Guide to SEO javascript sites. Part 1. The Internet through the eyes of Google
We present to your attention the translation of the first part of the material, which is devoted to search engine optimization of sites built using JavaScript. It will focus on the features of scanning, analyzing and indexing such sites by search engines, on the problems associated with these processes, and on approaches to solving these problems.
In particular, today the author of this material, Tomasz Rudski from Elephate, will talk about how sites that use modern JS frameworks, such as Angular, React, Vue.js and Polymer, look from Google’s point of view. Namely, the discussion will focus on how Google handles websites, on technologies used for page analysis, on how a developer can analyze a website in order to understand whether Google can properly index this website.

')
JavaScript technologies for developing websites are very popular these days, so it may seem that they have already reached a fairly high level of development in all conceivable directions. However, in reality it is not so. In particular, developers and SEO specialists are still at the very beginning of making websites built on JS frameworks successful in terms of their interaction with search engines. Until now, many similar sites, despite their popularity, occupy far from the highest places in the search results of Google and other search engines.
Back in 2014, Google announced that their systems index sites using JavaScript quite well. However, despite these statements, recommendations were always made to treat this issue with caution. Take a look at this extract from the original material “ Improving the understanding of web pages ” (hereinafter the selection is made by the author of the material):
“Unfortunately, indexing does not always go smoothly, which can lead to problems affecting the position of your site in the search results ... If the JavaScript code is too complicated or confused, Google may analyze it incorrectly ... Sometimes JavaScript removes content from the page and does not add it which also makes indexing difficult. ”
Scanning capability, analysis capability and scanning budget
In order to understand whether the search engine will be able to correctly process the site, that is, to process it as expected by the creator of the site, you need to take into account three factors:
Speaking of whether Google can crawl and analyze websites that use JavaScript, we need to touch on two very important concepts: rendering, or rendering pages, on the server side, and on the client side. These ideas need to be understood by every SEO expert who deals with JavaScript.
In the traditional approach (server rendering), a browser or a Googlebot robot downloads the HTML code that fully describes the page from the server. All the necessary materials are ready, the browser (or robot) only needs to load HTML and CSS and create a page ready for viewing or analysis. Usually search engines have no problems with indexing sites that use server rendering.
The method of rendering pages on the client side, which has certain features, is becoming increasingly popular. These features sometimes lead to problems with the analysis of such pages by search engines. It’s quite common that the browser (or Googlebot) gets a blank HTML page during the initial download of data.
In fact, on such a page, either there are no data at all suitable for analysis and indexing, or there are very few of them. Then the JavaScript mechanisms come into play, which asynchronously load data from the server and update the page (changing the DOM).
If you are using a client-side rendering technique, you need to make sure that Google is able to correctly scan and process the pages of your site.
HTML and JS are fundamentally different in error handling. The only error in the JavaScript code can lead to Google not being able to index the page.
Let me quote Matthias Schafer, author of “Reliable JavaScript” : “The JS parser is not user friendly. He is completely intolerant of mistakes. If it encounters a symbol that is not expected to appear in a certain place, it immediately stops parsing the current script and issues a SyntaxError. Therefore, the only character that is not where it is needed, the only typo, can lead to a complete inoperability of the script. "
You may have heard about the SEO experiment as applied to JavaScript sites, which Bartosh Goralevich, who holds the position of CEO at Elephate, conducted to find out whether Google can index websites created using common JS frameworks.

The list of investigated technologies
At the very beginning, it turned out that Googlebot was not able to analyze pages created using Angular 2. This was strange, because Angular was created by the Google team, so Bartosz decided to find out the reasons for what was happening. Here is what he writes about this:
“It turned out that there was an error in QuickStart Angular 2, in a bit of a tutorial on how to prepare projects based on this framework. The link to this manual was in the official documentation. It turned out that the Google Angular team made a mistake that was fixed on April 26, 2017. ”
Error in Angular 2
The correction of the error led to the possibility of normal indexing of the test site on Angular 2.
This example perfectly illustrates the situation where a single error may lead to Googlebot not being able to analyze the page.
The fact that the mistake was made not by a beginner, but by an experienced person involved in the development of Angular, the second most popular JS framework, adds fuel to the fire.
Here is another great example that, ironically, is again linked to Angular. In December 2017, Google excluded from the index several pages of the Angular.io website (a website based on Angular 2+, on which client-side visualization technology is used). Why did this happen? As you can guess, one mistake in their code made it impossible to visualize pages using Google and led to a massive exclusion of pages from the index. The error was later corrected.
Here’s how Igor Minar from Angular.io explained this:
“Considering that we did not change the problematic code for 8 months, and we faced a significant drop in traffic from search engines starting around December 11, 2017, I believe that during this time something has changed in the site crawling system, which and led to the fact that most of the site was excluded from the search index, which, in turn, caused a drop in traffic to the resource. "
The correction of the aforementioned error, which prevented the analysis of the pages of the Angular.io resource, was possible due to the experienced team of JS developers, and the fact that they implemented error logging . After the bug was fixed, Google was able to index the problem pages again.
Here's how to scan and index ordinary HTML pages. Everything is simple and clear:
All this happens very quickly.
However, the process is complicated if the work is carried out with a web site based on JavaScript:
This whole process is much more complicated than scanning HTML sites. Here you need to take into account the following:

Indexing HTML pages and pages generated by JS
Now I would like to illustrate the problem of the complexity of JavaScript code. I bet that 20-50% of visitors to your site are viewing it from a mobile device. Do you know how long it takes to parse a 1 MB JS code on a mobile device? According to Sam Sakkone from Google , the Samsung Galaxy S7 spends about 850 ms on it, and the Nexus 5 spends about 1700 ms! After parsing the JS code, it still needs to be compiled and executed. And every second counts.
If you want to know more about the budget for scanning, I advise you to read Barry Adams' JavaScript and SEO: The Difference Between Crawling and Indexing material. SEO specialists dealing with JavaScript are especially helpful in the sections "JavaScript = Inefficiency" and "Good SEO is Efficiency". At the same time you can see this material.
In order to understand why Google may encounter problems when crawling websites that use JS, we should talk about the technical limitations of Google.
I am sure that you are using the latest version of your favorite browser. However, this is not the case with Google. Here, for rendering web sites, Chrome 41 is used. This browser was released in March 2015. He is already three years old! Both the Google Chrome browser and JavaScript have evolved enormously over the years.
As a result, it turns out that there are many modern features that are simply not available for the Googlebot robot. Here are some of its main limitations:
Considering the technical limitations of Chrome 41, you can analyze the difference between Chrome 41 and Chrome 66 (the latest version of Chrome at the time of this writing).
Now that you know that Chrome 41 is using Google for building pages, take the time to download this browser and check your own websites to see if this browser can work with them. If not, take a look at the Chrome 41 console to try to find out what might be causing the errors.
By the way, since I started talking about this, here is my material on working with Chrome 41.
How to be someone who seeks to use modern features of JS, but at the same time, wants Google to properly index its sites? This frame is answered by this frame from the video:
Current JavaScript features and page indexing
The browser used by Google for generating pages of JS-based sites can correctly handle sites that use modern JS features, however, the developers of such sites will need to make some efforts for this. Namely, use polyfills, create a simplified version of the site (using the technique of gradual degradation) and perform code transfiguration in ES5.
The popularity of javascript grew very quickly, and now it is happening faster than ever. However, some features of JavaScript are simply not implemented in outdated browsers (it just so happened that Chrome 41 is just such a browser). As a result, normal rendering of sites using modern JS features in such browsers is impossible. However, webmasters can get around this by using a gradual degradation technique.
If you want to implement some of the modern features of JS that only a few browsers support, in this case you need to ensure that a simplified version of your website is used in other browsers. Remember that the version of Chrome that Googlebot uses is definitely not up to date. This browser is already three years old.
By analyzing the browser, you can check at any time whether it supports some feature or not. If it does not support this feature, you, instead of it, should offer something that is suitable for this browser. This replacement is called polyfill.
In addition, if you want the site to be processed by Google search robots, you absolutely need to use JS-code transpiling in ES5, that is, converting those JS constructs that Googlebot does not understand, in a design that it understands.
For example, when the transpiler encounters the expression
If you are using modern JavaScript features and want your sites to be properly processed by Google search robots, you should definitely use ES5 transpilation and polyfills.
Here I try to explain all this so that it would be clear not only to JS-developers, but also, for example, to SEO-specialists who are far from JavaScript. However, we don’t go into details, so if you feel the need to better understand what polyfills are, take a look at this material .
When you surf the Internet, your browser (Chrome, Firefox, Opera, or any other) loads resources (images, scripts, styles) and shows you the pages collected from all this.
However, Googlebot does not work like a regular browser. His goal is to index everything that he can reach, while loading only the most important.
The World Wide Web is a huge information space, so Google optimizes its scanning system in terms of performance. That is why Googlebot sometimes does not visit all pages that a web developer expects to visit.
More importantly, Google’s algorithms are trying to identify the resources that are needed in terms of page formation. If a resource looks, from this point of view, not particularly important, it may simply not be downloaded by Googlebot.
Googlebot and WRS selectively upload content, selecting only the most important.
As a result, it may turn out that the scanner will not load some of your JS files, since its algorithms have decided that, from the point of view of the formation of the page, they are not important. The same thing can happen because of performance problems (that is, in a situation where the execution of the script takes too much time).
I want to note that Tom Anthony noticed one interesting feature in the behavior of Googlebot . When the
Many SEO experiments indicate that, in general, Google cannot wait for the completion of the script that runs for more than 5 seconds. My experiments seem to confirm this.
Do not take this for granted: get your JS files to load and complete in less than 5 seconds.
If your web site loads up really slowly, you can lose a lot. Namely:
Try to make your site not too heavy, provide a high speed of server response, and also make sure that the server is working normally under a high load (use for this, for example, Load Impact ). Do not make life difficult for Google robots.
A common mistake in terms of performance that developers make is that they put the code for all the components of a page into a single file. But if the user goes to the home page of the project, he absolutely does not need to upload what is related to the section intended for the site administrator. The same is true for search engines.
To solve performance problems, it is recommended to find the appropriate guide on the applicable JS-framework. It is worth exploring and finding out what can be done to speed up the site. In addition, I advise you to read this material.
If you want to look at the Internet, and especially at your website, through the eyes of Google’s robots, you can take one of two approaches:
Here is another option: the Rich Results Test tool. I'm not kidding - this tool can show you how Google interprets your page, demonstrating the results of the DOM rendering, and this is very useful. Google plans to add DOM rendering results to Fetch and Render tools. Since this has not been done so far, John Muller advises using Rich Results for this. Now it’s not quite clear whether Rich Results follows the same rendering rules as the Google indexing system. Perhaps, in order to find out, it is worth conducting additional experiments.
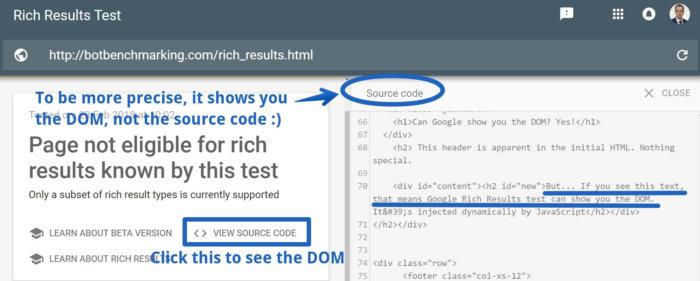
Rich Results Test tool
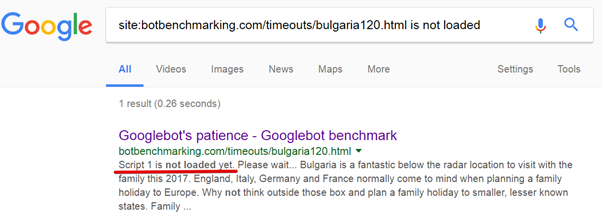
The Fetch and Render tools can only tell you whether Google has the technical ability to form the page being analyzed. However, do not rely on them when it comes to timeouts. I often came across a situation where Fetch and Render were able to display a page, but Google’s indexing system could not index this page due to the timeouts used by this system. Here is the evidence for this statement.
I did a simple experiment . The first JS-file included in the analyzed page was loaded with a delay of 120 seconds. At the same time there was no technical possibility to avoid this delay. The nginx server was configured to wait two minutes before issuing this file.
The project used for the experiment
Pilot Project Page
It turned out that the Fetch and Render tools were waiting for the script to load 120 seconds (!), After which the page was displayed correctly.
Page analysis with Fetch and Render
However, the indexing system was not so patient.
Results of experimental site indexing
Here you can see that the Google indexing system simply did not wait for the download of the first script and analyzed the page without taking into account the results of the work of this script.
As you can see, the Google Search Console is a great tool. However, they should be used only to test the technical ability of Google Robots to analyze the page. Do not use this tool to check if the indexing system is waiting for your scripts to load.
Many SEO experts have used the Google cache to search for problems with page analysis. However, this technique is not suitable for JS-intensive sites, as the Google cache itself is the original HTML that Googlebot downloads from the server (note this is confirmed many times by John Muller from Google).

Google Cache stuff
Looking through the contents of the cache, you can see how your browser interprets the HTML compiled by Googlebot. This has nothing to do with page formation for indexing purposes. If you want to know more about the Google cache, take a look at this material .
Currently, one of the best ways to check whether any data has been indexed by Google is to use the
To do this, simply copy a piece of text from your page and enter the following command in the Google search engine:
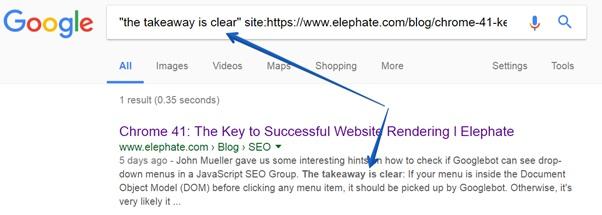
Command site
If, in response to such a command, you see the required fragment in the search results, it means that the data has been indexed.
Here I would like to note that such search queries are recommended to be performed in anonymous mode. Several times I had cases when the editors of the site changed the texts, and for some reason the
The HTML file is the source information that the browser uses to form the page. I assume that you know what an HTML document is. It contains information about the layout of the page - for example, about splitting text into paragraphs, about images, links, it includes commands for downloading JS and CSS files.
You can view the HTML code of the page in the Google Chrome browser by calling the context menu by right-clicking and selecting the View page source command.
However, using this mode of viewing the page code, you will not see the dynamic content (that is, the changes made to the page using JavaScript).
DOM should be analyzed instead. This can be done using the command of the same Inspect Element menu (view code).
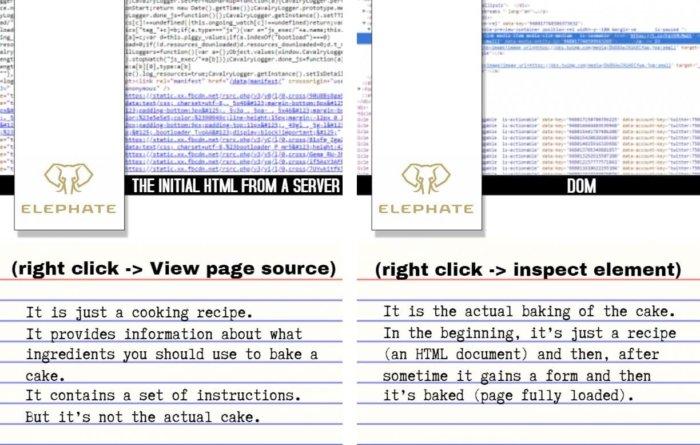
The source HTML code received from the server (what is displayed by the View page source command) is something like a culinary recipe. It provides information about what ingredients are part of a certain dish, contains instructions for cooking. But the recipe is not a finished dish.
The DOM (Inspect Element team) is an HTML-recipe dish. At the very beginning, the browser loads the “recipe”, then prepares the dish, and as a result, after the page is fully loaded, something “edible” appears before us.
HTML downloaded from server and DOM
Please note that if Google fails to generate a page based on the loaded HTML code, it can simply index this HTML source code (which does not contain dynamically updated content). Details on this can be found in this Barry Adams article . Barry also gives advice on how to quickly compare source HTML and DOM.
In this article, we talked about how Google handles sites that are created using JavaScript technology. In particular, the fact that Chrome 41 is used to analyze pages on Google is of great importance. This imposes certain restrictions on the use of JavaScript.
In the second part of the translation of this material we will focus on what you should pay attention to so that JS-sites are properly indexed by search engines. There will also be raised some more topics related to SEO and JavaScript.
Dear readers! How do you analyze your sites, checking whether Google indexes them the way you expect it?

In particular, today the author of this material, Tomasz Rudski from Elephate, will talk about how sites that use modern JS frameworks, such as Angular, React, Vue.js and Polymer, look from Google’s point of view. Namely, the discussion will focus on how Google handles websites, on technologies used for page analysis, on how a developer can analyze a website in order to understand whether Google can properly index this website.
')
JavaScript technologies for developing websites are very popular these days, so it may seem that they have already reached a fairly high level of development in all conceivable directions. However, in reality it is not so. In particular, developers and SEO specialists are still at the very beginning of making websites built on JS frameworks successful in terms of their interaction with search engines. Until now, many similar sites, despite their popularity, occupy far from the highest places in the search results of Google and other search engines.
Can Google crawl and analyze JavaScript-based sites?
Back in 2014, Google announced that their systems index sites using JavaScript quite well. However, despite these statements, recommendations were always made to treat this issue with caution. Take a look at this extract from the original material “ Improving the understanding of web pages ” (hereinafter the selection is made by the author of the material):
“Unfortunately, indexing does not always go smoothly, which can lead to problems affecting the position of your site in the search results ... If the JavaScript code is too complicated or confused, Google may analyze it incorrectly ... Sometimes JavaScript removes content from the page and does not add it which also makes indexing difficult. ”
Scanning capability, analysis capability and scanning budget
In order to understand whether the search engine will be able to correctly process the site, that is, to process it as expected by the creator of the site, you need to take into account three factors:
- The ability to crawl a site: Google systems should be able to crawl a site, given its structure.
- The ability to analyze the site: Google systems should not have problems during the analysis of the site using the technologies used to generate its pages.
- Scan budget: the time allocated by Google to process the site should be sufficient for it to be fully indexed.
About client and server rendering
Speaking of whether Google can crawl and analyze websites that use JavaScript, we need to touch on two very important concepts: rendering, or rendering pages, on the server side, and on the client side. These ideas need to be understood by every SEO expert who deals with JavaScript.
In the traditional approach (server rendering), a browser or a Googlebot robot downloads the HTML code that fully describes the page from the server. All the necessary materials are ready, the browser (or robot) only needs to load HTML and CSS and create a page ready for viewing or analysis. Usually search engines have no problems with indexing sites that use server rendering.
The method of rendering pages on the client side, which has certain features, is becoming increasingly popular. These features sometimes lead to problems with the analysis of such pages by search engines. It’s quite common that the browser (or Googlebot) gets a blank HTML page during the initial download of data.
In fact, on such a page, either there are no data at all suitable for analysis and indexing, or there are very few of them. Then the JavaScript mechanisms come into play, which asynchronously load data from the server and update the page (changing the DOM).
If you are using a client-side rendering technique, you need to make sure that Google is able to correctly scan and process the pages of your site.
Javascript and errors
HTML and JS are fundamentally different in error handling. The only error in the JavaScript code can lead to Google not being able to index the page.
Let me quote Matthias Schafer, author of “Reliable JavaScript” : “The JS parser is not user friendly. He is completely intolerant of mistakes. If it encounters a symbol that is not expected to appear in a certain place, it immediately stops parsing the current script and issues a SyntaxError. Therefore, the only character that is not where it is needed, the only typo, can lead to a complete inoperability of the script. "
Errors of framework developers
You may have heard about the SEO experiment as applied to JavaScript sites, which Bartosh Goralevich, who holds the position of CEO at Elephate, conducted to find out whether Google can index websites created using common JS frameworks.
The list of investigated technologies
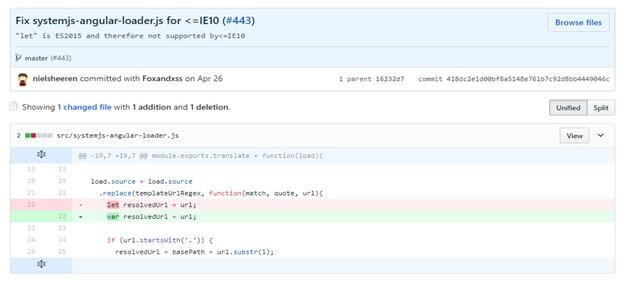
At the very beginning, it turned out that Googlebot was not able to analyze pages created using Angular 2. This was strange, because Angular was created by the Google team, so Bartosz decided to find out the reasons for what was happening. Here is what he writes about this:
“It turned out that there was an error in QuickStart Angular 2, in a bit of a tutorial on how to prepare projects based on this framework. The link to this manual was in the official documentation. It turned out that the Google Angular team made a mistake that was fixed on April 26, 2017. ”
Error in Angular 2
The correction of the error led to the possibility of normal indexing of the test site on Angular 2.
This example perfectly illustrates the situation where a single error may lead to Googlebot not being able to analyze the page.
The fact that the mistake was made not by a beginner, but by an experienced person involved in the development of Angular, the second most popular JS framework, adds fuel to the fire.
Here is another great example that, ironically, is again linked to Angular. In December 2017, Google excluded from the index several pages of the Angular.io website (a website based on Angular 2+, on which client-side visualization technology is used). Why did this happen? As you can guess, one mistake in their code made it impossible to visualize pages using Google and led to a massive exclusion of pages from the index. The error was later corrected.
Here’s how Igor Minar from Angular.io explained this:
“Considering that we did not change the problematic code for 8 months, and we faced a significant drop in traffic from search engines starting around December 11, 2017, I believe that during this time something has changed in the site crawling system, which and led to the fact that most of the site was excluded from the search index, which, in turn, caused a drop in traffic to the resource. "
The correction of the aforementioned error, which prevented the analysis of the pages of the Angular.io resource, was possible due to the experienced team of JS developers, and the fact that they implemented error logging . After the bug was fixed, Google was able to index the problem pages again.
About the complexity of scanning sites built using JavaScript
Here's how to scan and index ordinary HTML pages. Everything is simple and clear:
- Googlebot loads an HTML file.
- Googlebot extracts links from the page code, as a result, it can process several pages in parallel.
- Googlebot downloads CSS files.
- Googlebot sends all downloaded resources to the indexing system (Caffeine).
- Caffeine index page.
All this happens very quickly.
However, the process is complicated if the work is carried out with a web site based on JavaScript:
- Googlebot loads an HTML file.
- Googlebot downloads CSS and JS files.
- After this, Googlebot must use the Google Web Rendering Service (WRS) (this system is part of Caffeine) in order to parse, compile, and execute the JS code.
- WRS then retrieves data from external APIs, from databases, and so on.
- After the page is collected, it, as a result, can be processed by the indexing system.
- Only now the robot can detect new links and add them to the scan queue.
This whole process is much more complicated than scanning HTML sites. Here you need to take into account the following:
- Parsing, compiling and executing JS are operations that take a lot of time.
- In the case of sites that use JavaScript heavily, Google has to wait until all the above steps have been completed before the page content can be indexed.
- The process of assembling the page is not the only slow operation. This also applies to the process of finding new links. On JS-intensive sites, Google usually cannot find new links until the page is fully formed.
Indexing HTML pages and pages generated by JS
Now I would like to illustrate the problem of the complexity of JavaScript code. I bet that 20-50% of visitors to your site are viewing it from a mobile device. Do you know how long it takes to parse a 1 MB JS code on a mobile device? According to Sam Sakkone from Google , the Samsung Galaxy S7 spends about 850 ms on it, and the Nexus 5 spends about 1700 ms! After parsing the JS code, it still needs to be compiled and executed. And every second counts.
If you want to know more about the budget for scanning, I advise you to read Barry Adams' JavaScript and SEO: The Difference Between Crawling and Indexing material. SEO specialists dealing with JavaScript are especially helpful in the sections "JavaScript = Inefficiency" and "Good SEO is Efficiency". At the same time you can see this material.
Google and browser released 3 years ago
In order to understand why Google may encounter problems when crawling websites that use JS, we should talk about the technical limitations of Google.
I am sure that you are using the latest version of your favorite browser. However, this is not the case with Google. Here, for rendering web sites, Chrome 41 is used. This browser was released in March 2015. He is already three years old! Both the Google Chrome browser and JavaScript have evolved enormously over the years.
As a result, it turns out that there are many modern features that are simply not available for the Googlebot robot. Here are some of its main limitations:
- Chrome 41 only partially supports the modern syntax of JavaScript ES6. For example, he does not understand new language constructs.
- Interfaces like IndexedDB and WebSQL are disabled.
- Cookies, local storage and session storage are cleared when the page is reloaded.
- And, again, we have a browser that was released three years ago!
Considering the technical limitations of Chrome 41, you can analyze the difference between Chrome 41 and Chrome 66 (the latest version of Chrome at the time of this writing).
Now that you know that Chrome 41 is using Google for building pages, take the time to download this browser and check your own websites to see if this browser can work with them. If not, take a look at the Chrome 41 console to try to find out what might be causing the errors.
By the way, since I started talking about this, here is my material on working with Chrome 41.
Current JavaScript features and site indexing
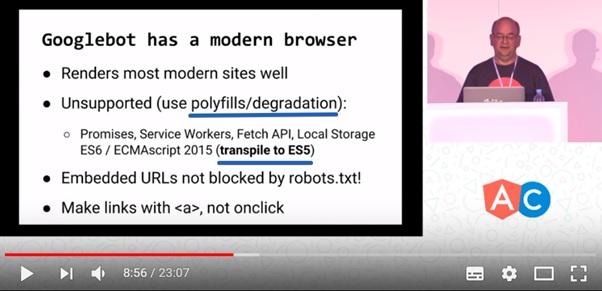
How to be someone who seeks to use modern features of JS, but at the same time, wants Google to properly index its sites? This frame is answered by this frame from the video:
Current JavaScript features and page indexing
The browser used by Google for generating pages of JS-based sites can correctly handle sites that use modern JS features, however, the developers of such sites will need to make some efforts for this. Namely, use polyfills, create a simplified version of the site (using the technique of gradual degradation) and perform code transfiguration in ES5.
Gradual degradation and polyfills
The popularity of javascript grew very quickly, and now it is happening faster than ever. However, some features of JavaScript are simply not implemented in outdated browsers (it just so happened that Chrome 41 is just such a browser). As a result, normal rendering of sites using modern JS features in such browsers is impossible. However, webmasters can get around this by using a gradual degradation technique.
If you want to implement some of the modern features of JS that only a few browsers support, in this case you need to ensure that a simplified version of your website is used in other browsers. Remember that the version of Chrome that Googlebot uses is definitely not up to date. This browser is already three years old.
By analyzing the browser, you can check at any time whether it supports some feature or not. If it does not support this feature, you, instead of it, should offer something that is suitable for this browser. This replacement is called polyfill.
In addition, if you want the site to be processed by Google search robots, you absolutely need to use JS-code transpiling in ES5, that is, converting those JS constructs that Googlebot does not understand, in a design that it understands.
For example, when the transpiler encounters the expression
let x=5 (most older browsers will not understand this construction), it transforms it into the expression var x=5 (this construction is understandable to all browsers, including Chrome 41, which plays a special role for us) .If you are using modern JavaScript features and want your sites to be properly processed by Google search robots, you should definitely use ES5 transpilation and polyfills.
Here I try to explain all this so that it would be clear not only to JS-developers, but also, for example, to SEO-specialists who are far from JavaScript. However, we don’t go into details, so if you feel the need to better understand what polyfills are, take a look at this material .
Googlebot is not a real browser.
When you surf the Internet, your browser (Chrome, Firefox, Opera, or any other) loads resources (images, scripts, styles) and shows you the pages collected from all this.
However, Googlebot does not work like a regular browser. His goal is to index everything that he can reach, while loading only the most important.
The World Wide Web is a huge information space, so Google optimizes its scanning system in terms of performance. That is why Googlebot sometimes does not visit all pages that a web developer expects to visit.
More importantly, Google’s algorithms are trying to identify the resources that are needed in terms of page formation. If a resource looks, from this point of view, not particularly important, it may simply not be downloaded by Googlebot.
Googlebot and WRS selectively upload content, selecting only the most important.
As a result, it may turn out that the scanner will not load some of your JS files, since its algorithms have decided that, from the point of view of the formation of the page, they are not important. The same thing can happen because of performance problems (that is, in a situation where the execution of the script takes too much time).
I want to note that Tom Anthony noticed one interesting feature in the behavior of Googlebot . When the
setTimeout JS function is used, the current browser is instructed to wait a certain time. However, Googlebot does not wait, it performs everything immediately. This should not be surprising, since the goal of Google’s robots is to index the entire Internet, so they are optimized for performance.Five seconds rule
Many SEO experiments indicate that, in general, Google cannot wait for the completion of the script that runs for more than 5 seconds. My experiments seem to confirm this.
Do not take this for granted: get your JS files to load and complete in less than 5 seconds.
If your web site loads up really slowly, you can lose a lot. Namely:
- Visitors to the site will be uncomfortable working with him, they may leave it.
- Google may have trouble analyzing pages.
- This can slow down the site scanning process. If the pages are slow, Google may decide that its robots slow down your site and reduce the frequency of crawling. Read more about it here .
Try to make your site not too heavy, provide a high speed of server response, and also make sure that the server is working normally under a high load (use for this, for example, Load Impact ). Do not make life difficult for Google robots.
A common mistake in terms of performance that developers make is that they put the code for all the components of a page into a single file. But if the user goes to the home page of the project, he absolutely does not need to upload what is related to the section intended for the site administrator. The same is true for search engines.
To solve performance problems, it is recommended to find the appropriate guide on the applicable JS-framework. It is worth exploring and finding out what can be done to speed up the site. In addition, I advise you to read this material.
How to look at the Internet through Google?
If you want to look at the Internet, and especially at your website, through the eyes of Google’s robots, you can take one of two approaches:
- Use the Fetch (scan) and Render (display) tools from the Google Search Console (obviously!). But do not rely on them for 100%. This Googlebot may have timeouts that differ from those provided for in Fetch and Render.
- Use Chrome 41. As already mentioned, it is reliably known that Google uses Chrome 41 for rendering robot-loaded pages. Download this browser, for example, here . Using Chrome 41 has many advantages over using page loading using the Google Search Console:
- Through the use of Chrome 41, you can see the error log displayed in the browser console. If you encounter errors in this browser, you can be almost completely sure that Googlebot will encounter the same errors.
- The Fetch and Render tools will not show you the results of the DOM rendering, and the browser will show you. Using Chrome 41, you can check if Googlebot sees your links, content of panels, and so on.
Here is another option: the Rich Results Test tool. I'm not kidding - this tool can show you how Google interprets your page, demonstrating the results of the DOM rendering, and this is very useful. Google plans to add DOM rendering results to Fetch and Render tools. Since this has not been done so far, John Muller advises using Rich Results for this. Now it’s not quite clear whether Rich Results follows the same rendering rules as the Google indexing system. Perhaps, in order to find out, it is worth conducting additional experiments.
Rich Results Test tool
Fetch and Render tools and checking index timeouts
The Fetch and Render tools can only tell you whether Google has the technical ability to form the page being analyzed. However, do not rely on them when it comes to timeouts. I often came across a situation where Fetch and Render were able to display a page, but Google’s indexing system could not index this page due to the timeouts used by this system. Here is the evidence for this statement.
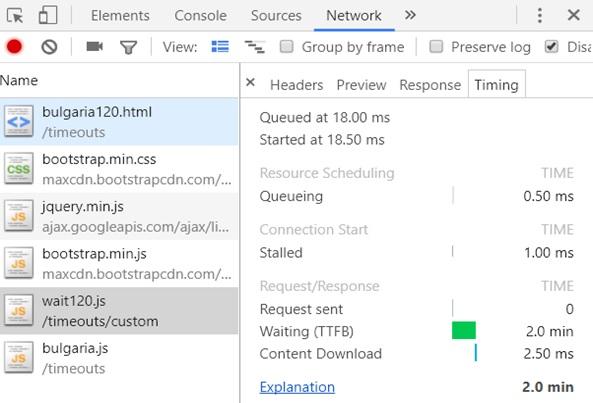
I did a simple experiment . The first JS-file included in the analyzed page was loaded with a delay of 120 seconds. At the same time there was no technical possibility to avoid this delay. The nginx server was configured to wait two minutes before issuing this file.
The project used for the experiment
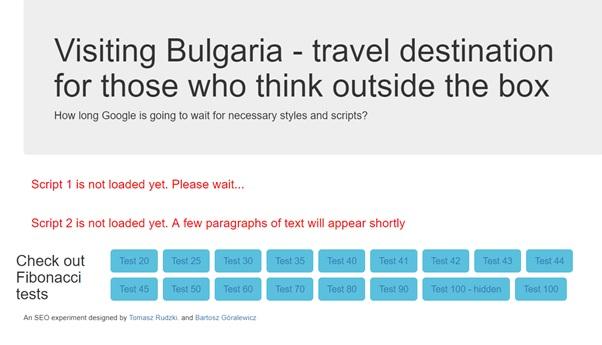
Pilot Project Page
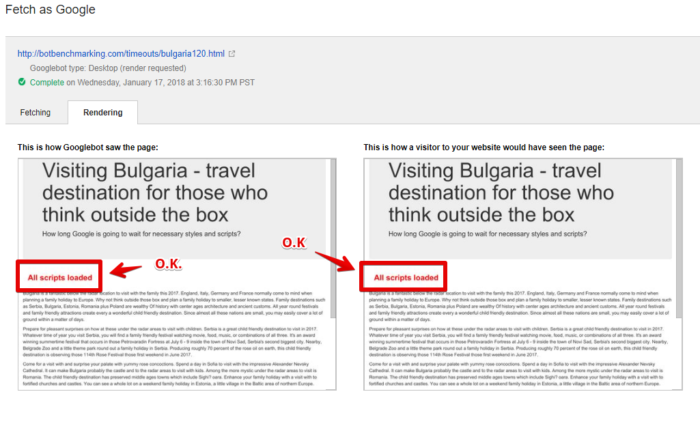
It turned out that the Fetch and Render tools were waiting for the script to load 120 seconds (!), After which the page was displayed correctly.
Page analysis with Fetch and Render
However, the indexing system was not so patient.
Results of experimental site indexing
Here you can see that the Google indexing system simply did not wait for the download of the first script and analyzed the page without taking into account the results of the work of this script.
As you can see, the Google Search Console is a great tool. However, they should be used only to test the technical ability of Google Robots to analyze the page. Do not use this tool to check if the indexing system is waiting for your scripts to load.
Google cache analysis and JavaScript-intensive sites
Many SEO experts have used the Google cache to search for problems with page analysis. However, this technique is not suitable for JS-intensive sites, as the Google cache itself is the original HTML that Googlebot downloads from the server (note this is confirmed many times by John Muller from Google).
Google Cache stuff
Looking through the contents of the cache, you can see how your browser interprets the HTML compiled by Googlebot. This has nothing to do with page formation for indexing purposes. If you want to know more about the Google cache, take a look at this material .
Using the site command instead of analyzing the Google cache
Currently, one of the best ways to check whether any data has been indexed by Google is to use the
site command.To do this, simply copy a piece of text from your page and enter the following command in the Google search engine:
site:{your website} "{fragment}" Command site
If, in response to such a command, you see the required fragment in the search results, it means that the data has been indexed.
Here I would like to note that such search queries are recommended to be performed in anonymous mode. Several times I had cases when the editors of the site changed the texts, and for some reason the
site command reported that old texts were indexed. After switching to anonymous browser mode, this command began to produce the correct result.View HTML-page code and audit sites based on JS
The HTML file is the source information that the browser uses to form the page. I assume that you know what an HTML document is. It contains information about the layout of the page - for example, about splitting text into paragraphs, about images, links, it includes commands for downloading JS and CSS files.
You can view the HTML code of the page in the Google Chrome browser by calling the context menu by right-clicking and selecting the View page source command.
However, using this mode of viewing the page code, you will not see the dynamic content (that is, the changes made to the page using JavaScript).
DOM should be analyzed instead. This can be done using the command of the same Inspect Element menu (view code).
Differences between the source HTML code received from the server and the DOM
The source HTML code received from the server (what is displayed by the View page source command) is something like a culinary recipe. It provides information about what ingredients are part of a certain dish, contains instructions for cooking. But the recipe is not a finished dish.
The DOM (Inspect Element team) is an HTML-recipe dish. At the very beginning, the browser loads the “recipe”, then prepares the dish, and as a result, after the page is fully loaded, something “edible” appears before us.
HTML downloaded from server and DOM
Please note that if Google fails to generate a page based on the loaded HTML code, it can simply index this HTML source code (which does not contain dynamically updated content). Details on this can be found in this Barry Adams article . Barry also gives advice on how to quickly compare source HTML and DOM.
Results
In this article, we talked about how Google handles sites that are created using JavaScript technology. In particular, the fact that Chrome 41 is used to analyze pages on Google is of great importance. This imposes certain restrictions on the use of JavaScript.
In the second part of the translation of this material we will focus on what you should pay attention to so that JS-sites are properly indexed by search engines. There will also be raised some more topics related to SEO and JavaScript.
Dear readers! How do you analyze your sites, checking whether Google indexes them the way you expect it?
Source: https://habr.com/ru/post/350976/
All Articles