Rake when moving to a virtual platform with physical hardware
There is a company like a small chain of stores, production or scientific institute. At some point, comes the understanding that we need our own servers in the cloud. A plan is bought, tests are done, then the move begins.
And then we, as a platform, begin to take it and beat ourselves in the face, because customers are starting to complain that something in the cloud is not working that way. The problem is - at least in 80% of cases - in architecture, another part is in the desire to save the last penny, and we have only a few last percent.
')
For example, the database is located on 7K disks and on a weak virtual machine. Why is that? Because the desired performance is estimated on average. And in real business there is no medium: usually it is a chain of small peaks between the practical absence of workload. At stores, little is happening at night, at scientific research institutes - between long calculations.
I'll tell you a little more about typical situations.
Ruta
Quite a literacy campaign, but we often see root-access over SSH on Linux machines and life without updates on Win-machines. Why is it important? Because there are viruses like "Petit". Of course, clients often say that they are not personally needed by anyone and no one will attack them. But botnets do not care - they are breaking on all devices on the network and sorting out vulnerabilities and passwords.
Good practice is to do authentication by keys, not passwords and close the “extra” ports. Ideally, use access tables. Moving is a good reason to set up, update ACL lists, put out only those services that are really needed from a large Internet.
It sounds pretty simple, but many are already burning on this. Because many people in IT in an ordinary business (like ice-cream production or a car service) somehow many years ago set up someone, and they still live, do not touch anything. Then layers of new features grow on top of this, and as a result, they start digging in archeology only when something is not working. Not preventive.
Naturally, we don’t climb into the client systems, we simply provide the infrastructure: we are a maintenance service. But we help with the move, and sometimes they share this pain with us. We can do an audit and resolve all issues. True, some prefer to step on the rake themselves, and only then they order an audit.
One client, for example, did not create ACL lists at all - put all the machines with a bare ass on the Internet. I caught Petya, just povyrubal everything and re-deployed the virtuals. Then it helped: we passed the recommendations, but, most likely, will apply them from the second time. Now we fasten the perimeter scan automatically so that the notifications reach it in advance.
Example of standard ACL setting by clients:

Parallelism
Clients often have poor services building architecture: they use virtualization as physics. There is one fat virtual machine, and if with it a pack, then the business gets cancer. No load balancers, no parallelization of server load, no replication. The beauty of the clouds is that VM can be a lot. This is not necessary:

And here it is necessary:

More often, these rakes are attacked by those who had a half-rack in the office. Stood a server - fat VM on 16 GB. Scaling it - the addition of memory and disk. And it is necessary to put excess machines and a balancer.
Legacy on iron
The next part of the story is dragging everything that is already in use into the cloud, but has long been out of date. For example, many people want to drag in their network rules and firewalls, because their entire network is placed on them. And the network is already different, and the old principles can be applied to it in backward compatibility mode, of course, but it is better to just take a normal tool and make a new one.
The result of working with Legacy: in order to maintain the necessary functionality, people begin to install all sorts of third-party products to protect their structure in terms of security, for example, pfSense. Spent on resources, although much is being done at all by the built-in cloud, for example, the NSX Firewall.
It is enough to figure out how to configure them, and not put your own inside the cloud. Read the instructions on the access and subnet lists and implement it with the help of the cloud, and not raise individual VMs.
Of course, the built-in tools are not always perfect, because someone needs to read the logs, and their tools solve individual problems better. But without the need to better throw off this ballast.
End-to-end resources
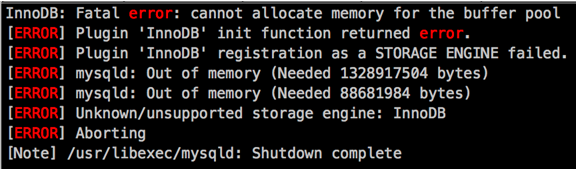
Quite often there is the most severe savings on virtual machines. The base is 28 GB, and the virtual machine is given 4 GB of memory. With large requests, departures start with actions, or just everything slows down. Let's increase the memory? No, we must try to optimize! For now it will be released, let it choke.
Or, for example, if you need to deploy an additional machine, people get an error and think for a long time what to do with it. Roughly speaking, resources purchased back to back do not allow making a snapshot, they cannot normally restore the machine from a backup, etc. A lot of resulting problems that will gradually expand. We advise to expand the resource: otherwise - no way.
A subtype of this error is the calculation of the physical cores. When an admin physicist comes in who has not worked with a virtual environment before, he often misses the few percent of the load that the hypervisor gives, and as a result counts on the cores, one to one with his past system.
The downside: of course, resources cost money. Almost all customers are trying to save as much as possible, trying to squeeze out of cars as much as possible. Savings for large companies - about 60 thousand rubles per month. And it is not clear whether the opportunity to maneuver this money or not. The situation is characteristic only and exclusively for a business that is not related to IT. For example, we host a large antivirus development in the cloud - banks, insurance, large retail. All of them know their consumption and have sufficient reserve to accommodate additional capacity at any time.
Large customers usually have problems not at the stage of unfolding machines, but at the stage of raising all the tunnels. And, of course, large companies - their administrators usually have more competence. They can afford more expensive administrators.
Compatibility
OS migration: many try to use what they already have. And do not pay attention to the compatibility of their OS with VMware. Suppose there are high-loaded Debian databases.
Or, in the LVM compiled on SSD disks, 7K disks are added by mistake, and then the client tries to blame us for the speed of SSD disks that does not match the stated speed.
It is very important: it may seem that this is a completely unnecessary educational program and everyone knows this very well. But no. I highly recommend doing a list check when moving.
We can advise in difficult cases to switch to CentOS or Red Hat, but in general it is better to think about this before planning the move.
Rarer cases
The client is preparing to migrate to the cloud. The system administrator made RAID-5 on his servers in a degraded state, “touched” before being fired. Then he left the company. Some time passed, preparations began for the move. In the course of the preparation, one disk flew out of the RAID. There base 1C. They could not restore themselves: something with the physics of the disk. Backup was not configured. No comment what is called.
A similar case was with a fire: there the backup was in the same server room where the main database worked.
Often include the second network interfaces, and then for a long time can not deal with routing. Two interfaces in the system scare untrained admins. This is usually a small business: there are not enough competences, technical education leaves much to be desired. They say: "We desperately need a second network interface", - respectively, add it. Then you need to adjust, and everything stops working correctly for them. The error is not one-time. We are now writing a tutorial on how to configure what should work and on what OS it is done.
We received a claim from the client, the client bought VDC and added a VM to two interfaces, one to the internal network, another to the external one, and, in fact, got confused in two interfaces. In order to organize the routing, I used network bridges and decided to install the PROXMOX 5 hypervisor. They helped to resolve everything quickly - the peculiarity was that the customers had not worked with this architecture before. Well, they turned in time before building this structure with the hypervisor in the hypervisor.
At one client remote workplaces braked. The solution is simple: it turned out that 10 Mbit / s come to the office in a hundred of machines.
Another client could not move us because his old cloud provider did not let go. Reduced the speed of the channel. This only aggravated the situation in their relationship. We can unload all VMs via the fast channel and put them on a closed exchanger. Day to unload: lunch - evening, the next day he left. Everything. That's the way it should be.
Trite people confuse speed: one comrade Megabyte from Megabit began to distinguish only after talking with us.
In general, all people are very overloaded with exploitation, and those who are engaged in writing documents will write very little without techies. And it turns a vicious circle. Because user experience needs to be developed - the technical staff says that there is a problem. And further together this problem is described by the literary language. In fact, there should be a knowledge base.
In general, we, as the exploitation of the cloud, do not have to go anywhere beyond the level of the hypervisor, but due to the fact that, as an integrator, we are doing a number of “big Technoserv” security audits, and we help with architecture, and so on and so forth. But in general, we try not only to solve the problem, but also to form it.
The text was prepared by Dmitry Maximov, Head of the Technoserv Cloud Operations Department.
Source: https://habr.com/ru/post/350038/
All Articles