Object classification in real time

Author: Igor Panteleev, Software Developer, DataArt
Image recognition is very widely used in machine learning. There are many different solutions in this area, but neither of them has met the needs of our project. We needed a completely local solution that can work on a tiny computer and transfer recognition results to a cloud service. This article describes our approach to creating an image recognition solution using TensorFlow.
')
Yolo
YOLO is an advanced real-time object detection system. On the official website, you can find SSD300, SSD500, YOLOv2 and Tiny YOLO, which have been trained with two different data sets: VOC 2007 + 2012 and COCO. You can find more options for machine learning configurations and data sets on the Internet (for example, YOLO9k). Thanks to the wide range of options available, you can choose the version that best suits your needs. For example, Tiny YOLO is the most “compact” version, which can work quickly even on smartphones or Raspberry Pi. We liked the last option, and we used it in our project.
DarkNet and TensorFlow
The Yolo model was developed for DarkNet- based neural network, for us some features of this solution are not suitable. DarkNet stores trained coefficients (weights) in a format that can be recognized using various methods on different platforms. This problem can be a stumbling block, because you may need to train a model on heavy-duty equipment, and then use it on other equipment. DarkNet is written in C and has no other software interface, so if the requirements of the platform or your own preferences force you to turn to another programming language, you will have to work further on integrating it. It is also distributed only in source code format, and the compilation process on some platforms can be quite problematic.
On the other hand, we have TensorFlow, a convenient and flexible computing system that can be used on most platforms. TensorFlow provides APIs for Python, C ++, Java, Go, and other community-supported programming languages . The default configuration framework can be installed with one click of the mouse, but if you want more (for example, support for specific processor instructions), you can easily compile from a source with automatic detection of hardware. Running TensorFlow on a GPU is also quite simple. All you need is NVIDIA CUDA and tenorflow-gpu, a special package with support for the graphics processor. A huge advantage of TensorFlow is its scalability. It can use multiple GPUs to improve performance as well as clustering for distributed data processing.
We decided to take the best of both worlds and adapt the YOLO model for TensorFlow.
Adaptive Yolo for TensorFlow
So, our task was to transfer the YOLO model to TensorFlow. We wanted to avoid any third-party dependencies and use YOLO directly with TensorFlow. First, we needed to transfer the model structure, the only way to do this is to repeat the model layer by layer. Fortunately for us, there are many open source converters that can do this. For our purposes, DarkFlow turned out to be the most suitable solution. We have added a simple function to DarkFlow, which allows us to save TensorFlow control points to metadata, its code can be viewed here . You can do it manually, but if you want to try different models, it is easier to automate this process.
The YOLO model we have chosen has a strict array of input data of 608x608 pixels. We needed some kind of interface that can take any image, normalize it and feed it to the neural network. And we have developed this interface. For normalization, it uses TensorFlow, which works much faster than other solutions we tested (native Python, numpy, openCV).
The last layer of the YOLO model returns functions that need to be converted into data of a certain form that people can read. We added some operations after the last layer to get the coordinates of the detection zone.
As a result, we developed a Python module that can restore the model from a file, normalize the input data, and then process the functions from the model to get the bounding fields for the predicted classes.
Model training
For our purposes, we decided to use a pre-trained model. Trained coefficients are available on the official YOLO website . The next task was to import DarkNet weights into TensorFlow, this was done as follows:
- Reading the layer data in the DarkNet configuration file;
- Reading the trained coefficients from the DarkNet scale file in accordance with the layer structure;
- Preparing the TensorFlow layer based on the data from the DarkNet layer;
- Add links in a new layer;
- Repeat for each layer.
For this we used DarkFlow.
Model Architecture and Data Flow

Usually with each iteration, the classifier makes an assumption as to what type of object is in the window. It performs thousands of predictions for each image. This slows down the process, as a result of which recognition work is rather slow.
The biggest advantage of the model YOLO, in fact, is reflected in the title - You Only Look Once. This model imposes a grid on the image, dividing it into cells. Each cell tries to predict the coordinates of the detection zone with an estimate of the confidence for these fields and the probability of the classes. Then, the confidence score for each detection zone is multiplied by the class probability to get the final score.

Illustration from YOLO website.
Implementation
In our GitHub repository, you can find a demo project, which is a pre-trained TensorFlow YOLO2 model. This model can recognize 80 classes. To start it, you need to install additional dependencies required for demonstration purposes (for the model interface, only TensorFlow is required). After installation, just run python eval.py , and it will capture the video stream from your webcam, evaluate it and display the results in a simple window with your predictions. The evaluation process is frame-by-frame and may take some time depending on the equipment on which it is running. On the Raspberry Pi, it may take several seconds to evaluate a single frame.
You can specify a video file for this script by passing an argument --video like this: python eval.py --video = "/ path_to_video_file /" . The URL of the video can also be transmitted (tested on YouTube): python eval.py --video = ” https://www.youtube.com/watch?v=hfeNyZV6Dsk ” .
The script will skip frames from the camera during the evaluation and take the next available frame when the previous evaluation phase is completed. For recorded video, it does not miss any frames. For most tasks, it is possible to skip some frames in order to ensure that the process works in real time.
Integration with IoT
Of course, it would be nice to integrate the IoT service into this project, as well as configure the delivery of the recognition results to where other services can access them.
There is another demo script - python daemon.py, which will launch a simple server that displays a video stream from a webcam with forecasts for
http://127.0.0.1:8000/events/.

It also starts the DeviceHive client. Configuration available on
http://127.0.0.1:8000/.

This allows you to send all the predicted information to DeviceHive in the form of notifications.
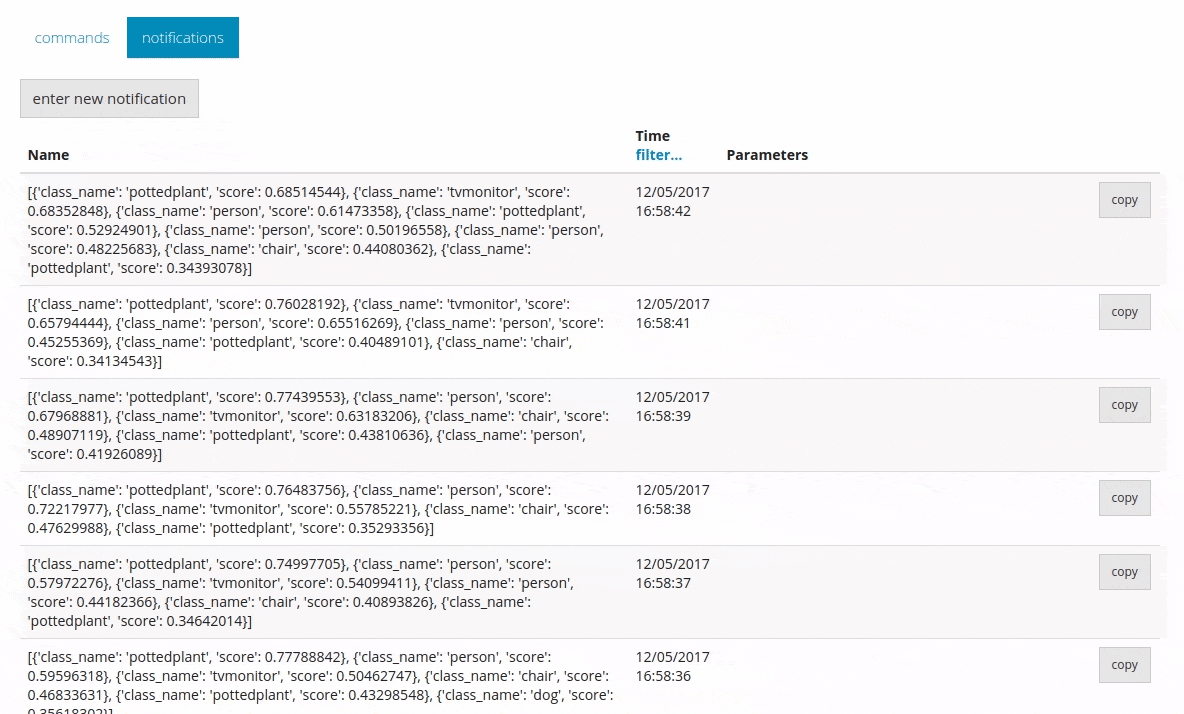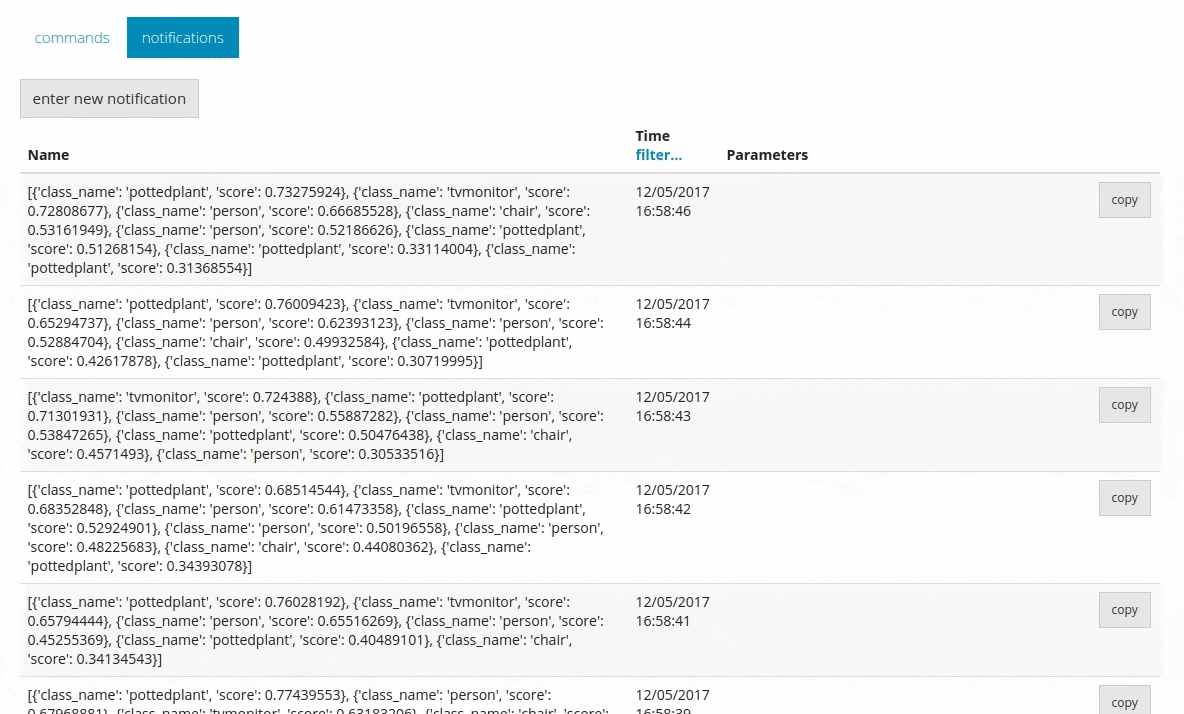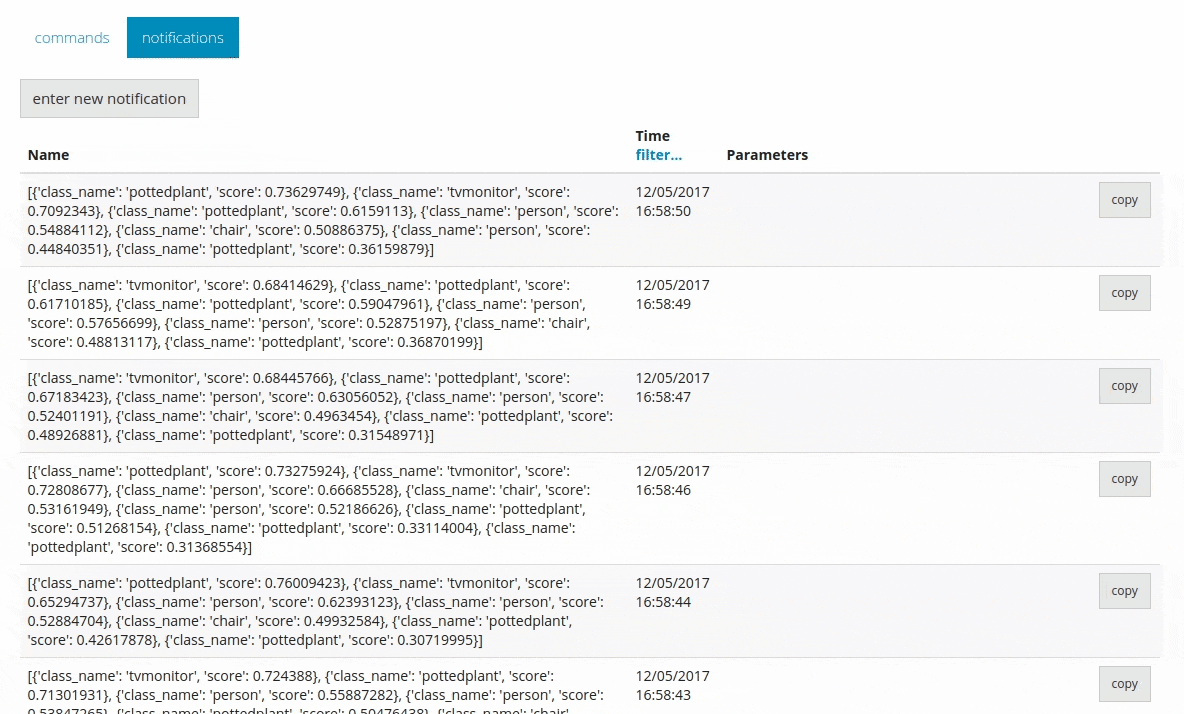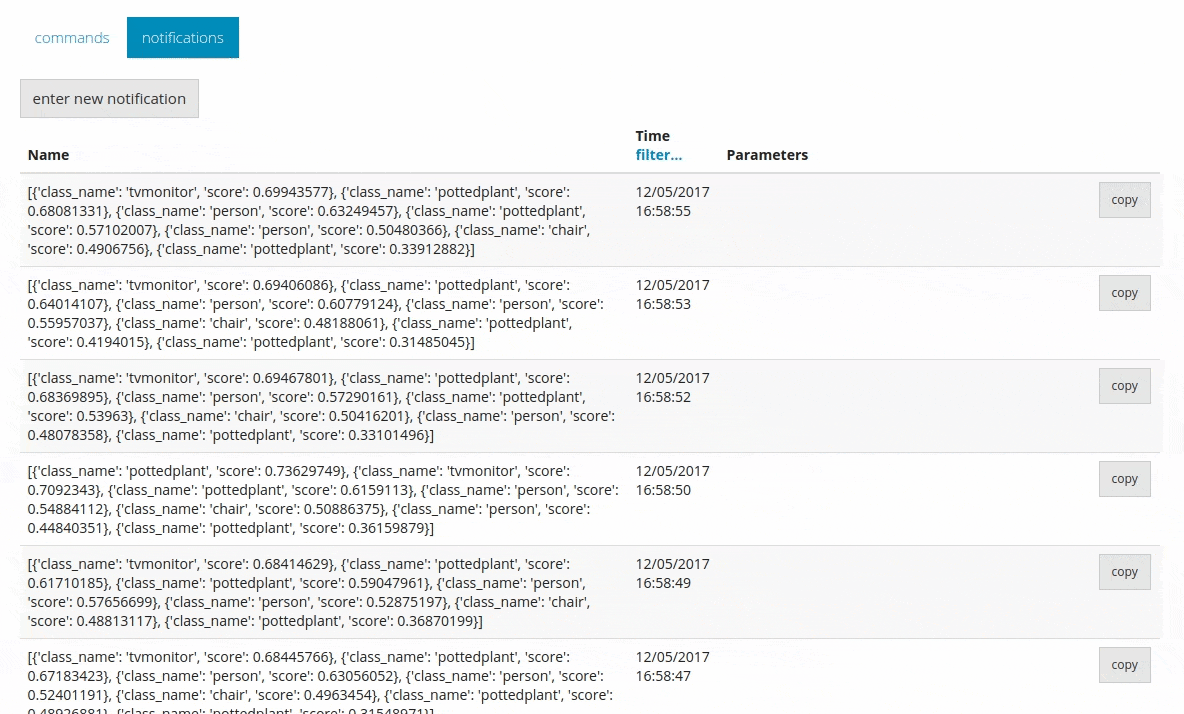
Conclusion
As you can see, there are many ready-made open source projects for almost any occasion; you just need to be able to use them correctly. Certainly, certain changes are necessary, but it is much easier to implement them than to create a new model from scratch. A huge advantage of such tools is their cross-platform. We can develop a solution on a desktop PC, and then use the same code on embedded systems with the Linux operating system and ARM architecture. We really hope that our project will help you in creating your own elegant solution.
PS During the development of the project and the preparation of the article for printing, OpenCV has gained support for YOLO within itself . Perhaps in some cases this solution will be more preferable.
Source: https://habr.com/ru/post/350120/
All Articles