Load testing "non-HTTP". Part 2 Gatling
In the first part of the article, we conducted a comparative analysis of Java load tools for JMeter , left the XML test plans and reached 30K RPS from one machine, loading the “non-HTTP” service using the example of Apache Thrift .
In this article we will consider another tool for load testing - Gatling and, as promised earlier, we will try to increase its performance tenfold.

Gatling is a opensource tool for creating load scripts on Scala. It can be easily connected to your project with your favorite build tool. Under the hood, there is a model of Akka actors, known for its excellent performance.
')
Before diving deeper into writing a load script for the “non-HTTP” protocol, let’s analyze the simplest example for HTTP:
In the protocol builder specify the address. In the script builder, we will describe the script name, the name of the specific request, and the HTTP method. In the load profile setting block we add a load script and define a protocol. For more information, see the documentation .
It was a small digression - after all, we were going to test "non-HTTP". As in the case of JMeter, we still want to have an easily modifiable plugin, on the framework of which it is possible to load various protocols, replacing only the client. Therefore, standard extensions do not suit us.
It was based on a rather ancient but understandable code from Github . He already clashed with the current version of Gatling (2.3.1), but worked with the old one. Most importantly, his dignity was in working with actors.
A simple move to the new version was overshadowed by the failure of backward compatibility by Gatling developers for minor versions and global internal refactoring. In particular, this commit gets rid of actors where it is not really needed:

A great incomprehensible Wikipedia article and a slightly more understandable excerpt from an article on Habré are written about what an actor and actor model is:

The repair customer (we are with you) asks the construction company to repair him several rooms. The foreman manages the queue and the builder loading, makes sure that he does not overwork and do not stand idle. We do not directly communicate with the builder, but work with his representative (company). Knowing how we are slowly building, we give up the task and do not even hope for its quick execution (we do not wait for the result, but we go to do our own business).
By analogy with the HTTP-example and taking as a basis the old script to describe the custom protocol, we will write our builder. It takes some action of the client for the load and works with the actors:
The run result handler is not included in the standard implementation of the load scripts. The code from the old example no longer worked, so after the migration I had to dig a little in the Gatling source, studying the HTTP implementation:
We already wrote the client for Thrift in the first part of the article. The car with which we ship - set up. Microservice also remained the same and holds 50K RPS.
It's time to ship. Let's try to linearly increase the load from 1 to 2K RPS for 60 seconds:
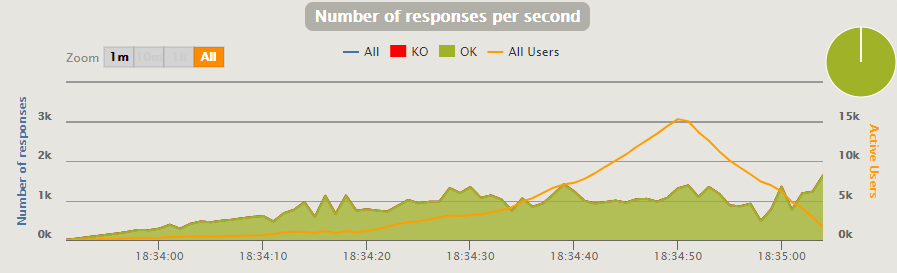
We see the lack of productivity growth from 1,100 RPS and the avalanche-like graph of Gatling-user request handlers. The oddity adds an extended test run time. So far there are more questions than answers.
The simplest and right decision turned out to be to add sleep instead of calling the client, after which the requests got into a long queue. It seems that we have created a single-agent load facility. We need more actors! Create a pool with them by adding just one line in ActionBuilder:
Run the test again and see that we have reached 2K RPS:

Let's try 10K:

Not bad, but if 18K:

Again, similar problems at 15K, but there is nowhere to inflate the pool. Having rummaged in the Gatling repository, we found that the developers added the ability to reconfigure the very configuration of the Akka-actors model. This is done using the gatling-akka-defaults.conf file, which by default looks like this:
Gatling will offer your option:
How we work with the dispatcher is determined by the strategy in the executor. The settings with the parallelism prefix are responsible for the number of threads (at last we remembered them) and depend on the capabilities of the machine and the number of CPUs. Throughput determines the maximum of messages processed by one actor, before a thread gives a message to another actor. You should also correctly approach the selection of coefficients for these parameters.
Run with new settings and pool:
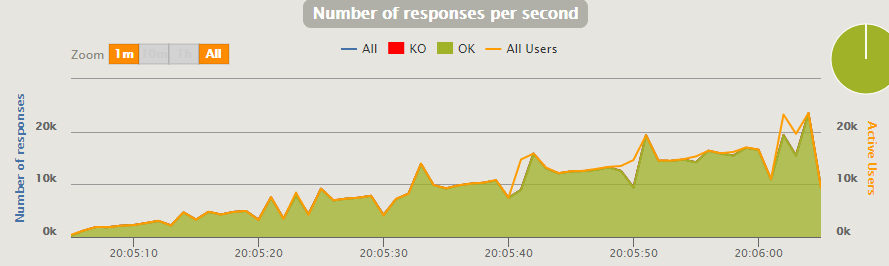
Coped with 18K, but began to notice periodic subsidence associated with the GC and the strategy of adding Gatling-users.
Remembering that the car gave out 30K RPS with JMeter, we will try to give a similar load on Gatling, and we get 32K:
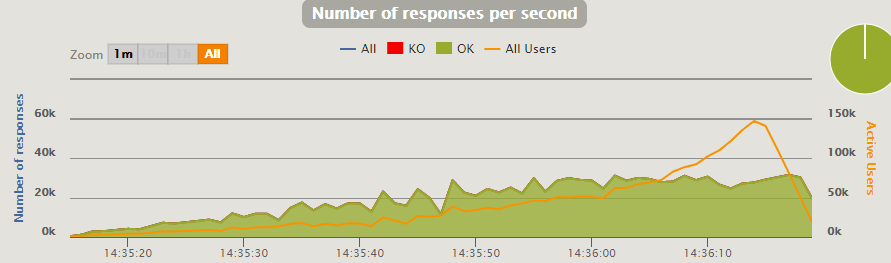

JMeter makes it faster and easier to get results, but it has a slightly worse performance. Gatling allows you to load large volumes (which you may not need), but it’s harder to work with. The choice is yours.
In this article we will consider another tool for load testing - Gatling and, as promised earlier, we will try to increase its performance tenfold.
Gatling
Gatling is a opensource tool for creating load scripts on Scala. It can be easily connected to your project with your favorite build tool. Under the hood, there is a model of Akka actors, known for its excellent performance.
')
Before diving deeper into writing a load script for the “non-HTTP” protocol, let’s analyze the simplest example for HTTP:
class BasicSimulation extends Simulation { val httpConf: HttpProtocolBuilder = http .baseURL("http://123.random.com") val scn: ScenarioBuilder = scenario("BasicSimulation") .exec(http("request_1") .get("/")) setUp( scn.inject(atOnceUsers(1)) ).protocols(httpConf) } In the protocol builder specify the address. In the script builder, we will describe the script name, the name of the specific request, and the HTTP method. In the load profile setting block we add a load script and define a protocol. For more information, see the documentation .
The choice of means load
It was a small digression - after all, we were going to test "non-HTTP". As in the case of JMeter, we still want to have an easily modifiable plugin, on the framework of which it is possible to load various protocols, replacing only the client. Therefore, standard extensions do not suit us.
It was based on a rather ancient but understandable code from Github . He already clashed with the current version of Gatling (2.3.1), but worked with the old one. Most importantly, his dignity was in working with actors.
Old implementation
class PerfCustomProtocolSimulation extends Simulation { val mine = new ActionBuilder { def build(next: ActorRef, protocols: Protocols) = { system.actorOf(Props(new MyAction(next))) } } val userLog = csv("user_credentials.csv").circular val scn = scenario("My custom protocol test") .feed(userLog) { exec(mine) } setUp( scn.inject( atOnceUsers(10) ) ) } class MyAction(val next: ActorRef) extends Chainable { def greet(session: Session) { // Call any custom code you wish, say an API call } def execute(session: Session) { var start: Long = 0L var end: Long = 0L var status: Status = OK var errorMessage: Option[String] = None try { start = System.currentTimeMillis; greet(session) end = System.currentTimeMillis; } catch { case e: Exception => errorMessage = Some(e.getMessage) logger.error("FOO FAILED", e) status = KO } finally { val requestStartDate, requestEndDate = start val responseStartDate, responseEndDate = end val requestName = "Test Scenario" val message = errorMessage val extraInfo = Nil DataWriter.dispatch(RequestMessage( session.scenarioName, session.userId, session.groupHierarchy, requestName, requestStartDate, requestEndDate, responseStartDate, responseEndDate, status, message, extraInfo)) next ! session } } } A simple move to the new version was overshadowed by the failure of backward compatibility by Gatling developers for minor versions and global internal refactoring. In particular, this commit gets rid of actors where it is not really needed:
Akka Actors Model
A great incomprehensible Wikipedia article and a slightly more understandable excerpt from an article on Habré are written about what an actor and actor model is:
Aktor Akka consists of several interacting components. ActorRef is the logical address of the actor, allowing you to send messages to the actor asynchronously according to the “send and forget” principle. The dispatcher is responsible for placing messages in the queue leading to the actor's mailbox, and also orders the mailbox to remove one or more messages from the queue, but only one at a time - and transfer them to the actor for processing. Akka does not allow direct access to the actor and therefore ensures that the only way to interact with the actor is asynchronous messages. Cannot call method in actor.Complicated. Let's try to explain with the example of the construction:
In addition, it should be noted that sending a message to an actor and processing this message by an actor are two separate operations that most likely occur in different threads. Of course, Akka provides the necessary synchronization to ensure that any state changes are visible to all threads.
The repair customer (we are with you) asks the construction company to repair him several rooms. The foreman manages the queue and the builder loading, makes sure that he does not overwork and do not stand idle. We do not directly communicate with the builder, but work with his representative (company). Knowing how we are slowly building, we give up the task and do not even hope for its quick execution (we do not wait for the result, but we go to do our own business).
Load script
By analogy with the HTTP-example and taking as a basis the old script to describe the custom protocol, we will write our builder. It takes some action of the client for the load and works with the actors:
val mine = new ActionBuilder { def build(ctx: ScenarioContext, next: Action): Action = { new ActorDelegatingAction(name, ctx.system.actorOf( Props(new MyAction(next, lient, ctx)))) } } The run result handler is not included in the standard implementation of the load scripts. The code from the old example no longer worked, so after the migration I had to dig a little in the Gatling source, studying the HTTP implementation:
val engine: StatsEngine = ctx.coreComponents.statsEngine engine.logResponse( session, requestName, ResponseTimings(start, end), status, None, message, Nil) The first run of the script
We already wrote the client for Thrift in the first part of the article. The car with which we ship - set up. Microservice also remained the same and holds 50K RPS.
It's time to ship. Let's try to linearly increase the load from 1 to 2K RPS for 60 seconds:
We see the lack of productivity growth from 1,100 RPS and the avalanche-like graph of Gatling-user request handlers. The oddity adds an extended test run time. So far there are more questions than answers.
The simplest and right decision turned out to be to add sleep instead of calling the client, after which the requests got into a long queue. It seems that we have created a single-agent load facility. We need more actors! Create a pool with them by adding just one line in ActionBuilder:
ctx.system.actorOf(RoundRobinPool(POOL_SIZE).props( Props(new MyAction(next, lient, ctx))))) Script c pool
Run the test again and see that we have reached 2K RPS:
Let's try 10K:
Not bad, but if 18K:
Again, similar problems at 15K, but there is nowhere to inflate the pool. Having rummaged in the Gatling repository, we found that the developers added the ability to reconfigure the very configuration of the Akka-actors model. This is done using the gatling-akka-defaults.conf file, which by default looks like this:
actor { default-dispatcher { throughput = 20 } } Gatling will offer your option:
actor { default-dispatcher { type = Dispatcher executor = "fork-join-executor" fork-join-executor { parallelism-min = 10 parallelism-factor = 2.0 parallelism-max = 30 } throughput = 100 } } How we work with the dispatcher is determined by the strategy in the executor. The settings with the parallelism prefix are responsible for the number of threads (at last we remembered them) and depend on the capabilities of the machine and the number of CPUs. Throughput determines the maximum of messages processed by one actor, before a thread gives a message to another actor. You should also correctly approach the selection of coefficients for these parameters.
Run with new settings and pool:
Coped with 18K, but began to notice periodic subsidence associated with the GC and the strategy of adding Gatling-users.
Ultimate load
Remembering that the car gave out 30K RPS with JMeter, we will try to give a similar load on Gatling, and we get 32K:
findings
JMeter makes it faster and easier to get results, but it has a slightly worse performance. Gatling allows you to load large volumes (which you may not need), but it’s harder to work with. The choice is yours.
Source: https://habr.com/ru/post/350452/
All Articles