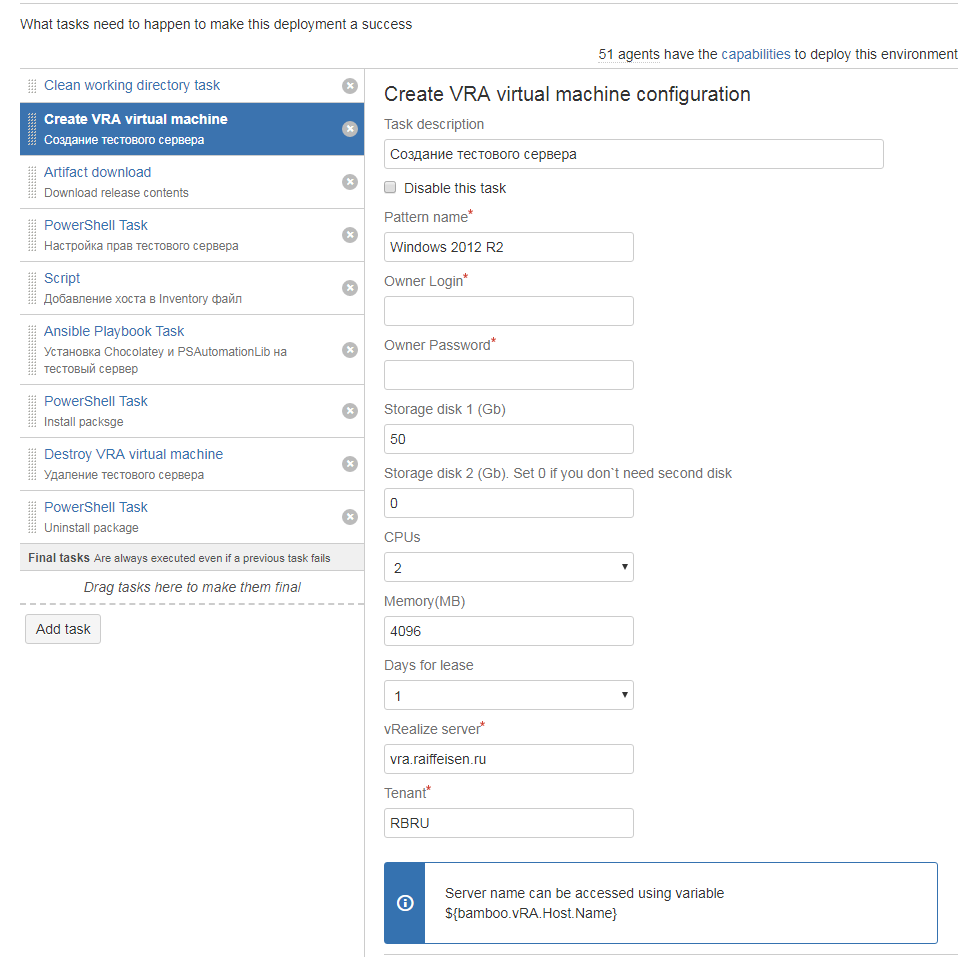
In modern realities, talking about the process of deployment, it is impossible to ignore such a thing as clouds. As we already wrote that we have an internal cloud based on VMWare vRealize. It is used both in non-industrial environments and in production. We also integrated the cloud into the pipeline with the help of another own plug-in. Now through Bamboo we can create or delete servers in the cloud.
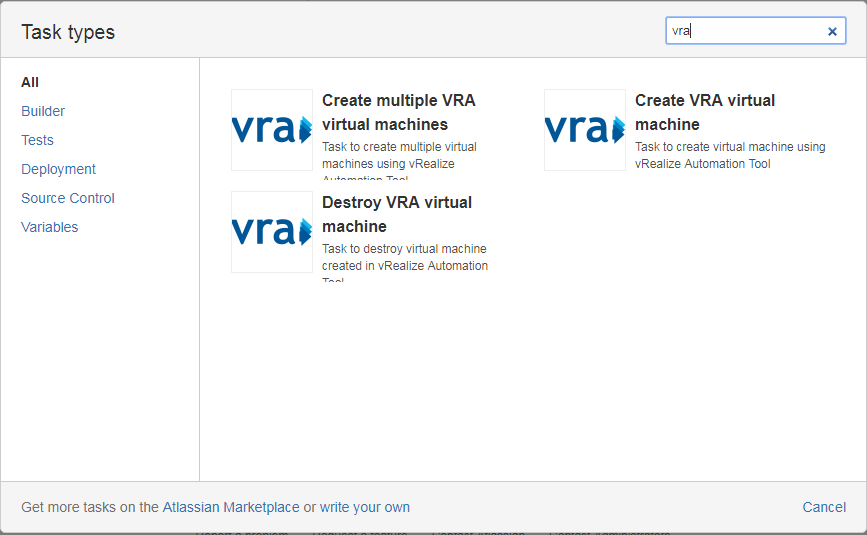
For example, we re-create the servers mentioned above for Bamboo agents in the cloud every two weeks simply by launching a deployment plan that creates the necessary number of servers, installs all the necessary software on them, registers in the monitoring system, etc. This operation takes about two hours, and then only because more than a hundred applications are installed.
Thus, thanks to the boxed integration and small customization, we were able to build a CI / CD pipeline that can solve all the tasks. But nothing stands still. Now we (like all progressive humanity) are actively moving towards integrating the pipeline with chatops tools, using containers and automating the processes associated with the pipeline itself.
In the comments to the previous article, we asked a number of other questions, which, in our opinion, are not related either to CI / CD or to the pipeline. So we will answer them in the "question-answer" format. Probably, the answers will seem monotonous to you. But the bank has more than 700 applications written at different times, under different operating systems and using different technologies, therefore it is impossible to give a definite answer, in most cases everything is determined by the application and its team.
What deployment schemes are used? (green / blue, rolling, canary, etc.). And if you need to roll back?
Depends on the specific application. As far as I know, for sure there is green / blue and rolling, I'm not sure about the rest. The teams themselves choose the best deployment option. If you need to roll back and it is possible, then roll back.
How and by whom is the decision about successful deployment made? Based on what parameters?
It's not entirely clear what this is about. If the deployment process itself, then the decision is made by Bamboo. The plan worked without errors - well, did not work - an error. If the question about the functional component of the installed changes, then the decision is made by business customers during smoke-testing after installation.
What if the load increases? Is it easy to add more servers to keep up the load? Is there autoscaling?
It depends on the application and still many, many factors, as always, when it comes to the load. Autoscaling is not used.
Is each new deployment running on newly created servers or the same ones?
Depends on the application. Our team re-creates the servers every two weeks, and we deploy only to new ones. Other commands always deploy to the same servers. The teams themselves choose the approach.
What with patches on the operating system?
Depends on the application, OS and updates. But, in the end, we have installed all critical fixes and no vulnerabilities.
And what about monitoring and application and system metrics (OS)?
The topic of monitoring deserves a separate large article that may be written by our monitoring specialists. I can say that there is monitoring, alerts work, incidents are recorded and processed, some processing is automated.
What do you use for load balancing between application copies? nginx / haproxy / etc?
Depends on the application There are both nginx, and haproxy, and NLB, and Cisco hardware.
I think that it is best to describe the whole process from the moment the work begins on the task to the launch of the changes made to the operation. And in the course of the story I will try to answer all the questions that were left unanswered in the last article.
Immediately make a reservation that our development teams enjoy complete freedom in building processes, so it cannot be said that all teams work in exact accordance with the description below. Although, of course, a set of tools imposes certain restrictions. So, to the point.
')
In the bank, the main error tracking system is JIRA. It registers tasks for all modifications, changes, and so on. Developing the task, the developers “cut off” the branch from the main repository and further develop it in it. Below is an example of a fairly typical problem.
When finished with the task, the developer initiates a Bitbucket pull request to make changes to the main branch. And here, for the first time, he encounters a manifestation of the work of the pipeline: pull request starts the process of automatic code revision.
Our audit is performed using the SonarQube integrated into the pipeline through the Sonar for Bamboo and Sonar for Bitbucket plugins. When you register a pull request in Bamboo, the build plan automatically runs, analyzing the branch you want to add. The result of the analysis is displayed directly in the pull request in this form:
In the form of a pull request, you can immediately see which new notes the code contains, their criticality, category, etc. The comments themselves can be viewed directly from the pull request form, just go to the Diff tab.
Thus, the code revision process is significantly accelerated and facilitated, plus a fairly large number of settings allows for very flexible adjustment of the behavior of the pipeline both during the audit and in its results. Suppose the audit is completed successfully, and we can move on.
The next step is to build from our code something necessary and useful. Build runs in Bamboo in a variety of ways. You can manually, automatically after a merge or commit in the repository, on a schedule, or even through a call to the Bamboo Rest API. For simplicity and clarity, we consider the most banal option - run the assembly by hand. To do this, go to Bamboo, select the desired plan and press start.
After starting, according to the dependencies indicated in the plan, a suitable agent is selected on which the assembly will be performed. At the moment we have 30 Windows agents, 20 Linux, 2 iOS agents, and 5 more we keep for experiments and pilots. Half of the agents are deployed in our internal cloud, but more on that later. This number allows us to smoothly serve more than 500 active build plans and about a couple of hundred deployment projects.
But back to our assembly plan. The pipeline supports all common build tools, the list of which can be expanded with plug-ins.
The build itself is standard: the code is saved to the agent, compiled in the same binaries and packaged in the appropriate packages. Optionally any testing is connected, up to modular and integration. At the end of the build, we get a beautiful report containing a lot of useful information about what commits went into the build, what tests were performed and with what result, what tasks went into the build, etc.
The artifact generated as a result of the assembly is automatically placed in the Artifactory.
On the one hand, this system is used as a centralized repository of artifacts collected by us, and on the other hand, through the Artifactory we proxify most external repositories, which significantly speeds up the build process and reduces the load on the network. When assembling, we turn to Artifactory for all dependencies, rather than pumping them out of external repositories, which very well affects the speed and stability of the work of the assembly plans.
Having placed the package in the Artifactory, we can do anything with it, including installing it on the environment we need. Teams typically use three environments to create software. Dev-environment - development environment, used for development and debugging. Test environment - used for functional and integration testing of applications. Preview-environment - is used for acceptance of the functionality by the customer and load testing; as a rule, it is closest to operating conditions. Some teams have decided to install to yesterday's copy of the working environment before installing it in production, which also helps to identify problems.
The teams, together with the support, decide who sets up what environments, and here we use almost all the options. There are teams that only developers are responsible for deployment (hello, DevOps!); There are teams where developers update only dev and test, and support - preview and prod. Some teams generally have dedicated people who install in all environments.
A deployable project is a collection of environments associated with a specific build plan.
The environment contains medium-dependent variables that are configured for each environment separately. In the comments to the last article there was a question about how we store passwords. As you can see in the screenshot, we store them in the parameters of the build and deployment plans. In Bamboo, a password encryption mechanism is implemented: it is enough to use the word password in the variable name, and it will be encrypted. After saving, the value of such a variable can no longer be viewed through the interface or seen in the execution logs, it will be “masked” by asterisks everywhere.
In addition to variables, the environment contains an executable part, implemented as tasks that describe the set of actions required to install the application on the target host or hosts. The list supports all standard tools and can be expanded with plugins.
Based on the execution results, we also get a detailed execution log, with nesting levels and cross-references to tasks, commits, assemblies, etc.
About installation in production, probably, it is worth talking separately. The bank has a change registration process (CM), according to which all changes in production must be announced and agreed in advance. To register changes, the command gets change management request (CRQ) at least three days before installation. All sorts of testing reports are attached to this CRQ, an impressive list of coordinators is being formed. The process is rather slow and cumbersome ... But we are dispelling myths about IT in banks
We have teams that, together with business and support, have decided that they are doing everything so well that they are ready to make any changes to production at any time, and this will not lead to disastrous consequences. Especially for such teams, the process of simplified registration and coordination of changes in the production-system was invented, within which you can make changes to production at any time, and register the CRQ after the actual work has been done. But what kind of a CI / CD is this, if you need to start some applications manually ... Therefore, we wrote our own plugin for Bamboo, which allows you to automatically register a CRQ that is embedded in the deployment plan.
Now the whole process of registration and approval of changes takes several minutes and does not require manual intervention. By the way, we have more than a dozen teams working in this new process, and their number is steadily growing. So, in such bulky, conservative organizations like a bank, you can successfully implement best practices from the IT sphere.
In modern realities, talking about the process of deployment, it is impossible to ignore such a thing as clouds. As we already wrote that we have an internal cloud based on VMWare vRealize. It is used both in non-industrial environments and in production. We also integrated the cloud into the pipeline with the help of another own plug-in. Now through Bamboo we can create or delete servers in the cloud.
For example, we re-create the servers mentioned above for Bamboo agents in the cloud every two weeks simply by launching a deployment plan that creates the necessary number of servers, installs all the necessary software on them, registers in the monitoring system, etc. This operation takes about two hours, and then only because more than a hundred applications are installed.
Thus, thanks to the boxed integration and small customization, we were able to build a CI / CD pipeline that can solve all the tasks. But nothing stands still. Now we (like all progressive humanity) are actively moving towards integrating the pipeline with chatops tools, using containers and automating the processes associated with the pipeline itself.
In the comments to the previous article, we asked a number of other questions, which, in our opinion, are not related either to CI / CD or to the pipeline. So we will answer them in the "question-answer" format. Probably, the answers will seem monotonous to you. But the bank has more than 700 applications written at different times, under different operating systems and using different technologies, therefore it is impossible to give a definite answer, in most cases everything is determined by the application and its team.
What deployment schemes are used? (green / blue, rolling, canary, etc.). And if you need to roll back?
Depends on the specific application. As far as I know, for sure there is green / blue and rolling, I'm not sure about the rest. The teams themselves choose the best deployment option. If you need to roll back and it is possible, then roll back.
How and by whom is the decision about successful deployment made? Based on what parameters?
It's not entirely clear what this is about. If the deployment process itself, then the decision is made by Bamboo. The plan worked without errors - well, did not work - an error. If the question about the functional component of the installed changes, then the decision is made by business customers during smoke-testing after installation.
What if the load increases? Is it easy to add more servers to keep up the load? Is there autoscaling?
It depends on the application and still many, many factors, as always, when it comes to the load. Autoscaling is not used.
Is each new deployment running on newly created servers or the same ones?
Depends on the application. Our team re-creates the servers every two weeks, and we deploy only to new ones. Other commands always deploy to the same servers. The teams themselves choose the approach.
What with patches on the operating system?
Depends on the application, OS and updates. But, in the end, we have installed all critical fixes and no vulnerabilities.
And what about monitoring and application and system metrics (OS)?
The topic of monitoring deserves a separate large article that may be written by our monitoring specialists. I can say that there is monitoring, alerts work, incidents are recorded and processed, some processing is automated.
What do you use for load balancing between application copies? nginx / haproxy / etc?
Depends on the application There are both nginx, and haproxy, and NLB, and Cisco hardware.
Source: https://habr.com/ru/post/350986/
All Articles