Dovecot and Apache Solr integration
Good day.
Today, mail is still one of the key messaging tools in the corporate segment. The volume of stored mail only grows and eventually takes hundreds of gigabytes, or even several terabytes. At this point, users in most cases begin to experience problems during the operation of mail, for example, with search. If you use a Web client, for example, the same RoundCube, then when searching through all messages in all folders, and even by the content of the letter itself, very often the result had to wait tens of seconds, which is not very pleasant. That's why I thought it would be time to configure the FTS plugin in dovecot.
For most serious and experienced administrators, setting up a dovecot bundle - solr is not a big problem, but if this is your first time encountering this, then setting up an acceptable search result may take some time. I will try to simplify the setting for those who will face it for the first time.
So, initially we have the following initial data:
')
Now proceed to the settings.
The version of this application must be higher than 2.2.19. This is due to the fact that it fixed an error in the fts-solr plugin, which led to an incorrect formation of the request, the result was always 404. The application should also be compiled with the support of the fts and fts-solr plugin. Strange as it may sound, but when doing:
Dovecot cannot be learned to support fts and fts-solr. Regardless of the build parameters, these plugins do not appear there. In order to make sure that the plugins are there and work, let's execute the following command:
The result looks like this for me:
If your result is similar to mine, then everything is fine, you can proceed to setup.
To do this, in the /etc/dovecot/conf.d directory in the 10-mail.conf file into the mail_plugins variable at the end we add our plugins, for me it looks like this:
Then open the file 90-fts.conf and bring it to the form:
If you do not have a 90-fts.conf file, you can create it with the contents listed above. This completes the dovecot setting. Unforgettable restart dovecot. Go to Solr.
It's all pretty simple too. Therefore, immediately proceed to business.
Since Solr is written in Java, you need to install openjdk:
First, download the Apache Solr distribution; at the time of writing, the current version is 7.2.1.
Extract the installer file from the archive:
And install Solr:
As a result, the installation output will be like this:
Here you can see that Solr was successfully installed, as well as some installation data. Solr has a web interface that will be available on port 8983, there you can watch statistics, errors and some other things. Now let's set it up.
The first thing you want to do is move the data directory, since it will grow very quickly (it all depends on the amount of data that needs to be indexed) and it is desirable that there is a lot of space. I don’t have enough space in the / var directory, so we’ll fix it.
Create a directory for solr:
All data will be stored in it. Now open the file /etc/default/solr.in.sh and fix some settings in it:
Regarding the RAM to understand, Solr looks like this for me:
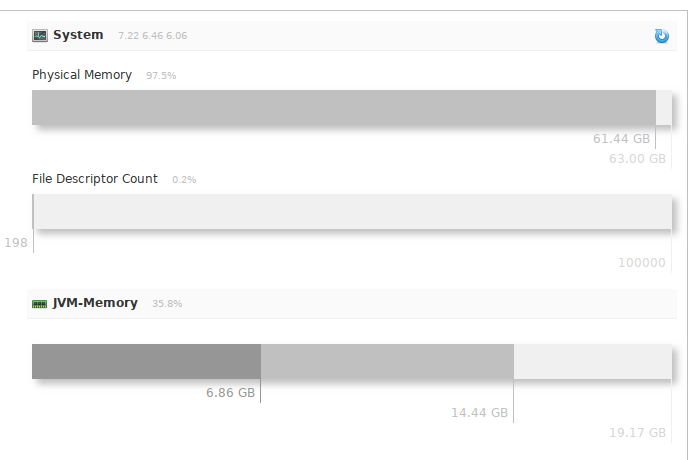
those. I was not mistaken with zeros in the settings, he eats a lot, with a large amount of data.
Also in this file you can fix and other settings, look at this file, there are many interesting things. We still have enough of this.
Copy the contents of the old directory to the new one:
And set the correct rights:
Now you can restart Solr so that he re-read the configuration file:
Go to the Solr installation directory and log in as the solr user:
You can create a scheme and configure Solr itself to work, so that it correctly receives and processes requests from dovecot:
Create the kernel:
Go to the newly created kernel directory:
This is where the basic settings for our kernel will lie. We are interested in two files:
First, let's look at schema.xml. The scheme that comes with dovecot is not acceptable to use from the word, absolutely. Therefore, I will give a more correct scheme, bring the file to this content:
The main thing that interests us is the two analyzer blocks that describe the rules of indexing and queries to Solr. I will describe the main points:
tokenizer class Describes how Solr will break a sentence into words. This scheme uses the solr.ClassicTokenizerFactory , according to the documentation, it offers:
“Please, email john.doe@foo.com by 03-09, re: m37-xq.”
Understand the words as follows:
“Please”, “email”, “john.doe@foo.com”, “by”, “03-09”, “re”, “m37-xq”.
I am more than happy with this, but not everyone is happy with it, so you can choose your own class which will be more optimal for your system. See the link that I gave above.
filter class Describes the processing of words that come out of tokenizer output. There may be specified various parameters about which you can read the link that I gave. I will describe the main ones:
solr.EdgeNGramFilterFactory - forms tokens from a word according to its parameters minGramSize and maxGramSize. I have 1 and 40, which means that the following tokens will be formed from the word "Domains": "d", "before", "house", "house", "domain", "domains". Such tokens will be created up to 40 characters in size. There is a small nuance, if a word is longer than 40 characters, for example 50, then if the user enters a search query with a size of> 40 and <50, then the result will be zero. Therefore, I entered such a large number, since I have not met email longer than 40 characters, and in Russian in general, the longest word is 25 characters.
solr.LowerCaseFilterFactory - lists all words in lower case, adds that the search would be independent of the register of entered characters.
solr.StopFilterFactory - tells Solr which words should not be indexed at all and simply ignored, write the words to a file and specify using the words parameter.
solr.EnglishMinimalStemFilterFactory - filter for handling plural English words, dogs will be converted to dog, etc.
solr.EnglishPossessiveFilterFactory - also for processing English words, removes possessive and not only endings, Man's is converted to Man.
solr.KeywordMarkerFilterFactory - language parameter, described here in more detail. If I understood correctly, some kind of word exceptions that solr indexes without preliminary modifications, so to say "as is".
These parameters can be used both in the index analyzer and in the query analyzer. Naturally, these analyzers may have different parameters and they do not affect each other. On this with the scheme you can finish.
Go to solrconfig.xml. There is a moment from the 7th Solr version by default, the json format is used for communication, but the dovecot plugin uses xml. Therefore, we need to find several parameters in the file and correct them (this does not apply to Solr 6)
In the block (~ 745 line):
Block "defaults" we bring to the form:
In the block (~ 810 line):
Block "defaults" we bring to the form:
Now you need to remove (you can just comment out) the block (Concerns 6 and 7 versions of Solr)
and add a block (around 1190 lines)
before block:
This completes the Solr setting; you can proceed to indexing. Do not forget that after any changes to the configuration file, you must restart Solr.
In order to index the user mailboxes, dovecot has several commands.
If you have a doveadm that swears that it cannot find users or something similar, check if you have an iterate_query parameter. Without this parameter, there may be problems finding users and their mailboxes. My users are in the database and this parameter looks like this for me:
It lies in the file where the requests to the database of users and passwords are described.
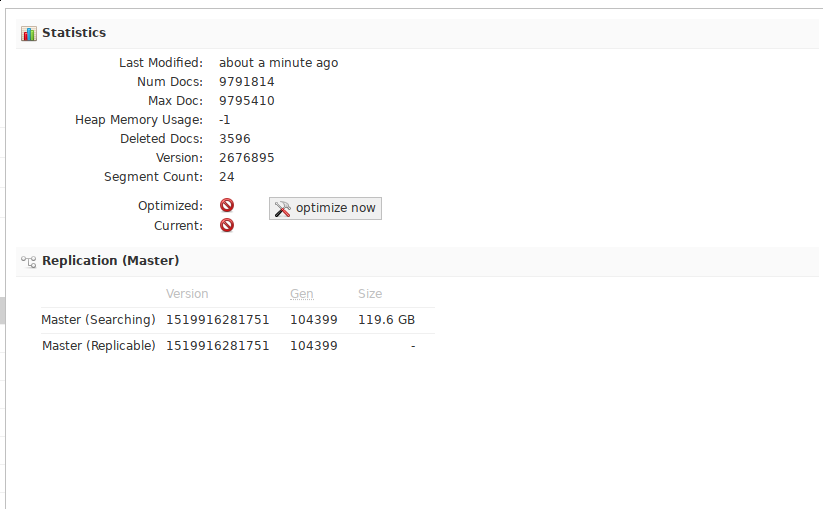
The Solr statistics for the dovecot kernel now look like this for me:
A bit of optimization, I added the following parameters to cron:
You can also add to the base optimization.
After a full indexation of the mailbox and the speed of processing search queries has grown many times, if before a complex query took tens of seconds, it is now less than a second. Unfortunately, there are no old tests left, but I think that I can take my word for it, or check it personally using this instruction.
Not without flaws, if you change the indexing parameters, then you have to index all mail from scratch. And it takes a lot of time, in my volume and with my iron characteristics about 3 days. But once setting everything will work as it should.
If you have forgotten something or misled, do not blame me for writing most of the memory, since everything is already set up and working.
Today, mail is still one of the key messaging tools in the corporate segment. The volume of stored mail only grows and eventually takes hundreds of gigabytes, or even several terabytes. At this point, users in most cases begin to experience problems during the operation of mail, for example, with search. If you use a Web client, for example, the same RoundCube, then when searching through all messages in all folders, and even by the content of the letter itself, very often the result had to wait tens of seconds, which is not very pleasant. That's why I thought it would be time to configure the FTS plugin in dovecot.
For most serious and experienced administrators, setting up a dovecot bundle - solr is not a big problem, but if this is your first time encountering this, then setting up an acceptable search result may take some time. I will try to simplify the setting for those who will face it for the first time.
So, initially we have the following initial data:
')
- CentOS 6 - for the solution of our problem, the distribution kit is generally not important, but I will do it by example
- Dovecot 2.2.32 - it is important for us that the version be 2.2.19 and higher.
- Apache Solr 7 - there can be either version 6 or 7 here.
Now proceed to the settings.
Dovecot
The version of this application must be higher than 2.2.19. This is due to the fact that it fixed an error in the fts-solr plugin, which led to an incorrect formation of the request, the result was always 404. The application should also be compiled with the support of the fts and fts-solr plugin. Strange as it may sound, but when doing:
dovecot --build-options Dovecot cannot be learned to support fts and fts-solr. Regardless of the build parameters, these plugins do not appear there. In order to make sure that the plugins are there and work, let's execute the following command:
ls /usr/lib64/dovecot/ | grep -E "solr|fts" The result looks like this for me:
lib20_fts_plugin.so lib21_fts_solr_plugin.so lib21_fts_squat_plugin.so libdovecot-fts.so.0 libdovecot-fts.so.0.0.0 If your result is similar to mine, then everything is fine, you can proceed to setup.
To do this, in the /etc/dovecot/conf.d directory in the 10-mail.conf file into the mail_plugins variable at the end we add our plugins, for me it looks like this:
mail_plugins = quota acl expire mail_log notify fts fts_solr Then open the file 90-fts.conf and bring it to the form:
plugin { fts = solr fts_solr = url=http://127.0.0.1:8983/solr/dovecot/ # ! fts_autoindex = yes } If you do not have a 90-fts.conf file, you can create it with the contents listed above. This completes the dovecot setting. Unforgettable restart dovecot. Go to Solr.
Apache sorl
It's all pretty simple too. Therefore, immediately proceed to business.
Since Solr is written in Java, you need to install openjdk:
yum install java-1.8.0-openjdk lsof First, download the Apache Solr distribution; at the time of writing, the current version is 7.2.1.
wget http://apache-mirror.rbc.ru/pub/apache/lucene/solr/7.2.1/solr-7.2.1.tgz -O /usr/src/solr-7.2.1.tgz Extract the installer file from the archive:
tar zxf solr-7.2.1.tgz solr-7.2.1/bin/install_solr_service.sh And install Solr:
./solr-7.2.1/bin/install_solr_service.sh solr-7.2.1.tgz As a result, the installation output will be like this:
We recommend installing the 'lsof' command for more stable start/stop of Solr id: solr: no such user Creating new user: solr Extracting solr-7.2.1.tgz to /opt Installing symlink /opt/solr -> /opt/solr-7.2.1 ... Installing /etc/init.d/solr script ... Installing /etc/default/solr.in.sh ... Service solr installed. Customize Solr startup configuration in /etc/default/solr.in.sh NOTE: Please install lsof as this script needs it to determine if Solr is listening on port 8983. Started Solr server on port 8983 (pid=1647). Happy searching! Found 1 Solr nodes: Solr process 1647 running on port 8983 { "solr_home":"/var/solr/data", "version":"7.2.1 b2b6438b37073bee1fca40374e85bf91aa457c0b - ubuntu - 2018-01-10 00:54:21", "startTime":"2018-03-01T11:22:40.462Z", "uptime":"0 days, 0 hours, 0 minutes, 15 seconds", "memory":"25.6 MB (%5.2) of 490.7 MB"} Here you can see that Solr was successfully installed, as well as some installation data. Solr has a web interface that will be available on port 8983, there you can watch statistics, errors and some other things. Now let's set it up.
The first thing you want to do is move the data directory, since it will grow very quickly (it all depends on the amount of data that needs to be indexed) and it is desirable that there is a lot of space. I don’t have enough space in the / var directory, so we’ll fix it.
Create a directory for solr:
mkdir -p /srv/solr/data All data will be stored in it. Now open the file /etc/default/solr.in.sh and fix some settings in it:
SOLR_JAVA_MEM="-Xms10240m -Xmx20480m" # Solr SOLR_HOME="/srv/solr/data" # Solr Regarding the RAM to understand, Solr looks like this for me:
those. I was not mistaken with zeros in the settings, he eats a lot, with a large amount of data.
Also in this file you can fix and other settings, look at this file, there are many interesting things. We still have enough of this.
Copy the contents of the old directory to the new one:
cp /var/solr/data/* /srv/solr/data/ And set the correct rights:
chown -R solr:solr /srv/solr Now you can restart Solr so that he re-read the configuration file:
service solr restart Go to the Solr installation directory and log in as the solr user:
cd /opt/solr/bin su solr You can create a scheme and configure Solr itself to work, so that it correctly receives and processes requests from dovecot:
Create the kernel:
./solr create_core -c dovecot -n dovecot Go to the newly created kernel directory:
cd /srv/solr/data/dovecot/conf This is where the basic settings for our kernel will lie. We are interested in two files:
- schema.xml - the main configuration file for indexing rules and queries to Solr
- solrconfig.xml - the configuration file of the kernel itself.
First, let's look at schema.xml. The scheme that comes with dovecot is not acceptable to use from the word, absolutely. Therefore, I will give a more correct scheme, bring the file to this content:
<?xml version="1.0" encoding="UTF-8" ?> <!-- For fts-solr: This is the Solr schema file, place it into solr/conf/schema.xml. You may want to modify the tokenizers and filters. --> <schema name="dovecot" version="1.5"> <types> <!-- IMAP has 32bit unsigned ints but java ints are signed, so use longs --> <fieldType name="string" class="solr.StrField" /> <fieldType name="long" class="solr.TrieLongField" /> <fieldType name="boolean" class="solr.BoolField" /> <fieldType name="text" class="solr.TextField" positionIncrementGap="100"> <analyzer type="index"> <tokenizer class="solr.ClassicTokenizerFactory"/> <filter class="solr.StopFilterFactory" ignoreCase="true" words="lang/stopwords_ru.txt"/> <filter class="solr.EdgeNGramFilterFactory" minGramSize="1" maxGramSize="40"/> <filter class="solr.LowerCaseFilterFactory"/> <filter class="solr.EnglishPossessiveFilterFactory"/> <filter class="solr.KeywordMarkerFilterFactory" protected="protwords.txt"/> <filter class="solr.EnglishMinimalStemFilterFactory"/> </analyzer> <analyzer type="query"> <tokenizer class="solr.ClassicTokenizerFactory"/> <filter class="solr.SynonymFilterFactory" synonyms="synonyms.txt" ignoreCase="true" expand="true"/> <filter class="solr.StopFilterFactory" ignoreCase="true" words="lang/stopwords_en.txt"/> <filter class="solr.LowerCaseFilterFactory"/> <filter class="solr.EnglishPossessiveFilterFactory"/> <filter class="solr.KeywordMarkerFilterFactory" protected="protwords.txt"/> <filter class="solr.EnglishMinimalStemFilterFactory"/> </analyzer> </fieldType> </types> <fields> <field name="id" type="string" indexed="true" stored="true" required="true" /> <field name="uid" type="long" indexed="true" stored="true" required="true" /> <field name="box" type="string" indexed="true" stored="true" required="true" /> <field name="user" type="string" indexed="true" stored="true" required="true" /> <field name="hdr" type="text" indexed="true" stored="false" /> <field name="body" type="text" indexed="true" stored="false" /> <field name="from" type="text" indexed="true" stored="false" /> <field name="to" type="text" indexed="true" stored="false" /> <field name="cc" type="text" indexed="true" stored="false" /> <field name="bcc" type="text" indexed="true" stored="false" /> <field name="subject" type="text" indexed="true" stored="false" /> <!-- Used by Solr internally: --> <field name="_version_" type="long" indexed="true" stored="true"/> </fields> <uniqueKey>id</uniqueKey> </schema> The main thing that interests us is the two analyzer blocks that describe the rules of indexing and queries to Solr. I will describe the main points:
tokenizer class Describes how Solr will break a sentence into words. This scheme uses the solr.ClassicTokenizerFactory , according to the documentation, it offers:
“Please, email john.doe@foo.com by 03-09, re: m37-xq.”
Understand the words as follows:
“Please”, “email”, “john.doe@foo.com”, “by”, “03-09”, “re”, “m37-xq”.
I am more than happy with this, but not everyone is happy with it, so you can choose your own class which will be more optimal for your system. See the link that I gave above.
filter class Describes the processing of words that come out of tokenizer output. There may be specified various parameters about which you can read the link that I gave. I will describe the main ones:
solr.EdgeNGramFilterFactory - forms tokens from a word according to its parameters minGramSize and maxGramSize. I have 1 and 40, which means that the following tokens will be formed from the word "Domains": "d", "before", "house", "house", "domain", "domains". Such tokens will be created up to 40 characters in size. There is a small nuance, if a word is longer than 40 characters, for example 50, then if the user enters a search query with a size of> 40 and <50, then the result will be zero. Therefore, I entered such a large number, since I have not met email longer than 40 characters, and in Russian in general, the longest word is 25 characters.
solr.LowerCaseFilterFactory - lists all words in lower case, adds that the search would be independent of the register of entered characters.
solr.StopFilterFactory - tells Solr which words should not be indexed at all and simply ignored, write the words to a file and specify using the words parameter.
solr.EnglishMinimalStemFilterFactory - filter for handling plural English words, dogs will be converted to dog, etc.
solr.EnglishPossessiveFilterFactory - also for processing English words, removes possessive and not only endings, Man's is converted to Man.
solr.KeywordMarkerFilterFactory - language parameter, described here in more detail. If I understood correctly, some kind of word exceptions that solr indexes without preliminary modifications, so to say "as is".
These parameters can be used both in the index analyzer and in the query analyzer. Naturally, these analyzers may have different parameters and they do not affect each other. On this with the scheme you can finish.
Go to solrconfig.xml. There is a moment from the 7th Solr version by default, the json format is used for communication, but the dovecot plugin uses xml. Therefore, we need to find several parameters in the file and correct them (this does not apply to Solr 6)
In the block (~ 745 line):
<requestHandler name="/select" class="solr.SearchHandler"> Block "defaults" we bring to the form:
<lst name="defaults"> <str name="echoParams">explicit</str> <int name="rows">10</int> <str name="wt">xml</str> <!-- <str name="df">text</str> --> </lst> In the block (~ 810 line):
<requestHandler name="/query" class="solr.SearchHandler"> Block "defaults" we bring to the form:
<lst name="defaults"> <str name="echoParams">explicit</str> <str name="wt">xml</str> <str name="indent">true</str> </lst> Now you need to remove (you can just comment out) the block (Concerns 6 and 7 versions of Solr)
<processor class="solr.AddSchemaFieldsUpdateProcessorFactory"> and add a block (around 1190 lines)
<schemaFactory class="ClassicIndexSchemaFactory"></schemaFactory> before block:
<updateRequestProcessorChain name="add-unknown-fields-to-the-schema"> This completes the Solr setting; you can proceed to indexing. Do not forget that after any changes to the configuration file, you must restart Solr.
In order to index the user mailboxes, dovecot has several commands.
# , doveadm fts rescan -u s.chistiakov@example.com # doveadm -vvvvv index -u s.chistiakov@exmample.com "*" # . doveadm -v index -A "*" If you have a doveadm that swears that it cannot find users or something similar, check if you have an iterate_query parameter. Without this parameter, there may be problems finding users and their mailboxes. My users are in the database and this parameter looks like this for me:
iterate_query = SELECT username as user FROM mailbox It lies in the file where the requests to the database of users and passwords are described.
The Solr statistics for the dovecot kernel now look like this for me:
A bit of optimization, I added the following parameters to cron:
0 6 * * * /usr/bin/doveadm -v index -A "*" 5 */1 * * * curl "http://127.0.0.1:8983/solr/dovecot/update?commit=true" You can also add to the base optimization.
0 22 * * * curl "http://127.0.0.1:8983/solr/dovecot/update?optimize=true" Total
After a full indexation of the mailbox and the speed of processing search queries has grown many times, if before a complex query took tens of seconds, it is now less than a second. Unfortunately, there are no old tests left, but I think that I can take my word for it, or check it personally using this instruction.
Not without flaws, if you change the indexing parameters, then you have to index all mail from scratch. And it takes a lot of time, in my volume and with my iron characteristics about 3 days. But once setting everything will work as it should.
If you have forgotten something or misled, do not blame me for writing most of the memory, since everything is already set up and working.
Source: https://habr.com/ru/post/350256/
All Articles