Rich Text Editor development: problems and solutions
Text editors, as a type of software, appeared a little later than dinosaurs, and most likely it was generally the first software that you encountered in your life, perhaps someone even caught up with MS-DOS Editor.
However, with the transition of a large part of the software into browsers, the corresponding visual editors Rich Text Editors are relevant, and there are a lot of problem areas in their development. If for some reason you decide to make your own editor, then think again - there is an opinion that this is not necessary.

')
So that you could make a more balanced decision, Yegor Yakovishen summed up all his experience gained in the process of creating Setka Editor , and told about the problems that he would have to face and what can be done to solve them.
Disclaimer: The article is written on the basis of a report by Egor at the Frontend Conf 2017 conference in June 2017. The situation with browser support for certain APIs could have changed since then.

Setka, a company in which I work, develops tools for streamlining processes in content marketing teams, online media editorial offices, and content brands that launch their publications. One of our products is the cool visual editor Setka Editor, which allows you to create user-engaging content really quickly and without losing quality. Here are a number of editor features:
The editor can be used in WordPress (we have released a special plugin for this), as well as integrated into any other CMS.
Setka was born within the walls of Look At Media publishing house, which brings together popular publications The Village, Furfur, Wonderzine and others. You can read more about the background and development history of Setka Editor in an article from the Setka corporate blog . Below is an example of the layout of the post, which is made in our editor.

It can be both daily news, and longrida, and special projects.
Posts created in Setka Editor only on our publications monthly generate more than 20 million views per month - just so that you understand the scale of the tasks that we have to face.
So let's go!
Text editors, as a type of software, appeared a long time ago. Probably, for many, it was generally the first software they encountered in their lives. Someone may have found the MS-DOS Editor:

Obviously, everyone saw Notepad in its different versions:
Microsoft Word has also gone through many versions:

In addition, there are specialized programs, for example, Adobe InDesign , for really complex magazine layouts:
But this is all classic software that works in the operating system as desktop software.
Meanwhile, in the browser, the situation is different. First, we have the usual textarea. This is a field where you can write text, it works absolutely everywhere - great cross-browser compatibility! But there is a problem: no stylization, and even more complicated layout in this textarea will never be done, because this is just a plain text input field. It is only slightly more complex than text input.
There are many products that call themselves Rich Text Editor. You have probably come across them many times on different sites. Here are some classic representatives.
Tinmyce
CKEditor

Froala editor
And dozens of other projects of different levels of development, most of which have so-called “generic problems”.
WYSIWYG
In almost all editors, the key principle of WYSIWYG (What You See) is not observed. This means that the layout you see in the editor will not necessarily coincide with what visitors see on your site. In the editor you work with a small window of a fixed size, and on the pages of the site everything turns out to be completely different, since there is a specific site template with its own styles, another width of the content area, additional blocks, etc. And if the user enters the site from a mobile device, completely different rules are already applied there.
Very few or too many functions.
Functions in such editors, as a rule, are either very few (bold, italic, text alignment), or too many - 5 lines of buttons that cannot be understood.
It is difficult to "make friends" with an existing site design.
The design has already been approved by the art director, the site is up and running. And now you need to somehow make your editor friends with this design so that you can make a beautiful layout in it, but within the framework of the company's corporate identity. This can be quite a challenge.
Cross-browser compatibility
Many editors have problems with cross-browser compatibility, both with their interface and with the layout they generate. This is especially true of old IE and Safari, but at times Firefox sometimes surprises.
General purpose tools
In most cases, Rich Text Editor is simply a tool for translating visual blocks into HTML and CSS code created for people who for various reasons do not want or cannot write code manually. If you need a more advanced tool for solving your problems, then often WYSIWYG editors from helpers turn into obstacles.
There are also a lot of other problems, for example:
And so on. There are really a lot of problems and questions.
So, the moment X came, and for some reason you decided to make your own editor.
Nice try, but don't do it!
The Internet is just full of posts, where it says that you should not do this. Most likely, a lot of restrictions will prevent you from making a really good product.
In particular, this is a screenshot from StackOverflow , in which one of the developers of CKEditor (one of the old and famous editors) writes that they have been doing it for 10 years, they still have thousands of issues and, unfortunately, they cannot get a good result - not because they are bad developers, but because they are bad browsers.
Nevertheless, you still rejected all doubts and want to make your editor. What are the key questions you face? It will be necessary to understand:
We will talk about this today. Let's start in order.
Historically, browsers for this provide the following features.
Designmode
The document object has such a property, it exists for a very long time - probably, in the late 90s it was implemented in the first versions of Internet Explorer.
When this property is switched to the on mode, then absolutely the whole page, the entire contents of the body becomes editable. You can place the cursor anywhere and edit the text.
If you google, you can see the enthusiastic comments 10-15 years ago on forums like Antimat, how cool you can edit any page, for example, Microsoft, Google and so on.
This way is imperfect. Its main problem is that, more often than not, it’s not necessary to edit the whole page, but only a specific block. Probably the only case when the designMode is applicable is when the editable area is in an iframe, and you really want to make this block entirely editable. But these situations are not very many.
Contenteditable
This is the main browser API for creating editable blocks. When this attribute is switched to true, everything inside the block becomes editable. In this way, most visual editors are now done, and ours is no exception.
The problem is that each browser implements user actions in this block differently. The simplest example: there is a block with the text “Hello, world”, turn on contenteditable = ”true”, it becomes editable. Next, put the cursor after the comma after the word "Hello" and press the Enter button.
After that, a new <div> inside the block will appear in Chrome and Safari, there is an unbreakable space and the remaining word "world".
And in Firefox - line break <br>.
Thus, you have no control over the situation, because each browser acts differently.
Document.execCommand
This is a special method that allows browser commands to be applied to a selected part of the text. There are a fixed number of such commands, for example, bold, fontSize, formatText, and so on.
Js
HTML
This API also exists a long time ago and it is extremely unstable. Suppose, in the same example, you selected the word “Hello” and executed the execCommand ('bold') command. The text turned into a <b> tag. What potential problems could there be? First, maybe I want not <b>, but <strong> (I was advised by SEOs). Or, maybe, I want to add another class to this <b> tag and I will have to do an additional action.
Okay, <b> is still not so scary, and if I want, say, to make the font a big headline? I run the browser fontSize command, pass the value 7. And what? Inserted tag <font>, which we have not seen on sites since the beginning of the 2000s, with the 7th size. Yes, visually, this is similar to what was required, but in terms of code, semantics, SEO, and subsequent support, this is a nightmare.
As a result, if you use only standard API, then the editor is incomplete. You cannot use semantic tags and apply correct styles, you do not know how to parse it later and how it will affect SEO.
There is a textbook article “ Why ContentEditable is Terrible ”, in which developers describe why contenteditable is bad, and what to do about it.
To avoid these problems, you can make your editor using canvas. Such examples exist, but, in fact, you have to completely reinvent the entire rendering of the text, cursor, selection, etc.
We will now see that in fact a lot of this has to be done. But in the case of Canvas, you work with the text area in fact as with a picture. It is too complicated and most likely you will get so many problems that all this work will become ungrateful.
The second method, which is most often used in practice in almost all modern editors (and in particular, in our country), is a bunch of contenteditable areas and document state storage based on the actions that take place in this area.
Let's say you have a contenteditable area. In its classic use, you put the cursor, write text, and the content changes, and, as we said, it changes unpredictably. In this case, when you write something to input, the state first changes as necessary, and then the input is redefined based on the state change. In essence, this is an approach called React Controlled Input in React. This, in turn, can cause performance problems with fast typing. Then you need to use a hybrid version: input text characters immediately display in the DOM, and more complex actions to process first yourself.
Suppose you put the cursor in a text field and press Enter. The editor understands that it is necessary to insert a line break, or if at this moment you have not selected the text, but the object, then you need to perform some other action. Thus, you can control absolutely everything: what happens in your editor: perform the necessary actions, cancel unnecessary, etc.
General scheme:
The state can store:
Thus, all this can be stored in the state, and work with the editor as an application that changes this state. For example, here is the editor of Draft.js from Facebook, made at React:
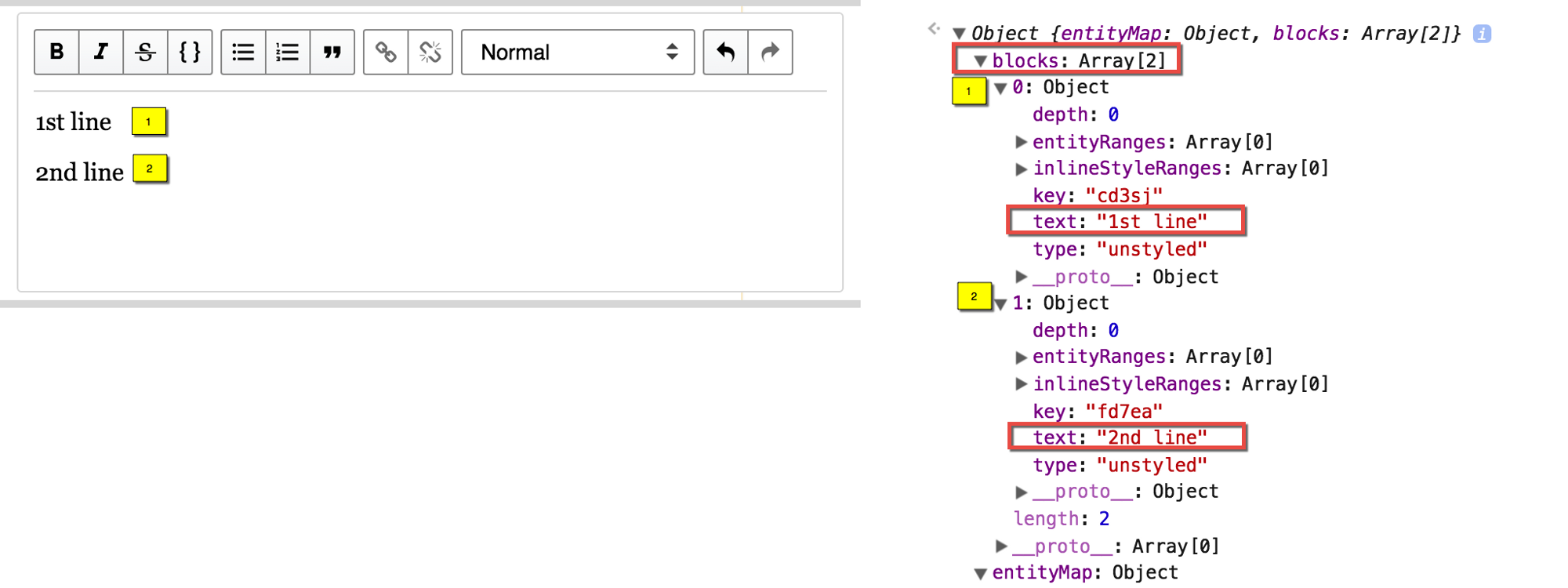
The screenshot shows how they store the state of their editor. The text consists of two lines, and on the right they are presented as a JS object. They have text attributes, each has its own unique key key, they can be styled or not, etc.
But the farthest in this issue went Google Docs with its kix engine. They had a completely non-standard task: not just developing an editor, but also implementing simultaneous multi-user work. This means synchronization of changes, multiple cursors, and all other complex things that generally lie outside the editor’s design issues.
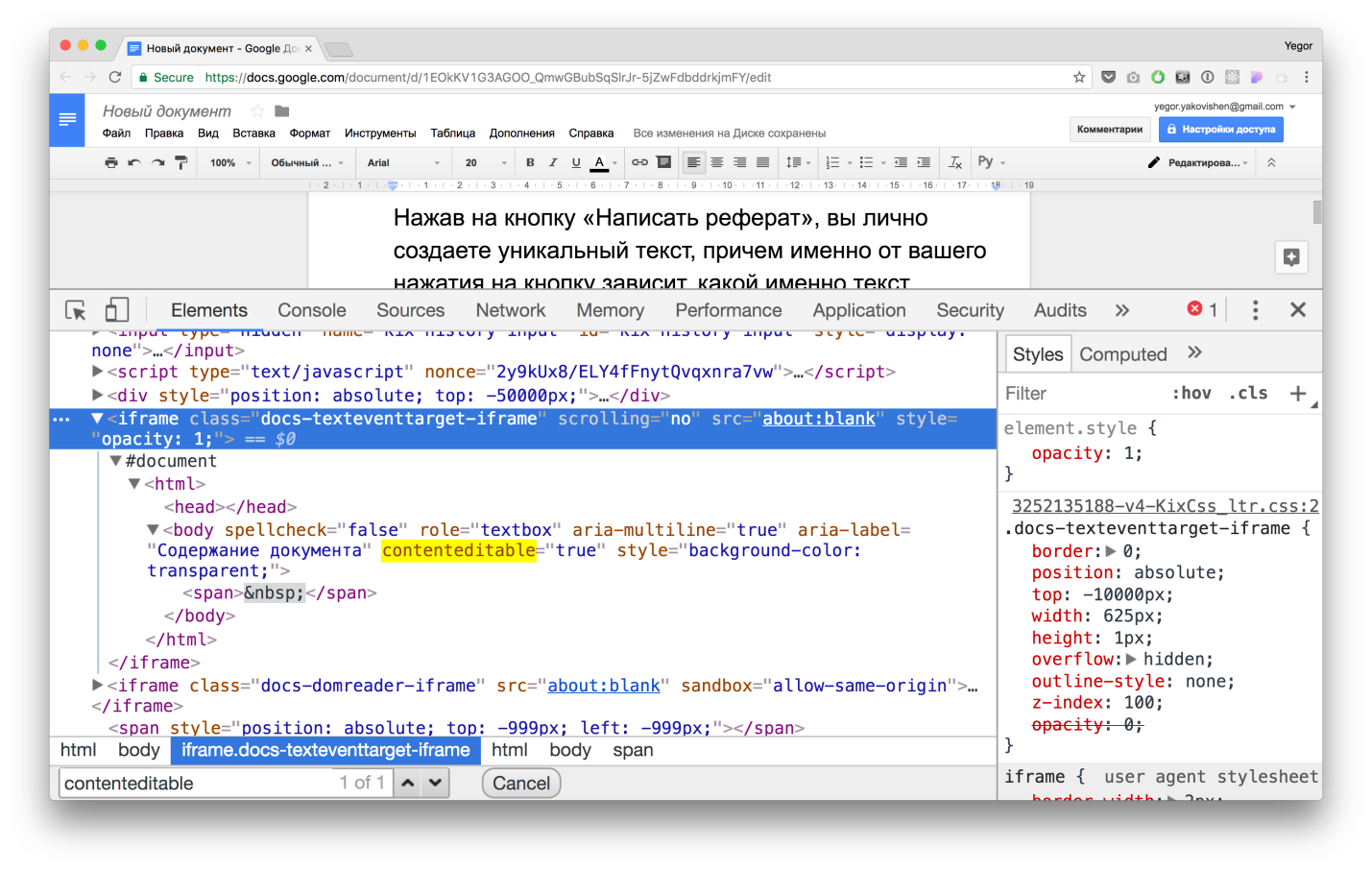
To do this, they track all the events that occur on the page, in a special Iframe, which is generally far, far away from the screen. The screenshot shows that this iframe has a top coordinate of –10000px, and a height of only 1px. It is used only to intercept events that occur on the page. As you can see, this iframe doesn't even have content, only an empty container with contenteditable = "true" . That is, it is exclusively a service tool.
To solve all the tasks, the developers of Google Docs, had, in fact, to reinvent the entire system of text rendering in the editor.
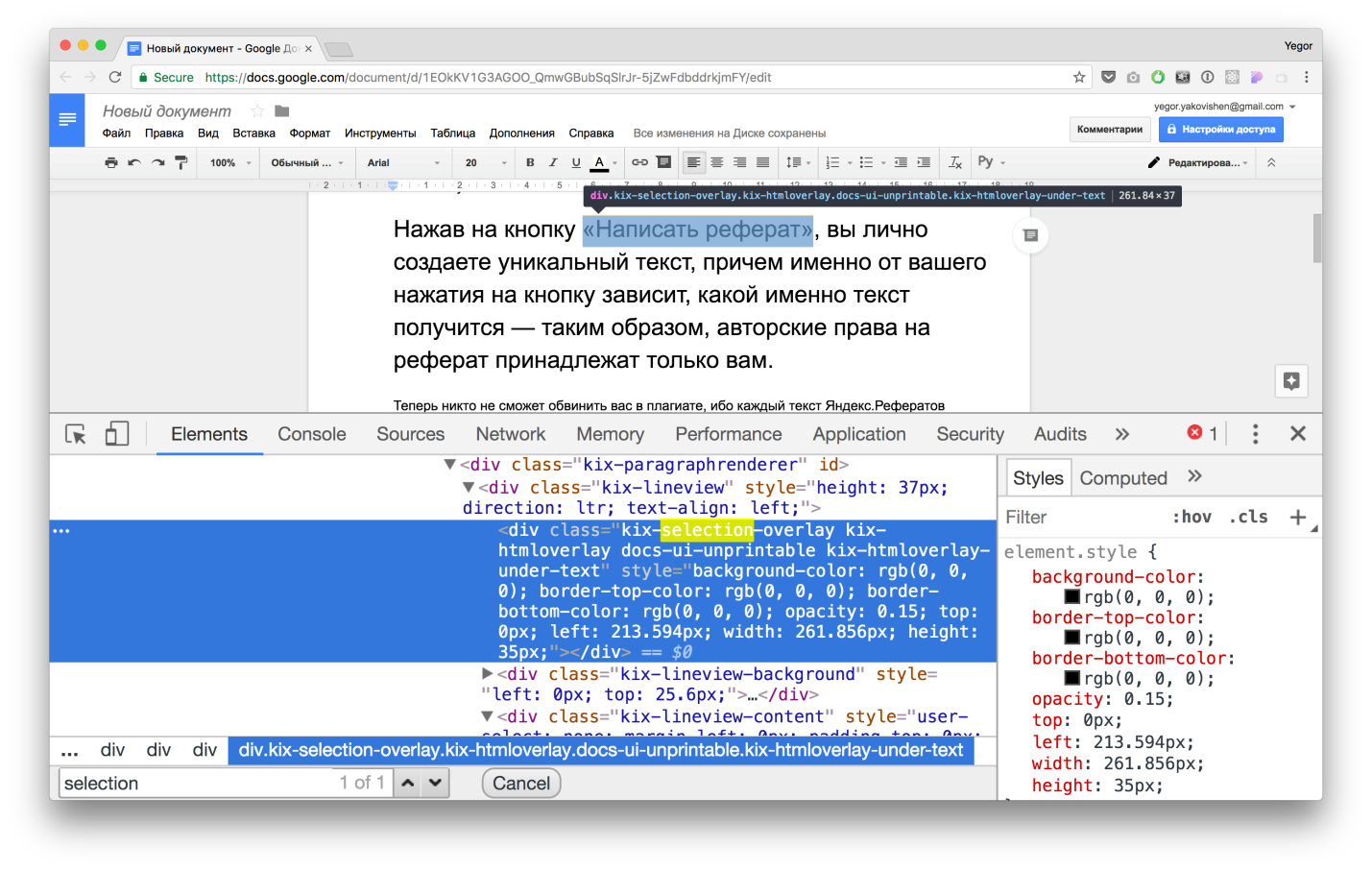
The screenshot above shows the selection of the text, and you can see that this is not a standard selection of the operating system, but also a special div called kix-selection-overlay. It has background-color, opacity, size and coordinates. That is, this is a special DOM wrapper around the content, which is a selection.

Moreover, they even have a cursor - it’s a 1-2px wide div, line-tall, with certain CSS properties applied to it, which allow it to flash for half a second. Thus, there can be 5 cursors on a page at a time, if it is edited by 5 people.
Here we turn to the question of how to store the state of the content in the state. Traditionally, the content that is displayed on web pages is stored as HTML.
This has its advantages:
But there are also disadvantages:
Anyway, most likely you will need your own convenient format for storing the contents of the document.
Decomposition on entities
First, you need to decompose into entities what you are working with in the editor. Most likely, you will have classic elements of any text:
In the code editor there will be your entities, in the graphic editor - others. You need to understand what content you are working with.
Data structure
Further, these entities should be presented in the form of a structure with types and attributes, with which you can then work. Here is an abstract example of the structure of a text element:
In this example, you can see that there is a Paragraph element, it has a certain content, and its first 4 letters are formatted in bold format. Such a structure can be rendered in any kind of representation, for example:
Importantly, such a structure can be displayed in the editor in one way (for example, with additional editing elements, buttons, etc.), and from the outside - in a completely different way. Thus, you again become a full-fledged master of what is happening with your content.
You can ask the expected question: “Listen, my content is stored in HTML for many years, I have my own CMS. Do you propose to forget everything, invent your own format and then rewrite all the code to work with it? Obviously, I do not want to do this, because the benefits from a business point of view are incomprehensible "
We had the same problem when we implemented the editor on our sites, where there was a large proportion of legacy code and thousands of post posts.
We are doing exactly that now. Our editor works on a variety of platforms, and we do not have the right to impose our data storage format. We need to work with what is.
Your editor is not required to support absolutely all of these input methods. Most likely, few people will enter long texts in a voice so far, but, nevertheless, possible options should be taken into account.
The browser for this offers a whole "zoo" of various APIs, because contenteditable-areas, unfortunately, do not have a single change event to which you can subscribe and know exactly when changes occur. There are several key APIs with which you can work somehow. Although I will emphasize, in almost every post about the creation of visual editors - and my story is no exception - it is emphasized that the situation with the browser-based API is bad.
Selection API allows you to work with the selection of text on the page.
Contains 2 useful events: selectstart and selectionchange . Selectstart is triggered when we start to select a region of text on a page, and the selectionchange is triggered every time the selection changes. Moreover, what is useful, it works not only when the selection changes with the cursor, but also when we press the Shift + arrows or Ctrl-A to select all the content on the page.
Window.getSelection () - using this method, you can get an object with information about the current selection of text on the page. This object contains useful properties, such as anchorNode and focusNode. AnchorNode is the node on which the selection began, and focusNode is the node on which the selection ended. Each of these nodes can have its own offset, i.e. number of selected characters in this node.
As an example, consider the screenshot of the FrontendConf website page. I highlighted the text, starting with the word “design” and ending with the phrase “mobile sites,” considered the current selection and looked at what exactly was highlighted. You can see that anchorNode and focusNode are both text nodes, anchorOffset = 11 (the word “design” starts at the 11th position), and focusOffset = 15. In this way we can understand which text on the page is currently highlighted.

Selection API is fairly well maintained and fairly stable.

The next API is clipboard, Clipboard API . There are much more problems with him, there are some stars and comments everywhere.

The Clipboard API offers several events that you can subscribe to: copying content (copy), cutting (paste), pasting (paste), and what happens right before this: beforecopy, beforecut, beforepaste.
Some of them can be self-invoked using execCommand, but for security reasons, many actions with the clipboard are blocked.
For example, if the user himself initiated copying, pressed <Ctrl-C> or <Edit-Copy>, a copy event occurs, and at this point the developer can intervene and perform certain actions:
But it is impossible to initiate an operation with the clipboard if the user does not want this.
The reasons for this are clear: suppose a person on the clipboard has a password or credit card number. If a browser application could independently read this data and send it somewhere, then there would be no security. Therefore, if the user himself does not initiate an event, we cannot in any way call it ourselves.
Clipboard API support is good, but there are certain limitations. Suppose you want in your editor to copy not just text, but some complex object. But the copy event will not occur if the page does not have selected text. To do this, you can use the algorithm of the company Trello, which they openly write on Stack Overflow . For a user, this works like this: you move the cursor over some card in the board, press Ctrl-C, then move the cursor to another place, press Ctrl-V, and this card is inserted into the right place.

Implemented as follows:
When the user then moves the cursor to another location and clicks "Paste", the insert event is intercepted, and with the help of JS the card is inserted into the list that the cursor is hovering over.
At home we copied complex objects in a similar way.
Composition Events
There is a separate type of API events that we do not encounter very often, because they are largely associated with accents and hieroglyphs, which are inserted by several composite actions. Also, these events are associated with alternative input methods, such as voice.
In a few words about how they work: if you want to insert an à - character with a accented character, at macOS you press <Alt + '>, then <a>, and they are glued together into a single à character.
This causes several events at once:
Voice input also works the same way: you slander the text, the browser decodes it, turns it into a string, and compositionupdate happens.When you finish speaking, compositionend occurs and the final line appears.
Undo / Redo
Another familiar function of text editors is undo and redo, i.e. the ability to undo their actions. But the system mechanism is no longer suitable for us, because, I remind you, we store data in our own format in the state, and the system mechanism will affect only those changes that occurred in the DOM, i.e. state will not roll back.
Therefore, you have to intercept the pressing of the <Command + Z> / <Ctrl + Z> buttons and implement your Undo / Redo mechanism, which, as a rule, is based on storing state snapshots. The algorithm is simple: some kind of action happened, we saved the snapshot, and then we can return to it. Some changes it makes sense to group in one record of history. There is a convenient redux-undo module for working with history .
So, you have a document format and you learned how to edit it. But besides the structure, he also has styles, and here, too, not everything is not so simple:
We need to isolate all this from each other, and we remember:
Example WordPress CSS
In the screenshot below we see the interface for creating a post in WordPress. The whole page is an application, it has its own styles of UI-elements (text fields, buttons, headers, etc.). The green area is a plugin of our editor with its own UI-styles. Inside the editor is a post (blue block). Since the editor is located right in the DOM tree of the page, and not inside the iframe, we need to make sure that the styles of all these components do not affect each other.
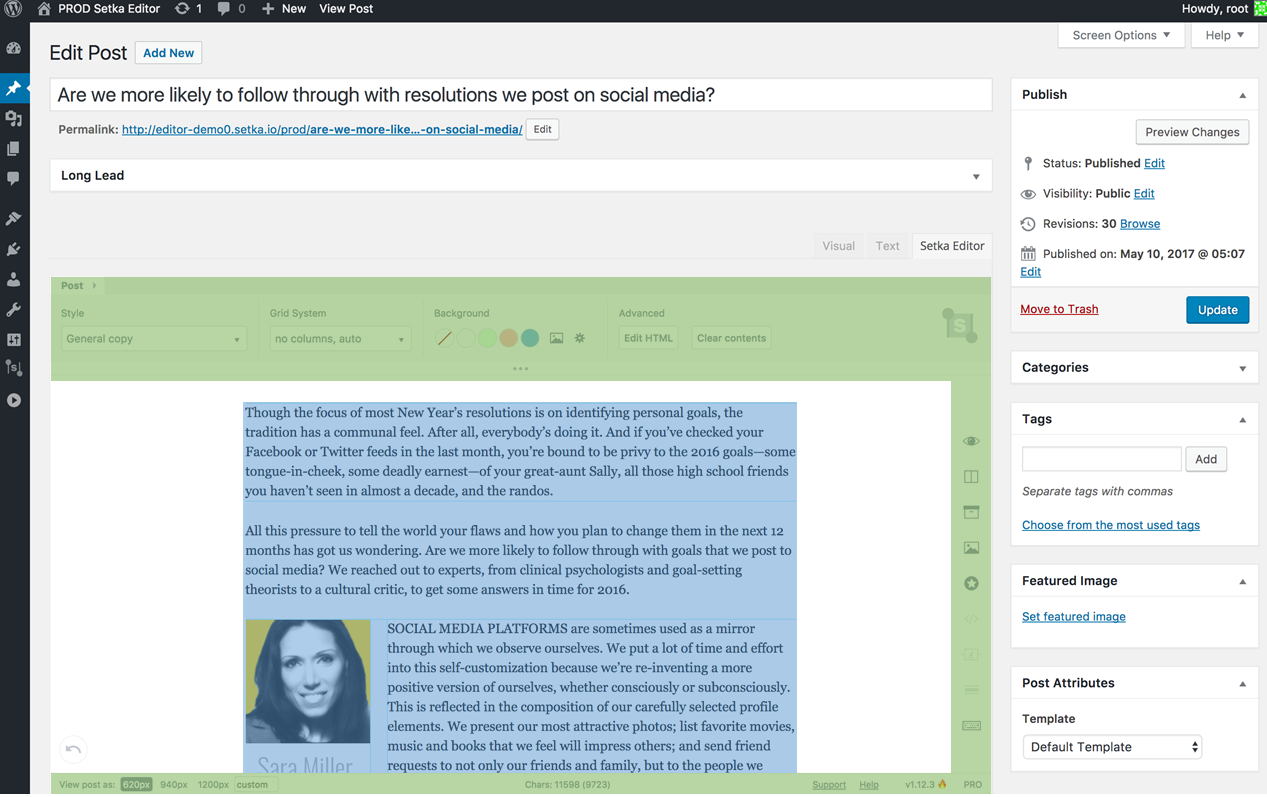
A real example of CSS from WordPress code: for all H2 headers that lie inside a block with id = "poststuff", certain typography and indent rules are specified. And we remember that selectors that have an id specified have a very large weight, which can only be interrupted by the same selector or even stronger.
So, we need to isolate:
Since we deliver our product with the ability to configure post styles separately from the site styles, the site template style and post style should not conflict with each other.
The 3 main ways to isolate CSS are:
Suppose we want to interrupt those styles of WordPress CSS styles that were considered above with our styles. The only way to do this with selectors is to set the selector with the same weight and override the rule.
WordPress CSS
CSS editor
Or you can get on the slippery track of inline-styles and! Important , but then in the future we will begin constant conflicts with specificity (both someone else’s and our own).
Unfortunately, all this does not give a 100% guarantee - for every cunning selector there will be an even more cunning selector who will interrupt him.
On the one hand, everything in the iframe is convenient, because then everything will be precisely isolated, because there is a barrier between the page and the editor. On the other hand, this barrier will be permanent, but we need to periodically exchange messages between the external page and the content of the iframe, and simply can’t do it. There are other problems typical for frames - for example, its size needs to be automatically adapted to the height of the block with content inside it.
Shadow DOM + Custom Elements
Perhaps the most advanced approach that everyone is looking forward to is using Shadow DOM and Custom Elements. Then it will be possible to turn the editor into a web component, inside it will have a shadow root and all content will be completely isolated.
That would be great, but so far, from this bright future, we are limited by the fact that Shadow DOM is normally supported only in a few browsers.

With Custom Elements, the same story.

I recall that we now have half the traffic - mobile devices, and this value continues to grow. At the same time, our editors and publishing designers work on desktop computers and laptops, but they want to see how their layout, especially complex, will look on mobile devices. Also, sometimes there is a need to change the settings of certain elements of the post, so that they are better displayed on smartphones, especially for multicolumn grids. At the same time, we don’t want to adapt everything every time manually - I want it to work right away without the participation of developers.
We implemented a special preview mode (preview) in our website, where you can see how the post looks on the desktop, and then switch to mobile mode and see how it will look on mobile devices (and both modes are displayed on wide screens) . To do this, we on the fly generate 2 iframes with a certain width - one for the desktop, the second for mobile. They include the same CSS file that is used later on the site. This ensures the principle of WYSIWYG. But because the width of the iframe is limited, it becomes possible to apply mobile rules for media queries. Thus, you can see the real result, which will then be on the smartphone. Each time you click the button to switch to the Preview mode, we generate the necessary HTML and put it inside the iframe, it happens quite quickly.The iframe has no SRC attribute, its content is programmatically changed every time programmatically.
Congratulations, you wrote an editor, and it works. You have a kernel, but this is not enough: you constantly need to finish new features. Therefore, the editor, like any extensible product, must have a public API and plug-in connection system . And, of course, this should all be documented .
If you built the editor on the principle of the immutable state, then, in essence, every plug-in, as used in Redux terminology, is a set of actions and reducers. Examples of plugins:
First, Web Components are coming to help solve the problem of isolating components and their styles on the page, which would be very useful. If we talk about the text editing API, now the W3C Input Events specification is in development , which introduces input and before input events for editable areas and provides detailed information about what action took place, for example:
Additional properties:
In general, this is a much richer API that will allow you to make more advanced web editors. Moreover, in the comments to this specification it is written that this is still not an ideal solution, and developers are invited to participate in the process of writing and approving the document.
Think ahead:
Examples of good modern editors:
» Email: yakovishen@setka.io
» Telegram: t.me/yaplusplus
» Facebook: facebook.com/yaplusplus
» Twitter: twitter.com/yaplusplus
» Setka website: https://setka.io
However, with the transition of a large part of the software into browsers, the corresponding visual editors Rich Text Editors are relevant, and there are a lot of problem areas in their development. If for some reason you decide to make your own editor, then think again - there is an opinion that this is not necessary.
')
So that you could make a more balanced decision, Yegor Yakovishen summed up all his experience gained in the process of creating Setka Editor , and told about the problems that he would have to face and what can be done to solve them.
Disclaimer: The article is written on the basis of a report by Egor at the Frontend Conf 2017 conference in June 2017. The situation with browser support for certain APIs could have changed since then.
About experience
Setka, a company in which I work, develops tools for streamlining processes in content marketing teams, online media editorial offices, and content brands that launch their publications. One of our products is the cool visual editor Setka Editor, which allows you to create user-engaging content really quickly and without losing quality. Here are a number of editor features:
- multicolumn “magazine” layout;
- flexible customization of styles for each edition or brand;
- adaptive layout for all devices;
- standardization and automation of article creation processes (snippets, templates);
- custom CSS and JS-embeds;
- live preview - the ability to watch a clean version of the layout on the fly.
The editor can be used in WordPress (we have released a special plugin for this), as well as integrated into any other CMS.
Setka was born within the walls of Look At Media publishing house, which brings together popular publications The Village, Furfur, Wonderzine and others. You can read more about the background and development history of Setka Editor in an article from the Setka corporate blog . Below is an example of the layout of the post, which is made in our editor.
It can be both daily news, and longrida, and special projects.
There are many more examples under the spoiler.
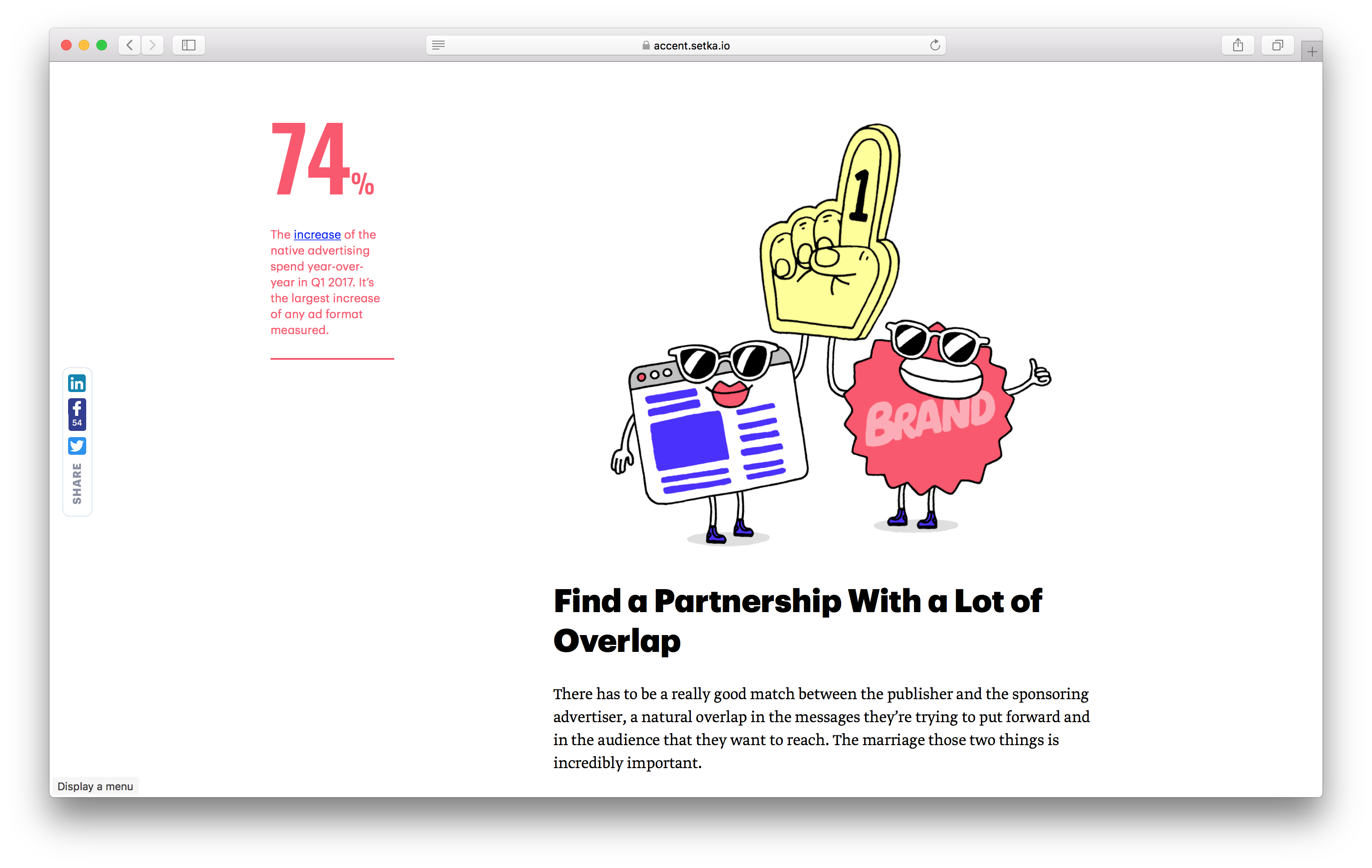



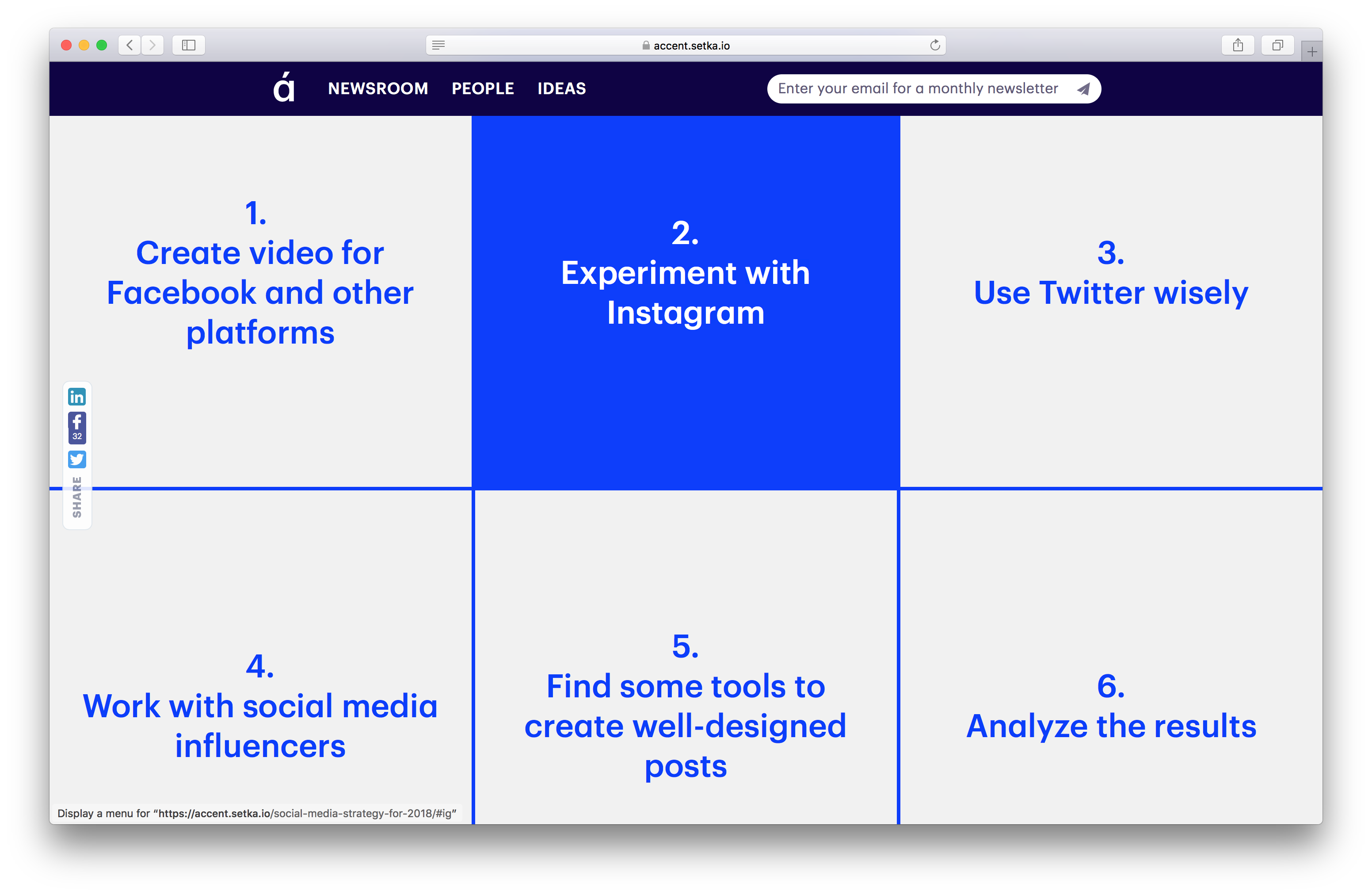
Posts created in Setka Editor only on our publications monthly generate more than 20 million views per month - just so that you understand the scale of the tasks that we have to face.
So let's go!
Prehistory
Text editors, as a type of software, appeared a long time ago. Probably, for many, it was generally the first software they encountered in their lives. Someone may have found the MS-DOS Editor:
Obviously, everyone saw Notepad in its different versions:
Microsoft Word has also gone through many versions:
In addition, there are specialized programs, for example, Adobe InDesign , for really complex magazine layouts:
But this is all classic software that works in the operating system as desktop software.
Meanwhile, in the browser, the situation is different. First, we have the usual textarea. This is a field where you can write text, it works absolutely everywhere - great cross-browser compatibility! But there is a problem: no stylization, and even more complicated layout in this textarea will never be done, because this is just a plain text input field. It is only slightly more complex than text input.
There are many products that call themselves Rich Text Editor. You have probably come across them many times on different sites. Here are some classic representatives.
Tinmyce
CKEditor
Froala editor
And dozens of other projects of different levels of development, most of which have so-called “generic problems”.
Typical problems Rich Text Editors
WYSIWYG
In almost all editors, the key principle of WYSIWYG (What You See) is not observed. This means that the layout you see in the editor will not necessarily coincide with what visitors see on your site. In the editor you work with a small window of a fixed size, and on the pages of the site everything turns out to be completely different, since there is a specific site template with its own styles, another width of the content area, additional blocks, etc. And if the user enters the site from a mobile device, completely different rules are already applied there.
Very few or too many functions.
Functions in such editors, as a rule, are either very few (bold, italic, text alignment), or too many - 5 lines of buttons that cannot be understood.
It is difficult to "make friends" with an existing site design.
The design has already been approved by the art director, the site is up and running. And now you need to somehow make your editor friends with this design so that you can make a beautiful layout in it, but within the framework of the company's corporate identity. This can be quite a challenge.
Cross-browser compatibility
Many editors have problems with cross-browser compatibility, both with their interface and with the layout they generate. This is especially true of old IE and Safari, but at times Firefox sometimes surprises.
General purpose tools
In most cases, Rich Text Editor is simply a tool for translating visual blocks into HTML and CSS code created for people who for various reasons do not want or cannot write code manually. If you need a more advanced tool for solving your problems, then often WYSIWYG editors from helpers turn into obstacles.
There are also a lot of other problems, for example:
- HTML code in such editors, as a rule, undergoes a very strong cleaning or, on the contrary, it does not pass at all. That is, either you are severely limited in capabilities, or create a potential XSS vulnerability.
- This often creates problems with SEO.
- As a rule, such editors allow you to create posts only for the desktop, and you do not know in advance how your content will be converted to mobile. Although, for example, on our sites, mobile traffic is already more than 50%.
- Support for very old browsers (and a lot of legacy code because of this) or, on the contrary, only the newest
And so on. There are really a lot of problems and questions.
You decided to make your editor
So, the moment X came, and for some reason you decided to make your own editor.
Nice try, but don't do it!
The Internet is just full of posts, where it says that you should not do this. Most likely, a lot of restrictions will prevent you from making a really good product.
In particular, this is a screenshot from StackOverflow , in which one of the developers of CKEditor (one of the old and famous editors) writes that they have been doing it for 10 years, they still have thousands of issues and, unfortunately, they cannot get a good result - not because they are bad developers, but because they are bad browsers.
Nevertheless, you still rejected all doubts and want to make your editor. What are the key questions you face? It will be necessary to understand:
- how to edit content on a web page;
- how to store this content;
- how to deal with styles (CSS);
- how to extend the functionality of the editor.
We will talk about this today. Let's start in order.
How to edit content?
Historically, browsers for this provide the following features.
Designmode
The document object has such a property, it exists for a very long time - probably, in the late 90s it was implemented in the first versions of Internet Explorer.
document.designMode = "on" When this property is switched to the on mode, then absolutely the whole page, the entire contents of the body becomes editable. You can place the cursor anywhere and edit the text.
If you google, you can see the enthusiastic comments 10-15 years ago on forums like Antimat, how cool you can edit any page, for example, Microsoft, Google and so on.
This way is imperfect. Its main problem is that, more often than not, it’s not necessary to edit the whole page, but only a specific block. Probably the only case when the designMode is applicable is when the editable area is in an iframe, and you really want to make this block entirely editable. But these situations are not very many.
Contenteditable
This is the main browser API for creating editable blocks. When this attribute is switched to true, everything inside the block becomes editable. In this way, most visual editors are now done, and ours is no exception.
<div contenteditable="true"> … </div> The problem is that each browser implements user actions in this block differently. The simplest example: there is a block with the text “Hello, world”, turn on contenteditable = ”true”, it becomes editable. Next, put the cursor after the comma after the word "Hello" and press the Enter button.
After that, a new <div> inside the block will appear in Chrome and Safari, there is an unbreakable space and the remaining word "world".
<div contenteditable="true"> Hello, <div>nbsp;world</div> </div> And in Firefox - line break <br>.
<div contenteditable=“true”> Hello, <br> world </div> Thus, you have no control over the situation, because each browser acts differently.
Document.execCommand
This is a special method that allows browser commands to be applied to a selected part of the text. There are a fixed number of such commands, for example, bold, fontSize, formatText, and so on.
Js
document.execCommand('bold'); document.execCommand('fontSize', false, 7); HTML
<b>Hello</b>, world <font size=“7”>Hello</font>, world This API also exists a long time ago and it is extremely unstable. Suppose, in the same example, you selected the word “Hello” and executed the execCommand ('bold') command. The text turned into a <b> tag. What potential problems could there be? First, maybe I want not <b>, but <strong> (I was advised by SEOs). Or, maybe, I want to add another class to this <b> tag and I will have to do an additional action.
Okay, <b> is still not so scary, and if I want, say, to make the font a big headline? I run the browser fontSize command, pass the value 7. And what? Inserted tag <font>, which we have not seen on sites since the beginning of the 2000s, with the 7th size. Yes, visually, this is similar to what was required, but in terms of code, semantics, SEO, and subsequent support, this is a nightmare.
Summary:
- Different browsers generate different HTML.
- execCommand does not work everywhere and not always (and also in different ways).
- You do not control what happens.
As a result, if you use only standard API, then the editor is incomplete. You cannot use semantic tags and apply correct styles, you do not know how to parse it later and how it will affect SEO.
There is a textbook article “ Why ContentEditable is Terrible ”, in which developers describe why contenteditable is bad, and what to do about it.
Alternative ways
To avoid these problems, you can make your editor using canvas. Such examples exist, but, in fact, you have to completely reinvent the entire rendering of the text, cursor, selection, etc.
We will now see that in fact a lot of this has to be done. But in the case of Canvas, you work with the text area in fact as with a picture. It is too complicated and most likely you will get so many problems that all this work will become ungrateful.
The second method, which is most often used in practice in almost all modern editors (and in particular, in our country), is a bunch of contenteditable areas and document state storage based on the actions that take place in this area.
Let's say you have a contenteditable area. In its classic use, you put the cursor, write text, and the content changes, and, as we said, it changes unpredictably. In this case, when you write something to input, the state first changes as necessary, and then the input is redefined based on the state change. In essence, this is an approach called React Controlled Input in React. This, in turn, can cause performance problems with fast typing. Then you need to use a hybrid version: input text characters immediately display in the DOM, and more complex actions to process first yourself.
Suppose you put the cursor in a text field and press Enter. The editor understands that it is necessary to insert a line break, or if at this moment you have not selected the text, but the object, then you need to perform some other action. Thus, you can control absolutely everything: what happens in your editor: perform the necessary actions, cancel unnecessary, etc.
General scheme:
- contenteditable is used as an interface for tracking events;
- all events are intercepted and the document state changes (except for events that occur very often and negatively affect performance, for example, the movement of the caret cursor - they can be monitored separately and use debounce or throttle);
- after changing the state, React is connected and updates the DOM representation of the document;
- controlled input.
The state can store:
- Content (text, images, embeds, separators). The structure can be nested - for example, our layout is built largely on the use of multi-column grids of any depth of nesting.
- The position of the cursor . It is useful to remember where the cursor is positioned so that later it can be returned to its place, saved, serialized, etc.
- Select text . We'll talk about this in more detail below.
- Editor's UI — for example, which panel is currently open, what is active, what is not active, what mode you are in, etc.
Thus, all this can be stored in the state, and work with the editor as an application that changes this state. For example, here is the editor of Draft.js from Facebook, made at React:
The screenshot shows how they store the state of their editor. The text consists of two lines, and on the right they are presented as a JS object. They have text attributes, each has its own unique key key, they can be styled or not, etc.
But the farthest in this issue went Google Docs with its kix engine. They had a completely non-standard task: not just developing an editor, but also implementing simultaneous multi-user work. This means synchronization of changes, multiple cursors, and all other complex things that generally lie outside the editor’s design issues.
To do this, they track all the events that occur on the page, in a special Iframe, which is generally far, far away from the screen. The screenshot shows that this iframe has a top coordinate of –10000px, and a height of only 1px. It is used only to intercept events that occur on the page. As you can see, this iframe doesn't even have content, only an empty container with contenteditable = "true" . That is, it is exclusively a service tool.
To solve all the tasks, the developers of Google Docs, had, in fact, to reinvent the entire system of text rendering in the editor.
The screenshot above shows the selection of the text, and you can see that this is not a standard selection of the operating system, but also a special div called kix-selection-overlay. It has background-color, opacity, size and coordinates. That is, this is a special DOM wrapper around the content, which is a selection.
Moreover, they even have a cursor - it’s a 1-2px wide div, line-tall, with certain CSS properties applied to it, which allow it to flash for half a second. Thus, there can be 5 cursors on a page at a time, if it is edited by 5 people.
How to store content?
Here we turn to the question of how to store the state of the content in the state. Traditionally, the content that is displayed on web pages is stored as HTML.
This has its advantages:
- Such content is easy to show in the browser, because browsers are well able to render HTML. If you pass in for example JSON, then it will be displayed as a JSON-tree. You will have to first convert it to HTML and style it as needed.
- HTML is easy to change without editor. If for some reason the editor does not work, you can always correct the code as you see fit,
- Most likely, now the content is stored in the database of your site in this way (in the form of HTML).
- Finally, and also importantly, other code, such as search bots or third-party plug - ins, is accustomed to working with HTML , and not with the structure that you can think of.
But there are also disadvantages:
- First, as we have already discussed, different browsers produce different HTML from contenteditable regions.
- Such code is more difficult to export to other formats such as Facebook Instant Articles or JSON. This is true if you want your content to be displayed not only on the site, but also fly into a mobile application, be available for download in PDF, etc. Every time we have to parse the HTML, clean out the excess and turn it into the format that is required.
- This content is closely related to the design using HTML attributes such as style, class, etc.
Own format
Anyway, most likely you will need your own convenient format for storing the contents of the document.
Decomposition on entities
First, you need to decompose into entities what you are working with in the editor. Most likely, you will have classic elements of any text:
- title;
- paragraph;
- picture;
- table;
- list;
- comment.
In the code editor there will be your entities, in the graphic editor - others. You need to understand what content you are working with.
Data structure
Further, these entities should be presented in the form of a structure with types and attributes, with which you can then work. Here is an abstract example of the structure of a text element:
1: { id: 1, type: "Paragraph", content: "this is a text", style: [ { range: [0,3], format: ["bold"] } ] } In this example, you can see that there is a Paragraph element, it has a certain content, and its first 4 letters are formatted in bold format. Such a structure can be rendered in any kind of representation, for example:
- Plain text without any design;
- HTML;
- PDF for printing and saving;
- JSON, XML;
- RSS;
- Facebook Instant Articles, Google AMP, Apple News.
Importantly, such a structure can be displayed in the editor in one way (for example, with additional editing elements, buttons, etc.), and from the outside - in a completely different way. Thus, you again become a full-fledged master of what is happening with your content.
You can ask the expected question: “Listen, my content is stored in HTML for many years, I have my own CMS. Do you propose to forget everything, invent your own format and then rewrite all the code to work with it? Obviously, I do not want to do this, because the benefits from a business point of view are incomprehensible "
We had the same problem when we implemented the editor on our sites, where there was a large proportion of legacy code and thousands of post posts.
Workaround:
- Store data in the database in the form in which they are already. Most likely it is HTML.
- When you load them into the editor, parse them and work with your format. And when saving data to the database, serialize it back to HTML and save it in this form.
- This is useful in cases when you need to work in an established ecosystem (for example, CMS with plugins like WordPress).
We are doing exactly that now. Our editor works on a variety of platforms, and we do not have the right to impose our data storage format. We need to work with what is.
How to work with user input?
Types of user input in the browser:
- Good old keyboard. It happens also virtual, and also allows to use hot keys.
- Context menu.
- Copy & Paste.
- Drag & drop.
- Voice input, which is becoming increasingly popular.
- Handwriting that is relevant in Asian countries: you draw something that turns into a text character, and then enters the text field.
- Autocorrection and autocompletion.
Your editor is not required to support absolutely all of these input methods. Most likely, few people will enter long texts in a voice so far, but, nevertheless, possible options should be taken into account.
Browser APIs
The browser for this offers a whole "zoo" of various APIs, because contenteditable-areas, unfortunately, do not have a single change event to which you can subscribe and know exactly when changes occur. There are several key APIs with which you can work somehow. Although I will emphasize, in almost every post about the creation of visual editors - and my story is no exception - it is emphasized that the situation with the browser-based API is bad.
Selection API allows you to work with the selection of text on the page.
Contains 2 useful events: selectstart and selectionchange . Selectstart is triggered when we start to select a region of text on a page, and the selectionchange is triggered every time the selection changes. Moreover, what is useful, it works not only when the selection changes with the cursor, but also when we press the Shift + arrows or Ctrl-A to select all the content on the page.
Window.getSelection () - using this method, you can get an object with information about the current selection of text on the page. This object contains useful properties, such as anchorNode and focusNode. AnchorNode is the node on which the selection began, and focusNode is the node on which the selection ended. Each of these nodes can have its own offset, i.e. number of selected characters in this node.
As an example, consider the screenshot of the FrontendConf website page. I highlighted the text, starting with the word “design” and ending with the phrase “mobile sites,” considered the current selection and looked at what exactly was highlighted. You can see that anchorNode and focusNode are both text nodes, anchorOffset = 11 (the word “design” starts at the 11th position), and focusOffset = 15. In this way we can understand which text on the page is currently highlighted.
Selection API is fairly well maintained and fairly stable.
The next API is clipboard, Clipboard API . There are much more problems with him, there are some stars and comments everywhere.
The Clipboard API offers several events that you can subscribe to: copying content (copy), cutting (paste), pasting (paste), and what happens right before this: beforecopy, beforecut, beforepaste.
Some of them can be self-invoked using execCommand, but for security reasons, many actions with the clipboard are blocked.
For example, if the user himself initiated copying, pressed <Ctrl-C> or <Edit-Copy>, a copy event occurs, and at this point the developer can intervene and perform certain actions:
- change the contents of the clipboard;
- disable insertion;
- change the insertion algorithm;
But it is impossible to initiate an operation with the clipboard if the user does not want this.
The reasons for this are clear: suppose a person on the clipboard has a password or credit card number. If a browser application could independently read this data and send it somewhere, then there would be no security. Therefore, if the user himself does not initiate an event, we cannot in any way call it ourselves.
Clipboard API support is good, but there are certain limitations. Suppose you want in your editor to copy not just text, but some complex object. But the copy event will not occur if the page does not have selected text. To do this, you can use the algorithm of the company Trello, which they openly write on Stack Overflow . For a user, this works like this: you move the cursor over some card in the board, press Ctrl-C, then move the cursor to another place, press Ctrl-V, and this card is inserted into the right place.
Implemented as follows:
- Intercepted by pressing the Ctrl key. The developers of Trello captured a pattern of behavior: when a person presses Ctrl, that is, there is a high probability that after this he will press <C> to copy.
- An invisible textarea is created with the code of the element to be copied. When you press Ctrl off-screen, an invisible textarea is created, where the code of the element that the person wants to copy is placed, and a cursor and focus are placed there.
- The user presses <C> and his code is copied, which is in this textarea (because there is a cursor).
- The insert event is intercepted.
When the user then moves the cursor to another location and clicks "Paste", the insert event is intercepted, and with the help of JS the card is inserted into the list that the cursor is hovering over.
At home we copied complex objects in a similar way.
Composition Events
There is a separate type of API events that we do not encounter very often, because they are largely associated with accents and hieroglyphs, which are inserted by several composite actions. Also, these events are associated with alternative input methods, such as voice.
In a few words about how they work: if you want to insert an à - character with a accented character, at macOS you press <Alt + '>, then <a>, and they are glued together into a single à character.
This causes several events at once:
- compositionstart - the beginning of the process of composition of one character from several;
- compositionupdate - add each component of this symbol;
- compositionend - the formation of the final symbol.
Voice input also works the same way: you slander the text, the browser decodes it, turns it into a string, and compositionupdate happens.When you finish speaking, compositionend occurs and the final line appears.
Undo / Redo
Another familiar function of text editors is undo and redo, i.e. the ability to undo their actions. But the system mechanism is no longer suitable for us, because, I remind you, we store data in our own format in the state, and the system mechanism will affect only those changes that occurred in the DOM, i.e. state will not roll back.
Therefore, you have to intercept the pressing of the <Command + Z> / <Ctrl + Z> buttons and implement your Undo / Redo mechanism, which, as a rule, is based on storing state snapshots. The algorithm is simple: some kind of action happened, we saved the snapshot, and then we can return to it. Some changes it makes sense to group in one record of history. There is a convenient redux-undo module for working with history .
How to be with CSS?
So, you have a document format and you learned how to edit it. But besides the structure, he also has styles, and here, too, not everything is not so simple:
- An editor is a component that by itself (outside the application) is of little use.
- The editor has its own styles (UI) - panels, buttons, sizes, etc.
- The editor lives inside the application, for example, CMS.
- The application has its own styles.
- Inside the editor lives the post itself, which you are editing.
- The post also has its own styles (fonts, colors, etc.). They can be completely different. You can create posts with different corporate styles in the same editor.
We need to isolate all this from each other, and we remember:
- CSS rules live in the global scope;
- The order of application of the rules is determined by specificity;
- With all this, we need to ensure the principle of WYSIWYG - that in the editor, then on the site.
Example WordPress CSS
In the screenshot below we see the interface for creating a post in WordPress. The whole page is an application, it has its own styles of UI-elements (text fields, buttons, headers, etc.). The green area is a plugin of our editor with its own UI-styles. Inside the editor is a post (blue block). Since the editor is located right in the DOM tree of the page, and not inside the iframe, we need to make sure that the styles of all these components do not affect each other.
A real example of CSS from WordPress code: for all H2 headers that lie inside a block with id = "poststuff", certain typography and indent rules are specified. And we remember that selectors that have an id specified have a very large weight, which can only be interrupted by the same selector or even stronger.
#poststuff h2 { font-size: 14px; padding: 8px 12px; margin: 0; line-height: 1.4; } So, we need to isolate:
- CMS editor;
- post from the editor and CMS;
- CMS from the editor and post;
- Website template (header, basement, sidebar, additional widgets) from the post styles created in the editor.
Since we deliver our product with the ability to configure post styles separately from the site styles, the site template style and post style should not conflict with each other.
The 3 main ways to isolate CSS are:
- CSS reset + BEM - all pre-set and apply a specific naming system for your classes. In this case, this is the most common BEM, but you can replace any other methodology.
- Putting everything in an iframe is more “reinforced concrete” protection, but with its own drawbacks.
- Everything is hidden in the Shadow DOM and Custom Elements , but the obvious disadvantage of this method is poor browser support.
CSS reset + BEM
Suppose we want to interrupt those styles of WordPress CSS styles that were considered above with our styles. The only way to do this with selectors is to set the selector with the same weight and override the rule.
WordPress CSS
#poststuff h2 { font-size: 14px; } CSS editor
#my-editor h2 { font-size: 28px; } Or you can get on the slippery track of inline-styles and! Important , but then in the future we will begin constant conflicts with specificity (both someone else’s and our own).
Unfortunately, all this does not give a 100% guarantee - for every cunning selector there will be an even more cunning selector who will interrupt him.
iframe
On the one hand, everything in the iframe is convenient, because then everything will be precisely isolated, because there is a barrier between the page and the editor. On the other hand, this barrier will be permanent, but we need to periodically exchange messages between the external page and the content of the iframe, and simply can’t do it. There are other problems typical for frames - for example, its size needs to be automatically adapted to the height of the block with content inside it.
Shadow DOM + Custom Elements
Perhaps the most advanced approach that everyone is looking forward to is using Shadow DOM and Custom Elements. Then it will be possible to turn the editor into a web component, inside it will have a shadow root and all content will be completely isolated.
<my-editor> #shadow-root </my-editor> That would be great, but so far, from this bright future, we are limited by the fact that Shadow DOM is normally supported only in a few browsers.
With Custom Elements, the same story.
Adaptive layout
I recall that we now have half the traffic - mobile devices, and this value continues to grow. At the same time, our editors and publishing designers work on desktop computers and laptops, but they want to see how their layout, especially complex, will look on mobile devices. Also, sometimes there is a need to change the settings of certain elements of the post, so that they are better displayed on smartphones, especially for multicolumn grids. At the same time, we don’t want to adapt everything every time manually - I want it to work right away without the participation of developers.
We implemented a special preview mode (preview) in our website, where you can see how the post looks on the desktop, and then switch to mobile mode and see how it will look on mobile devices (and both modes are displayed on wide screens) . To do this, we on the fly generate 2 iframes with a certain width - one for the desktop, the second for mobile. They include the same CSS file that is used later on the site. This ensures the principle of WYSIWYG. But because the width of the iframe is limited, it becomes possible to apply mobile rules for media queries. Thus, you can see the real result, which will then be on the smartphone. Each time you click the button to switch to the Preview mode, we generate the necessary HTML and put it inside the iframe, it happens quite quickly.The iframe has no SRC attribute, its content is programmatically changed every time programmatically.
How to extend the functionality?
Congratulations, you wrote an editor, and it works. You have a kernel, but this is not enough: you constantly need to finish new features. Therefore, the editor, like any extensible product, must have a public API and plug-in connection system . And, of course, this should all be documented .
The API should be able to:
- get and change content in the editor;
- register event callbacks in the editor;
- integrate the editor with the external environment (CMS, application).
Plugin system
If you built the editor on the principle of the immutable state, then, in essence, every plug-in, as used in Redux terminology, is a set of actions and reducers. Examples of plugins:
- spellchecking;
- autotype autograph;
- integration with external services (Google Drive, etc.).
, . , :
- oembed HTML;
- context menu;
- ;
- HTML CSS-;
- - ();
- ;
- -;
- API.
rich text editing
First, Web Components are coming to help solve the problem of isolating components and their styles on the page, which would be very useful. If we talk about the text editing API, now the W3C Input Events specification is in development , which introduces input and before input events for editable areas and provides detailed information about what action took place, for example:
- Insert - insert text;
- insertReplacementText - replacing specific text with auto-correction;
- deleteByCut - delete;
- formatBold - formatting.
Additional properties:
- InputEvent.data (insert *, format *) makes it clear which formatting is used.
- InputEvent.dataTransfer (text / plain, text / html) allows you to get content that changes in text / plain mode or text / html mode.
- InputEvent.getTargetRanges ()
In general, this is a much richer API that will allow you to make more advanced web editors. Moreover, in the comments to this specification it is written that this is still not an ideal solution, and developers are invited to participate in the process of writing and approving the document.
findings
How to edit data?
- Use contenteditable to track events. Now this is the best tool for creating editors: track user events, change state and update your editor.
- Store the state of the editor and content in state.
- Do not store the state in the DOM. This applies, probably, to any application, not just the editor.
How to store data?
- Identify the entities you work with.
- Think over the state structure.
- Write the code that will translate this structure into the formats you need.
How to be with CSS?
- The editor will live in an environment that you do not control.
- Think about CSS isolation in advance.
- Put the editor in the iframe or clean everything you can.
Expansion of functionality
Think ahead:
- Modular architecture.
- API.
- The ability to write and connect plugins.
Examples of good modern editors:
- Quill (Salesforce, Telegra.ph);
- Draft.js (Facebook);
- Trix (Basecamp);
- ProseMirror, CodeMirror;
- Google Docs
- iCloud Pages.
Contacts:
» Email: yakovishen@setka.io
» Telegram: t.me/yaplusplus
» Facebook: facebook.com/yaplusplus
» Twitter: twitter.com/yaplusplus
» Setka website: https://setka.io
In the web and the frontend in particular, on the one hand, everything is developing very fast, the frameworks there are impossible to keep track of. On the other - there are basic questions, such as in this article. We will talk about this and about this at the May festival of RIT ++ conferences and invite active specialists to submit applications and make presentations.
Source: https://habr.com/ru/post/350252/
All Articles