ViyaDB: analytical database for unsorted data
About a year ago, I happened to work in the same company, where I ran into an interesting problem. Imagine a massive flow of data on the use of mobile applications (tens of billions of events per day), which contains such interesting information as the installation date of the application, as well as the advertising campaign that led to this installation. Having such data, you can easily divide users into groups by installation dates and promotions in order to understand which of them was the most successful from the point of view of ROI (return of investment).
Consider a visual example (picture found on the Internet):
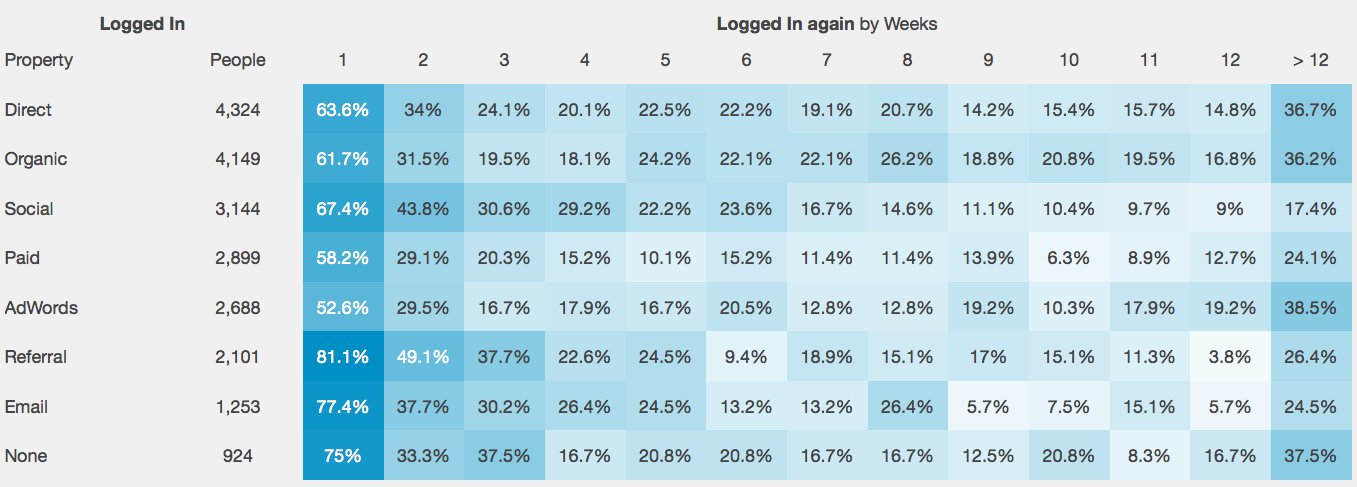
As we can see, users who came from AdWords "billboards" turned out to be the most loyal to this particular application (they continued to actively use the application).
There is no doubt that such methods cannot be overestimated when it comes to marketing optimization, but we will consider this problem from the point of view of us, data engineers.
All requests of such a plan, as a rule, imply a condition related to the installation date of the application, which is not a temporary series: in our data stream there are events from both applications installed yesterday and applications installed 2 years ago. Translated into database language, this means a complete scan of data from a given point and up to the current time.
Evolution of solutions
The problem was aggravated by the fact that the chosen solution was required to support multiple parallel queries, so the analytical databases that were not designed for hundreds of users working simultaneously with the analysis panel of our company had to be excluded initially.
At first, MongoDB was used to store such data, but very soon we reached the limits of this remarkable database, both during queries and during recording. It was possible, of course, to “despair” all this disgrace, but because of the operational complexity of sharding MongoDB, it was decided to try other solutions.
The second attempt was Druid, but since this database works with data sorted by time, this helped us very little. In fact, if we ignore the real-time information and rebuild the database every day by sorting the data by the installation date, this can work very well.
Databases like Cassandra, which require building a table "on demand", also had to be neglected because of the desire to support so-called ad-hoc queries, when the list of query fields may vary from user to user.
As a result, everything ended with the choice of MemSQL - a new generation database ( NewSQL ), combining support for both OLTP and OLAP loads, thanks to the modern architecture, and also due to the fact that the data is in memory. But, as we understand, there is no perfect solution, and therefore two problems remained:
1) The write speed left much to be desired due to the use of WAL (write-ahead log), which we didn’t really need, just as the data was saved on S3, and we were ready to sacrifice fast data recovery for a huge write speed .
2) Price
The invention of the wheel
Then I thought about writing something of my own, simpler ... For example, to keep the vector of consecutive static-sized records in memory, thus ensuring quick passage and filtering by a given criterion. And also, break it all into processes, and assign a data partition to each process. So was born ViyaDB . In fact, this is an analytical database that keeps aggregated data in memory in a column format, which allows you to “run through” fairly quickly. Requests are translated into machine code, which avoids unnecessary branching and it is more correct to use the processor cache when re-requesting a similar type.
This is a bird's-eye view of ViyaDB architecture:

Below is an example of using this unpretentious database.
Test Drive
First, install Consul , which coordinates the components of the ViyaDB cluster. Then, add the required cluster configuration to Consul.
In the key "viyadb / clusters / cluster001 / config" we write:
{ "replication_factor": 1, "workers": 32, "tables": ["events"] } In the key "viyadb / tables / events / config" we write:
{ "name": "events", "dimensions": [ {"name": "app_id"}, {"name": "user_id", "type": "uint"}, { "name": "event_time", "type": "time", "format": "millis", "granularity": "day" }, {"name": "country"}, {"name": "city"}, {"name": "device_type"}, {"name": "device_vendor"}, {"name": "ad_network"}, {"name": "campaign"}, {"name": "site_id"}, {"name": "event_type"}, {"name": "event_name"}, {"name": "organic", "cardinality": 2}, {"name": "days_from_install", "type": "ushort"} ], "metrics": [ {"name": "revenue" , "type": "double_sum"}, {"name": "users", "type": "bitset", "field": "user_id", "max": 4294967295}, {"name": "count" , "type": "count"} ], "partitioning": { "columns": [ "app_id" ] } } (the last value is the DDL for our table)
Install ViyaDB on four Amazon machines like r4.2xlarge (based on Ubuntu Artful image from Canonical):
apt-get update apt-get install g++-7 update-alternatives --install /usr/bin/gcc gcc /usr/bin/gcc-7 60 --slave /usr/bin/g++ g++ /usr/bin/g++-7 cd /opt curl -sS -L https://github.com/viyadb/viyadb/releases/download/v1.0.0-beta/viyadb-1.0.0-beta-linux-x86_64.tgz | tar -zxf - Create a configuration file on each of the machines (/etc/viyadb/store.json):
{ "supervise": true, "workers": 8, "cluster_id": "cluster001", "consul_url": "http://consul-host:8500", "state_dir": "/var/lib/viyadb" } ( consul-host is the address of the machine where Consul is installed)
We start the database on all machines:
cd /opt/viyadb-1.0.0-beta-linux-x86_64 ./bin/viyadb /etc/viyadb/store.json Data loading
The database has basic SQL language support. Run the utility that allows you to send SQL queries to the database:
/opt/viyadb-1.0.0-beta-linux-x86_64/bin/vsql viyadb-host 5555 ( viyadb-host is one of four hosts on which we installed ViyaDB)
1 billion events lies on S3 in TSV format; To load them, run the command:
COPY events ( app_id, user_id, event_time, country, city, device_type, device_vendor, ad_network, campaign, site_id, event_type, event_name, organic, days_from_install, revenue, count ) FROM 's3://viyadb-test/events/input/' Requests
To be fair, all subsequent queries were run a second time, so as not to take into account the time they were compiled at the total time of the query.
1) Types of messages and their number for a given application:
ViyaDB> SELECT event_type,count FROM events WHERE app_id IN ('com.skype.raider', 'com.adobe.psmobile', 'com.dropbox.android', 'com.ego360.flatstomach') ORDER BY event_type DESC event_type count ---------- ----- session 117927202 install 263444 inappevent 200466796 impression 58431 click 297 Time taken: 0.530 secs 2) The five most active cities in the states by the number of application installations:
ViyaDB> SELECT city,count FROM events WHERE app_id='com.dropbox.android' AND country='US' AND event_type='install' ORDER BY count DESC LIMIT 5; city count ---- ----- Clinton 28 Farmington 20 Madison 18 Oxford 18 Highland Park 18 Time taken: 0.171 secs 3) The ten most active advertising agencies by the number of installations, again:
ViyaDB> SELECT ad_network, count FROM events WHERE app_id='kik.android' AND event_type='install' AND ad_network <> '' ORDER BY count DESC LIMIT 10; ad_network count ---------- ----- Twitter 1257 Facebook 1089 Google 904 jiva_network 96 yieldlove 79 i-movad 66 barons_media 57 cpmob 50 branovate 35 somimedia 34 Time taken: 0.089 secs 4) And most importantly, for the sake of what all this cheese has been started, this is a report on user loyalty based on individual user sessions:
ViyaDB> SELECT ad_network, days_from_install, users FROM events WHERE app_id='kik.android' AND event_time BETWEEN '2015-01-01' AND '2015-01-31' AND event_type='session' AND ad_network IN('Facebook', 'Google', 'Twitter') AND days_from_install < 8 ORDER BY days_from_install, users DESC ad_network days_from_install users ---------- ----------------- ----- Twitter 0 33 Google 0 20 Facebook 0 14 Twitter 1 31 Google 1 18 Facebook 1 13 Twitter 2 30 Google 2 17 Facebook 2 12 Twitter 3 29 Google 3 14 Facebook 3 11 Twitter 4 27 Google 4 13 Facebook 4 10 Twitter 5 26 Google 5 13 Facebook 5 10 Twitter 6 23 Google 6 12 Facebook 6 9 Twitter 7 22 Google 7 12 Facebook 7 9 Time taken: 0.033 secs Conclusion
Sometimes, solving some very specific problem, the invention of the wheel can be justified. Testing a similar solution showed that it is possible to reduce costs by about four times compared with MemSQL, while not losing anything from the functionality of the base. Of course, to take and transfer a multi-million dollar business to a database written by one person is completely unjustified at this stage, and therefore it was decided not to interrupt the contract with MemSQL. The code laid out in Github is a project that I started from scratch, after leaving the above company.
')
Source: https://habr.com/ru/post/350154/
All Articles