Results of MentorHack: chat bot for selecting conversations from dialogues, services for building career paths and teams
Recently, we participated in the organization of MentorHack - a hackathon to create services for mentoring in the corporate environment, entrepreneurship and education.
Under the cut a bit about the hackathon: through everyday life, checking the FSO and the forum to the winners with a chat bot for auto selection of tasks from correspondence, a service for building career paths to the desired positions in the future and assembling teams for projects.

To begin, we recall that in the base track of the hackathon there were 2 conditional thematic areas: all sorts of matching and AI Boss elements with a prize pool of 500,000 rubles.
')
As well as two equally large specialties:
Since there were quite a few participants - 200, it was decided to weed out the participants in the hackathon process. To this end, on the first and second days we discussed with the participants their ideas and the current implemented functionality in order to assess the completeness of the project. They passed quite cheerfully in the company of curators from the most different companies and funds who broke through the security, although most of the teams were not ready for such a format - the good old format of the review of presentations was expected. 30 teams were allowed to the finals, having received many joyful emotions about dropping out 20 and talking about the fact that it is impossible to fill methodological tables and tables from designers instead of code.
The jury members in the final evaluated the teams on four criteria:
- technical implementation,
- level of study,
- relevance and demand,
- commercial potential and scalability.
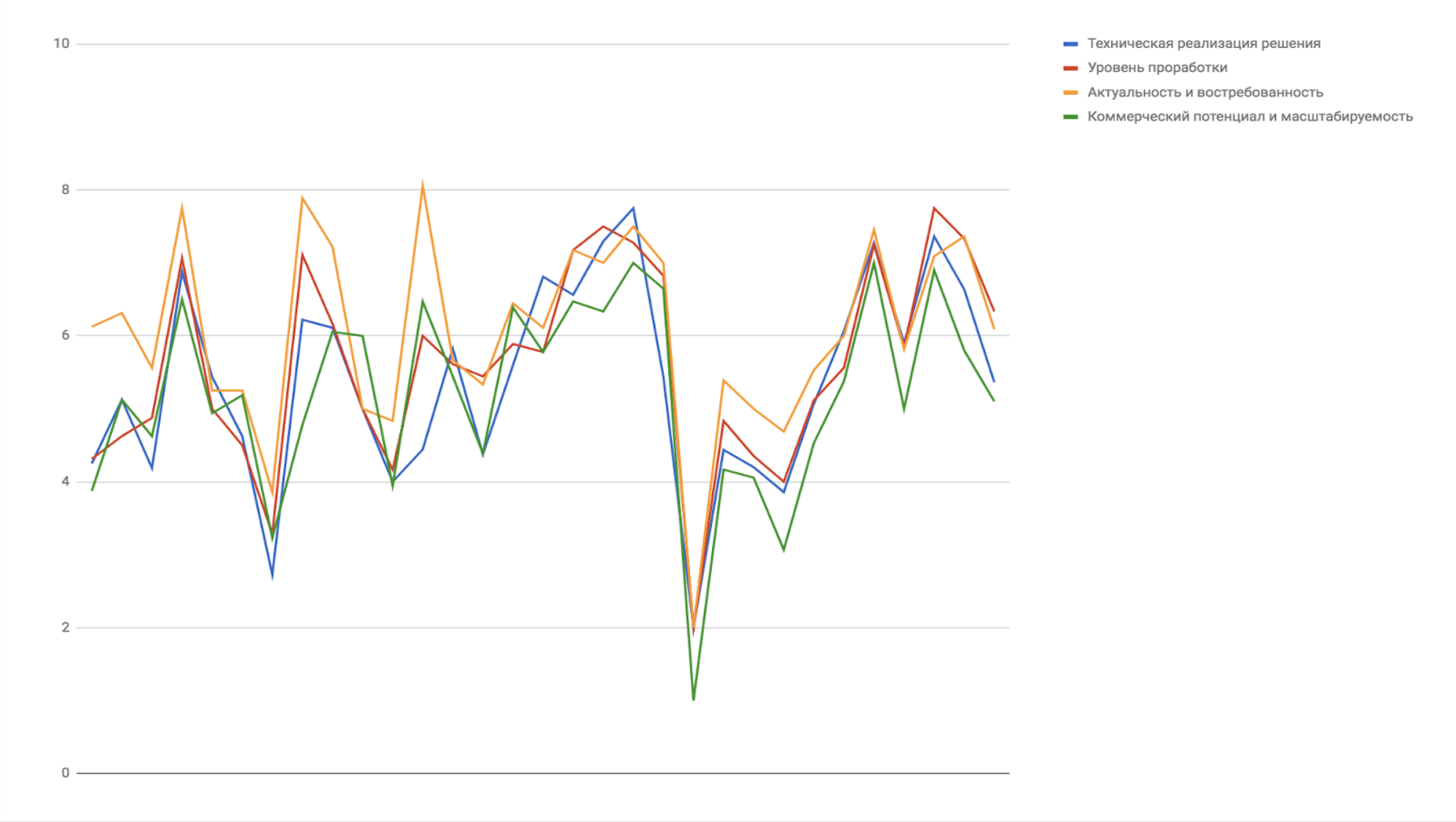
As expected, in fact, in most cases, the jury each team in fact puts one assessment, expressing the overall impression - liked / disliked, so the estimates on the four criteria were very close.
For the final assessment, the jury's opinion was averaged with the assessment from our supervisors in terms of the quality and efficiency of the code.
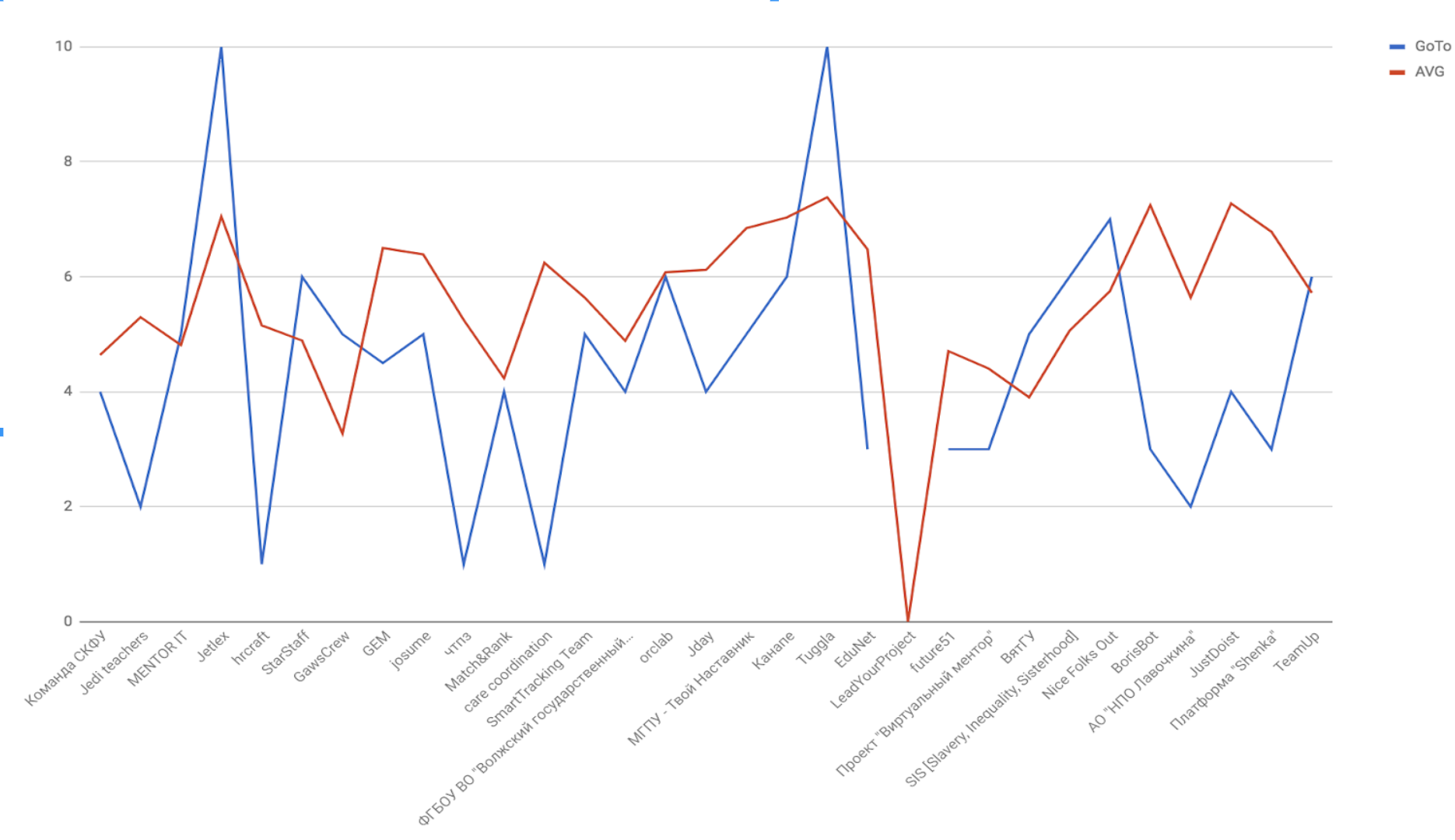
The graph shows that good projects almost always received high marks for both the presentation and the technical implementation. Real-time processing of the jury's estimates of 20 people in the absence of the Internet and a working printer to the sound of an understanding pavilion became a separate entertainment. But we planted a couple of machine-gunners for Excel and managed to, in the end we got these ratings:

Jetlex
The Nota project is a bot assistant for working with chat rooms in natural language, highlighting the assigned tasks in correspondence. To get started, you need to add Nota to the chat and register with Trello. Then the bot will tell you what to do - everything is simple.
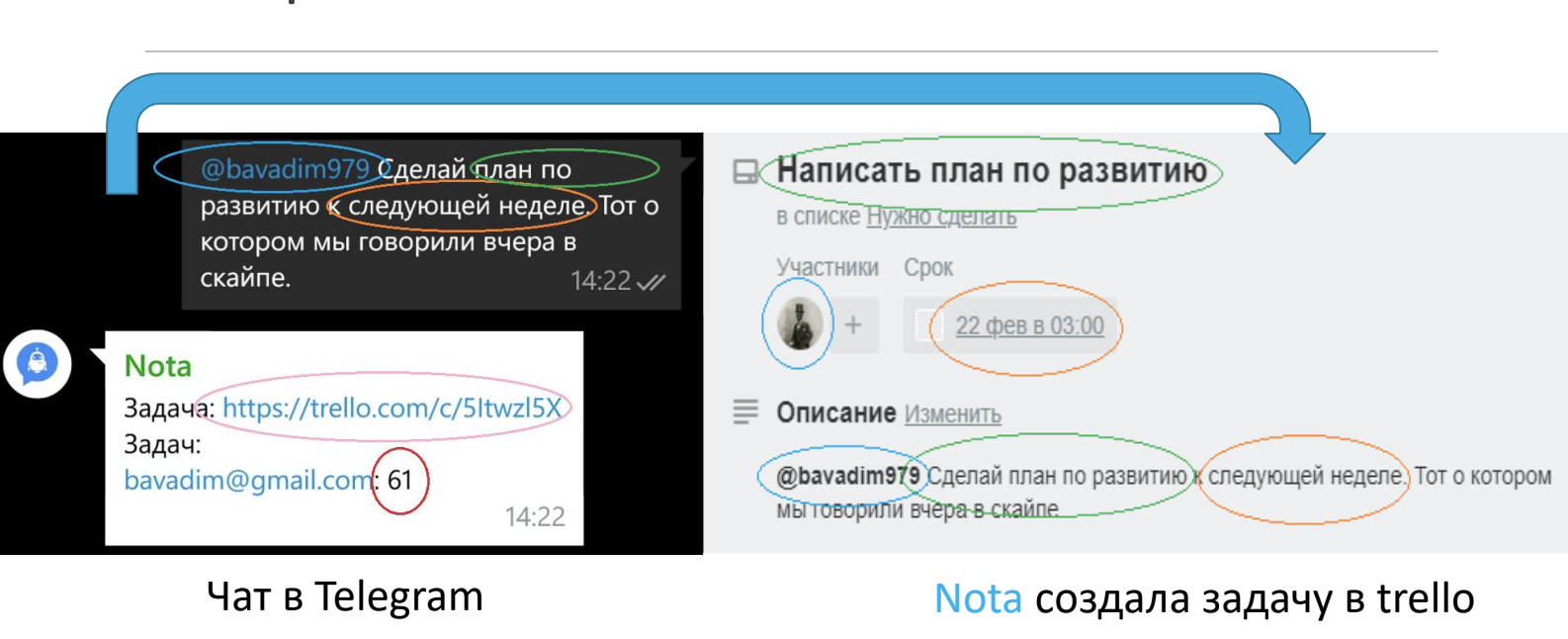
After adding to the chat, the bot will reveal messages where one user sets a task to another. In this message, Nota determines the date of performance and the contractor, and then creates a task in trello based on the data received. In this case, Nota itself generates the name of the task, based on the essence of the task, using a neural summator. Nota distinguishes ordinary messages and floods from real-world tasks.
For example, from the text: "@ viktorboyko09 prepare a quarterly report for the next week! The one we spoke on Skype yesterday." Nota will do a task in Trello with the title “Reporting”, for a period of “until February 26, 2018 (Nota counted 7 days from the date the problem was set)”, responsible for “Victor Boyko” and a description corresponding to the original text.

For the classifier training, a dataset was created based on messages from the drom.ru, moskvaforum.ru, women.ru, antiwomen.ru, and vashdom.ru forums - in order to determine which messages are not tasks. And as examples of tasks messages from youdo.ru and fl.ru were collected. As a result, more than 35 million examples were collected, of which 3 million were tasks. We used the data about the tasks and their headers for training the sumizer (seq2seq implementation of OpenNMT). In the course of the competition, we found that tasks are often set in the imperative mood, and the tasks in our dataset used verbs in the infinitive (for example, “[need] to paint the fence”). Therefore, we decided to augment our dataset messages with verbs in the imperative mood. It turned out that this can be done easily with the help of pymorphy2 (the inflect function). Find datasets here:
Summarizer training - train and test .
Classifier training - train and test .
Our temporary tfidf + SVM classifier with linear cores was later to be replaced by the CNN classifier. But this did not happen and the temporary version remained the final decision, because the neural classifier learned only one day after the end of the competition.
Team members wrote in different languages, so we chose a service approach to architecture. The service architecture allowed us to easily integrate modules written in Python (totalisation services, NER and phrase classifications), Go (I / O to Telegram) and Node.js (I / O to Trello). IPC between services was built on the basis of standard I / O streams.
You can try our bot by adding manager_assist_bot to the group. As a demo version of Nota, all tasks are added to one common Trello board.
Tuggla
We have developed a system that will be able to select vacancies for each candidate, suitable for his skills, show further career paths in each direction, and also explain what skills a person needs to pull up and get to get to the desired position. After receiving the SuperJob dataset in the form json lines of resumes and vacancies, we did not have time to come up with a solution, found it logical to compare experience with a real vacancy, as this will give us an idea of the chronology of a person receiving skills that requires work the applicant in the vacancy.
The main problem was the amount of data (250,000 vacancies and resumes, each resume had at least 3-4 positions, and sometimes up to 50). If you just use word2vec to match, it will take more than one day, which is not the most optimal step within the framework of the hackathon. Therefore, we found more or less similar vacancies for experience in the resume using TF-iDF, and the final answer (suitable or not) gave us word2vec. After comparing the vacancies, it is time to get the skills out of the field of demand from the candidate for the vacancy. We did this with the help of regex, logic and black magic. Logic and regexs had a very long tyunit because all the requirements were written in a derived style. After 20 ifs and clouds of regexs, we pulled out something more or less similar to skills. Of course, you can do something more intelligent, for example, make merge of all skills, play around with stop words more, but we had a little less than a day, so we moved on to the next stage of work. As each vacancy in dataset was compared with an abstract area (manager, assistant, etc.), we considered the most common skills for each area. After that, we took the average of the vectors of these skills and called it the profession vector.
For example, the top 10 lawyer skills:
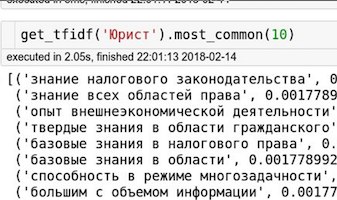
Further, when the user enters skills, we use the same magic and regexs to pull out the “real” (our) skills, take their vector, mean, and with the help of cosine we look at the distance to the vector of the profession. Thus, we can say under what area your skills are suitable. SuperJob was more interested in predicting the next step, and we wanted to win, so we took all the career trajectories and decided to look at the dynamics of skills and chronology of the professions. Since we juxtaposed each line in the experience of working with a vacancy, and the vacancy is juxtaposed with a profession — for us, a career path is simply a set of professions in chronological order. Here’s how it looks for a single resume:
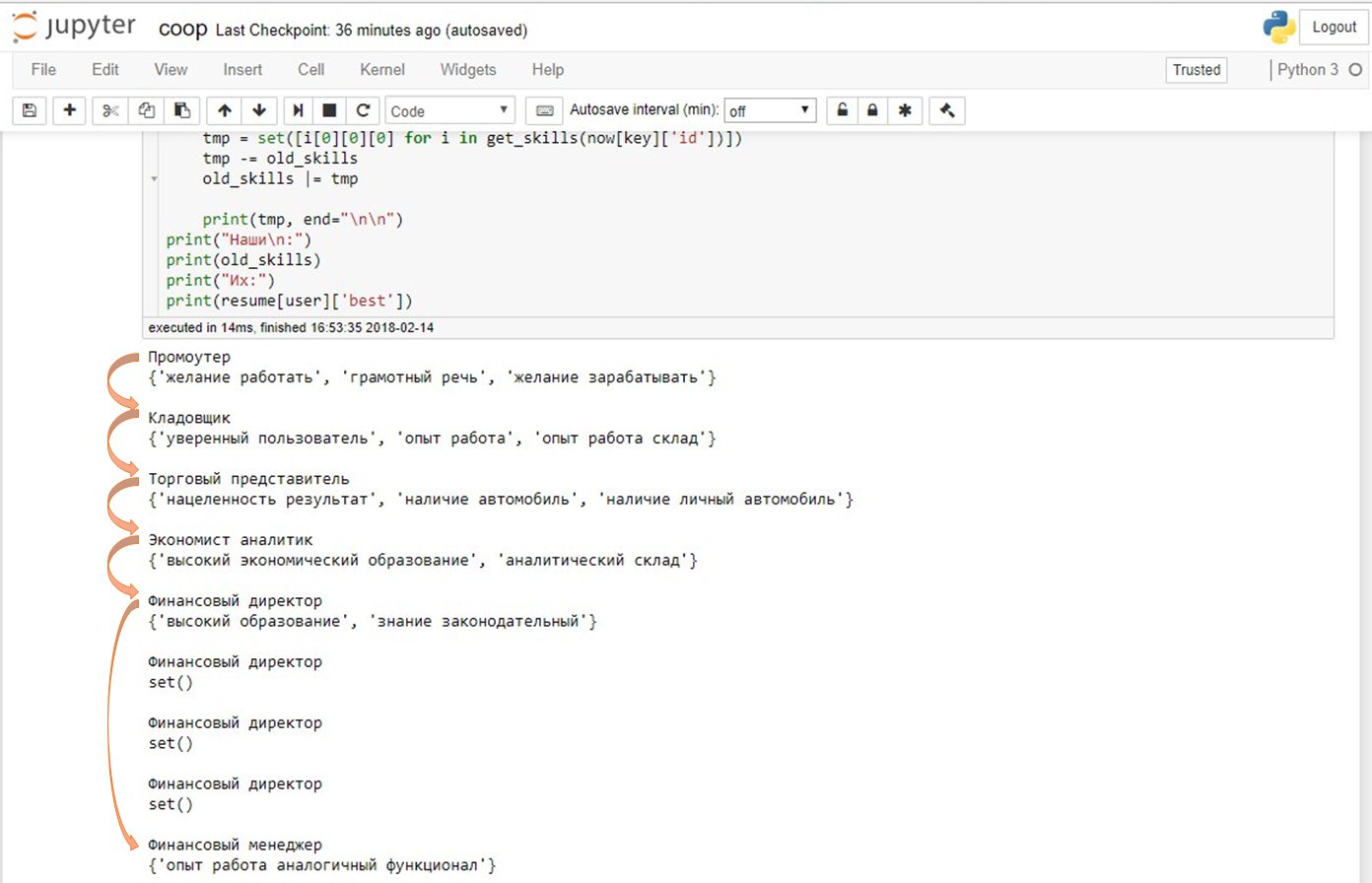
After that, we identified the “right” career paths. This is the most interesting and muddy part of our project. The fact is that it is not very clear what career growth is. It is especially incomprehensible how to convey our sense of career growth in the code. After long discussions, 7 hours before the end of the hackathon, it was decided to assign levels to professions depending on the frequency of transition to it from the current one.
For example: General Director - level 10, Driver - level 1. And this is what we got:
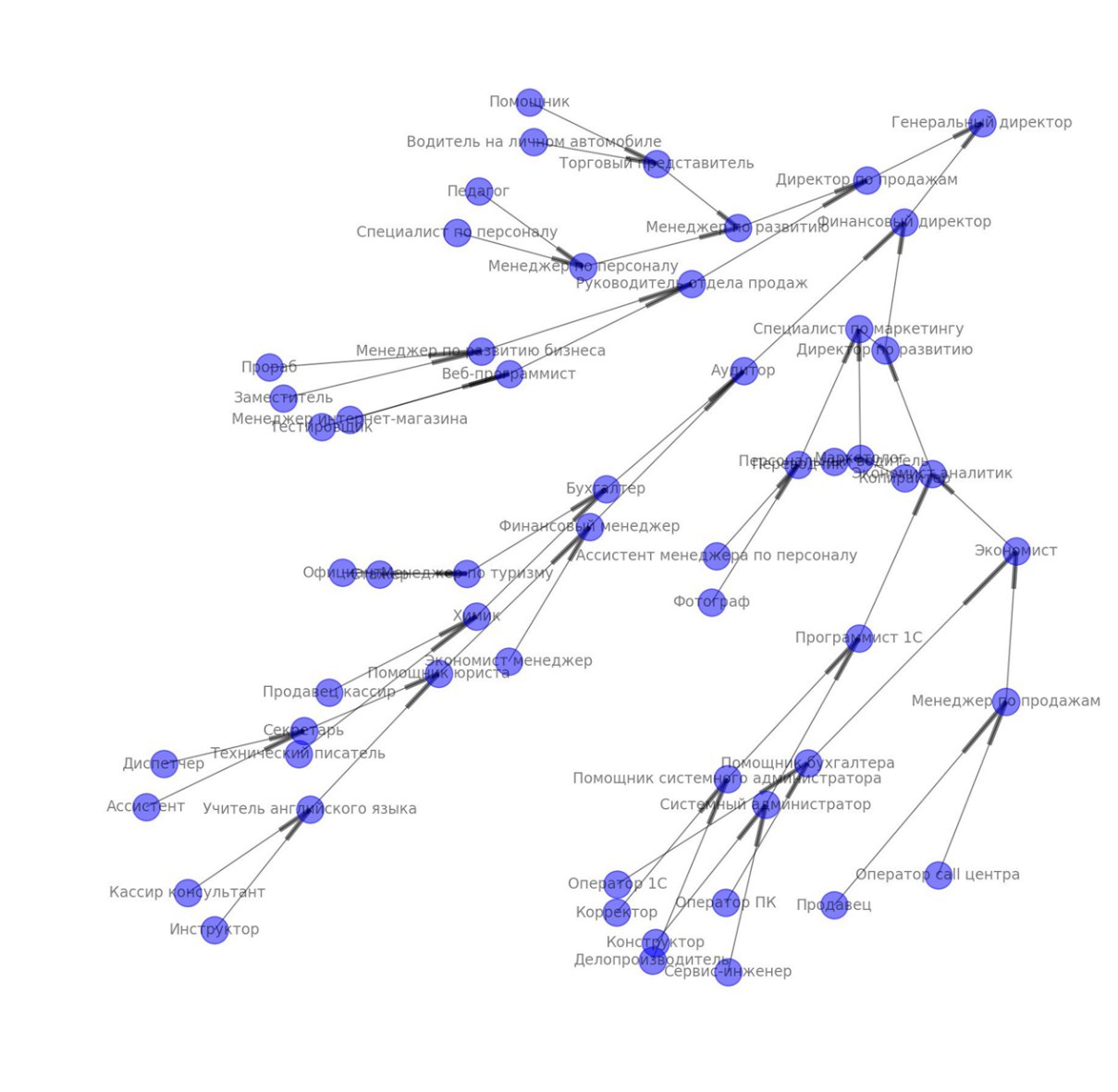
Here an interesting problem is hidden - it turns out that people do not always develop in our paradigm. And sometimes they even become drivers after being managers or bankers or writing complete nonsense on their resume - and we get 40 vacancies that have nothing in common. Therefore, we had to write several conditions to check the adequacy of the career path:
- The path should take a foreseeable number of transitions - for example, from 3 to 8.
- Each next position, if it does not coincide with the previous one, should be 1-3 levels higher.
After receiving career paths, you can build a path from the current profession and recommend vacancies based on the skills that the user has.
A couple of skill mapping examples:
Project descriptions for several other winners
Canape
Our task was to assemble a team for a specific project in the form of a set of vacancies.
We assembled a team according to two main criteria: coverage of all necessary skills and compatibility for interests.
A custom implementation of resume2vec was made for a “smart” search for suitable people. It works like this:
Teamup
We worked on a service for assembling resume teams. People from the database were filtered by competence, and then ranked. For the analysis of a person, the answers to questions about interests were used, the answers were vectorized with the help of word2vec and were found closest to the filtered ones. Using the ApplyMagicSauce API, an additional type was determined using the OCEAN scheme on the basis of the same questions. Also for ranking used the ratio of age to total work experience. The final score for each person is the weighted sum of these three parameters.
Nice folks out
In advanced companies, you need to monitor the quality of the project code. Good analytics can give an external expert. In order for this analytics to be most useful, it is necessary that the competencies of the expert coincide with the competencies of the team. To this end, we have developed a platform for code analytics, which determines the degree of similarity of projects by their content and description using machine learning.
If you have read to here and would like to familiarize yourself with the rest of the projects and their presentations, welcome here , here you will find prototypes of the service for selecting a supervisor, increasing team efficiency, mentoring, and much more.
Under the cut a bit about the hackathon: through everyday life, checking the FSO and the forum to the winners with a chat bot for auto selection of tasks from correspondence, a service for building career paths to the desired positions in the future and assembling teams for projects.
To begin, we recall that in the base track of the hackathon there were 2 conditional thematic areas: all sorts of matching and AI Boss elements with a prize pool of 500,000 rubles.
')
As well as two equally large specialties:
- SuperJob with the task of building career paths from the current resume to the desired vacancy with an additional prize of 500 tr.
- BusinessChain with the task of assembling teams for a project based on the project description and the resume of candidates with a prize of 300 tr.
Since there were quite a few participants - 200, it was decided to weed out the participants in the hackathon process. To this end, on the first and second days we discussed with the participants their ideas and the current implemented functionality in order to assess the completeness of the project. They passed quite cheerfully in the company of curators from the most different companies and funds who broke through the security, although most of the teams were not ready for such a format - the good old format of the review of presentations was expected. 30 teams were allowed to the finals, having received many joyful emotions about dropping out 20 and talking about the fact that it is impossible to fill methodological tables and tables from designers instead of code.
The jury members in the final evaluated the teams on four criteria:
- technical implementation,
- level of study,
- relevance and demand,
- commercial potential and scalability.
As expected, in fact, in most cases, the jury each team in fact puts one assessment, expressing the overall impression - liked / disliked, so the estimates on the four criteria were very close.
For the final assessment, the jury's opinion was averaged with the assessment from our supervisors in terms of the quality and efficiency of the code.
The graph shows that good projects almost always received high marks for both the presentation and the technical implementation. Real-time processing of the jury's estimates of 20 people in the absence of the Internet and a working printer to the sound of an understanding pavilion became a separate entertainment. But we planted a couple of machine-gunners for Excel and managed to, in the end we got these ratings:
Winners about their projects
Jetlex
The Nota project is a bot assistant for working with chat rooms in natural language, highlighting the assigned tasks in correspondence. To get started, you need to add Nota to the chat and register with Trello. Then the bot will tell you what to do - everything is simple.
After adding to the chat, the bot will reveal messages where one user sets a task to another. In this message, Nota determines the date of performance and the contractor, and then creates a task in trello based on the data received. In this case, Nota itself generates the name of the task, based on the essence of the task, using a neural summator. Nota distinguishes ordinary messages and floods from real-world tasks.
For example, from the text: "@ viktorboyko09 prepare a quarterly report for the next week! The one we spoke on Skype yesterday." Nota will do a task in Trello with the title “Reporting”, for a period of “until February 26, 2018 (Nota counted 7 days from the date the problem was set)”, responsible for “Victor Boyko” and a description corresponding to the original text.
For the classifier training, a dataset was created based on messages from the drom.ru, moskvaforum.ru, women.ru, antiwomen.ru, and vashdom.ru forums - in order to determine which messages are not tasks. And as examples of tasks messages from youdo.ru and fl.ru were collected. As a result, more than 35 million examples were collected, of which 3 million were tasks. We used the data about the tasks and their headers for training the sumizer (seq2seq implementation of OpenNMT). In the course of the competition, we found that tasks are often set in the imperative mood, and the tasks in our dataset used verbs in the infinitive (for example, “[need] to paint the fence”). Therefore, we decided to augment our dataset messages with verbs in the imperative mood. It turned out that this can be done easily with the help of pymorphy2 (the inflect function). Find datasets here:
Summarizer training - train and test .
Classifier training - train and test .
Our temporary tfidf + SVM classifier with linear cores was later to be replaced by the CNN classifier. But this did not happen and the temporary version remained the final decision, because the neural classifier learned only one day after the end of the competition.
Team members wrote in different languages, so we chose a service approach to architecture. The service architecture allowed us to easily integrate modules written in Python (totalisation services, NER and phrase classifications), Go (I / O to Telegram) and Node.js (I / O to Trello). IPC between services was built on the basis of standard I / O streams.
You can try our bot by adding manager_assist_bot to the group. As a demo version of Nota, all tasks are added to one common Trello board.
Tuggla
We have developed a system that will be able to select vacancies for each candidate, suitable for his skills, show further career paths in each direction, and also explain what skills a person needs to pull up and get to get to the desired position. After receiving the SuperJob dataset in the form json lines of resumes and vacancies, we did not have time to come up with a solution, found it logical to compare experience with a real vacancy, as this will give us an idea of the chronology of a person receiving skills that requires work the applicant in the vacancy.
The main problem was the amount of data (250,000 vacancies and resumes, each resume had at least 3-4 positions, and sometimes up to 50). If you just use word2vec to match, it will take more than one day, which is not the most optimal step within the framework of the hackathon. Therefore, we found more or less similar vacancies for experience in the resume using TF-iDF, and the final answer (suitable or not) gave us word2vec. After comparing the vacancies, it is time to get the skills out of the field of demand from the candidate for the vacancy. We did this with the help of regex, logic and black magic. Logic and regexs had a very long tyunit because all the requirements were written in a derived style. After 20 ifs and clouds of regexs, we pulled out something more or less similar to skills. Of course, you can do something more intelligent, for example, make merge of all skills, play around with stop words more, but we had a little less than a day, so we moved on to the next stage of work. As each vacancy in dataset was compared with an abstract area (manager, assistant, etc.), we considered the most common skills for each area. After that, we took the average of the vectors of these skills and called it the profession vector.
For example, the top 10 lawyer skills:
Further, when the user enters skills, we use the same magic and regexs to pull out the “real” (our) skills, take their vector, mean, and with the help of cosine we look at the distance to the vector of the profession. Thus, we can say under what area your skills are suitable. SuperJob was more interested in predicting the next step, and we wanted to win, so we took all the career trajectories and decided to look at the dynamics of skills and chronology of the professions. Since we juxtaposed each line in the experience of working with a vacancy, and the vacancy is juxtaposed with a profession — for us, a career path is simply a set of professions in chronological order. Here’s how it looks for a single resume:
After that, we identified the “right” career paths. This is the most interesting and muddy part of our project. The fact is that it is not very clear what career growth is. It is especially incomprehensible how to convey our sense of career growth in the code. After long discussions, 7 hours before the end of the hackathon, it was decided to assign levels to professions depending on the frequency of transition to it from the current one.
For example: General Director - level 10, Driver - level 1. And this is what we got:
Here an interesting problem is hidden - it turns out that people do not always develop in our paradigm. And sometimes they even become drivers after being managers or bankers or writing complete nonsense on their resume - and we get 40 vacancies that have nothing in common. Therefore, we had to write several conditions to check the adequacy of the career path:
- The path should take a foreseeable number of transitions - for example, from 3 to 8.
- Each next position, if it does not coincide with the previous one, should be 1-3 levels higher.
After receiving career paths, you can build a path from the current profession and recommend vacancies based on the skills that the user has.
A couple of skill mapping examples:
- Gramortal speech and organizational skills - supervisor card .
- Russian language and writing texts - journalist card .
Project descriptions for several other winners
Canape
Our task was to assemble a team for a specific project in the form of a set of vacancies.
We assembled a team according to two main criteria: coverage of all necessary skills and compatibility for interests.
A custom implementation of resume2vec was made for a “smart” search for suitable people. It works like this:
- parsim skills from dataset with resume,
- create a graph where the vertices are the summary, and the edges are the similarity between them, then we use the node2vec technology described in this article . For the second part, we wrote a chat bot that parses VKontakte and determines its interests by subscriptions and user groups.
Teamup
We worked on a service for assembling resume teams. People from the database were filtered by competence, and then ranked. For the analysis of a person, the answers to questions about interests were used, the answers were vectorized with the help of word2vec and were found closest to the filtered ones. Using the ApplyMagicSauce API, an additional type was determined using the OCEAN scheme on the basis of the same questions. Also for ranking used the ratio of age to total work experience. The final score for each person is the weighted sum of these three parameters.
Nice folks out
In advanced companies, you need to monitor the quality of the project code. Good analytics can give an external expert. In order for this analytics to be most useful, it is necessary that the competencies of the expert coincide with the competencies of the team. To this end, we have developed a platform for code analytics, which determines the degree of similarity of projects by their content and description using machine learning.
If you have read to here and would like to familiarize yourself with the rest of the projects and their presentations, welcome here , here you will find prototypes of the service for selecting a supervisor, increasing team efficiency, mentoring, and much more.
Partner Comments
“On the first day of the hackathon, little was believed that the participants would overcome not only technical, but also domestic difficulties. Still, a forum of this magnitude does not greatly contribute to creating a calm, creative atmosphere. I am pleased to note that all 30 teams that reached the finals coped with the cold, hunger and harmful experts during checkpoints. On the second day, in some cases, it seemed that the team’s idea could not be saved and the experts were not shy about the estimates. The next day, we were surprised to see how literally in a few hours the project changed beyond recognition, acquiring a new logical and interesting form. For us it was a very interesting experience. Thanks to the organizing team and success to all participants. ”
Elena Alexandrova, Development Director of the IPI Laboratory, author of the special nominations from the BusinessChain project.
“We decided to participate in the hackathon spontaneously. After the meeting at the Superjob office with Alena Ilyina, the decision was made in half an hour. We have long hatched the idea of carrying out the hackathon for our tasks and at that moment decided that the stars came together, and this event would be a good base for us to run in a new mechanism and study all the pitfalls. And just the pitfalls we had more than enough. Starting with very sprint terms, ending with ever-changing organizational introductory, the existence of which is difficult even to guess, constantly playing only in the commercial field. We had a lot of options for setting the problem, since there are a lot of areas that SJ develops, ranging from direct commercial stories to vocational guidance and volunteer areas. We agreed on the task of career trajectories - it was interesting how the guys will be able to realize what we are already working on, if they can give us a new vision and show what we may lack. By the size of the prize fund, the decision was changed upwards as quickly when they tried to divide the agreed amount into three places and it turned out to be “ugly”. Probably, it was a bonus to our determination against all laws of logic, to be in time in a couple of weeks, we got a piece at our disposal under the lounge and with a couple of hundred gray hair when it was arranged in conditions “as long as we don’t know how many meters it is, in what room that there you can put, stick, connect ". When at last we reached the opening day, we realized that we knew nothing at all about the processes and mechanisms, but by that time we already had friends who were just as old as we are (forgive Allen, we hope everything is reversible) who dragged us through all 48 hours. And if the guys (terrific, good, crazy, and just good people) worked for two days at the site, then we spent 48 hours doing divinations and predictions without any machine learning. Each following check-point changed the scale "everything is fucking-all gone" in opposite directions. By the finals, we already knew who the favorite was, but with 2 and 3 places we suddenly “stopped”. We decided on the pitches, but we hope that we made the right choice. Briefly summarized, it was a roller coaster and a horror room in one. In general, the attraction was a success, and we liked it. We learned a lot about “how not to”, we met with great guys and understood a lot about what we can do using such mechanisms to work out our tasks. We know that we will repeat it and we know that it will be cool. ”
Julia Sharapova, spokesperson for SuperJob .
Elena Alexandrova, Development Director of the IPI Laboratory, author of the special nominations from the BusinessChain project.
“We decided to participate in the hackathon spontaneously. After the meeting at the Superjob office with Alena Ilyina, the decision was made in half an hour. We have long hatched the idea of carrying out the hackathon for our tasks and at that moment decided that the stars came together, and this event would be a good base for us to run in a new mechanism and study all the pitfalls. And just the pitfalls we had more than enough. Starting with very sprint terms, ending with ever-changing organizational introductory, the existence of which is difficult even to guess, constantly playing only in the commercial field. We had a lot of options for setting the problem, since there are a lot of areas that SJ develops, ranging from direct commercial stories to vocational guidance and volunteer areas. We agreed on the task of career trajectories - it was interesting how the guys will be able to realize what we are already working on, if they can give us a new vision and show what we may lack. By the size of the prize fund, the decision was changed upwards as quickly when they tried to divide the agreed amount into three places and it turned out to be “ugly”. Probably, it was a bonus to our determination against all laws of logic, to be in time in a couple of weeks, we got a piece at our disposal under the lounge and with a couple of hundred gray hair when it was arranged in conditions “as long as we don’t know how many meters it is, in what room that there you can put, stick, connect ". When at last we reached the opening day, we realized that we knew nothing at all about the processes and mechanisms, but by that time we already had friends who were just as old as we are (forgive Allen, we hope everything is reversible) who dragged us through all 48 hours. And if the guys (terrific, good, crazy, and just good people) worked for two days at the site, then we spent 48 hours doing divinations and predictions without any machine learning. Each following check-point changed the scale "everything is fucking-all gone" in opposite directions. By the finals, we already knew who the favorite was, but with 2 and 3 places we suddenly “stopped”. We decided on the pitches, but we hope that we made the right choice. Briefly summarized, it was a roller coaster and a horror room in one. In general, the attraction was a success, and we liked it. We learned a lot about “how not to”, we met with great guys and understood a lot about what we can do using such mechanisms to work out our tasks. We know that we will repeat it and we know that it will be cool. ”
Julia Sharapova, spokesperson for SuperJob .
Source: https://habr.com/ru/post/350524/
All Articles