Parsing proposals for Russian language patterns
There are several parsers suitable for the Russian language. Some of them can even parse like SyntaxNet , MaltParser and AOT :
... or reveal facts like Tomita .
Looking at these parsers, I see some enormous computational complexity, memory requirements, licensing restrictions and ... the limitations of each solution, alas.
To understand what is so complicated there, I wanted to make my own parser. Fortunately, the weekend was long.
I thought, how do we analyze the text? How do we separate key elements from a phrase, build relationships between words in the head?
')
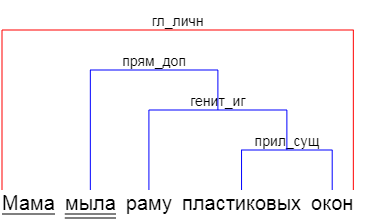
Tomita is said to be built on a GLR parser, which in turn extends an LR parser that reads the words in order, trying to build a tree of relationships between them.
I had the idea that the text should be considered as a set of stamps, which we have a good eye on. "A white moth on a red rose ", "a dark sky over the blue sea ", "a stupid penguin shyly hides " - everywhere we see a noun and the adjective relating to it. And we understand that the "white" refers to the moth, and not to the rose. How do we do it? At a minimum, we see that the “white” is masculine, like the “moth”, and the “red” is feminine, like the rose. In the case of "sky" and "sea", the case in which the noun is placed helps us.
Then, finding the stamps, we combine the resulting phrase pieces into other stamps, and so, until we understand the entire phrase - “moth on a rose” (moth is white, rose is red), “the sky above the sea” (the sky is dark, the sea is blue).
That is, to search for a pattern (adjective, noun), I need to look for a couple of words in the same case, number and gender. How? The natural solution for characterization (gramme) in Python is to use pymorphy2 by kmike
The words 'femn', 'ADJF', 'sing', 'gent', 'Qual' are the symbols for grammes adopted in pymorphy2 . Designations are unique, they can be used to uniquely identify the desired characteristics of the word.
Now, having a tool, we create a simple template:
Here we are looking for a noun (NOUN) in the nominative case (nomn), followed by a verb (VERB), then a noun in the accusative case (accs). The characteristics not described in the template are not important to us.
Let's make it a reader:
Don't be afraid of working here through StringIO - I wanted to do streaming reading, just in case, if you need to read large texts.
The given piece of code only reads the templates, but does nothing more. Add the parsed text and its parsing:
Pymorphy2 when analyzing a word returns an array of all possible variants, what kind of a word can it be: “soap” is a noun or verb. Therefore, our task is to check all these options and choose from them such that the characteristics of the word fit the pattern. This is done in the checkWord function.
We get the result of parsing:
Well, not bad for a start.
No, of course, now it is necessary to describe the conformity of cases, childbirth, etc. between words. Modifying the template description:
A line for defining variables
Add rule parsing to template parsing. The rule is compiled into two lambdas - to get the value before the "=" symbol, and for to get the second value.
And we add rule checking to text parsing - just calculating lambdas and comparing their results:
Drive on classics
We also introduce a rule for names:
It gives analysis:
Everything was so good, which meant we didn't notice anything. The parser broke down on the phrase “The younger brothers Misha and Vova go to kindergarten” - he could not confirm the rule
Therefore, the rule should be more complicated. Well, since I still compile lambdas from text, you can create one instead of the two that returns the result of the check. Then this rule can be written as an expression in pure Python-e:
It seemed to me that Python should have a built-in tool for getting the names “a” and “b” involved in the expression. The premonition was not deceived, a small reading of help and documentation led me to the AST parser, which had everything I needed, and the following code:
All rules rewrote on Python expressions. By the way, if the rule is written incorrectly, then it is not compiled even when reading the template dictionary and the program crashes by exception, so if the dictionary is read, then the rules are enforceable.
And everything turned out:
1. As you can see, I stopped on the search for individual templates, but did not begin to parse the result of the parsing in the parse tree. There are several reasons for this, and one of them is - I'm not sure what to do. Each parsing option gives us a little bit of information. Combining them into a tree, we are trying to squeeze knowledge into an artificial structure. A child can read and understand sentences without knowing which word is subject to it, and which one is predicate. He takes grains and creates in his head a picture of the (described) world. Why do we need more from the machine?
2. Obviously there is not enough rule for how one word can be removed in the text from another. So "Dad" became "Ilya", although between them are the words "and brother."
3. It is also obvious that you need to sort the results among themselves and discard the unlikely ones. Determining relevance is an open question, at a minimum it is possible to measure the distance of words from each other.
4. The rules, in addition to other parts of speech, lack punctuation. You can enter the constant literals "NOUN '-' NOUN", and you can, as in the example with the teacher above, check the sign in the rule.
5. Pymorphy2 can assume that words belong to parts of speech, therefore, even such options are possible:
However, the original words of Petrushevskaya had to be swapped, since There is no template with the inverse word order. It’s not that this is a problem, the template is not long to be entered, but the rearrangements of words in Russian happen often and not cover all of them with templates. Therefore, it makes sense to introduce any permutation modifiers into the template descriptions.
The code is on github .
... or reveal facts like Tomita .
Looking at these parsers, I see some enormous computational complexity, memory requirements, licensing restrictions and ... the limitations of each solution, alas.
To understand what is so complicated there, I wanted to make my own parser. Fortunately, the weekend was long.
main idea
I thought, how do we analyze the text? How do we separate key elements from a phrase, build relationships between words in the head?
')
Tomita is said to be built on a GLR parser, which in turn extends an LR parser that reads the words in order, trying to build a tree of relationships between them.
I had the idea that the text should be considered as a set of stamps, which we have a good eye on. "A white moth on a red rose ", "a dark sky over the blue sea ", "a stupid penguin shyly hides " - everywhere we see a noun and the adjective relating to it. And we understand that the "white" refers to the moth, and not to the rose. How do we do it? At a minimum, we see that the “white” is masculine, like the “moth”, and the “red” is feminine, like the rose. In the case of "sky" and "sea", the case in which the noun is placed helps us.
Then, finding the stamps, we combine the resulting phrase pieces into other stamps, and so, until we understand the entire phrase - “moth on a rose” (moth is white, rose is red), “the sky above the sea” (the sky is dark, the sea is blue).
Choosing the right tool.
That is, to search for a pattern (adjective, noun), I need to look for a couple of words in the same case, number and gender. How? The natural solution for characterization (gramme) in Python is to use pymorphy2 by kmike
import pymorphy2 as py def tags(word): morph = py.MorphAnalyzer() return morph.parse(word) >>> print(tags('')[0]) Parse(word='', tag=OpencorporaTag('ADJF,Qual femn,sing,gent'), normal_form='', score=0.125, methods_stack=((<DictionaryAnalyzer>, '', 86, 8),)) >>> print(tags('')[0].tag.grammemes) frozenset({'femn', 'ADJF', 'sing', 'gent', 'Qual'}) The words 'femn', 'ADJF', 'sing', 'gent', 'Qual' are the symbols for grammes adopted in pymorphy2 . Designations are unique, they can be used to uniquely identify the desired characteristics of the word.
First touches on canvas
Now, having a tool, we create a simple template:
source = ''' # # / _- NOUN,nomn VERB NOUN,accs ''' Here we are looking for a noun (NOUN) in the nominative case (nomn), followed by a verb (VERB), then a noun in the accusative case (accs). The characteristics not described in the template are not important to us.
Let's make it a reader:
class PPattern: def __init__(self): super().__init__() import io def parseSource(src): def parseLine(s): nonlocal arr, last s = s.strip() if s == '': last = None return if s[0] == '#': return if last is None: last = PPattern() arr.append(last) last.example = s else: last.tags = s.split() arr = [] last = None buf = io.StringIO(src) s = buf.readline() while s: parseLine(s) s = buf.readline() return arr s = parseSource(source) Don't be afraid of working here through StringIO - I wanted to do streaming reading, just in case, if you need to read large texts.
The given piece of code only reads the templates, but does nothing more. Add the parsed text and its parsing:
source = ''' # # / _- NOUN,nomn VERB NOUN,accs ADJF NOUN # NOUN,nomn VERB NOUN,loct ''' text = ''' ''' import pymorphy2 as py class PPattern: def __init__(self): super().__init__() def checkPhrase(self,text): def checkWordTags(tags, grams): for t in tags: if t not in grams: return False return True def checkWord(tags, word): variants = morph.parse(word) for v in variants: if checkWordTags(self.tags[nextTag].split(','), v.tag.grammemes): return (word, v) return None morph = py.MorphAnalyzer() words = text.split() nextTag = 0 result = [] for w in words: res = checkWord(self.tags[nextTag].split(','), w) if res is not None: result.append(res) nextTag = nextTag + 1 if nextTag >= len(self.tags): return result return None def parseText(pats, text): def parseLine(line): was = False for p in pats: res = p.checkPhrase(line) if res: print('+',line, p.tags, [r[0] for r in res]) was = True if not was: print('-',line) buf = io.StringIO(text) s = buf.readline() while s: s = s.strip() if s != '': parseLine(s) s = buf.readline() patterns = parseSource(source) parseText(patterns, text) Pymorphy2 when analyzing a word returns an array of all possible variants, what kind of a word can it be: “soap” is a noun or verb. Therefore, our task is to check all these options and choose from them such that the characteristics of the word fit the pattern. This is done in the checkWord function.
We get the result of parsing:
+ ['NOUN,nomn', 'VERB', 'NOUN,accs'] ['', '', '']
+ ['NOUN,nomn', 'VERB', 'NOUN,accs'] ['', '', '']
+ ['NOUN,nomn', 'VERB', 'NOUN,accs'] ['', '', '']
+ ['ADJF', 'NOUN'] ['', '']
+ ['NOUN,nomn', 'VERB', 'NOUN,accs'] ['', '', '']
+ ['ADJF', 'NOUN'] ['', '']
Well, not bad for a start.
And what is all this?
No, of course, now it is necessary to describe the conformity of cases, childbirth, etc. between words. Modifying the template description:
source = ''' # ADJF NOUN -a- -b- # , = a.case = b.case = a.number = b.number = a.gender = b.gender ''' A line for defining variables
-a- -b- and rule lines that begin with "=" appeared. In general, I did not bother with the syntax of templates, so each statement lives on one line, and the type of statement is determined by the first character.Add rule parsing to template parsing. The rule is compiled into two lambdas - to get the value before the "=" symbol, and for to get the second value.
def parseFunc(v, names): dest = v.split('.') index = names.index(dest[0]) dest = (eval('lambda a: a.' + '.'.join(dest[1:])), index) return dest def parseLine(s): ... elif s[0] == '-': # s = [x.strip('-') for x in s.split()] last.names = s elif s[0] == '=': # s = [x for x in s[1:].split() if x != ''] dest = parseFunc(s[0],last.names) src = parseFunc(s[2],last.names) last.rules.append(((dest[1],src[1]), dest, src)) else: ... And we add rule checking to text parsing - just calculating lambdas and comparing their results:
... res = checkWord(self.tags[nextTag].split(','), w) if res is not None: result.append(res) usedP.add(wi) if not self.checkRules(usedP, result): result.remove(res) usedP.remove(wi) else: nextTag = nextTag + 1 if nextTag >= len(self.tags): return (result, usedP) ... def checkRules(self, used, result): for r in self.rules: if max(r[0]) < len(result): destRes = result[r[0][0]] destV = destRes[1] destFunc = r[1][0] srcRes = result[r[0][1]] srcFunc = r[2][0] srcV = srcRes[1] if not self.checkPropRule(destFunc,destV, srcFunc, srcV): return False return True def checkPropRule(self, getFunc, getArgs, srcFunc, srcArgs, \ op = lambda x,y: x == y): v1 = getFunc(getArgs) v2 = srcFunc(srcArgs) return op(v1,v2) Drive on classics
+ ['ADJF', 'NOUN'] ['', '']
+ ['ADJF', 'NOUN'] ['', '']
+ ['NOUN,nomn', 'VERB', 'PREP', 'NOUN,loct'] ['', '', '', '']
+ ['NOUN,nomn', 'VERB', 'PREP', 'NOUN,loct'] ['', '', '', '']We also introduce a rule for names:
# NOUN Name -a- -b- = a.tag.case = b.tag.case = a.tag.number = b.tag.number It gives analysis:
+ - ['NOUN', 'Name'] ['', '']More rules, good and different
Everything was so good, which meant we didn't notice anything. The parser broke down on the phrase “The younger brothers Misha and Vova go to kindergarten” - he could not confirm the rule
= a.gender = b.gender , because the “younger ones” have no tribal affiliation and can refer to the masculine word “brothers” , and to the female "sister."Therefore, the rule should be more complicated. Well, since I still compile lambdas from text, you can create one instead of the two that returns the result of the check. Then this rule can be written as an expression in pure Python-e:
= a.tag.gender is None or a.tag.gender == b.tag.gender It seemed to me that Python should have a built-in tool for getting the names “a” and “b” involved in the expression. The premonition was not deceived, a small reading of help and documentation led me to the AST parser, which had everything I needed, and the following code:
import ast def parseSource(src): def parseFunc(expr, names): m = ast.parse(expr) # varList = list(set([ x.id for x in ast.walk(m) if type(x) == ast.Name])) # indexes = [ names.index(v) for v in varList ] lam = 'lambda %s: %s' % (','.join(varList), expr) return (indexes, eval(lam), lam) All rules rewrote on Python expressions. By the way, if the rule is written incorrectly, then it is not compiled even when reading the template dictionary and the program crashes by exception, so if the dictionary is read, then the rules are enforceable.
And everything turned out:
+ ['ADJF', 'NOUN'] ['', '']All text and parsing
Phrases are mostly taken from the Primer. After all, if you start to read the car, it is better to use a proven method.
Pattern Dictionary
Parsing
# , text = ''' - ''' Pattern Dictionary
# source = ''' # # # / _- NOUN,nomn VERB NOUN,accs # -a- -b- -c- = a.tag.number == b.tag.number # :SNOUN # ADJF NOUN -a- -b- # = a.tag.case == b.tag.case = a.tag.number == b.tag.number = a.tag.gender is None or a.tag.gender == b.tag.gender # # NOUN,nomn VERB PREP NOUN,loct -a- -b- -c- -d- = a.tag.number == b.tag.number # VERB INFN # NOUN Name -a- -b- = a.tag.case == b.tag.case = a.tag.number == b.tag.number # NOUN CONJ NOUN -a- -c- -b- = a.tag.case == b.tag.case # NOUN PNCT NOUN -a- -c- -b- = a.tag.case == b.tag.case = c.normal_form == '-' ''' Parsing
+ ['NOUN,nomn', 'VERB', 'NOUN,accs'] ['', '', '']
+ ['NOUN,nomn', 'VERB', 'NOUN,accs'] ['', '', '']
+ ['NOUN,nomn', 'VERB', 'NOUN,accs'] ['', '', '']
+ ['ADJF', 'NOUN'] ['', '']
+ ['NOUN,nomn', 'VERB', 'NOUN,accs'] ['', '', '']
+ ['ADJF', 'NOUN'] ['', '']
+ ['ADJF', 'NOUN'] ['', '']
+ ['ADJF', 'NOUN'] ['', '']
+ ['NOUN', 'Name'] ['', '']
+ ['NOUN', 'Name'] ['', '']
+ ['NOUN', 'Name'] ['', '']
+ ['NOUN', 'CONJ', 'NOUN'] ['', '', '']
+ ['NOUN,nomn', 'VERB', 'NOUN,accs'] ['', '', '']
+ - ['NOUN', 'Name'] ['', '']
+ - ['NOUN', 'PNCT', 'NOUN'] ['', '-', '']
+ - ['NOUN', 'PNCT', 'NOUN'] ['', '-', '']
+ ['NOUN,nomn', 'VERB', 'NOUN,accs'] ['', '', '']
+ ['NOUN,nomn', 'VERB', 'PREP', 'NOUN,loct'] ['', '', '', '']
+ ['NOUN,nomn', 'VERB', 'NOUN,accs'] ['', '', '']
+ ['ADJF', 'NOUN'] ['', '']
+ ['ADJF', 'NOUN'] ['', '']
+ ['NOUN', 'CONJ', 'NOUN'] ['', '', '']
+ ['NOUN', 'CONJ', 'NOUN'] ['', '', '']
+ ['ADJF', 'NOUN'] ['', '']
+ ['ADJF', 'NOUN'] ['', '']
+ ['NOUN,nomn', 'VERB', 'PREP', 'NOUN,loct'] ['', '', '', '']
+ ['NOUN,nomn', 'VERB', 'PREP', 'NOUN,loct'] ['', '', '', '']
+ ['VERB', 'INFN'] ['', '']
What's next?
1. As you can see, I stopped on the search for individual templates, but did not begin to parse the result of the parsing in the parse tree. There are several reasons for this, and one of them is - I'm not sure what to do. Each parsing option gives us a little bit of information. Combining them into a tree, we are trying to squeeze knowledge into an artificial structure. A child can read and understand sentences without knowing which word is subject to it, and which one is predicate. He takes grains and creates in his head a picture of the (described) world. Why do we need more from the machine?
2. Obviously there is not enough rule for how one word can be removed in the text from another. So "Dad" became "Ilya", although between them are the words "and brother."
3. It is also obvious that you need to sort the results among themselves and discard the unlikely ones. Determining relevance is an open question, at a minimum it is possible to measure the distance of words from each other.
4. The rules, in addition to other parts of speech, lack punctuation. You can enter the constant literals "NOUN '-' NOUN", and you can, as in the example with the teacher above, check the sign in the rule.
5. Pymorphy2 can assume that words belong to parts of speech, therefore, even such options are possible:
>>> parseText(patterns, ' ')
+ ['ADJF', 'NOUN'] ['', '']
+ ['NOUN', 'Name'] ['', '']
However, the original words of Petrushevskaya had to be swapped, since There is no template with the inverse word order. It’s not that this is a problem, the template is not long to be entered, but the rearrangements of words in Russian happen often and not cover all of them with templates. Therefore, it makes sense to introduce any permutation modifiers into the template descriptions.
The code is on github .
Source: https://habr.com/ru/post/350802/
All Articles