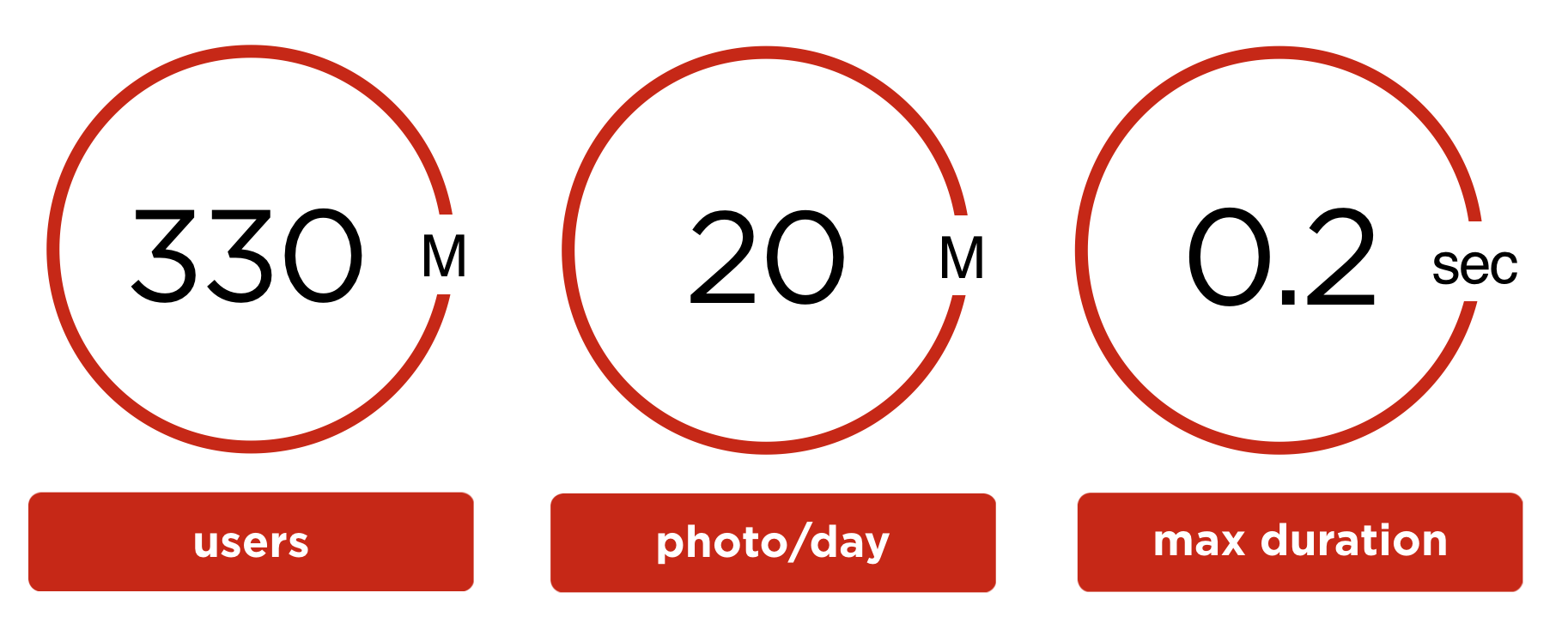
Schi, or Recognition of 330 million people at a speed of 400 photos / sec
The recognition of faces in 2018 will not surprise anyone - every student, maybe even a schoolboy, did it. But everything becomes a bit more complicated when you don’t have 1 million users, but:
- 330 million user accounts;
- 20 million user photos are uploaded daily;
- the maximum time for processing one photo should not exceed 0.2 seconds ;
- limited equipment for solving the problem.

In this article, we will share the experience of developing and launching the facial recognition system on user photos on the Odnoklassniki social network and tell you everything from A to Z:
- mathematical apparatus;
- technical implementation;
- launch results;
- and the StarFace share that we used for PR of our solution.
Task
More than 330 million accounts registered in Odnoklassniki, these accounts contain more than 30 billion photos.
OK users upload 20 million photos per day. On 9 million photos uploaded per day, there are faces, and a total of 23 million faces are detected. That is, an average of 2.5 faces per photo containing at least one face.
Users have the opportunity to mark people in a photo, but usually they are lazy. We decided to automate the search for friends in photos in order to increase the user's awareness of the photos uploaded with him and the amount of feedback for user photos.
In order for the author to instantly confirm friends after uploading a photo, in the worst case, the processing of the photo must be within 200 milliseconds.
User recognition system in the social network
Face Recognition on Uploaded Photo
The user uploads a photo from any client (from a browser or iOS, Android mobile applications), it hits the detector, whose task is to find faces and align them.
After the detector, the sliced and preprocessed faces fall on the neural network recognizer, which builds the characteristic profile of the user's face. After this, the most similar profile is searched in the database. If the degree of similarity of profiles is greater than the limit value, then the user is automatically detected, and we send him a notification that he is in the photo.
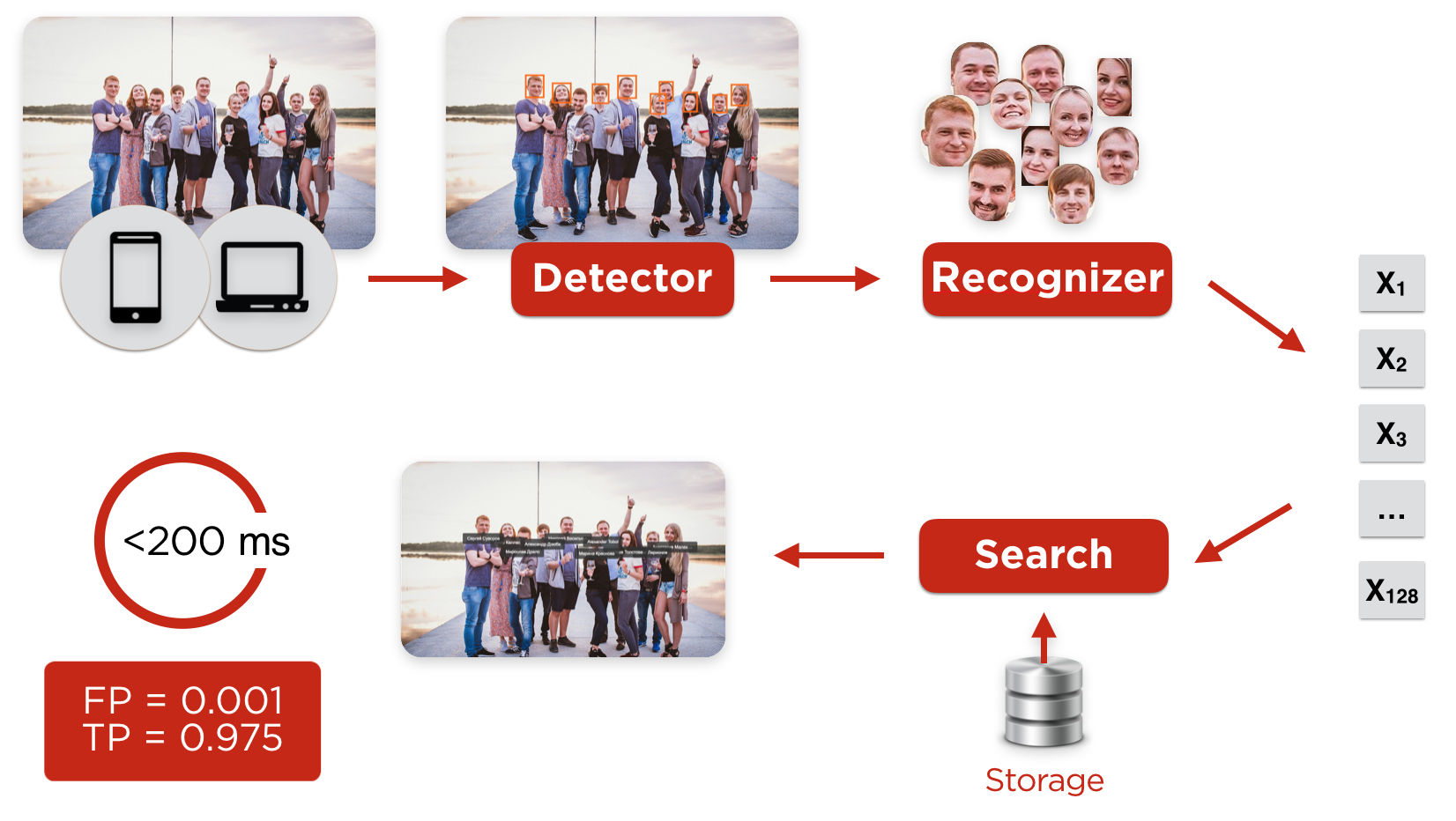
Figure 1. Recognizing users in the photo
Before you start automatic recognition, you need to create a profile for each user and fill out the database.
Building user profiles
For face recognition algorithms, just one photo, such as avatars, is enough. But will this avatar contain a profile photo? Users put photos of stars on avatars, and profiles are replete with memes or contain only group photos.

Figure 2. Difficult profile
Consider a user profile consisting of group photos only.
Determine the owner of the account (Fig. 2), if you consider his gender and age, as well as friends, whose profiles were built earlier.
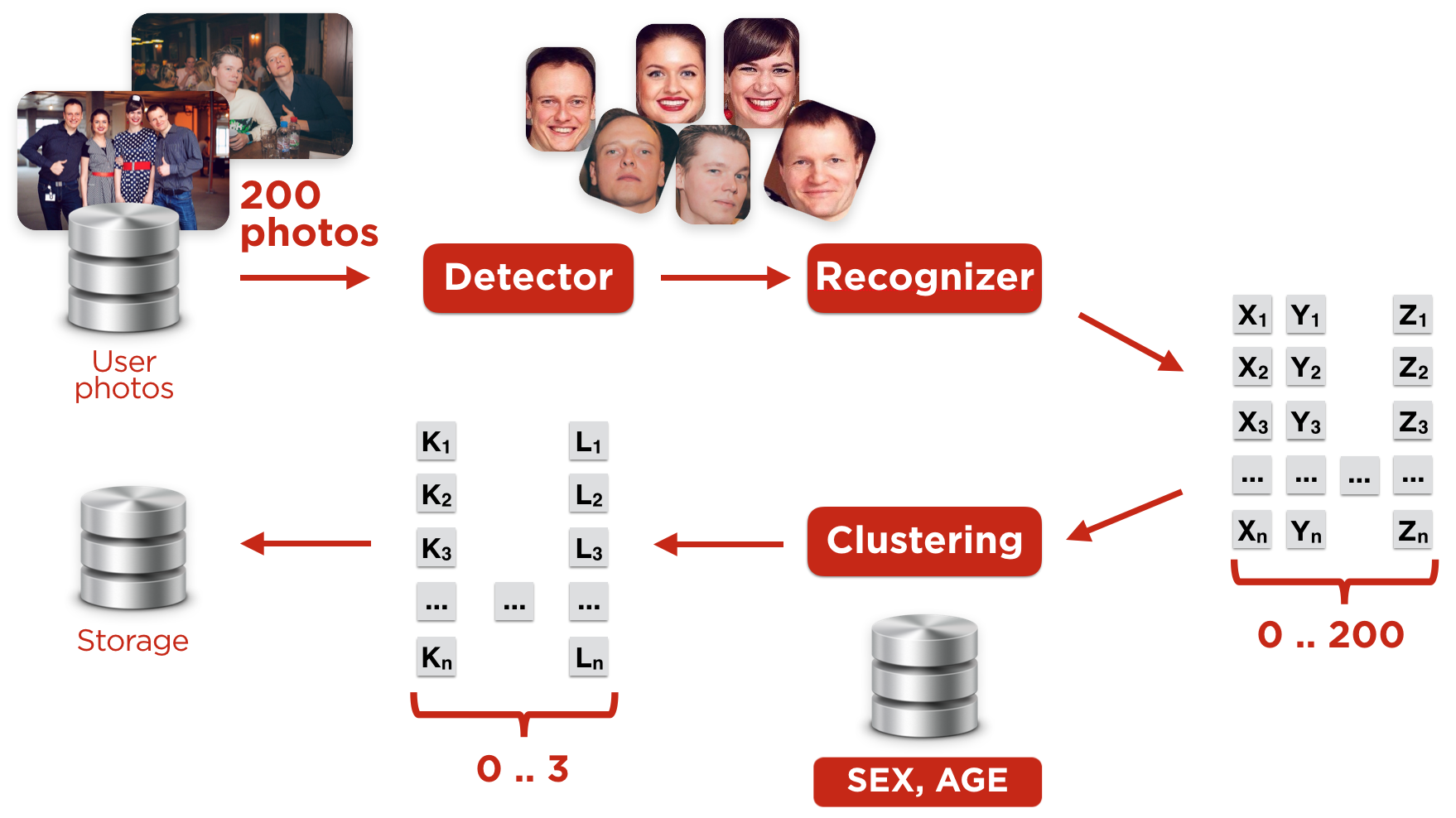
Figure 3. Building user profiles
We built the user profile as follows (Fig. 3):
1) Chose the highest quality photos of the user
If there were too many photos, we used no more than a hundred of the best.
Photo quality was determined based on:
- the presence of user marks on the photo (fotopinov) manually;
- photo information (photo uploaded from a mobile phone, taken on the front camera, on vacation, ...);
- photo was on avatar
2) We searched for these faces in these photos
- it is not scary if it will be other users (in step 4 we will filter them)
3) Calculate the characteristic facial vector
- such a vector is called embedding
4) Produced clustering vectors
The task of this clustering is to determine which particular set of vectors belongs to the account holder. The main problem is the presence of friends and relatives in the photographs. For clustering, we use the DBScan algorithm.
5) Determined the leading cluster
For each cluster, we calculated the weight based on:
- cluster size;
- the quality of the photographs, according to which embeddings in the cluster are built;
- the presence of photopins attached to individuals from the cluster;
- matching gender and age of individuals in the cluster with information from the profile;
- The proximity of the cluster centroid to the profiles of friends previously calculated.
The coefficients of the parameters involved in calculating the weight of the cluster will be trained by linear regression. Honest gender and age profile - a separate challenge, we will tell about it later.
In order for a cluster to be considered a leader, it is necessary that its weight be greater than the nearest competitor by a constant calculated on the training set. If the leader is not found, we once again go to point 2, but use a larger number of photos. For some users, we saved two clusters. This happens for joint profiles - some families have a common profile.
6) Received user embeddings in his clusters
- Finally, we build a vector that will characterize the appearance of the account holder, “user embedding”.
User embedding is the centroid of the selected (leading) cluster.
You can build centroids in many different ways. After numerous experiments, we returned to the simplest of them: averaging the vectors included in the cluster.
Like clusters, the user may have several embeddings.
During the iteration, we processed eight billion photos, iterated 330 million profiles and built embeddings for three hundred million accounts. On average, to build one profile, we processed 26 photos. At the same time, even one photo is enough to build a vector, but the larger the photo, the greater our confidence that the built profile belongs to the account holder.
We made the process of building all profiles on the portal several times, as the availability of information about friends improves the quality of cluster selection.
The amount of data needed to store the vectors is ~ 300 GB.
Face detector
The first version of the OK face detector was launched in 2013 on the basis of a third-party solution, similar in characteristics to the detector based on the Viola-Jones method. For 5 years, this solution is outdated, modern solutions based on MTCNN , show accuracy twice as high. Therefore, we decided to follow the trends and built our cascade of convolutional neural networks (MTCNN).
For the operation of the old detector, we used more than 100 “old” servers with CPUs. Almost all modern algorithms for finding faces in the photo are based on convolutional neural networks that most effectively work on the GPU. We were unable to purchase a large number of video cards for objective reasons: expensive all bought miners. It was decided to run c detector on the CPU (well, do not throw out the same server).
To detect faces on the photos we upload, we use a cluster of 30 cars (the rest drank passed in the scrap). Detection when building custom vectors (iteration through accounts) is done on 1000 virtual cores with low priority in our cloud. The cloud solution is described in detail in the report of Oleg Anastasyev : One-cloud is the OS of the level of the data center in Odnoklassniki .
When analyzing the detector operation time, we encountered such a worse case: the top-level network skips too many candidates to the next cascade level, and the detector begins to work for a long time. For example, the search time reaches 1.5 seconds in such photos:

Figure 4. Examples of a large number of candidates after the first network in a cascade
Optimizing this case, we suggested that there are usually few faces in the photograph. Therefore, after the first stage of the cascade, we leave no more than 200 candidates, relying on the confidence of the corresponding neural network that this person.
This optimization reduced the worst case time to 350 ms, i.e., 4 times.
Applying a pair of optimizations (for example, replacing Non-Maximum Suppression after the first stage of the cascade with Blob detection based filtering), the detector was further dispersed 1.4 times without loss of quality.
However, progress on the spot also did not stand, and now it is more elegant methods to look for faces on the photo - see. FaceBoxes . We do not exclude that in the near future we will move to something similar.
Face Recognizer
When developing a recognizer system, we experimented with several architectures: Wide ResNet , Inception-ResNet , Light CNN .
Inception-ResNet showed itself a little bit better than the rest while staying on it.
The algorithm requires a trained neural network. It can be found on the Internet, buy or train yourself. For the training of neural networks, a certain set of data (dataset) is needed, on which training and validation takes place. Since face recognition is a well-known task, ready-made datasets already exist for it: MSCeleb, VGGFace / VGGFace2, MegaFace. However, here comes the harsh reality: the generalizing ability of modern neural networks in the tasks of identification by face (and indeed in general) leaves much to be desired.
And on our portal, faces are very different from what can be found in open datasets:
- Other age distribution - there are children in our photos;
- Other distribution of ethnic groups;
- There are people in very low quality and resolution (photos from the phone, taken 10 years ago, group photos).
The third point is easy to overcome, artificially reducing the resolution and imposing jpeg-artifacts, but the rest will not be able to emulate the quality.
Therefore, we decided to create our own dataset.
In the process of building a set of trial and error, we came to this procedure:
- We download photos from ~ 100k open profiles
Profiles are chosen randomly, minimizing the number of those who are friends with each other. As a result, we assume that each person from dataset appears in only one profile. - We build vectors (embeddingings) of persons
To build embeddings, we use the pre-trained open source neural network (we took it from here ). Cluster entities within each account
A couple of obvious observations:- We do not know how many different people appear on the photo from the account. Therefore, the clusteriser should not require the number of clusters as a hyperparameter.
- Ideally, for the faces of the same person, we hope to get very similar vectors that form dense spherical clusters. But the universe does not care about our aspirations, and in practice these clusters crawl into intricate forms (for example, for a person with glasses and without a cluster usually consists of two clots). Therefore, centroid-based methods will not help us here, you need to use density-based.
For these two reasons and the results of the experiments, DBSCAN was chosen. Hyperparameters were picked up by hands and validated by eyes, everything is standard here. For the most important of them - eps in terms of scikit-learn - came up with a simple heuristic on the number of people in the account.
Filter the cluster
The main sources of pollution dataset and how we fought with them:- Sometimes the faces of different people merge into one cluster (due to the imperfection of the neural network replicator and the density-based nature of DBSCAN).
The simplest reinsurance helped us: if two or more people in a cluster came from one photo, we would throw out such a cluster just in case.
This means that lovers of selfie collages did not fall into ours, but it was worth it, because the number of false “mergers” has decreased significantly. - The opposite happens: the same person forms several clusters (for example, when there are photos with glasses and without, makeup and without, etc.).
Common sense and experiments led us to the following. We measure the distance between the centroids of a pair of clusters. If it is more than a certain threshold, we merge; if it is large enough, but the threshold does not pass, we throw one of the clusters away from sin. - It happens, the detector is mistaken, and not the faces are in the clusters at all.
Fortunately, the neural network recognizer is easily forced to filter such false positives. More on this below.
- Sometimes the faces of different people merge into one cluster (due to the imperfection of the neural network replicator and the density-based nature of DBSCAN).
- We will train the neural network on what we have, we return with it to point 2
Repeat 3-4 times until ready.
Gradually, the network is getting better, and at the last iterations there is no need for our heuristics to filter.
Having decided that the more diverse, the better - we mix in our new dataset (3.7M people, 77K people; code name - OKFace) something else.
The VGGFace2 turned out to be the most useful of something else - quite large and complex (turns, lighting). As usual, made up of celebrity photos found in Google. No wonder very “dirty”. Fortunately, cleaning it up with a neural network pre-trained on OKFace is trivial.
Loss function
A good loss function for embedding learning is still an open task. We tried to approach it, relying on the following position: it is necessary to strive so that the loss function most closely corresponds to how the model will be used after training
And our network will be used in the most standard way.
When you are on the photo of his face embedding will be compared with centroids from candidate profiles (the user himself + his friends) over cosine distance. If a , we declare that the photo - candidate number .
Accordingly, we want to:
- for the “right” candidate , exceeded the threshold ;
- for the rest - was lower and even desirable with a margin .
Deviation from this ideal will be punished by the square, because everyone does it empirically so it turned out better. The same in terms of formulas:
And the centroids themselves - these are just the parameters of the neural network, they are trained, like everything else, by gradient descent.
This loss function has its problems. Firstly, it is poorly suited for learning from scratch. Secondly, select as many as two parameters - and - quite tiring. However, the additional training with its use has allowed us to achieve higher accuracy than the other known functions: Center Loss , Contrastive-Center Loss , A-Softmax (SphereFace) , LMCL (CosFace) .
And was it worth it?
| Lfw | OKFace, test set | |||
| Accuracy | TP@FP0.001 | Accuracy | TP@FP0.001 | |
| Before | 0.992 + -0.003 | 0.977 + -0.006 | 0.941 + -0.007 | 0.476 + -0.022 |
| After | 0.997 + -0.002 | 0.992 + -0.004 | 0.994 + -0.003 | 0.975 + -0.012 |
the numbers in the table are average results of 10 measurements + standard deviation
An important indicator for us is TP @ FP: what percentage of faces we identify with a fixed proportion of false positives (here - 0.1%).
With a limit of 1 in 1000 errors and without further training of the neural network on our dataset, we could recognize only half of the faces on the portal.
Minimizing detector false alarms
The detector sometimes finds faces where there are none, and often does on user photos (4% of false positives).
It is rather unpleasant when such “garbage” falls into the training dataset.
It is very unpleasant when we persistently ask our users to “mark a friend” in a bouquet of roses or on a carpet texture.
The problem can be solved, and the most obvious way is to collect more non-individuals and run them through the neural network replicator.
We, as usual, decided to start with a quick crutch:
- We borrow from the Internet a dozen images on which, in our opinion, individuals should not be

- We take random crops, build embeddingings for them and cluster them. We only got 14 clusters.
- If the embedding of the tested “face” is close to the centroid of one of the clusters, then we consider the “face” to be a non-face.
- We are happy with how well our method works.
- We realize that the described scheme is implemented by a two-layer neural network (with 14 units on a hidden layer) on top of embeddings, and we are a bit sad.
The interesting thing is that the network-resolver sends all the variety of non-persons to just a few areas in the embeddingd space, although nobody has taught it to that.
Everyone lies or the definition of the real age and gender in the social network
Users often do not indicate their age or indicate it incorrectly. Therefore, the user’s age will be estimated using his friend graph. Here clustering of ages of friends will help us: in general, the age of a user is in the largest cluster of ages of his friends, and first and last names helped us with determining gender.
Vitaliy Khudobakhshov told about this: “ How to find out the age of a person in a social network, even if it is not specified ”
Solution Architecture
Since the entire internal infrastructure is OK built on Java, then we will wrap all the components in Java. Inference to detector and recognizer works under TensorFlow control via Java API. The Detector runs on the CPU as it meets our requirements and runs on the existing hardware. For Recognizer, we installed 72 GPU cards, since running Inception-ResNet is not expedient on the CPU in terms of resources.
As a database for storing user vectors we use Cassandra.
Since the total volume of the vectors of all portal users is ~ 300Gb, for quick access to the vectors we add a cache. The cache is implemented in off-heap, details can be found in the article by Andrei Pangin : " Using shared memory in Java and off-heap caching ."
The built architecture maintains a load of up to 1 billion photos per day while iterating over user profiles, and at the same time processing of new uploaded photos ~ 20 million photos per day continues.

Figure 6. Solution architecture
results
As a result, we wrote down a system that was trained on real data of a social network, which gives good results with limited resources.
The recognition quality on a dataset built on real profiles from OC was TP = 97.5% with FP = 0.1%. The average processing time for a single photograph is 120 ms, and the 99th percentile fits into 200 ms. The system is self-learning, and the more the user tags on the photo, the more accurate his profile becomes.
Now, after uploading photos, users found on them receive notifications and can confirm themselves in the photo or delete if they don’t like the photo.

Automatic recognition led to a 2-fold increase in impressions of events in the tape about the elevations in photographs, and the number of clicks on these events increased by 3 times. The interest of users to the new feature is obvious, but we plan to increase the activity even more by improving UX and new points of application, such as Starface.
StarFace flashmob
In order to acquaint users of the social network with new functionality, OK announced a contest: users upload their photos with Russian sports stars, show business and popular bloggers leading their Odnoklassniki accounts, and receive a badge for an avatar or a subscription to paid services. Details here: https://insideok.ru/blog/odnoklassniki-zapustili-raspoznavanie-lic-na-foto-na-osnove-neyrosetey
In the first days of the promotion, users have already uploaded more than 10 thousand photos with celebrities. They laid out selfies and photos with stars, photos against posters and, of course, “photoshop”. Photos of users who received VIP status:

Plans
Since most of the time is spent on the detector, the speed should be further optimized exactly in the detector: replace it or transfer it to the GPU.
Try a combination of different models of recognition, if it significantly improves the quality.
From a user point of view, the next step is to recognize the people in the video. We also plan to inform the user about the availability of copies of his profile on the network with the opportunity to complain about the clone.
Offer your ideas for using face recognition in comments.
')
Source: https://habr.com/ru/post/350566/
All Articles