Technologies of unmanned vehicles. Yandex lecture
Yandex continues to develop technology unmanned vehicles. Today we are publishing a lecture by one of the leaders of this project, Anton Slesarev. Anton spoke at the "Data-tree" at the end of 2017 and spoke about one of the important components of the stack of technologies necessary for the operation of the drone.
- My name is Anton Slesarev. I am responsible for what works inside the unmanned vehicle, and for the algorithms that prepare the car for the trip.
I will try to tell you what technologies we use. Here is a brief block diagram of what happens in a car.
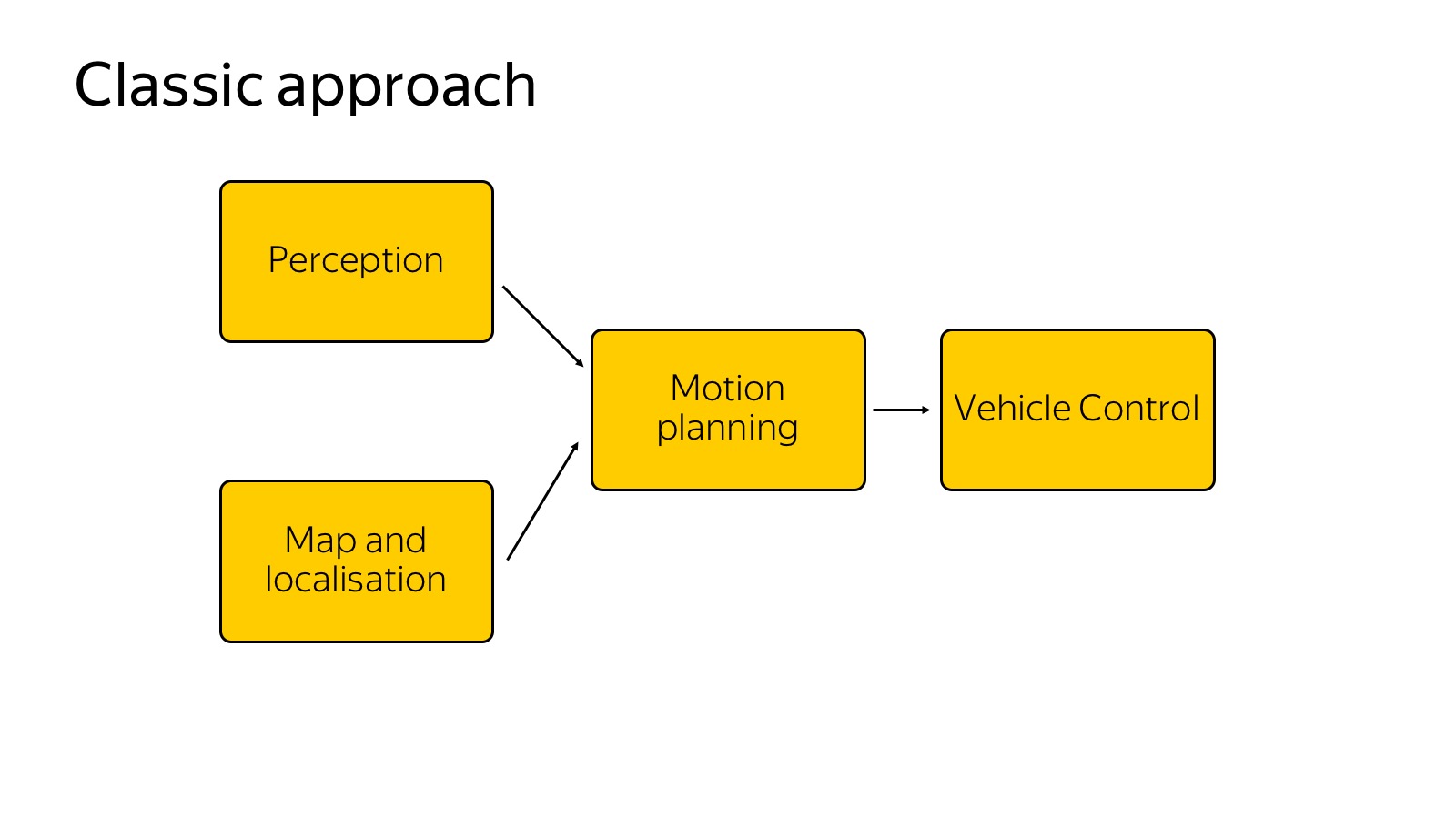
We can assume that this scheme appeared as follows: it was told and invented in 2007, when the DARPA Urban Challenge was held in the USA, a competition about how the car would travel in urban areas. Several top American universities such as Carnegie Mellon, Stanford, and MIT competed. It seems Carnegie Mellon won. The participating teams published excellent detailed reports on how they made the car and how they drove in urban environments. From the point of view of the components, they all painted about the same thing, and this scheme is still relevant.
We have a perception that is responsible for the world around us. There are maps and localization that are responsible for where the car is located in the world. Both of these components are input to the motion planning component - it makes decisions about where to go, what path to build, taking into account the world around. Finally, motion planning transmits the trajectory to the vehicle control component, which performs the trajectory based on the physics of the car. Vehicle control is more about physics.
')
Today we will focus on the perception component, since it is more about data analysis, and in my opinion, in the near future, this is the most challenging part on the entire front of UAV operations. The remaining components are also incredibly important, but the better we recognize the world around us, the easier it will be to do the rest.
First show another approach. Many have heard that there are end-to-end architectures and, more specifically, there is a so-called behavior cloning, when we try to collect data on how the driver drives and to slope his behavior. There are several works, which describes how it is easiest to do. For example, the variant is used when we have only three cameras to “aggregate” the data so that we do not travel along the same trajectory. This is all thrust into a single neural network that tells where to turn the wheel. And it somehow works, but as the current state of affairs shows, now the end-to-end is still in a state of research.
We tried it too. We have one person end-to-end quickly trained. We were even a little afraid that we’ll dismiss the rest of the team, because in one month it achieved the results that we have been doing for a lot of people for three months. But the problem is that it is already hard to move further. We have learned to ride around one building, and driving around the same building in the opposite direction is much more difficult. Until now, there is no way to present everything in the form of a single neural network so that it works more or less robustly. Therefore, everything that drives in real conditions usually works on the classical approach, where perception explicitly builds the world around.
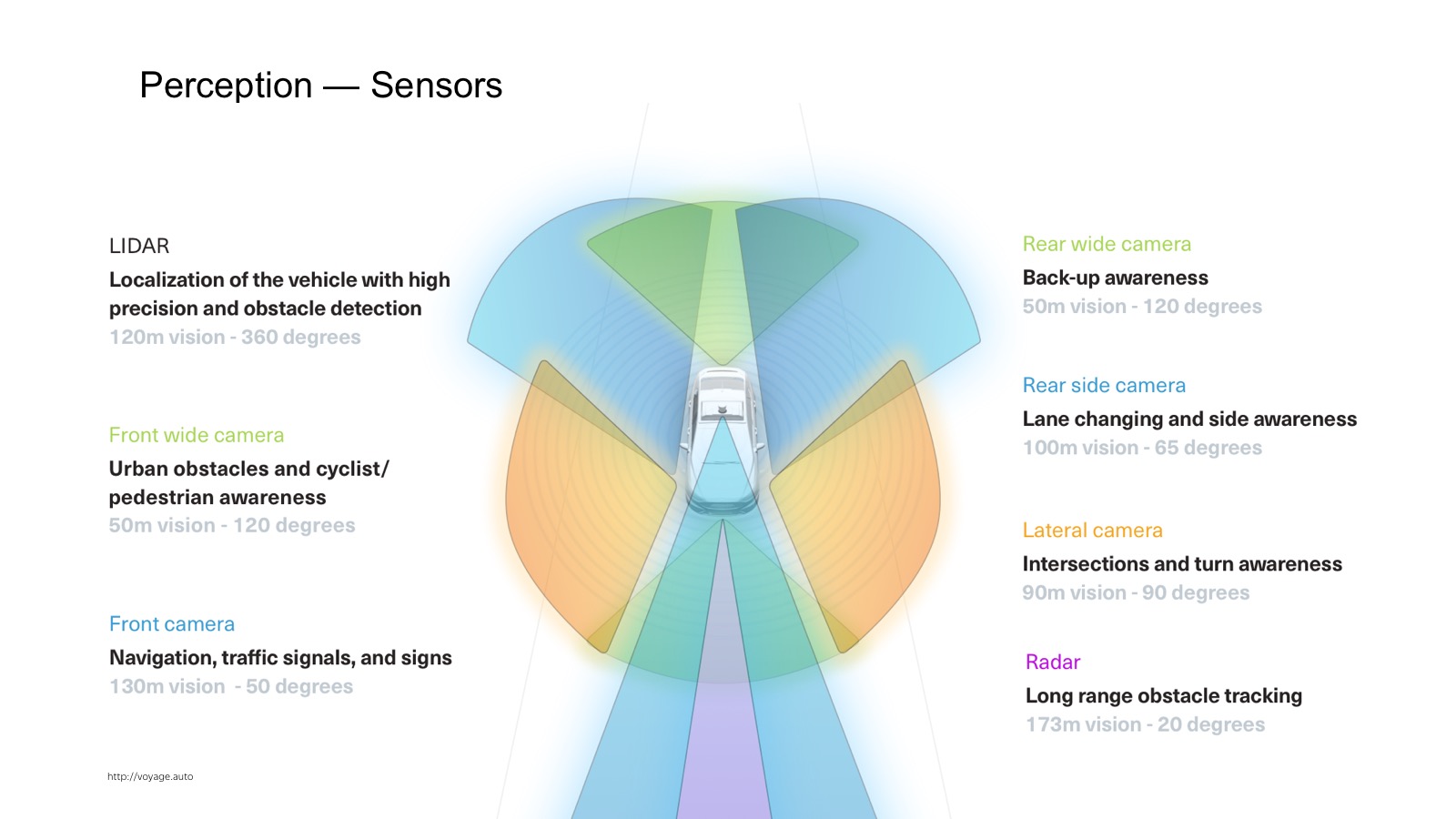
How does perception work? First you need to understand what data and what information flows to the input of the car. In the car a lot of sensors. The most widely used are cameras, radars and lidars.
The radar is already a production sensor that is actively used in adaptive cruise controls. This is a sensor that says where the car is located on the corner. It works very well on metal things such as cars. On pedestrians works worse. A distinctive feature of the radar is that it not only provides the position, but also gives out speed. Knowing the Doppler effect, we can find out the radial velocity.

Cameras - of course, the usual video picture.

More interesting is the lidar. Those who did repairs at home, are familiar with the laser rangefinder, which is hung on the wall. Inside, there is a stopwatch that counts how much the light flies back and forth, and we measure the distance.
In fact, there are more complex physical principles, but the point is that there are many laser rangefinders, which are vertically located. They scan the space, it is spinning.

Here is a picture that is obtained by a 32-ray lidar. Very cool sensor, at a distance of several meters a person can find out. Even naive approaches work, a level has found a plane - everything above this obstacle. Therefore, the lidar is very much loved, it is a key component of unmanned vehicles.
With lidar a few problems. The first - it is quite expensive. The second is that it is spinning all the time, and sooner or later it will unscrew. Their reliability leaves much to be desired. They promise lidars without moving parts and are cheaper, while others promise that they will do everything on computer vision only on cameras. Who will win - the most interesting question.
There are several sensors, each of them generates some data. There is a classic pipeline of how we train some machine learning algorithms.
We need to collect data, fill it with some kind of cloud, using the example of a car, we collect data from cars, fill it with clouds, mark it in some way, choose the best model, invent a model, tune parameters, retrain. An important caveat is that you have to put it back on the car so that it works very quickly.
Data collected in the cloud, we want to mark them.
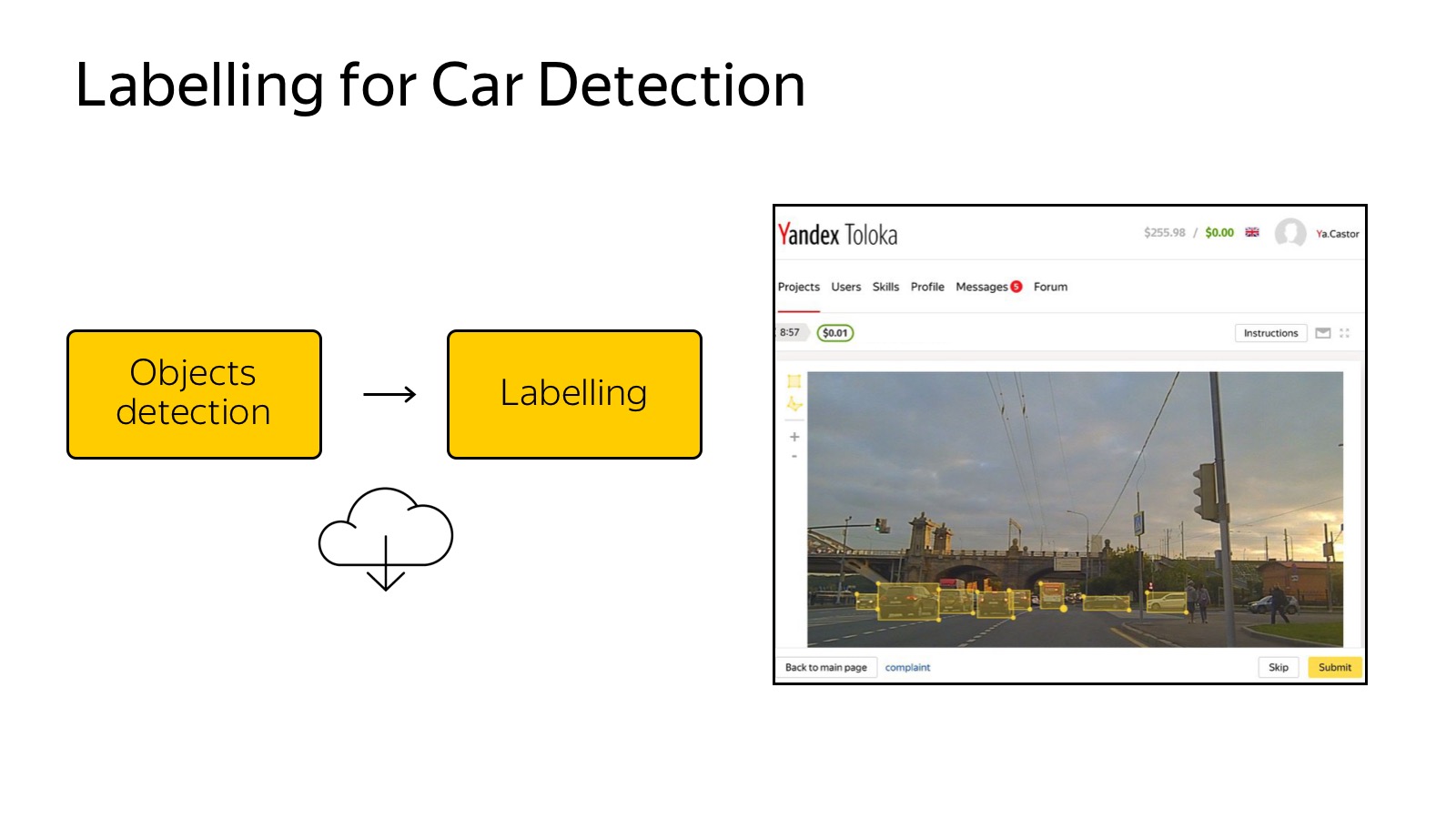
Already today, the mentioned Toloka is my favorite Yandex service, which allows you to mark a lot of data very cheaply. You can create a GUI as a web page and distribute it to the markup. In the case of a detector of machines, it is enough for us to select them with rectangles, this is done simply and cheaply.
Then we choose some method of machine learning. For ML, there are many quick methods: SSD, Yolo, their modifications.
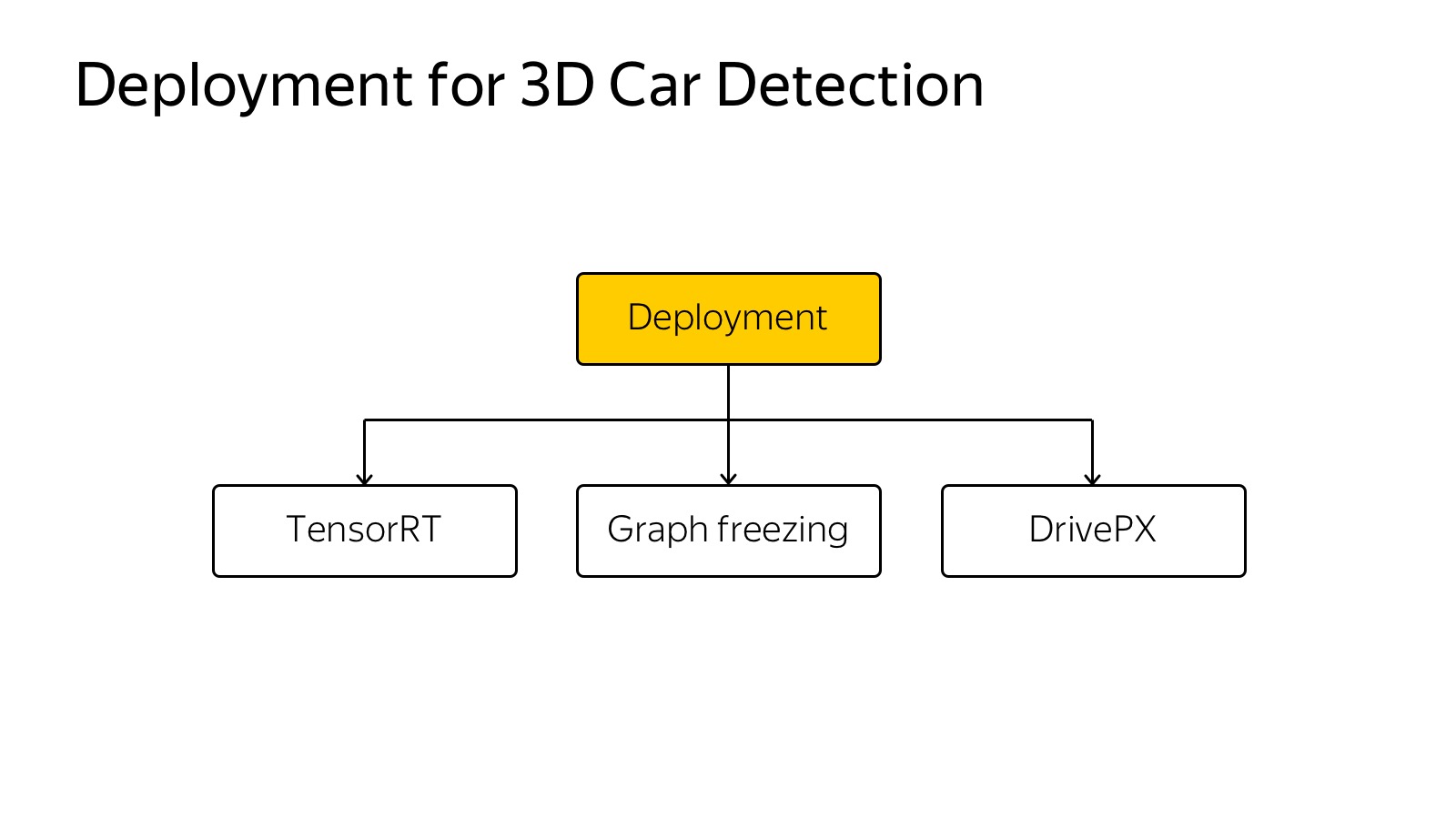
Then it needs to be inserted into the car. A lot of cameras, 360 degrees must be covered, it must work very quickly to react. A variety of techniques are used, Inference engines like Tensor RT, specialized hardware, Drive PX, FuseNet, several algorithms are used, a single backend, convolutions are banished once. This is a fairly common technology.
Object detection works like this:
Here, in addition to cars, we will detect more pedestrians, still detect the direction. The arrow shows the estimated direction only for the camera. Now she is crap. This is an algorithm that works on a large number of cameras in real time on the machine.
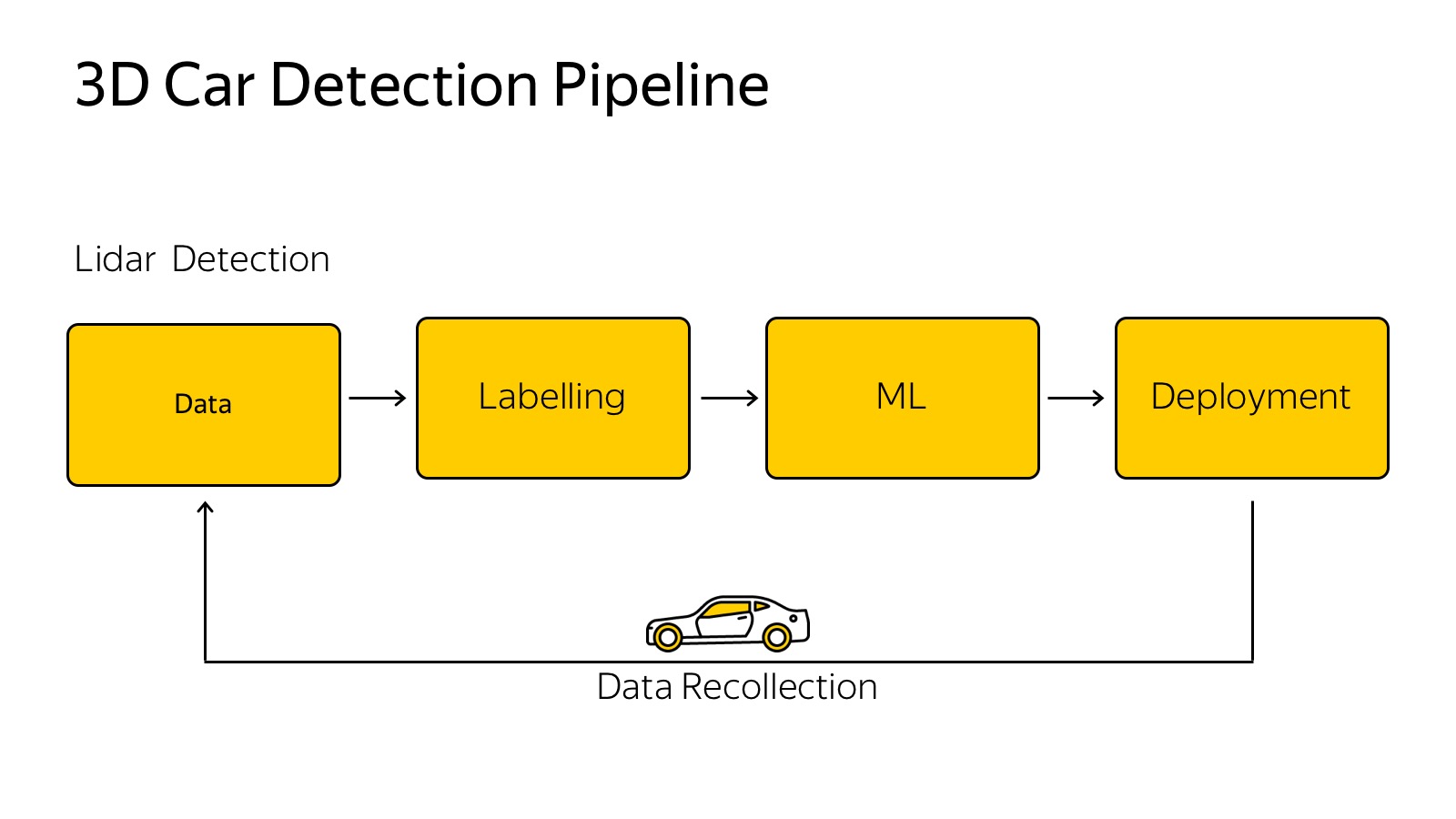
About object detection is a solved problem, many people can do it, a bunch of algorithms, a lot of competitions, a bunch of datasets. Well, not very much, but there is.
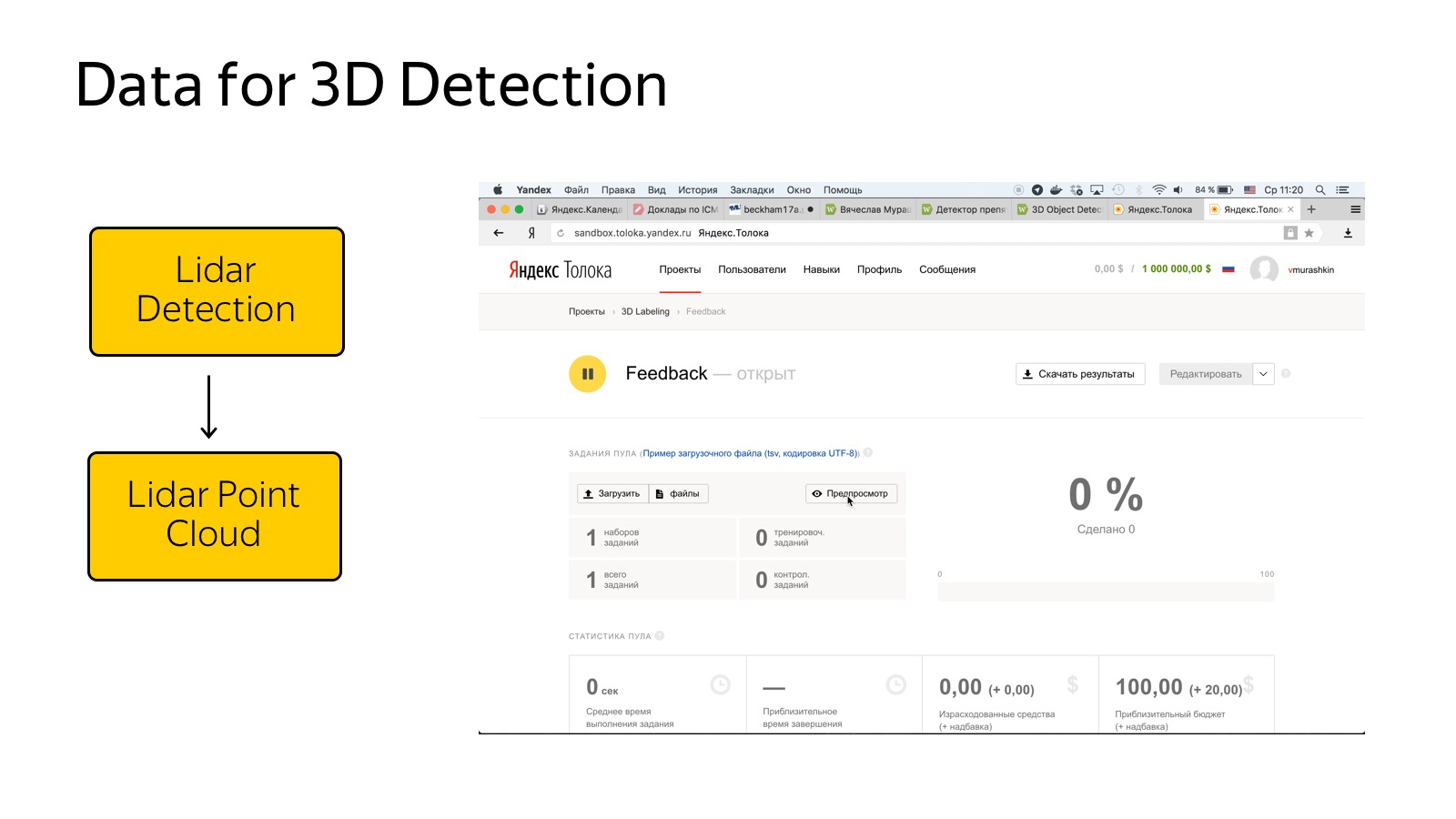
With lidars it is much more difficult, there is one more or less relevant dataset, this is KITTI dataset. It is necessary to mark from scratch.
The process of marking a cloud of points is a fairly non-trivial procedure. Ordinary people work in Toloka, and explaining to them how 3D projections work, how to find machines in the cloud is a rather trivial task. We spent some amount of effort, it seemed to be more or less able to streamline the flow of this kind of data.
How to work with it? Clouds of points, neural networks are the best in detection, so you need to understand how a cloud of points with 3D coordinates around the car is fed to the input of the network.
It all looks like you need to somehow present it. We experimented with the approach when you need to make a projection, a top view of the points, and cut into cells. If there is at least one dot in the box, then it is busy.
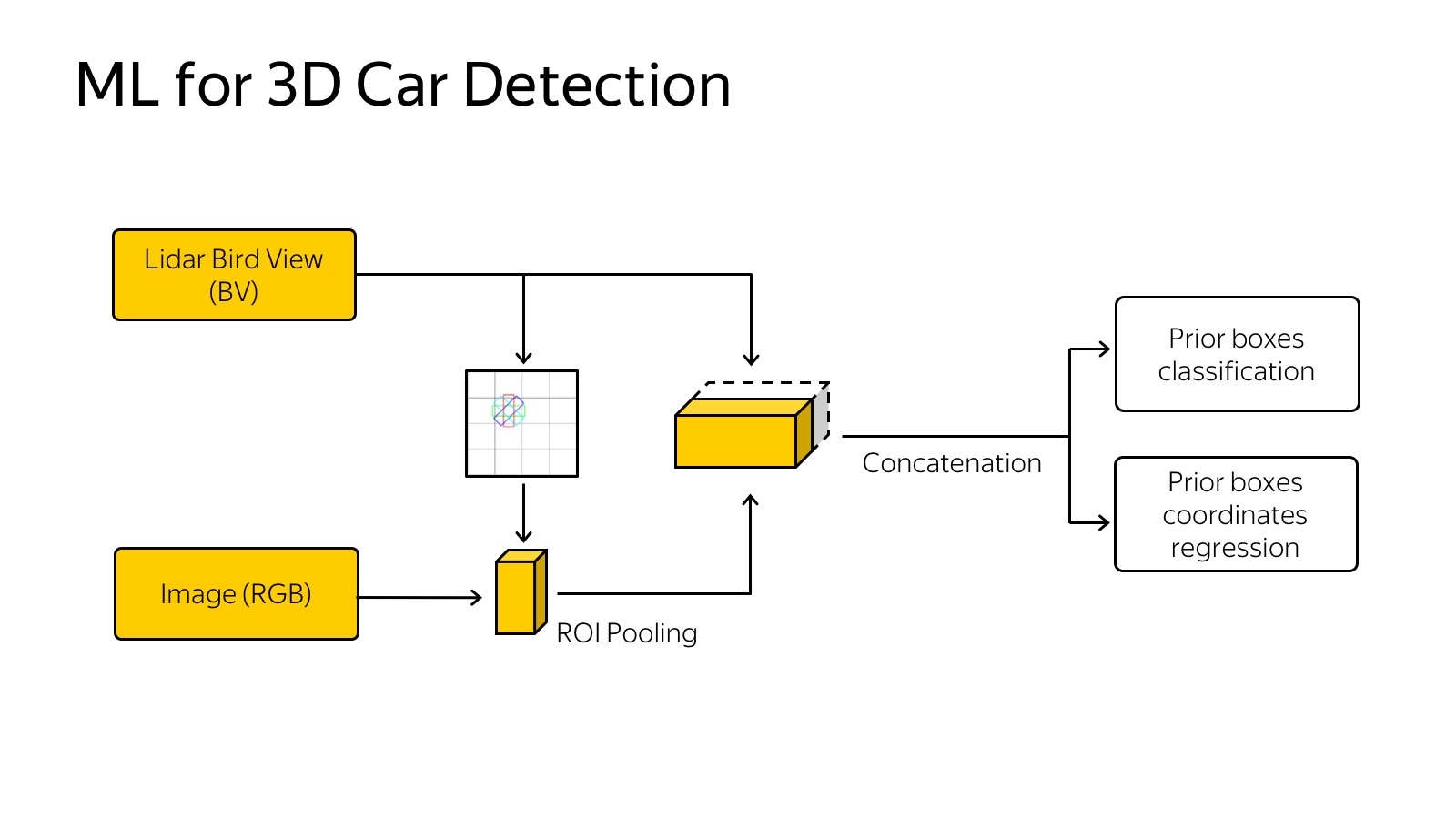
You can go further - to make slices vertically and, if there is at least one point in the cube vertically, write it in some characteristic. For example, recording the highest point in the cube works well. Slices are fed to the input of the neural network, it’s just an analogue of pictures, we have 14 channels to the input, we work about the same as with SSD. Another signal comes from the network, trained for detection. At the entrance of the network is a picture, this is all end-to-end training. At the exit, we predict 3D boxes, their classes and position.
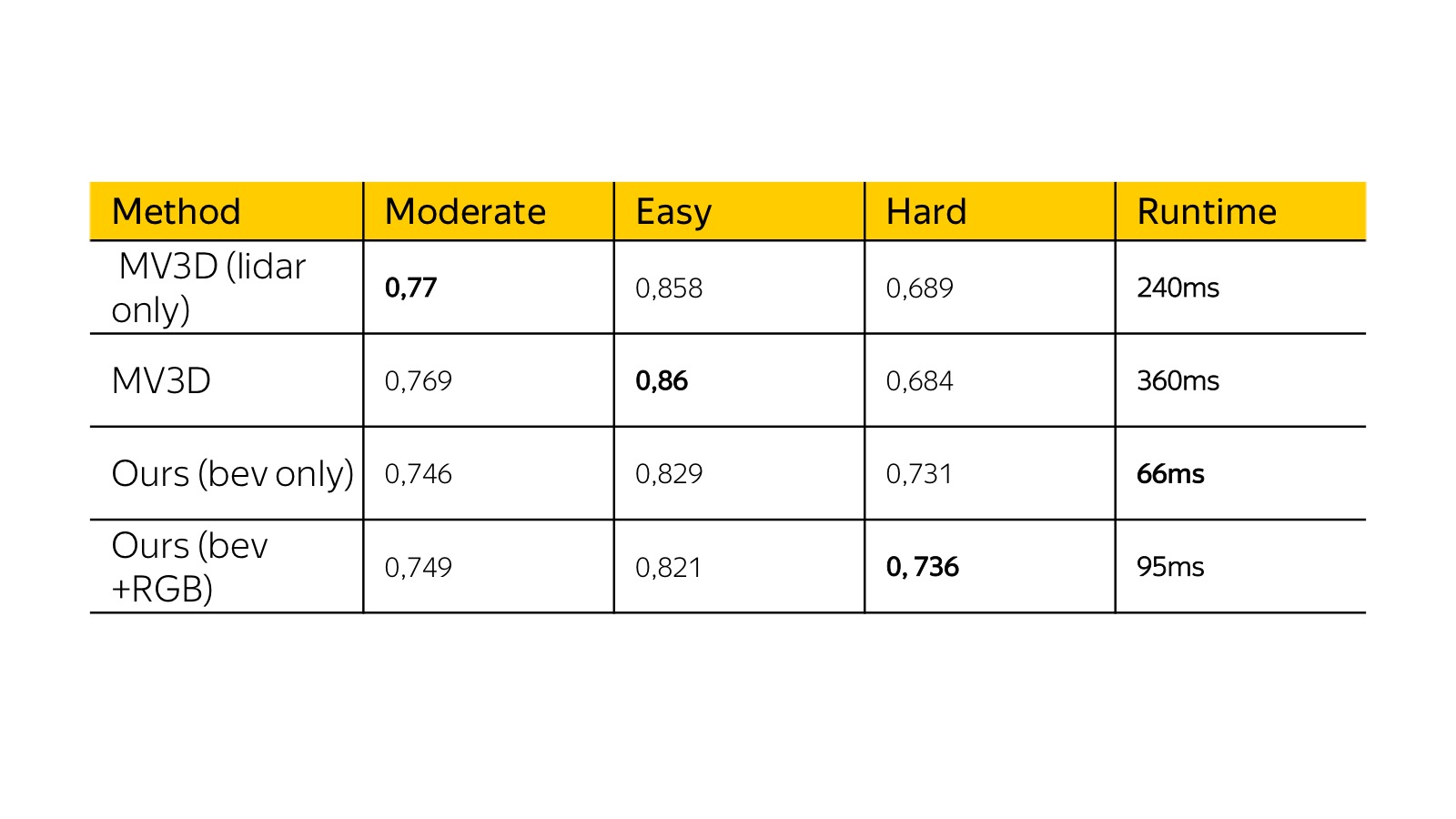
Here are the results of a month ago on KITTI dataset. Then multiple view 3D was a state of the art. Our algorithm was similar in quality from the point of view of precision, but it worked several times faster, and we could plug it into a real machine. Acceleration was achieved by simplifying the presentation basically.
It is necessary again on the typewriter. Here is an example of work.

Here you have to be careful, this is a train, but it also works on the test, the green boxes are marked with cars.

Segmentation is another algorithm that can be used to understand what is located in the picture. Segmentation tells which class each pixel belongs to. Specifically, in this picture there is a road marking. The edges of the road are highlighted in green, and the cars are slightly different, purple.

Who understands the disadvantages of segmentation in terms of how to do this in motion planning feed? Everything merges. If there are parked cars nearby, then we have one large purple spot of cars, we do not know how many there are. Therefore, there is another remarkable formulation of the problem - Instance segmentation, when you still need to cut different entities into pieces. And we also do this, comrade last week in the top 5 city scapes for instance segmentation came. I wanted to take first place until it works, but there is such a task too.
We try to try as many different approaches, hypotheses as possible. Our task is not to write the best object detection in the world. This is necessary, but, first of all, there are new sensors, new approaches. The task is to try and implement them as soon as possible in real life circumstances. We are working on all that hinders us. Slowly we mark the data - we make a system that marks them with the active use of the Toloka service. The problem with the deployment of the car - we figure out how to accelerate it in a unified way.
It seems that the winner is not the one who now has a lot of experience, but the one who runs faster. And we are focused on this, we want to try everything as quickly as possible.
Here is a video that we recently showed, travel in winter conditions. This is an advertising video, but it is clearly seen here, about how unmanned vehicles drive in the current realities (since then another video has appeared - approx. Ed.). Thank.
- My name is Anton Slesarev. I am responsible for what works inside the unmanned vehicle, and for the algorithms that prepare the car for the trip.
I will try to tell you what technologies we use. Here is a brief block diagram of what happens in a car.
We can assume that this scheme appeared as follows: it was told and invented in 2007, when the DARPA Urban Challenge was held in the USA, a competition about how the car would travel in urban areas. Several top American universities such as Carnegie Mellon, Stanford, and MIT competed. It seems Carnegie Mellon won. The participating teams published excellent detailed reports on how they made the car and how they drove in urban environments. From the point of view of the components, they all painted about the same thing, and this scheme is still relevant.
We have a perception that is responsible for the world around us. There are maps and localization that are responsible for where the car is located in the world. Both of these components are input to the motion planning component - it makes decisions about where to go, what path to build, taking into account the world around. Finally, motion planning transmits the trajectory to the vehicle control component, which performs the trajectory based on the physics of the car. Vehicle control is more about physics.
')
Today we will focus on the perception component, since it is more about data analysis, and in my opinion, in the near future, this is the most challenging part on the entire front of UAV operations. The remaining components are also incredibly important, but the better we recognize the world around us, the easier it will be to do the rest.
First show another approach. Many have heard that there are end-to-end architectures and, more specifically, there is a so-called behavior cloning, when we try to collect data on how the driver drives and to slope his behavior. There are several works, which describes how it is easiest to do. For example, the variant is used when we have only three cameras to “aggregate” the data so that we do not travel along the same trajectory. This is all thrust into a single neural network that tells where to turn the wheel. And it somehow works, but as the current state of affairs shows, now the end-to-end is still in a state of research.
We tried it too. We have one person end-to-end quickly trained. We were even a little afraid that we’ll dismiss the rest of the team, because in one month it achieved the results that we have been doing for a lot of people for three months. But the problem is that it is already hard to move further. We have learned to ride around one building, and driving around the same building in the opposite direction is much more difficult. Until now, there is no way to present everything in the form of a single neural network so that it works more or less robustly. Therefore, everything that drives in real conditions usually works on the classical approach, where perception explicitly builds the world around.
How does perception work? First you need to understand what data and what information flows to the input of the car. In the car a lot of sensors. The most widely used are cameras, radars and lidars.
The radar is already a production sensor that is actively used in adaptive cruise controls. This is a sensor that says where the car is located on the corner. It works very well on metal things such as cars. On pedestrians works worse. A distinctive feature of the radar is that it not only provides the position, but also gives out speed. Knowing the Doppler effect, we can find out the radial velocity.
Cameras - of course, the usual video picture.
More interesting is the lidar. Those who did repairs at home, are familiar with the laser rangefinder, which is hung on the wall. Inside, there is a stopwatch that counts how much the light flies back and forth, and we measure the distance.
In fact, there are more complex physical principles, but the point is that there are many laser rangefinders, which are vertically located. They scan the space, it is spinning.
Here is a picture that is obtained by a 32-ray lidar. Very cool sensor, at a distance of several meters a person can find out. Even naive approaches work, a level has found a plane - everything above this obstacle. Therefore, the lidar is very much loved, it is a key component of unmanned vehicles.
With lidar a few problems. The first - it is quite expensive. The second is that it is spinning all the time, and sooner or later it will unscrew. Their reliability leaves much to be desired. They promise lidars without moving parts and are cheaper, while others promise that they will do everything on computer vision only on cameras. Who will win - the most interesting question.
There are several sensors, each of them generates some data. There is a classic pipeline of how we train some machine learning algorithms.
We need to collect data, fill it with some kind of cloud, using the example of a car, we collect data from cars, fill it with clouds, mark it in some way, choose the best model, invent a model, tune parameters, retrain. An important caveat is that you have to put it back on the car so that it works very quickly.
Data collected in the cloud, we want to mark them.
Already today, the mentioned Toloka is my favorite Yandex service, which allows you to mark a lot of data very cheaply. You can create a GUI as a web page and distribute it to the markup. In the case of a detector of machines, it is enough for us to select them with rectangles, this is done simply and cheaply.
Then we choose some method of machine learning. For ML, there are many quick methods: SSD, Yolo, their modifications.
Then it needs to be inserted into the car. A lot of cameras, 360 degrees must be covered, it must work very quickly to react. A variety of techniques are used, Inference engines like Tensor RT, specialized hardware, Drive PX, FuseNet, several algorithms are used, a single backend, convolutions are banished once. This is a fairly common technology.
Object detection works like this:
Here, in addition to cars, we will detect more pedestrians, still detect the direction. The arrow shows the estimated direction only for the camera. Now she is crap. This is an algorithm that works on a large number of cameras in real time on the machine.
About object detection is a solved problem, many people can do it, a bunch of algorithms, a lot of competitions, a bunch of datasets. Well, not very much, but there is.
With lidars it is much more difficult, there is one more or less relevant dataset, this is KITTI dataset. It is necessary to mark from scratch.
The process of marking a cloud of points is a fairly non-trivial procedure. Ordinary people work in Toloka, and explaining to them how 3D projections work, how to find machines in the cloud is a rather trivial task. We spent some amount of effort, it seemed to be more or less able to streamline the flow of this kind of data.
How to work with it? Clouds of points, neural networks are the best in detection, so you need to understand how a cloud of points with 3D coordinates around the car is fed to the input of the network.
It all looks like you need to somehow present it. We experimented with the approach when you need to make a projection, a top view of the points, and cut into cells. If there is at least one dot in the box, then it is busy.
You can go further - to make slices vertically and, if there is at least one point in the cube vertically, write it in some characteristic. For example, recording the highest point in the cube works well. Slices are fed to the input of the neural network, it’s just an analogue of pictures, we have 14 channels to the input, we work about the same as with SSD. Another signal comes from the network, trained for detection. At the entrance of the network is a picture, this is all end-to-end training. At the exit, we predict 3D boxes, their classes and position.
Here are the results of a month ago on KITTI dataset. Then multiple view 3D was a state of the art. Our algorithm was similar in quality from the point of view of precision, but it worked several times faster, and we could plug it into a real machine. Acceleration was achieved by simplifying the presentation basically.
It is necessary again on the typewriter. Here is an example of work.
Here you have to be careful, this is a train, but it also works on the test, the green boxes are marked with cars.
Segmentation is another algorithm that can be used to understand what is located in the picture. Segmentation tells which class each pixel belongs to. Specifically, in this picture there is a road marking. The edges of the road are highlighted in green, and the cars are slightly different, purple.
Who understands the disadvantages of segmentation in terms of how to do this in motion planning feed? Everything merges. If there are parked cars nearby, then we have one large purple spot of cars, we do not know how many there are. Therefore, there is another remarkable formulation of the problem - Instance segmentation, when you still need to cut different entities into pieces. And we also do this, comrade last week in the top 5 city scapes for instance segmentation came. I wanted to take first place until it works, but there is such a task too.
We try to try as many different approaches, hypotheses as possible. Our task is not to write the best object detection in the world. This is necessary, but, first of all, there are new sensors, new approaches. The task is to try and implement them as soon as possible in real life circumstances. We are working on all that hinders us. Slowly we mark the data - we make a system that marks them with the active use of the Toloka service. The problem with the deployment of the car - we figure out how to accelerate it in a unified way.
It seems that the winner is not the one who now has a lot of experience, but the one who runs faster. And we are focused on this, we want to try everything as quickly as possible.
Here is a video that we recently showed, travel in winter conditions. This is an advertising video, but it is clearly seen here, about how unmanned vehicles drive in the current realities (since then another video has appeared - approx. Ed.). Thank.
Source: https://habr.com/ru/post/350414/
All Articles