Git: Newbies Tips - Part 3

In the final part of our series of articles on working with Git, we will continue to talk about branches, consider the peculiarities of working with the push team, and tell you what a rebase is. The first and second articles of the series can be read on the links.
Chapter 16. Where did the branch come from?
Be patient and continue to consider different work situations. If we make several commits, and then we execute the fetch command (download fresh commits, but do not apply them to the working directory yet), we will see a bit confusing picture:

What is this branch turned out? We did not create any branch. Maybe it was created by someone from the staff? No, nobody created it. Restore the chronology of events:
- First we downloaded the latest commits. Then the last was a commit "2".
- Then we made commits "3" and "4" (but have not yet fired them).
- At this time, other employees launched commits "5", "6" and "7" into a remote repository. Then we knew nothing about it.
- Finally, we made a fetch and saw what was in the picture.
In Git, each commit stores a link to the previous one (this allows us to connect circles in the figures; each segment is a link to the previous commit). When we made commit 3, the last commit for us was 2, so they are connected. But when someone launched commit 5 on origin, commit 2 was the last one too, because we hadn’t yet launched our commits 3 and 4, and there weren’t any origin. And if so, then for commit "5", the previous commit is also called "2", it is this link that Git remembered.
')
So, different people, independently of each other, changed the result of commit "2" - that is where the branch appeared. By the way, this thread is now only in our local repository. It does not exist in origin yet, since we have not yet started commits "3" and "4".
What's next? Since we did fetch, not pull, the downloaded commits have not yet applied to our working directory. Let's apply them - for this run merge. The result is shown in the picture:

What happened is already familiar to us. An automatic merge-commit "8" has been generated - master and head now point to it. Changes from commits "5", "6" and "7" appeared in the working copy, which merged with our changes from commits "3" and "4". origin / master still points to “7”, since our last operations were performed on the local computer. And origin / master can move only after our repository communicates with origin.
Finally, we do push, and now origin / master also points to "8", because:
- Our merge-commit "8" has been sent to origin.
- There he became the last one, so the remote master pointer now points to it.
- We downloaded information about the remote master index and we see it as origin / master.
So he shows at "8". Is logical.
Resist the faint-hearted desire to skip these explanations. There is nothing difficult in them, only attentiveness is needed. Be sure to go through the steps until you understand why it all works.
Chapter 17. Why does push give an error?
You will surely come across the fact that Git gives an error with the push command. What is the problem? Why does he not accept our commits? Push will succeed only if Git can find a predecessor for every commit sent to origin. Example:

Here, on the left, there are commits in your local repository, and on the right, commits in a remote repository (origin).
The chronology of these commits is as follows:
- First, origin was commits "1" and "2".
- We did a pull (in the local repository, too, there were only these two commits).
- Then we committed "3" and "4" to the local repository (but did not push).
- Someone made commit "5" in origin.
And it turned out that now in the picture. Understood?
Now our attempt to push "3" and "4" to origin will end with an error. Git will refuse to dock our commits to the last commit "5" in origin, because in local the predecessor for commit "3" is commit "2" - and not at all "5", as in origin! For Git, it is important that the predecessor be the same.
The problem is solved easily. Before pushing, we will pull (we take commit "5" to ourselves). Here you can ask: “Just a second! And why can Git commit “5” commit it, but it cannot send commits “3” and “4”? It seems the situation is symmetrical in both directions. ” The right question! And the answer is simple. If Git allowed to send commits "3" and "4" in such a situation, you would have to do a merge on the origin side - and who would solve conflicts there? No one. Therefore, Git makes you first pick up fresh commits for yourself, do a merge on your computer (if there are conflicts, then resolve them), and it will allow you to send a ready result to origin using the command push. At the same time, there can be no conflicts in origin.
Let's see what the local history will look like after you pick up commit 5 with the pull command.

Here, at "3" and "5", the ancestor is "2", as in the previous picture. And the new commit "6" is a merge-commit that has long been known to us.
In this state, local commits can already be launched. Let there be a branching of history, but both branches merzh merged. So the head of the branch is alone again. That is, nothing prevents push. After that, origin commits will look exactly the same "loop."
Now that push will give you an error, you already know why and what to do about it.
Chapter 18. Rebase
In the previous chapter, we made several local commits, and then the pull team took commits of other employees from the remote repository. In our local repository, a kind of “branch” was formed, which later merged back with the main one. After push, this temporary branch split into origin, from where employees will download it and see it in their history. Often these "loops" are considered undesirable. Because instead of a beautiful linear history, you get a bunch of loops that make viewing difficult.
Git offers an alternative. Above we did fetch + merge. The first team takes the latest commits, the second combines them with our uncommitted commits (if any) and creates a merge-commit with the result of the merge.
So, it turns out you can do fetch + rebase instead of fetch + merge. What kind of rebase and how does it differ from merge? Recall again how merge went through in the previous example:

Rebase works differently - it disconnects your chain of not-committed commits from its ancestor. Recall that these were commits "3" and "4". They disconnect from their ancestor "2" and rebase puts them "from above" on the newly downloaded commit "5". That is, "3" and "4" will be attached to the top of "5" (and the merge commit "6" will not appear at all). The result will be:
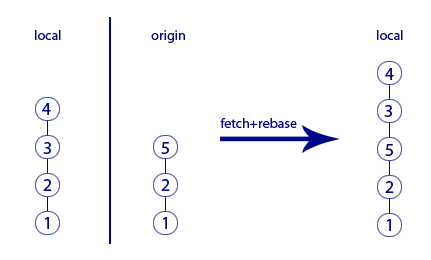
No loop anymore, the story is linear and beautiful! Long live the rebase! Now we know that when downloading commits from origin, it’s better to merge them with your local commits using rebase, not merge.
Well, and if it's not about a couple of your commits, but about a big branch with the development of a new feature. When the time comes to merge this feature into the main branch, how can this be done better - via rebase or merge? Both methods have advantages:
- rebase will keep the history simple and linear - it will add a chain of your commits from the branch to the end of the main branch.
- merge will make a loop, but in the history the history of the development of your feature will be more clearly traced.
The question of preference rebase or merge in such cases, discuss with the lead programmer of your project.
Chapter 19. Epilogue
We have dealt with a variety of Git commands for working with repositories:
- pull
- commit
- push
- add
- clone
- checkout
- stash
- merge
- rebase
- abort
- fetch
These are not all the commands that are needed in the work - only the most frequent. Be prepared to learn others. You can work with Git with the help of various git clients. We mainly use these three:
- Cantilevered
- Sourcetree
- Tortoisegit
Customer choice is a matter of taste.
Console - works on all platforms, but it has an extremely ascetic interface. If you are not used to working in the console, then most likely you will be uncomfortable in it.
SourceTree is a graphical client with a fairly simple interface. There are versions for our main platforms: Win and Mac. However, employees often complain about his slow work and glitches.
TortoiseGit is another graphical client. There is a version for Win, for Mac no. The interface is somewhat unusual, but many like it. There are significantly fewer complaints about glitches and brakes than in the case of SourceTree.
Interestingly, both SourceTree and TortoiseGit do not work directly with the Git repository. Inside they use console git. When you click on the beautiful buttons, Git console commands are invoked with different tricky options, and the result of the call is shown again in a beautiful way. Using all clients of console Git means that they all work with the standard file structure of Git-storage on your hard disk. So you can use a mixed style of work: some operations to perform in one client, and others in another.
So, you have learned the basic concepts used by the Git version control system. And also how the main teams work. Surely when reading the article, you lacked the description of "which buttons to press." However, in each Git-client it looks different, so we had to separate the description of the logic from the description of the interface. It is time to choose one of the clients and explore its user interface.
Successes!
Git: Newbies Tips - Part 1
Git: Newbies Tips - Part 2
Git: Newbies Tips - Part 3
Source: https://habr.com/ru/post/350492/
All Articles