Benchmark of Google's new tensor processor for deep learning

Each Cloud TPU device consists of four “TPUv2 chips”. The chip has 16 GB of memory and two cores, each core with two units for multiplying matrices. Together, the two cores issue 45 TFLOPS, a total of 180 TFLOPS and 64 GB of memory per TPU
Most of us provide in-depth training on the Nvidia GPU. Currently there are almost no alternatives. Google Tensor Processor (Tensor Processing Unit, TPU) is a specially designed chip for in-depth training that should make a difference.
Nine months after the initial announcement two weeks ago, Google finally released TPUv2 and opened access to the first beta testers on the Google Cloud platform. At RiseML, we took the opportunity and drove a couple of quick benchmarks. We want to share our experience and preliminary results.
')
For a long time we have been waiting for the emergence of competition in the market for equipment for in-depth training. It must break the monopoly of Nvidia and determine what the future depth learning infrastructure will look like.
Keep in mind that TPU is still in the early beta, as Google clearly and universally reminds - so some of the ratings discussed may change in the future.
TPU in the google cloud
While the first generation of TPUv1 chips focused on speeding up data output, the current second generation is primarily focused on speeding up training. At the heart of TPUv2 is the systolic array responsible for the multiplication of matrices that are actively used in depth learning. According to Jeff Dean's slides , each Cloud TPU device consists of four “TPUv2 chips”. The chip has 16 GB of memory and two cores, each core with two units for multiplying matrices. Together, the two cores issue 45 TFLOPS, a total of 180 TFLOPS and 64 GB of memory per TPU. For comparison, the current generation Nvidia V100 has only 125 TFLOPS and 16 GB of memory.
To use tensor processors on the Google Cloud platform, you need to run Cloud TPU (after receiving a quota for it). It is not necessary (and possible) to assign a Cloud TPU to a specific virtual machine instance. Instead, the TPU from the instance is accessed over the network. Each Cloud TPU is assigned a name and an IP address, which should be indicated in the TensorFlow code.

Creating a new Cloud TPU. Please note that he has an IP address. Animated gif
TPUs are supported only in TensorFlow version 1.6, which is still in release candidate status. In addition, no drivers are needed for the VM, since all the necessary code is included in TensorFlow. The code for execution on TPU is optimized and compiled by the JIT compiler XLA , also included in TensorFlow.
To use TPU effectively, the code must be based on high-level abstractions of the Estimator class. Then go to the class TPUEstimator , which performs many of the necessary tasks for the effective use of TPU. For example, configures data queues for the TPU and parallelizes the calculations between the cores. There is definitely a way to do without using the TPUEstimator, but we are not aware of such examples or documentation yet.
When everything is set up, run your TensorFlow code as usual. TPU will be detected when loading, the calculation schedule will be compiled and will be transferred there. Interestingly, TPU can also directly read and write to the cloud storage control points and summaries. To do this, you need to allow entry to the cloud storage in your Cloud TPU account.
Benchmarks
Of course, the most interesting thing is the real performance of tensor processors. The TensorFlow repository on GitHub has a set of tested and optimized TPU models . Below are the results of experiments with ResNet and Inception . We also wanted to see how a model that is not optimized for TPU is being calculated, so we adapted the model to classify text on the long short-term memory architecture (LSTM) to run on TPU. In fact, Google recommends using larger models (see the “When to use TPU” section ). We have a smaller model, so it’s especially interesting to see if TPU gives any advantage.
For all models, we compared the learning speed on a single Cloud TPU with a single Nvidia P100 and V100 graphics processor. It should be noted that a full-fledged comparison should include a comparison of the final quality and convergence of models, and not just throughput. Our experiments are only superficial first benchmarks, and leave a detailed analysis for the future.
Tests for TPU and P100 were launched on n1-standard-16 instances of the Google Cloud platform (16 Intel Haswell virtual CPUs, 60 GB memory). For the V100 graphics processor, p3.2xlarge instances on AWS were used (8 virtual CPUs, 60 GB of memory). All systems under Ubuntu 16.04. For TPU, install TensorFlow 1.6.0-rc1 from the PyPi repository. Tests for GPUs were launched from nvidia-docker containers with TensorFlow 1.5 images ( tensorflow: 1.5.0-gpu-py3 ), including support for CUDA 9.0 and cuDNN 7.0.
TPU-optimized models
Let's look first at the performance of models that are officially optimized for TPU. The following shows the performance by the number of processed images per second.
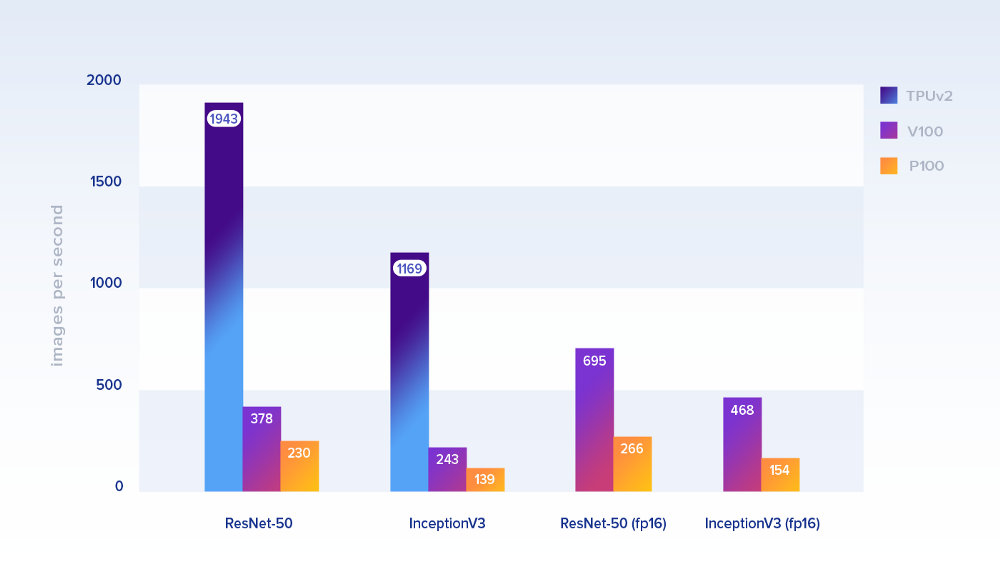
Package sizes: 1024 on TPU and 128 on GPU. For the latter, they took the implementation from the TensorFlow benchmarks repository. As training data, simulate Google’s ImageNet dataset in cloud storage (for TPU) and on local disks (for GPU)
On the ResNet-50, a single Cloud TPU tensor processor (8 cores and 64 GB of RAM) was about 8.4 times faster than one P100, and about 5.1 times faster than a V100. For InceptionV3, the performance difference is almost the same (~ 8.4 and ~ 4.8, respectively). On calculations with lower accuracy (fp16), the V100 adds significantly to speed.

It is clear that in addition to speed you need to take into account the price. The table shows the performance, normalized by price with every second billing. TPU still clearly wins.
Custom models LSTM
Our custom model is a bidirectional LSTM for text classification with 1024 hidden units. LSTM are the main building blocks in modern neural networks, so this is a good addition for official machine vision models.
The original code has already used the Estimator framework, so it is very easy to adapt it for TPUEstimator. Although there is one big caveat: on TPU we could not achieve the convergence of the model , although the same model (packet size, etc.) on the GPU worked fine. We think this is due to some bug that will be fixed - either in our code (if you find it, let us know!) Or in TensorFlow.
It turned out that TPU provides an even greater increase in performance on the LSTM model (21402 samples / s): ~ 12.9 times faster than P100 (1658 samples / s) and ~ 7.7 times faster than V100 (2778 samples /with)! Given that the model is relatively small and has not been optimized in any way, this is a very promising result. But until the bug is fixed, we will consider these results preliminary.
Conclusion
On the tested models, TPU performed very well both in terms of performance and in terms of money saving compared to the latest generations of GPUs. This is contrary to previous estimates .
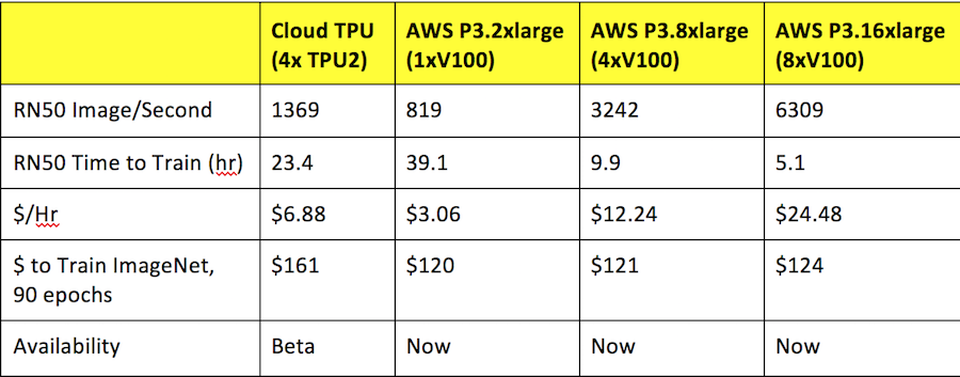
The results of previous benchmarks. Source: Forbes
Although Google is promoting TPU as the optimal solution for scaling large models, our preliminary results on a small model have proved very promising. In general, the experience of using TPU and adapting the TensorFlow code is already quite good for the beta version.
We believe that when TPU becomes available to a wider audience, it can be a real alternative to the Nvidia GPU.
Source: https://habr.com/ru/post/350042/
All Articles