Compiler bug? Linker? No, Windows kernel bug
 Heisenbag is the worst thing that can happen. In the study described below, which stretched for 20 months , we have already reached the point where we began to look for hardware problems, errors in compilers, linkers, and other things that should be done at the very last. Usually, it is not necessary to translate arrows in this way (the bug is most likely in your code), but in this case we are on the contrary - we didn’t have enough of a global view of the problem. Yes, we did find a bug in the linker, but in addition to it we also found a bug in the Windows kernel.
Heisenbag is the worst thing that can happen. In the study described below, which stretched for 20 months , we have already reached the point where we began to look for hardware problems, errors in compilers, linkers, and other things that should be done at the very last. Usually, it is not necessary to translate arrows in this way (the bug is most likely in your code), but in this case we are on the contrary - we didn’t have enough of a global view of the problem. Yes, we did find a bug in the linker, but in addition to it we also found a bug in the Windows kernel.In September 2016, we began to notice randomly occurring errors when building Chrome - 3 builds out of 200 failed due to the crash of the protoc.exe process. This is one of the binaries, which when assembling Chromium is first assembled by itself, and then launched to generate header files for other components. But instead, it fell with an “access violation” error.
The developers who investigated this problem understood that something strange was happening, but could not reproduce the problem locally, so they had to guess about its causes. Several corrections were made at random - changing the order of the arguments , explicitly adding dependencies . The latter seemed to work - the problems disappeared.
But now, literally a couple of days after the bug was celebrated for a year from the day it was created, the problem arose again. The heavens opened and a loud alarm sounded about the build of the project. Over the next few months, about 10 different fixes were added in an attempt to rectify the situation. Something they may have improved, but according to the statistics of the success of the assembly, it was clear that none of them solved the main problem.
')
Local reproduction of the problem
I joined this research almost by accident - I once managed to reproduce a bug on my machine. I ran the “bad” binary under the debugger and saw the following:
… 00000001400010A1 00 00 add byte ptr [rax],al 00000001400010A3 00 00 add byte ptr [rax],al mainCRTStartup: 00000001400010A5 00 00 add byte ptr [rax],al 00000001400010A7 00 00 add byte ptr [rax],al … Now we have a problem that we can at least put into words: why are large pieces of a code segment of a binary filled with zeros?
I deleted the "bad" binary and linked it again - this time the zero byte sequences were replaced with the correct instructions and it did not fall again. A long array of zero bytes belonged to the code that created the VC ++ incremental linker so that somehow it is more convenient for it to transfer functions. At this point, it became obvious that we found a bug in the incremental linker, right? It was impossible to disable it completely - incremental linking is an important part of the strategy for optimizing the build time of large binaries (like our chrome.dll). But we could disable it for smaller binaries like protoc.exe and the like. So we did.
And it helped fix this particular bug in this particular case. But, as it turned out, this was not the bug that we were actually looking for and which broke most of our builds.
Two weeks later, Chrome assembly fell on my computer again. And it was already an assembly that included the previous fix with disabled incremental linking for protoc.exe. This time there was again an array of zero bytes in the binary instead of the correct code instructions, but it was already in the code, the creation of which the incremental linker had no relation to.
Moreover, these zero bytes were already inserted into the code by another tool — by this time I switched from the linker from Microsoft to lld-link (use_lld = true in the build parameters). Moreover, this time I and the compiler used another (clang instead of VC ++). It turns out that replacing the entire assembly toolchain in general did not help fix this problem. This means that the problem is not in the toolchain. By this time, mass hysteria seemed to be the best explanation for what was happening.
But no, we have science!
No wonder the tools and methods of development and debugging have been improved for many years . We have something that we can oppose to the heisenbags. The bug was reproduced on my computer more often than on the others, since I was then engaged in optimizing the Chrome build, and I made these assemblies significantly more than the average programmer (even much more than other Chrome developers). Well, if you need a lot of builds to play a bug, so let's do a lot of builds.
I changed my scripts to build Chrome again and again in an infinite loop, which should stop only when the bug makes itself felt. With the system of distributed assembly and the minimum level of generation of symbolic information, I could (with good luck) collect Chrome up to 12 times per hour. With such a frequency of assemblies, even so rarely reproduced a bug began to occur steadily at least once every half day. Besides him, of course, other bugs ( zombies! ) Began to emerge, but this is another story.
And then I suddenly got lucky. One morning I logged into my computer, which drove the Chrome assembly all night and saw that the genmodule.exe module had crashed (and different binaries were falling every time). Since the build was stopped at that, I had exactly the same binary on the disk, whose launch caused the crash during the build. And I decided to start it again - it is always more interesting to see a “live” crash than to dig into the old dumps. But this time the binaries did not fall.
I had crashes (because Windows Error Reporting on my computer was configured to save local crash dumps , which I advise all Windows developers to do). In this cracksdump, I saw a sequence of zeros already familiar to me at the point where the code was executed. This sequence of instructions didn’t, in any theory, could be executed without error. I ran the genmodule.exe binary again under the debugger, reached the same address - and there was a normal code, no zeros.
I downloaded the crash dump in WinDbg and typed “! Chkimg”. This command compares the bytes of the commands in the crash dump with the corresponding bytes in the binary image on the disk. This can be useful, for example, in cases of hardware failures of RAM or HDD, as well as patch errors. I have seen cases where up to several tens of bytes were subject to change for the above reasons. In this case, the binary on the disk and the executable code from the crash dump differed in 9322 bytes .
Perhaps in this place, when the executable code of the binary in memory does not match the bytes in the image of this binary on the disk, it is too sensitive of you to stop reading. In fact, what next to believe in? But still continue!
Now we can formulate the problem even more specifically: why do we execute the wrong code that the linker wrote in the binary?
It began to look like a bug in the Windows file system. Perhaps something related to caching. It looked as if the file loader was reading pages with zero bytes when reading a binary from the disk instead of actually written by the linker to the instruction file.
My colleague Zack advised me to run the sync utility from sysinternals after the linker was done. I refused at first - the sync launch is very resource intensive and requires administrative rights, but in the end I gave up and decided to run this test. Over the weekend I collected Chrome from scratch more than 1000 times, with administrator rights, in three different versions:
- Normal build : drops in 3.5% of cases
- 7-second pause after the end of the linker : a fall in 2% of cases
- Running sync.exe after the linker is finished : a single crash
Hooray! Running sync.exe is, of course, not fixing the problem (it is very resource intensive), but already something! The next step was a small C ++ program that opened the newly linked binary and called FlushFileBuffers for it. It worked much faster and did not require administrative rights. And it also prevented the crash bug for 100% of the builds. The final step was to rewrite it in Python, add the main Chrome branch to the assembly and write a tweet about it.
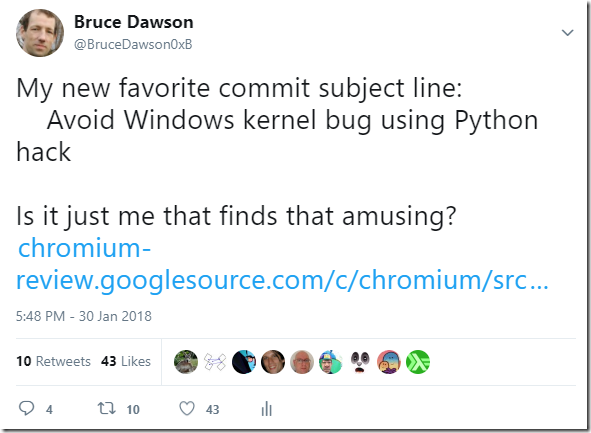
Later that day (I didn’t even have time to send the official bug report to Microsoft) - I received a letter from my former colleague, who now works at Microsoft, who asked about this bug from my tweet.
I shared with him my findings and research methodology. He and his colleagues tried to reproduce the bug - but they failed. Perhaps because they didn’t run Chrome as many times as I did. But they helped me set up ETW - a tool that can record a very detailed log of events occurring in the system and stop recording at the time of the error. After several attempts I managed to reproduce the bug and write down the ETW-log. I sent it to the guys from Microsoft - I hope it helps them understand the problem.
The problem was that when the linker writes a PE file (EXE or DLL) using the Memory Mapped File mechanism and the program then immediately starts (or the library is loaded by calling LoadLibrary / LoadLibraryEx) and the OS is currently under heavy load on / output, the flush call may fail. This is a very rare event, and I can imagine its appearance only on build servers, like my 24-processor monster when building very large projects, such as Chrome. Microsoft programmers confirmed that my solution with forced Flush after the end of linking should help fix the problem (I also came to this conclusion, because by this time I had received about 600 consecutive builds without a single crash) and promised to make a correction to the Windows kernel.
If you want to understand yourself
Most likely you will not be able to reproduce this bug in a reasonable time on your home computer. I laid out the cracks, corresponding binary and symbol file on GitHub . You can load them into Visual Studio and see the zeros I mentioned above. You can also load them into WinDbg and use the! Chkimg command:
0:000> .sympath . Symbol search path is: . 0:000> .ecxr eax=cbb75f7e … re2c!mainCRTStartup: 00412d40 0000 add byte ptr [eax],al ds:002b:cbb75f7e=?? 0:000> !chkimg 9658 errors : @$ip (00408000-00415815) 0:000> uf eip re2c+0x12d40: 00412d40 0000 add byte ptr [eax],al 00412d42 0000 add byte ptr [eax],al 00412d44 0000 add byte ptr [eax],al 00412d46 0000 add byte ptr [eax],al Difficulties in the study
1) Build Chrome causes the CcmExec.exe process to lose handles, which multiplies the zombie processes, I wrote a separate article about it.
2) Most Windows developers have seen the number 0xC0000005 many times to remember that it means Access Violation. That is, your program turned to the area of memory where it was absolutely not worth contacting. But few people can look at the numbers 3221225477 or -1073741819 and say what they mean. And in fact, this is the same number 0xC0000005, deduced as a signed or unsigned decimal integer. Your eye will always catch on 0xC0000005, but at the sight of a negative number of a couple of billions you will not have a single thought.
3) When examining this bug ( crbug.com/644525 ), another one was found ( crbug.com/812421 ). I was worried that it was the same bug or two interconnected, but it turned out that they were two completely different stories. The first bug was completed with everything described in this article above, and the second concerned Control Flow Guard - protection against the exploitation of certain types of vulnerabilities. It turned out that sometimes using problems with incremental linking and control flow guard. The simple solution was to update our build configurations so that the / incremental and / cfg keys are never used together (this makes little sense anyway).
Epilogue
We still do not know what caused this problem to affect us. Perhaps this is our transition to a new build system, which somewhat changed the order of steps in this operation.
Also, we do not know why the bug, having appeared once, suddenly disappeared for a whole year. Perhaps it was generally several different bugs, one of which was accidentally fixed in the past? Or are we just lucky?
In any case, after our latest fixes, Chrome has become more stable. I can again run a series of my build performance tests without the risk of failing.
My problem fix works reliably for all combinations of compilers and linkers. If you are working on a program that creates executable binaries, then you should also add something like calling FlushFileBuffers before closing the file. (I, for example, sent an internal bug to the Go developers). The problem is currently reproduced on all versions of Windows from 7 to the last 10 with all the installed updates, so take care to fix it if this concerns you.
Source: https://habr.com/ru/post/350126/
All Articles