Bitcoin and Ethereum: what happens on nodes that are not mining, and what will happen next?

Introduction
Recently, quite often people talk about the prospects of blockchain systems, that in the future, the blockchain will replace classical payment systems, such as, for example, Visa or Mastercard, and then, perhaps, will fundamentally change jurisprudence due to the possibilities of smart contracts. But, despite all the expectations, a full-fledged and comprehensive payment system on the blockchain has not yet been created. Payment of real goods and services by cryptocurrencies, as a rule, is carried out in cases when certain restrictions are imposed on the use of classical payment methods. At the same time, a significant part of transactions using cryptocurrency is speculative.
There are certainly a lot of factors hindering the development of blockchain systems. They can be both technical and economic, political or even psychological. This article will discuss only some of the technical limitations of the two most popular blockchain systems - Bitcoin and Ethereum.
It is assumed that you are already familiar with the basic principles of operation of these systems. If some terms are not completely clear, their explanation can be found in the book Mastering Bitcoin by Andreas Antonopoulos (you can find a translation into Russian in the network), and in the article about the principles of Ethereum work on Geektimes .
It is also worth noting that recently, in the wake of the popularity of blockchain systems, some distributed data warehouses have become attributed to them, which in the original understanding of the term blockchain are not, and therefore, as a rule, do not have an adequate level of security together with openness and independence. In this article, under the blockchain systems, we will understand distributed repositories that meet the following requirements:
- Data is stored in a single block chain. For short periods of time, several forks may occur at the end of the chain. But subsequently, only one of the branches can be recognized as valid.
- Data is kept decentralized, all nodes are equal and independent. The system does not have a single owner who can independently manage it. Any changes in the system can occur only if the majority of nodes accept these changes.
- All users have the opportunity to view any data stored in the system and check, on their basis, the correctness of adding blocks, and, consequently, the correctness of the data itself.
Prospects for accelerating the production of blocks
In modern systems, transactions are much slower compared to conventional payment systems. The most popular systems today, in the first place, Bitcoin and Ethereum are based on the use of the proof-of-work principle. To confirm the transaction in such systems, you must first wait until the transaction passes the turn to be added and will be fixed in the next block. Then you have to wait some time, during which the amount of computational work will be sufficient to guarantee that no one else can repeat this work on their own in order to modify the added data. In the Bitcoin system, the transaction is usually considered confirmed after adding 6 blocks after the block containing the corresponding transaction. This process takes about one hour. As for Ethereum, there is no consensus on a reliable confirmation: some wallets can wait for confirmation of 5 blocks (about a minute), while individual exchanges may require adding several hundred blocks for confirmation.
Some exchanges can carry out internal operations with cryptocurrencies much faster - in a matter of fractions of a second. But these transactions are internal. They are not entered into the general blockchain, but are stored in the database of a specific exchange. Information about transfers will get into the main blockchain only when depositing and withdrawing funds from an exchange. Therefore, in the future, we will not consider the internal transactions of the exchange as blockchain transactions.
To make small purchases, due to the low risks of the seller, it is often not necessary to wait for confirmation. There is enough information that the transaction is online and added to the queue. But, if we consider the system as a whole, the main element limiting network performance is still mining (mining) of blocks, since all the sent transactions will sooner or later have to be added to the blocks. The complexity of the extraction does not have a real physical basis, but is artificially set to provide the necessary amount of work for reliable confirmation. In the Bitcoin system, the mining difficulty is adjusted so that the average time to add a new block is approximately 10 minutes. If the blocks start to be mined faster, the complexity increases, if longer - decreases. The frequency of adding blocks to Ethereum is higher - a new block is added approximately every 15 seconds.
If necessary, the frequency of adding new blocks can be increased by reducing the complexity of the extraction, or even abandon the extraction process altogether, switching the system to work in accordance with the proof-of-stake principle. However, in both cases, the probability of simultaneously finding new blocks will increase, which will lead to an increase in the number of branching chains (fork) and the corresponding inconvenience. The critical time of adding a block here will be the time corresponding to the characteristic block propagation time over the network. After this threshold is exceeded, the miners too often will receive information about the new mined block after they have already obtained it (possibly including another set of transactions in it) and sent it to the network. Thus, the addition of almost every block will be accompanied by branching, which will make impossible the normal functioning of the network. The propagation time of the data across the network between different continents can be roughly estimated as 100 ms. Thus, the speed of adding blocks to Bitcoin can be increased by no more than , and in Ethereum - in .
Features of storing the transaction database on full nodes
It is possible to increase the number of processed transactions not only by increasing the frequency of production of new blocks, but also by increasing their size. In this case, sooner or later certain restrictions will also appear. One of the most simple limitations is the amount of disk space used. Working with data in Bitcoin and Ethereum is arranged in different ways, so it makes sense to consider them separately from each other.
Bitcoin
In the Bitcoin blockchain, account information is not stored. Only information about transfers is stored there. Therefore, in order to get the current balance of the user or just to make sure that he has enough funds to complete a particular transaction, you need to find such transfers in the database, as a result of which the relevant user receives funds, and make sure that these funds are not were spent as a result of subsequent transfers. Therefore, in order to be able to verify the authenticity of transactions in Bitcoin, you need to store on your device the history of operations since the creation of the system.
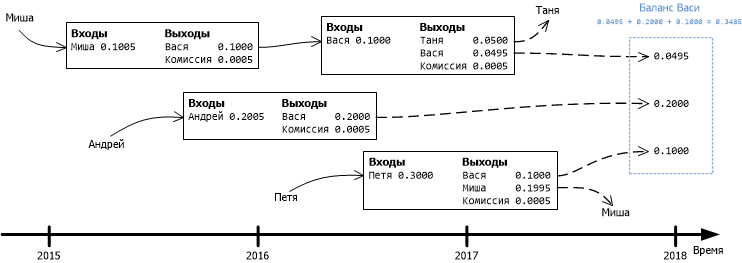
Figure 1. The Bitcoin blockchain does not store information about the current status of accounts, only information about debiting and crediting funds within specific transactions. To find out the current balance, you need to sum up all transactions with unspent exits.
At the moment, the Bitcoin blockchain size exceeds 150 GB and is increasing at a rate of about 50 GB / year. It should be noted that this growth is associated not so much with the arrival of new users, as with the completion of transactions by existing users. Since the information about new transactions is added to the repository every day, and the information about old transactions is not deleted, the volume of the database will only grow.
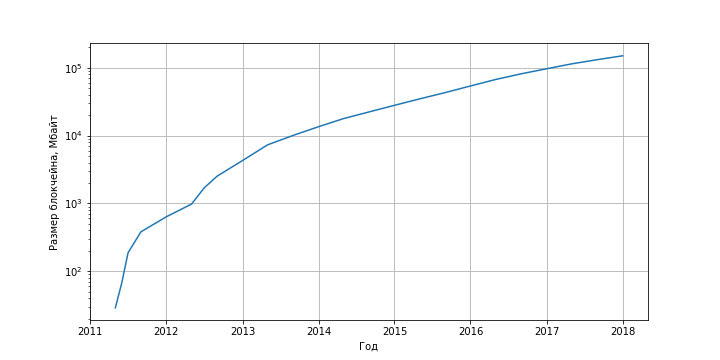
Figure 2. Bitcoin block size dependence on time. Source: blockchain.info .
Not all users are ready to allocate on their personal computer several hundred gigabytes of disk space to store the blockchain. It should be noted that these are not just files stored on a disk, but a database, which, when adding new blocks, rebuilds a part of the data to ensure the efficiency of their storage. Bitcoin clients most often use the LevelDB NoSQL database built on LSM trees.
Verification of transactions can be optimized through the use of a separate transaction database with unspent exits (UTXO), since it is these data that are of the greatest interest. Theoretically, by verifying the authenticity of UTXO, information about old transactions can be removed from the common database for the purpose of optimization. However, the remaining database still takes more than one gigabyte of disk space. The intensity of disk access will decrease slightly. The base size, of course, will be an order of magnitude smaller, but in addition to adding transactions, UTXO deletes with closed outputs will appear in this case. Thus, the maintenance of the so-called full network node causes some inconvenience to ordinary users. It is believed that a significant part of the complete Bitcoin nodes are already located in data centers.
For the operation of the software "wallet" and sending transactions the storage of a complete database is not a prerequisite. Usually it is enough to have a “light” node, which will request the necessary data from other nodes over the network. So many programs "wallets" and clients for mobile devices work. However, this approach does not provide absolute reliability: you have to trust the data obtained over the network. By requesting additional, redundant data from various sources, it is possible to achieve an increase in reliability, but the reliability will be probabilistic in this case. The same applies to anonymity: by requesting data on certain transactions over the network, the user actually gives out his area of interest. By requesting redundant data, the area of interest can be masked, but only with a certain probability. The refusal of users to maintain complete nodes is not favorable for the network as a whole, since it makes it easier to dial a critical number of full nodes, which allows you to influence the transaction processing process.
Ethereum
In Ethereum, there is the concept of a state (state) of an account, which includes the state of the account. The blockchain stores changes to such states. Ethereum nodes store current status of accounts and, when receiving new blocks, apply changes to existing states, thereby maintaining their relevance. To ensure reliability, it is not necessary to keep old states; the last current state is enough and confidence that it is correct. Due to this, in Ethereum there are not two but three types of nodes:
- Archive nodes . Such nodes sequentially process all transactions, store the entire history of states and allow at any time to recreate the entire history of operations, in particular, the history of fulfilling "smart" contracts. Such nodes are used, as a rule, for debugging and statistical analysis. They may also be required to explain and justify actions resulting from calls to “smart” contracts. In addition, a complete database is required for production.
- Full nodes . Full nodes also perform all incoming transactions, but store only current states and do not store the entire history of operations. Using such nodes, you can safely make transfers (there is a guarantee that the available information about the balance of other participants in the transaction is reliable), but you cannot view the history of operations. It is reasonable to use such nodes on stationary PCs to make transfers.
- Easy knots . Similar to Bitcoin light nodes, such nodes store a minimal set of information and request data from the network as necessary. The use of such nodes is not completely safe. But the nodes of this type impose significantly lower requirements on users' computers and can work on mobile devices.
For more information on the types of synchronization, see the article on dev.to.
The problems of Ethereum archive nodes are similar to the problems of full Bitcoin nodes: the database size is in the hundreds of gigabytes and, if the growth rate of the amount of data remains, then by the end of 2018 the full database will no longer fit on one standard hard drive or solid-state drive.
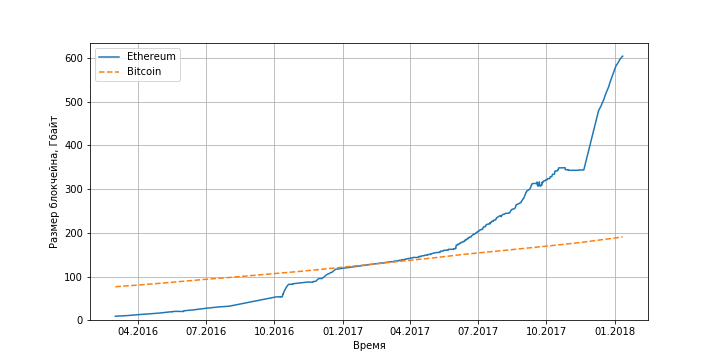
Figure 3. The dependence of the Ethereum blockchain size on time (for comparison, the dependence for Bitcoin is also shown). Source: daniel.net.nz .
But, as mentioned above, to securely conduct transactions with a fairly complete Ethereum node with a “clipped” database, which currently occupies “only” 40 GB.
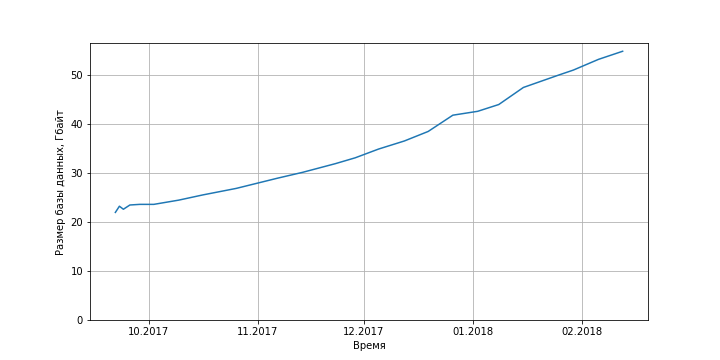
Figure 4. The dependence of the size of the Ethereum full node database on time. Source: etherscan.io .
However, in practice, not everything is so simple. As a result of experiments with one of the most popular client implementations of Ethereum, Geth (Go Ethereum), in January 2018, it turned out that in approximately two weeks of the client’s work, the database size increased from 40 GB to 80 GB. Further research showed that after the synchronization of the database is completed, this client enters the archive site mode. That is, information about outdated account states is not deleted from the database, which leads to an increase in the size of the database, which may relatively quickly exceed several hundred gigabytes (see Figure 3). The developers know about the problem , but the ticket is closed almost six months ago without taking any measures to solve the problem. The only practical recommendation is to remove the database and reload it in the “fast” synchronization mode (it may take several days). In this case, the loaded database will indeed be smaller, but after the synchronization is complete, the client will again switch to full synchronization mode and the database size will again start to grow rapidly.
It seems that one of Ethereum’s most popular customers is not designed for long-term use in safe mode, but is focused only on miners, which require a full base, and speculators who are only interested in the cost of cryptocurrency, and not the reliability and reliability of using the appropriate software.
Ethereum Virtual Machine
As you know, Ethereum is not only a means for making payments, but also a distributed virtual machine that allows you to execute smart contracts. Such contracts are simple programs executed on a special virtual machine. Taking into account the fact that each complete or archive node must consistently fulfill all incoming calls of such contracts, it is reasonable to assume that the further development of Ethereum is limited precisely by the capabilities of modern computers for handling a large number of calls to such contracts.
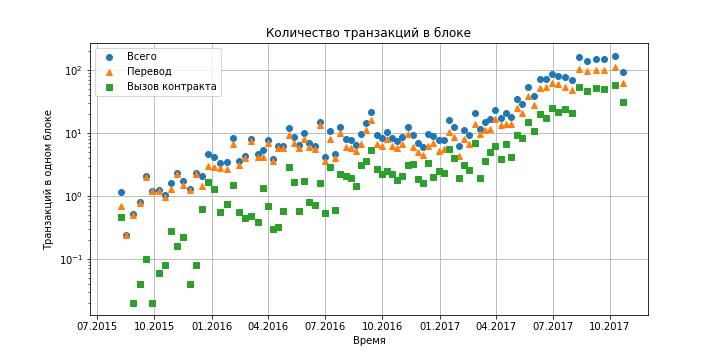
Figure 5. Dependence of the number of transactions in one block of the Ethereum blockchain on time (the rate of adding blocks is almost constant and is approximately four blocks per minute).
You can estimate the growth of the computational complexity of processing “smart” contracts by downloading the full database. Among other things, the full database stores the code of all contracts, the complete history of their states and the arguments with which they were invoked. All this allows you to replay all the calls of contracts and get traces of their execution in operations of the Ethereum virtual machine (EVM - Ethereum Virtual Machine). The list of used commands can be viewed, for example, on GitHub .
After analyzing these traces, you can estimate the number of operations performed when adding the next block. The most demanding of resources are operations that perform the calculation of hash functions, operations for working with memory and service operations associated with the challenge of other contracts.
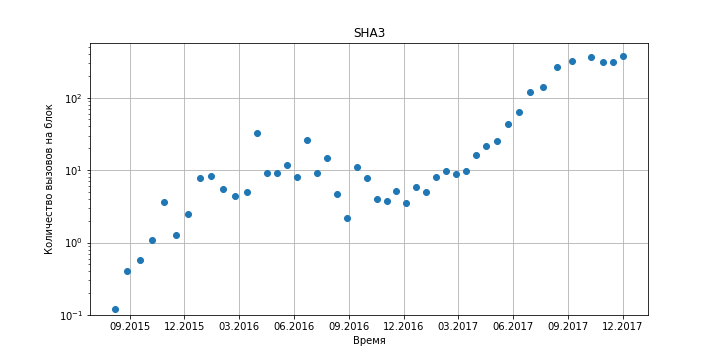
Figure 6. The number of calls to the sha3 hash function in Ethereum contracts versus time.
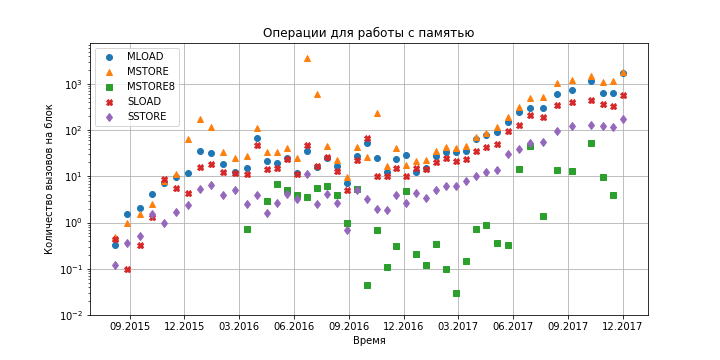
Figure 7. Dependence of the number of calls to various memory access operations in Ethereum contracts on time.
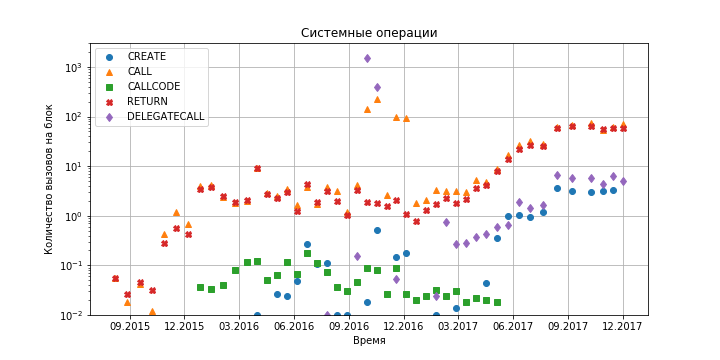
Figure 8. Dependence of the number of system calls in Ethereum contracts on time.
As can be seen from the graphs, at the moment the Ethereum virtual machine for its work does not require a large amount of resources: within a second, about one hundred hash functions are calculated (taking into account the production rate of 4 blocks per minute), several hundred memory accesses of various types and order 10 system calls. Even if we take into account a tenfold growth over the course of a year, problems with data storage will arise much earlier (see previous sections).
Ethereum profiling
Despite the fact that the Ethereum virtual machine should not consume a lot of resources in the course of its work, the Geth client almost completely loads the CPU and uses memory and hard disk quite actively. The Ethereum database contains a significant number of records; therefore, it is possible that quite a lot of resources are required to work with it. You can roughly estimate the frequency of disk accesses. When performing a transaction, you need to check that the sender's funds are fixed in the blockchain. To do this, make a search in the database on disk. Taking into account the logarithmic search time and the overhead associated with the structure of LSM trees, one search operation in the database can be estimated as 100 random disk accesses. Each block contains approximately 100 transactions (see previous section). Approximately 4 blocks are added per minute. Thus, only to check transactions per minute you need to commit random disk accesses.
To verify this assessment and identify the most difficult from the computational point of view of the client, its profiling was carried out using the execution trace recording function provided by the developers. To analyze the recorded trace, standard go (go tool trace) language tools were used.
The diagram below shows the results of measuring the time of operation of various gorutin (analogous to flows in the go language) during the work of the Geth client after the completion of full synchronization. The measurements were carried out for 60 seconds.
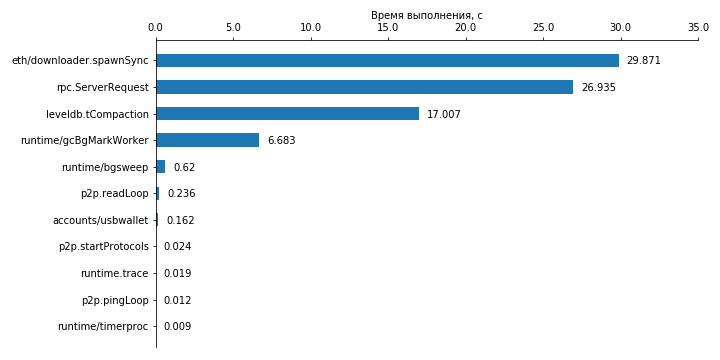
Figure 9. Runtime of the 10 most resource-demanding GORUTIN client of the Geth after the completion of full synchronization in case of placing the database on the hard disk. The measurement time is 1 minute.
The diagram shows that most of the time is occupied by the work of the loader, which must import blocks, verify transactions, execute the corresponding contract calls using the virtual machine, and update the corresponding states in the database. Due to the small amount of data (4 blocks of approximately 100 transactions per minute), the download itself should not take much time. The work of the virtual machine, as it turned out, too. A more detailed analysis of the profile showed that during the measurement (1 minute) about 100,000 system calls were made, most of which were accessing LevelDB database files that were located on the hard disk (that is, the estimate given above turned out to be correct) . Thus, the average time between adjacent file accesses is , which is in order of magnitude comparable to the time of random access to the hard disk. Based on this, we can conclude that disk access is the bottleneck in this case. This assumption also has experimental confirmation in the form of a consistently high disk load in the process of the client.
The situation with rpc.ServerRequest (a task that ranked second in terms of execution time) is similar - a fairly large number of system calls, at the time of which the top part of the stack looks like:
syscall.Pread:1372 os.(*File).pread:238 os.(*File).ReadAt:120 github.com/ethereum/go-ethereum/vendor/github.com/syndtr/goleveldb/leveldb/table.(*Reader).readRawBlock:564 github.com/ethereum/go-ethereum/vendor/github.com/syndtr/goleveldb/leveldb/table.(*Reader).readFilterBlock:653 * * * In third place in terms of execution is database maintenance - leveldb.tCompaction. This is followed by the overhead associated with garbage collection in the go language. The remaining gorutin takes negligible time.
Thus, in the case of storing the full database on a hard disk (not SSD), the limiting factor is the operation of the database, or rather file I / O. Therefore, to ensure the effective operation of a full site, it is recommended to use solid-state drives, which theoretically can speed up the database by 2-3 orders of magnitude. You can further reduce the load on the database by using fast synchronization. In this case, the size of the database should be an order of magnitude smaller (tens of gigabytes instead of hundreds), so the update in such a database should be faster, including at the expense of a smaller number of accesses to the hard disk. The results of profiling the Geth client in the process of adding blocks after quick synchronization in the conditions of placing the base on the SSD are shown in the diagram below. The measurements were carried out for 10 minutes.
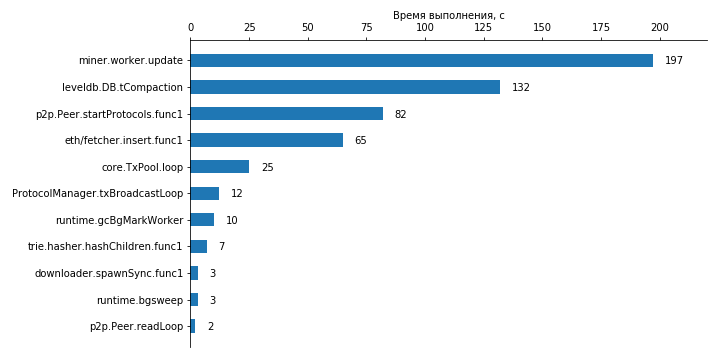
Figure 10. The execution time of the 10 most demanding gorutin in the Geth client after the completion of fast synchronization in case of placing the database on a solid-state drive. The measurement time is 10 minutes.
As a result of profiling, it turned out that the miner. (* Worker) .update took the longest time to complete. At first glance, the results seem surprising, since before the start of profiling mining was turned off by explicitly calling the appropriate API function. A more detailed analysis of the results of profiling and viewing the Geth source code showed that, despite the production turned off, the miner continues to process incoming transactions and add them to its database. Thus, there is no real mining here, and most of the work of the miner comes down to working with the database and system calls to access the corresponding files.
In second place is the database maintenance. Further, there are other tasks that in one way or another use the database.
Interestingly, hashing (gorutin (* hasher) .hashChildren) on average takes 30 times less time than working with a miner transaction database. At the same time, if the miner works all the time within the framework of a single gorutina, then for calculating the hashes, the gorutins are created and destroyed each time with all the attendant overhead. In a second, several hundred such gorutin are created and destroyed. Thus, in the case of accelerating the database and increasing the number of added transactions, the calculation of hash functions is likely to become one of the main bottlenecks.
Hashing is used not only to confirm and verify blocks in systems based on the proof-of-work principle, but also underlies the storage of data in blocks and checking their integrity. Therefore, the problem of calculating hash functions will arise in systems based on proof of ownership (proof-of-stake). The solution to this problem can be the use of accelerators, which can be built both on the basis of general-purpose video cards, and on the basis of specialized coprocessors or microchips, which are already used today for mining in the Bitcoin system.
Conclusion
If you do not take into account the mining process, as artificially created complexity, the bottleneck in terms of performance in modern blockchain systems are databases. If the growth rate of the number of transactions made does not decrease, then, probably, by the end of 2018, the complete block chains of the most popular blockchain systems will no longer fit onto one hard disk. In one of the most popular clients of the Ethereum system, there is still no normal support for a full node in the pruned mode. In the Bitcoin system, such modes are not explicitly provided.
When working with databases in blockchain systems, not only disk size is important, but also its speed. Already, in the case of placing data on ordinary hard drives, much of the time is spent reading and writing data. Probably, soon full nodes will be able to work only on solid-state drives. In the future, you will probably need to switch to SSD arrays and use more complex databases that provide higher performance due to parallel operation with a large number of drives.
With regard to technical limitations not related to databases, the greatest of them, most likely, will be the calculation of hash functions. This problem can be solved by using video cards or other specialized devices.
Therefore, many users who today maintain complete nodes on their personal computers may soon have to abandon them in favor of "light" and at the same time less secure clients. Thus, the number of full nodes in the network will decrease, and they will most likely be located in data centers of large companies that can afford high-performance data warehouses, servers with really large amounts of RAM to optimize database performance and specialized accelerators for computing hash functions. Whether large companies will be able to unite into a common network or will they independently support several different systems, and how exactly work with such systems will be organized is not yet clear. However, it is obvious that such systems will not be as decentralized and independent as, for example, modern Bitcoin.
Another approach is possible, consisting in the distributed storage of individual parts of the blockchain on user devices. In this case, users will need significantly less disk space, but the network load will increase, since most of the data will be requested from other users. A sufficient level of security can be achieved only with significant redundancy of the requested data, provided there are a sufficient number of independent sources. The organization of interaction between nodes that store different parts of the database may require special nodes-routers (perhaps, such nodes will be arranged similarly to BitTorrent trackers), which will also lead to a decrease in the decentralization of the network.
In any case, as the number of transactions increases, changes will occur in the structure of the blockchain systems. What exactly they will be, how it will affect the security, reliability and independence of such systems, time will tell.
Literature
')
Source: https://habr.com/ru/post/350418/
All Articles