Introduction to recommender systems
Hi, Habr!
Let's return to the topic of machine learning and neural networks that we periodically touch on. Today we will discuss the main types of recommendation systems, their advantages and disadvantages. Under the cut is an interesting article by Toby Deigle with Python code,
Above the cut is a link to the great presentation of our wonderful author Sergey Nikolenko, whose book " Deep Learning. Immersion in the World of Neural Networks ", written in collaboration with Arthur Kadurin and Ekaterina Arkhangelskaya, we simply do not have time to reprint. The presentation describes the main types of recommender systems and the principles of their work.
')
We read and comment!
What is a recommendation system?
Recommended engines are a subfamily of content filtering systems that provide the user with items that might interest him. Recommendations are selected based on preferences and user behavior. The system should predict your reaction to one or another element - and suggest others that you might also like.
How to create a recommendation system?
Although, when programming recommender systems, many methods are used, I will tell you about the three most simple ones that are used most often. It will be about collaborative filtering (collaborative filtering), content filtering (content-based filtering) and, finally, expert systems (knowledge-based systems). For each system, I will describe its weak points, potential pitfalls, and tell you how to get around them. Finally, in the final article, I will give the full implementation of the recommendation engine.
Collaborative filtering

The first of the methods considered, collaborative filtering is one of the simplest and most effective. This three-step process begins with the collection of user information. Then a matrix is built up for calculating associations and, finally, a very reliable recommendation is given. There are two main varieties of this method: based on the users involved in the search, and on the basis of the elements forming one or another category.
Custom collaborative filtering
The idea behind this method is to search for users whose tastes are similar to the preferences of our target user. If earlier Jean-Pierre and Jason put similar ratings on several films, then we believe that they have similar tastes, and we can guess the unknown ratings of Jason from the ratings of certain films made by Jean-Pierre. For example, if Jean-Pierre liked The Return of the Jedi and The Empire Strikes Back , and Jason liked the movie The Return of the Jedi , then we should definitely tell Jason and the film The Empire Strikes Back . In principle, to predict Jason's interests, you need to find several users with whom he has similar tastes.
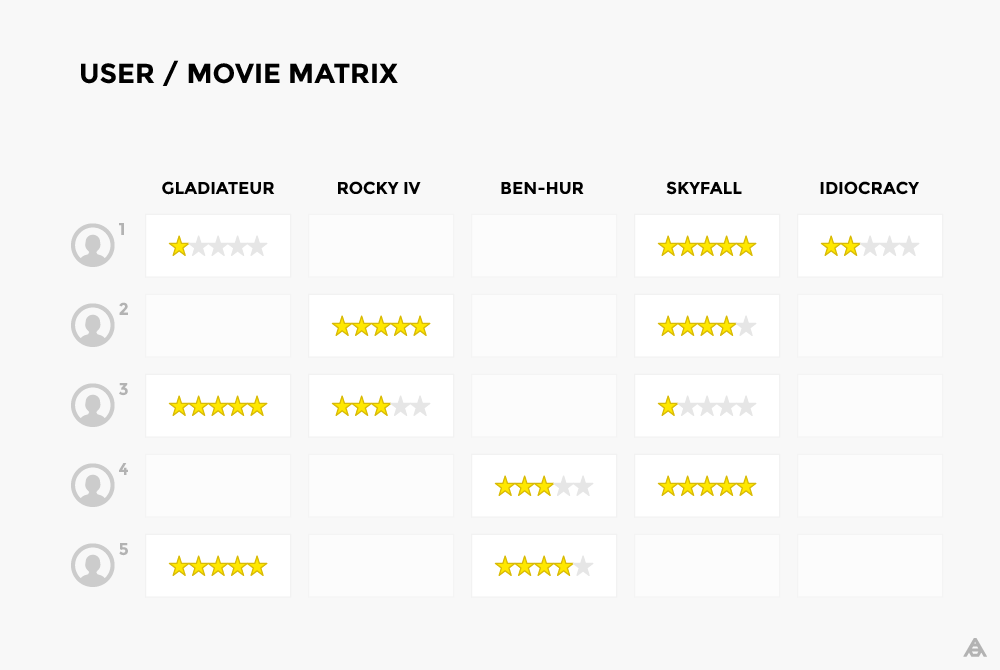
In the table, where each row corresponds to a user, and each column corresponds to a film, simply find similarities between the rows in the matrix and, accordingly, find users with common interests.
However, such an implementation poses a number of problems:
Collaborative filtering by item
The process is simple. The similarity of the two elements is calculated by the ratings issued by the user. Let us return to the example of Jean-Pierre and Jason - as we remember, both liked the films “ Return of the Jedi ” and “ The Empire Strikes Back. ” It can be concluded that the majority of users, who highly appreciated the first film, should like the second one. Thus, it would be relevant to offer the movie “The Empire Strikes Back” by Larry, who liked the movie “The Return of the Jedi ”.
Therefore, the similarity is calculated by columns, not by rows (as is clear from the matrix with the users and movies above). Often, it is preferable to collaborative filtering by elements, as it is devoid of all the disadvantages inherent in custom filtering. First, the elements in the system (here - films) do not change with time, so the recommendations will be more relevant. In addition, the elements are usually much smaller than the users, so data processing with this filtering is faster. Ultimately, such systems are much more difficult to fool.
Content recommender system

Content recommendations systems formulate recommendations based on the attributes assigned to each element. The term “content” refers specifically to these descriptions. For example, if you study the history of Sophie's musical interests, you can see that she likes the country genre. Therefore, the system can recommend her country-style compositions, as well as compositions of similar genres. More complex systems are able to identify relationships between multiple attributes and make better recommendations. So, on the Music Genome Project website , each song that is available in the database is categorized into 450 different attributes. It is on the basis of this engine that the musical recommender system works on the Pandora website.
Expert recommendation systems
Expert advisory systems are especially good for working with items that are rarely purchased — for example, homes, cars, financial assets, or expensive luxury items. In such cases, the recommendatory process is complicated due to the lack of ratings for products. In expert systems, recommendations are offered not on the basis of ratings, but on the basis of similarities between user requirements and product description, or depending on the restrictions set by the user when specifying the desired product. Therefore, a system of this type is obtained uniquely, because it allows the client to clearly indicate what he wants. As for restrictions - in cases when they are generally applied - usually such restrictions are known from the very beginning and are implemented by experts in a given subject area. For example, if the user clearly indicates that he is looking for real estate in this price category, then the system should be guided by this specification when selecting options.
The problem of cold start in recommender systems
One of the major problems associated with recommender systems is that the initial number of available ratings is usually small. What if the new user has not yet rated the films, or if a new film has been added to the system? In such cases, it is difficult to apply traditional models of collaborative filtering. Content methods and expert systems cope with the problem of cold start more confidently with collaborative models, but they are not always available. Therefore, it is for such cases that a number of alternative solutions have been developed - for example, hybrid systems.
Hybrid recommendation systems
So, all the various recommender systems discussed above have their advantages and disadvantages, and the options offered by these systems are based on different source data. Some recommendation engines, in particular, expert systems, are most effective in contexts where the amount of available data is limited. Other systems, such as collaborative filtering, work best in environments where there are large amounts of data. Often, when the data is diversified, we have enough flexibility to solve the same problem by different methods. Therefore, it is possible to combine the recommendations obtained in several ways, thereby increasing the quality of the system as a whole. Studied many combinatorial techniques, including:
One of the most well-known hybrid engines is a system that became known as a result of the Netflix Prize competition and worked from 2006 to 2009. The goal of the project was to improve the Cinematch recommendation engine from Netflix, which offered users new films, and the task was to increase the accuracy of hits by at least 10%. The Bellkor Pragmatix Chaos team won a $ 1 million award for a solution that combined 107 different algorithms; their program has increased Cinematch accuracy by 10.06%. For reference: accuracy is the degree of coincidence of the current film rating with the subsequent ratings given to it.
What about AI?
Recommender systems are often used in the context of artificial intelligence. The possibility of issuing hints, predicting events and underlining correlations are all results of the use of AI. On the other hand, when implementing recommender systems, machine learning techniques are often used. For example, Arcbees has written an effective advisory engine that works on the basis of neural networks and data taken from IMdB. Neural networks allow you to quickly solve complex problems and easily manipulate big data. Taking the list of films as input, and comparing the output with user ratings, the network can learn the rules and then follow them, predicting further ratings that a particular user can put down.
Expert Tips
Reading materials on this topic, I found two excellent tips from the experts. First, the basic material for the work of the recommendation engine should be such elements for which users are willing to pay. In this case, you can be sure that the ratings given by users will be fairly accurate and relevant. Secondly, it is always better to rely on a set of algorithms, and not on a single algorithm. A good example is the Netflix Prize.
Implementation of the recommendation system based on the selection of elements
The following code shows how quickly and easily you can implement a recommendation engine that uses collaborative filtering. The code is written in Python , the Pandas and Numpy libraries are used here - one of the most popular in this segment. Movie ratings were used as a data file, and a lot of data is available on MovieLens .
Stage 1: Find Similar Movies
Read data
Choose a movie and generate an index of similarity (correlation) between this movie and all the others.
Remove unpopular movies so that the system does not give us inappropriate recommendations
Extract popular movies that are similar to the target.
Stage 2: we offer the user recommendations depending on their ratings
We generate a similarity index in each pair of films and leave only popular ones.
We generate recommendations for each movie viewed and rated by our user (here is the data for user 0)
We summarize the performance of identical films.
We leave only those films that the user has not watched.
What's next?
In the above case, we were quite able to process a lot of MovieLens data using the Pandas library on a regular processor. However, processing larger data sets may take longer. In such cases, more powerful solutions can help - for example, Spark or MapReduce .
Let's return to the topic of machine learning and neural networks that we periodically touch on. Today we will discuss the main types of recommendation systems, their advantages and disadvantages. Under the cut is an interesting article by Toby Deigle with Python code,
Above the cut is a link to the great presentation of our wonderful author Sergey Nikolenko, whose book " Deep Learning. Immersion in the World of Neural Networks ", written in collaboration with Arthur Kadurin and Ekaterina Arkhangelskaya, we simply do not have time to reprint. The presentation describes the main types of recommender systems and the principles of their work.
')
We read and comment!
Many receive advice, but only the wise are able to use it. - Harper LeeRecommender systems seem like many magical artifacts, as if reading our thoughts. Recall at least the Netflix advisory engine, which tells us new movies, or Amazon, which offers us products that you might like. Since its inception, such tools have been improved and honed, it has become increasingly convenient to use them. But even if many of the recommendation engines are very complex systems, their fundamental structure is very straightforward.
What is a recommendation system?
Recommended engines are a subfamily of content filtering systems that provide the user with items that might interest him. Recommendations are selected based on preferences and user behavior. The system should predict your reaction to one or another element - and suggest others that you might also like.
How to create a recommendation system?
Although, when programming recommender systems, many methods are used, I will tell you about the three most simple ones that are used most often. It will be about collaborative filtering (collaborative filtering), content filtering (content-based filtering) and, finally, expert systems (knowledge-based systems). For each system, I will describe its weak points, potential pitfalls, and tell you how to get around them. Finally, in the final article, I will give the full implementation of the recommendation engine.
Collaborative filtering
The first of the methods considered, collaborative filtering is one of the simplest and most effective. This three-step process begins with the collection of user information. Then a matrix is built up for calculating associations and, finally, a very reliable recommendation is given. There are two main varieties of this method: based on the users involved in the search, and on the basis of the elements forming one or another category.
Custom collaborative filtering
The idea behind this method is to search for users whose tastes are similar to the preferences of our target user. If earlier Jean-Pierre and Jason put similar ratings on several films, then we believe that they have similar tastes, and we can guess the unknown ratings of Jason from the ratings of certain films made by Jean-Pierre. For example, if Jean-Pierre liked The Return of the Jedi and The Empire Strikes Back , and Jason liked the movie The Return of the Jedi , then we should definitely tell Jason and the film The Empire Strikes Back . In principle, to predict Jason's interests, you need to find several users with whom he has similar tastes.
In the table, where each row corresponds to a user, and each column corresponds to a film, simply find similarities between the rows in the matrix and, accordingly, find users with common interests.
However, such an implementation poses a number of problems:
- User preferences change over time. As a result, the system can generate many irrelevant recommendations;
- The greater the number of users, the longer it takes to generate a recommendation.
- User filtering is vulnerable to cheating ratings when an attacker cheats the system and biasedly improves the rating of some products in comparison with others.
Collaborative filtering by item
The process is simple. The similarity of the two elements is calculated by the ratings issued by the user. Let us return to the example of Jean-Pierre and Jason - as we remember, both liked the films “ Return of the Jedi ” and “ The Empire Strikes Back. ” It can be concluded that the majority of users, who highly appreciated the first film, should like the second one. Thus, it would be relevant to offer the movie “The Empire Strikes Back” by Larry, who liked the movie “The Return of the Jedi ”.
Therefore, the similarity is calculated by columns, not by rows (as is clear from the matrix with the users and movies above). Often, it is preferable to collaborative filtering by elements, as it is devoid of all the disadvantages inherent in custom filtering. First, the elements in the system (here - films) do not change with time, so the recommendations will be more relevant. In addition, the elements are usually much smaller than the users, so data processing with this filtering is faster. Ultimately, such systems are much more difficult to fool.
Content recommender system
Content recommendations systems formulate recommendations based on the attributes assigned to each element. The term “content” refers specifically to these descriptions. For example, if you study the history of Sophie's musical interests, you can see that she likes the country genre. Therefore, the system can recommend her country-style compositions, as well as compositions of similar genres. More complex systems are able to identify relationships between multiple attributes and make better recommendations. So, on the Music Genome Project website , each song that is available in the database is categorized into 450 different attributes. It is on the basis of this engine that the musical recommender system works on the Pandora website.
Expert recommendation systems
Expert advisory systems are especially good for working with items that are rarely purchased — for example, homes, cars, financial assets, or expensive luxury items. In such cases, the recommendatory process is complicated due to the lack of ratings for products. In expert systems, recommendations are offered not on the basis of ratings, but on the basis of similarities between user requirements and product description, or depending on the restrictions set by the user when specifying the desired product. Therefore, a system of this type is obtained uniquely, because it allows the client to clearly indicate what he wants. As for restrictions - in cases when they are generally applied - usually such restrictions are known from the very beginning and are implemented by experts in a given subject area. For example, if the user clearly indicates that he is looking for real estate in this price category, then the system should be guided by this specification when selecting options.
The problem of cold start in recommender systems
One of the major problems associated with recommender systems is that the initial number of available ratings is usually small. What if the new user has not yet rated the films, or if a new film has been added to the system? In such cases, it is difficult to apply traditional models of collaborative filtering. Content methods and expert systems cope with the problem of cold start more confidently with collaborative models, but they are not always available. Therefore, it is for such cases that a number of alternative solutions have been developed - for example, hybrid systems.
Hybrid recommendation systems
So, all the various recommender systems discussed above have their advantages and disadvantages, and the options offered by these systems are based on different source data. Some recommendation engines, in particular, expert systems, are most effective in contexts where the amount of available data is limited. Other systems, such as collaborative filtering, work best in environments where there are large amounts of data. Often, when the data is diversified, we have enough flexibility to solve the same problem by different methods. Therefore, it is possible to combine the recommendations obtained in several ways, thereby increasing the quality of the system as a whole. Studied many combinatorial techniques, including:
- Weighted: recommendations obtained by different methods are assigned different weights - that is, some recommendations are considered more preferable than others.
- Mixed: a general set of recommendations, with no clear preference for one or another class.
- Updated: recommendations from one system are used as input for the next, and so on the chain.
- Switch: random selection
One of the most well-known hybrid engines is a system that became known as a result of the Netflix Prize competition and worked from 2006 to 2009. The goal of the project was to improve the Cinematch recommendation engine from Netflix, which offered users new films, and the task was to increase the accuracy of hits by at least 10%. The Bellkor Pragmatix Chaos team won a $ 1 million award for a solution that combined 107 different algorithms; their program has increased Cinematch accuracy by 10.06%. For reference: accuracy is the degree of coincidence of the current film rating with the subsequent ratings given to it.
What about AI?
Recommender systems are often used in the context of artificial intelligence. The possibility of issuing hints, predicting events and underlining correlations are all results of the use of AI. On the other hand, when implementing recommender systems, machine learning techniques are often used. For example, Arcbees has written an effective advisory engine that works on the basis of neural networks and data taken from IMdB. Neural networks allow you to quickly solve complex problems and easily manipulate big data. Taking the list of films as input, and comparing the output with user ratings, the network can learn the rules and then follow them, predicting further ratings that a particular user can put down.
Expert Tips
Reading materials on this topic, I found two excellent tips from the experts. First, the basic material for the work of the recommendation engine should be such elements for which users are willing to pay. In this case, you can be sure that the ratings given by users will be fairly accurate and relevant. Secondly, it is always better to rely on a set of algorithms, and not on a single algorithm. A good example is the Netflix Prize.
Implementation of the recommendation system based on the selection of elements
The following code shows how quickly and easily you can implement a recommendation engine that uses collaborative filtering. The code is written in Python , the Pandas and Numpy libraries are used here - one of the most popular in this segment. Movie ratings were used as a data file, and a lot of data is available on MovieLens .
Stage 1: Find Similar Movies
Read data
import pandas as pd ratings_cols = ['user_id', 'movie_id', 'rating'] ratings = pd.read_csv('u.data', sep='\t', names=ratings_cols, usecols=range(3)) movies_cols = ['movie_id', 'title'] movies = pd.read_csv('u.item', sep='|', names=movies_cols, usecols=range(2)) ratings = pd.merge(ratings, movies) X movieRatings = ratings.pivot_table(index=['user_id'],columns=['title'],values='rating') Choose a movie and generate an index of similarity (correlation) between this movie and all the others.
starWarsRatings = movieRatings['Star Wars (1977)'] similarMovies = movieRatings.corrwith(starWarsRatings) similarMovies = similarMovies.dropna() df = pd.DataFrame(similarMovies) Remove unpopular movies so that the system does not give us inappropriate recommendations
ratingsCount = 100 movieStats = ratings.groupby('title').agg({'rating': [np.size, np.mean]}) popularMovies = movieStats['rating']['size'] >= ratingsCount movieStats[popularMovies].sort_values([('rating', 'mean')], ascending=False)[:15] Extract popular movies that are similar to the target.
df = movieStats[popularMovies].join(pd.DataFrame(similarMovies, columns=['similarity'])) df.sort_values(['similarity'], ascending=False)[:15] Stage 2: we offer the user recommendations depending on their ratings
We generate a similarity index in each pair of films and leave only popular ones.
userRatings = ratings.pivot_table(index=['user_id'],columns=['title'],values='rating') corrMatrix = userRatings.corr(method='pearson', min_periods=100) We generate recommendations for each movie viewed and rated by our user (here is the data for user 0)
myRatings = userRatings.loc[0].dropna() simCandidates = pd.Series() for i in range(0, len(myRatings.index)): # , sims = corrMatrix[myRatings.index[i]].dropna() # , sims = sims.map(lambda x: x * myRatings[i]) # simCandidates = simCandidates.append(sims) simCandidates.sort_values(inplace = True, ascending = False) We summarize the performance of identical films.
simCandidates = simCandidates.groupby(simCandidates.index).sum() simCandidates.sort_values(inplace = True, ascending = False) We leave only those films that the user has not watched.
filteredSims = simCandidates.drop(myRatings.index) What's next?
In the above case, we were quite able to process a lot of MovieLens data using the Pandas library on a regular processor. However, processing larger data sets may take longer. In such cases, more powerful solutions can help - for example, Spark or MapReduce .
Source: https://habr.com/ru/post/350346/
All Articles