Richard Hamming: Chapter 29. You get what you measure
“The goal of this course is to prepare you for your technical future.”
 Hi, Habr. Remember the awesome article "You and your work" (+219, 2365 bookmarks, 360k readings)?
Hi, Habr. Remember the awesome article "You and your work" (+219, 2365 bookmarks, 360k readings)?So Hamming (yes, yes, self-checking and self-correcting Hamming codes ) has a whole book based on his lectures. Let's translate it, because the man is talking.
This book is not just about IT, it is a book about the thinking style of incredibly cool people. “This is not just a charge of positive thinking; it describes the conditions that increase the chances of doing a great job. ”
')
We have already translated 12 (out of 30) chapters.
For the translation, thanks to Valery Dmitrushchenkov, who responded to my call in the "previous chapter." Who wants to help with the translation - write in a personal or mail magisterludi2016@yandex.ru (By the way, we also started the translation of another cool book - "The Dream Machine: The History of Computer Revolution" )
Chapter 29. You get what you measure
It may seem to you that the title of the chapter implies that if you carefully measure, you will get an accurate result and not otherwise, but in fact, it refers to a much more subtle thing - the method of measurement you choose greatly influences the result. Recall the story of Eddington about fishermen fishing with a net. They measured the fish caught and concluded that there is a minimum size of fish swimming in the sea. That is, the tool you use significantly affects what you see.
At the moment, a popular example of this effect is the use of the bottom line of the quarterly income statement to assess the success of a company. This works well for a company that is mainly interested in short-term profit, but is weakly related to long-term profit.
If in the rating system the starting score of each is 95%, then it is clear that a person can do little to raise his rating, but much to lower it. Thus, a reasonable strategy for employees is to work without risk and, as a result, eventually to the top. At higher levels, you may want to increase your risk tolerance, since the class of people you can choose from is basically conservative.
The rating system in the early stages may tend to remove exactly those employees you want to have at a later stage.
If we use a rating system in which the average person would have a rating of about 50%, then this approach would be more balanced. And if you wanted to encourage risk, you could start with a rating of 20% or less, thereby encouraging people to increase their rating, including using risky methods, because in case of failure their losses would not be too great, but if successful, the reward would fully justify the risk. To take risk in an organization, you must encourage a reasonable degree of risk in the early stages, using this approach in career advancement, so that eventually some of the risky employees may appear at the top.
Of the things you want to measure, some are quantifiable, such as height and weight, while others are only categorically measurable, in particular, social attitudes. There is always a tendency to engage in quantitative measurements, although this approach may be deliberately losing compared to categorical measurements (estimates?), Which in the end may be more appropriate for your tasks. Measurement accuracy is often confused with the relevance (relevance?) Of measurements, and this happens much more often than most people think. The fact that a measurement is accurate, reproducible and easily accomplished does not mean that it should be performed, instead a measurement that is more complex, but more closely related to your goals, may be preferable. For example, in school it is easy to assess preparation and it is difficult to assess education, as a result of which you most often see in the assessments in the final exams an emphasis on preparation and a noticeable disregard for education.
Let me turn to another effect of the measuring system and illustrate it by defining and using IQ. A list of questions appears to be acceptable, based on previous experience, and then it is tested on a small sample of people. Those questions that show internal correlation with others are preserved, and those that do not correlate too well are discarded. Then the updated test is calibrated by testing already on a much larger sample of people.
How? Simply taking the accumulated points (the number of points of people who are below a given value) and plotting these numbers as a representation of the probabilities on which the cumulative probabilities of the normal distribution are represented by horizontal lines. Then the points at which the cumulative actual points fall into the specified percentage points are linked to the corresponding points on the cumulative normal probability curve through a calibration table. The result is that the intelligence of the population has a normal distribution!
Of course, this is so - the method itself meant just such a result! Moreover, IQ was defined as the result of a measurement with a calibrated exam, and with this definition of intelligence, it goes without saying that it has a normal distribution. But if you think that IQ is not exactly what the calibrated exam determines, then you have the right to doubt that this indicator has a normal distribution among the population. Again, you get what was measured, and the declared normal distribution is an artifact of the measurement method and is unlikely to be related to reality.
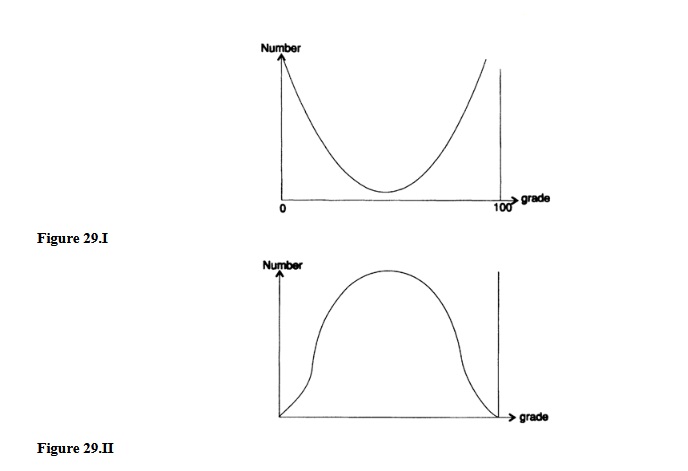
When I take the final exam for a course in, say, mathematical analysis, I can get almost any distribution of marks I want. If I could create an exam in which the questions would be of the same complexity, then each student would usually receive all the correct or incorrect answers. Therefore, I will get a distribution of estimates that reaches a maximum at both ends (Figure 29.I). If, on the contrary, I would ask a few simple questions, most of the questions of average complexity, and a few very difficult ones, then I would get a typical normal distribution; a small number of assessments at each of the ends and most of the assessments in the middle (Figure 29.II).
It is quite obvious that if I know the class, then I can get almost any distribution I want. Usually, in the final exam, I am most interested in the “passed / failed” border and build the exam in such a way that I have as little doubt as possible about how to act, and also have solid evidence of my case in the event of a complaint.
Another aspect of the rating system is its dynamic range. Suppose you are given a scale from 1 to 10, with 5 being the average. Most people will assign ratings 4, 5, and 6, and rarely resort to extreme values of 1 and 9. If you give a rating of 6 to what you like, I will use the entire dynamic range and assign a rating of 2 to what I don't like , in this case, the result of our estimates gives, despite the differences of our opinion, the sum of the ratings is 6 + 2 = 8, while the average will be 4 - the effect of my opinion will be greater, which erases your rating!
When using a rating scheme, you should try to use the entire dynamic range, in which case you will have a much greater impact on the final average - provided that it will be considered, as in most such cases, a blind averaging of the assigned ratings. Remember that coding theory says that entropy (mean deviation) is maximum when the distribution is uniform. You have the most information when all assessments are used equally, as you know from chapter 13 “Information Theory”.
If you consider assigning grades in a course as a communication channel, then, as just noted, equal use of the frequency of all grades will give the maximum amount of information - while typical for postgraduate studies the use of the two highest grades, A and B, is significantly reduces the amount of information transmitted. I understand that the Naval Academy uses rank in the classroom, and, in a sense, it is the only defense against “rating inflation” and the inability to use the entire dynamic range of the scale evenly, while giving the maximum amount of information, taking into account the fixed alphabet for assessments. The main mistake that arises when using a rank as a rating is when all very good people will be in a certain class, but some of them still have to be at the bottom!
It also raises the question of how you initially attract people to a certain area of activity. In psychology, it can often be noted that people entering a new field have much more confusion in their heads than the average professor and the average student in college — the courses have less of an effect on this, although I suspect that they help confuse the student further, but The initial choice has a much greater impact. Similarly, the exact sciences and the humanities have their own attractive and negative aspects, based more on the originally perceived features of the field, and not necessarily on the actual features of the field. Thus, people tend to enter areas of activity that will favor their characteristics, how they perceive them, and then, when they enter the area of activity, these features will often be further enhanced. The result - poorly balanced, but highly specialized people, without whom it is often impossible to do to achieve success in the current situation.
In mathematics and computer science, there is a similar effect of initial selection. At earlier stages of studying mathematics up to mathematical analysis, as well as in computer science, assessments are closely related to the ability to take into account a large amount of parts with high reliability. But later, especially in mathematics, the qualities necessary for success change, it is required to prove more theorems, better abilities to reason and assume new results, theorems and definitions that will be important. Still later, the ability to see the entire region as a whole, and not a lot of fragments, comes to the fore. But the evaluation process has largely eliminated many of those you would like to use, and who would really be needed at a later stage! A very similar situation is in computer science, where the ability to cope with a mass of software details favors one type of mind, which often negatively correlates with a vision of a more general picture.
The Department of Personnel Employment also affects who is recruited into the system. If recruiting is required for research, then a typical human resources officer in a large organization will most likely not want to attract the right people. Due to the fact that good researchers have originality of thinking in science and technology, they are usually original in other aspects of their behavior and clothes, and this means that they do not attract a typical recruiter from the personnel department. Consequently, as in Bell Telephone Laboratories, usually research people fail when they try to get a job in the research area, and the personnel department shudders! This is not a trivial moment, since the recruitment of one generation determines the next generation of the organization.
There is also a vicious promotion feature in most systems. At higher levels, the current participants choose the next generation - and they tend to choose people like themselves, people with whom they will feel comfortable. The board of directors of the company has strong control over the officers and future members of the board of directors nominated for elections (the results of which are often more or less predictable). You are prone to reproduction of your own kind (“inbreeding”), but also you, as a rule, acquire features of the organization. Consequently, a common method of advancement of one’s choice at higher levels of organization has both good and bad traits. This question is still on the topic “You get what you measure,” because there is a certain question of assessment here, and the criteria used, although unconscious, still exist.
In the distant past, most of the faculties of mathematics (a topic with which I am more familiar than for other fields) adhered to the general rule that they did not hire their own graduates to fight "inbreeding". The rule is not so widely applied now, as far as I can see, on the contrary, it seems that there is a tendency to prefer to hire our own graduates over outsiders. There were several cases in which economics departments were so “inbreeding” that the university’s top management had to intervene and carry out a hiring procedure, so to speak, through the “corpses of professors” in order to organize a reasonable balance of different opinions at the university. The same thing happened in the faculties of psychology, law, and, without doubt, in others.
As already mentioned, the rating system, which allows those inside, to choose the next generation, has both good and bad features, and requires careful testing in order to prevent too much “inbreeding”. Some “inbreeding” means a common point of view and a more harmonious work day by day, but probably will not allow for greater innovation in the future. I suspect that in the future constant change will be the normal state of affairs, and this topic will become more important than it was in the past, and it definitely was a problem in the past!
I believe that you understand the fact that I am not trying to be too picky in this respect; rather, I am trying to illustrate the topic of this chapter - “you get what you measure”. This is rarely thought of by people setting ratings, measuring methods or other registration schemes for things, and yet in the long run it has a huge impact on the entire system - usually in areas that they never thought about at all!
Although the measurement is clearly bad when it is unsuccessful, there is still no way to avoid measurement, evaluation of things, people, etc. At the same time, only one person can be the head of the organization, and the selection should use education rated on a simple rating scale so that to make a comparison. Despite the fact that people are at least as complex as vectors, and probably even more complex than matrices or tensors of numbers; a complex person, plus the effect of the environment in which he works, must somehow be reduced to a simple measure that will produce an ordered array of options.
This procedure can be performed in the mind, without common sense, but it should be done regardless of whether you believe in the rating of people or not - this cannot be avoided in any society where there are differences in rank, management capabilities, or any other function. you wish. Even in the entertainment program there must be the first and the last performer - all cannot be put on the same queue. You may hate judging people like me, but this must be done regularly in our society, and in any society in which there is no absolute equality, this should happen very often. You can also accept this fact and learn how to do this work more efficiently than most people - they just continue to make choices, rather than thoroughly analyze the whole process, and observe how others do it, and learn from them.
Now you see, I hope, how different measurement scales affect what comes out of it. They are of fundamental importance, but they usually receive very little attention. To highlight what I’m talking about, I’ll just tell you more examples of how the measurement scale affects the system.
Earthquakes are almost always measured on the Richter scale, which effectively uses the logarithm of the estimated amount of energy in an earthquake. I'm not saying that this is a wrong measuring scale, but its effect is that you have few really strong earthquakes with a magnitude of 7 and 8, and a lot of weak ones with a magnitude of 1 and 2. Think about it. I do not know the distribution on the mother-nature scale, but I doubt that it uses the Richter scale. Linear transformations, for example, from feet to meters, are not complex, but other non-linear scale transformations are another matter.
Most of the time, we measure incentives applied to people on a logarithmic scale, but for weight and height we use linear scales. They make it easy to add additivity, but for non-linear scales you don’t have this capability. For example, when measuring herd size, you tend to count the number of animals in a herd. Thus, you have additivity - combining two herds together gives the correct amount of combined herds. If you have a herd of 3 heads and the same number is added to it, this is one thing, but if you have a herd of 1000 heads and a herd of 3 heads is added to it, this is quite another thing - therefore, the additivity of the number in the herd not always the proper measure to use. In this case, the percentage change may be more informative.
How, then, decide which scale to use when measuring things? I do not have a simple answer.Indeed, I have a terrible observation that one measurement scale is suitable for one type of results in some area, another measurement scale may be more suitable for some other type of results in the exact same area! But how rarely is it recognized and used! Of course, you can sometimes observe that we calmly do the transformation when we apply the established formula, but it is difficult to decide which scale of measurement to use in each particular case. Much depends on the field and existing theories, as well as new theories that you hope to find! All this does not really help you in any particular situation.
There is one more question I mentioned in the previous chapter, and now I must return to it. This is the rate at which people respond to changes in the rating system. I told you how there was a constant battle between me and computer users, I tried to optimize the performance of the system as a whole, and they tried to optimize their own usage scenarios. Any change in the rating system that you think will improve the performance of the system as a whole will not work well unless you think about how people respond to the change - they will certainly change their behavior. You only need to think about your own career optimization, how changes in the rating system in the past have changed some of your plans and strategies.
Some measurement systems obviously have bad features, but traditions and other subtleties support their existence. For example, the state of readiness of the military unit. In the navy, ships are checked on a regular basis, one standard function after another, and the skipper gets the ship and crew ready for each one, largely neglecting the others, until they show up. Of course, the skipper gets high points. But when we encounter military teachings, what is the true readiness of the fleet? Surely not the same as the reports say - as you can easily imagine. But what then should we use? Of course, we have to use the given data - we would not be trusted if we used other data! Thus, we teach people in military exercises to use an idealized fleet,not real! The same thing happens in business games: we train leaders to win in a simulated game, not in the real world. I leave this moment to you to think about how you will act when you are responsible, and you want to know the true readiness of your organization. Will random checks decide everything? Not!But they will improve the situation a little.
Every organization faces this problem. Now you are at low levels in your organization, and see for yourself what is reported about events and how reports are different from reality, and nothing will change, as long as you do not get the power to radically change the situation. The air force allegedly uses random inspections, but like my friend, a retired fleet captain, once I noticed, every base commander has a radar and knows what is in the air, and if the inspection team was a surprise to him, then he must be a fool. However, in this case, he has less time to prepare than in the case of scheduled inspections, therefore, apparently, inspection reports are perhaps closer to reality than when inspections take place only at a time known in advance. Yes,inspections are measurements, and you “get what you measure”. This situation is not too different in other organizations - the news about the upcoming measurement (inspection) "breaks gossip on the vine", and the addressee of the news, pretending to be surprised, is often ready for it in the morning.
Another thing that is obvious, but I think it needs to be mentioned; the popularity of one or another form of measurement is little related to its accuracy or relevance for the organization.
One more note - everything from top to bottom in the organization, each person refracts the facts so that they themselves look good - at least from their point of view! The only thing that saves top management is that different levels below, each of which can slightly refract facts, often have different goals, and therefore many changes of facts most often partially cancel each other due to the weak law of large numbers. If the whole organization works together to fool the top, then management can do little about it. When I was on the Board of Directors, I was so clearly aware of this fact that I often came either a day earlier, or was delayed a day later, and just wandered around asking questions, looking and asking myself if there were any facts that were reported. For example, one day, when the warehouse stock was very large,Because of the change in the lineup of computers we were making, which made us have parts of both lines on hand at the same time, I walked, suddenly turned to the storeroom and just entered. Then I looked around to decide whether, in my opinion, any significant discrepancy or amount reported was sufficiently accurate.
Again, were the computers that we had to ship to the loading dock, or were they mythical, as happened in many companies? Sniffing around, I found that at the end of each quarter, the cars that had to be sent were actually sent, but often in the process of releasing later machines on the production line, and therefore the next few weeks were spent returning the cars in proper condition. I could never stop this bad habit of employees, even though I was on the Board of Directors! If you only look around in your organization you will find a lot of weird things that shouldn’t really happen, but they are considered a common practice by staff.
Another strange thing that happens is that at one level it is considered as one, otherwise it is considered at a higher level. For example, it often happens that assessments of an organization’s capacity at one level are interpreted as probabilities at a higher level! Why is this happening? Just because a lower level cannot accomplish what the higher wants and therefore does what he can do, and a higher level deliberately, because he wants to get his numbers, he prefers to change the meaning of the reports.
I have already discussed the question of life tests - what can be done and what is needed is not at all the same! At the moment we do not know how to produce what is needed; to ensure reliability for many years of work with a high level of confidence in parts that were first delivered to us yesterday. This problem will not disappear, but much can be done to design the necessary reliability of things. One of my first tasks at Bell Telephone Laboratories was the development of a series of concentric rings made of copper and ceramics, such that for given radii, when the temperature changed, ceramics would always be compressed and never stretch, since it has low strength. The design has a degree of reliability built into it! In my opinion, too little has been done in this direction, but, as I have already noted, when they said that there was no time for that,"There is never time to do the job right, but there is always time to fix things later."
There are rating systems in which some degree of human judgment is embedded - and that sounds good. But let me tell you a story that impressed me a lot. I developed a computational method for estimating phase shifts from measured gains at various signal frequencies, which replaced the manual method. I do not claim that it was better, but the manual method could not solve the new problem when we moved from voice to TV band range. One clever man once told me: “Before when people were doing things, we could not make further improvements due to random human variations; now that you’ve deleted a random item, we can hope to find out things that weren’t obvious before. ” Assessment methods that do not have human judgment have some advantages, but do not considerthat I am opposed to putting the element of human judgment. Most formal methods are necessarily finite, and the complexity of reality is almost endless, so reasonably applied human judgment is often a good thing — although, as has just been noted, it stands in the way of further progress with its subjective aspects.
From all of this, please do not conclude that measurement cannot be done - it may be clear, but the question of relevance and the effects of the form of measurement should be thought out as best you can before you start any new dimension in your organization . The inevitable changes that will occur in the future, and the increase in the power of computers to automatically monitor things, means that many new measurement systems will be used, which you yourself will have to develop, create and install. So let me tell you another story about the effects of measurement.
In computer science, the complexity of programming is often measured by the number of lines of code — what could be simpler? From the point of view of the coder, there is absolutely no reason to try to clear the code fragment; on the contrary, in order to get a higher rating on the performance scale, there is every reason to leave unnecessary instructions there; indeed, turn on a few “bells and whistles” if it is possible. This indicator of software performance, which is widely used, is one of the reasons why we have such bloated software systems these days. It does not encourage the development of clean, compact and reliable code that we all need. In addition, the measure used affects the outcome in ways that damage the entire system! It also creates habits that are difficult to get rid of later.
When it is your turn to install a measuring system, or even comment on what someone else is using, try to think about your path to all the hidden consequences that will happen to the organization. Of course, in principle, measurement is good, but it can often do more harm than good. I hope the idea is loud and clear:
You get what you measure.
To be continued...
Who wants to help with the translation - write in a personal or mail magisterludi2016@yandex.ru
By the way, we also launched another translation of the coolest book - "The Dream Machine: The History of Computer Revolution" )
Book content and translated chapters
— magisterludi2016@yandex.ru
- Intro to The Art of Doing Science and Engineering: Learning to Learn (March 28, 1995) ( ) : 1
- «Foundations of the Digital (Discrete) Revolution» (March 30, 1995) 2. ()
- «History of Computers — Hardware» (March 31, 1995) ( )
- «History of Computers — Software» (April 4, 1995) 4. —
- «History of Computers — Applications» (April 6, 1995) ( )
- «Artificial Intelligence — Part I» (April 7, 1995) ( )
- «Artificial Intelligence — Part II» (April 11, 1995) ( )
- «Artificial Intelligence III» (April 13, 1995) 8. -III
- «n-Dimensional Space» (April 14, 1995) 9. N-
- «Coding Theory — The Representation of Information, Part I» (April 18, 1995) ( )
- «Coding Theory — The Representation of Information, Part II» (April 20, 1995)
- «Error-Correcting Codes» (April 21, 1995) ( )
- «Information Theory» (April 25, 1995) ( , )
- «Digital Filters, Part I» (April 27, 1995)
- «Digital Filters, Part II» (April 28, 1995)
- «Digital Filters, Part III» (May 2, 1995)
- «Digital Filters, Part IV» (May 4, 1995)
- «Simulation, Part I» (May 5, 1995) ( )
- «Simulation, Part II» (May 9, 1995)
- «Simulation, Part III» (May 11, 1995)
- «Fiber Optics» (May 12, 1995)
- «Computer Aided Instruction» (May 16, 1995) ( )
- «Mathematics» (May 18, 1995) 23.
- «Quantum Mechanics» (May 19, 1995) 24.
- «Creativity» (May 23, 1995). : 25.
- «Experts» (May 25, 1995) 26.
- «Unreliable Data» (May 26, 1995) ( )
- «Systems Engineering» (May 30, 1995) 28.
- «You Get What You Measure» (June 1, 1995) 29. ,
- «How Do We Know What We Know» (June 2, 1995)
- Hamming, «You and Your Research» (June 6, 1995). :
— magisterludi2016@yandex.ru
Source: https://habr.com/ru/post/350144/
All Articles