We study parallel computing with OpenMPI and a supercomputer on the example of hacking neighbor WiFi
At the time of writing the thesis, one of the research directions was parallelization of the search in the state space on computing clusters. I had access to a computing cluster, but there was no programming practice for clusters (or HPC - High Performance Computing). Therefore, before moving on to the combat mission, I wanted to practice something simple. But I am not a fan of abstract hello world without real practical problems, therefore such a task was quickly found.

Everyone knows that brute force is the most inefficient way to select passwords. However, with the advent of supercomputers, it became possible to significantly speed up this process, since, as a rule, the search will be paralleled with virtually no overhead. Therefore, in theory, a process with a linear coefficient can be accelerated on a cluster, i.e. having 100 cores - speed up the process 1000 * k times (where 0.0 <k <= 1.0). Is it in practice?
Therefore, as a training exercise, the task was to check it. A practical task was the organization of brute force passwords to WPA2 on a computing cluster. Therefore, in this article I will describe the methodology used, the results of experiments and lay out the source codes written for this.
It should be understood that the practical use of the problem being solved tends to zero, since no one will actually drive huge clusters, burning electricity worth hundreds of times more than the cost of the router and the annual subscription fee for the Internet, in order to find the password for this poor router. But if you close your eyes to this and look at the rating of supercomputers , you can see that the top clusters include up to 6 million cores. This means that if on a single-core machine a certain password is selected for 10 years, then such a cluster in the case of a spherical horse in a vacuum will deal with it in 10 365 24 60 60/6000000 = 53 seconds.
How WPA2 Authorization Works
There are enough resources on this topic in the open spaces of the network, so I will explain very briefly. Suppose there is an access point and a client device nearby. If the client wants to establish a connection, he initiates a sequence of packet exchange, during which he tells the password to the access point, and the point decides whether to grant him access or not. If they "agree", then the connection is considered established.
In order for an attacker to obtain an authorization password, it is necessary to fully listen to the exchange of messages between the access point and the client, and then pick up a hash from a specific field of a specific package (the so-called handshake). It is in this package that the client tells his password.
But how to catch the authorization process? If we assume that we are breaking the neighbor's WiFi, then we must either wait until the neighbor comes out with the phone and comes back, or forcibly break the connection. And there is such an opportunity. To do this, send a request to disconnect the connection, to which the devices will eventually respond, and reconnection will occur. For the user, this process will be invisible, and we will find the authorization process.
Instruments
The packages themselves can be caught by “special” WiFi points, the drivers for which are available in the specialized Kali Linux distribution , as are all the necessary tools. On ebay or aliexpress, you can find hundreds of suitable points, and compatibility should be checked on the OS website in advance (compatibility should be checked with the chip on which the point is based).
However, for this work the greatest interest are the tools for processing a handshake package and selecting a password. The most famous and advanced tool is aircrack-ng , which also has open source code. We still need it, but this later.
However, they are all designed to use a local processor or video card. I have not found such a tool to run on a supercomputer, which means we don’t invent a bicycle and it's time to write it ourselves.
Alphabetical enumeration
Before something parallel, you need to make a semantic part - the search mechanism. To do this, we introduce the concept of "alphabet" on the basis of which the search is carried out. The alphabet is a non-repeating set of all characters that a password can make up. Therefore, if the alphabet has N symbols, then any password can be represented as a number in the Nth numeral system, where each digit corresponds to a symbol with an identical sequence number.
: abcdefgh (8 , ) 00000 => aaaaa 01070 => abaha 11136 => bbbdg Therefore, we will create the class key_manager, which will be initialized with a string alphabet.
class key_manager { using key_t = std::string; using internal_key_t = numeric_key_t; key_manager(const key_t & _alphabet); // key_id_t get_key_id(const internal_key_t & key) const; // void to_internal(const key_t & alpha_key, internal_key_t & int_key) const; // key_id_t get_key_id(const key_t & alpha_key) const; }; It will need methods for converting from internal representation (in numerical form) to string form and in the opposite direction. In the opposite direction, you will need to convert if you need to start with some given password, and not a zero one, for example, if you need to continue the search, and not start over.
At the same time, the numbers themselves will be stored in a special class, the so-called internal representation. I do not want to lose readability and do it correctly, so we will make it in the form of a vector, where each element corresponds to a “number”.
struct numeric_key_t { ... std::vector<uint8_t> data; }; The ordinal identifier will be an integer, take as an example a 128-bit unsigned int.
using key_id_t = __uint128_t; Of course, if you do it in an entirely clever way, then you should write your class big_integer, but as part of my experiments, all the passwords fit into a 128-bit integer, so we will not waste time on things that will never be needed.
Search Engine Architecture
The task of the search engine is to iterate over the range of keys, to tell whether the correct one is found, and if so, to return the found key. But the engine doesn’t care what the passwords are for - for WiFi or md5, so we’ll hide the implementation details inside the template.
template<typename C> class brute_forcer : public key_manager { bool operator()(unsigned key_length, uint_t first, uint_t last, uint_t & correctKeyId) const; } Inventory of this method, we simply write a loop that goes linearly from first to last, and if a suitable key is found, it will return true and write the identifier found in the correctKeyId.
using checker_t = C; ... private: checker_t checker; ... if(checker(first, str_key, correctVal, correctKeyId)) return true; Thus, it becomes clear what the interface should be for a class that already "knows" what the password is being selected for. In my version, I debugged this class on md5 before switching to wpa2, so you can find classes for both tasks in the repository. Next, let's do the checker itself.
We check the password
Let's start with a simple version for selecting a password for md5-hashes. The corresponding class will be as simple as possible, it only needs one method, in which the actual check takes place:
struct md5_crypter{ using value_t = std::string; bool operator()(typename key_manager::key_id_t cur_id, const std::string & code, const std::string & correct_res, typename key_manager::key_id_t & correctId) const { bool res = (md5(code) == correct_res); if(res) correctId = cur_id; return res; } }; The function std :: string md5 (std :: string) is used for this, which, on the basis of the given string, returns it md5. Everything is as simple as possible, so now let's hook up the aircrack-ng fragments.
We connect aircrack
The first difficulties come in getting the file with the handshake package. Here I find it difficult to remember exactly how I received it, but it seems that patch airodump or aircrack, so that it preserves the desired fragment. And maybe it was done by regular means. In any case - in the repository is an example of such a package.
Throwing away all unnecessary, for work we need the following structure:
struct ap_data_t { char essid[36]; unsigned char bssid[6]; WPA_hdsk hs; }; Which of the corresponding file can be considered as reading several fragments of the handshake file:
FILE * tmpFile = fopen(file_name.c_str(), "rb"); ap_data_t ap_data; fread(ap_data.essid, 36, 1, tmpFile); fread(ap_data.bssid, 6, 1, tmpFile); fread(&ap_data.hs, sizeof(struct WPA_hdsk), 1, tmpFile); fclose(tmpFile); Next, you need to perform some kind of preprocessing of this data in order not to repeat the calculations for each password (in the wpa2_crypter constructor), but here you can not really think about it, but simply transfer it from the aircrack. The most interesting is in aircrack / sha1-sse2.h, in which there are functions calc_pmk and calc_4pmk, which perform useful calculations.
Moreover, calc_4pmk is a version of calc_pmk, which, in the presence of an SSE2 processor, allows you to calculate as many as 4 keys in one step, thus speeding up the process 4 times. Considering that now such an extension exists on almost all processors, it should definitely be used, even though this adds a slight complexity to the implementation.
To do this, we add buffering to our wpa2_crypter class — since brute_forcer will request one key, calculations will be run only for every 4th time. And the data processing logic, again, is neatly transferable from aircrack, without changing anything. As a result, the verification function is obtained as follows:
value_t operator()(typename key_manager::key_id_t cur_id, const std::string & code, bool , typename key_manager::key_id_t & correctId) const { cache[localId].key_id = cur_id; memcpy(cache[localId].key, code.data(), code.size()); ++localId; if(localId == 4) { // 4 // calc_4pmk((char*)cache[0].key, (char*)cache[1].key, (char*)cache[2].key, (char*)cache[3].key, (char*)apData.essid, cache[0].pmk, cache[1].pmk, cache[2].pmk, cache[3].pmk); for(unsigned j = 0; j < localId; ++j) { for (unsigned i = 0; i < 4; i++){ pke[99] = i; HMAC(EVP_sha1(), cache[j].pmk, 32, pke, 100, cache[j].ptk + i * 20, NULL); } HMAC(EVP_sha1(), cache[j].ptk, 16, apData.hs.eapol, apData.hs.eapol_size, cache[j].mic, NULL); if(memcmp(cache[j].mic, apData.hs.keymic, 16) == 0) { //, correctId = cur_id; return true; } } localId = 0; } return false; } For all non-multiple 4m requests - we say that the key does not fit. And at 4m, if the key is found, then we return both the true and the key itself. The buffer is accumulated in an array of 4 elements of the following type:
struct cache_t { mutable char key[128]; unsigned char pmk[128]; unsigned char ptk[80]; unsigned char mic[20]; typename key_manager::key_id_t key_id; }; As a matter of fact, the re-finder is ready. In order to use it, perform the following actions:
// handshake- ap_data_t ap_data; // , wpa2_crypter crypter(ap_data); // brute_forcer<wpa2_crypter> bforcer(crypter, true, "abcdefg123455..."); // 1000 std::string correct_key; bforcer(8, 0, 1000, correct_key); However, aircrack can also count in one stream, but we don’t need it?
Concurrency architecture
After studying the existing frameworks and software for organizing parallel computing installed on a cluster to which I had access, I decided to stop at Open MPI . Work with him begins with the lines:
// fork MPI::Init(); // int rank = MPI::COMM_WORLD.Get_rank(); int size = MPI::COMM_WORLD.Get_size(); // ... // MPI::Finalize(); On the Init () call, the processes will be split, after which the rank number of the calculator will be in rank, and the total number of calculators in size. Processes can be run on different machines that make up a cluster, so you will have to forget about shared memory in an easy way - communication between processes comes with the help of two functions:
MPI :: COMM_WORLD.Recv (& res_task, sizeof (res_task), MPI :: CHAR, MPI_ANY_SOURCE, 0, status);
// MPI_Send( void* data, int count, MPI_Datatype datatype, int destination, int tag, MPI_Comm communicator) // MPI_Recv( void* data, int count, MPI_Datatype datatype, int source, int tag, MPI_Comm communicator, MPI_Status* status) More information about the interaction can be found here . And now let's invent the architecture of the parallel search engine.
For good, given the specifics of the problem, it would be worth making the following architecture. If there are N cores in a cluster, then every i-th core should check the keys with i + N * k identifiers, k = 0,1,2 ..., without interacting with each other. Then the performance will be maximum. But, as I said at the very beginning, the main task is to master the technology, therefore it is necessary to master the communication between the computers.
Therefore, I chose a different architecture, where the processes are divided into two types, and here I will describe the most clear option, the version is implemented in the repository a little bit harder and faster, but still this is not the fastest option.
To do this, conditionally divide the processes into 2 types - managers and workers. The manager will send tasks to workers, and the workers will, in fact, count hashes. For simplicity, the exchange between processes will be POD structs. Schematically, you can imagine the processes in the following figure:
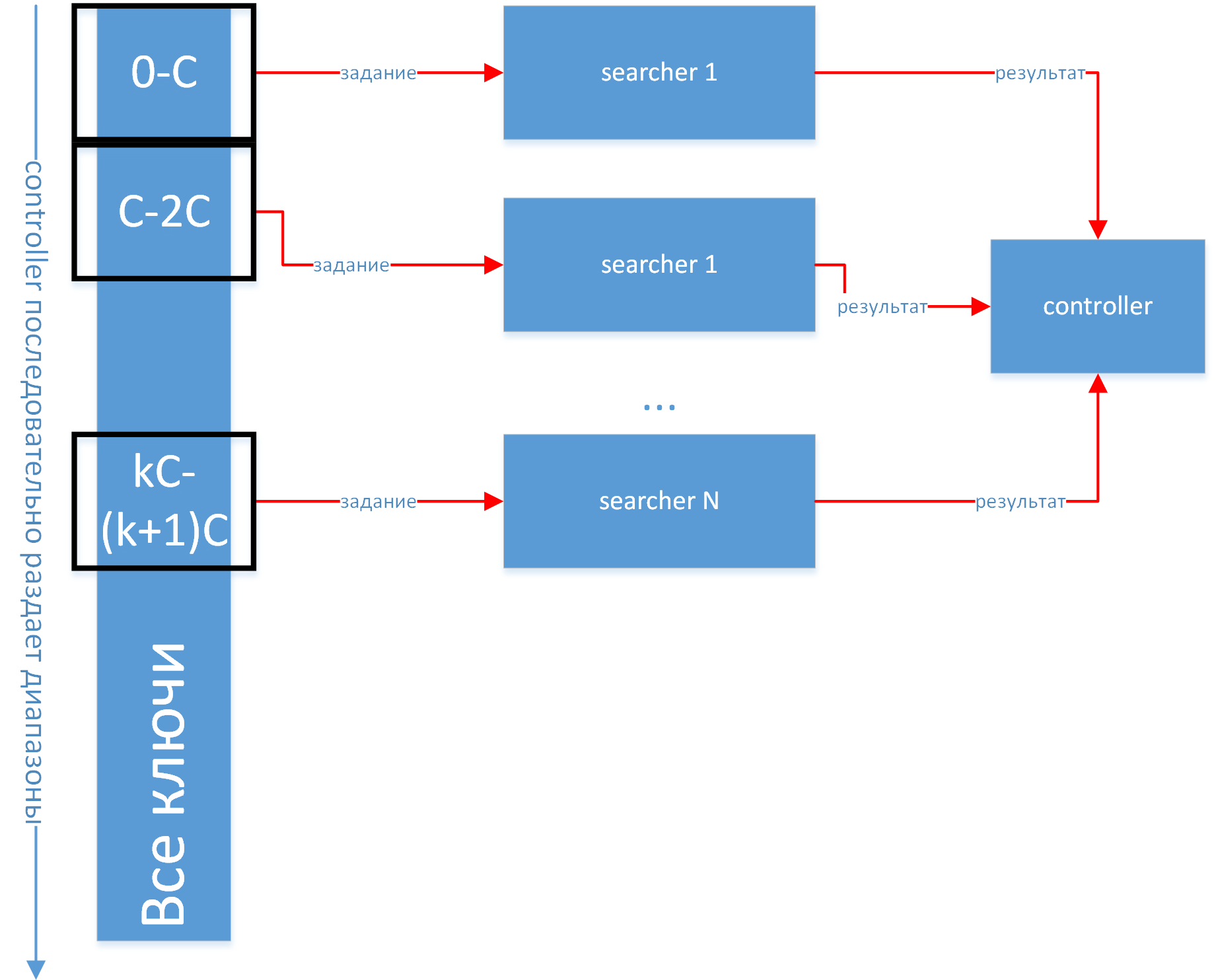
Create, respectively, the controller and searcher classes, which we instantiate after identifying the process:
if(rank == 0) { controller ctrl(this, start_key); ctrl.run(size - 1); } else { searcher srch(this, rank); srch.run(); } Objects searchers will wait for task messages, process them and send back reports messages. The controller will only deal with sending tasks and checking the results. Seriously, the controller can also do calculations during downtime, but for our example we will not complicate the architecture with this.
Moreover, it is necessary to avoid situations when the worker thread counted the task, and did not have time to get new and idle. This is achieved through the use of queues, and separation of the transport and computational flow in the simplest case with mutexes, although the good need to be done on conditional_variable. Therefore, schematically, the data exchange between the controller and the workflow can be represented as follows:

Instead of citing synchronized code snippets here, I refer to my own repository. And we turn to the final part - the experiments.
Experiments
It would seem that this is the most expected part of the article, but due to the simplicity of the problem being solved, the results completely coincide with the expected ones.
For experiments, a handshake package was taken, which I took from my point, as well as a pair of neighbors. By the way, the process is not very pleasant and deterministic, and it took more than an hour.
On my packages I was convinced of the correctness of the work of the developed software, and on the neighbors already tried the technology in real conditions.
In the above sources, I made a periodic output of debug information about the current speed, the number of scanned keys and the expected time to check the keys of the current length.
At my disposal was a small supercomputer with 128 cores in total. There was, of course, SSE in it, although for the purity of the experiment I turned it off - and received a speed 4 times less.
The dynamics of the work itself is also quite expected - it takes a few seconds to disperse and collect statistics, after which the engine shows a stable brute force. Depending on the number of cores, an approximately linear increase in speed is achieved (which is obvious), however, a simple controller core and careless synchronization of threads make themselves felt - the growth constant turned out to be in the region of 0.8–0.9.
But the most interesting thing awaited me when I started the engine on the neighbor's key - not having managed to overclock all the cores, the password was already found ... it was the date of birth of someone from the neighbor's family. On the one hand, I was disappointed, on the other - I still solved the initial problem.
I don’t see the absolute values of the speeds, because You can try it on your available machines - all the sources are at the end of the article. And knowing the coefficient of parallelism and the characteristics of the machine, you can quite accurately calculate what speed can be achieved.
Sources
The sources for the described implementation can be found in my github repository. The code was fully working, going under Linux and Mac OS. But ... more than 2 years have passed, I do not know how much the API of the same Open MPI has changed.
In the test / folder you can find an example of a handshake package compiled under the format used.
The code itself is rather dirty, but due to the lack of practical value of the problem being solved, there was no sense in combing it either. The project also does not develop due to the senselessness, but if someone liked the idea, or he saw why it can be used ... then take it and use it.
The start-up line indicates the handshake file and, optionally, the start key, if you want to start with a non-zero element.
brute_wpa2 k aaa123aaab ap_Dom.hshk
Parameter parsing itself is in src / brute_wpa2.cpp, from it you can also understand how to set the first key identifier by a number, as well as set the chunk size.
Conclusion
This article gives a small excursion into parallel programming on the example of the simplest practical problem and its fairly simple solution. I accomplished the task I have set - not only having mastered the modern technologies of parallel programming, I got the skills to accomplish the combat task in my thesis, but also picked up the password from the neighboring WiFi. True, I used them only once - to check the correctness, but it was still nice.
But returning to the practical usefulness of the work done, in connection with the latest events, I would like to note the rush around the bitcoins. Considering that the basis of WPA2 hacking is the calculation of SHA hashes, as in the mining of bitcoins, a new direction is opened for the development of this work. Since mining equipment has been developed that can only count the necessary hashes, it is interesting to check how adaptable it is and how it is applicable for WPA2 hacking. Of course, such chips are much more efficient than the latest general-purpose processors in the selection of hashes, so perhaps interesting results can be achieved here.
')
Source: https://habr.com/ru/post/350838/
All Articles