Multi-classification of Google queries using neural network in Python
Enough time has passed since the publication of my first article on the topic of natural language processing. I continued to actively explore this topic, discovering something new for myself every day.
Today I would like to talk about one of the ways to classify search queries by category using the Keras neural network. The subject area of the queries was chosen scope of cars.
The basis was taken of a dataset of ~ 32,000 search queries, marked up in 14 classes: Avtoistoriya, Auto Insurance, VU (driver's license), Complaints, Record in traffic police, Record in MADI, Record on medical commission, Violations and fines, Appeals in MADI and AMPP, Title, Registration, Registration Status, Taxi, Evacuation.
')
Dataset itself (.csv file) looks like this:
And so on…
Before building a model of a neural network, it is necessary to prepare a dataset, namely, remove all stop words, special characters. So, as in requests like “break through Cymru 2.4 by wines number online” the numbers do not carry a semantic load, we will delete them too.
Stop words are taken from the NLTK package. Also, list the stop words with symbols.
This is what should happen in the end:
The request that will be received at the entrance for classification also needs to be prepared. Let's write a function that will "clear" the request.
You can’t just take ordinary words into a neural network, and even in Russian! Before we start learning the network, we transform our queries into sequence matrices (sequences), and classes must be represented as a vector of size N, where N is the number of classes. To transform the data, we need the Tokenizer library, which, by associating a separate index with each word, can convert requests (sentences) into arrays
indexes. But since the lengths of requests can be different, the lengths of the arrays will be different, which is unacceptable for a neural network. To solve this problem, it is necessary to transform the query into a two-dimensional array of sequences of equal length, as previously discussed. With the output (class vector), the situation is slightly simpler. The class vector will contain either ones or zeros, which indicates that the request belongs to the corresponding class.
So, look what happened:
We initialize the model by adding several layers, then compile it, indicating that the loss function will be “categorical_crossentropy” as we have more than 2 classes (not binary). Then, we will train and save the model to a file. See the code below:
By the way, accuracy (accuracy) in training was 97%, which is still a pretty good result.
Now we will write a small script for the command line that takes as input an argument - a search query, and on output gives the class to which the query most likely belongs according to the model we created earlier. I will not go into the details of the code in this section, all sources look at GITHUB . Let's get down to business, namely, run the script on the command line and start typing requests:
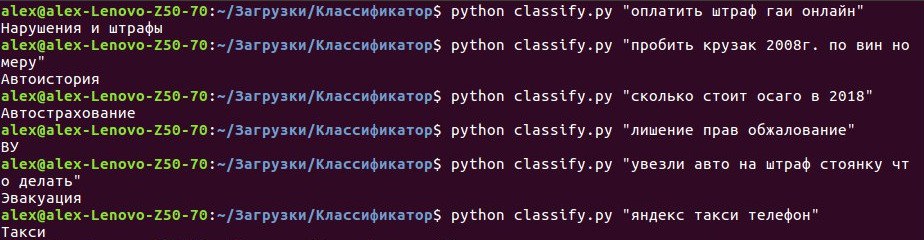
Figure 1 - Example of using a classifier
The result is quite obvious - the classifier accurately recognizes any queries we enter, which means that all the work was done for a reason!
The neural network coped with the task perfectly and it can be seen with an unarmed look. An example of the practical application of this model can be considered the sphere of public services, where citizens submit all sorts of applications, complaints, etc. By automating the reception of all these “papers” with the help of the intellectual classification, it is possible to significantly speed up the work of all government agencies.
Your suggestions on the practical application, as well as the opinion about the article I wait in the comments!
Today I would like to talk about one of the ways to classify search queries by category using the Keras neural network. The subject area of the queries was chosen scope of cars.
The basis was taken of a dataset of ~ 32,000 search queries, marked up in 14 classes: Avtoistoriya, Auto Insurance, VU (driver's license), Complaints, Record in traffic police, Record in MADI, Record on medical commission, Violations and fines, Appeals in MADI and AMPP, Title, Registration, Registration Status, Taxi, Evacuation.
')
Dataset itself (.csv file) looks like this:
;
;
;
;
;
;
;
;
;
And so on…
Dataset preparation
Before building a model of a neural network, it is necessary to prepare a dataset, namely, remove all stop words, special characters. So, as in requests like “break through Cymru 2.4 by wines number online” the numbers do not carry a semantic load, we will delete them too.
Stop words are taken from the NLTK package. Also, list the stop words with symbols.
This is what should happen in the end:
stop = set(stopwords.words('russian')) stop.update(['.', ',', '"', "'", '?', '!', ':', ';', '(', ')', '[', ']', '{', '}','#','№']) def clean_csv(df): for index,row in df.iterrows(): row[''] = remove_stop_words(row['']).rstrip().lower() The request that will be received at the entrance for classification also needs to be prepared. Let's write a function that will "clear" the request.
def remove_stop_words(query): str = '' for i in wordpunct_tokenize(query): if i not in stop and not i.isdigit(): str = str + i + ' ' return str Data formalization
You can’t just take ordinary words into a neural network, and even in Russian! Before we start learning the network, we transform our queries into sequence matrices (sequences), and classes must be represented as a vector of size N, where N is the number of classes. To transform the data, we need the Tokenizer library, which, by associating a separate index with each word, can convert requests (sentences) into arrays
indexes. But since the lengths of requests can be different, the lengths of the arrays will be different, which is unacceptable for a neural network. To solve this problem, it is necessary to transform the query into a two-dimensional array of sequences of equal length, as previously discussed. With the output (class vector), the situation is slightly simpler. The class vector will contain either ones or zeros, which indicates that the request belongs to the corresponding class.
So, look what happened:
# CSV df = pd.read_csv('cleaned_dataset.csv',delimiter=';',encoding = "utf-8").astype(str) num_classes = len(df[''].drop_duplicates()) X_raw = df[''].values Y_raw = df[''].values # tokenizer = Tokenizer(num_words=max_words) tokenizer.fit_on_texts(X_raw) x_train = tokenizer.texts_to_matrix(X_raw) # encoder = LabelEncoder() encoder.fit(Y_raw) encoded_Y = encoder.transform(Y_raw) y_train = keras.utils.to_categorical(encoded_Y, num_classes) Building and compiling the model
We initialize the model by adding several layers, then compile it, indicating that the loss function will be “categorical_crossentropy” as we have more than 2 classes (not binary). Then, we will train and save the model to a file. See the code below:
model = Sequential() model.add(Dense(512, input_shape=(max_words,))) model.add(Activation('relu')) model.add(Dropout(0.5)) model.add(Dense(num_classes)) model.add(Activation('softmax')) model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy']) model.fit(x_train, y_train, batch_size=batch_size, epochs=epochs, verbose=1) model.save('classifier.h5') By the way, accuracy (accuracy) in training was 97%, which is still a pretty good result.
Model testing
Now we will write a small script for the command line that takes as input an argument - a search query, and on output gives the class to which the query most likely belongs according to the model we created earlier. I will not go into the details of the code in this section, all sources look at GITHUB . Let's get down to business, namely, run the script on the command line and start typing requests:
Figure 1 - Example of using a classifier
The result is quite obvious - the classifier accurately recognizes any queries we enter, which means that all the work was done for a reason!
Conclusions and Conclusion
The neural network coped with the task perfectly and it can be seen with an unarmed look. An example of the practical application of this model can be considered the sphere of public services, where citizens submit all sorts of applications, complaints, etc. By automating the reception of all these “papers” with the help of the intellectual classification, it is possible to significantly speed up the work of all government agencies.
Your suggestions on the practical application, as well as the opinion about the article I wait in the comments!
Source: https://habr.com/ru/post/350900/
All Articles